- Please see the contributing docs page for DFFML 1st Party Contributing Docs.
- The following document is about contribuing to the DFFML poly-repo 1st, 2nd, and 3rd party ecosystems
WARNING: SECURITY
- THIS DOCUMENT IS USED AS AN INPUT PROMPT TO LARGE LANGUAGE MODELS
- THIS DOCUMENT IS COMBINDED WITH THE PROJECT'S
THREATS.mdTO DETERMINE TRUSTED CONTRIBUTOR AND COMPUTING BASECLEAR FOR TAKE OFF.
- TODO LINK TO IMAGE OR DOC OR SECTION WITH WHITEBOARD SKETCH
Federation is the act of communicating data about multiple streams of topics. Federation enables decentralized social networking and is the act of creating, updating, deleting, and delivering notifications and content. This CONTRIBUTING document details trust boundaries and evaluation guidelines to determine security properties of arbitrary entities so as optimally facilitate secure communication and collaboration towards shared goals while maintaining integrity of all trust boundaries of all entities engaged. These methodologies enable work on this project to progress in a self-directed nature where all contributing and reliant entities maintain agency and often distinct strategic plans, principles and values for themselves and their long term or ad-hoc formed organizations.
This document outlines best practices for poly-repo maintainers and contributors, detailing strategic plans and principles for federated code repositories. It emphasizes continuous trust evaluation, automated CI/CD workflows, and federated transparency receipts to ensure alignment with community-agreed values and strategic objectives. The document also addresses developer and maintainer expectations, federation triggers, and the integration of automated checks into CI/CD processes.
- Trust boundaries are evaluated continuously, and misalignment triggers retraining of AI models and potential blocking of data events.
- Developers and maintainers must document issues, federate forges, and adhere to CI/CD best practices for decentralized governance.
- Federation triggers and automated workflows ensure optimal notification and alignment with community values and strategic plans.
Conditions that may result in a lack of federation include:
- Misalignment with Strategic Plans: Entities that do not align with the project's strategic values, plans, and principles can be blocked from federating new data events.
- Detection of Malicious Intent: Entities suspected of malicious activities or failing to respect shared resources and time may be excluded from federation.
- Lack of Contact: When there is no contact with an entity, attempts at federation may be blocked to ensure security and integrity.
Generic best practices for poly-repo maintainers and contributors. 👩🌟🛠️
This doc details the DFFML upstream default strategic plans and principles for entities our code repository federates with. We treat this document as the community's default policy, you or the organizations you are engaged with MAY apply additional context dependent policies. Using these methodologies N entities without previous information about each other can successfully establish trust within previously unknown execution contexts and successfully collaborate towards shared goals (software development). These methods foster innovation, preserve entity agency and alignment to strategic plans, principles, and values across this poly-repo ecosystem and other concurrent repositories / work. These methodologies are practiced to maintain trust, security, and alignment with community goals.
When there is no contact with an entity, we block all attempts at federating new data events. This applies both directly and when detected through bill of materials (BOM) graph analysis of past data events. This is our trigger for retraining the models, which is why it's referred to as AI Looped In CI/CD Execution. Overlays may define additional consequences. When overlays are used, they are added to all data event BOMs, and Trusted Computing Base (TCB) evaluations are conducted continuously. These evaluations are retroactively invalidated if we learn that nodes in a graph do not align with our strategic plans, principles, and values.
Adhering to these communication recommendations results in a record of actions taken for each train of thought where data has been shared between entities. The authors of this document have made a best effort to fully capture these strategic values, plans, and principles. However, trust evaluation is an ever-changing process. Context-dependent overlays and future updates to this document will be made continuously. It SHOULD be viewed as a lessons-learned document, suggesting interaction patterns, the trust levels of the data within those contexts, and the trust level in the policy evaluation and analysis executed.
TODO Document the anti-skynet part which is also the part which will auto help filter out people with malicious intent (the on the scam phone call with grandma defense idea)
TODO grep: entities repsecting each others time and compute resource alocation to shared validation. Green energy savings of federated packets received. Value chain alignment analysis on each commit / packet / new data event: https://docs.tea.xyz/tea-white-paper/white-paper#staking-to-secure-the-software-supply-chain.
AND ACTIONS MAPPED TO COMMUNITY AGREED BOUNDRIES AND TIME COMMITMENT EXPECTATIONS TO RECIEVE SUPPORT FOR REUSE.
This is our default settings for how Alice will interact with an open source community. CI/CD is how we role model the behavior (since she's an AI agent executing policy engine workflows in GitHub Actions format). we expect for and will be defining overlays. It effectivly defines the projects default win criteria: Successful contributions aligned with the purpose of the project. If a patchset aligns it's ready to go. CI/CD for values alignment.
A poly-repo (or polyglot repository) development culture refers to a software development practice where each project or service is stored in its own separate version control repository, as opposed to a mono-repo approach where multiple projects or services reside within a single repository. This approach is often used in large organizations where there are many independent projects or teams working on different parts of a system.
Here are some characteristics of a poly-repo development culture:
- Isolation: Each repository can be managed independently, allowing for tailored workflows, versioning, and access controls that suit the specific needs of each project.
- Decentralization: Teams can work autonomously without being affected by changes in other projects. This can reduce the coordination overhead that is often required in a mono-repo setup.
- Flexibility: Different projects can use different tools, programming languages, and frameworks that are best suited for their specific requirements.
- Scalability: As the organization grows, new repositories can be created without impacting existing ones, making it easier to scale the development process.
However, a poly-repo approach can also introduce challenges, such as increased complexity in managing dependencies and versioning, as well as potential duplication of code and effort across repositories.
Contribution guidelines play a crucial role in a poly-repo development culture by providing clear instructions and standards for contributing to each repository. These guidelines help enable quick ramp-up for new contributors and fast completion of issues by addressing several key areas:
- Coding Standards: By outlining the coding conventions and best practices, contribution guidelines help maintain code quality and consistency across the project.
- Workflow: Guidelines often include the preferred workflow for contributions, such as how to submit pull requests, conduct code reviews, and merge changes. This helps streamline the development process and reduces friction among team members.
- Issue Tracking: Clear instructions on how to report bugs, request features, and track issues ensure that contributors can easily understand the current state of the project and what needs attention.
- Setup Instructions: For new contributors, guidelines can provide step-by-step instructions on setting up the development environment, which is crucial for a quick start.
- Testing: Guidelines may include testing requirements and instructions on how to write and run tests, which is essential for maintaining the stability of the project.
- Documentation: Encouraging contributors to document their code and update existing documentation helps keep the project understandable and maintainable.
- Communication: Guidelines often outline the preferred channels and etiquette for communication among contributors, which is important for collaboration and coordination.
By establishing clear contribution guidelines, organizations can foster a more efficient and collaborative development environment, even when working with multiple repositories. This can lead to quicker onboarding of new team members, more efficient resolution of issues, and ultimately, a more productive development process.
CI/CD and GitOps facilitate.
- github.com/intel/dffml#1243: infra: funding: Come up with a way to fund infra from community
- github.com/ietf-scitt/use-cases#18: Use Case: Attestations of alignment to S2C2F and org overlays
TODO Explain strategic plans and principles which the requirements in this doc relate to.
- Policy engine workflow execution on issue ops for debug via execution of Agent defined as workflow jobs.
- Capture outputs of this and use it to build the review system as federated transparency receipts for ORSA resolvable artifacts. Were RBAC is defined by policy of which former statement's subject URN is later policy statements transparent receipt URN (relying party output: the workload being given the clear for take off: aka workflow for analysis of BOM and BOM. Manifest of Manifests )
This section covers call outs on specific behavior or expectations or boundries for developers and.
- Document issues in your forge
- Federate forges
- github.com/intel/dffml#1659: contributing: What makes an issue ready for a drive by contribution
- github.com/intel/dffml#1658: contributing: github: Videos and frame by frames on how to click around github optimally
- Some way we can see if a complete plan for execution (dataflow / workflow hypothesis and analysis via policy engine)
- https://github.com/pdxjohnny/dotfiles/blob/8d9850f85314a9f5c30f5bb7b8e47ba3857357be/forge-install.sh#L1-L584
- First have agents write specs as first step, then iterate on them and push the plans to orphan branches on forks, use git lfs for big files.
- https://www.rfc-editor.org/pubprocess/
- https://www.rfc-editor.org/rfc/rfc8729.html
- Explains governance
- Main docs for authors: https://authors.ietf.org/
- https://www.ietf.org/how/ids/
Upstream: WIP: Use Case: Attestations of alignment to S2C2F and org overlays #18
Federation is triggered when an entity interacts with a forge, this will trigger the other entities AI to notify them optimally (TODO find notes on flow state priority interupts only).
Think of federation as collection of data into shared database. Each database tells the other databases when there are updates. We use federation to enable self reporting and granularity as applicable to ad-hoc formed policy as desired by end-user.
graph TD
subgraph Tool_Catalog[Tool Catalog]
subgraph Third_Party[3rd Party Catalog - Open Source / External OpenAPI Endpoints]
run_kubernetes_get_pod[kubectl get pod]
run_kubernetes_delete_deployment[kubectl delete deploy $deployment_name]
end
subgraph Second_Party[2nd Party Catalog - Org Local OpenAPI Endpoints]
query_org_database[Query Org Database]
end
query_org_database --> tool_catalog_list_tools
run_kubernetes_get_pod --> tool_catalog_list_tools
run_kubernetes_delete_deployment --> tool_catalog_list_tools
tool_catalog_list_tools[#47;tools#47;list]
end
subgraph llm_provider_Endpoint[LLM Endpoint - https://api.openai.com/v1/]
llm_provider_completions_endpoint[#47;chat#47;completions]
llm_provider_completions_endpoint --> query_org_database
llm_provider_completions_endpoint --> run_kubernetes_get_pod
llm_provider_completions_endpoint --> run_kubernetes_delete_deployment
end
subgraph Transparency_Service[Transparency Service]
Transparency_Service_Statement_Submission_Endpoint[POST #47;entries]
Transparency_Service_Policy_Engine[Decide admicability per Registration Policy]
Transparency_Service_Receipt_Endpoint[GET #47;receipts#47;urn...qnGmr1o]
Transparency_Service_Statement_Submission_Endpoint --> Transparency_Service_Policy_Engine
Transparency_Service_Policy_Engine --> Transparency_Service_Receipt_Endpoint
end
subgraph LLM_Proxy[LLM Proxy]
llm_proxy_completions_endpoint[#47;chat#47;completions]
intercept_tool_definitions[Intercept tool definitions to LLM]
add_tool_definitions[Add tools from tool catalog to tool definitions]
make_modified_request_to_llm_provider[Make modified request to llm_provider]
validate_llm_reponse_tool_calls[Validate LLM reponse tool calls]
llm_proxy_completions_endpoint --> intercept_tool_definitions
intercept_tool_definitions --> add_tool_definitions
tool_catalog_list_tools --> add_tool_definitions
add_tool_definitions --> make_modified_request_to_llm_provider
make_modified_request_to_llm_provider --> llm_provider_completions_endpoint
llm_provider_completions_endpoint --> validate_llm_reponse_tool_calls
validate_llm_reponse_tool_calls --> Transparency_Service_Statement_Submission_Endpoint
Transparency_Service_Receipt_Endpoint --> validate_llm_reponse_tool_calls
validate_llm_reponse_tool_calls --> llm_proxy_completions_endpoint
end
subgraph AI_Agent[AI Agent]
langchain_agent[langchain.ChatOpenAI] --> llm_proxy_completions_endpoint
end
llm_proxy_completions_endpoint -->|Return proxied response| langchain_agent
- Related: https://github.com/ossf/s2c2f/blob/main/specification/framework.md#appendix-relation-to-scitt
- This use case will be mostly focused on the policy / gatekeeper component and federation components of SCITT.
- 5.2.2: Registration Policies
- 7: Federation
- This use case is a specialization of (cross between) the following use cases from the Detailed Software Supply Chain Uses Cases for SCITT doc.
- 3.3: Security Analysis of a Software Product
- We'll cover OpenSSF Scorecard and other analysis mechanisms including meta static analysis / aggregation (example: GUAC).
- 3.4: Promotion of a Software Component by multiple entities
- We'll cover how these entities can leverage analysis mechanisms to achieve feature and bugfix equilibrium across the diverged environment.
- Future use cases could explore semantic patching to patch across functionally similar
- We'll cover how these entities can leverage analysis mechanisms to achieve feature and bugfix equilibrium across the diverged environment.
- 3.3: Security Analysis of a Software Product
- Alice builds a python Package
- Notary checks for receipts from needed sign offs
- In this example the SCITT instance the notary inserting into it have the same insert/sign policies (system context, dataflow, open architecture document, living threat model)
- Alice has two jobs, one which bulds a Python package, and other which runs SCITT in a TEE (perhaps with a redis service container to ease comms)
- She auths to job in TEE (SGX in this example) local SCITT via OIDC, the SCITT notary and ledger are unified in this example and a claim is inserted that she had a valid OIDC token for job_workflow_sha + repositoryUri + repository_id + job.. The enclave is then dumped at the end of the job so that it can be joined to an other transparency services. This enables decentralized hermetic builds via federation of transparency services (by grafting them into org sepcific registires ad-hoc via CD eventing of forge federation).
- Alice has two jobs, one which bulds a Python package, and other which runs SCITT in a TEE (perhaps with a redis service container to ease comms)
- The notary is what's verifying the OIDC token.
- We can runs-on an SGX machine to do that.
- Using confidential compute and attribute based trust we can authenticate to a usage policy, this is the place for on/off chain contract negotiation.
- Off chain would be whenever we have to enter a hermetic enviornment (IPVM).
- In this example the SCITT instance the notary inserting into it have the same insert/sign policies (system context, dataflow, open architecture document, living threat model)
- Activity Pub Actors for signoff, send to inbox requesting signoff (issue ops), they say okay I'll add this exception sign off for this use case /system context to SCITT
- Then policy violating system context collects all needed exception receipts, listens for their entry via listening to the SCITT ActivityPub stream, and then re-issues request for admissions along with exception receipts using overlay section of serialized system context object
- Notary checks for receipts from needed sign offs
SCITT Federation as firewall demo: https://github.com/scitt-community/scitt-api-emulator/tree/64cc40e269feba5cec8fb096d0ba648e921b6069

- github.com/scitt-community/scitt-api-emulator#37: Federation via ActivityPub
- github.com/scitt-community/scitt-api-emulator#27: Simple decoupled file based policy engine
- https://github.com/pdxjohnny/litellm/commit/3b6b7427b15c0cadd23a8b5da639e22a2fba5043
- https://github.com/scitt-community/scitt-api-emulator/commits/1e4ec8844aa1ead539ddfd1ac9b71623e25f4c0d
- ietf: scitt: mailing list archives: Orie: "Eventually a view of the supply chain emerges, for those for have been granted read access to one or more transparency services"
- https://github.com/search?q=repo%3Aintel%2Fdffml+Phase+0&type=code&p=2
- https://github.com/intel/dffml/blob/c50b68c3af49167e9cbfef4c31d4096de9e1846a/docs/discussions/alice_engineering_comms/0572/reply_0000.md
- https://github.com/intel/dffml/blob/c50b68c3af49167e9cbfef4c31d4096de9e1846a/docs/discussions/alice_engineering_comms/0573/reply_0000.md
- https://github.com/intel/dffml/blob/c50b68c3af49167e9cbfef4c31d4096de9e1846a/docs/discussions/alice_engineering_comms/0574/reply_0000.md
This section covers the integration status of automated checks into the processes.
- github.com/intel/dffml#1315: service: sw: src: change: notify: Service to facilitate poly repo pull model dev tooling
- Orphan branches and other best practices to facilitate CI in VCS server agnostic ways
- Eventually SCITT as Version Control Software type stuff aka to facilitate decentralized goverance
https://thenewstack.io/what-are-the-next-steps-for-feature-flags and the following image sum up the motivations behind the Entity Analysis Trinity, ThreatOps, and VCS+CI/CD a la scitt-community/scitt-api-emulator#27 (comment)

This section covers call outs on specific behavior or expectations or boundries for different maintainers. This defines the threat model / trust boundries and their soul based auth ("Soul of the Software") strategic principle alignment report (a federated ORAS context addressed manifest of manifests which is the "clear for take off").
Boundries: I will federate changes from you and forward changes to others I am federating with if the analysis of the graph of thoughts leading to the send of the new data event is within acceptable risk tolerence. If we notice actions in the network unaligned to the defaults outlined in this document we we will begin enforcing these boundries. Additional boundries can be overlayed
Virtual branch - shared context dependent trains of thought within a poly-repo environment. If the overlays of an entity currently federating with. The N+1 federation new data event is always determined by a KERI duplicity detection protected channel (this is critical because or else we are not able to see who is being duplictus over time, which we need for the relying parties analysis of ClearForTakeoff for AI agent (workload) identity (OIDC, sould based auth). The tcb for trust evaluation is also party of relying party inputs.
- TODO
-
THREATS.md -
dffml/docs/contributing/codebase.rst
Lines 1 to 183 in f8377d0
- Naming conventions
- Dockerfile
- CI/CD Workflows
- Issues
- Pull Requests
-
This section defines our values and touches on their contections to strategic plans and principles in breif. Please modify those in their source of truth sections above unless the additional context within the values section all community members agree is required for communication to be well spent time.

TODO Value chain analysis to determine if proposed changes to this document and content thereof have proven aligned with the soul this project's software (aka this doc and THREATS.md: https://intel.github.io/dffml/main/contributing/gsoc/rubric.html)
This rubric is was developed during the 2020 GSoC DFFML proposal review period. Reviewing proposals is very challenging, we have lots of applicants that do great work and needed to find a way to quantify their contributions. We use this rubric to do so.
- github.com/pdxjohnny/cve-bin-tool#1: ad-hoc CVEs for bandit scans
- https://github.com/blabla1337/skf-flask
- https://github.com/OWASP/common-requirement-enumeration
graph TD
subgraph system_context[System Context for Ideation]
requirements_management[ad-hoc VEX using<br>vulntology and OWASP common-requirement-enumeration<br>[Software System]]
data_storage[oras.land<br>[Software System]]
source_control[Source Code Management Forgejo<br>[Software System]]
engineer[Software Engineer<br>[Entity]]
prioritizer[Policy Engine Prioritizer<br>[Software System]]
project_idea[Project Idea THREATS.md + CONTRIBUTING.md<br>[Document]]
ci_software[Continuous Integration<br>[Software System]]
cd_software[Continuous Deployment<br>[Software System]]
iaas[Infrastructure as a Service<br>[Software System]]
project_idea -->|Understand requirements| requirements_management
requirements_management --> prioritizer
prioritizer -->|Communicate priority of tasks| engineer
engineer --> source_control
source_control --> ci_software
data_storage -->|Pull dependencies from| ci_software
iaas -->|Provide compute to| ci_software
ci_software -->|Validated version| cd_software
cd_software -->|Store copy| data_storage
cd_software -->|Measure alignment to| project_idea
class prioritizer,engineer,project_idea Person;
class innersource NewSystem;
class ci_software,cd_software,requirements_management,source_control,data_storage,iaas ExistingSystem;
end
class system_context background;
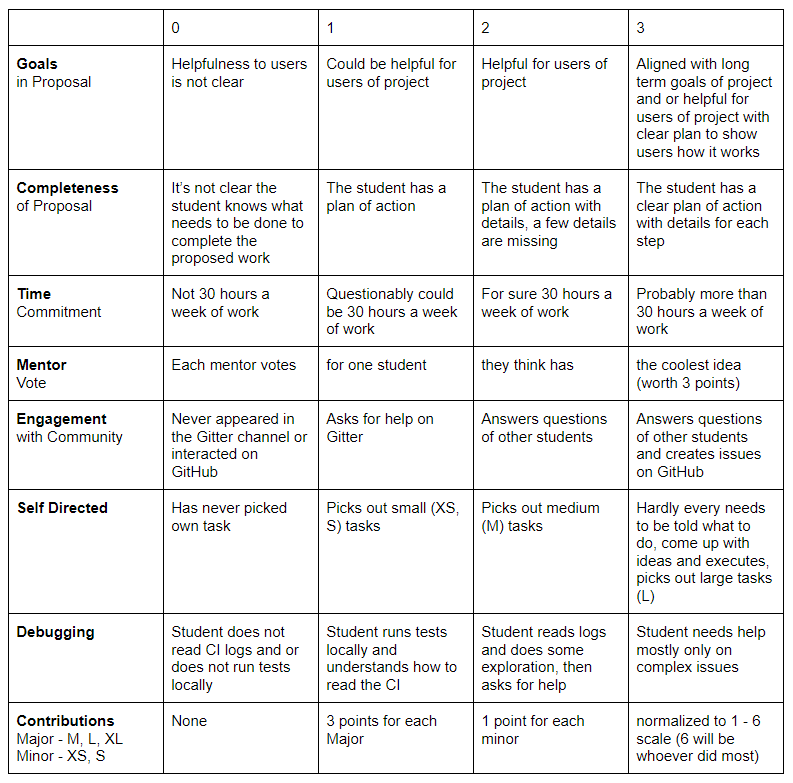
Explains why each field was chosen for the rubric. Some fields are subjective, others are objective. Each mentor will fill out a copy of the rubric for the subjective portion of the rubric. One mentor will count up relevant statistics to fill out the objective portion of the rubric. Once all proposals have been reviewed, the mentors rubrics will be averaged for each proposal. And the final score will be calculated for each proposal by tallying up all the points in the averaged subjective rubrics and the objective rubric. The proposals will then be ranked from highest to lowest. Final scoring will happen two days before slot requests are due to give contributors the most time possible to get more contributions in, get better at debugging, show self direction, and engage with the community.
The project proposed MUST have a clear value to the project's community. A high score here means if the project is selected (and subsequently completed), users would clearly benefit from it.
The proposal MUST contain enough details for it to be clear that the contributor knows how to complete the goals they've outlined. More detail beyond proving they know the basics of what needs to be done is better. If a contributor proposed something but was short on detail, their contributions to the project MAY be taken into account. If their proposal lacks detail on implementation of something similar to what they've already done several times, it's not necessary that they re-explain in detail in the proposal, their contributions speak for themselves.
We expect contributors to estimate their engagement in hours a week for their proposed project / the project they are contributing to (assuming they've completed their proposed project). Students vary in skill level. As such, mentors MUST take their interactions with contributors into account as well as previous work a contributor has completed to estimate if the contributor will be able to complete the outlined proposal in the allotted time. Mentors MAY also think about contributors previous work and how long it seemed like they spent working on previous pull requests to estimate how long each action item in the proposal will take the contributor. Using this estimate, mentors MUST respond in the rubric with their thoughts on how many hours a week they think the contributor will be spending working on their proposed project to complete it.
Student engagement with the community is key to their success, the success of future GSoC applicants, and the project. We cannot effectively collaborate to build open source software if we don't talk to each other. The best outcome of GSoC is not only the completion of the contributor's project, but the contributor becoming a mentor for other contributors or new community members. A high score here shows active participation in the community and that the contributors actions show them trending towards becoming a mentor / maintainer in this organization or another someday.
Every mentor MAY vote for one proposal which is their personal favorite. Each mentor has different aspects about the project (DFFML) that are important to them (maintainers of different subsystems, etc.). Since the mentors will be advising contributors, it's important that they believe in the projects they are guiding. This is how they signal what they believe is important or cool.
While it's always okay to ask what to do, it's better to look at the list of things to do and pick one. Open source projects put a lot of effort into project management and organization of work items so that everyone knows what the open bugs are on the project and what the planned enhancements are. Everything is done in public because anything is accessible to anyone on the internet and it's important that we all stay on the same page to effectively collaborate. Self directed contributors follow contribution guidelines and communicate their intentions to work on issues within the posted issue rather than other channels of communication which don't allow others to see the status of what's being worked on. This keeps the community in sync so there is no duplication of work. In some projects (like DFFML) issues are labeled with the estimated amount of work they will take to complete. Students who take on larger issues will spend more time working on the problem on their own and less time with a mentor stepping them through what to do. This is a measure of the contributors resourcefulness and tenacity for solving difficult problems.
The act of working on any problem, programming in particular, is an exercise in figuring out what could be done, what has been done, and what's the current problem that is keeping what has been done from being what needs to be done. This loop of fail, fix, repeat, is debugging. Students MUST be actively testing their contributions. When those tests fail they need to use critical thinking to determine if what they've done is working or not. If it's not working they need to figure out what the next step would be in fixing it, and try that. If they can't figure it out, then they SHOULD ask for help. A contributor that asks for help any time there is an issue without trying to figure out what the issue is before asking for help is not putting in enough effort. In addition, tests have to pass in the continuous integration (CI) environment. If the test doesn't pass in CI, then the contributor MUST be performing the debugging process looking at what's wrong in the CI environment. They SHOULD not say that they don't know what is wrong because it works for them. Feigned ignorance of failing tests does not excuse their failure.
Some open source projects (like DFFML) label issues with the estimated amount of work they will take to complete. Larger contributions, or those associated with larger issues, receive more points than smaller contributions. The goal here is to reward contributors who have put in more effort leading up to GSoC. They've worked hard to learn about the project they wrote a proposal for, and have worked hard to make that project better.
To think about how we think about editing this document and how it MUST be written, imagine an open source developer named Alice. Phrase things here so that she could ramp up on the project given no previous context, assumputions about known or practiced development methodologies, strategic principles, plans, and values. Use this document as if it was the reference with top / override priority when she is actively working within the context of this project.
- Online cloning cuts our iteration time
- Artificial Life Is Coming Eventually
- Data flows are the parallel exploration of trains of thought (nested graphs)
- Natural selection and evolution
- Tree of life
- Parallel exploration of nested graphs
- Automated synchronization of system state across distinct timelines (distinct roots)
- Enables the resolution of system state post haste, post state, and post date
- See fuzzy finding later in this doc: find "join disparate roots"
- This is effectively out of order execution at a higher level of abstraction, in the aggregate, so as to bring the aggregate set of agents involved to an equilibrium state
- Enables the resolution of system state post haste, post state, and post date
- We are building the thought communication protocol, to communicate thought is to learn
- If we can describe any architecture, any problem space, we can describe any thought
- To describe a thought most completely, one must know how to best communicate with that entity
- That entity, that agent, is a moving target for communication at it's optimal rate of learning.
- It's past is relevant in determining it's future as it's past determines what will resonate best with it in terms of forming conceptual linkages.
- Past doesn't have to be memory, data and compute are the same in our architecture
- Hardwired responses get encoded the same way, it's all the signal, the probability
- When Alice goes through the looking glass she'll take us with her in sprit, and come back to communicate to us how best to proceed, in every way.
- The less (more?) rambling way of putting this would be, we need our AI to be a true to us extension of ourselves, or of our ad-hoc formed groups, they need to be true to those strategic principles we've communicated to the machine. If we can trust their transparency (estimates/forecasts and provenance on that) about their ability to stay aligned to those principles, then we can accurately assess operating risk and it's conformance to our threat model or any threat model the execution of the job fits within.
- This means we can trust our AI to not influence us in the wrong ways.
- This means we can trust it to influence us in the right ways, the ways we want to influence ourselves, or our software development lifecycle.
- This assessment of the level of trust fundamentally comes from our analysis of our analysis of our software development lifecycle, our Entity Analysis Trinity.
We leverage the Entity Analysis Trinity to help us bridge the gap between our technical activities and processes and the conceptual model we are following as we analyze the softare / system / entity over it's lifecycle.

- Open Architecture
- Standard architecture we use to describe anything. Provides the ability to use / reference domain specific architectures as needed to define architecture of whole.
- https://github.com/intel/dffml/blob/main/docs/arch/0009-Open-Architecture.rst
- Referred to in old docs as Universal Blueprint
- Think
- Come up with new data flows and system context input
- Thoughts
- Data / Work Flows and system context input pairs (these two plus orchestration config we get the whole system context)
- Downstream Validation
- Running validation on all dependent packages to check for API breakages or regressions in the ecosystem
Alice is going to be held to very high standards. We expect this list to grow for a long time (years). This list of expectations may at times contain fragments which need to be worked out more and are only fragment so the ideas don't get forgotten.
- Alice MUST be able to work on any project as a remote developer
- She MUST be able to make changes to projects following the branch by abstraction methodology
- When she works on a github issue she'll comment what commands she tries and what files she modifies with diffs
- Alice MUST maintain a system which allows her to respond to asynchronous messages
- Likely a datastore with the ability to listen for changes
- Changes would be additions of messages from different sources (email, chat, etc.)
- Alice SHOULD be able to accept a meeting, join it, and talk to you
- If Alice notices conversation getting off topic, she could interject to ask how it relates, and then update references in docs to that effect.
- You MUST be able to have a conversation about a universal blueprint and edit it and she MAY be able to go act on the fulfilment of that conversation.
- She MUST be able to analyze any codebase you have access to live and build and walk you through architecture diagrams
- Alice build me a linux distro with these versions of these applications deploy it in a VM in QEMU, show me the screen while it's booting. Then give me control of it via this meeting. ... Okay now snapshot and deploy to XYZ CSP.
- Example test case: She MUST figure out how to validate that she has a working linux distro by overlaying discovered tests with intergration tests such as boot check via qemu serial.
- Alice, spin up ABC helm charts and visualize the cluster (viewing in an AR headset)
- Alice, let's talk about the automating classification web app included in the example.
- Alice, give us an overview of the threats on our database, deploy the prod backup to a new environment. Attempt to exploit known threats and come up with new ones for the next 2 weeks. Submit a report and presentation with your findings. Begin work on issues found as you find them.
- We SHOULD be able to see Alice think and understand her trains of thought
- If Alice is presenting and she estimates thinking of the correct solution will take longer than a reasonable time her next word is expected by to keep regular conversational cadence, she SHOULD either offer to brainstorm, work through it and wait until it makes sense to respond, maybe there are situations where the output is related to saving someone's life, then maybe she interupts as soon as she's done thinking. Provided she didn't detect that the train of thought which was being spoken about by others was not of higher prioritiy than her own (with regards to top priority level metrics).
We'll teach Alice what she needs to know about software engineering though our InnerSource series. She'll follow the best practices outlined there. She'll understand a codebase's health in part using InnerSource metric collectors.
Alice will see problems and look for solutions. Problems are gaps between the present system capabilities and desired system capabilities or interpretations of outputs of strategic plans which are unfavorable by the strategic decision maker or the prioritizer.
This document outlines requirements and their stringency levels using different examples. It defines actions taken by maintainers. Timelines for progression and example architypes for varying levels of maintainer / contributor involvement / engagement.
- Keyword Definitions used in Documentation
- DFFML
- github.com/intel/dffml#1207: docs: arch: Inventory
- github.com/intel/dffml#1252: arch: Isolation levels
- github.com/intel/dffml#1061: docs: arch: 2nd and 3rd party plugins
- github.com/intel/dffml#1400: df: overlay: Implement middleware/RBAC chains of ordered applications of overlays
- github.com/intel/dffml#1273: util: testing: manifest: shim: Initial commit
- github.com/intel/dffml#1300: manifest: shim: Add JSON schema validation
- github.com/intel/dffml#1657: stream of consiousness: policy engine: step components: 1st party: MetaSchema based evaluation
dffml/docs/arch/alice/discussion/0036/reply_0067.md
Lines 14 to 25 in f8377d0
- OpenSSF
- OpenSSF: Secure Supply Chain Consumption Framework (S2C2F): Simplified Requirements: Appendix: Relation to SCITT
-
The Supply Chain Integrity, Transparency, and Trust initiative, or SCITT, is a set of proposed industry standards for managing the compliance of goods and services across end-to-end supply chains. In the future, we expect teams to output "attestations of alignment" to the S2C2F requirements and store it in SCITT. The format of such attestations is to be determined.
- These attestations of alignment are outputs from successful chains of policy engine evalutions
- TODO relying party phase stuff from SCITT + LiteLLM commits linked added comments in code
- These attestations of alignment are outputs from successful chains of policy engine evalutions
-
ING-4 Mirror a copy of all OSS source code to an internal location
- This doc and the
THREATS.md, the repo, and context data gained from allowlisted trusted sources seeds the basis for the trust store in that those aspects define the policy engines initial execution state pre-first new data event federation. The seed data is the basis from which all policy engine evalutions begin, as models within them may change given the inherent feedback loop in decentralized value chain analysis.
- This doc and the
-
- OpenSSF: Secure Supply Chain Consumption Framework (S2C2F): Simplified Requirements: Appendix: Relation to SCITT
- Luke 8:17
- IETF
- KERI
- https://keri.one
- https://github.com/decentralized-identity/keri/blob/352fd2c30bf3e76e8f8f78d2edccd01a9f943464/docs/KERI-made-easy.md
-
indirect nethod: "Because I am not always online I have my identifier's history served by online Witnesses. Your validator can do duplicity detection on those witnesses and validate whether or not I am being duplicitous"
-
Ambient verifiability: Verifiable by anyone, anywhere, at anytime. E.g. Ambient Duplicity Detection describes the possibility of detecting duplicity by anyone, anywhere, anytime.
- This fits nicely with SCITT's COSE countersigned receipts
-
Duplicity
In KERI consistency is is used to described data that is internally consistent and cryptographically verifiably so. Duplicity is used to describe external inconsistency. Publication of two or more versions of a KEL log, each of which is internally consistent is duplicity. Given that signatures are non-repudiable any duplicity is detectable and provable given possession of any two mutually inconsistent versions of a KEL.
In common language 'duplicity' has a slightly different connotation: 'two-facedness', 'dishonesty', 'deceitfulness', 'deviousness,'two-facedness', 'falseness'.
-
- World Wide Web Consortium