【GiantPandaCV导语】本文是笔者出于兴趣搞了一个小的库,主要是用于定位红外小目标。由于其具有尺度很小的特点,所以可以尝试用点的方式代表其位置。本文主要采用了回归和heatmap两种方式来回归关键点,是一个很简单基础的项目,代码量很小,可供新手学习。
数据集:数据来源自小武,经过小武的授权使用,但不会公开。本项目只用了其中很少一部分共108张图片。
标注工具:https://github.com/pprp/landmark_annotation
标注工具也可以在GiantPandaCV公众号后台回复“landmark”关键字获取

上图是数据集中的两张图片,红圈代表对应的目标,标注的时候只需要在其中心点一下即可得到该点对应的横纵坐标。
该数据集有一个特点,每张图只有一个目标(不然没法用简单的方法回归),多余一个目标的图片被剔除了。
1
0.42 0.596以上是一个标注文件的例子,1.jpg对应1.txt
回归确定关键点比较简单,网络部分采用手工构建的一个两层的小网络,训练采用的是MSELoss。
这部分代码在:https://github.com/pprp/SimpleCVReproduction/tree/master/simple_keypoint/regression
数据的组织比较简单,按照以下格式组织:
- data
- images
- 1.jpg
- 2.jpg
- ...
- labels
- 1.txt
- 2.txt
- ...重写一下Dataset类,用于加载数据集。
class KeyPointDatasets(Dataset):
def __init__(self, root_dir="./data", transforms=None):
super(KeyPointDatasets, self).__init__()
self.img_path = os.path.join(root_dir, "images")
# self.txt_path = os.path.join(root_dir, "labels")
self.img_list = glob.glob(os.path.join(self.img_path, "*.jpg"))
self.txt_list = [item.replace(".jpg", ".txt").replace(
"images", "labels") for item in self.img_list]
if transforms is not None:
self.transforms = transforms
def __getitem__(self, index):
img = self.img_list[index]
txt = self.txt_list[index]
img = cv2.imread(img)
if self.transforms:
img = self.transforms(img)
label = []
with open(txt, "r") as f:
for i, line in enumerate(f):
if i == 0:
# 第一行
num_point = int(line.strip())
else:
x1, y1 = [(t.strip()) for t in line.split()]
# range from 0 to 1
x1, y1 = float(x1), float(y1)
tmp_label = (x1, y1)
label.append(tmp_label)
return img, torch.tensor(label[0])
def __len__(self):
return len(self.img_list)
@staticmethod
def collect_fn(batch):
imgs, labels = zip(*batch)
return torch.stack(imgs, 0), torch.stack(labels, 0)返回的结果是图片和对应坐标位置。
import torch
import torch.nn as nn
class KeyPointModel(nn.Module):
def __init__(self):
super(KeyPointModel, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 3, 1, 1)
self.bn1 = nn.BatchNorm2d(6)
self.relu1 = nn.ReLU(True)
self.maxpool1 = nn.MaxPool2d((2, 2))
self.conv2 = nn.Conv2d(6, 12, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(12)
self.relu2 = nn.ReLU(True)
self.maxpool2 = nn.MaxPool2d((2, 2))
self.gap = nn.AdaptiveMaxPool2d(1)
self.classifier = nn.Sequential(
nn.Linear(12, 2),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.maxpool2(x)
x = self.gap(x)
x = x.view(x.shape[0], -1)
return self.classifier(x)其结构就是卷积+pooling+卷积+pooling+global average pooling+Linear,返回长度为2的tensor。
def train(model, epoch, dataloader, optimizer, criterion):
model.train()
for itr, (image, label) in enumerate(dataloader):
bs = image.shape[0]
output = model(image)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if itr % 4 == 0:
print("epoch:%2d|step:%04d|loss:%.6f" % (epoch, itr, loss.item()/bs))
vis.plot_many_stack({"train_loss": loss.item()*100/bs})
total_epoch = 300
bs = 10
########################################
transforms_all = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((360,480)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4372, 0.4372, 0.4373],
std=[0.2479, 0.2475, 0.2485])
])
datasets = KeyPointDatasets(root_dir="./data", transforms=transforms_all)
data_loader = DataLoader(datasets, shuffle=True,
batch_size=bs, collate_fn=datasets.collect_fn)
model = KeyPointModel()
optimizer = torch.optim.Adam(model.parameters(), lr=3e-4)
# criterion = torch.nn.SmoothL1Loss()
criterion = torch.nn.MSELoss()
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=30,
gamma=0.1)
for epoch in range(total_epoch):
train(model, epoch, data_loader, optimizer, criterion)
loss = test(model, epoch, data_loader, criterion)
if epoch % 10 == 0:
torch.save(model.state_dict(),
"weights/epoch_%d_%.3f.pt" % (epoch, loss*1000))loss部分使用Smooth L1 loss或者MSE loss均可。
MSE Loss: $$ loss(x,y)=\frac{1}{n}\sum(x_i-y_i)^2 $$ Smooth L1 Loss: $$ smooth_{L_1}(x)= \begin{cases} 0.5x^2 & if |x|<1 \ |x|-0.5 & otherwise \end{cases} $$

这部分代码很多参考了CenterNet,不过曾经尝试CenterNet中的loss在这个问题上收敛效果不好,所以参考了kaggle人脸关键点定位的解决方法,发现使用简单的MSELoss效果就很好。
这部分和CenterNet构建heatmap的过程类似,不过半径的确定是人工的。因为数据集中的目标都比较小,半径的范围最大不超过半径为30个像素的圆。
class KeyPointDatasets(Dataset):
def __init__(self, root_dir="./data", transforms=None):
super(KeyPointDatasets, self).__init__()
self.down_ratio = 1
self.img_w = 480 // self.down_ratio
self.img_h = 360 // self.down_ratio
self.img_path = os.path.join(root_dir, "images")
self.img_list = glob.glob(os.path.join(self.img_path, "*.jpg"))
self.txt_list = [item.replace(".jpg", ".txt").replace(
"images", "labels") for item in self.img_list]
if transforms is not None:
self.transforms = transforms
def __getitem__(self, index):
img = self.img_list[index]
txt = self.txt_list[index]
img = cv2.imread(img)
if self.transforms:
img = self.transforms(img)
label = []
with open(txt, "r") as f:
for i, line in enumerate(f):
if i == 0:
# 第一行
num_point = int(line.strip())
else:
x1, y1 = [(t.strip()) for t in line.split()]
# range from 0 to 1
x1, y1 = float(x1), float(y1)
cx, cy = x1 * self.img_w, y1 * self.img_h
heatmap = np.zeros((self.img_h, self.img_w))
draw_umich_gaussian(heatmap, (cx, cy), 30)
return img, torch.tensor(heatmap).unsqueeze(0)
def __len__(self):
return len(self.img_list)
@staticmethod
def collect_fn(batch):
imgs, labels = zip(*batch)
return torch.stack(imgs, 0), torch.stack(labels, 0)核心函数是draw_umich_gaussian,具体如下:
def gaussian2D(shape, sigma=1):
m, n = [(ss - 1.) / 2. for ss in shape]
y, x = np.ogrid[-m:m + 1, -n:n + 1]
h = np.exp(-(x * x + y * y) / (2 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
# 限制最小的值
return h
def draw_umich_gaussian(heatmap, center, radius, k=1):
diameter = 2 * radius + 1
gaussian = gaussian2D((diameter, diameter), sigma=diameter / 6)
# 一个圆对应内切正方形的高斯分布
x, y = int(center[0]), int(center[1])
width, height = heatmap.shape
left, right = min(x, radius), min(width - x, radius + 1)
top, bottom = min(y, radius), min(height - y, radius + 1)
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
masked_gaussian = gaussian[radius - top:radius +
bottom, radius - left:radius + right]
if min(masked_gaussian.shape) > 0 and min(masked_heatmap.shape) > 0: # TODO debug
np.maximum(masked_heatmap, masked_gaussian * k, out=masked_heatmap)
# 将高斯分布覆盖到heatmap上,取最大,而不是叠加
return heatmapsigma参数直接沿用了CenterNet中的设置,没有调节这个超参数。
网络结构参考了知乎上一个复现YOLOv3中提到的模块,Sematic Embbed Block(SEB)用于上采样部分,将来自低分辨率的特征图进行上采样,然后使用3x3卷积和1x1卷积统一通道个数,最后将低分辨率特征图和高分辨率特征图相乘得到融合结果。
class SematicEmbbedBlock(nn.Module):
def __init__(self, high_in_plane, low_in_plane, out_plane):
super(SematicEmbbedBlock, self).__init__()
self.conv3x3 = nn.Conv2d(high_in_plane, out_plane, 3, 1, 1)
self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)
self.conv1x1 = nn.Conv2d(low_in_plane, out_plane, 1)
def forward(self, high_x, low_x):
high_x = self.upsample(self.conv3x3(high_x))
low_x = self.conv1x1(low_x)
return high_x * low_x
class KeyPointModel(nn.Module):
"""
downsample ratio=2
"""
def __init__(self):
super(KeyPointModel, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 3, 1, 1)
self.bn1 = nn.BatchNorm2d(6)
self.relu1 = nn.ReLU(True)
self.maxpool1 = nn.MaxPool2d((2, 2))
self.conv2 = nn.Conv2d(6, 12, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(12)
self.relu2 = nn.ReLU(True)
self.maxpool2 = nn.MaxPool2d((2, 2))
self.conv3 = nn.Conv2d(12, 20, 3, 1, 1)
self.bn3 = nn.BatchNorm2d(20)
self.relu3 = nn.ReLU(True)
self.maxpool3 = nn.MaxPool2d((2, 2))
self.conv4 = nn.Conv2d(20, 40, 3, 1, 1)
self.bn4 = nn.BatchNorm2d(40)
self.relu4 = nn.ReLU(True)
self.seb1 = SematicEmbbedBlock(40, 20, 20)
self.seb2 = SematicEmbbedBlock(20, 12, 12)
self.seb3 = SematicEmbbedBlock(12, 6, 6)
self.heatmap = nn.Conv2d(6, 1, 1)
def forward(self, x):
x1 = self.conv1(x)
x1 = self.bn1(x1)
x1 = self.relu1(x1)
m1 = self.maxpool1(x1)
x2 = self.conv2(m1)
x2 = self.bn2(x2)
x2 = self.relu2(x2)
m2 = self.maxpool2(x2)
x3 = self.conv3(m2)
x3 = self.bn3(x3)
x3 = self.relu3(x3)
m3 = self.maxpool3(x3)
x4 = self.conv4(m3)
x4 = self.bn4(x4)
x4 = self.relu4(x4)
up1 = self.seb1(x4, x3)
up2 = self.seb2(up1, x2)
up3 = self.seb3(up2, x1)
out = self.heatmap(up3)
return out网络模型也是自己写的小网络,用了四个卷积层,三个池化层,然后进行了三次上采样。最终输出分辨率和输入分辨率相同。
训练过程和基于回归的方法几乎一样,代码如下:
datasets = KeyPointDatasets(root_dir="./data", transforms=transforms_all)
data_loader = DataLoader(datasets, shuffle=True,
batch_size=bs, collate_fn=datasets.collect_fn)
model = KeyPointModel()
if torch.cuda.is_available():
model = model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=3e-3)
criterion = torch.nn.MSELoss() # compute_loss
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=30,
gamma=0.1)
for epoch in range(total_epoch):
train(model, epoch, data_loader, optimizer, criterion, scheduler)
loss = test(model, epoch, data_loader, criterion)
if epoch % 5 == 0:
torch.save(model.state_dict(),
"weights/epoch_%d_%.3f.pt" % (epoch, loss*10000))用的是MSELoss进行监督,训练曲线如下:
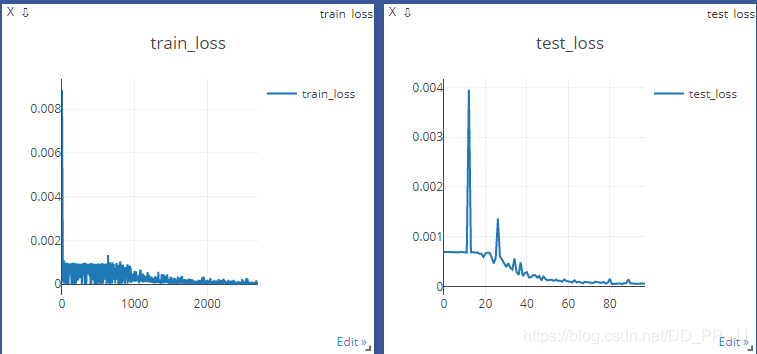
测试过程和CenterNet的推理过程一致,也用到了3x3的maxpooling来筛选极大值点
for iter, (image, label) in enumerate(dataloader):
# print(image.shape)
bs = image.shape[0]
hm = model(image)
hm = _nms(hm)
hm = hm.detach().numpy()
for i in range(bs):
hm = hm[i]
hm = np.maximum(hm, 0)
hm = hm/np.max(hm)
hm = normalization(hm)
hm = np.uint8(255 * hm)
hm = hm[0]
# heatmap = torch.sigmoid(heatmap)
# hm = cv2.cvtColor(hm, cv2.COLOR_RGB2BGR)
hm = cv2.applyColorMap(hm, cv2.COLORMAP_JET)
cv2.imwrite("./test_output/output_%d_%d.jpg" % (iter, i), hm)
cv2.waitKey(0)以上的nms和topk代码都在CenterNet系列最后一篇讲过了。这里直接对模型输出结果使用nms,然后进行可视化,结果如下:
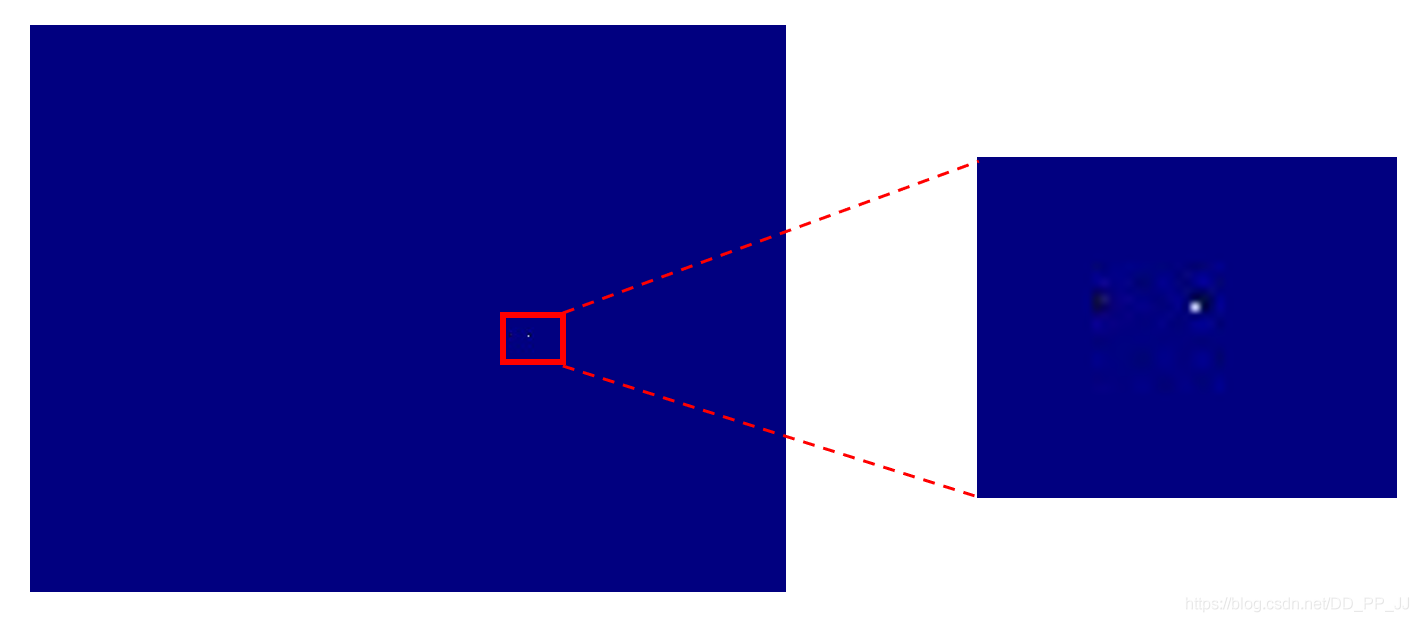
上图中白色的点就是目标位置,为了更形象的查看结果,detect.py部分负责可视化。
可视化的问题经常遇见,比如CAM、Grad CAM等可视化特征图的时候就会碰到。以下是可视化的一个简单的方法(参考了CSDN的一位博主的方案,具体链接因太过久远找不到了)。
具体实现代码如下:
def normalization(data):
_range = np.max(data) - np.min(data)
return (data - np.min(data)) / _range
heatmap = model(img_tensor_list)
heatmap = heatmap.squeeze().cpu()
for i in range(bs):
img_path = img_list[i]
img = cv2.imread(img_path)
img = cv2.resize(img, (480, 360))
single_map = heatmap[i]
hm = single_map.detach().numpy()
hm = np.maximum(hm, 0)
hm = hm/np.max(hm)
hm = normalization(hm)
hm = np.uint8(255 * hm)
hm = cv2.applyColorMap(hm, cv2.COLORMAP_JET)
hm = cv2.resize(hm, (480, 360))
superimposed_img = hm * 0.2 + img
coord_x, coord_y = landmark_coord[i]
cv2.circle(superimposed_img, (int(coord_x), int(coord_y)), 2, (0, 0, 0), thickness=-1)
cv2.imwrite("./output2/%s_out.jpg" % (img_name_list[i]), superimposed_img)注意通过处理以后的hm和原图叠加的时候0.2只是一个参考值,这个值既不会影响原图显示又能将heatmap中重点关注的位置可视化出来。
结果如下:

可以看到,定位结果要比回归更准一些,图中黑色点是获取到最终坐标的位置,几乎和目标是重叠的状态,效果比较理想。