由于文档正在更新中,描述可能有错误。
本库支持模型微调(fine tuning)、DreamBooth、训练LoRA和文本反转(Textual Inversion)(包括XTI:P+ ) 本文档将说明它们通用的训练数据准备方法和选项等。
请提前参考本仓库的README,准备好环境。
以下本节说明。
-
准备训练数据(使用设置文件的新格式)
-
训练中使用的术语的简要解释
-
先前的指定格式(不使用设置文件,而是从命令行指定)
-
生成训练过程中的示例图像
-
各脚本中常用的共同选项
-
准备 fine tuning 方法的元数据:如说明文字(打标签)等
-
如果只执行一次,训练就可以进行(相关内容,请参阅各个脚本的文档)。如果需要,以后可以随时参考。
在任意文件夹(也可以是多个文件夹)中准备好训练数据的图像文件。支持 .png, .jpg, .jpeg, .webp, .bmp 格式的文件。通常不需要进行任何预处理,如调整大小等。
但是请勿使用极小的图像,若其尺寸比训练分辨率(稍后将提到)还小,建议事先使用超分辨率AI等进行放大。另外,请注意不要使用过大的图像(约为3000 x 3000像素以上),因为这可能会导致错误,建议事先缩小。
在训练时,需要整理要用于训练模型的图像数据,并将其指定给脚本。根据训练数据的数量、训练目标和说明(图像描述)是否可用等因素,可以使用几种方法指定训练数据。以下是其中的一些方法(每个名称都不是通用的,而是该存储库自定义的定义)。有关正则化图像的信息将在稍后提供。
-
DreamBooth、class + identifier方式(可使用正则化图像)
将训练目标与特定单词(identifier)相关联进行训练。无需准备说明。例如,当要学习特定角色时,由于无需准备说明,因此比较方便,但由于训练数据的所有元素都与identifier相关联,例如发型、服装、背景等,因此在生成时可能会出现无法更换服装的情况。
-
DreamBooth、说明方式(可使用正则化图像)
事先给每个图片写说明(caption),存放到文本文件中,然后进行训练。例如,通过将图像详细信息(如穿着白色衣服的角色A、穿着红色衣服的角色A等)记录在caption中,可以将角色和其他元素分离,并期望模型更准确地学习角色。
-
微调方式(不可使用正则化图像)
先将说明收集到元数据文件中。支持分离标签和说明以及预先缓存latents等功能,以加速训练(这些将在另一篇文档中介绍)。(虽然名为fine tuning方式,但不仅限于fine tuning。)
训练对象和你可以使用的规范方法的组合如下。
| 训练对象或方法 | 脚本 | DB/class+identifier | DB/caption | fine tuning |
|---|---|---|---|---|
| fine tuning微调模型 | fine_tune.py |
x | x | o |
| DreamBooth训练模型 | train_db.py |
o | o | x |
| LoRA | train_network.py |
o | o | o |
| Textual Invesion | train_textual_inversion.py |
o | o | o |
如果您想要训练LoRA、Textual Inversion而不需要准备说明(caption)文件,则建议使用DreamBooth class+identifier。如果您能够准备caption文件,则DreamBooth Captions方法更好。如果您有大量的训练数据并且不使用正则化图像,则请考虑使用fine-tuning方法。
对于DreamBooth也是一样的,但不能使用fine-tuning方法。若要进行微调,只能使用fine-tuning方式。
在这里,我们只介绍每种指定方法的典型模式。有关更详细的指定方法,请参见数据集设置。
在该方法中,每个图像将被视为使用与 class identifier 相同的标题进行训练(例如 shs dog)。
这样一来,每张图片都相当于使用标题“分类标识”(例如“shs dog”)进行训练。
要将训练的目标与identifier和属于该目标的class相关联。
(虽然有很多称呼,但暂时按照原始论文的说法。)
以下是简要说明(请查阅详细信息)。
class是训练目标的一般类别。例如,如果要学习特定品种的狗,则class将是“dog”。对于动漫角色,根据模型不同,可能是“boy”或“girl”,也可能是“1boy”或“1girl”。
identifier是用于识别训练目标并进行学习的单词。可以使用任何单词,但是根据原始论文,“Tokenizer生成的3个或更少字符的罕见单词”是最好的选择。
使用identifier和class,例如,“shs dog”可以将模型训练为从class中识别并学习所需的目标。
在图像生成时,使用“shs dog”将生成所学习狗种的图像。
(作为identifier,我最近使用的一些参考是“shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny”等。最好是不包含在Danbooru标签中的单词。)
正则化图像是为防止前面提到的语言漂移,即整个类别被拉扯成为训练目标而生成的图像。如果不使用正则化图像,例如在 shs 1girl 中学习特定角色时,即使在简单的 1girl 提示下生成,也会越来越像该角色。这是因为 1girl 在训练时的标题中包含了该角色的信息。
通过同时学习目标图像和正则化图像,类别仍然保持不变,仅在将标识符附加到提示中时才生成目标图像。
如果您只想在LoRA或DreamBooth中使用特定的角色,则可以不使用正则化图像。
在Textual Inversion中也不需要使用(如果要学习的token string不包含在标题中,则不会学习任何内容)。
一般情况下,使用在训练目标模型时只使用类别名称生成的图像作为正则化图像是常见的做法(例如 1girl)。但是,如果生成的图像质量不佳,可以尝试修改提示或使用从网络上另外下载的图像。
(由于正则化图像也被训练,因此其质量会影响模型。)
通常,准备数百张图像是理想的(图像数量太少会导致类别图像无法被归纳,特征也不会被学习)。
如果要使用生成的图像,生成图像的大小通常应与训练分辨率(更准确地说,是bucket的分辨率,见下文)相匹配。
创建一个文本文件,并将其扩展名更改为.toml。例如,您可以按以下方式进行描述:
(以#开头的部分是注释,因此您可以直接复制粘贴,或者将其删除。)
[general]
enable_bucket = true # 是否使用Aspect Ratio Bucketing
[[datasets]]
resolution = 512 # 训练分辨率
batch_size = 4 # 批次大小
[[datasets.subsets]]
image_dir = 'C:\hoge' # 指定包含训练图像的文件夹
class_tokens = 'hoge girl' # 指定标识符类
num_repeats = 10 # 训练图像的重复次数
# 以下仅在使用正则化图像时进行描述。不使用则删除
[[datasets.subsets]]
is_reg = true
image_dir = 'C:\reg' # 指定包含正则化图像的文件夹
class_tokens = 'girl' # 指定class
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了基本上只需更改以下几个地方即可进行训练。
-
训练分辨率
指定一个数字表示正方形(如果是
512,则为 512x512),如果使用方括号和逗号分隔的两个数字,则表示横向×纵向(如果是[512,768],则为 512x768)。在SD1.x系列中,原始训练分辨率为512。指定较大的分辨率,如[512,768]可能会减少纵向和横向图像生成时的错误。在SD2.x 768系列中,分辨率为768。 -
批次大小
指定同时训练多少个数据。这取决于GPU的VRAM大小和训练分辨率。详细信息将在后面说明。此外,fine tuning/DreamBooth/LoRA等也会影响批次大小,请查看各个脚本的说明。
-
文件夹指定
指定用于学习的图像和正则化图像(仅在使用时)的文件夹。指定包含图像数据的文件夹。
-
identifier 和 class 的指定
如前所述,与示例相同。
-
重复次数
将在后面说明。
重复次数用于调整正则化图像和训练用图像的数量。由于正则化图像的数量多于训练用图像,因此需要重复使用训练用图像来达到一对一的比例,从而实现训练。
请将重复次数指定为“ 训练用图像的重复次数×训练用图像的数量≥正则化图像的重复次数×正则化图像的数量 ”。
(1个epoch(指训练数据过完一遍)的数据量为“训练用图像的重复次数×训练用图像的数量”。如果正则化图像的数量多于这个值,则剩余的正则化图像将不会被使用。)
详情请参考相关文档进行训练。
在此方式中,每个图像都将通过caption进行训练。
请将与图像具有相同文件名且扩展名为 .caption(可以在设置中更改)的文件放置在用于训练图像的文件夹中。每个文件应该只有一行。编码为 UTF-8。
与class+identifier格式相同。可以在规范化图像上附加caption,但通常不需要。
创建一个文本文件并将扩展名更改为 .toml。例如,您可以按以下方式进行描述:
[general]
enable_bucket = true # 是否使用Aspect Ratio Bucketing
[[datasets]]
resolution = 512 # 训练分辨率
batch_size = 4 # 批次大小
[[datasets.subsets]]
image_dir = 'C:\hoge' # 指定包含训练图像的文件夹
caption_extension = '.caption' # 若使用txt文件,更改此项
num_repeats = 10 # 训练图像的重复次数
# 以下仅在使用正则化图像时进行描述。不使用则删除
[[datasets.subsets]]
is_reg = true
image_dir = 'C:\reg' # 指定包含正则化图像的文件夹
class_tokens = 'girl' # 指定class
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了基本上只需更改以下几个地方来训练。除非另有说明,否则与class+identifier方法相同。
-
训练分辨率
-
批次大小
-
文件夹指定
-
caption文件的扩展名
可以指定任意的扩展名。
-
重复次数
详情请参考相关文档进行训练。
将caption和标签整合到管理文件中称为元数据。它的扩展名为 .json,格式为json。由于创建方法较长,因此在本文档的末尾进行描述。
创建一个文本文件,将扩展名设置为 .toml。例如,可以按以下方式编写:
[general]
shuffle_caption = true
keep_tokens = 1
[[datasets]]
resolution = 512 # 图像分辨率
batch_size = 4 # 批次大小
[[datasets.subsets]]
image_dir = 'C:\piyo' # 指定包含训练图像的文件夹
metadata_file = 'C:\piyo\piyo_md.json' # 元数据文件名基本上只需更改以下几个地方来训练。除非另有说明,否则与DreamBooth, class+identifier方法相同。
-
训练分辨率
-
批次大小
-
指定文件夹
-
元数据文件名
指定使用后面所述方法创建的元数据文件。
详情请参考相关文档进行训练。
由于省略了细节并且我自己也没有完全理解,因此请自行查阅详细信息。
指训练模型并微调其性能。具体含义因用法而异,但在 Stable Diffusion 中,狭义的微调是指使用图像和caption进行训练模型。DreamBooth 可视为狭义微调的一种特殊方法。广义的微调包括 LoRA、Textual Inversion、Hypernetworks 等,包括训练模型的所有内容。
粗略地说,每次在训练数据上进行一次计算即为一步。具体来说,“将训练数据的caption传递给当前模型,将生成的图像与训练数据的图像进行比较,稍微更改模型,以使其更接近训练数据”即为一步。
批次大小指定每个步骤要计算多少数据。批次计算可以提高速度。一般来说,批次大小越大,精度也越高。
“批次大小×步数”是用于训练的数据数量。因此,建议减少步数以增加批次大小。
(但是,例如,“批次大小为 1,步数为 1600”和“批次大小为 4,步数为 400”将不会产生相同的结果。如果使用相同的学习速率,通常后者会导致模型欠拟合。请尝试增加学习率(例如 2e-6),将步数设置为 500 等。)
批次大小越大,GPU 内存消耗就越大。如果内存不足,将导致错误,或者在边缘时将导致训练速度降低。建议在任务管理器或 nvidia-smi 命令中检查使用的内存量进行调整。
注意,一个批次是指“一个数据单位”。
学习率指的是每个步骤中改变的程度。如果指定一个大的值,学习速度就会加快,但是可能会出现变化太大导致模型崩溃或无法达到最佳状态的情况。如果指定一个小的值,学习速度会变慢,同时可能无法达到最佳状态。
在fine tuning、DreamBooth、LoRA等过程中,学习率会有很大的差异,并且也会受到训练数据、所需训练的模型、批次大小和步骤数等因素的影响。建议从通常值开始,观察训练状态并逐渐调整。
默认情况下,整个训练过程中学习率是固定的。但是可以通过调度程序指定学习率如何变化,因此结果也会有所不同。
Epoch指的是训练数据被完整训练一遍(即数据已经迭代一轮)。如果指定了重复次数,则在重复后的数据迭代一轮后,为1个epoch。
1个epoch的步骤数通常为“数据量÷批次大小”,但如果使用Aspect Ratio Bucketing,则略微增加(由于不同bucket的数据不能在同一个批次中,因此步骤数会增加)。
Stable Diffusion 的 v1 是以 512*512 的分辨率进行训练的,但同时也可以在其他分辨率下进行训练,例如 256*1024 和 384*640。这样可以减少裁剪的部分,希望更准确地学习图像和标题之间的关系。
此外,由于可以在任意分辨率下进行训练,因此不再需要事先统一图像数据的长宽比。
此值可以被设定,其在此之前的配置文件示例中已被启用(设置为 true)。
只要不超过作为参数给出的分辨率区域(= 内存使用量),就可以按 64 像素的增量(默认值,可更改)在垂直和水平方向上调整和创建训练分辨率。
在机器学习中,通常需要将所有输入大小统一,但实际上只要在同一批次中统一即可。 NovelAI 所说的分桶(bucketing) 指的是,预先将训练数据按照长宽比分类到每个学习分辨率下,并通过使用每个 bucket 内的图像创建批次来统一批次图像大小。
这是一种通过命令行选项而不是指定 .toml 文件的方法。有 DreamBooth 类+标识符方法、DreamBooth caption方法、微调方法三种方式。
指定文件夹名称以指定迭代次数。还要使用 train_data_dir 和 reg_data_dir 选项。
创建一个用于存储训练图像的文件夹。此外,按以下名称创建目录。
<迭代次数>_<标识符> <类别>
不要忘记下划线_。
例如,如果在名为“sls frog”的提示下重复数据 20 次,则为“20_sls frog”。如下所示:

该方法很简单,在用于训练的图像文件夹中,需要准备多个文件夹,每个文件夹都是以“重复次数_<标识符> <类别>”命名的,同样,在正则化图像文件夹中,也需要准备多个文件夹,每个文件夹都是以“重复次数_<类别>”命名的。
例如,如果要同时训练“sls青蛙”和“cpc兔子”,则应按以下方式准备文件夹。
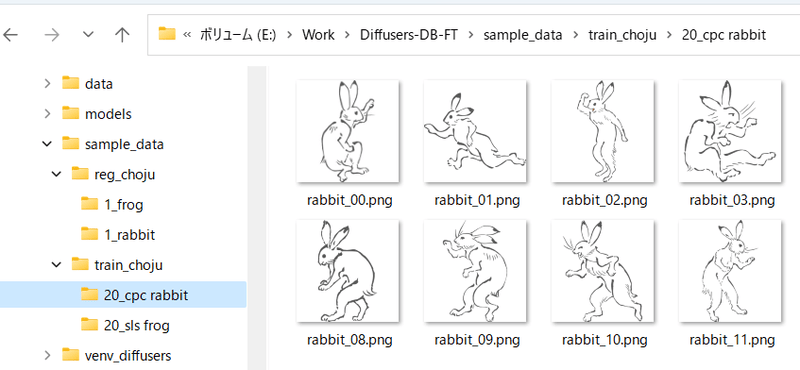
如果一个类别包含多个对象,可以只使用一个正则化图像文件夹。例如,如果在1girl类别中有角色A和角色B,则可以按照以下方式处理:
- train_girls
- 10_sls 1girl
- 10_cpc 1girl
- reg_girls
- 1_1girl
这是使用正则化图像时的过程。
创建一个文件夹来存储正则化的图像。 此外, 创建一个名为<repeat count>_<class> 的目录。
例如,使用提示“frog”并且不重复数据(仅一次):
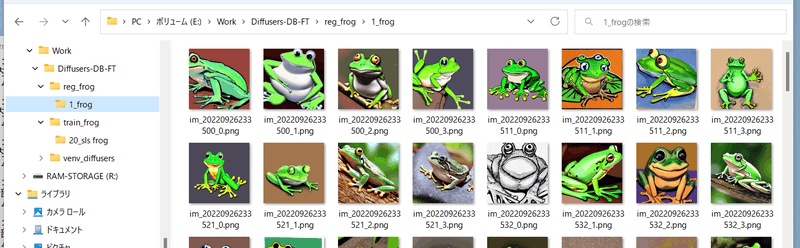
步骤3. 执行训练
执行每个训练脚本。使用 --train_data_dir 选项指定包含训练数据文件夹的父文件夹(不是包含图像的文件夹),使用 --reg_data_dir 选项指定包含正则化图像的父文件夹(不是包含图像的文件夹)。
在包含训练图像和正则化图像的文件夹中,将与图像具有相同文件名的文件.caption(可以使用选项进行更改)放置在该文件夹中,然后从该文件中加载caption所作为提示进行训练。
※文件夹名称(标识符类)不再用于这些图像的训练。
默认的caption文件扩展名为.caption。可以使用训练脚本的 --caption_extension 选项进行更改。 使用 --shuffle_caption 选项,同时对每个逗号分隔的部分进行训练时会对训练时的caption进行混洗。
创建元数据的方式与使用配置文件相同。 使用 in_json 选项指定元数据文件。
通过在训练中使用模型生成图像,可以检查训练进度。将以下选项指定为训练脚本。
-
--sample_every_n_steps/--sample_every_n_epochs指定要采样的步数或epoch数。为这些数字中的每一个输出样本。如果两者都指定,则 epoch 数优先。
-
--sample_prompts指定示例输出的提示文件。
-
--sample_sampler指定用于采样输出的采样器。
'ddim', 'pndm', 'heun', 'dpmsolver', 'dpmsolver++', 'dpmsingle', 'k_lms', 'k_euler', 'k_euler_a', 'k_dpm_2', 'k_dpm_2_a'が選べます。
要输出样本,您需要提前准备一个包含提示的文本文件。每行输入一个提示。
# prompt 1
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
# prompt 2
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40以“#”开头的行是注释。您可以使用“-- + 小写字母”为生成的图像指定选项,例如 --n。您可以使用:
--n否定提示到下一个选项。--w指定生成图像的宽度。--h指定生成图像的高度。--d指定生成图像的种子。--l指定生成图像的 CFG 比例。--s指定生成过程中的步骤数。
文档更新可能跟不上脚本更新。在这种情况下,请使用 --help 选项检查可用选项。
-
--v2/--v_parameterization如果使用 Hugging Face 的 stable-diffusion-2-base 或来自它的微调模型作为学习目标模型(对于在推理时指示使用
v2-inference.yaml的模型),- 当使用-v2选项与 stable-diffusion-2、768-v-ema.ckpt 及其微调模型(对于在推理过程中使用v2-inference-v.yaml的模型),- 指定两个 -v2和--v_parameterization选项。以下几点在 Stable Diffusion 2.0 中发生了显着变化。
- 使用分词器
- 使用哪个Text Encoder,使用哪个输出层(2.0使用倒数第二层)
- Text Encoder的输出维度(768->1024)
- U-Net的结构(CrossAttention的头数等)
- v-parameterization(采样方式好像变了)
其中base使用1-4,非base使用1-5(768-v)。使用 1-4 进行 v2 选择,使用 5 进行 v_parameterization 选择。
-
--pretrained_model_name_or_path指定要从中执行额外训练的模型。您可以指定Stable Diffusion检查点文件(.ckpt 或 .safetensors)、diffusers本地磁盘上的模型目录或diffusers模型 ID(例如“stabilityai/stable-diffusion-2”)。
-
--output_dir指定训练后保存模型的文件夹。
-
--output_name指定不带扩展名的模型文件名。
-
--dataset_config指定描述数据集配置的 .toml 文件。
-
--max_train_steps/--max_train_epochs指定要训练的步数或epoch数。如果两者都指定,则 epoch 数优先。
-
--mixed_precision
训练混合精度以节省内存。指定像--mixed_precision = "fp16"。与无混合精度(默认)相比,精度可能较低,但训练所需的 GPU 内存明显较少。
(在RTX30系列以后也可以指定`bf16`,请配合您在搭建环境时做的加速设置)。
-
--gradient_checkpointing通过逐步计算权重而不是在训练期间一次计算所有权重来减少训练所需的 GPU 内存量。关闭它不会影响准确性,但打开它允许更大的批次大小,所以那里有影响。
另外,打开它通常会减慢速度,但可以增加批次大小,因此总的训练时间实际上可能会更快。
-
--xformers/--mem_eff_attn当指定 xformers 选项时,使用 xformers 的 CrossAttention。如果未安装 xformers 或发生错误(取决于环境,例如
mixed_precision="no"),请指定mem_eff_attn选项而不是使用 CrossAttention 的内存节省版本(xformers 比 慢)。 -
--save_precision指定保存时的数据精度。为 save_precision 选项指定 float、fp16 或 bf16 将以该格式保存模型(在 DreamBooth 中保存 Diffusers 格式时无效,微调)。当您想缩小模型的尺寸时请使用它。
-
--save_every_n_epochs/--save_state/--resume为 save_every_n_epochs 选项指定一个数字可以在每个时期的训练期间保存模型。如果同时指定save_state选项,训练状态包括优化器的状态等都会一起保存。。保存目的地将是一个文件夹。
训练状态输出到目标文件夹中名为“<output_name>-??????-state”(??????是epoch数)的文件夹中。长时间训练时请使用。
使用 resume 选项从保存的训练状态恢复训练。指定训练状态文件夹(其中的状态文件夹,而不是
output_dir)。请注意,由于 Accelerator 规范,epoch 数和全局步数不会保存,即使恢复时它们也从 1 开始。
-
--save_model_as(DreamBooth, fine tuning 仅有的)您可以从
ckpt, safetensors, diffusers, diffusers_safetensors中选择模型保存格式。 -
--save_model_as=safetensors指定喜欢当读取Stable Diffusion格式(ckpt 或safetensors)并以diffusers格式保存时,缺少的信息通过从 Hugging Face 中删除 v1.5 或 v2.1 信息来补充。 -
--clip_skip2如果指定,则使用文本编码器 (CLIP) 的倒数第二层的输出。如果省略 1 或选项,则使用最后一层。*SD2.0默认使用倒数第二层,训练SD2.0时请不要指定。
如果被训练的模型最初被训练为使用第二层,则 2 是一个很好的值。
如果您使用的是最后一层,那么整个模型都会根据该假设进行训练。因此,如果再次使用第二层进行训练,可能需要一定数量的teacher数据和更长时间的训练才能得到想要的训练结果。
-
--max_token_length默认值为 75。您可以通过指定“150”或“225”来扩展令牌长度来训练。使用长字幕训练时指定。
但由于训练时token展开的规范与Automatic1111的web UI(除法等规范)略有不同,如非必要建议用75训练。
与clip_skip一样,训练与模型训练状态不同的长度可能需要一定量的teacher数据和更长的学习时间。
-
--persistent_data_loader_workers在 Windows 环境中指定它可以显着减少时期之间的延迟。
-
--max_data_loader_n_workers指定数据加载的进程数。大量的进程会更快地加载数据并更有效地使用 GPU,但会消耗更多的主内存。默认是"
8或者CPU并发执行线程数 - 1,取小者",所以如果主存没有空间或者GPU使用率大概在90%以上,就看那些数字和2或将其降低到大约1。 -
--logging_dir/--log_prefix保存训练日志的选项。在 logging_dir 选项中指定日志保存目标文件夹。以 TensorBoard 格式保存日志。
例如,如果您指定 --logging_dir=logs,将在您的工作文件夹中创建一个日志文件夹,并将日志保存在日期/时间文件夹中。 此外,如果您指定 --log_prefix 选项,则指定的字符串将添加到日期和时间之前。使用“--logging_dir=logs --log_prefix=db_style1_”进行识别。
要检查 TensorBoard 中的日志,请打开另一个命令提示符并在您的工作文件夹中键入:
tensorboard --logdir=logs我觉得tensorboard会在环境搭建的时候安装,如果没有安装,请用
pip install tensorboard安装。)然后打开浏览器到http://localhost:6006/就可以看到了。
-
--noise_offset本文的实现:https://www.crosslabs.org//blog/diffusion-with-offset-noise看起来它可能会为整体更暗和更亮的图像产生更好的结果。它似乎对 LoRA 训练也有效。指定一个大约 0.1 的值似乎很好。
-
--debug_dataset通过添加此选项,您可以在训练之前检查将训练什么样的图像数据和标题。按 Esc 退出并返回命令行。按
S进入下一步(批次),按E进入下一个epoch。*图片在 Linux 环境(包括 Colab)下不显示。
-
--vae如果您在 vae 选项中指定Stable Diffusion检查点、VAE 检查点文件、扩散模型或 VAE(两者都可以指定本地或拥抱面模型 ID),则该 VAE 用于训练(缓存时的潜伏)或在训练过程中获得潜伏)。
对于 DreamBooth 和微调,保存的模型将包含此 VAE
-
--cache_latents在主内存中缓存 VAE 输出以减少 VRAM 使用。除 flip_aug 之外的任何增强都将不可用。此外,整体训练速度略快。
-
--min_snr_gamma指定最小 SNR 加权策略。细节是这里请参阅。论文中推荐
5。
-
--optimizer_type-- 指定优化器类型。您可以指定- AdamW : torch.optim.AdamW
- 与过去版本中未指定选项时相同
- AdamW8bit : 参数同上
- PagedAdamW8bit : 参数同上
- 与过去版本中指定的 --use_8bit_adam 相同
- Lion : https://github.com/lucidrains/lion-pytorch
- Lion8bit : 参数同上
- PagedLion8bit : 参数同上
- 与过去版本中指定的 --use_lion_optimizer 相同
- SGDNesterov : torch.optim.SGD, nesterov=True
- SGDNesterov8bit : 参数同上
- DAdaptation(DAdaptAdamPreprint) : https://github.com/facebookresearch/dadaptation
- DAdaptAdam : 参数同上
- DAdaptAdaGrad : 参数同上
- DAdaptAdan : 参数同上
- DAdaptAdanIP : 参数同上
- DAdaptLion : 参数同上
- DAdaptSGD : 参数同上
- Prodigy : https://github.com/konstmish/prodigy
- AdaFactor : Transformers AdaFactor
- 任何优化器
-
--unet_lr指定学习率。合适的学习率取决于训练脚本,所以请参考每个解释。
-
--lr_scheduler/--lr_warmup_steps/--lr_scheduler_num_cycles/--lr_scheduler_power学习率的调度程序相关规范。
使用 lr_scheduler 选项,您可以从线性、余弦、cosine_with_restarts、多项式、常数、constant_with_warmup 或任何调度程序中选择学习率调度程序。默认值是常量。
使用 lr_warmup_steps,您可以指定预热调度程序的步数(逐渐改变学习率)。
lr_scheduler_num_cycles 是 cosine with restarts 调度器中的重启次数,lr_scheduler_power 是多项式调度器中的多项式幂。
有关详细信息,请自行研究。
要使用任何调度程序,请像使用任何优化器一样使用“--scheduler_args”指定可选参数。
使用 --optimizer_args 选项指定优化器选项参数。可以以key=value的格式指定多个值。此外,您可以指定多个值,以逗号分隔。例如,要指定 AdamW 优化器的参数,--optimizer_args weight_decay=0.01 betas=.9,.999。
指定可选参数时,请检查每个优化器的规格。 一些优化器有一个必需的参数,如果省略它会自动添加(例如 SGDNesterov 的动量)。检查控制台输出。
D-Adaptation 优化器自动调整学习率。学习率选项指定的值不是学习率本身,而是D-Adaptation决定的学习率的应用率,所以通常指定1.0。如果您希望 Text Encoder 的学习率是 U-Net 的一半,请指定 --text_encoder_lr=0.5 --unet_lr=1.0。
如果指定 relative_step=True,AdaFactor 优化器可以自动调整学习率(如果省略,将默认添加)。自动调整时,学习率调度器被迫使用 adafactor_scheduler。此外,指定 scale_parameter 和 warmup_init 似乎也不错。
自动调整的选项类似于--optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True"。
如果您不想自动调整学习率,请添加可选参数 relative_step=False。在那种情况下,似乎建议将 constant_with_warmup 用于学习率调度程序,而不要为梯度剪裁范数。所以参数就像--optimizer_type=adafactor --optimizer_args "relative_step=False" --lr_scheduler="constant_with_warmup" --max_grad_norm=0.0。
使用 torch.optim 优化器时,仅指定类名(例如 --optimizer_type=RMSprop),使用其他模块的优化器时,指定“模块名.类名”。(例如--optimizer_type=bitsandbytes.optim.lamb.LAMB)。
(内部仅通过 importlib 未确认操作。如果需要,请安装包。)
如上所述准备好你要训练的图像数据,放在任意文件夹中。
例如,存储这样的图像:
如果您只想训练没有标题的标签,请跳过。
另外,手动准备caption时,请准备在与教师数据图像相同的目录下,文件名相同,扩展名.caption等。每个文件应该是只有一行的文本文件。
最新版本不再需要 BLIP 下载、权重下载和额外的虚拟环境。按原样工作。
运行 finetune 文件夹中的 make_captions.py。
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
如果batch size为8,训练数据放在父文件夹train_data中,则会如下所示
python finetune\make_captions.py --batch_size 8 ..\train_data
caption文件创建在与教师数据图像相同的目录中,具有相同的文件名和扩展名.caption。
根据 GPU 的 VRAM 容量增加或减少 batch_size。越大越快(我认为 12GB 的 VRAM 可以多一点)。 您可以使用 max_length 选项指定caption的最大长度。默认值为 75。如果使用 225 的令牌长度训练模型,它可能会更长。 您可以使用 caption_extension 选项更改caption扩展名。默认为 .caption(.txt 与稍后描述的 DeepDanbooru 冲突)。 如果有多个教师数据文件夹,则对每个文件夹执行。
请注意,推理是随机的,因此每次运行时结果都会发生变化。如果要修复它,请使用 --seed 选项指定一个随机数种子,例如 --seed 42。
其他的选项,请参考help with --help(好像没有文档说明参数的含义,得看源码)。
默认情况下,会生成扩展名为 .caption 的caption文件。
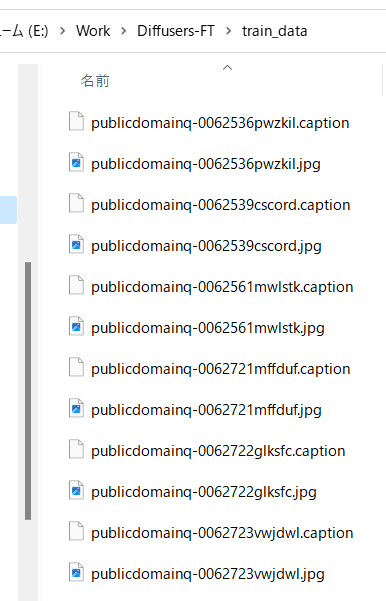
例如,标题如下:
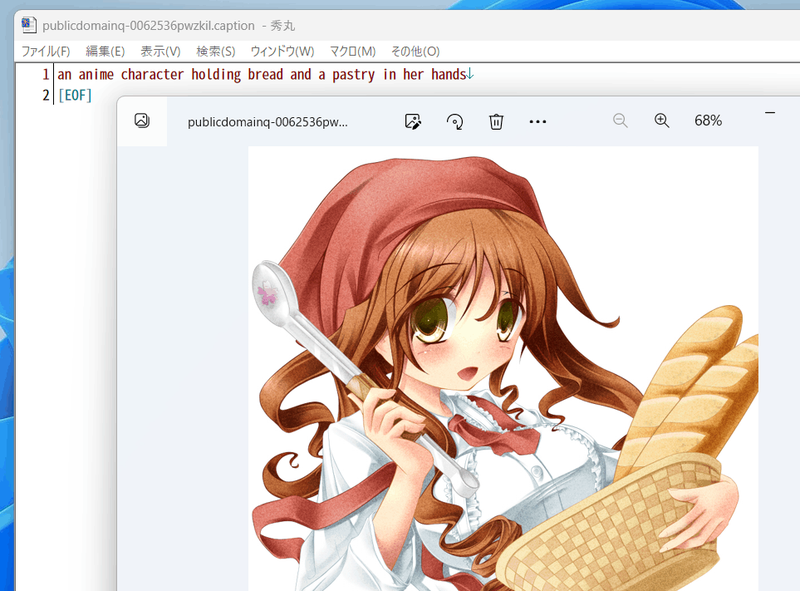
如果不想给danbooru标签本身打标签,请继续“标题和标签信息的预处理”。
标记是使用 DeepDanbooru 或 WD14Tagger 完成的。 WD14Tagger 似乎更准确。如果您想使用 WD14Tagger 进行标记,请跳至下一章。
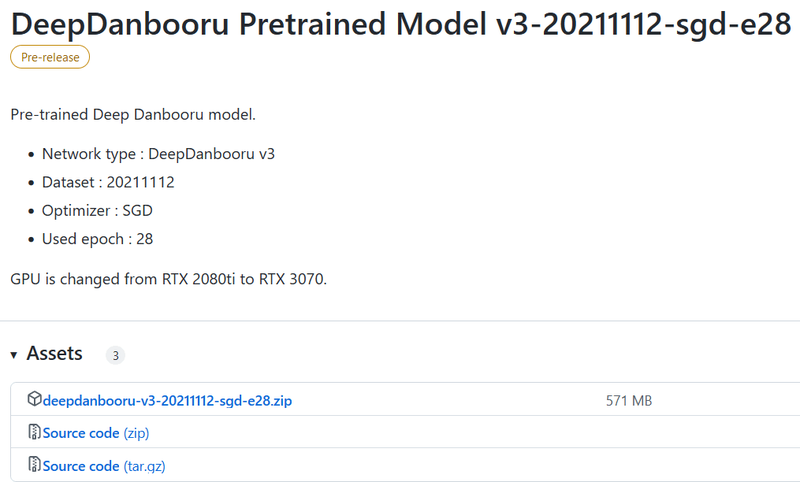
将 DeepDanbooru https://github.com/KichangKim/DeepDanbooru 克隆到您的工作文件夹中,或下载并展开 zip。我解压缩了它。 另外,从 DeepDanbooru 发布页面 https://github.com/KichangKim/DeepDanbooru/releases 上的“DeepDanbooru 预训练模型 v3-20211112-sgd-e28”的资产下载 deepdanbooru-v3-20211112-sgd-e28.zip 并解压到 DeepDanbooru 文件夹。
从下面下载。单击以打开资产并从那里下载。
做一个这样的目录结构
 为diffusers环境安装必要的库。进入 DeepDanbooru 文件夹并安装它(我认为它实际上只是添加了 tensorflow-io)。
为diffusers环境安装必要的库。进入 DeepDanbooru 文件夹并安装它(我认为它实际上只是添加了 tensorflow-io)。
pip install -r requirements.txt
接下来,安装 DeepDanbooru 本身。
pip install .
这样就完成了标注环境的准备工作。
转到 DeepDanbooru 的文件夹并运行 deepdanbooru 进行标记。
deepdanbooru evaluate <教师资料夹> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
如果将训练数据放在父文件夹train_data中,则如下所示。
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
在与教师数据图像相同的目录中创建具有相同文件名和扩展名.txt 的标记文件。它很慢,因为它是一个接一个地处理的。
如果有多个教师数据文件夹,则对每个文件夹执行。
它生成如下。
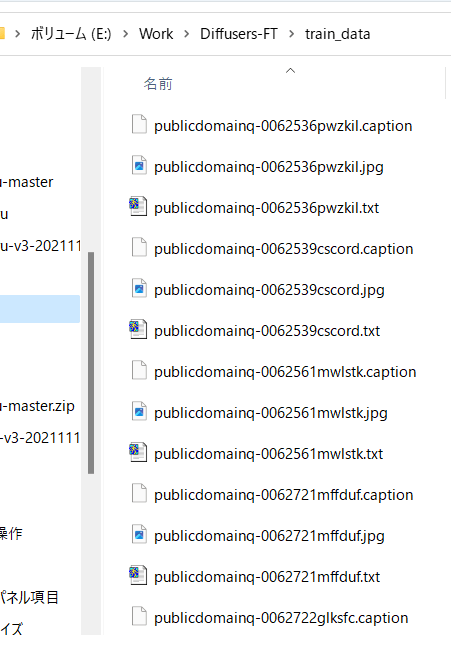
它会被这样标记(信息量很大...)。
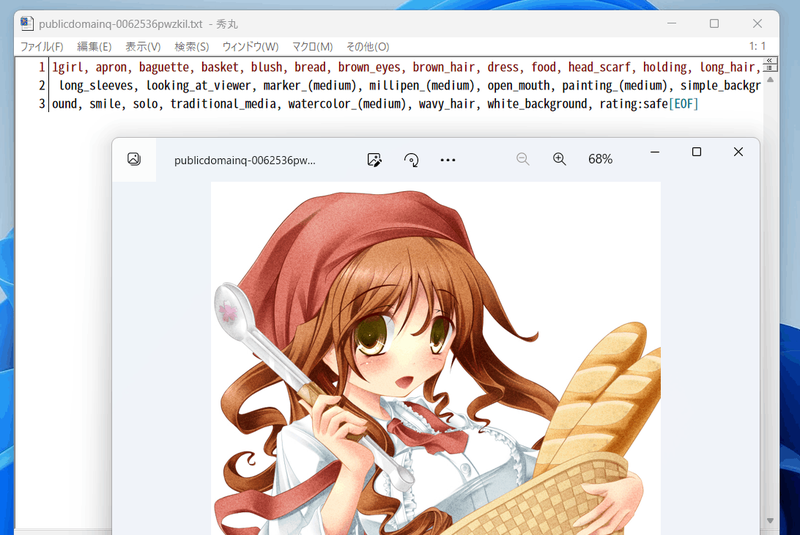
此过程使用 WD14Tagger 而不是 DeepDanbooru。
使用 Mr. Automatic1111 的 WebUI 中使用的标记器。我参考了这个 github 页面上的信息 (https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger)。
初始环境维护所需的模块已经安装。权重自动从 Hugging Face 下载。
运行脚本以进行标记。
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
如果将训练数据放在父文件夹train_data中,则如下所示
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
模型文件将在首次启动时自动下载到 wd14_tagger_model 文件夹(文件夹可以在选项中更改)。它将如下所示。
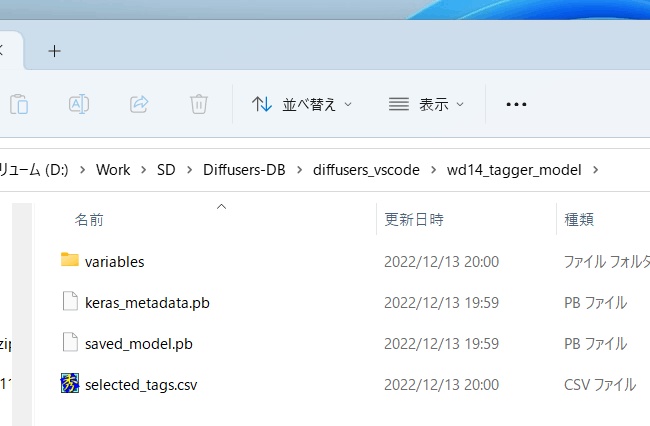
在与教师数据图像相同的目录中创建具有相同文件名和扩展名.txt 的标记文件。


使用 thresh 选项,您可以指定确定的标签的置信度数以附加标签。默认值为 0.35,与 WD14Tagger 示例相同。较低的值给出更多的标签,但准确性较低。
根据 GPU 的 VRAM 容量增加或减少 batch_size。越大越快(我认为 12GB 的 VRAM 可以多一点)。您可以使用 caption_extension 选项更改标记文件扩展名。默认为 .txt。
您可以使用 model_dir 选项指定保存模型的文件夹。
此外,如果指定 force_download 选项,即使有保存目标文件夹,也会重新下载模型。
如果有多个教师数据文件夹,则对每个文件夹执行。
将caption和标签作为元数据合并到一个文件中,以便从脚本中轻松处理。
要将caption放入元数据,请在您的工作文件夹中运行以下命令(如果您不使用caption进行训练,则不需要运行它)(它实际上是一行,依此类推)。指定 --full_path 选项以将图像文件的完整路径存储在元数据中。如果省略此选项,则会记录相对路径,但 .toml 文件中需要单独的文件夹规范。
python merge_captions_to_metadata.py --full_path <教师资料夹>
--in_json <要读取的元数据文件名> <元数据文件名>
元数据文件名是任意名称。 如果训练数据为train_data,没有读取元数据文件,元数据文件为meta_cap.json,则会如下。
python merge_captions_to_metadata.py --full_path train_data meta_cap.json
您可以使用 caption_extension 选项指定标题扩展。
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行。
python merge_captions_to_metadata.py --full_path
train_data1 meta_cap1.json
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
train_data2 meta_cap2.json
如果省略in_json,如果有写入目标元数据文件,将从那里读取并覆盖。
__* 每次重写 in_json 选项和写入目标并写入单独的元数据文件是安全的。 __
同样,标签也收集在元数据中(如果标签不用于训练,则无需这样做)。
python merge_dd_tags_to_metadata.py --full_path <教师资料夹>
--in_json <要读取的元数据文件名> <要写入的元数据文件名>
同样的目录结构,读取meta_cap.json和写入meta_cap_dd.json时,会是这样的。
python merge_dd_tags_to_metadata.py --full_path train_data --in_json meta_cap.json meta_cap_dd.json
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行。
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
train_data1 meta_cap_dd1.json
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
train_data2 meta_cap_dd2.json
如果省略in_json,如果有写入目标元数据文件,将从那里读取并覆盖。 __※ 通过每次重写 in_json 选项和写入目标,写入单独的元数据文件是安全的。 __
到目前为止,标题和DeepDanbooru标签已经被整理到元数据文件中。然而,自动标题生成的标题存在表达差异等微妙问题(※),而标签中可能包含下划线和评级(DeepDanbooru的情况下)。因此,最好使用编辑器的替换功能清理标题和标签。
※例如,如果要学习动漫中的女孩,标题可能会包含girl/girls/woman/women等不同的表达方式。另外,将"anime girl"简单地替换为"girl"可能更合适。
我们提供了用于清理的脚本,请根据情况编辑脚本并使用它。
(不需要指定教师数据文件夹。将清理元数据中的所有数据。)
python clean_captions_and_tags.py <要读取的元数据文件名> <要写入的元数据文件名>
--in_json 请注意,不包括在内。例如:
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
标题和标签的预处理现已完成。
※ 这一步骤并非必须。即使省略此步骤,也可以在训练过程中获取 latents。但是,如果在训练时执行 random_crop 或 color_aug 等操作,则无法预先获取 latents(因为每次图像都会改变)。如果不进行预先获取,则可以使用到目前为止的元数据进行训练。
提前获取图像的潜在表达并保存到磁盘上。这样可以加速训练过程。同时进行 bucketing(根据宽高比对训练数据进行分类)。
请在工作文件夹中输入以下内容。
python prepare_buckets_latents.py --full_path <教师资料夹>
<要读取的元数据文件名> <要写入的元数据文件名>
<要微调的模型名称或检查点>
--batch_size <批次大小>
--max_resolution <分辨率宽、高>
--mixed_precision <准确性>
如果要从meta_clean.json中读取元数据,并将其写入meta_lat.json,使用模型model.ckpt,批处理大小为4,训练分辨率为512*512,精度为no(float32),则应如下所示。
python prepare_buckets_latents.py --full_path
train_data meta_clean.json meta_lat.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
教师数据文件夹中,latents以numpy的npz格式保存。
您可以使用--min_bucket_reso选项指定最小分辨率大小,--max_bucket_reso指定最大大小。默认值分别为256和1024。例如,如果指定最小大小为384,则将不再使用分辨率为256 * 1024或320 * 768等。如果将分辨率增加到768 * 768等较大的值,则最好将最大大小指定为1280等。
如果指定--flip_aug选项,则进行左右翻转的数据增强。虽然这可以使数据量伪造一倍,但如果数据不是左右对称的(例如角色外观、发型等),则可能会导致训练不成功。
对于翻转的图像,也会获取latents,并保存名为\ *_flip.npz的文件,这是一个简单的实现。在fline_tune.py中不需要特定的选项。如果有带有_flip的文件,则会随机加载带有和不带有flip的文件。
即使VRAM为12GB,批次大小也可以稍微增加。分辨率以“宽度,高度”的形式指定,必须是64的倍数。分辨率直接影响fine tuning时的内存大小。在12GB VRAM中,512,512似乎是极限(*)。如果有16GB,则可以将其提高到512,704或512,768。即使分辨率为256,256等,VRAM 8GB也很难承受(因为参数、优化器等与分辨率无关,需要一定的内存)。
*有报道称,在batch size为1的训练中,使用12GB VRAM和640,640的分辨率。
以下是bucketing结果的显示方式。
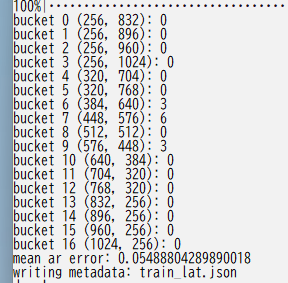
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行
python prepare_buckets_latents.py --full_path
train_data1 meta_clean.json meta_lat1.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
python prepare_buckets_latents.py --full_path
train_data2 meta_lat1.json meta_lat2.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
可以将读取源和写入目标设为相同,但分开设定更为安全。
※建议每次更改参数并将其写入另一个元数据文件,以确保安全性。