




该语料库包含从网站Insurance Library 收集的问题和答案。
据我们所知,本数据集发布之时,2017 年,这是保险领域首个开放的QA语料库:
-
该语料库的内容由现实世界的用户提出,高质量的答案由具有深度领域知识的专业人士提供。 所以这是一个具有真正价值的语料,而不是玩具。
-
在上述论文中,语料库用于答复选择任务。 另一方面,这种语料库的其他用法也是可能的。 例如,通过阅读理解答案,观察学习等自主学习,使系统能够最终拿出自己的看不见的问题的答案。
-
数据集分为两个部分“问答语料”和“问答对语料”。问答语料是从原始英文数据翻译过来,未经其他处理的。问答对语料是基于问答语料,又做了分词和去标去停,添加label。所以,"问答对语料"可以直接对接机器学习任务。如果对于数据格式不满意或者对分词效果不满意,可以直接对"问答语料"使用其他方法进行处理,获得可以用于训练模型的数据。
- Python: 2.x, 3.x
- Pip
pip install -U insuranceqa_data
进入证书商店,购买证书,购买后进入【证书-详情】,点击【复制证书标识】。
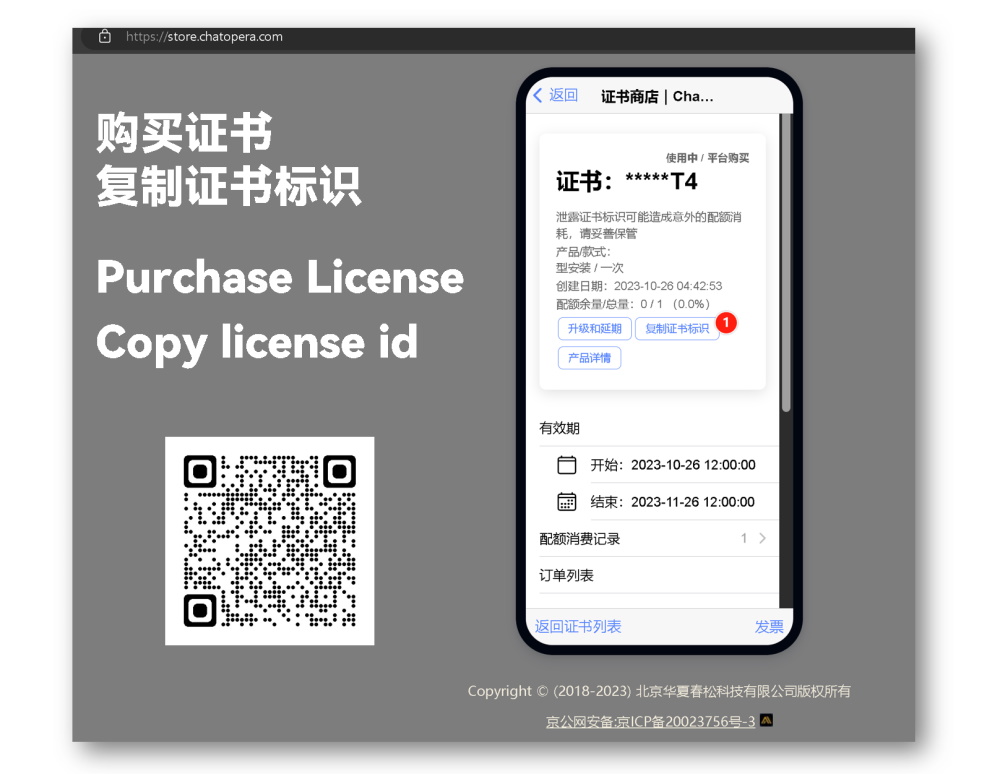
然后,设置环境变量 INSQA_DL_LICENSE,比如使用命令行终端:
# Linux / macOS
export INSQA_DL_LICENSE=YOUR_LICENSE
## e.g. if your license id is `FOOBAR`, run `export INSQA_DL_LICENSE=FOOBAR`
# Windows
## 1/2 Command Prompt
set INSQA_DL_LICENSE=YOUR_LICENSE
## 2/2 PowerShell
$env:INSQA_DL_LICENSE='YOUR_LICENSE'最后,执行以下命令,完成数据的下载。
python -c "import insuranceqa_data; insuranceqa_data.download_corpus()"数据分为两种:POOL 格式;PAIR 格式。其中,PAIR 格式更适合用于机器学习训练模型。
import insuranceqa_data as insuranceqa
train_data = insuranceqa.load_pool_train() # 训练集
test_data = insuranceqa.load_pool_test() # 测试集
valid_data = insuranceqa.load_pool_valid() # 验证集
# valid_data, test_data and train_data share the same properties
for x in train_data: # 打印数据
print('index %s value: %s ++$++ %s ++$++ %s' % \
(x, train_data[x]['zh'], train_data[x]['en'], train_data[x]['answers'], train_data[x]['negatives']))
answers_data = insuranceqa.load_pool_answers()
for x in answers_data: # 答案数据
print('index %s: %s ++$++ %s' % (x, answers_data[x]['zh'], answers_data[x]['en']))| - | 问题 | 答案 | 词汇(英语) |
|---|---|---|---|
| 训练 | 12,889 | 21,325 | 107,889 |
| 验证 | 2,000 | 3354 | 16,931 |
| 测试 | 2,000 | 3308 | 16,815 |
每条数据包括问题的中文,英文,答案的正例,答案的负例。案的正例至少1项,基本上在1-5条,都是正确答案。答案的负例有200条,负例根据问题使用检索的方式建立,所以和问题是相关的,但却不是正确答案。
{
"INDEX": {
"zh": "中文",
"en": "英文",
"domain": "保险种类",
"answers": [""] # 答案正例列表
"negatives": [""] # 答案负例列表
},
more ...
}
-
训练:
corpus/pool/train.json.gz -
验证:
corpus/pool/valid.json.gz -
测试:
corpus/pool/test.json.gz -
答案:
corpus/pool/answers.json一共有 27,413 个回答,数据格式为json:
{
"INDEX": {
"zh": "中文",
"en": "英文"
},
more ...
}
格式 INDEX ++$++ 保险种类 ++$++ 中文 ++$++ 英文
corpus/pool/train.txt.gz, corpus/pool/valid.txt.gz, corpus/pool/test.txt.gz.
格式 INDEX ++$++ 中文 ++$++ 英文
corpus/pool/answers.txt.gz
语料库使用gzip进行压缩以减小体积,可以使用zmore, zless, zcat, zgrep等命令访问数据。
zmore pool/test.txt.gz
使用"问答数据",还需要做很多工作才能进入机器学习的模型,比如分词,去停用词,去标点符号,添加label标记。所以,在"问答数据"的基础上,还可以继续处理,但是在分词等任务中,可以借助不同分词工具,这点对于模型训练而言是有影响的。为了使数据能快速可用,insuranceqa-corpus-zh提供了一个使用HanLP分词和去标,去停,添加label的数据集,这个数据集完全是基于"问答数据"。
import insuranceqa_data as insuranceqa
train_data = insuranceqa.load_pairs_train()
test_data = insuranceqa.load_pairs_test()
valid_data = insuranceqa.load_pairs_valid()
# valid_data, test_data and train_data share the same properties
for x in test_data:
print('index %s value: %s ++$++ %s ++$++ %s' % \
(x['qid'], x['question'], x['utterance'], x['label']))
vocab_data = insuranceqa.load_pairs_vocab()
vocab_data['word2id']['UNKNOWN']
vocab_data['id2word'][0]
vocab_data['tf']
vocab_data['total']vocab_data包含word2id(dict, 从word到id), id2word(dict, 从id到word),tf(dict, 词频统计)和total(单词总数)。 其中,未登录词的标识为UNKNOWN,未登录词的id为0。
train_data, test_data 和 valid_data 的数据格式一样。qid 是问题Id,question 是问题,utterance 是回复,label 如果是 [1,0] 代表回复是正确答案,[0,1] 代表回复不是正确答案,所以 utterance 包含了正例和负例的数据。每个问题含有10个负例和1个正例。
train_data含有问题12,889条,数据 141779条,正例:负例 = 1:10
test_data含有问题2,000条,数据 22000条,正例:负例 = 1:10
valid_data含有问题2,000条,数据 22000条,正例:负例 = 1:10
句子长度:
max len of valid question : 31, average: 5(max)
max len of valid utterance: 878(max), average: 165(max)
max len of test question : 33, average: 5
max len of test utterance: 878, average: 161
max len of train question : 42(max), average: 5
max len of train utterance: 878, average: 162
vocab size: 24997
可将本语料库和以下开源码配合使用
deep-qa-1: Baseline model
InsuranceQA TensorFlow: CNN with TensorFlow
n-grams-get-started: N元模型
word2vec-get-started: 词向量模型
声明1 : insuranceqa-corpus-zh
本数据集使用翻译 insuranceQA而生成,代码发布证书Chunsong Public License, version 1.0。数据仅限于研究用途,如果在发布的任何媒体、期刊、杂志或博客等内容时,必须注明引用和地址。
InsuranceQA Corpus, Chatopera Inc., https://github.com/chatopera/insuranceqa-corpus-zh, 07 27, 2017
任何基于insuranceqa-corpus衍生的数据也需要开放并需要声明和“声明1”和“声明2”一致的内容。
声明2 : insuranceQA
此数据集仅作为研究目的提供。如果您使用这些数据发表任何内容,请引用我们的论文:Applying Deep Learning to Answer Selection: A Study and An Open Task。Minwei Feng, Bing Xiang, Michael R. Glass, Lidan Wang, Bowen Zhou @ 2015