ICE-Talk is an Interface for a Controllable Expressive Talking Machine. It is a web-based GUI that allows the use of a TTS system with controllable parameters via a text field and a clickable 2D plot. It enables the study of latent spaces for controllable TTS. This repository implements:
- Visualization and Interpretation of Latent Spaces for Controlling Expressive Speech Synthesis Through Audio Analysis
- ICE-Talk: an Interface for a Controllable Expressive Talking Machine
- ICE-Talk 2: Interface for Controllable Expressive TTS with perceptual assessment tool !!! NEW !!! This Journal Article comes with a fully reproducible code capsule. It consists of an environment setup, a pretrained model (LJ-Speech seed), and all the preprocessing steps up to the acoustic analysis: https://doi.org/10.24433/CO.1645822.v1
Click on "Reproducible Run" to execute. Look at "run.sh" in the capsule to see what is done. You can dowload a docker image and see the dockerfile from there.
Here are samples from a model trained on Blizzard 2013 dataset that you can explore through a 2D interface:
http://noetits.com/speak-with-style-demo/
https://jsfiddle.net/g9aos1dz/show
All the samples behind that are stored here
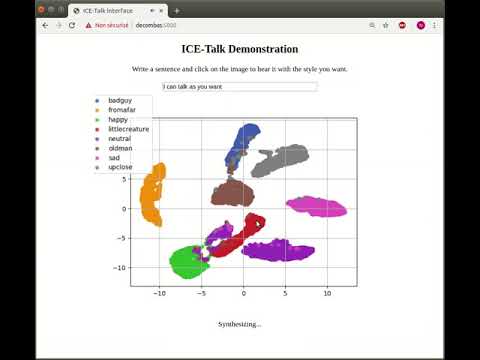
And here is a demo of the TTS with control from the 2D space, trained with a proprietary dataset, containing specific speech style categories:
The TTS architecture is based on Oliver Watt's ophelia and Kyubyong Park's dc_tts repository, which implements a variant of the system described in Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention.
Go to a suitable location and clone repository:
git clone https://github.com/noetits/ICE-Talk
cd ICE-Talk/
CODEDIR=`pwd`
create a conda environment and activate it:
conda create -n py_ice_talk python=3
conda activate py_ice_talk
With the virtual environment activated, you can now install the necessary packages.
Then:
conda install -c anaconda tensorflow-gpu=1.13.1
pip install librosa matplotlib
pip install -r requirements.txt
The first command takes a few minutes. The rest is faster.
We will use the LJ speech dataset, this is ~24 hrs audiobook read by a US female speaker. To download it and extract the contents, run:
DATADIR=/some/convenient/directory
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
DATADIR=$DATADIR/LJSpeech-1.1
For more details on the dataset, visit the webpage: https://keithito.com/LJ-Speech-Dataset/
The downloaded data contains a file called metadata.csv providing a transcription of the audio in plain text. Use Festival with the CMU lexicon to phonetise this transcription.
If you don't have a Festival installation, you can
Install with apt:
sudo apt-get install festival festvox-kallpc16k
Install from sources by running this
INSTALL_DIR=/some/convenient/directory/festival
mkdir -p $INSTALL_DIR
cd $INSTALL_DIR
wget http://www.cstr.ed.ac.uk/downloads/festival/2.4/festival-2.4-release.tar.gz
wget http://www.cstr.ed.ac.uk/downloads/festival/2.4/speech_tools-2.4-release.tar.gz
tar xvf festival-2.4-release.tar.gz
tar xvf speech_tools-2.4-release.tar.gz
## Install Speech tools first
cd speech_tools
./configure --prefix=$INSTALL_DIR
gmake
## Then compile Festival
cd ../festival
./configure --prefix=$INSTALL_DIR
gmake
# Finally, get a Festival voice with the CMU lexicon
cd ..
wget http://www.cstr.ed.ac.uk/downloads/festival/2.4/voices/festvox_cmu_us_awb_cg.tar.gz
tar xvf festvox_cmu_us_awb_cg.tar.gz
wget http://www.cstr.ed.ac.uk/downloads/festival/2.4/festlex_CMU.tar.gz
tar xvf festlex_CMU.tar.gz
wget http://www.cstr.ed.ac.uk/downloads/festival/2.4/festlex_POSLEX.tar.gz
tar xvf festlex_POSLEX.tar.gz
If gmake is not found, do this and try again: sudo ln -s /usr/bin/make /usr/bin/gmake
gmake is make on Ubuntu (any GNU/Linux system).
To test the installation, open Festival and load the voice. Run the locally installed festival (NB: initial ./ is important!)
./festival/bin/festival
festival> (voice_cmu_us_awb_cg)
festival> (SayText "If i'm speaking then installation actually went ok.")
festival> (quit)
If you have an error about /dev/dsp, search for the file "festival.scm" in festival installation and add these lines:
(Parameter.set 'Audio_Command "aplay -q -c 1 -t raw -f s16 -r $SR $FILE")
(Parameter.set 'Audio_Method 'Audio_Command)
Now, to phonetise the LJ transcription, you will pass the metadata.csv file through Festival and obtain phone transcriptions with the CMU lexicon.
cd $CODEDIR
# Get a file formatting the sentences in the right way for Festival, the "utts.data" file
python ./script/festival/csv2scm.py -i $DATADIR/metadata.csv -o $DATADIR/utts.data
cd $DATADIR/
FEST=$INSTALL_DIR
SCRIPT=$CODEDIR/script/festival/make_rich_phones_cmulex.scm
$FEST/festival/bin/festival -b $SCRIPT | grep ___KEEP___ | sed 's/___KEEP___//' | tee ./transcript_temp1.csv
python $CODEDIR/script/festival/fix_transcript.py ./transcript_temp1.csv > ./transcript_temp2.csv
head -n-2 transcript_temp2.csv > transcript.csv
During the process you should see the print of the resulting transcription, for example:
LJ003-0043||and it was not ready to relieve Newgate till late in eighteen fifteen.|<_START_> ae n d <> ih t <> w aa z <> n aa t <> r eh d iy <> t ax <> r ih l iy v <> n uw g ey t <> t ih l <> l ey t <> ih n <> ey t iy n <> f ih f t iy n <.> <_END_>
You can see that each line in transcript.csv contains four fields separated by the pipe (|) symbol. The first one in the name of the wav file. The second one corresponds to unnormalised text (in this case empty). The third field is the normalised text. The fourth field contains the phonetic transcription, enriched with: starting and ending symbols, word boundaries, and special punctuation symbols.
From the transcript.csv we will take the last 10 sentences to build a test_transcript.csv. The rest of the chapter 50 will be used as validation data (you can change this in the config file).
tail -n 10 transcript.csv > test_transcript.csv
Normalise level and trim end silences based only on acoustics:
cd $CODEDIR
python ./script/normalise_level.py -i $DATADIR/wavs -o $DATADIR/wav_norm/ -ncores 25
./util/submit_tf_cpu.sh ./script/split_speech.py -w $DATADIR/wav_norm/ -o $DATADIR/wav_trim/ -dB 30 -ncores 25 -trimonly
Despite its name, split_speech.py only trims end silences when used with the -trimonly flag. It is worth listening to a few trimmed waveforms to check the level used (30 dB) is appropriate. It works for LJSpeech, but might need adjusting for other databases. Reduce this value to trim more aggressively.
Clean up by removing untrimmed and unnormalised data:
rm -r $DATADIR/wavs $DATADIR/wav_norm/
Build a new config file for your project, by making your own copy of config/lj_tutorial.cfg.
You will have to modify the value datadir, by adding the path to the LJ folder.
# Modify in config file
datadir = '/path/to/LJSpeech-1.1/'
Use the config file to extract acoustic features. The acoustic features are mels and mags. You only need to run this once per dataset.
cd $CODEDIR
./util/submit_tf_cpu.sh $CODEDIR/prepare_acoustic_features.py -c $CODEDIR/config/lj_tutorial.cfg -ncores 25
This will output data by default in directories under:
$CODEDIR/work/<config>/data/
This can take quite a bit of space:
du -sh work/lj_test/data/*
2.1G work/lj_test/data/full_mels
27G work/lj_test/data/mags
548M work/lj_test/data/mels
We need to provide to the config file the maximum length of the phone transcriptions and the coarse mels (the inputs and outputs to the T2M model).
cd $CODEDIR
python $CODEDIR/script/check_transcript.py -i $DATADIR/transcript.csv -phone -cmp $CODEDIR/work/lj_tutorial/data/mels
Some of the output should look like this. The script is giving information about the length of the sequences, the phone set in the transcriptions, and a histogram of the lengths. In the config file, you can use the maximum length, or you can choose a different cutting point, for example, if you only have one sentence at that max length but most of your data is below that value.
------------------
Observed phones:
------------------
['<!>', '<">', "<'>", "<'s>", '<)>', '<,>', '<.>', '<:>', '<;>', '<>', '<?>', '<]>', '<_END_>', '<_START_>', 'aa', 'ae', 'ah', 'ao', 'aw', 'ax', 'ay', 'b', 'ch', 'd', 'dh', 'eh', 'er', 'ey', 'f', 'g', 'hh', 'ih', 'iy', 'jh', 'k', 'l', 'm', 'n', 'ng', 'ow', 'oy', 'p', 'r', 's', 'sh', 't', 'th', 'uh', 'uw', 'v', 'w', 'y', 'z', 'zh']
------------------
Letter/phone length max:
166
Frame length max:
203
We will add these to the config file. You can see in there in vocab there is the list of phones. Change the max_N and max_T to the values given by the script.
# In the config file
max_N = 150 # Maximum number of characters/phones
max_T = 200 # Maximum number of mel frames
The configuration file allows for two options for guided attention. If you leave an empty string for the variable attention_guide_dir, global attention matrix will be used, of size (max_N, max_T). Otherwise, if there is a path given, then attention guides per utterance length will be constructed.
# In the config file
attention_guide_dir = ''
Otherwise, you can add a path or use the one already there, and then build attention guides per utterance length. Run:
$CODEDIR/util/submit_tf.sh $CODEDIR/prepare_attention_guides.py -c $CODEDIR/config/lj_tutorial.cfg -ncores 25
The config lj_tutorial trains on only a few sentences for a limited number of epochs. It
won't produce anything decent-sounding, but use it to check the tools work. You have to train separately the T2M model from the SSRN. If you have multiple GPUs, you can train both in parallel.
$CODEDIR/util/submit_tf.sh $CODEDIR/train.py -c $CODEDIR/config/lj_tutorial.cfg -m t2m
$CODEDIR/util/submit_tf.sh $CODEDIR/train.py -c $CODEDIR/config/lj_tutorial.cfg -m ssrn
Note the use of ./util/submit_tf.sh, which will reserve a single GPU and make only that one visible for the job you are starting, and add some necessary resources to system path.
If you want to train the whole dataset, you have to change in the config file n_utts = 200, to n_utts = 0, as well as the number of epochs in max_epochs = 10. If you get any errors regarding memory, you can decrease the batch size in batchsize = {'t2m': 32, 'ssrn': 8} (as mels are longer, you might need to decrease especially the ssrn batch size).
Use the last saved model to synthesise N sentences from the test set:
$CODEDIR/util/submit_tf.sh $CODEDIR/synthesize.py -c $CODEDIR/config/lj_tutorial.cfg -N 5
As promised, this will not sound at all like speech.
To do so, you have to train an unsupervised model. Do so by using the "lj_unsupervised.cfg" config file. Once trained, you can compute the codes of the latent space that are extracted by the "Audio2Emo" encoder.
python $CODEDIR/synthesize_with_latent_space.py -c $CODEDIR/config/lj_unsupervised.cfg -m t2m -t compute_codes
Then use dimensionality reduction to reduce them to 2D. You can choose betwwen three dimensionality reduction methods: pca, tsne, umap:
python $CODEDIR/synthesize_with_latent_space.py -c $CODEDIR/config/lj_unsupervised.cfg -m t2m -t reduce_codes -r umap
Finally, you can launch the server:
python $CODEDIR/synthesize_with_latent_space.py -c $CODEDIR/config/lj_unsupervised.cfg -m t2m -t ICE_TTS_server -r umap
First you have to download and extract opensmile in a folder "tools": https://www.audeering.com/opensmile/
mkdir tools
cd tools
wget https://www.audeering.com/download/opensmile-2-3-0-tar-gz/?wpdmdl=4782 --no-check-certificate
mv index.html\?wpdmdl\=4782 opensmile.tar.gz
tar -xvf opensmile.tar.gz
rm opensmile.tar.gz
In the config file you can see the parameter validate_every_n_epochs = 1, this means the model will generate parameters that will be saved in separate folders in work/<config-name>. As objective evaluations are not as reliable as listening to the samples, you can synthesize these parameters to have an idea of the sound that the model is able to generate at the given epoch.
$CODEDIR/util/submit_tf.sh $CODEDIR/synthesise_validation_waveforms.py -c $CODEDIR/config/lj_tutorial.cfg -ncores 25