

Everything begins and ends with our biggest engineering principle: we take a very practical approach to how we build. This applies to Front’s engineering team, but also across all teams within the company and even how we do continuous integration and continuous delivery (CI/CD). There are always more engineering ideas and projects than there are resources and bandwidth. We want to build for the highest ROI and not for perfection, while remaining cognizant of the fact that we’re going to have to scale. Things we’re building today might have to change or might become a concern in the future, so we try to balance that while solving for today’s problems.
In addition to balancing these priorities, we also want to move quickly. When we started Front, we managed all of our infrastructure with Chef because it enabled us to more easily bring servers up—despite the manual process. Our full CI and end-to-end deployment process ballooned to 30 minutes as more servers were added over time. It became a bottleneck, contrasting with our engineering team’s philosophy of moving quickly. We wanted to be able to see our changes live as quickly as possible, and waiting 30 minutes was simply too long.
That all changed when we moved from using Chef to using Kubernetes. Building a deploy process around Kubernetes was a big transformation for us. Now, we do canary deployments and frictionless continuous deployments at the same time, and every engineer has their own staging environment. It’s not 100 percent safe, but we have high confidence in our process, and it allows us to develop a lot faster. We also have safeguards: our scripts can roll back to a stable version if we’re alerted of any issues. So on one hand, we’re still taking a risk. On the other, it’s very practical and allows our team to get a lot accomplished.
Setting the foundation for successful projects
See more ways teams speed up their DevOps workflows
We try to scope projects to be only a few weeks long from the start. By setting timelines that are about the same as a typical sprint, we can continue to iterate and show results every few weeks. For more complex projects that take longer, we break them into smaller, more manageable goals and begin the planning process for each of these with a one-pager.
The one-pager includes everything from a prompt statement—what we’re trying to solve—to the pain points and implementation. The engineer responsible for the feature or project explains what design decisions need to be made, and if there are specific infrastructure or systems designs that need to be taken into account. At the end of the one-pager, we include the key layer process and rollout, along with the timeline for each part of the project. Then different stakeholders review and add their feedback.
Learn how to share code and project plans with gists
Since this process alone can take anywhere from a few days to a week, we try to finish the one-pager before the project officially starts. That way all the details of the project have already been discussed and decided on by the time the engineer picks it up. Once development kicks off, the way we track what happens next depends on the individual team. Some teams use JIRA, others track it internally in standups, or some just touch base with discussions.
Best practices
Increase velocity by improving the developer experience.
Keep pull requests small for better quality and speed.
Add new tests deliberately, and balance the tradeoff between CI and development time they bring.
Give developers individual branches and staging environments.
Use multiple, parallel canary deployments to get changes to production faster.
A staging environment for every developer
From there, the development process begins—and almost immediately branches off. There are different ways to stage and test depending on the code being written. We’ve built our staging environments to mimic our production infrastructure as much as possible, so both run on Kubernetes. When we push code to designated staging GitHub branches, it'll trigger a deploy to the matching staging environment. The same thing goes for pre-production, canaries, and production. We have different CI workflows for each one of them.
There are advantages and disadvantages to each environment based on the type of change, the part of our system being tested, and what it requires. If we want to test email deliverability or integrations with third-party providers or applications, we need to be able to connect to these providers. But if we need to test functionality unique to Front, we can get a local instance of our application running on a laptop with a single command, without wifi or anything else. A lot of the groundwork for our local environment was built by our CTO; he was traveling back and forth between Paris and San Francisco and wanted to work on the plane. Some of the features in Front were actually built and tested through the local environment.
Not only have we been able to create multiple copies of staging environments, but we’ve also been able to create individual staging environments for each developer. This is a massive improvement we’ve undertaken over the last year. Previously, we had around 40 engineers vying for a few staging servers. With this new focus on improving the developer experience, we’ve removed the resource contention around testing and everyone has what they need.
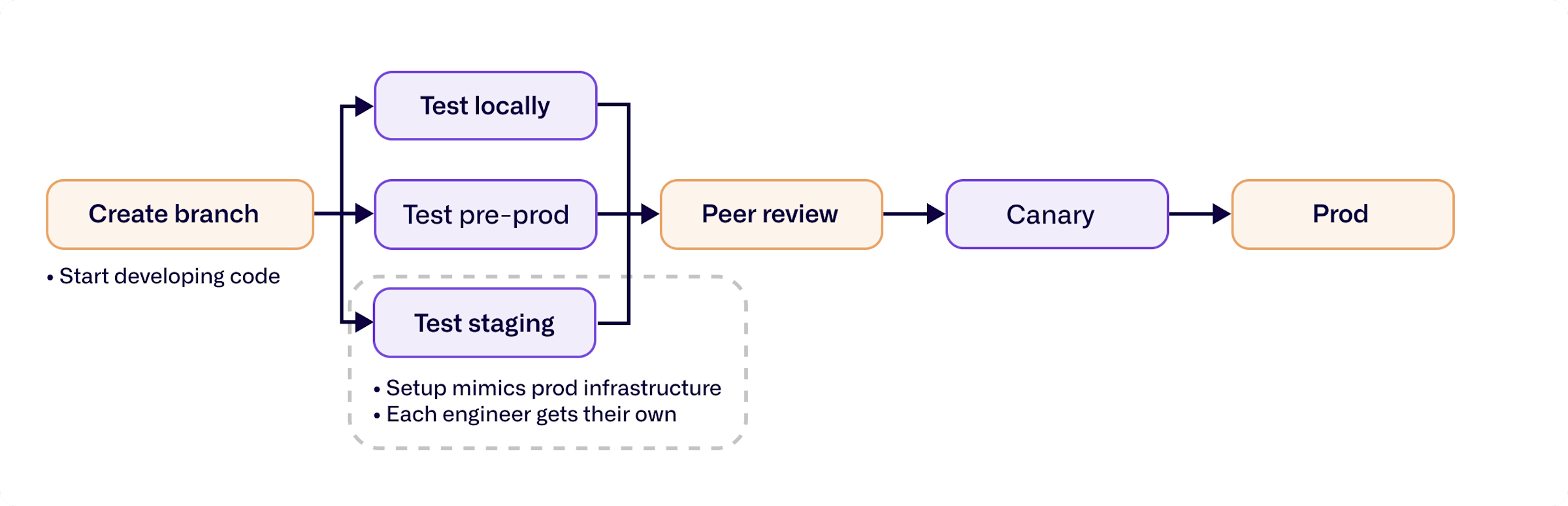
Reducing friction in pull requests and checks
Once the staging environment is set, new code and code changes have to follow a specific list of tests and checks before they pass over to code review. The review process has to move quickly or it’s going to block the engineer—but since our team is split between Paris and San Francisco, any cross-office reviews will add lag time.
Explore the connection between pull requests and productivity
Given that we sometimes have to overcome large time zone differences, we want to minimize the back and forth. We accomplish this by making pull requests as small and easy to comprehend as possible, which in turn makes them easier to review and test. Since we have continuous deployments, we aren’t pressured to load as many changes into a deploy as we can. When we do have pull requests with a lot of comments, we try to diagnose why. We often find that the discussion stems from designs not being fully agreed upon in the original one-pager, or a new engineer not fully understanding the changes being made. In either case, we encourage having these discussions earlier and synchronously over a video call rather than through the pull request.
For the checks themselves, we use CircleCI and GitHub Actions. When a pull request is either created or updated, it triggers an action, which triggers specific checks in our CircleCI workflow. We want to run all possible checks before deploying to production. We use a GitHub plugin called Danger JS, which runs specific checks to see what’s been committed as part of the pull request. We can see if certain files are being modified—and in those cases, if the right tests are being run—and flag them to either undergo additional testing or request additional explanation.
Keep pull requests moving with scheduled reminders
GitHub is our centralized hub for pull request status. If any tests or code checks fail, the pull request will be blocked from merging. But if we’re just deploying to a staging environment, we keep the checks minimal and just build an image—another way to avoid slowing down our workflow.
Fewer incidents, faster tests with parallel canaries
Once the code is reviewed and passes all the right checks, we move on to canary deployments. We’ve made some improvements to speed up our process here as well. Before, we had to pull in the latest changes from production, run the tests there, and then we could deploy using canary servers. This took a long time, which led to people not canary-ing their pull requests because it was too slow. Corners were cut, canaries weren’t run, and it caused preventable incidents. So on the testing side, we stepped back and made some changes to our requirements. Now if the tests run fine on a pull request and there aren’t any conflicts with the new production changes, it’s ready for canary deployment.
Get more canary best practices from the GitHub Deploy Team
Despite the improvements to the canary CI time, we still had a queue for canary-ing as we could only support one canary at a time. To address this issue, we rebuilt our deployment infrastructure to allow multiple canary deployments at once. We support canary deployments and our production infrastructure with two separate Helm charts. Separating the two means we can run canaries and production deployments in parallel, allowing long-running canaries—and their critical code tests—to run for hours without impacting deployment velocity. The deploy service will know either to deploy a new full production rollout or to just deploy a canary version.
Scalable rollbacks and deployments
With these updates, we’ve seen a lot more engineers using canary deployments and have had fewer incidents as a result. But the new changes posed new challenges: if we have multiple canary deployments running and a deployment happening at the same time, how do we know which one is causing issues? Or what if the tests said everything ran fine, but once we actually merge it, it starts causing issues?
Key indicators
Lead time for changes (CI and end-to-end release process)
Change failure rate
Code review turnaround time
We mitigate these risks by not scaling up all the way. We start by deploying the canary changes to a single server, which can be scaled up by the engineer running canaries as they gain more confidence that their change isn't breaking anything. They can see if there’s an issue, then scale down those canary servers and replay everything. We can actually retry all failures within our system before anything moves to production, and if needed, at scale in production as well. Once we're done with the canary process and everything goes as well as anticipated, we can merge the changes, and they’ll get deployed to production.
Looking back while building forward
There’s always room for improvement. That’s how we’ve streamlined our process—identifying not just what works, but what could be better. After every project, we take a look at how things went and what could’ve been done differently. With canary deployments, that meant changing our requirements. For pull requests, it was keeping comments minimal and using video for in-depth discussions. And on a much larger scale, it was switching to Kubernetes to cut down on manual tasks. Some of these were bigger changes than others, but it all comes back to balance and practicality. It’s important to make changes that will have the most meaningful impact on the way we work today, while setting ourselves up for success in the future.


