
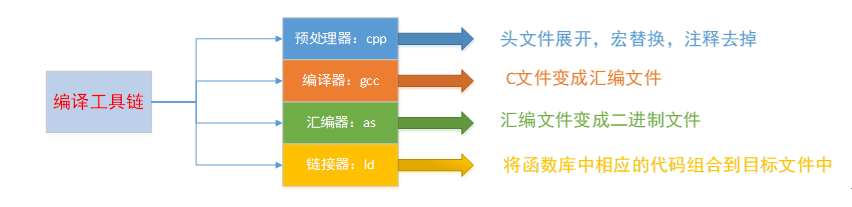
-
预处理: cpp预处理器, 去掉注释, 展开头文件, 宏替换
gcc -E test.c -o test.i -
编译: gcc, 将源代码文件编译成汇编语言代码
gcc -S test.i -o test.s -
汇编: as, 将汇编语言代码编译成了二进制文件(目标代码)
gcc -c test.s -o test.o -
链接: ld, 链接test.c代码中调用的库函数
gcc -o test test.o
-v:查看gcc版本号, --version也可以-E:生成预处理文件-S:生成汇编文件-c:只编译,生成.o文件, 通常称为目标文件-I:指定头文件所在的路径-L:指定库文件所在的路径-l:指定库的名字-o:指定生成的目标文件的名字-g:包含调试信息使用gdb调试需要添加-g参数-On:n=0∼3,编译优化,n越大优化得越多
库是二进制文件, 是源代码文件的另一种表现形式, 是加了密的源代码; 是一些功能相近或者是相似的函数的集合体。
- 提高代码的可重用性, 而且还可以提高程序的健壮性。
- 可以减少开发者的代码开发量, 缩短开发周期。
-
头文件:包含了库函数的声明
-
库文件:包含了库函数的代码实现
-
库不能单独使用, 只能作为其他执行程序的一部分完成某些功能, 也就是说只能被其他程序调用才能使用
-
库可分静态库(static library)和共享库(shared library)
-
一些目标代码的集合,在可执行程序运行前,就已经加入执行码中,成为执行程序的一部分(编译后删除.a无影响)
-
前缀
lib,后缀.a -
制作
- 将.c文件编译成.o文件:
gcc -c fun1.c fun2.c - 使用ar命令将.o文件打包成.a文件:
ar rcs libtest1.a fun1.o fun2.o
- 将.c文件编译成.o文件:
-
使用
-
头文件要引用
-
gcc -o main main.c-I 头文件路径-L .a文件路径-l 库名(只要中间,不带lib和.a) -
main.c与head.h和libtest1.a在同一级目录的情况:
gcc -o main1 main.c -I./ -L./ -ltest -
main.c与head.h和libtest1.a在不同一级目录的情况:
gcc -o main1 main.c -I./include -L./lib -ltest1
-
-
优缺点:
- 函数库最终被打包到应用程序中,实现是函数本地化,寻址方便、速度快。(库函数调用效率自定义函数使用效率)
- 程序在运行时与函数库再无瓜葛,移植方便。
- 消耗系统资源较大, 每个进程使用静态库都要复制一份, 无端浪费内存。
- 静态库会给程序的更新、部署和发布带来麻烦。如果静态库libxxx.a更新了,所有使用它的应用程序都需要重新编译、发布给用户(对于玩家来说,可能是一个很小的改动,却导致整个程序重新下载)。
- 不同程序都用一个库,内存中只要一份该共享库的拷贝,共享库在程序编译过程中不会连接到目标程序中,运行时才被引入。
- 前缀
lib,后缀.so - 制作:
- 将.c文件编译成.o文件:
gcc -fpic -c fun1.c fun2.c - 使用gcc将.o文件编译成库文件:
gcc -shared fun1.o fun2.o -o libtest2.so
- 将.c文件编译成.o文件:
- 使用与静态库相同,
nm命令可以查看.so库中有哪些函数 - 特点:
- 动态库把对一些库函数的链接载入推迟到程序运行的时期。
- 可以实现进程之间的资源共享。(因此动态库也称为共享库)
- 将一些程序升级变得简单。
- 甚至可以真正做到链接载入完全由程序员在程序代码中控制(显示调用)
- makefile文件中定义了一系列的规则来指定, 哪些文件需要先编译, 哪些文件需要后编译, 哪些文件需要重新编译, 甚至于进行更复杂的功能操作, 因为makefile就像一个Shell脚本一样, 其中也可以执行操作系统的命令
- 好处就是——“自动化编译”, 一旦写好, 只需要一个make命令, 整个工程完全自动编译, 极大的提高了软件开发的效率
- make是一个命令工具, 是一个解释makefile中指令的命令工具
- makefile文件中会使用gcc编译器对源代码进行编译, 最终生成可执行文件或者是库文件
- makefile文件的命名:makefile或者Makefile
-
目标:依赖
(tab)命令
-
三要素:
- 目标: 要生成的目标文件
- 依赖: 目标文件由哪些文件生成
- 命令: 通过执行该命令由依赖文件生成目标
main:main.c fun1.c fun2.c sum.c
gcc -o main main.c fun1.c fun2.c sum.c -I./-
缺点:效率低,修改一个文件, 所有的文件会全部重新编译
-
Makefile注释:
#多行前插入#:Ctrl+V进入列模式,hjkl移动选定,大I(shift+I)插入,#,两次ESC
-
Makefile工作原理:
-
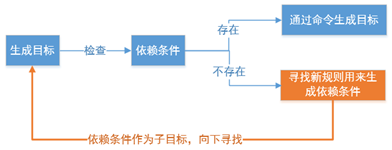
基本原则:若想生成目标, 检查规则中的所有的依赖文件是否都存在
-
如果有的依赖文件不存在, 则向下搜索规则, 看是否有生成该依赖文件的规则
- 如果有规则用来生成该依赖文件, 则执行规则中的命令生成依赖文件
- 如果没有规则用来生成该依赖文件, 则报错
-
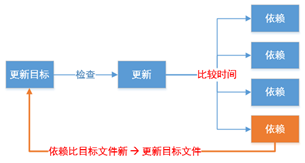
如果所有依赖都存在, 检查规则中的目标是否需要更新, 必须先检查它的所有依赖,依赖中有任何一个被更新, 则目标必须更新.(检查的规则是哪个时间大哪个最新)
- 若目标的时间 > 依赖的时间, 不更新
- 若目标的时间 < 依赖的时间, 则更新
-
main:main.o fun1.o fun2.o sum.o
gcc -o main main.o fun1.o fun2.o sum.o
main.o:main.c
gcc -o main.o -c main.c -I./
fun1.o:fun1.c
gcc -o fun1.o -c fun1.c
fun2.o:fun2.c
gcc -o fun2.o -c fun2.c
sum.o:sum.c
gcc -o sum.o -c sum.c
-
缺点:冗余, 若.c文件数量很多, 编写起来比较麻烦
-
Makefile中的变量:
-
类似于C语言中的宏定义, 使用该变量相当于内容替换, 使用变量可以使makefile易于维护, 修改起来变得简单
-
变量分三种:普通变量、自带变量、自动变量
-
普通变量
- 变量定义直接用
=:foo = abc - 使用变量值用
$(变量名):bar = $(foo)
- 变量定义直接用
-
自带变量:makefile中也提供了一些变量(变量名大写)供用户直接使用, 我们可以直接对其进行赋值
CC= gcc #arm-linux-gccCPPFLAGS: C预处理的选项 -ICFLAGS: C编译器的选项 -Wall -g -cLDFLAGS: 链接器选项 -L -l
-
自动变量:只能在规则命令中使用
$@: 表示规则中的目标$<: 表示规则中的第一个条件$^: 表示规则中的所有条件, 组成一个列表, 以空格隔开, 如果这个列表中有重复的项则消除重复项。
-
-
模式规则:用%,
%.o,%.c
target=main
object=main.o fun1.o fun2.o sum.o
CC=gcc
CPPFLAGS=-I./
$(target):$(object)
$(CC) -o $@ $^
%.o:%.c
$(CC) -o $@ -c $< $(CPPFLAGS) - Makefile函数:makefile中的函数有很多, 在这里给大家介绍两个最常用的:
wildcard:查找指定目录下的指定类型的文件,src=$(wildcard *.c),找到当前目录下所有后缀为.c的文件,赋值给srcpatsubst:匹配替换,obj=$(patsubst %.c,%.o, $(src)),把src变量里所有后缀为.c的文件替换成.o
src=$(wildcard ./*.c)
object=$(patsubst %.c, %.o, $(src))
target=main
CC=gcc
CPPFLAGS=-I./
$(target):$(object)
$(CC) -o $@ $^
%.o:%.c
$(CC) -o $@ -c $< $(CPPFLAGS) - Makefile清理:清除编译生成的中间.o文件和最终目标文件
- clean 如果当前目录下有同名clean文件,则不执行clean对应的命令,解决方案:
PHONY:clean,声明目标为伪目标之后, makefile将不会检查该目标是否存在或者该目标是否需要更新
- clean命令中的特殊符号:
-:此条命令出错,make也会继续执行后续的命令。如:“-rm main.o”@:不显示命令本身, 只显示结果。如:“@echo clean done”
- clean 如果当前目录下有同名clean文件,则不执行clean对应的命令,解决方案:
- make 默认执行第一个出现的目标, 可通过make dest指定要执行的目标
- make -f : -f执行一个makefile文件名称, 使用make执行指定的makefile: make -f mainmak
src=$(wildcard ./*.c)
object=$(patsubst %.c, %.o, $(src))
target=main
CC=gcc
CPPFLAGS=-I./
$(target):$(object)
$(CC) -o $@ $^
%.o:%.c
$(CC) -o $@ -c $< $(CPPFLAGS)
.PHONY:clean
clean:
-rm -f $(target) $(object)GDB(GNU Debugger)是GCC的调试工具,主要帮你完成下面四个方面的功能:
- 启动程序, 可以按照你的自定义的要求随心所欲的运行程序。
- 可让被调试的程序在你所指定的断点处停住。(断点可以是条件表达式)
- 当程序被停住时, 可以检查此时你的程序中所发生的事。
- 动态的改变你程序的执行环境。
首先在编译时, 我们必须要把调试信息加到可执行文件中,使用编译器(cc/gcc/g++)的`-g`参数,如果没有`-g`,你将看不见程序的函数名、变量名。所代替的全是运行时的内存地址。
- 启动:
gdb+程序,执行gdb进入gdb环境 - 设置运行参数:
set args,如:set args 10 20 30 40 50 - 查看设置的运行参数:
show args - 启动程序:
run:程序开始执行, 如果有断点, 停在第一个断点处start:程序向下执行一行。(在第一条语句处停止)
list命令显示源代码,默认10行list linenum:打印第linenum行的上下文内容.list function:显示函数名为function的函数的源程序。list: 显示当前行后面的源程序。list -:显示当前文件开始处的源程序。list file:linenum: 显示file文件下第n行list file:function: 显示file文件的函数名为function的函数的源程序
- 简单断点,当前文件:
break设置断点, 可以简写为bb 10设置断点, 在源程序第10行b func设置断点, 在func函数入口处
- 多文件设置断点,其他文件
b filename:linenum在源文件filename的linenum行处停住b filename:function在源文件filename的function函数的入口处停住
- 查询所有断点
info b==info break==i break==i b - 条件断点:为断点设置一个条件, 我们使用if关键词, 后面跟其断点条件。设置一个条件断点:
b test.c:8 if intValue == 5 - 删除断点:
delete可简写为d- 删除某个断点:
delete num - 删除多个断点:
delete num1 num2 ... - 删除连续的多个断点:
delete m-n - 删除所有断点:
delete
- 删除某个断点:
- 使指定断点无效:
disable简写为dis。不会删除,要用时可enable- 使一个断点无效/有效:
disable num - 使多个断点无效有效:
disable num1 num2 ... - 使多个连续的断点无效有效:
disable m-n - 使所有断点无效有效:
disable
- 使一个断点无效/有效:
- 使无效断点生效:
enable简写为ena- 使一个断点无效/有效:
enable num - 使多个断点无效有效:
enable num1 num2 ... - 使多个连续的断点无效有效:
enable m-n - 使所有断点无效有效:
disable/enable
- 使一个断点无效/有效:
-
run运行程序, 可简写为r -
next单步跟踪, 函数调用当作一条简单语句执行, 可简写为n -
step单步跟踪, 函数调进入被调用函数体内, 可简写为s -
finish退出进入的函数, 如果出不去, 看一下函数体中的循环中是否有断点,如果有删掉,或者设置无效 -
until在一个循环体内单步跟踪时, 这个命令可以运行程序直到退出循环体,可简写为u,如果出不去, 看一下函数体中的循环中是否有断点,如果有删掉,或者设置无效
-
continue继续运行程序, 可简写为c(若有断点则跳到下一个断点处)
- 查看运行时变量的值:
print打印变量、字符串、表达式等的值, 可简写为p - 自动显示变量的值:当程序停住时, 或是在你单步跟踪时, 这些变量会自动显示
display变量名info display:查看display设置的自动显示的信息。undisplay num(info display时显示的编号)delete display dnums:删除自动显示, dnums意为所设置好了的自动显式的编号。如果要同时删除几个, 编号可以用空格分隔, 如果要删除一个范围内的编号, 可以用减号表示disable display dnums:使自动显示无效enable display dnums:使无效自动显示有效
- 查看修改变量的值
ptype width:查看变量width的类型p width:打印变量width的值set var width=47:将变量var值设置为47