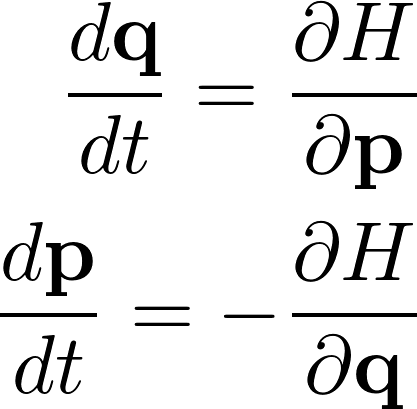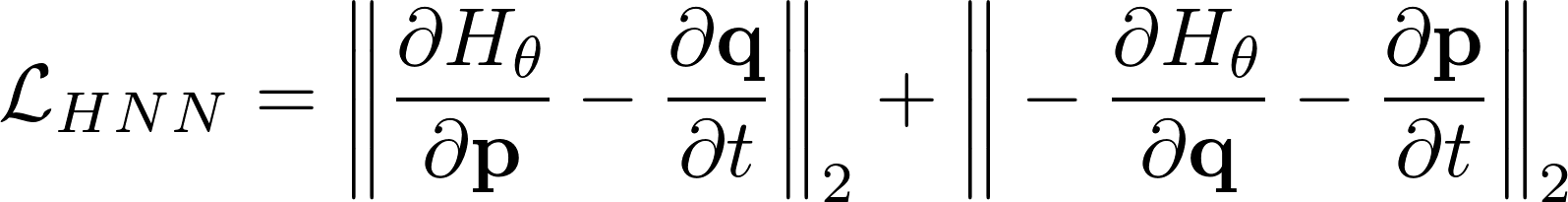diff --git a/_site/404.html b/_site/404.html
new file mode 100644
index 00000000..b7c3474c
--- /dev/null
+++ b/_site/404.html
@@ -0,0 +1,4 @@
+
+
404: Page not found
+
Sorry, we've misplaced that URL or it's pointing to something that doesn't exist. Head back home to try finding it again.
+
diff --git a/_site/README.md b/_site/README.md
new file mode 100755
index 00000000..d8f5e39c
--- /dev/null
+++ b/_site/README.md
@@ -0,0 +1,227 @@
+# papers-I-read
+
+I am trying a new initiative - a-paper-a-week. This repository will hold all those papers and related summaries and notes.
+
+## List of papers
+
+- [Toolformer - Language Models Can Teach Themselves to Use Tools](https://shagunsodhani.com/papers-I-read/Toolformer-Language-Models-Can-Teach-Themselves-to-Use-Tools)
+- [Hints for Computer System Design](https://shagunsodhani.com/papers-I-read/Hints-for-Computer-System-Design)
+- [Synthesized Policies for Transfer and Adaptation across Tasks and Environments](https://shagunsodhani.com/papers-I-read/Synthesized-Policies-for-Transfer-and-Adaptation-across-Tasks-and-Environments)
+- [Deep Neural Networks for YouTube Recommendations](https://shagunsodhani.com/papers-I-read/Deep-Neural-Networks-for-YouTube-Recommendations)
+- [The Tail at Scale](https://shagunsodhani.com/papers-I-read/The-Tail-at-Scale)
+- [Practical Lessons from Predicting Clicks on Ads at Facebook](https://shagunsodhani.com/papers-I-read/Practical-Lessons-from-Predicting-Clicks-on-Ads-at-Facebook)
+- [Ad Click Prediction - a View from the Trenches](https://shagunsodhani.com/papers-I-read/Ad-Click-Prediction-a-View-from-the-Trenches)
+- [Anatomy of Catastrophic Forgetting - Hidden Representations and Task Semantics](https://shagunsodhani.com/papers-I-read/Anatomy-of-Catastrophic-Forgetting-Hidden-Representations-and-Task-Semantics)
+- [When Do Curricula Work?](https://shagunsodhani.com/papers-I-read/When-Do-Curricula-Work)
+- [Continual learning with hypernetworks](https://shagunsodhani.com/papers-I-read/Continual-learning-with-hypernetworks)
+- [Zero-shot Learning by Generating Task-specific Adapters](https://shagunsodhani.com/papers-I-read/Zero-shot-Learning-by-Generating-Task-specific-Adapters)
+- [HyperNetworks](https://shagunsodhani.com/papers-I-read/HyperNetworks)
+- [Energy-based Models for Continual Learning](https://shagunsodhani.com/papers-I-read/Energy-based-Models-for-Continual-Learning)
+- [GPipe - Easy Scaling with Micro-Batch Pipeline Parallelism](https://shagunsodhani.com/papers-I-read/GPipe-Easy-Scaling-with-Micro-Batch-Pipeline-Parallelism)
+- [Compositional Explanations of Neurons](https://shagunsodhani.com/papers-I-read/Compositional-Explanations-of-Neurons)
+- [Design patterns for container-based distributed systems](https://shagunsodhani.com/papers-I-read/Design-patterns-for-container-based-distributed-systems)
+- [Cassandra - a decentralized structured storage system](https://shagunsodhani.com/papers-I-read/Cassandra-a-decentralized-structured-storage-system)
+- [CAP twelve years later - How the rules have changed](https://shagunsodhani.com/papers-I-read/CAP-twelve-years-later-How-the-rules-have-changed)
+- [Consistency Tradeoffs in Modern Distributed Database System Design](https://shagunsodhani.com/papers-I-read/Consistency-Tradeoffs-in-Modern-Distributed-Database-System-Design)
+- [Exploring Simple Siamese Representation Learning](https://shagunsodhani.com/papers-I-read/Exploring-Simple-Siamese-Representation-Learning)
+- [Data Management for Internet-Scale Single-Sign-On](https://shagunsodhani.com/papers-I-read/Data-Management-for-Internet-Scale-Single-Sign-On)
+- [Searching for Build Debt - Experiences Managing Technical Debt at Google](https://shagunsodhani.com/papers-I-read/Searching-for-Build-Debt-Experiences-Managing-Technical-Debt-at-Google)
+- [One Solution is Not All You Need - Few-Shot Extrapolation via Structured MaxEnt RL](https://shagunsodhani.com/papers-I-read/One-Solution-is-Not-All-You-Need-Few-Shot-Extrapolation-via-Structured-MaxEnt-RL)
+- [Learning Explanations That Are Hard To Vary](https://shagunsodhani.com/papers-I-read/Learning-Explanations-That-Are-Hard-To-Vary)
+- [Remembering for the Right Reasons - Explanations Reduce Catastrophic Forgetting](https://shagunsodhani.com/papers-I-read/Remembering-for-the-Right-Reasons-Explanations-Reduce-Catastrophic-Forgetting)
+- [A Foliated View of Transfer Learning](https://shagunsodhani.com/papers-I-read/A-Foliated-View-of-Transfer-Learning)
+- [Harvest, Yield, and Scalable Tolerant Systems](https://shagunsodhani.com/papers-I-read/Harvest,-Yield,-and-Scalable-Tolerant-Systems)
+- [MONet - Unsupervised Scene Decomposition and Representation](https://shagunsodhani.com/papers-I-read/MONet-Unsupervised-Scene-Decomposition-and-Representation)
+- [Revisiting Fundamentals of Experience Replay](https://shagunsodhani.com/papers-I-read/Revisiting-Fundamentals-of-Experience-Replay)
+- [Deep Reinforcement Learning and the Deadly Triad](https://shagunsodhani.com/papers-I-read/Deep-Reinforcement-Learning-and-the-Deadly-Triad)
+- [Alpha Net: Adaptation with Composition in Classifier Space](https://shagunsodhani.com/papers-I-read/Alpha-Net-Adaptation-with-Composition-in-Classifier-Space)
+- [Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer](https://shagunsodhani.com/papers-I-read/Outrageously-Large-Neural-Networks-The-Sparsely-Gated-Mixture-of-Experts-Layer)
+- [Gradient Surgery for Multi-Task Learning](https://shagunsodhani.com/papers-I-read/Gradient-Surgery-for-Multi-Task-Learning)
+- [GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks](https://shagunsodhani.com/papers-I-read/GradNorm-Gradient-Normalization-for-Adaptive-Loss-Balancing-in-Deep-Multitask-Networks)
+- [TaskNorm: Rethinking Batch Normalization for Meta-Learning](https://shagunsodhani.com/papers-I-read/TASKNORM-Rethinking-Batch-Normalization-for-Meta-Learning)
+- [Averaging Weights leads to Wider Optima and Better Generalization](https://shagunsodhani.com/papers-I-read/Averaging-Weights-leads-to-Wider-Optima-and-Better-Generalization)
+- [Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions](https://shagunsodhani.com/papers-I-read/Decentralized-Reinforcement-Learning-Global-Decision-Making-via-Local-Economic-Transactions)
+- [When to use parametric models in reinforcement learning?](https://shagunsodhani.com/papers-I-read/When-to-use-parametric-models-in-reinforcement-learning)
+- [Network Randomization - A Simple Technique for Generalization in Deep Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Network-Randomization-A-Simple-Technique-for-Generalization-in-Deep-Reinforcement-Learning)
+- [On the Difficulty of Warm-Starting Neural Network Training](https://shagunsodhani.com/papers-I-read/On-the-Difficulty-of-Warm-Starting-Neural-Network-Training)
+- [Supervised Contrastive Learning](https://shagunsodhani.com/papers-I-read/Supervised-Contrastive-Learning)
+- [CURL - Contrastive Unsupervised Representations for Reinforcement Learning](https://shagunsodhani.com/papers-I-read/CURL-Contrastive-Unsupervised-Representations-for-Reinforcement-Learning)
+- [Competitive Training of Mixtures of Independent Deep Generative Models](https://shagunsodhani.com/papers-I-read/Competitive-Training-of-Mixtures-of-Independent-Deep-Generative-Models)
+- [What Does Classifying More Than 10,000 Image Categories Tell Us?](https://shagunsodhani.com/papers-I-read/What-Does-Classifying-More-Than-10,000-Image-Categories-Tell-Us)
+- [mixup - Beyond Empirical Risk Minimization](https://shagunsodhani.com/papers-I-read/mixup-Beyond-Empirical-Risk-Minimization)
+- [ELECTRA - Pre-training Text Encoders as Discriminators Rather Than Generators](https://shagunsodhani.com/papers-I-read/ELECTRA-Pre-training-Text-Encoders-as-Discriminators-Rather-Than-Generators)
+- [Gradient based sample selection for online continual learning](https://shagunsodhani.com/papers-I-read/Gradient-based-sample-selection-for-online-continual-learning)
+- [Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One](https://shagunsodhani.com/papers-I-read/Your-Classifier-is-Secretly-an-Energy-Based-Model,-and-You-Should-Treat-it-Like-One)
+- [Massively Multilingual Neural Machine Translation in the Wild - Findings and Challenges](https://shagunsodhani.com/papers-I-read/Massively-Multilingual-Neural-Machine-Translation-in-the-Wild-Findings-and-Challenges)
+- [Observational Overfitting in Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Observational-Overfitting-in-Reinforcement-Learning)
+- [Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML](https://shagunsodhani.com/papers-I-read/Rapid-Learning-or-Feature-Reuse-Towards-Understanding-the-Effectiveness-of-MAML)
+- [Accurate, Large Minibatch SGD - Training ImageNet in 1 Hour](https://shagunsodhani.com/papers-I-read/Accurate-Large-Minibatch-SGD-Training-ImageNet-in-1-Hour)
+- [Superposition of many models into one](https://shagunsodhani.com/papers-I-read/Superposition-of-many-models-into-one)
+- [Towards a Unified Theory of State Abstraction for MDPs](https://shagunsodhani.com/papers-I-read/Towards-a-Unified-Theory-of-State-Abstraction-for-MDPs)
+- [ALBERT - A Lite BERT for Self-supervised Learning of Language Representations](https://shagunsodhani.com/papers-I-read/ALBERT-A-Lite-BERT-for-Self-supervised-Learning-of-Language-Representations)
+- [Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model](https://shagunsodhani.com/papers-I-read/Mastering-Atari,-Go,-Chess-and-Shogi-by-Planning-with-a-Learned-Model)
+- [Contrastive Learning of Structured World Models](https://shagunsodhani.com/papers-I-read/Contrastive-Learning-of-Structured-World-Models)
+- [Gossip based Actor-Learner Architectures for Deep RL](https://shagunsodhani.com/papers-I-read/Gossip-based-Actor-Learner-Architectures-for-Deep-RL)
+- [How to train your MAML](https://shagunsodhani.com/papers-I-read/How-to-train-your-MAML)
+- [PHYRE - A New Benchmark for Physical Reasoning](https://shagunsodhani.com/papers-I-read/PHYRE-A-New-Benchmark-for-Physical-Reasoning)
+- [Large Memory Layers with Product Keys](https://shagunsodhani.com/papers-I-read/Large-Memory-Layers-with-Product-Keys)
+- [Abductive Commonsense Reasoning](https://shagunsodhani.com/papers-I-read/Abductive-Commonsense-Reasoning)
+- [Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models](https://shagunsodhani.com/papers-I-read/Deep-Reinforcement-Learning-in-a-Handful-of-Trials-using-Probabilistic-Dynamics-Models)
+- [Assessing Generalization in Deep Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Assessing-Generalization-in-Deep-Reinforcement-Learning)
+- [Quantifying Generalization in Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Quantifying-Generalization-in-Reinforcement-Learning)
+- [Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks](https://shagunsodhani.com/papers-I-read/Set-Transformer-A-Framework-for-Attention-based-Permutation-Invariant-Neural-Networks)
+- [Measuring abstract reasoning in neural networks](https://shagunsodhani.com/papers-I-read/Measuring-Abstract-Reasoning-in-Neural-Networks)
+- [Hamiltonian Neural Networks](https://shagunsodhani.com/papers-I-read/Hamiltonian-Neural-Networks)
+- [Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations](https://shagunsodhani.com/papers-I-read/Extrapolating-Beyond-Suboptimal-Demonstrations-via-Inverse-Reinforcement-Learning-from-Observations)
+- [Meta-Reinforcement Learning of Structured Exploration Strategies](https://shagunsodhani.com/papers-I-read/Meta-Reinforcement-Learning-of-Structured-Exploration-Strategies)
+- [Relational Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Relational-Reinforcement-Learning)
+- [Good-Enough Compositional Data Augmentation](https://shagunsodhani.com/papers-I-read/Good-Enough-Compositional-Data-Augmentation)
+- [Multiple Model-Based Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Multiple-Model-Based-Reinforcement-Learning)
+- [Towards a natural benchmark for continual learning](https://shagunsodhani.com/papers-I-read/Towards-a-natural-benchmark-for-continual-learning)
+- [Meta-Learning Update Rules for Unsupervised Representation Learning](https://shagunsodhani.com/papers-I-read/Meta-Learning-Update-Rules-for-Unsupervised-Representation-Learning)
+- [GNN Explainer - A Tool for Post-hoc Explanation of Graph Neural Networks](https://shagunsodhani.com/papers-I-read/GNN-Explainer-A-Tool-for-Post-hoc-Explanation-of-Graph-Neural-Networks)
+- [To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks](https://shagunsodhani.com/papers-I-read/To-Tune-or-Not-to-Tune-Adapting-Pretrained-Representations-to-Diverse-Tasks)
+- [Model Primitive Hierarchical Lifelong Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Model-Primitive-Hierarchical-Lifelong-Reinforcement-Learning)
+- [TuckER - Tensor Factorization for Knowledge Graph Completion](https://shagunsodhani.com/papers-I-read/TuckER-Tensor-Factorization-for-Knowledge-Graph-Completion)
+- [Linguistic Knowledge as Memory for Recurrent Neural Networks](https://shagunsodhani.com/papers-I-read/Linguistic-Knowledge-as-Memory-for-Recurrent-Neural-Networks)
+- [Diversity is All You Need - Learning Skills without a Reward Function](https://shagunsodhani.com/papers-I-read/Diversity-is-All-You-Need-Learning-Skills-without-a-Reward-Function)
+- [Modular meta-learning](https://shagunsodhani.com/papers-I-read/Modular-meta-learning)
+- [Hierarchical RL Using an Ensemble of Proprioceptive Periodic Policies](https://shagunsodhani.com/papers-I-read/Hierarchical-RL-Using-an-Ensemble-of-Proprioceptive-Periodic-Policies)
+- [Efficient Lifelong Learningi with A-GEM](https://shagunsodhani.com/papers-I-read/Efficient-Lifelong-Learning-with-A-GEM)
+- [Pre-training Graph Neural Networks with Kernels](https://shagunsodhani.com/papers-I-read/Pre-training-Graph-Neural-Networks-with-Kernels)
+- [Smooth Loss Functions for Deep Top-k Classification](https://shagunsodhani.com/papers-I-read/Smooth-Loss-Functions-for-Deep-Top-k-Classification)
+- [Hindsight Experience Replay](https://shagunsodhani.com/papers-I-read/Hindsight-Experience-Replay)
+- [Representation Tradeoffs for Hyperbolic Embeddings](https://shagunsodhani.com/papers-I-read/Representation-Tradeoffs-for-Hyperbolic-Embeddings)
+- [Learned Optimizers that Scale and Generalize](https://shagunsodhani.com/papers-I-read/Learned-Optimizers-that-Scale-and-Generalize)
+- [One-shot Learning with Memory-Augmented Neural Networks](https://shagunsodhani.com/papers-I-read/One-shot-Learning-with-Memory-Augmented-Neural-Networks)
+- [BabyAI - First Steps Towards Grounded Language Learning With a Human In the Loop](https://shagunsodhani.com/papers-I-read/BabyAI-First-Steps-Towards-Grounded-Language-Learning-With-a-Human-In-the-Loop)
+- [Poincaré Embeddings for Learning Hierarchical Representations](https://shagunsodhani.com/papers-I-read/Poincare-Embeddings-for-Learning-Hierarchical-Representations)
+- [When Recurrent Models Don’t Need To Be Recurrent](https://shagunsodhani.com/papers-I-read/When-Recurrent-Models-Don-t-Need-To-Be-Recurrent)
+- [HoME - a Household Multimodal Environment](https://shagunsodhani.com/papers-I-read/HoME-a-Household-Multimodal-Environment)
+- [Emergence of Grounded Compositional Language in Multi-Agent Populations](https://shagunsodhani.com/papers-I-read/Emergence-of-Grounded-Compositional-Language-in-Multi-Agent-Populations)
+- [A Semantic Loss Function for Deep Learning with Symbolic Knowledge](https://shagunsodhani.com/papers-I-read/A-Semantic-Loss-Function-for-Deep-Learning-with-Symbolic-Knowledge)
+- [Hierarchical Graph Representation Learning with Differentiable Pooling](https://shagunsodhani.com/papers-I-read/Hierarchical-Graph-Representation-Learning-with-Differentiable-Pooling)
+- [Imagination-Augmented Agents for Deep Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Imagination-Augmented-Agents-for-Deep-Reinforcement-Learning)
+- [Kronecker Recurrent Units](https://shagunsodhani.com/papers-I-read/Kronecker-Recurrent-Units)
+- [Learning Independent Causal Mechanisms](https://shagunsodhani.com/papers-I-read/Learning-Independent-Causal-Mechanisms)
+- [Memory-based Parameter Adaptation](https://shagunsodhani.com/papers-I-read/Memory-Based-Parameter-Adaption)
+- [Born Again Neural Networks](https://shagunsodhani.com/papers-I-read/Born-Again-Neural-Networks)
+- [Net2Net-Accelerating Learning via Knowledge Transfer](https://shagunsodhani.com/papers-I-read/Net2Net-Accelerating-Learning-via-Knowledge-Transfer)
+- [Learning to Count Objects in Natural Images for Visual Question Answering](https://shagunsodhani.com/papers-I-read/Learning-to-Count-Objects-in-Natural-Images-for-Visual-Question-Answering)
+- [Neural Message Passing for Quantum Chemistry](https://shagunsodhani.com/papers-I-read/Neural-Message-Passing-for-Quantum-Chemistry)
+- [Unsupervised Learning by Predicting Noise](https://shagunsodhani.com/papers-I-read/Unsupervised-Learning-By-Predicting-Noise)
+- [The Lottery Ticket Hypothesis - Training Pruned Neural Networks](https://shagunsodhani.com/papers-I-read/The-Lottery-Ticket-Hypothesis-Training-Pruned-Neural-Networks)
+- [Cyclical Learning Rates for Training Neural Networks](https://shagunsodhani.com/papers-I-read/Cyclical-Learning-Rates-for-Training-Neural-Networks)
+- [Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Improving-Information-Extraction-by-Acquiring-External-Evidence-with-Reinforcement-Learning)
+- [An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks](https://shagunsodhani.com/papers-I-read/An-Empirical-Investigation-of-Catastrophic-Forgetting-in-Gradient-Based-Neural-Networks)
+- [Learning an SAT Solver from Single-Bit Supervision](https://shagunsodhani.com/papers-I-read/Learning-a-SAT-Solver-from-Single-Bit-Supervision)
+- [Neural Relational Inference for Interacting Systems](https://shagunsodhani.com/papers-I-read/Neural-Relational-Inference-for-Interacting-Systems)
+- [Stylistic Transfer in Natural Language Generation Systems Using Recurrent Neural Networks](https://shagunsodhani.com/papers-I-read/Stylistic-Transfer-in-Natural-Language-Generation-Systems-Using-Recurrent-Neural-Networks)
+- [Get To The Point: Summarization with Pointer-Generator Networks](https://shagunsodhani.com/papers-I-read/Get-To-The-Point-Summarization-with-Pointer-Generator-Networks)
+- [StarSpace - Embed All The Things!](https://shagunsodhani.com/papers-I-read/StarSpace-Embed-All-The-Things)
+- [Emotional Chatting Machine - Emotional Conversation Generation with Internal and External Memory](https://shagunsodhani.com/papers-I-read/Emotional-Chatting-Machine-Emotional-Conversation-Generation-with-Internal-and-External-Memory)
+- [Exploring Models and Data for Image Question Answering](https://shagunsodhani.com/papers-I-read/Exploring-Models-and-Data-for-Image-Question-Answering)
+- [How transferable are features in deep neural networks](https://shagunsodhani.com/papers-I-read/How-transferable-are-features-in-deep-neural-networks)
+- [Distilling the Knowledge in a Neural Network](https://shagunsodhani.com/papers-I-read/Distilling-the-Knowledge-in-a-Neural-Network)
+- [Revisiting Semi-Supervised Learning with Graph Embeddings](https://shagunsodhani.com/papers-I-read/Revisiting-Semi-Supervised-Learning-with-Graph-Embeddings)
+- [Two-Stage Synthesis Networks for Transfer Learning in Machine Comprehension](https://shagunsodhani.com/papers-I-read/Two-Stage-Synthesis-Networks-for-Transfer-Learning-in-Machine-Comprehension)
+- [Higher-order organization of complex networks](https://shagunsodhani.com/papers-I-read/Higher-order-organization-of-complex-networks)
+- [Network Motifs - Simple Building Blocks of Complex Networks](https://shagunsodhani.com/papers-I-read/Network-Motifs-Simple-Building-Blocks-of-Complex-Networks)
+- [Word Representations via Gaussian Embedding](https://shagunsodhani.com/papers-I-read/Word-Representations-via-Gaussian-Embedding)
+- [HARP - Hierarchical Representation Learning for Networks](https://shagunsodhani.com/papers-I-read/HARP-Hierarchical-Representation-Learning-for-Networks)
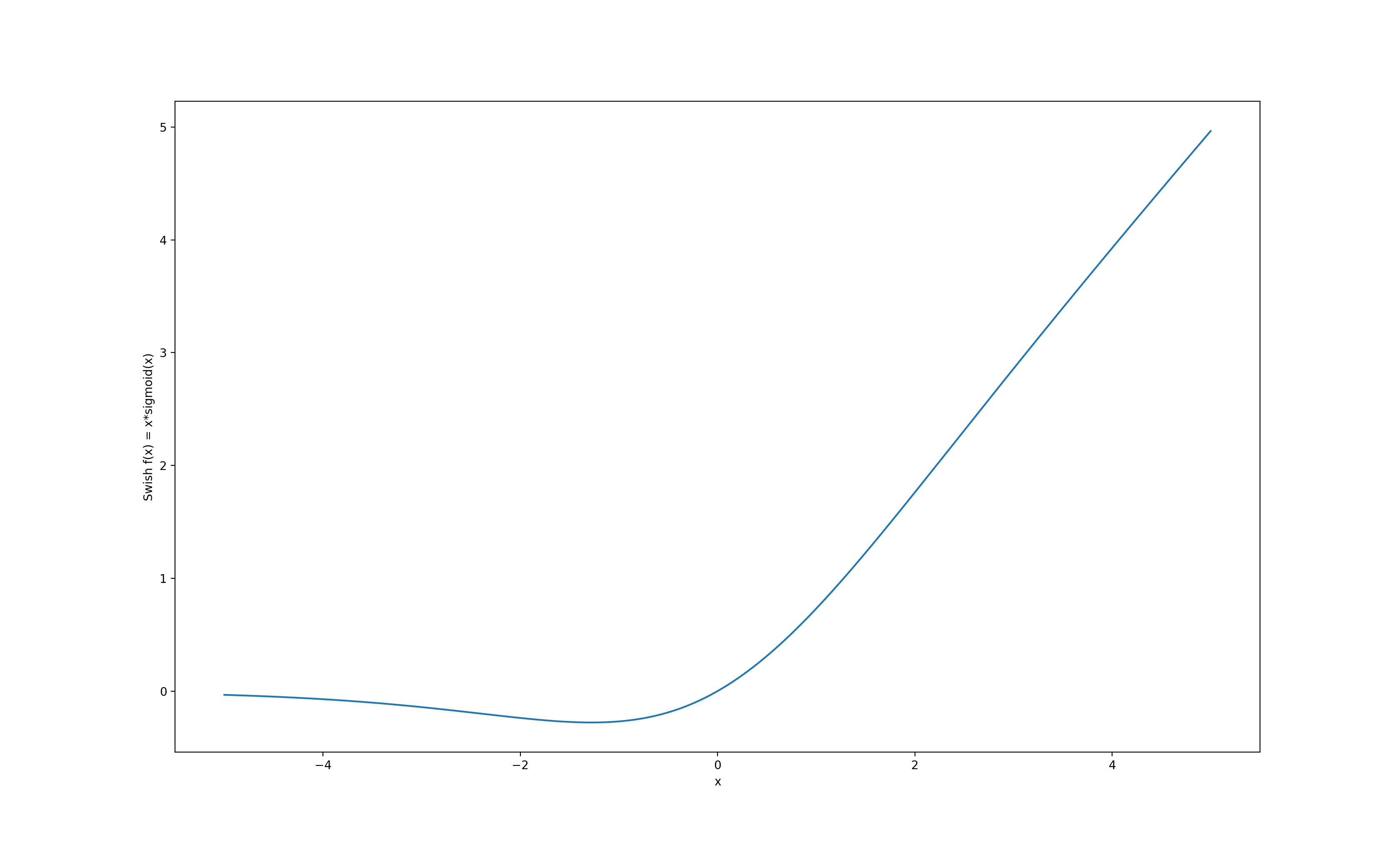
+- [Swish - a Self-Gated Activation Function](https://shagunsodhani.com/papers-I-read/Swish-A-self-gated-activation-function)
+- [Reading Wikipedia to Answer Open-Domain Questions](https://shagunsodhani.com/papers-I-read/Reading-Wikipedia-to-Answer-Open-Domain-Questions)
+- [Task-Oriented Query Reformulation with Reinforcement Learning](https://shagunsodhani.com/papers-I-read/Task-Oriented-Query-Reformulation-with-Reinforcement-Learning)
+- [Refining Source Representations with Relation Networks for Neural Machine Translation](https://shagunsodhani.com/papers-I-read/Refining-Source-Representations-with-Relation-Networks-for-Neural-Machine-Translation)
+- [Pointer Networks](https://shagunsodhani.com/papers-I-read/Pointer-Networks)
+- [Learning to Compute Word Embeddings On the Fly](https://shagunsodhani.com/papers-I-read/Learning-to-Compute-Word-Embeddings-On-the-Fly)
+- [R-NET - Machine Reading Comprehension with Self-matching Networks](https://shagunsodhani.com/papers-I-read/R-NET-Machine-Reading-Comprehension-with-Self-matching-Networks)
+- [ReasoNet - Learning to Stop Reading in Machine Comprehension](https://shagunsodhani.com/papers-I-read/ReasoNet-Learning-to-Stop-Reading-in-Machine-Comprehension)
+- [Principled Detection of Out-of-Distribution Examples in Neural Networks](https://shagunsodhani.com/papers-I-read/Principled-Detection-of-Out-of-Distribution-Examples-in-Neural-Networks)
+- [Ask Me Anything: Dynamic Memory Networks for Natural Language Processing](https://shagunsodhani.com/papers-I-read/Ask-Me-Anything-Dynamic-Memory-Networks-for-Natural-Language-Processing)
+- [One Model To Learn Them All](https://shagunsodhani.com/papers-I-read/One-Model-To-Learn-Them-All)
+- [Two/Too Simple Adaptations of Word2Vec for Syntax Problems](https://shagunsodhani.com/papers-I-read/Two-Too-Simple-Adaptations-of-Word2Vec-for-Syntax-Problems)
+- [A Decomposable Attention Model for Natural Language Inference](https://shagunsodhani.com/papers-I-read/A-Decomposable-Attention-Model-for-Natural-Language-Inference)
+- [A Fast and Accurate Dependency Parser using Neural Networks](https://shagunsodhani.com/papers-I-read/A-Fast-and-Accurate-Dependency-Parser-using-Neural-Networks)
+- [Neural Module Networks](https://shagunsodhani.com/papers-I-read/Neural-Module-Networks)
+- [Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering](https://shagunsodhani.com/papers-I-read/Making-the-V-in-VQA-Matter-Elevating-the-Role-of-Image-Understanding-in-Visual-Question-Answering)
+- [Conditional Similarity Networks](https://shagunsodhani.com/papers-I-read/Conditional-Similarity-Networks)
+- [Simple Baseline for Visual Question Answering](https://shagunsodhani.com/papers-I-read/Simple-Baseline-for-Visual-Question-Answering)
+- [VQA: Visual Question Answering](https://shagunsodhani.com/papers-I-read/VQA-Visual-Question-Answering)
+- [Learning to Generate Reviews and Discovering Sentiment](https://gist.github.com/shagunsodhani/634dbe1aa678188399254bb3d0078e1d)
+- [Seeing the Arrow of Time](https://gist.github.com/shagunsodhani/828d8de0034a350d97738bbedadc9373)
+- [End-to-end optimization of goal-driven and visually grounded dialogue systems](https://gist.github.com/shagunsodhani/bbbc739e6815ab6217e0cf0a8f706786)
+- [GuessWhat?! Visual object discovery through multi-modal dialogue](https://gist.github.com/shagunsodhani/2418238e6aefd7b1e8c922cda9e10488)
+- [Semantic Parsing via Paraphrasing](https://gist.github.com/shagunsodhani/93c96d7dd0488d0d00bd7078889dd6f6)
+- [Traversing Knowledge Graphs in Vector Space](https://gist.github.com/shagunsodhani/e8e6213906ec2642f27b1aca3a6201c6)
+- [PPDB: The Paraphrase Database](https://gist.github.com/shagunsodhani/fa1f387f084355dfafdf7550b1899af6)
+- [NewsQA: A Machine Comprehension Dataset](https://gist.github.com/shagunsodhani/c47f0d5c1dfe60ce5da0dd8241e506ea)
+- [A Persona-Based Neural Conversation Model](https://gist.github.com/shagunsodhani/8ad464e7d0ea4c7c6ed5189ac4e44095)
+- [“Why Should I Trust You?” Explaining the Predictions of Any Classifier](https://gist.github.com/shagunsodhani/bd744ab6c17a2289ca139ea586d1d65e)
+- [Conditional Generative Adversarial Nets](https://gist.github.com/shagunsodhani/5d726334de3014defeeb701099a3b4b3)
+- [Addressing the Rare Word Problem in Neural Machine Translation](https://gist.github.com/shagunsodhani/a18fe14b74c7292129c6c5ecb37f33b5)
+- [Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models](https://gist.github.com/shagunsodhani/d32e665b27696ce0436c79174a136410)
+- [Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank](https://gist.github.com/shagunsodhani/6ca136088f58d24f7b08056ec8b97595)
+- [Improving Word Representations via Global Context and Multiple Word Prototypes](https://gist.github.com/shagunsodhani/1be86a9bcbd7f120ce55994dcd932bbf)
+- [Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation](https://gist.github.com/shagunsodhani/9dccec626e68e495fd4577ecdca36b7b)
+- [Skip-Thought Vectors](https://gist.github.com/shagunsodhani/4a4eb32de8cabf21bda9a4ada15c46e8)
+- [Deep Convolutional Generative Adversarial Nets](https://gist.github.com/shagunsodhani/aa79796c70565e3761e86d0f932a3de5)
+- [Generative Adversarial Nets](https://gist.github.com/shagunsodhani/1f9dc0444142be8bd8a7404a226880eb)
+- [A Roadmap towards Machine Intelligence](https://gist.github.com/shagunsodhani/9928673525b1713c2d41fd0fac38f81f)
+- [Smart Reply: Automated Response Suggestion for Email](https://gist.github.com/shagunsodhani/da411f15b71ed6a664f9d5ac46409b42)
+- [Convolutional Neural Network For Sentence Classification](https://gist.github.com/shagunsodhani/9ae6d2364c278c97b1b2f4ec53255c56)
+- [Conditional Image Generation with PixelCNN Decoders](https://gist.github.com/shagunsodhani/3cc7066ce7de051d769908b8fab11990)
+- [Pixel Recurrent Neural Networks](https://gist.github.com/shagunsodhani/e741ebd5ba0e0fc0f49d7836e30891a7)
+- [Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps](https://gist.github.com/shagunsodhani/f48da7f77418aa22751ffed115779126)
+- [Bag of Tricks for Efficient Text Classification](https://gist.github.com/shagunsodhani/432746f15889f7f4a798bf7f9ec4b7d8)
+- [GloVe: Global Vectors for Word Representation](https://gist.github.com/shagunsodhani/efea5a42d17e0fcf18374df8e3e4b3e8)
+- [SimRank: A Measure of Structural-Context Similarity](https://gist.github.com/shagunsodhani/6329486212643fd61f58a5a3eb5abb3c)
+- [How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation](https://gist.github.com/shagunsodhani/f05748b6339ceff26420ceecfc79d58d)
+- [Neural Generation of Regular Expressions from Natural Language with Minimal Domain Knowledge](https://gist.github.com/shagunsodhani/004d803bc021f579d4aa3b24cec5b994)
+- [WikiReading : A Novel Large-scale Language Understanding Task over Wikipedia](https://gist.github.com/shagunsodhani/2788ac9dbcac5523cb8b2d0a3d70f2d2)
+- [WikiQA: A challenge dataset for open-domain question answering](https://gist.github.com/shagunsodhani/7cf3677ff2b0028a33e6702fbd260bc5)
+- [Teaching Machines to Read and Comprehend](https://gist.github.com/shagunsodhani/a863eb099bb7a1ab4831cd37bffffb04)
+- [Evaluating Prerequisite Qualities for Learning End-to-end Dialog Systems](https://gist.github.com/shagunsodhani/5e7c40f61c18502eec2809e5cf1ead6b)
+- [Recurrent Neural Network Regularization](https://gist.github.com/shagunsodhani/d66245692b276cd0b6dcbaf43e4211db)
+- [Deep Math: Deep Sequence Models for Premise Selection](https://gist.github.com/shagunsodhani/d8387256f2bb08f39509600f9d7db498)
+- [A Neural Conversational Model](https://gist.github.com/shagunsodhani/ec6835964df0e49fdef0459c8b334b94)
+- [Key-Value Memory Networks for Directly Reading Documents](https://gist.github.com/shagunsodhani/a5e0baa075b4a917c0a69edc575772a8)
+- [Advances In Optimizing Recurrent Networks](https://gist.github.com/shagunsodhani/75dc31e3c7999ad4a1edf4f289deaa88)
+- [Query Regression Networks for Machine Comprehension](https://gist.github.com/shagunsodhani/93caa283af3c151372f4be86ed4c4b99)
+- [Sequence to Sequence Learning with Neural Networks](https://gist.github.com/shagunsodhani/a2915921d7d0ac5cfd0e379025acfb9f)
+- [The Difficulty of Training Deep Architectures and the Effect of Unsupervised Pre-Training](https://gist.github.com/shagunsodhani/e3608ccf262d6e5a6b537128c917c92https://gist.github.com/shagunsodhani/bbbc739e6815ab6217e0cf0a8f706786c)
+- [Question Answering with Subgraph Embeddings](https://gist.github.com/shagunsodhani/b65e299ff5f79a4f9da4a2e9281a0676)
+- [Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks](https://gist.github.com/shagunsodhani/12691b76addf149a224c24ab64b5bdcc)
+- [Visualizing Large-scale and High-dimensional Data](https://gist.github.com/shagunsodhani/6c267cf6122399e9be36491a2f510641)
+- [Visualizing Data using t-SNE](https://gist.github.com/shagunsodhani/2153e01d026712ac94a2b4928a2dbf3e)
+- [Curriculum Learning](https://gist.github.com/shagunsodhani/7e4e1c9817c46e3cb1932f62aac8806b)
+- [End-To-End Memory Networks](https://gist.github.com/shagunsodhani/17881da05d9ee1f6539b2baa8067a6ef)
+- [Memory Networks](https://gist.github.com/shagunsodhani/c7a03a47b3d709e7c592fa7011b0f33e)
+- [Learning To Execute](https://gist.github.com/shagunsodhani/b44b29b86cdfe1b6bae4286253f76350)
+- [Distributed GraphLab: A Framework for Machine Learning and Data Mining in the Cloud](https://gist.github.com/shagunsodhani/1bb05a7134c27cffa1e2f57dc6b1c136)
+- [Large Scale Distributed Deep Networks](https://gist.github.com/shagunsodhani/5733fffe6b1a268998bd93f29ec9fbeb)
+- [Efficient Estimation of Word Representations in Vector Space](https://gist.github.com/shagunsodhani/176a283e2c158a75a0a6)
+- [Regularization and variable selection via the elastic net](https://gist.github.com/shagunsodhani/1cd5d136c8ca30432de5)
+- [Fractional Max-Pooling](https://gist.github.com/shagunsodhani/ccfe3134f46fd3738aa0)
+- [TAO: Facebook’s Distributed Data Store for the Social Graph](https://gist.github.com/shagunsodhani/1c91987c2a4a098fa9f1)
+- [Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift](https://gist.github.com/shagunsodhani/4441216a298df0fe6ab0)
+- [The Unified Logging Infrastructure for Data Analytics at Twitter](https://gist.github.com/shagunsodhani/0083f8a2d276e026b15c)
+- [A Few Useful Things to Know about Machine Learning](https://gist.github.com/shagunsodhani/5c2cdfc269bf8aa50b72)
+- [Hive – A Petabyte Scale Data Warehouse Using Hadoop](https://gist.github.com/shagunsodhani/b0651ade0dc39aeb7cfd)
+- [Kafka: a Distributed Messaging System for Log Processing](https://medium.com/@shagun/notes-about-kafka-cc6c1b5c5025)
+- [Power-law distributions in Empirical data](https://github.com/shagunsodhani/powerlaw/blob/master/paper/README.md)
+- [Pregel: A System for Large-Scale Graph Processing](https://gist.github.com/shagunsodhani/af9677bdc79bb34be698)
+- [GraphX: Unifying Data-Parallel and Graph-Parallel Analytics](https://gist.github.com/shagunsodhani/c72bc1928aeef40280c9)
+- [Pig Latin: A Not-So-Foreign Language for Data Processing](https://medium.com/@shagun/pig-latin-e840ac23db93)
+- [Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing](https://medium.com/@shagun/resilient-distributed-datasets-97c28c3a9411)
+- [MapReduce: Simplified Data Processing on Large Clusters](https://medium.com/@shagun/mapreduce-1c88f8a7c3d2)
+- [BigTable: A Distributed Storage System for Structured Data](https://medium.com/@shagun/bigtable-bf580262f030)
+- [Spark SQL: Relational Data Processing in Spark](https://medium.com/@shagun/spark-sql-68a6fac271fe)
+- [Spark: Cluster Computing with Working Sets](https://medium.com/@shagun/spark-8ca626d55d21)
+- [Fast Data in the Era of Big Data: Twitter’s Real-Time Related Query Suggestion Architecture](https://medium.com/@shagun/fast-data-in-the-era-of-big-data-e6208e6d3575)
+- [Scaling Memcache at Facebook](https://medium.com/@shagun/scaling-memcache-at-facebook-1ba77d71c082)
+- [Dynamo: Amazon’s Highly Available Key-value Store](https://medium.com/@shagun/dynamo-9665c22a1ddb)
+- [f4 : Facebook's Warm BLOB Storage System](https://medium.com/@shagun/f4-cba2f141cb0c)
+- [A Theoretician’s Guide to the Experimental Analysis of Algorithms](https://medium.com/@shagun/dos-and-dont-s-of-research-fe33322c7aff)
+- [Cuckoo Hashing](https://medium.com/@shagun/cuckoo-hashing-eb160dfab804)
+- [Never Ending Learning](https://medium.com/@shagun/never-ending-learning-e7b78006e713)
diff --git a/_site/assets/BatchNormalization/eq1.png b/_site/assets/BatchNormalization/eq1.png
new file mode 100755
index 00000000..d4620aff
Binary files /dev/null and b/_site/assets/BatchNormalization/eq1.png differ
diff --git a/_site/assets/BatchNormalization/eq2.png b/_site/assets/BatchNormalization/eq2.png
new file mode 100755
index 00000000..435b1712
Binary files /dev/null and b/_site/assets/BatchNormalization/eq2.png differ
diff --git a/_site/assets/FewThingsAboutML/BiasVarianceDiagram.png b/_site/assets/FewThingsAboutML/BiasVarianceDiagram.png
new file mode 100755
index 00000000..f5e49fc6
Binary files /dev/null and b/_site/assets/FewThingsAboutML/BiasVarianceDiagram.png differ
diff --git a/_site/assets/HNN/equation1.png b/_site/assets/HNN/equation1.png
new file mode 100644
index 00000000..e0181f93
Binary files /dev/null and b/_site/assets/HNN/equation1.png differ
diff --git a/_site/assets/HNN/equation2.png b/_site/assets/HNN/equation2.png
new file mode 100644
index 00000000..fd422b3e
Binary files /dev/null and b/_site/assets/HNN/equation2.png differ
diff --git a/_site/assets/RNTN/MVRNN.png b/_site/assets/RNTN/MVRNN.png
new file mode 100755
index 00000000..99d9100d
Binary files /dev/null and b/_site/assets/RNTN/MVRNN.png differ
diff --git a/_site/assets/RNTN/P1RNTN.png b/_site/assets/RNTN/P1RNTN.png
new file mode 100755
index 00000000..5afdcbf2
Binary files /dev/null and b/_site/assets/RNTN/P1RNTN.png differ
diff --git a/_site/assets/RNTN/P2RNTN.png b/_site/assets/RNTN/P2RNTN.png
new file mode 100755
index 00000000..1f99c784
Binary files /dev/null and b/_site/assets/RNTN/P2RNTN.png differ
diff --git a/_site/assets/RNTN/ParseTreeMVRNN.png b/_site/assets/RNTN/ParseTreeMVRNN.png
new file mode 100755
index 00000000..c2c18daf
Binary files /dev/null and b/_site/assets/RNTN/ParseTreeMVRNN.png differ
diff --git a/_site/assets/RNTN/RNN.png b/_site/assets/RNTN/RNN.png
new file mode 100755
index 00000000..46afade1
Binary files /dev/null and b/_site/assets/RNTN/RNN.png differ
diff --git a/_site/assets/RNTN/RNNModels.png b/_site/assets/RNTN/RNNModels.png
new file mode 100755
index 00000000..c2b00f52
Binary files /dev/null and b/_site/assets/RNTN/RNNModels.png differ
diff --git a/_site/assets/Swish/plot.png b/_site/assets/Swish/plot.png
new file mode 100644
index 00000000..802cd5bf
Binary files /dev/null and b/_site/assets/Swish/plot.png differ
diff --git a/_site/assets/topk/eq1.png b/_site/assets/topk/eq1.png
new file mode 100644
index 00000000..c2dfbbad
Binary files /dev/null and b/_site/assets/topk/eq1.png differ
diff --git a/_site/assets/topk/eq2.png b/_site/assets/topk/eq2.png
new file mode 100644
index 00000000..4e28741a
Binary files /dev/null and b/_site/assets/topk/eq2.png differ
diff --git a/_site/site/2017/04/27/VQA-Visual-Question-Answering.html b/_site/site/2017/04/27/VQA-Visual-Question-Answering.html
new file mode 100644
index 00000000..36f3c864
--- /dev/null
+++ b/_site/site/2017/04/27/VQA-Visual-Question-Answering.html
@@ -0,0 +1,106 @@
+
Problem Statement
+
+
+
+
Given an image and a free-form, open-ended, natural language question (about the image), produce the answer for the image.
The authors organise an annual challenge and workshop to discuss the state-of-the-art methods and best practices in this domain.
+
Interestingly, the second version is starting on 27th April 2017 (today).
+
+
+
Benefits over tasks like image captioning:
+
+
+
Simple, n-gram statistics based methods are not sufficient.
+
Requires the system to blend in different aspects of knowledge - object detection, activity recognition, commonsense reasoning etc.
+
Since only short answers are expected, evaluation is easier.
+
+
+
Dataset
+
+
+
Created a new dataset of 50000 realistic, abstract images.
+
Used AMT to crowdsource the task of collecting questions and answers for MS COCO dataset (>200K images) and abstract images.
+
Three questions per image and ten answers per question (along with their confidence) were collected.
+
The entire dataset contains over 760K questions and 10M answers.
+
The authors also performed an exhaustive analysis of the dataset to establish its diversity and to explore how the content of these question-answers differ from that of standard image captioning datasets.
+
+
+
Highlights of data collection methodology
+
+
+
Emphasis on questions that require an image, and not just common sense, to be answered correctly.
+
Workers were shown previous questions when writing new questions to increase diversity.
+
Answers collected from multiple users to account for discrepancies in answers by humans.
+
Two modalities supported:
+
+
Open-ended - produce the answer
+
multiple-choice - select from a set of options provided (18 options comprising of popular, plausible, random and ofc correct answer)
+
+
+
+
+
Highlights from data analysis
+
+
+
Most questions range from four to ten words while answers range from one to three words.
+
Around 40% questions are “yes/no” questions.
+
Significant (>80%) inter-human agreement for answers.
+
The authors performed a study where human evaluators were asked to answer the questions without looking at the images.
+
Further, they performed a study where evaluators were asked to label if a question could be answered using common sense and what was the youngest age group, they felt, could answer the question.
+
The idea was to establish that a sufficient number of questions in the dataset required more than just common sense to answer.
+
+
+
Baseline Models
+
+
+
random selection
+
prior (“yes”) - always answer as yes.
+
per Q-type prior - pick the most popular answer per question type.
+
nearest neighbor - find the k nearest neighbors for the given (image, question) pair.
+
+
+
Methods
+
+
+
+
2-channel model (using vision and language models) followed by softmax over (K = 1000) most frequent answers.
+
+
Image Channel
+
+
I - Used last hidden layer of VGGNet to obtain 4096-dim image embedding.
+
norm I - : l2 normalized version of I.
+
+
+
Question Channel
+
+
BoW Q - Bag-of-Words representation for the questions using the top 1000 words plus the top 1- first, second and third words of the questions.
+
LSTM Q - Each word is encoded into 300-dim vectors using fully connected + tanh non-linearity. These embeddings are fed to an LSTM to obtain 1024d-dim embedding.
+
Deeper LSTM Q - Same as LSTM Q but uses two hidden layers to obtain 2048-dim embedding.
+
+
+
Multi-Layer Perceptron (MLP) - Combine image and question embeddings to obtain a single embedding.
+
+
BoW Q + I method - concatenate BoW Q and I embeddings.
+
LSTM Q + I, deeper LSTM Q + norm I methods - image embedding transformed to 1024-dim using a FC layer and tanh non-linearity followed by element-wise multiplication of image and question vectors.
+
+
+
Pass combined embedding to an MLP - FC neural network with 2 hidden layers (1000 neurons and 0.5 dropout) with tanh, followed by softmax.
+
Cross-entropy loss with VGGNet parameters frozen.
+
+
+
Results
+
+
+
Deeper LSTM Q + norm I is the best model with 58.16% accuracy on open-ended dataset and 63.09% on multiple-choice but far behind the human evaluators (>80% and >90% respectively).
+
The best model performs well for answers involving common visual objects but performs poorly for answers involving counts.
+
Vision only model performs even worse than the model which always produces “yes” as the answer.
+
diff --git a/_site/site/2017/04/28/Simple-Baseline-for-Visual-Question-Answering.html b/_site/site/2017/04/28/Simple-Baseline-for-Visual-Question-Answering.html
new file mode 100644
index 00000000..049ba2b0
--- /dev/null
+++ b/_site/site/2017/04/28/Simple-Baseline-for-Visual-Question-Answering.html
@@ -0,0 +1,34 @@
+
Problem Statement
+
+
+
VQA Task: Given an image and a free-form, open-ended, natural language question (about the image), produce the answer for the image.
+
The paper attempts to fine tune the simple baseline method of Bag-of-Words + Image features (iBOWIMG) to make it competitive against more sophisticated LSTM models.
VQA modelled as a classification task where the system learns to choose among one of the top k most prominent answers.
+
Text Features - Convert input question to a one-hot vector and then transform to word vectors using a word embedding.
+
Image Features - Last layer activations from GoogLeNet.
+
Text features are concatenated with image features and fed into a softmax.
+
Different learning rates and weight clipping for word embedding layer and softmax layer with the learning rate for embedding layer much higher than that of softmax layer.
+
+
+
Results
+
+
+
iBOWIMG model reports an accuracy of 55.89% for Open-ended questions and 61.97% for Multiple-Choice questions which is comparable to the performance of other, more sophisticated models.
+
+
+
Interpretation of the model
+
+
+
Since the model is very simple, it is possible to interpret the model to know what exactly is the model learning. This is the greatest strength of the paper even though the model is very simple and naive.
+
The model attempts to memorise the correlation between the answer class and the informative words (in the question) and image features.
+
Question words generally can influence the answer given the bias in images occurring in COCO dataset.
+
Given the simple linear transformation being used, it is possible to quantify the importance of each single words (in the question) to the answer.
+
The paper uses the Class Activation Mapping (CAM) approach (which uses the linear relation between softmax and final image feature map) to highlight the informative image regions relevant to the predicted answer.
+
While the results reported by the paper are not themselves so significant, the described approach provides a way to interpret the strengths and weakness of different VQA datasets.
+
diff --git a/_site/site/2017/05/07/Conditional-Similarity-Networks.html b/_site/site/2017/05/07/Conditional-Similarity-Networks.html
new file mode 100644
index 00000000..3d9c83f2
--- /dev/null
+++ b/_site/site/2017/05/07/Conditional-Similarity-Networks.html
@@ -0,0 +1,103 @@
+
Problem Statement
+
+
+
A common way of measuring image similarity is to embed them into feature spaces where distance acts as a proxy for similarity.
+
But this feature space can capture one (or a weighted combination) of the many possible notions of similarity.
+
What if contracting notions of similarity could be captured at the same time - in terms of semantically distinct subspaces.
+
The paper proposes a new architecture called as Conditional Similarity Networks (CSNs) which learns a disentangled embedding such that the features, for different notions of similarity, are encoded into separate dimensions.
+
It jointly learns masks (or feature extractors) that select and reweights relevant dimensions to induce a subspace that encodes a specific notion of similarity.
Given an image, x, learn a non-linear feature embedding f(x) such that for any 2 images x1 and x2, the euclidean distance between f(x1) and f(x2) reflects their similarity.
+
+
+
Conditional Similarity Triplets
+
+
+
Given a triplet of images (x1, x2, x3) and a condition c (the notion of similarity), an oracle (say crowd) is used to determmine if x1 is more similar to x2 or x3 as per the given criteria c.
+
In general, for images i, j, l, the triplet t is ordered {i, j, l | c} if i is more similar to j than l.
+
+
+
Learning From Triplets
+
+
+
Define a loss function LT() to model the similarity structure over the triplets.
+
LT(i, j, l) = max{0, D(i, j) - D(i, l) + h} where D is the euclidean distance function and h is the similarity scalar margin to prevent trivial solutions.
+
To model conditional similarities, masks m are defined as m = σ(β) where σ is the RELU unit and β is a set of parameters to be learnt.
+
mc denotes the selection of the c-th mask column from feature vector. It thus acts as an element-wise gating function which selects the relevant dimensions of the embedding to attend to a particular similarity concept.
+
The euclidean function D now computes the masked distance (f(i, c)mc) between the two given images.
+
Two regularising terms are also added - L2 norm for D and L1 norm for m.
+
+
+
Experiments
+
+
Datasets
+
+
+
Fonts dataset by Bernhardsson
+
+
3.1 million 64 by 64-pixel grey scale images.
+
+
+
Zappos50k shoe dataset
+
+
Contains 50,000 images of individual richly annotated shoes.
+
Characteristics of interest:
+
+
Type of the shoes (i.e., shoes, boots, sandals or slippers)
+
Suggested gender of the shoes (i.e., for women, men, girls or boys)
+
Height of the shoes’ heels (0 to 5 inches)
+
Closing mechanism of the shoes (buckle, pull on, slip on, hook and loop or laced up)
+
+
+
+
+
+
+
Models
+
+
+
Initial model for the experiments is a ConvNet pre-trained on ImageNet
+
Standard Triplet Network
+
+
Learn from all available triplets jointly as if they have the same notion of similarity.
+
+
+
Set of Task Specific Triplet Networks
+
+
Train n separate triplet networks such that each is trained on a single notion of similarity.
In this version, only the convolutional filters and the embedding is learnt and masks are predefined to be disjoint.
+
Aims to learn a fully disjoint embedding.
+
+
+
Conditional Similarity Networks - learned masks
+
+
Learns all the components - conv filters, embedding and the masks.
+
+
+
Refer paper for details on hyperparameters.
+
+
+
Results
+
+
+
Visual exploration of the learned subspaces (t-sne visualisation) show that network successfully disentangles different features in the embedded vector space.
+
The learned masks are very sparse and share dimensions. This shows that CSNs may learn to only use the required number of dimensions thereby doing away with the need of picking the right size of embedding.
+
Order of performance:
+
+
CSNs with learned masks > CSNs with fixed masks > Task-specific networks > standard triplet network.
+
Though CSNs with learned masks require more training data.
+
+
+
CSNs also outperform Standard Triplet Network when used as off the shelf features for (brand) classification task and is very close to the performance of ResNet trained on ImageNet.
+
This shows that while CSN retained most of the information in the original network, the training mechanism of Standard Triplet Network hurts the underlying conv features and their generalising capability
+
diff --git a/_site/site/2017/05/14/Making-the-V-in-VQA-Matter-Elevating-the-Role-of-Image-Understanding-in-Visual-Question-Answering.html b/_site/site/2017/05/14/Making-the-V-in-VQA-Matter-Elevating-the-Role-of-Image-Understanding-in-Visual-Question-Answering.html
new file mode 100644
index 00000000..f1e7cfb1
--- /dev/null
+++ b/_site/site/2017/05/14/Making-the-V-in-VQA-Matter-Elevating-the-Role-of-Image-Understanding-in-Visual-Question-Answering.html
@@ -0,0 +1,38 @@
+
Problem Statement
+
+
+
Standard VQA models benefit from the inherent bias in the structure of the world and the language of the question.
+
For example, if the question starts with “Do you see a …”, it is more likely to be “yes” than “no”.
+
To truly assess the capability of any VQA system, we need to have evaluation tasks that require the use of both the visual and the language modality.
+
The authors present a balanced version of VQA dataset where each question in the dataset is associated with a pair of similar images such that the same question would give different answers on the two images.
+
The proposed data collection procedure enables the authors to develop a novel interpretable model which, given an image and a question, identifies an image that is similar to the original image but has a different answer to the same question thereby building trust for the system.
Given an (image, question, answer) triplet (I, Q, A) from the VQA dataset, a human worker (on AMT) is asked to identify an image I’ which is similar to I but for which the answer to question Q is A’ (different from A).
+
To facilitate the search for I’, the worker is shown 24 nearest-neighbor images of I (based on VGGNet features) and is asked to choose the most similar image to I, for which Q makes sense and answer for Q is different than A. In case none of the 24 images qualifies, the worker may select “not possible”.
+
In the second round, the workers were asked to answer Q for I’.
+
This 2-stage protocol results in a significantly more balanced dataset than the previous dataset.
+
+
+
Observation
+
+
+
State-of-the-art models trained on unbalanced VQA dataset perform significantly worse on the new, balanced dataset indicating that those models benefitted from the language bias in the older dataset.
+
Training on balanced dataset improves performance on the unbalanced dataset.
+
Further, the VQA model, trained on the balanced dataset, learns to differentiate between otherwise similar images.
+
+
+
Counter-example Explanations
+
+
+
Given an image and a question, the model not only answers the question, it also provides an image (from the k nearest neighbours of I, based on VGGNet features) which is similar to the input image but for which the model would have given different answer for the same image.
+
Supervising signal is provided by the data collection procedure where humans pick the image I’ from the same set of candidate images.
+
For each image in the candidate set, compute the inner product of question-image embedding and answer embedding.
+
The K inner product values are passed through a fully connected layer to generate K scores.
+
Trained with pairwise hinge ranking loss so that the score of the human picked image is higher than the score of all other images by a margin of M (hyperparameter).
+
The proposed explanation model achieves a recall@5 of 43.49%
+
diff --git a/_site/site/2017/05/23/Neural-Module-Networks.html b/_site/site/2017/05/23/Neural-Module-Networks.html
new file mode 100644
index 00000000..4cc6246c
--- /dev/null
+++ b/_site/site/2017/05/23/Neural-Module-Networks.html
@@ -0,0 +1,74 @@
+
Introduction
+
+
+
For the task of Visual Question Answering, decompose a question into its linguistic substructures and train a neural network module for each substructure.
+
Jointly train the modules and dynamically compose them into deep networks which can learn to answer the question.
+
Start by analyzing the question and decide what logical units are needed to answer the question and what should be the relationship between them.
+
The paper also introduces a new dataset for Visual Question Answering which has challenging, highly compositional questions about abstract shapes.
The system described in the paper uses arc-standard system (a greedy, transition-based dependency parsing system).
+
Words, POS tags and arc labels are represented as d dimensional vectors.
+
Sw, St, Sl denote the set of words, POS and labels respectively.
+
Neural network takes as input selected words from the 3 sets and uses a single hidden layer followed by Softmax which models the different actions that can be chosen by the arc-standard system.
+
Uses a cube activation function to allow interaction between features coming from the set of words, POS and labels in the first layer itself. These features come from different embeddings and are not related as such.
+
Using separate embedding for POS tags and labels allow for capturing aspects like NN (singular noun) should be closer to NNS (plural noun) than DT (determiner).
+
Input to the network contains words on the stack and buffer and their left and right children (read upon transition-based parsing), their labels and corresponding arc labels.
+
Output generated by the system is the action to be taken (transition to be performed) when reading each word in the input.
+
This sequential and deterministic nature of the input-output mapping allows the problem to be modelled as a supervised learning problem and a cross entropy loss can be used.
+
L2-regularization term is also added to the loss.
+
During inference, a greedy decoding strategy is used and transition with the highest score is chosen.
+
The paper mentions a pre-computation trick where matrix computation of most frequent top 10000 words is performed beforehand and cached.
+
+
+
Experiments
+
+
+
Dataset
+
+
English Penn Treebank (PTB)
+
Chinese Penn Treebank (CTB)
+
+
+
Two dependency representations used:
+
+
CoNLL Syntactic Dependencies (CD)
+
Stanford Basic Dependencies (SD)
+
+
+
Metrics:
+
+
Unlabeled Attached Scores (UAS)
+
Labeled Attached Scores (LAS)
+
+
+
Benchmarked against:
+
+
Greedy arc-eager parser
+
Greedy arc-standard parser
+
Malt-Parser
+
MSTParser
+
+
+
Results
+
+
The system proposed in the paper outperforms all other parsers in both speed and accuracy.
+
+
+
+
+
Analysis
+
+
+
Cube function gives a 0.8-1.2% improvement over tanh.
+
Pretained embeddings give 0.7-1.7% improvement over training embeddings from scratch.
+
Using POS and labels gives an improvement of 1.7% and 0.4% respectively.
+
diff --git a/_site/site/2017/06/17/A-Decomposable-Attention-Model-for-Natural-Language-Inference.html b/_site/site/2017/06/17/A-Decomposable-Attention-Model-for-Natural-Language-Inference.html
new file mode 100644
index 00000000..d99ce674
--- /dev/null
+++ b/_site/site/2017/06/17/A-Decomposable-Attention-Model-for-Natural-Language-Inference.html
@@ -0,0 +1,66 @@
+
Introduction
+
+
+
The paper proposes an attention based mechanism to decompose the problem of Natural Language Inference (NLI) into parallelizable subproblems.
+
Further, it uses much fewer parameters as compared to any other model while obtaining state of the art results.
The motivation behind the paper is that the tasks like NLI do not require deep modelling of the sentence structure and comparison of local text substructures followed by aggregation can also work very well
+
+
+
Approach
+
+
+
+
Given two sentences a and b, the model has to predict whether they have an “entailment” relationship, “neutral” relationship or “contradiction” relationship.
+
+
Embed
+
+
All the words are mapped to their corresponding word vector representation. In subsequent steps, “word” refers to the word vector representation of the actual word.
+
+
+
Attend
+
+
For each word i in a and j in b, obtain unnormalized attention weights *e(i, j)=F(i)TF(j) where F is a feed-forward neural network.
+
For i, compute a βi by performing softmax-like normalization of j using e(i, j) as the weight and normalizing for all words j in b.
+
βi captures the subphrase in b that is softly aligned to a.
+
Similarly compute αj for j.
+
+
+
Compare
+
+
Create two set of comparison vectors, one for a and another for b
+
For a, v1, i = G(concatenate(i, βi)).
+
Similarly for b, v2, j = G(concatenate(j, αj))
+
G is another feed-forward neural network.
+
+
+
Aggregate
+
+
Aggregate over the two set of comparison vectors to obtain v1 and v2.
+
Feed the aggregated results through the final classifier layer.
+
Multi-class cross-entropy loss function.
+
+
+
The paper also explains how this representation can be augmented using intra-sentence attention to the model compositional relationship between words.
+
+
+
Computational Complexity
+
+
+
Computationally, the proposed model is asymptotically as good as LSTM with attention.
+
Assuming that dimensionality of word vectors > length of the sentence (reasonable for the given SNLI dataset), the model is asymptotically as good as regular LSTM.
+
Further, the model has the advantage of being parallelizable.
+
+
+
Experiment
+
+
+
On Stanford Natural Language Inference (SNLI) dataset, the proposed model achieves the state of the art results even when it uses an order of magnitude lesser parameters than the next best model.
+
Adding intra-sentence attention further improve the test accuracy by 0.5 percent.
+
+
+
Notes
+
+
+
A similar approach could be tried on paraphrase detection problem as even that problem should not require very deep sentence representation. Quora Duplicate Question Detection Challenege would have been an ideal dataset but it has a lot of out-of-vocabulary information related to named entities which need to be accounted for.
+
diff --git a/_site/site/2017/06/26/Two-Too-Simple-Adaptations-of-Word2Vec-for-Syntax-Problems.html b/_site/site/2017/06/26/Two-Too-Simple-Adaptations-of-Word2Vec-for-Syntax-Problems.html
new file mode 100644
index 00000000..c0c28d97
--- /dev/null
+++ b/_site/site/2017/06/26/Two-Too-Simple-Adaptations-of-Word2Vec-for-Syntax-Problems.html
@@ -0,0 +1,9 @@
+
+
The paper proposes two variants of Word2Vec model so that it may account for syntactic properties of words and perform better on syntactic tasks like POS tagging and dependency parsing.
In the original Skip-Gram setting, the model predicts the 2c words in the context window (c is the size of the context window). But it uses the same set of parameters whether predicting the word next to the centre word or the word farthest away, thus losing all information about the word order.
+
Similarly, the CBOW (Continuous Bas Of Words) model just adds the embedding of all the surrounding words thereby losing the word order information.
+
The paper proposes to use a set of 2c matrices each for a different word in the context window for both Skip-Gram and CBOW models.
+
This simple trick allows for accounting of syntactic properties in the word vectors and improves the performance of dependency parsing task and POS tagging.
+
The downside of using this is that now the model has far more parameters than before which increases the training time and needs a large enough corpus to avoid sparse representation.
+
diff --git a/_site/site/2017/07/01/One-Model-To-Learn-Them-All.html b/_site/site/2017/07/01/One-Model-To-Learn-Them-All.html
new file mode 100644
index 00000000..a06941bd
--- /dev/null
+++ b/_site/site/2017/07/01/One-Model-To-Learn-Them-All.html
@@ -0,0 +1,177 @@
+
+
+
The current trend in deep learning is to design, train and fine tune a separate model for each problem.
+
+
+
Though multi-task models have been explored, they have been trained for problems from the same domain only and no competitive multi-task, multi-modal models have been proposed.
+
+
+
The paper explores the possibility of such a unified deep learning model that can solve different tasks across multiple domains by training concurrently on them.
Small, modality-specific subnetworks (called modality nets) should be used to map input data to a joint representation space and back.
+
+
+
+
The joint representation is to be of variable size.
+
+
+
Different tasks from the same domain share the modality net.
+
+
+
+
+
MultiModel networks should use computational blocks from different domains even if they are not specifically designed for the task at hand.
+
+
+
Eg the paper reports that attention and mixture-of-experts (MOE) layers slightly improve the performance on ImageNet even though they are not explicitly needed.
+
+
+
+
+
Architecture
+
+
+
+
MulitModel Network consists of few, small modality nets, an encoder, I/O mixer and an autoregressive decoder.
+
+
+
Encoder and decoder use the following computational blocks:
+
+
+
+
Convolutional Block
+
+
+
ReLU activations on inputs followed by depthwise separable convolutions and layer normalization.
+
+
+
+
Attention Block
+
+
+
Multihead, dot product based attention mechanism.
+
+
+
+
Mixture-of-Experts (MoE) Block
+
+
+
Consists of simple feed-forward networks (called experts) and a trainable gating network which selects a sparse combination of experts to process the inputs.
1-d waveform over time or 2-d spectrogram operated upon by stack of 8 residual convolution blocks.
+
+
+
+
+
+
+
Tasks
+
+
+
+
WSJ speech corpus
+
+
+
ImageNet dataset
+
+
+
COCO image captioning dataset
+
+
+
WSJ parsing dataset
+
+
+
WMT English-German translation corpus
+
+
+
German-English translation
+
+
+
WMT English-French translation corpus
+
+
+
German-French translation
+
+
+
+
Experiments
+
+
+
+
The experimental section is not very rigorous with many details skipped (would probably be added later).
+
+
+
While MultiModel does not beat the state of the art models, it does outperform some recent models.
+
+
+
Jointly trained model performs similar to single trained models on tasks with a lot of data and sometimes outperformed single trained models on tasks with less data (like parsing).
+
+
+
Interestingly, jointly training the model for parsing task and Imagenet tasks improves the performance of parsing task even though the two tasks are seemingly unrelated.
+
+
+
Another experiment was done to evaluate the effect of components (like MoE) on tasks (like Imagenet) which do not explicitly need them. It was observed that either the performance either went down or remained the same when MoE component was removed. This indicates that mixing different components does help to improve performance over multiple tasks.
+
+
+
But this observation is not conclusive as a different combination of say the encoder (that does not use MoE) could achieve better performance than one that does. The paper does not explore possibilities like these.
+
+
diff --git a/_site/site/2017/07/09/Ask-Me-Anything-Dynamic-Memory-Networks-for-Natural-Language-Processing.html b/_site/site/2017/07/09/Ask-Me-Anything-Dynamic-Memory-Networks-for-Natural-Language-Processing.html
new file mode 100644
index 00000000..3d7cc9a8
--- /dev/null
+++ b/_site/site/2017/07/09/Ask-Me-Anything-Dynamic-Memory-Networks-for-Natural-Language-Processing.html
@@ -0,0 +1,153 @@
+
Introduction
+
+
+
+
Dynamic Memory Networks (DMN) is a neural network based general framework that can be used for tasks like sequence tagging, classification, sequence to sequence and question answering requiring transitive reasoning.
+
+
+
The basic idea is that all these tasks can be modelled as question answering task in general and a common architecture could be used for solving them.
DMN takes as input a document(sentence, story, article etc) and a question which is to be answered given the document.
+
+
+
Input Module
+
+
+
+
Concatenate all the sentences (or facts) in the document and encode them by feeding the word embeddings of the text to a GRU.
+
+
+
Each time a sentence ends, extract the hidden representation of the GRU till that point and use as the encoded representation of the sentence.
+
+
+
+
Question Module
+
+
+
Similarly, feed the question to a GRU to obtain its representation.
+
+
+
Episodic Memory Module
+
+
+
+
Episodic memory consists of an attention mechanism and a recurrent network with which it updates its memory.
+
+
+
During each iteration, the network generates an episode e by attending over the representation of the sentences, question and the previous memory.
+
+
+
The episodic memory is updated using the current episode and the previous memory.
+
+
+
Depending on the amount of supervision available, the network may perform multiple passes. eg, in the bAbI dataset, some tasks specify how many passes would be needed and which sentence should be attended to in each pass. For others, a fixed number of passes are made.
+
+
+
Multiple passes allow the network to perform transitive inference.
+
+
+
+
Attention Mechanism
+
+
+
+
Given the input representation c, memory m and question q, produce a scalar score using a 2-layer feedforward network, to use as attention mechanism.
+
+
+
A separate GRU encodes the input representation and weights it by the attention.
+
+
+
Final state of the GRU is fed to the answer module.
+
+
+
+
Answer Module
+
+
+
Use a GRU (initialized with the final state of the episodic module) and at each timestep, feed it the question vector, last hidden state of the same GRU and the previously predicted output.
+
+
+
Training
+
+
+
There are two possible losses:
+
+
Cross-entropy loss of the predicted answer (all datasets)
+
Cross-entropy loss of the attention supervision (for datasets like bAbI)
+
+
+
+
+
Experiments
+
+
Question Answering
+
+
+
+
bAbI Dataset
+
+
+
For most tasks, DMN either outperforms or performs as good as Memory Networks.
+
+
+
For tasks like answering with 2 or 3 supporting facts, DMN lags because of limitation of RNN in modelling long sentences.
+
+
+
+
Text Classification
+
+
+
+
Stanford Sentiment Treebank Dataset
+
+
+
DMN outperforms all the baselines for both binary and fine-grained sentiment analysis.
+
+
+
+
Sequence Tagging
+
+
+
+
Wall Street Journal Dataset
+
+
+
DMN archives state of the art accuracy of 97.56%
+
+
+
+
Observations
+
+
+
+
Multiple passes help in reasoning tasks but not so much for sentiment/POS tags.
+
+
+
Attention in the case of 2-iteration DMN is more focused than attention in 1-iteration DMN.
+
+
+
For 2-iteration DMN, attention in the second iteration focuses only on relevant words and less attention is paid to words that lose their relevance in the context of the entire document.
+
+
+
+
Notes
+
+
+
+
It would be interesting to put some mechanism in place to determine the number of episodes that should be generated before an answer is predicted. A naive way would be to predict the answer after each episode and check if the softmax score of the predicted answer is more than a threshold.
+
+
+
Alternatively, the softmax score and other information could be fed to a Reinforcement Learning (RL) agent which decided if the document should be read again. So every time an episode is generated, the state is passed to the RL agent which decides if another iteration should be performed. If it decides to predict the answer and correct answer is generated, the agent gets a large +ve reward else a large -ve reward.
+
+
+
To discourage unnecessary iterations, a small -ve reward could be given everytime the agent decides to perform another iteration.
+
+
diff --git a/_site/site/2017/07/17/Principled-Detection-of-Out-of-Distribution-Examples-in-Neural-Networks.html b/_site/site/2017/07/17/Principled-Detection-of-Out-of-Distribution-Examples-in-Neural-Networks.html
new file mode 100644
index 00000000..90ce6089
--- /dev/null
+++ b/_site/site/2017/07/17/Principled-Detection-of-Out-of-Distribution-Examples-in-Neural-Networks.html
@@ -0,0 +1,120 @@
+
Problem Statement
+
+
+
+
Given a pre-trained neural network, which is trained using data from some distribution P (referred to as in-distribution data), the task is to detect the examples coming from a distribution Q which is different from P (referred to as out-of-distribution data).
+
+
+
For example, if a digit recognizer neural network is trained using MNIST images, an out-of-distribution example would be images of animals.
+
+
+
Neural Networks can make high confidence predictions even in such cases where the input is unrecognisable or irrelevant.
+
+
+
The paper proposes ODIN which can detect such out-of-distribution examples without changing the pre-trained model itself.
Softmax classifier for the classification network can be written as:
+
+
pi(x, T) = exp(fi(x)/T) / sum(exp(fj(x)/T))
+
+
+
+
where x is the input, p is the softmax probability and T is the temperature scaling parameter.
+
+
+
Increasing T (up to some extent) boosts the performance in distinguishing in-distribution and out-of-distribution examples.
+
+
+
Input Preprocessing
+
+
+
Add small perturbations to the input (image) before feeding it into the network.
+
+
+
x_perturbed = x - ε * sign(-δxlog(py(x, T)))
+
+
+
+
where ε is the perturbation magnitude
+
+
+
The perturbations are such that softmax scores between in-distribution and out-of-distribution samples become separable.
+
+
+
+
+
Given an input (image), first perturb the input.
+
Feed the perturbed input to the network to get its softmax score.
+
If the softmax score is greater than some threshold, mark the input as in-distribution and feed in the unperturbed version of the input to the network for classification.
+
Otherwise, mark the input as out-of-distribution.
+
For detailed mathematical treatment, refer section 6 and appendix in the paper
DenseNet with depth L = 100 and growth rate k = 12
+
Wide ResNet with depth = 28 and widen factor = 10
+
+
+
+
In-Distribution Datasets
+
+
+
CIFAR-10
+
CIFAR-100
+
+
+
+
Out-of-Distribution Datasets
+
+
+
TinyImageNet
+
LSUN
+
iSUN
+
Gaussian Noise
+
+
+
+
Metrics
+
+
+
False Positive Rate at 95% True Positive Rate
+
Detection Error - minimum misclassification probability over all thresholds
+
Area Under the Receiver Operating Characteristic Curve
+
Area Under the Precision-Recall Curve
+
+
+
+
ODIN outperforms the baseline across all datasets and all models by a good margin.
+
+
+
+
Notes
+
+
+
Very simple and straightforward approach with theoretical justification under some conditions.
+
Limited to examples from Vision so can not judge its applicability for NLP tasks.
+
diff --git a/_site/site/2017/07/24/ReasoNet-Learning-to-Stop-Reading-in-Machine-Comprehension.html b/_site/site/2017/07/24/ReasoNet-Learning-to-Stop-Reading-in-Machine-Comprehension.html
new file mode 100644
index 00000000..e2d5240e
--- /dev/null
+++ b/_site/site/2017/07/24/ReasoNet-Learning-to-Stop-Reading-in-Machine-Comprehension.html
@@ -0,0 +1,129 @@
+
Introduction
+
+
+
+
In the domain of machine comprehension, making multiple passes over the given document is an effective technique to extract the relation between the given passage, question and answer.
+
+
+
Unlike previous approaches, which perform a fixed number of passes over the passage, Reasoning Network (ReasoNet) uses reinforcement learning (RL) to decide how many times a document should be read.
+
+
+
Every time the document is read, ReasoNet determines whether the document should be read again or has the termination state been reached. If termination state is reached, the answer module is triggered to generate the answer.
+
+
+
Since the termination state is discrete and not connected to the final output, RL approach is used.
2 synthetic datasets to test if the network can answer questions like “Is node_1 connected to node_12”?
+
+
+
+
+
Architecture
+
+
+
+
Memory (M) - Comprises of the vector representation of the document and the question (encoded using GRU or other RNNs).
+
+
+
Attention - Attention vector (xt) is a function of current internal state st and external memory M. The state and memory are passed through FCs and fed to a similarity function.
+
+
+
Internal State (st) - Vector representation of the question state computed by a RNN using the previous internal state and the attention vector xt
+
+
+
Termination Gate (Tt) - Uses a logistic regression model to generate a random binary variable using the current internal state st.
+
+
Answer - Answer module is triggered when Tt = 1.
+
+
For CNN and DailyMail, a linear projection of GRU outputs is used to predict the answer from candidate entities.
+
For SQuAD, the position of the first and the last word from the answer span are predicted.
+
For Graph Reachability, a logistic regression module is used to predict yes/no as the answer.
+
+
+
+
Reinforcement Learning - For the RL setting, reward at time t, rt = 1 if Tt = 1 and answer is correct. Otherwise rt = 0
+
+
+
Workflow - Given a passage p, query q and answer a:
+
+
+
+
Extract memory using p
+
+
+
Extract initial hidden state using q
+
+
+
ReasoNet executes all possible episodes that can be enumerated by setting an upper limit on the number of passes.
+
+
+
These episodes generate actions and answers that are used to train the ReasoNet.
+
+
+
+
+
Result
+
+
+
+
CNN, DailyMail Corpus
+
+
+
ReasoNet outperforms all the baselines which use fixed number of reasoning steps and could benefit by capturing the word alignment signals between query and passage.
+
+
+
+
SQuAD
+
+
+
At the time of submission, ReasoNet was ranked 2nd on the SQuAD leaderboard and as of 9th July 2017, it is ranked 4th.
+
+
+
+
Graph Reachability Dataset
+
+
+
+
ReasoNet - Standard ReasoNet as described above.
+
+
+
ReasoNet-Last - Use the prediction from the Tmax
+
+
+
ReasoNet > ReasoNet-Last > Deep LSTM Reader
+
+
+
ReasoNet converges faster than ReasoNet-Last indicating that the terminate gate is useful.
+
+
+
+
+
+
+
Notes
+
+
+
As such there is nothing discouraging the ReasoNet to make unnecessary passes over the passage.
+
In fact, the modal value of the number of passes = upper bound on the number of passes.
+
This effect is more prominent for large graph indicating that the ReasoNet may try to play safe by performing extra passes.
+
It would be interesting to see if the network can be discouraged from making unnecessary passed by awarding a small negative reward for each pass.
+
+
+
diff --git a/_site/site/2017/08/07/R-NET-Machine-Reading-Comprehension-with-Self-matching-Networks.html b/_site/site/2017/08/07/R-NET-Machine-Reading-Comprehension-with-Self-matching-Networks.html
new file mode 100644
index 00000000..12467165
--- /dev/null
+++ b/_site/site/2017/08/07/R-NET-Machine-Reading-Comprehension-with-Self-matching-Networks.html
@@ -0,0 +1,90 @@
+
Introduction
+
+
+
+
R-NET is an end-to-end trained neural network model for machine comprehension.
+
+
+
It starts by matching the question and the given passage (using gated attention based RNN) to obtain question-aware passage representation.
+
+
+
Next, it uses a self-matching attention mechanism to refine the passage representation by matching the passage against itself.
+
+
+
Lastly, it uses pointer networks to determine the position of the answer in the passage.
Concatenate the word level and character level embeddings for each word and feed into a bidirectional GRU to obtain question and passage representation.
+
+
+
+
Gated Attention based RNN
+
+
+
+
Given question and passage representation, sentence pair representation is generated via soft-alignment of the words in the question and in the passage.
+
+
+
The newly added gate captures the relation between the question and the current passage word as only some parts of the passage are relevant for answering the given question.
+
+
+
+
+
Self Matching Attention
+
+
+
+
The passage representation obtained so far would not capture most of the context.
+
+
+
So the current representation is matched against itself so as to collect evidence from the entire passage and encode the evidence relevant to the current passage word and question.
+
+
+
+
+
Output Layer
+
+
+
+
Use pointer network (initialized using attention pooling over answer representation) to predict the position of the answer.
+
+
+
Loss function is the sum of negative log probabilities of start and end positions.
+
+
+
+
+
Results
+
+
+
+
R-NET is ranked second on SQuAD Leaderboard as of 7th August, 2017 and achieves best-published results on MS-MARCO dataset.
+
+
+
Using ideas like sentence ranking, using syntax information performing multihop inference and augmenting question dataset (using seqToseq network) do not help in improving the performance.
+
+
+
+
diff --git a/_site/site/2017/08/21/Learning-to-Compute-Word-Embeddings-On-the-Fly.html b/_site/site/2017/08/21/Learning-to-Compute-Word-Embeddings-On-the-Fly.html
new file mode 100644
index 00000000..fe327be6
--- /dev/null
+++ b/_site/site/2017/08/21/Learning-to-Compute-Word-Embeddings-On-the-Fly.html
@@ -0,0 +1,79 @@
+
Introduction
+
+
+
+
Word based language models suffer from the problem of rare or Out of Vocabulary (OOV) words.
+
+
+
Learning representations for OOV words directly on the end task often results in poor representation.
+
+
+
The alternative is to replace all the rare words with a single, unique representation (loss of information) or use character level models to obtain word representations (they tend to miss on the semantic relationship).
+
+
+
The paper proposes to learn a network that can predict the representations of words using auxiliary data (referred to as definitions) such as dictionary definitions, Wikipedia infoboxes, the spelling of the word etc.
+
+
+
The auxiliary data encoders are trained jointly with the end task to ensure that word representations align with the requirements of the end task.
+
+
+
+
Approach
+
+
+
+
Given a rare word w, let d(w) = <x1, x2…> denote its defination where xi are words.
+
+
+
d(w) is fed to a defination reader network f (LSTM) and its last state is used as the defination embedding ed(w)
+
+
+
In case w has multiple definitions, the embeddings are combined using mean pooling.
+
+
+
The approach can be extended to in-vocabulary words as well by using the definition embedding of such words to update their original embeddings.
+
+
+
+
Experiments
+
+
+
Auxiliary data sources
+
+
Word definitions from WordNet
+
Spelling of words
+
+
+
+
The proposed approach was tested on following tasks:
For all the tasks, models using both spelling and dictionary (SD) outperformed the model using just one.
+
+
While SD does not outperform the Glove model (with full vocabulary), it does bridge the performance gap significantly.
+
+
+
Future Work
+
+
+
+
Multi-token words like “San Francisco” are not accounted for now.
+
+
+
The model does not handle the rare words which appear in the definition and just replaces them by the token. Making the model recursive would be a useful addition.
+
+
diff --git a/_site/site/2017/08/27/Pointer-Networks.html b/_site/site/2017/08/27/Pointer-Networks.html
new file mode 100644
index 00000000..b0419516
--- /dev/null
+++ b/_site/site/2017/08/27/Pointer-Networks.html
@@ -0,0 +1,64 @@
+
Introduction
+
+
+
+
The paper introduces a novel architecture that generates an output sequence such that the elements of the output sequence are discrete tokens corresponding to positions in the input sequence.
+
+
+
Such a problem can not be solved using Seq2Seq or Neural Turing Machines as the size of the output softmax is variable (as it depends on the size of the input sequence).
Traditional attention-base sequence-to-sequence models compute an attention vector for each step of the output decoder and use that to blend the individual context vectors of the input into a single, consolidated attention vector. This attention vector is used to compute a fixed size softmax.
+
+
+
In Pointer Nets, the normalized attention vector (over all the tokens in the input sequence) is normalized and treated as the softmax output over the input tokens.
+
+
+
So Pointer Net is a very simple modification of the attention model.
+
+
+
+
Application
+
+
+
+
Any problem where the size of the output depends on the size of the input because of which fixed length softmax is ruled out.
+
+
+
eg combinatorial problems such as planar convex hull where the size of the output would depend on the size of the input.
+
+
+
+
Evaluation
+
+
+
+
The paper considers the following 3 problems:
+
+
+
Convex Hull
+
Delaunay triangulations
+
Travelling Salesman Problem (TSP)
+
+
+
+
Since some of the problems are NP hard, the paper considers approximate solutions whereever the exact solutions are not feasible to compute.
+
+
+
The authors used the exact same architecture and model parameters of all the instances of the 3 problems to show the generality of the model.
+
+
+
The proosed Pointer Nets outperforms LSTMs and LSTMs with attention and can generalise quite well for much larger sequences.
+
+
+
Interestingly, the order in which the inputs are fed to the system affects its performance. The authors discussed this apsect in their subsequent paper titled Order Matters: Sequence To Sequence for Sets
+
+
diff --git a/_site/site/2017/09/22/Refining-Source-Representations-with-Relation-Networks-for-Neural-Machine-Translation.html b/_site/site/2017/09/22/Refining-Source-Representations-with-Relation-Networks-for-Neural-Machine-Translation.html
new file mode 100644
index 00000000..ae052feb
--- /dev/null
+++ b/_site/site/2017/09/22/Refining-Source-Representations-with-Relation-Networks-for-Neural-Machine-Translation.html
@@ -0,0 +1,85 @@
+
Introduction
+
+
+
The paper introduces Relation Network (RN) that refines the encoding representation of the given source document (or sentence).
+
This refined source representation can then be used in Neural Machine Translation (NMT) systems to counter the problem of RNNs forgetting old information.
The RNN encoder-decoder architecture is the standard choice for NMT systems. But the RNNs are prone to forgetting old information.
+
In NMT models, the attention is modeled in the unit of words while the use of phrases (instead of words) would be a better choice.
+
While NMT systems might be able to capture certain relationships between words, they are not explicitly designed to capture such information.
+
+
+
Contributions of the paper
+
+
+
Learn the relationship between the source words using the context (neighboring words).
+
Relation Networks (RNs) build pairwise relations between source words using the representations generated by the RNNs. The RN would sit between the encoder and the attention layer of the encoder-decoder framework thereby keeping the main architecture unaffected.
+
+
+
Relation Network
+
+
+
Neural network which is desgined for relational reasoning.
+
Given a set of inputs * O = o1, …, on *, RN is formed as a composition of inputs:
+ RN(O) = f(sum(g(oi, oj))), f and g are functions used to learn the relations (feed forward networks)
+
g learns how the objects are related hence the name “relation”.
+
Components:
+
+
CNN Layer
+
+
Extract information from the words surrounding the given word (context).
+
The final output of this layer is the sequence of vectors for different kernel width.
+
+
+
Graph Propagation (GP) Layer
+
+
Connect all the words with each other in the form of a graph.
+
Each output vector from the CNN corresponds to a node in the graph and there is an edge between all possible pair of nodes.
+
The information flows between the nodes of the graph in a message passing sort of fashion (graph propagation) to obtain a new set of vectors for each node.
+
+
+
Multi-Layer Perceptron (MLP) Layer
+
+
The representation from the GP Layer is fed to the MLP layer.
+
The layer uses residual connections from previous layers in form of concatenation.
+
+
+
+
+
+
+
Datasets
+
+
+
IWSLT Data - 44K sentences from tourism and travel domain.
+
NIST Data - 1M Chinese-English parallel sentence pairs.
+
+
+
Models
+
+
+
MOSES - Open source translation system - http://www.statmt.org/moses/
+
NMT - Attention based NMT
+
NMT+ - NMT with improved decoder
+
TRANSFORMER - Google’s new NMT
+
RNMT+ - Relation Network integrated with NMT+
+
+
+
Evaluation Metric
+
+
+
case-insensitive 4-gram BLEU score
+
+
+
Observations
+
+
+
As sentences become larger (more than 50 words), RNMT clearly outperforms other baselines.
+
Qualitative evaluation shows that RNMT+ model captures the word alignment better than the NMT+ models.
+
Similarly, NMT+ system tends to miss some information from the source sentence (more so for longer sentences). While both CNNs and RNNs are weak at capturing long-term dependency, using the relation layer mitigates this issue to some extent.
+
diff --git a/_site/site/2017/10/01/Task-Oriented-Query-Reformulation-with-Reinforcement-Learning.html b/_site/site/2017/10/01/Task-Oriented-Query-Reformulation-with-Reinforcement-Learning.html
new file mode 100644
index 00000000..42ea0bcc
--- /dev/null
+++ b/_site/site/2017/10/01/Task-Oriented-Query-Reformulation-with-Reinforcement-Learning.html
@@ -0,0 +1,114 @@
+
Introduction
+
+
+
The paper introduces a query reformulation system that rewrites a query to maximise the number of “relevant” documents that are extracted from a given black box search engine.
+
A Reinforcement Learning (RL) agent selects the terms that are to be added to the reformulated query and the rewards are decided on the basis of document recall.
The underlying problem is as follows: when the end user makes a query to a search engine, the engine often relies on word matching techniques to perform retrieval. This means relevant documents could be missed if there is no exactly matching words between the query and the document.
+
This problem can be handled at two levels: First, the search engine itself takes care of query semantics. Alternatively, we assume the search engine to be dumb and instead have a system in place that can improve the original queries (automatic query reformulation).
+
The paper takes the latter approach and expands the original query by adding terms from the set of retrieved documents (pseudo relevance feedback).
+
+
+
Datasets
+
+
+
TREC - Complex Answer Retrieval (TREC-CAR)
+
Jeopardy Q&A dataset
+
Microsoft Academic (MSA) dataset - created by the authors using papers crawled from Microsoft Academic API
+
+
+
Framework
+
+
+
Query Reformulation task is modeled as an RL problem where:
+
+
Environment is the search engine.
+
Actions are whether a word is to be added to the query or not and if yes, then what word is added.
+
Reward is the retrieval accuracy.
+
+
+
The input to the system is a query q0 consisting of a sequence of words w1, …, wn and a candidate term ti with some context words.
+
Candidate terms are all the terms that appear in the original query and the documents retrieved using the query.
+
The words are mapped to vectors and then a fixed size representation is obtained for the sequence using CNN’s or RNNs.
+
Similarly, a representation is obtained for the candidate words by feeding them and their context words to the CNN or RNNs.
+
Finally, a sigmoidal score is computed for all the candidate words.
+
An RNN sequentially applies this model to emit query words till an end token is emitted.
+
Vocabulary is used only from the extracted documents and not the entire vocabulary set, to keep the inference fast.
+
+
+
Training
+
+
+
The model is trained using REINFORCE algorithm which minimizes the Ca = (R − R~) * sum(log(P(t|q))) where R~ is the baseline.
+
Value network minimises Cb = &\alpha(||R-R~||2)
+
Ca and Cb are minimised using SGD.
+
An entropy regulation term is added to prevent the probability distribution from reaching the peak.
+
+
+
Experiments
+
+
Baseline Methods
+
+
+
+
Raw - Original query is fed to the search engine without any modification.
+
+
+
Pseudo-Relevance Feedback (PRF-TFIDF) - The query is expanded using the top-N TF-IDF terms.
+
+
+
PRF-Relevance Model (PRF-RM) - Probability of adding token t to the query q0 is given by P(t|q0) = (1 − λ)P′(t|q0) + λ sum (P(d)P(t|d)P(q0|d))
+
+
+
+
Proposed Methods
+
+
+
Supervised Learning
+
+
Assumes that the query words contribute indepently to the query retrival performace. (Too strong an assumption).
+
A term is marked as relevant if (R(new_query) - R(old_query))/R(old_query) > 0.005
+
+
+
Reinforcement Learning
+
+
RL-RNN/CNN - RL Framework + RNN/CNN to encode the input features.
+
RL-RNN-SEQ - Add a sequential generator.
+
+
+
Metrics
+
+
Recall@K
+
Precision@K
+
Mean Average Precision@K
+
+
+
+
Reward - The paper uses Recall@K as a reward when training the RL-based models with the argument that the “metric has shown to be effective in improving the other metrics as well”, without any justification though.
+
+
+
SL-Oracle - classifier that perfectly selects terms that will increase performance based on the supervised learning approach.
+
+
RL-Oracle - Produces a conservative upper-bound for the performance of the RL Agent. It splits the test data into N subsets and trains an RL agent for each subset. Then, the reward is averaged over all the N subsets.
RL-RNN-SEQ performs slightly worse than RL-RNN but is much faster (as it produces shorter queries).
+
RL-based model benefits from more candidate terms while the classical PRF method quickly saturates.
+
+
+
Comments
+
+
+
Interestingly, for each raw query, they carried out the reformulation step just once and not multiple times. The number of times a query is reformulated could also have become a part of the RL framework.
+
diff --git a/_site/site/2017/10/15/Reading-Wikipedia-to-Answer-Open-Domain-Questions.html b/_site/site/2017/10/15/Reading-Wikipedia-to-Answer-Open-Domain-Questions.html
new file mode 100644
index 00000000..c02b439d
--- /dev/null
+++ b/_site/site/2017/10/15/Reading-Wikipedia-to-Answer-Open-Domain-Questions.html
@@ -0,0 +1,74 @@
+
Introduction
+
+
+
+
The paper presents a new machine comprehension dataset for question answering in real life setting (say when interacting with Cortana/Siri).
Existing machine comprehension (MC) datasets are either too small or synthetic (with a distribution different from that or real-questions posted by humans). MARCO questions are sampled from real, anonymized user queries.
+
+
+
Most datasets would provide a comparatively small and clean context to answer the question. In MARCO, the context documents (which may or may not contain the answer) are extracted using Bing from real-world documents. As such the questions and the context documents are noisy.
+
+
+
In general, the answer to the questions are restricted to an entity or text span within the document. In case of MARCO, the human judges are encouraged to generate complete sentences as answers.
+
+
+
+
Dataset Description
+
+
+
+
First release consists of 100K questions with the aim of releasing 1M questions in the future releases.
+
+
+
All questions are tagged with segment information.
+
+
+
A subset of questions has multiple answers and another subset has no answers at all.
+
+
+
Each record in the dataset contains the following information:
+
+
+
Query - The actual question
+
Passage - Top 10 contextual passages extracted from web search engine (which may or may not contain the answer to the question).
+
Document URLs - URLs for the top documents (which are the source of the contextual passages).
Accuracy and precision/recall for numeric questions
+
ROGUE-L/paraphrasing aware evaluation framework for long, textual answers.
+
+
+
+
Among generative models, Memory Networks performed better than seq-to-seq.
+
+
+
In the cloze-style test, ReasoNet achieved an accuracy of approx. 59% while Attention Sum Reader achieved an accuracy of approx 55%.
+
+
+
Current QA systems (including the ones using memory and attention) derive their power from supervised data and are very different from how humans do reasoning.
+
+
+
Imagenet dataset pushed the state-of-the-art performance on object classification to beyond human accuracy. Similar was the case with speech recognition dataset from DARPA which led to the advancement of speech recognition. Having a large, diverse and human-like questions dataset is a fundamental requirement to advance the field and the paper aims to provide just the right kind of dataset.
+
+
diff --git a/_site/site/2017/10/22/Swish-A-self-gated-activation-function.html b/_site/site/2017/10/22/Swish-A-self-gated-activation-function.html
new file mode 100644
index 00000000..8eafeb18
--- /dev/null
+++ b/_site/site/2017/10/22/Swish-A-self-gated-activation-function.html
@@ -0,0 +1,45 @@
+
Introduction
+
+
+
+
The paper presents a new activation function called Swish with formulation f(x) = x.sigmod(x) and its parameterised version called Swish-β where f(x, β) = 2x.sigmoid(β.x) and β is a training parameter.
+
+
+
The paper shows that Swish is consistently able to outperform RELU and other activations functions over a variety of datasets (CIFAR, ImageNet, WMT2014) though by small margins only in some cases.
Swish-β can be thought of as a smooth function that interpolates between a linear function and RELU.
+
+
+
Uses self-gating mechanism (that is, it uses its own value to gate itself). Gating generally uses multiple scalar inputs but since self-gating uses a single scalar input, it can be used to replace activation functions which are generally pointwise.
+
+
+
Being unbounded on the x>0 side, it avoids saturation when training is slow due to near 0 gradients.
+
+
+
Being bounded below induces a kind of regularization effect as large, negative inputs are forgotten.
+
+
+
Since the Swish function is smooth, the output landscape and the loss landscape are also smooth. A smooth landscape should be more traversable and less sensitive to initialization and learning rates.
+
+
+
+
Criticism
+
+
+
Swish is much more complicated than ReLU (when weighted against the small improvements that are provided) so it might not end up with as strong an adoption as ReLU.
+
diff --git a/_site/site/2017/10/28/HARP-Hierarchical-Representation-Learning-for-Networks.html b/_site/site/2017/10/28/HARP-Hierarchical-Representation-Learning-for-Networks.html
new file mode 100644
index 00000000..e71db893
--- /dev/null
+++ b/_site/site/2017/10/28/HARP-Hierarchical-Representation-Learning-for-Networks.html
@@ -0,0 +1,55 @@
+
Introduction
+
+
+
+
HARP is an architecture to learn low-dimensional node embeddings by compressing the input graph into smaller graphs.
Given a graph G = (V, E), compute a series of successively smaller (coarse) graphs G0, …, GL. Learn the node representations in GL and successively refine the embeddings for larger graphs in the series.
+
+
+
The architecture is independent of the algorithms used to embed the nodes or to refine the node representations.
+
+
+
Graph coarsening technique that preserves global structure
+
+
+
+
Collapse edges and stars to preserve first and second order proximity.
+
+
+
Edge collapsing - select the subset of E such that no two edges are incident on the same vertex and merge their nodes into a single node and merge their edges as well.
+
+
+
Star collapsing - given star structure, collapse the pairs of neighboring nodes (of the central node).
+
+
+
In practice, first apply star collapsing, followed by edge collapsing.
+
+
+
+
+
Extending node representation from coarse graph to finer graph
+
+
+
+
Lets say node1 and node2 were merged into node12 during coarsening. First copy the representation of node12 into node1, node2.
+
+
+
Additionally, if hierarchical softmax was used, extend the B-tree such that node12 is replaced by 2 child nodes node1 and node2.
+
+
+
Time complexity for HARP + DeepWalk is O(number of walks * |V|) while for HARP + LINE is O(number of iterations * |E|).
+
+
+
The asymptotic complexity remains the same as the HARP-less version for the two cases.
+
+
+
+
+
Multilabel classification task shows that HAR improves all the node embedding technique with gains up to 14%.
+
+
diff --git a/_site/site/2017/11/05/Word-Representations-via-Gaussian-Embedding.html b/_site/site/2017/11/05/Word-Representations-via-Gaussian-Embedding.html
new file mode 100644
index 00000000..4c232c0b
--- /dev/null
+++ b/_site/site/2017/11/05/Word-Representations-via-Gaussian-Embedding.html
@@ -0,0 +1,62 @@
+
Introduction
+
+
+
Existing word embedding models like Skip-Gram, GloVe etc map words to fixed sized vectors in a low dimensional vector space.
+
This fixed point setting cannot capture uncertainty about representation.
+
Further, these fixed point vectors are compared with measures like dot product and cosine similarity which are not suitable for capturing asymmetric properties like textual entailment and inclusion.
+
The paper proposes to learn Gaussian function embeddings (with diagonal covariance) for the word vectors.
+
This way, the words are mapped to soft regions in the embedding space which enables modeling uncertainty and asymmetric properties like inclusion and uncertainty.
KL divergence is used as the asymmetric distance function for comparing the distributions.
+
Unlike the Word2Vec model, the proposed model uses ranking-based loss.
+
+
+
Similarity Measures used
+
+
+
+
Symmetric Similarity
+
+
For two gaussian distributions, Pi and Pj, compute the inner product E(Pi, Pj) as N(0; meani - meanj, sigmai + sigmaj).
+
Compute the gradient of mean and sigma with respect to log(E).
+
+
The resulting loss function can be interpreted as pushing the means closer which encouraging the two gaussians to be more concentrated.
+
+
+
Asymmetric Similarity
+
+
Use KL divergence to encode the context distribution.
+
The benefit over the symmetric setting is that now entailment type relations can also be modeled.
+
For example, a low KL divergence from x to y indicates that y can be encoded as x or that y “entails” x.
+
+
+
Learning
+
+
+
One of the two notions of similarity is chosen and max-margin is used as the loss function.
+
Mean is regularized by adding a simple constraint on the L2-norm.
+
For covariance matrix, the eigenvalues are constrained to lie within a hypercube. This ensures that the positive-definite property of the covariance matrix is maintained while having a constraint on the size.
+
+
+
Observations
+
+
+
Polysemous words have higher variance in their word embeddings as compared to specific words.
+
KL divergence (with diagonal covariance) outperforms other models.
+
Simple tree hierarchies can also be modeled by embedding into the Gaussian space. A Gaussian is created for each node with randomly initialized mean and the same set of embeddings is used for nodes and context.
+
For word similarity benchmarks, embeddings with spherical covariance have a slight edge over embeddings with diagonal covariance and outperform the Skip-Gram model in all the cases.
+
+
+
Future Work
+
+
+
Use combinations of low rank and diagonal matrices for covariances.
+
Improved optimisation strategies.
+
Trying other distributions like Student’s-t distribution.
+
diff --git a/_site/site/2017/11/12/Network-Motifs-Simple-Building-Blocks-of-Complex-Networks.html b/_site/site/2017/11/12/Network-Motifs-Simple-Building-Blocks-of-Complex-Networks.html
new file mode 100644
index 00000000..b9df89b0
--- /dev/null
+++ b/_site/site/2017/11/12/Network-Motifs-Simple-Building-Blocks-of-Complex-Networks.html
@@ -0,0 +1,34 @@
+
Introduction
+
+
+
The paper presents the concept of “network motifs” to understand the structural design of a network or a graph.
A network motif is defined as “a pattern of inter-connections occurring in complex networks in numbers that are significantly higher than those in randomized networks”.
+
+
+
In the practical setting, given an input network, we first create randomized networks which have same single node characteristics (like a number of incoming and outgoing edges) as the input network.
+
+
+
The patterns that occur at a much higher frequency in the input graph (than the randomized graphs) are reported as motifs.
+
+
+
More specifically, the patterns for which the probability of appearing in a randomized network an equal or more number of times than in the real network is lower than a cutoff value (say 0.01).
+
+
+
+
Motivation
+
+
+
+
Real-life networks exhibit properties like “small world” property ( the majority of nodes are within a distance of fewer than 7 hops from each other) and “scale-free” property (fraction of nodes having k edges decays as a power-law).
+
+
+
Motifs are one such structural property that is exhibited by networks in biochemistry, neurobiology, ecology, and engineering. Further, motifs shared by graphs of different domains are different which hints at the usefulness of motifs as a fundamental structural property of the graph and relates to the process of evolution of the graph.
+
+
diff --git a/_site/site/2017/11/19/Higher-order-organization-of-complex-networks.html b/_site/site/2017/11/19/Higher-order-organization-of-complex-networks.html
new file mode 100644
index 00000000..9fbc589a
--- /dev/null
+++ b/_site/site/2017/11/19/Higher-order-organization-of-complex-networks.html
@@ -0,0 +1,62 @@
+
Introduction
+
+
+
+
The paper presents a generalized framework for graph clustering (clusters of network motifs) on the basis of higher-order connectivity patterns.
Given a motif M, the framework aims to find a cluster of the set of nodes S such that nodes of S participate in many instances of M and avoid cutting instances of M (that is only a subset of nodes in instances of M appears in S).
+
+
+
Mathematically, the aim is to minimise the motif conductance metric given as cutM(S, S’) / min[volM(S), volM(S’)] where S’ is complement of S, cutM(S, S’) = number of instances of M which have atleast one node from both S and S’ and volM(S) = Number of nodes in instances of M that belong only to S.
+
+
+
Solving the above equation is computationally infeasible and an approximate solution is proposed using eigenvalues and matrices.
+
+
+
The approximate solution is easy to implement, efficient and guaranteed to find clusters that are at most a quadratic factor away from the optimal.
+
+
+
+
Algorithm
+
+
+
+
Given the network and motif M, form a motif adjacency matrix WM where WM(i, j) is the number of instances of M that contains i and j.
+
+
+
Compute spectral ordering of the nodes from normalized motif laplacian matrix.
+
+
+
Compute prefix set of spectral ordering with small motif conductance.
+
+
+
+
Scalability
+
+
+
Worst case O(m1.5), based on experiments O(m1.2) where m is the number of edges.
+
+
+
Advantages
+
+
+
+
Applicable to directed, undirected and weighted graphs (allows for negative edge weights as well).
+
+
+
In case the motif is not known beforehand, the framework can be used to compute significant motifs.
+
+
+
The proposed framework unifies the two fundamental tools of network science (motif analysis and network partitioning) along with some worst-case guarantees for the approximations employed and can be extended to identify higher order modular organization of networks.
+
+
+
diff --git a/_site/site/2017/11/28/Two-Stage-Synthesis-Networks-for-Transfer-Learning-in-Machine-Comprehension.html b/_site/site/2017/11/28/Two-Stage-Synthesis-Networks-for-Transfer-Learning-in-Machine-Comprehension.html
new file mode 100644
index 00000000..49bd9020
--- /dev/null
+++ b/_site/site/2017/11/28/Two-Stage-Synthesis-Networks-for-Transfer-Learning-in-Machine-Comprehension.html
@@ -0,0 +1,98 @@
+
Introduction
+
+
+
The paper proposes a two-stage synthesis network that can perform transfer learning for the task of machine comprehension.
+
+
The problem is the following:
+
+
+
+
We have a domain DS for which we have labelled dataset of question-answer pairs and another domain DT for which we do not have any labelled dataset.
+
+
+
We use the data for domain DS to train SynNet and use that to generate synthetic question-answer pairs for domain DT.
+
+
+
Now we can train a machine comprehension model M on DS and finetune using the synthetic data for DT.
Answer Synthesis - Given a text paragraph, generate an answer.
+
Question Synthesis - Given a text paragraph and an answer, generate a question.
+
+
+
+
+
Answer Synthesis Network
+
+
+
Given the labelled dataset for DS, generate a labelled dataset of <word, tag> pair such that each word in the given paragraph is assigned one of the 4 tags:
+
+
IOBstart - if it is the starting word of an answer
+
IOBmid - if it is the intermediate word of an answer
+
IOBend - if it is the ending word of an answer
+
IOBnone - if it is not part of any answer
+
+
+
+
For training, map the words to their GloVe embeddings and pass through a Bi-LSTM. Next, pass them through two-FC layers followed by a softmax layer.
+
+
For the target domain DT, all the consecutive word spans where no label is IOBnone are returned as candidate answers.
+
+
+
Question Synthesis Network
+
+
+
+
Given an input paragraph and a candidate answer, Question Synthesis network generates question one word at a time.
+
+
+
Map each word in the paragraph to their GloVe embedding. After the word vector, append a ‘1’ if the word was part of the candidate answer else append a ‘0’.
+
+
+
Feed to a Bi-LSTM network (encoder-decoder) where the decoder conditions on the representation generated by the encoder as well as the question tokens generated so far. Decoding is stopped when “END” token is produced.
+
+
+
The paragraph may contain some named entities or rare words which do not appear in the softmax vocabulary. To account for such words, a copying mechanism is also incorporated.
+
+
+
At each time step, a Pointer Network (CP) and a Vocabulary Predictor (VP) are used to generate probability distribution for the next word and a Latent Predictor Network is used to decide which of the two networks would be used for the prediction.
+
+
+
At inference time, a greedy decoding is used where the most likely predictor is chosen and then the most likely word from that predictor is chosen.
+
+
+
+
Machine Comprehension Model
+
+
+
Given any MC model, first train it over domain DS and then fine-tune using the artificial questions generated using DT.
+
+
+
Implementation Details
+
+
+
+
Data Regularization - There is a need to alternate between mini batches from source and target domain while fine-tuning the MC model.
+
+
+
At inference time, the fine-tuned MC model is used to get the distribution P(i=start) and P(i=end) (corresponding to the likelihood of choosing word I as the starting or ending word for the answer) for all the words and DP is used to find the optimal answer span.
+
+
+
Checkpoint Averaging - Use the different checkpointed models to average the answer likelihood before running DP.
+
+
+
Using the synthetically generated dataset helps to gain a 2% improvement in terms of F-score (from SQuAD -> NewsQA). Using checkpointed models further improves the performance to overall 46.6% F score which closes the gap with respect to the performance of model trained on NewsQA itself (~52.3% F score)
+
+
+
diff --git a/_site/site/2017/12/11/Revisiting-Semi-Supervised-Learning-with-Graph-Embeddings.html b/_site/site/2017/12/11/Revisiting-Semi-Supervised-Learning-with-Graph-Embeddings.html
new file mode 100644
index 00000000..7e8d636c
--- /dev/null
+++ b/_site/site/2017/12/11/Revisiting-Semi-Supervised-Learning-with-Graph-Embeddings.html
@@ -0,0 +1,86 @@
+
Introduction
+
+
+
+
The paper presents a semi-supervised learning framework for graphs where the node embeddings are used to jointly predict both the class labels and neighbourhood context. Usually, graph embeddings are learnt in an unsupervised manner and can not leverage the supervising signal coming from the labelled data.
Given a graph G = (V, E) and xL and xU as feature vectors for labelled and unlabelled nodes and yL as labels for the labelled nodes, the problem is to learn a mapping (classifier) f: x -> y
+
+
+
There are two settings possible:
+
+
+
+
Transductive - Predictions are made only for those nodes which are already observed in the graph at training time.
+
+
+
Inductive - Predictions are made for nodes whether they have been observed in the graph at training time or not.
+
+
+
+
+
+
Approach
+
+
+
+
The general semi-supervised learning loss would be LS + λLU where LS is the supervised learning loss while LU is the unsupervised learning loss.
+
+
+
The unsupervised loss is a variant of the Skip-gram loss with negative edge sampling.
+
+
+
More specifically, first a random walk sequence S is sampled. Then either a positive edge is sampled from S (within a given context distance) or a negative edge is sampled.
+
+
+
The label information is injected by using the label as a context and minimising the distance between the positive edges (edges where the nodes have the same label) and maximising the distance between the negative edges (edges where the nodes have different labels).
+
+
+
+
Transductive Formulation
+
+
+
+
Two separate fully connected networks are applied over the node features and node embeddings.
+
+
+
These 2 representations are then concatenated and fed to a softmax classifier to predict the class label.
+
+
+
+
Inductive Formulation
+
+
+
+
In the inductive setting, it is difficult to obtain the node embeddings at test time. One naive approach is to retrain the network to obtain the embeddings on the previously unobserved nodes but that is inefficient.
+
+
+
The embeddings of node x are parameterized as a function of its input feature vector and is learnt by applying a fully connected neural network on the node feature vector.
+
+
+
This provides a simple way to extend the original approach to the inductive setting.
+
+
+
+
Results
+
+
+
+
The proposed approach is evaluated in 3 settings (text classification, distantly supervised entity extraction and entity classification) and it consistently outperforms approaches that use just node features or node embeddings.
+
+
+
The key takeaway is that the joint training in the semi-supervised setting has several benefits over the unsupervised setting and that using the graph context (in terms of node embeddings) is much more effective than using graph Laplacian-based regularization term.
+
+
diff --git a/_site/site/2017/12/24/PTE-Predictive-Text-Embedding-through-Large-scale-Heterogeneous-Text-Networks.html b/_site/site/2017/12/24/PTE-Predictive-Text-Embedding-through-Large-scale-Heterogeneous-Text-Networks.html
new file mode 100644
index 00000000..efc404a7
--- /dev/null
+++ b/_site/site/2017/12/24/PTE-Predictive-Text-Embedding-through-Large-scale-Heterogeneous-Text-Networks.html
@@ -0,0 +1,97 @@
+
Introduction
+
+
+
+
Unsupervised text embeddings can be generalized for different tasks but they have weaker predictive powers (as compared to end-to-end trained deep learning methods) for any particular task. But the deep learning techniques are expensive and need a large amount of supervised data and a large number of parameters to tune.
+
+
+
The paper introduces Predictive Text Embedding (PTE) - a semi-supervised approach which learns an effective low dimensional representation using a large amount of unsupervised data and a small amount of supervised data.
+
+
+
The work can be extended to general information networks as well as classic techniques like MDS, Iso-map, Laplacian EigenMaps etc do not scale well for large graphs.
+
+
+
Further, this model can be applied to heterogeneous networks as well unlike the previous works LINE and DeepWalk which work on homogeneous networks only.
Word-Word Network which captures the word co-occurrence information (local level).
+
Word-Document Network which captures the word-document co-occurrence information (local + document level).
+
Word-Label Network which captures the word-label co-occurrence information (bipartite graph).
+
+
+
+
All 3 graphs are integrated into one heterogeneous text network.
+
+
+
First, the authors extend their previous work, LINE, for heterogenous bipartite text networks as explained:
+
+
+
+
Given a bipartite graph G = (VA \bigcup VB, E) , where VA and VB are disjoint set of vertices, the conditional probability of va (in set VA) being generated by vb (in set VB) is given as the softmax score between embeddings of va and vb and normalised by the sum of exponentials of dot products between vb and all nodes in VA.
+
+
+
+
+
+
The second order proximity can be determined by the conditional distributions *p(.
+
vj)*p(.
+
vj)*.
+
+
+
+
+
+
The objective to be minimised the KL divergence between the conditional distribution p(.\vj) and the emperical distribution p^(.\vj) (given as wi, j/degj).
+
+
The objective can be further simplified and optimised using SGD with edge sampling and negative sampling.
+
+
+
+
Now, the 3 individual networks can all be interpreted as bipartite networks. So node representation of all the 3 individual networks is obtained as described above.
+
+
+
For the word-label network, since the training data is sparse, one could either train the unlabelled networks first and then the labelled network or they all could be trained jointly.
+
+
+
For the case of joint training, the edges are sampled from the 3 networks alternatively.
+
+
+
For the fine-tuning case, the edges are first sampled from the unlabelled network and then from the labelled network.
+
+
+
Once the word embeddings are obtained, the text embeddings may be obtained by simply averaging the word embeddings.
+
+
+
+
Evaluation
+
+
+
+
Baseline Models
+
+
+
Local word co-occurence based methods - SkipGram, LINE(Gww)
+
Document word co-occurence based methods - LINE(Gwd), PV-DBOW
+
Combined method - LINE (Gww + Gwd)
+
CNN
+
PTE
+
+
+
+
For long documents, PTE (joint) outperforms CNN and other PTE variants and is around 10 times faster than CNN model.
+
+
+
For short documents, PTE (joint) does not always outperform CNN model probably because the word sense ambiguity is more relevant in the short documents.
+
+
diff --git a/_site/site/2017/12/31/Distilling-the-Knowledge-in-a-Neural-Network.html b/_site/site/2017/12/31/Distilling-the-Knowledge-in-a-Neural-Network.html
new file mode 100644
index 00000000..50c584ca
--- /dev/null
+++ b/_site/site/2017/12/31/Distilling-the-Knowledge-in-a-Neural-Network.html
@@ -0,0 +1,92 @@
+
Introduction
+
+
+
+
In machine learning, it is common to train a single large model (with a large number of parameters) or ensemble of multiple smaller models using the same dataset.
+
+
+
While such large models help to improve the performance of the system, they also make it difficult and computationally expensive to deploy the system.
+
+
+
The paper proposes to transfer the knowledge from such “cumbersome” models into a single, “simpler” model which is more suitable for deployment. This transfer of knowledge is referred to as “distillation”.
Train the cumbersome model using the given training data in the usual way.
+
+
+
Train the simpler, distilled model using the class probabilities (from the cumbersome model) as the soft target. Thus, the simpler model is trained to generalise the same way as the cumbersome model.
+
+
+
If the soft targets have high entropy, they provide much more information than the hard targets and the gradient (between training examples) would vary lesser.
+
+
+
One approach is to minimise the L2 difference between logits produced by the cumbersome model and the simpler model. This approach was pursued by Buciluǎ et al.
+
+
+
The paper proposes a more general solution which they name “distillation”. The temperature of the final softmax is increased till the cumbersome model produces a set of soft targets (from the final softmax layer). These soft targets are then used to train the simpler model.
+
+
+
It also shows that the proposed approach is, in fact, a more general case of the first approach.
+
+
+
+
Approach
+
+
+
+
In the simplest setting, the cumbersome model is first trained with a high value of temperature and then the same temperature value is used to train the simpler model. The temperature is set to 1 when making predictions using the simpler model.
+
+
+
It helps to add an auxiliary objective function which corresponds to the cross-entropy loss with the correct labels. The second objective function should be given a much lower weight though. Further, the magnitude of the soft targets needs to be scaled by multiplying with the square of temperature.
+
+
+
+
Experiment
+
+
+
+
The paper reports favourable results for distillation task for the following domains:
+
+
+
+
Image Classification (on MNIST dataset)
+
+
+
An extra experiment is performed where the simpler model is not shown any images of “3” but the model fails for only 133 cases out of 1010 cases involving “3”.
+
+
+
+
Automatic Speech Recognition (ASR)
+
+
+
+
An extra experiment is performed where the baseline model is trained using both hard targets and soft targets alternatively. Further, only 3% of the total dataset is used.
+
+
+
The model using hard targets overfits and has poor test accuracy while the model using soft targets does not overfit and gets much better test accuracy. This shows the regularizing effect of soft targets.
+
+
+
+
+
Training ensemble specialists for very large datasets (JFT dataset - an internal dataset at Google)
+
+
+
+
The experiment shows that while training a single large model would take a lot of time, the performance of the model can be improved by learning a small number of specialised networks (which are faster to train).
+
+
+
Though it is yet to be shown that the knowledge of such specialist models can be distilled back into a single model.
+
+
+
+
+
+
diff --git a/_site/site/2018/01/06/How-transferable-are-features-in-deep-neural-networks.html b/_site/site/2018/01/06/How-transferable-are-features-in-deep-neural-networks.html
new file mode 100644
index 00000000..bca26258
--- /dev/null
+++ b/_site/site/2018/01/06/How-transferable-are-features-in-deep-neural-networks.html
@@ -0,0 +1,99 @@
+
Introduction
+
+
+
+
When neural networks are trained on images, they tend to learn the same kind of features for the first layer (corresponding to Gabor filters or colour blobs). The first layer features are “general” irrespective of the task/optimizer etc.
+
+
+
The final layer features tend to be “specific” in the sense that they strongly depend on the task.
+
+
+
The paper studies the transition of generalization property across layers in the network. This could be useful in the domain of transfer learning where features are reused across tasks.
Degree of generality of a set of features, learned on task A, is defined as the extent to which these features can be used for another task B.
+
+
+
Randomly split 1000 ImageNet classes into 2 groups (corresponding to tasks A and B). Each group has 500 classes and half the total number of examples.
+
+
+
Two 8-layer convolutional networks are trained on the two datasets and labelled as baseA and baseB respectively.
+
+
+
Now choose a layer numbered n from {1, 2…7}.
+
+
+
For each layer n, train the following two networks:
+
+
+
Selffer Network BnB
+
+
Copy (and freeze) first n layers from baseB. The remaining layers are initialized randomly and trained on B.
+
This serves as the control group.
+
+
+
Transfer Network AnB
+
+
Copy (and freeze) first n layers from baseA. The remaining layers are initialized randomly and trained on B.
+
This corresponds to transferring features from A to B.
+
+
+
+
+
+
If AnB performs well, nth layer features are “general”.
+
+
+
In another setting, the transferred layers are also fine-tuned (BnB+ and AnB+).
+
+
+
ImageNet dataset contains a hierarchy of classes which allow for creating the datasets A and B with high and low similarity.
+
+
+
+
Observation
+
+
Dataset A and B are similar
+
+
+
+
For n = {1, 2}, the performance of the BnB model is same as baseB model. For n = {3, 4, 5, 6}, the performance of BnB model is worse.
+
+
+
This indicates the presence of “fragile co-adaption” features on successive layers where features interact with each other in a complex way and can not be easily separated across layers. This is more prominent across middle layers and less across the first and the last layers.
+
+
+
For model AnB, the performance of baseB for n = {1, 2}. Beyond that, the performance begins to drop.
+
+
+
Transfer learning of features followed by fine-tuning gives better results than training the network from scratch.
+
+
+
+
Dataset A and B are dissimilar
+
+
+
Effectiveness of feature transfer decreases as the two tasks become less similar.
+
+
+
Random Weights
+
+
+
+
Instead of using transferred weights in BnB and BnA, the first n layers were initialized randomly.
+
+
+
The performance falls for layer 1 and 2. It further drops to near-random level for layers 3 and beyond.
+
+
+
Another interesting insight is that even for dissimilar tasks, transferring features is better than using random features.
+
+
diff --git a/_site/site/2018/01/14/Exploring-Models-and-Data-for-Image-Question-Answering.html b/_site/site/2018/01/14/Exploring-Models-and-Data-for-Image-Question-Answering.html
new file mode 100644
index 00000000..bd678269
--- /dev/null
+++ b/_site/site/2018/01/14/Exploring-Models-and-Data-for-Image-Question-Answering.html
@@ -0,0 +1,77 @@
+
Introduction
+
+
+
+
Problem Statement: Given an image, answer a given question about the image.
The answer is assumed to be a single word thereby bypassing the evaluation issues of multi-word generation tasks.
+
+
+
+
+
VIS-LSTM Model
+
+
+
Treat the input image as the first word in the question.
+
Obtain the vector representation (skip-gram) for words in the question.
+
Obtain the VGG Net embeddings of the image and use a linear transformation (dimensionality reduction weight matrix) to match the dimensions of word embeddings.
+
Keep image embedding frozen during training and use an LSTM to combine the word vectors.
+
LSTM outputs are fed into a softmax layer which generates the answer.
+
+
+
Dataset
+
+
+
DAtaset for QUestion Ansering on Real-world images (DAQUAR)
+
+
1300 images and 7000 questions with 37 object classes.
+
Downside is that even guess work can yield good results.
+
+
+
The paper proposed an algorithm for generating questions using MS-COCO dataset.
+
+
Perform preprocessing steps like breaking large sentences and changing indefinite determines to definite ones.
+
object questions, number questions, colour questions and location questions can be generated by searching for nouns, numbers, colours and prepositions respectively.
+
Resulting dataset has ~120K questions across above 4 semantic types.
+
+
+
+
+
Models
+
+
+
VIS+LSTM - explained above
+
2-VIS+BLSTM - Add the image features twice, in beginning and in the end (using different linear transformations) plus use bidirectional LSTM
+
IMG+BOW - Multinomial logistic regression on image features without dimensionality reduction + bag of words (averaging word vectors).
+
FULL - Simple average of above 2 models.
+
+
+
Baseline
+
+
+
Includes models where the answer is guessed, or only image or question features are used or image features along with prior knowledge of object are used.
+
Also includes a KNN model where the system finds the nearest (image, question) pair.
+
+
+
Metrics
+
+
+
Accuracy
+
Wu-Palmer similarity measure
+
+
+
Observations
+
+
+
The VIS-LSTM model outperforms the baselines while the FULL model benefits from averaging across all the models.
+
Some useful information seems to be lost when downsizing the VGG vectors.
+
Fine tuning the word vectors helps with performance.
+
Normalising CNN hidden image features into zero mean and unit variance leads to faster training.
+
Model does not perform well on the task of considering spatial relations between multiple objects and counting objects when multiple objects are present
+
diff --git a/_site/site/2018/01/22/Emotional-Chatting-Machine-Emotional-Conversation-Generation-with-Internal-and-External-Memory.html b/_site/site/2018/01/22/Emotional-Chatting-Machine-Emotional-Conversation-Generation-with-Internal-and-External-Memory.html
new file mode 100644
index 00000000..26ce6549
--- /dev/null
+++ b/_site/site/2018/01/22/Emotional-Chatting-Machine-Emotional-Conversation-Generation-with-Internal-and-External-Memory.html
@@ -0,0 +1,79 @@
+
+
+
The paper proposes ECM (Emotional Chatting Machine) which can generate both semantically and emotionally appropriate responses in a dialogue setting.
+
+
+
More specifically, given an input utterance or dialogue and the desired emotional category of the response, ECM is to generate an appropriate response that conforms to the given emotional category.
Much of the recent, deep learning based work on conversational agents has focused on the use of encoder-decoder framework where the input utterance (given sequence of words) is mapped to a response utterance (target sequence of words). This is the so-called seq2seq family of models.
+
+
+
ECM model can sit within this framework and introduces 3 new components:
+
+
+
Emotion Category Embedding
+
+
Embed the emotion categories into a real-valued, low-dimensional vector space.
+
These embeddings are used as input to the decoder and are learnt along with rest of the model.
+
+
+
Internal Memory
+
+
Physiological, emotional responses are relatively short-lived and involve changes.
+
ECM accounts for this effect by adding an Internal Memory which captures this dynamics of emotions during decoding.
+
It starts with “full” emotions in the beginning and keeps decaying the emotion value over time.
+
How much of the emotion value is to be decayed is determined by a sigmoid gate.
+
By the time the sentence is decoded, the value becomes zero, signifying that the emotion has been completely expressed.
+
+
+
External Memory
+
+
Emotional responses are expected to carry emotionally strong words along with generic, neutral words.
+
An external memory is used to include the emotionally strong words explicitly by using 2 non-overlapping vocabularies - generic vocabulary and the emotion vocabulary (read from the external memory).
+
Both these vocabularies are assigned different generation probabilities and an output gate controls the weights of generic and emotion words.
+
This way the emotion words are included in an otherwise neutral response.
+
+
+
+
+
+
Loss function
+
+
+
The first component is the cross-entropy loss between predicted and target token distribution.
+
A regularization term on internal memory to make sure the emotional state decays to 0 at the end of the decoding process.
+
Another regularization term on external memory to supervise the probability of selection of a generic vs emotion word.
+
+
+
*Dataset
+
+
STC Dataset (~220K posts and ~4300K responses) annotated by the emotional classifier. Any error on the part of the classifier degrades the quality of the training dataset.
+
NLPCC Dataset - Emotion classification dataset with 23105 sentences.
+
+
+
+
Metric
+
+
+
Perplexity to evaluate the model at the content level.
+
Emotion accuracy to evaluate the model at the emotional level.
+
+
+
+
ECM achieves a perplexity of 65.9 and emotional accuracy of 0.773.
+
+
+
Based on human evaluations, ECM statistically outperforms the seq2seq baselines on both naturalness (likeliness of response being generated by a human) and emotion accuracy.
+
+
+
Notes
+
+
+
It is an interesting idea to let the sigmoid gate decide how the emotion “value” be spent while decoding. It seems similar to the idea of how much do we want to “attend” to the emotion value the key difference being that your total attention is limited. It would be interesting to see the shape of the distribution of how much of the emotion value is spent at each decoding time step. If the curve is highly biased towards say using most of the emotion value towards the end of the decoding process, maybe another regularisation term is needed to ensure a more balanced distribution of how the emotion is spent.
+
+
+
diff --git a/_site/site/2018/01/29/StarSpace-Embed-All-The-Things.html b/_site/site/2018/01/29/StarSpace-Embed-All-The-Things.html
new file mode 100644
index 00000000..ce16a74e
--- /dev/null
+++ b/_site/site/2018/01/29/StarSpace-Embed-All-The-Things.html
@@ -0,0 +1,57 @@
+
Introduction
+
+
+
+
The paper describes a general purpose neural embedding model where different type of entities (described in terms of discrete features) are embedded in a common vector space.
+
+
+
A similarity function is learnt to compare these entities in a meaningful way and score their similarity. The definition of the similarity function could depend on the downstream task where the embeddings are used.
Each entity is described as a set of discrete features. For example, for the recommendation use case, the users may be described as a bag-of-words of movies they have liked. For the search use case, the document may be described as a bag-of-words of words they are made up of.
+
+
+
Given a dataset and a task at hand, generate a set of positive samples E = (a, b) such that a is the input to the task (from the dataset) and b is the expected label(answer/entity) for the given task.
+
+
+
Similarly, generate another set of negative samples E - = (a, bi-) such that bi- is one of the incorrect label(answer/entity) for the given task. The incorrect entity can be sampled randomly from the set of candidate entities. Multiple incorrect samples could be generated for each positive example. These incorrect samples are indexed using i.
+
+
+
For example, in case of supervised learning problem like document classification, a would be one of the documents (probably described in terms of words), b is the correct label and bi-) is one of the randomly sampled label from set of all the labels (excluding the correct label).
+
+
+
In case of collaborative filtering, a would be the user (either described as a discrete entity like a userid or in terms of items purchased so far), b is the next item the user purchases and bi-) is one of the randomly sampled item from the set of all the items.
+
+
+
A similarity function is chosen to compare the representation of entities of type a and b. The paper considered cosine similarity and inner product and observed that cosine similarity works better for the case with a large number of entities.
+
+
+
A loss function compares the similarity between positive pairs (a, b) and (a, bi-). The paper considered margin ranking loss and negative log loss of softmax and reported that margin ranking loss works better.
+
+
+
The norm of embeddings is capped at 1.
+
+
+
+
Observations
+
+
+
+
The same model architecture is applied to a variety of tasks including multi-class classification, multi-label classification, collaborative filtering, content-based recommendation, link prediction, information retrieval, word embeddings and sentence embeddings.
+
+
+
The model provides a strong baseline on all the tasks and performs at par with much more complicated and task-specific networks.
+
+
+
diff --git a/_site/site/2018/02/05/Get-To-The-Point-Summarization-with-Pointer-Generator-Networks.html b/_site/site/2018/02/05/Get-To-The-Point-Summarization-with-Pointer-Generator-Networks.html
new file mode 100644
index 00000000..c4500791
--- /dev/null
+++ b/_site/site/2018/02/05/Get-To-The-Point-Summarization-with-Pointer-Generator-Networks.html
@@ -0,0 +1,72 @@
+
Introduction
+
+
+
+
Sequence-to-Sequence models have made abstract summarization viable but they still suffer from issues like out of vocabulary words and repetitive sentences.
+
+
+
The paper proposes to overcome these limitations by using a hybrid Pointer-Generator network (to copy words from the source text) and a coverage vector that keeps track of content that has already been summarized so as to discourage repetition.
It is a hybrid model between the Sequence-to-Sequence network and Pointer Network such that when generating a word, the model decides whether the word would be generated using the softmax vocabulary (Sequence-to-Sequence) or using the source vocabulary (Pointer Network).
+
+
+
Since the model can choose a word from the source vocabulary, the issue of out of vocabulary words is handled.
+
+
+
+
Coverage Mechanism
+
+
+
+
The model maintains a coverage vector which is the sum of attention distributions over all previous decoder timesteps.
+
+
+
This coverage vector is fed as an input to the attention mechanism.
+
+
+
A coverage loss is added to prevent the model from repeatedly attending to the same word.
+
+
+
The idea is to capture how much coverage different words have already received from the attention mechanism.
+
+
+
+
Observation
+
+
+
+
Model when evaluated on CNN/Daily Mail summarization task, outperforms the state-of-the-art by at least 2 ROUGE points though it still does not outperform the lead-3 baseline.
+
+
+
Lead-3 baseline uses first 3 sentences as the summary of the article which should be a strong baseline given that the dataset is actually about news articles.
+
+
+
The model is initially trained without coverage and then finetuned with the coverage loss.
+
+
+
During training, the model first learns how to copy words and then how to generate words (pgen starts from 0.3 and converges to 0.53).
+
+
+
During testing, the model strongly prefers copying over generating (pgen = 0.17).
+
+
+
Further, whenever the model is at beginning of sentences or at the join between switched-together fragments, it prefers to generate a word instead of copying one from the source language.
+
+
+
The overall model is very simple, neat and interpretable and also performs well in practice.
+
+
diff --git a/_site/site/2018/02/11/Stylistic-Transfer-in-Natural-Language-Generation-Systems-Using-Recurrent-Neural-Networks.html b/_site/site/2018/02/11/Stylistic-Transfer-in-Natural-Language-Generation-Systems-Using-Recurrent-Neural-Networks.html
new file mode 100644
index 00000000..8676492f
--- /dev/null
+++ b/_site/site/2018/02/11/Stylistic-Transfer-in-Natural-Language-Generation-Systems-Using-Recurrent-Neural-Networks.html
@@ -0,0 +1,48 @@
+
Introduction
+
+
+
This workshop paper explores the problem of style transfer in natural language generation (NLG).
+
One possible manifestation would be rewriting technical articles in an easy-to-understate manner.
+
+
+
Challenges
+
+
+
Identifying relevant stylistic cues and using them to control text generation in NLG systems.
+
Absence of a large amount of training data.
+
+
+
Pitch
+
+
+
Using Recurrent Neural Networks (RNNs) to disentangle the style from semantic content.
+
Autoencoder model with two components - one for learning style and another for learning content.
+
This allows for “style” component to be replaced while keeping the “content” component same, resulting in a style transfer.
+
One way to think about this is - the encoder generates a 100-dimensional vector. In this, the first 50 entries, correspond to the “style” component and remaining to the “content” component.
+
The proposal is that the loss function should be modified to include a cross-covariance term for ensuring disentanglement.
+
I think one way of doing this is to have two loss functions:
+
+
The first loss function ensures that the input sentence is decoded properly into the target sentence. This loss is computed for each sentence.
+
The second loss ensures that the first 50 entries across all the encoded represenations are are correlated. This loss operates at the batch level.
+
The total loss is the weighted sum of these 2 losses.
Soundness - is the generated text entailed with the input sentence.
+
Coherence - free of grammatical errors, proper word usage etc.
+
Effectiveness - how effective was the style transfer
+
Since some of the metrics are subjective, human evaluators also need to be employed.
+
diff --git a/_site/site/2018/02/17/Neural-Relational-Inference-for-Interacting-Systems.html b/_site/site/2018/02/17/Neural-Relational-Inference-for-Interacting-Systems.html
new file mode 100644
index 00000000..cccd236d
--- /dev/null
+++ b/_site/site/2018/02/17/Neural-Relational-Inference-for-Interacting-Systems.html
@@ -0,0 +1,97 @@
+
Introduction
+
+
+
+
The paper presents Neural Relational Inference (NRI) model which can infer underlying interactions in a dynamical system in an unsupervised manner, using just the observational data in terms of the trajectories.
+
+
+
For instance, consider a simulated system where the particles are connected to each other by springs. The observational data does not explicitly specify which particles are connected to each other and only contains information like position and velocity of each particle at different timesteps.
+
+
+
The task is to explicitly infer the interaction structure (in this example, which pair of particles are connected to each other) while learning the dynamical model of the system itself.
The model consists of an encoder that encodes the given trajectories into an interaction graph and a decoder that decodes the dynamical model given the interaction graph.
+
+
+
The model starts by assuming that a full connected interaction graph exists between the objects in the system.
+
+
+
For this latent graph z, zi, j denotes the (discrete) edge type between object vi and vj with the assumption that there are K edge types.
+
+
+
The object vi has a feature vector xit associated with it at time t. This feature vector captures information like location and velocity.
+
+
+
+
Encoder
+
+
+
+
A Graph Neural Network (GNN) acts on the fully connected latent graph z, performs message passing from node to node via edges and predicts the discrete label for each edge.
+
+
+
The GNN architecture may itself use MLPs or ConvNets and returns a factorised distribution over the edge types qφ(z|x).
+
+
+
+
Decoder
+
+
+
+
The decoder is another GNN (with separate params for each edge type) that predicts the future dynamics of the system and returns pθ(x|z).
+
+
The overall model is a VAE that optimizes the ELBO given as:
+
+
Eqφ(z|x)[log pθ(x|z)] − KL[qφ(z|x)||pθ(z)]
+
+
+
pθ(x) is the prior which is assumed to be uniform distribution over the edge types.
+
+
+
Instead of predicting the dynamics of the system for just the next timestep, the paper chooses to use the prediction multiple steps (10) in the future. This ensures that the interactions can have a significant effect on the dynamics of the system.
+
+
In some cases, like real humans playing a physical sport, the dynamics of the system need not be Markovian and a recurrent decoder is used to model the time dependence.
+
+
+
Pipeline
+
+
+
+
Given the dynamical system, run the encoder to obtain qφ(z|x).
+
+
+
Sample zi, j from qφ(z|x).
+
+
+
Run the decoder to predict the future dynamics for the next T timesteps.
+
+
+
Optimise the ELBO loss.
+
+
+
Note that since the latent variables (edge labels) are discrete in this case, the sampling is done from a continuous approximation of the discrete distribution and reparameterization trick is applied over this discrete approximation to get the (biased) gradients.
+
+
+
+
Observations
+
+
+
+
Experiments are performed using simulated systems like particles connected to springs, phase coupled oscillators and charged particles and using real-world data like CMU Motion Capture database and NBA tracking data.
+
+
+
The NRI system effectively predicts the dynamics of the systems and is able to reconstruct the ground truth interaction graph (for simulated systems).
+
+
diff --git a/_site/site/2018/02/24/Learning-a-SAT-Solver-from-Single-Bit-Supervision.html b/_site/site/2018/02/24/Learning-a-SAT-Solver-from-Single-Bit-Supervision.html
new file mode 100644
index 00000000..bee8f3c8
--- /dev/null
+++ b/_site/site/2018/02/24/Learning-a-SAT-Solver-from-Single-Bit-Supervision.html
@@ -0,0 +1,95 @@
+
Introduction
+
+
+
+
The paper presents NeuroSAT, a message passing neural network that is trained to predict if a given SAT can be solved. As a side effect of training, the model also learns how to solve the SAT problem itself without any extra supervision.
Given an expression in the propositional logic, the task is to predict if there exists a substitution of variables that make the expression true.
+
+
+
The expression itself can be written as a conjunction of disjunctions (“and” over “or”) where each conjunct is called a clause and each variable within a clause is called a literal.
+
+
+
Invariants
+
+
+
+
The variables or clauses or literals (within the clauses) can be permuted.
+
+
+
Every occurrence of a variable can be negated.
+
+
+
+
+
+
Model
+
+
+
+
Given the SAT problem, create an undirected graph of literals, their negations and the clauses they belong to.
+
+
+
Put an edge between every literal and the clause to which it belongs and another kind of edge between every literal and its negation.
+
+
+
Perform message passing between nodes to obtain vector representations corresponding to each node. Specifically, first, each clause received a message from its neighbours (literals) and updates its embeddings. Then every literal receives a message from its neighbours (both literals and clauses) and updates its embeddings.
+
+
+
After T iterations, the nodes vote to decide the prediction of the model as a whole.
+
+
+
The model is trained end-to-end using the cross-entropy loss between logit and the true label.
+
+
+
Permutation invariance is ensured by operating on the nodes and the edges in the topological order and negation invariance is ensured by treating all literals as the same.
+
+
+
+
Decoding Satisfying Assignment
+
+
+
+
The most interesting aspect of this work is that even though the model was trained to predict if the SAT problem can be satisfied, it is actually possible to extract the correct assignment from the classifier.
+
+
+
In the early iterations, all the nodes vote “unsolvable” with low confidence. Then a few nodes start voting “solvable” and then a phase transition happens where most of the nodes start voting “solvable” with high confidence.
+
+
+
The model never becomes highly confident that problem is “unsolvable” and almost never guesses “solvable” on an “unsolvable” problem. So in some sense, the model is looking for the combination of literals that actually solves the problem.
+
+
+
The authors found that the 2 dimensional PCA projections of the literal embeddings are initially mixed up but become more and more linearly separable as the phase transition happens.
+
+
+
Based on this insight, the authors propose to obtain cluster centres C1 and C2, partition the variables according to the cluster centres and then try assignments from both the partitions.
+
+
+
This alone provides a satisfying solution in over 70% of the cases when though there is no explicit supervising signal about how to solve the problem.
+
+
+
The other strengths of the paper includes
+
+
+
+
Generalizing to longer and more difficult SAT problems (than those seen during training).
+
+
+
Generalizing to another kind of search problems like graph colouring, clique detection etc (over small random graphs).
+
+
+
+
+
The paper also reports that by adding supervising signal about which clauses in the given expression are unsatisfiable, it is possible to decode the literals which prove the “unsatisfiability” of an expression at test time. Though not a lot of details have been provided about this part and would probably be covered in the next iteration of the paper.
+
+
+
diff --git a/_site/site/2018/03/05/An-Empirical-Investigation-of-Catastrophic-Forgetting-in-Gradient-Based-Neural-Networks.html b/_site/site/2018/03/05/An-Empirical-Investigation-of-Catastrophic-Forgetting-in-Gradient-Based-Neural-Networks.html
new file mode 100644
index 00000000..57c40a98
--- /dev/null
+++ b/_site/site/2018/03/05/An-Empirical-Investigation-of-Catastrophic-Forgetting-in-Gradient-Based-Neural-Networks.html
@@ -0,0 +1,80 @@
+
Introduction
+
+
+
+
Catastrophic Forgetting refers to the phenomenon where when a learning system is trained on two tasks in succession, it may forget how to perform the first task.
+
+
+
The paper investigates this behaviour for different learning activations in presence and absence of dropout.
For each experiment, two tasks are defined - “old” task and “new” task.
+
+
+
The network is first trained on the “old” task until the validation set error has not improved for the last 100 epochs.
+
+
+
The “best” performing model is then trained for the “new” task until the combined error on the “old” and the “new” validation datasets has not improved in the last 100 epochs.
+
+
+
All the tasks used the same model architecture - 2 hidden layers followed by a softmax layer.
+
+
Following activations were tested:
+
+
Sigmoid
+
ReLU
+
Hard Local Winner Takes It All
+
Maxout
+
+
+
+
Models were trained using SGD with or without dropout.
+
+
+
For each combination of the model, activation and the training mechanism, a random hyper param search was performed with set of 25 hyperparams.
+
+
The authors took care to keep the hyperparams and other settings consistent and comparable across different experiments. Deviations, wherever applicable, and their reasons were documented.
+
+
+
Observations
+
+
+
+
In terms of the relationship between the “old” and the “new” tasks, three kinds of settings are considered:
+
+
+
+
The tasks are very very similar but the input is processed in a different format. For this setting, MNIST dataset was used with a different permutation of pixels for the “old” and the “new” task.
+
+
+
The tasks are similar but not exactly the same. For this setting, the task was to predict sentiments of reviews across 2 different product categories.
+
+
+
In the last setting, 2 dissimilar tasks were used. One task was to predict sentiment of reviews and another task was to perform classification over MNIST dataset (reduced to 2 classes).
+
+
+
+
+
Using Dropout improved the overall validation performance for all the models for all the tasks.
+
+
+
Using Dropout also increase the size of the optimal model across all the activations indicating that maybe the increased size of the model could explain the increased resistance to forgetting. It would have been interesting to check if dropout always selected the largest model possible given the set of the hyperparams.
+
+
+
On the dissimilar task, dropout improved the performance while reducing the model size so it might have other properties as well that helps to prevent forgetting.
+
+
+
As compared to the choice of training technique, the activation function has a less consistent effect on resistance to forgetting. The paper recommends performing cross-validation for the choice of the activation function. If that is not feasible, maxout activation function with dropout could be used.
+
+
diff --git a/_site/site/2018/03/11/Improving-Information-Extraction-by-Acquiring-External-Evidence-with-Reinforcement-Learning.html b/_site/site/2018/03/11/Improving-Information-Extraction-by-Acquiring-External-Evidence-with-Reinforcement-Learning.html
new file mode 100644
index 00000000..7633f1cb
--- /dev/null
+++ b/_site/site/2018/03/11/Improving-Information-Extraction-by-Acquiring-External-Evidence-with-Reinforcement-Learning.html
@@ -0,0 +1,120 @@
+
Introduction
+
+
+
+
Information Extraction - Given a query to be answered and an external search engine, information extraction entails the task of issuing search queries, extracting information from new sources and reconciling the extracted values till we are sufficiently confident about the extracted values.
+
+
+
The paper proposes the use of Reinforcement Learning (RL) to solve this task.
Use of Reinforcement Learning to resolve the ambiguity inherent in the textual documents.
+
Given a query, the RL agent would use template statement to formulate the queries (to be performed on the black box search engine). It would further resolve and combine the result for the query from the set of retrieved documents.
+
+
+
Datasets
+
+
+
Database of Mass Shootings in the United States.
+
Food Shield database of illegal food adulteration.
+
+
+
Framework
+
+
+
+
Information extraction task is modelled as a Markov Decision Process (MDP) <S, A, T, R>
+
+
S - Set of all possible states
+
+
The state consists of:
+
+
Extractor’s confidence in predicted entity values.
+
Context from which values are extracted.
+
Similarity between the new document (extracted just now from the search engine) and the original document accompanying the given query.
+
+
+
+
+
A - Set of all possible actions
+
+
Reconciliation decision - d
+
+
Accept all entities values.
+
Reject all entities values.
+
Stop the current episode.
+
+
+
Query choice - q
+
+
Choose the next query from a set of automatically generated alternatives.
+
+
+
+
+
R - Rewards
+
+
Maximise the final extraction accuracy while minimising the number of queries.
+
+
+
Q - Queries
+
+
Generated using a template.
+
The query is searched on a search engine and the top k links are retrieved.
+
+
+
Transition
+
+
Start with a single source article xi and extract the initial set of entities.
+
At each timestep, the agent is given the state (s) on basis of which it chooses the action (d, q). The episode stops whenever the action is a stop action.
+
+
+
+
Deep Q Network is used.
+
+
Parameters are learned using SGD and RMSProp.
+
+
+
Experimental Setup
+
+
Extraction Model
+
+
+
Max Entropy Classifier is used as the base extraction system.
+
First, all the words in the document are tagged as one of the entity types and the mode of these values is used to obtain the set of extracted entities.
+
+
+
Baseline
+
+
+
Basic Extractors
+
Aggregation System which either chooses the entity value with the highest confidence or takes a majority vote over all extracted values.
+
Meta-Classifier which operates over the same input state space and produces the same set of reconciliation decisions as the DQN.
+
Oracle Extractor which is computed assuming perfect reconciliation and query decisions on the top of the Maxnet base extractor.
+
+
+
RL Models
+
+
+
RL Basic - Only reconciliation decision.
+
RL Query - Only query decision with a fixed reconciliation strategy.
+
RL Extract - the full system with both reconciliation and query decision.
+
+
+
Result
+
+
+
RL Extract obtains substantial gains eg up to 11% over Maxnet.
+
Simple aggregation schemes do not handle the task well.
+
In terms of reward structure, providing rewards after each step works better than a single delayed reward.
+
diff --git a/_site/site/2018/03/18/Cyclical-Learning-Rates-for-Training-Neural-Networks.html b/_site/site/2018/03/18/Cyclical-Learning-Rates-for-Training-Neural-Networks.html
new file mode 100644
index 00000000..038f2ef3
--- /dev/null
+++ b/_site/site/2018/03/18/Cyclical-Learning-Rates-for-Training-Neural-Networks.html
@@ -0,0 +1,66 @@
+
Introduction
+
+
+
+
Conventional wisdom says that when training neural networks, learning rate should monotonically decrease. This insight forms the basis of the different type of adaptive learning rates.
+
+
+
Counter to this expected behaviour, the paper demonstrates that using a cyclical learning rate (CLR), varying between a minimum and a maximum value, helps to train the neural network faster without requiring fine-tuning of learning rate.
+
+
+
The paper also provides a simple approach to estimate the lower and upper bound for CLR.
Difficulty in minimizing the loss arises from saddle points and not from local minima. [Ref]
+
+
+
Increasing the learning rate allows for rapid traversal of saddle points.
+
+
+
Alternatively, the optimal learning rate is expected to be between bounds of CLR and thus the learning rate would always be close to the optimal learning rate.
+
+
+
+
Parameter Estimation
+
+
+
+
Cycle Length = Number of iterations till learning rate returns to the initial value = 2 * step_size
+
+
+
step_size should be set to 2-10 times the number of iterations in an epoch.
+
+
+
Estimating the CLR boundary values:
+
+
+
+
Run the model for several epochs while increasing the learning rate between the allowed low and high values.
+
+
+
Plot accuracy vs learning rate and note the learning rate values when the accuracy starts to fall.
+
+
+
This gives a good candidate value for upper and lower bound. Alternatively, the lower bound could be set to be 1/3 or 3/4 of the upper bound. But it is difficult to judge if the model has run for the sufficient number of epochs in the first place.
+
+
+
+
+
+
Notes
+
+
+
The idea in itself is very simple and straight-forward to add to any existing model which makes it very appealing.
+
The author has experimented with various architectures and datasets (from vision domain) and has reported faster training results.
+
diff --git a/_site/site/2018/03/25/The-Lottery-Ticket-Hypothesis-Training-Pruned-Neural-Networks.html b/_site/site/2018/03/25/The-Lottery-Ticket-Hypothesis-Training-Pruned-Neural-Networks.html
new file mode 100644
index 00000000..93c921fe
--- /dev/null
+++ b/_site/site/2018/03/25/The-Lottery-Ticket-Hypothesis-Training-Pruned-Neural-Networks.html
@@ -0,0 +1,72 @@
+
Introduction
+
+
+
+
Empirical evidence indicates that at training time, the neural networks need to be of significantly larger size than necessary.
+
+
+
The paper purposes a hypothesis called the lottery ticket hypothesis to explain this behaviour.
+
+
+
The idea is the following - Successful training of a neural network depends on a lucky random initialization of a subcomponent of the network. Such components are referred to as lottery tickets.
+
+
+
Larger networks are more likely to have these lottery tickets and hence are easier to train.
Various aspects of the hypothesis are explored empirically.
+
+
+
Two tasks are considered - MNIST and XOR.
+
+
+
For each task, the paper considers networks of different sizes and empirically shows that larger networks are more likely to converge (or have better performance) for a fixed number of epochs as compared to the smaller networks.
+
+
+
Given a large, trained network, some weights (or units) of the network are pruned and the resulting network is reset to its initial random weights.
+
+
+
The resulting network is the lottery-ticket in the sense that when the pruned network is trained, it is more likely to converge than an otherwise randomly initialised network of the same size. Further, it is more likely to match the original, larger network in terms of performance.
+
+
+
The paper explores different aspects of this experiment:
+
+
+
Pruning Strategies:
+
+
One-shot strategy prunes the network in one-go while the iterative strategy prunes the network iteratively.
+
Though the latter is computationally more intensive, it is more likely to find a lottery ticket.
+
+
+
+
Size of the pruned network affects the speed of convergence when training the lottery ticket.
+
+
+
If only the architecture or only the initial weights of the lottery ticket are used, the resulting network tends to converge more slowly and achieves a lower level of performance.
+
+
This indicates that the lottery ticket depends on both the network architecture and the weight initialization.
+
+
+
+
+
Discussion
+
+
+
+
The paper includes some more interesting experiments. For instance, the distribution of the initialization in the weights that survived the pruning suggests that small weights from before training tend to remain small after training.
+
+
+
One interesting experiment would be to show the performance of the pruned network before resetting its weights and retraining again. This performance should be compared with the performance of the initial large network and the performance of the lottery ticket after training.
+
+
+
Overall, the experiments are not sufficient to conclude anything about the correctness of the hypothesis. The proposition itself is very interesting and could enhance our understanding of how the neural networks work.
+
+
diff --git a/_site/site/2018/04/02/Unsupervised-Learning-By-Predicting-Noise.html b/_site/site/2018/04/02/Unsupervised-Learning-By-Predicting-Noise.html
new file mode 100644
index 00000000..1bd6354d
--- /dev/null
+++ b/_site/site/2018/04/02/Unsupervised-Learning-By-Predicting-Noise.html
@@ -0,0 +1,147 @@
+
Introduction
+
+
+
+
Convolutional Neural Networks are extremely good feature extractors in the sense that features extracted for one task (say image classification) can be easily transferred to another task (say image segmentation).
+
+
+
Existing unsupervised approaches do not aim to learn discriminative features and supervised approaches for discriminative features do not scale well.
+
+
+
The paper presents an approach to learn features in an unsupervised setting by using a set of target representations called as Noise As Target (NAT) which acts as a kind of proxy supervising signal.
Given a collection of image X (x1, x2, …, xn), we want to learn a parameterized mapping f such that f(xi) gives the features of image xi. We would jointly learn the target vectors yi (more on it later).
+
+
+
Loss Function
+
+
+
Squared L2 norm is used as the distance measure while making sure that final activations are unit normalized.
+
+
+
Fixed Target Representation
+
+
+
+
In the setting of the problem where we are learning both the features and the target representation, a trivial solution would be the one where all the input images map to the same target and are assigned the same representation. No discriminative features are learned in this case.
+
+
+
To avoid such situations, a set of k predefined target representations are chosen and each image is mapped to one of these k representations (based on the features).
+
+
+
There is an assumption that k > n so that each image is assigned a different target.
+
+
+
One simple choice of target representation is the standard one-hot vector which implies that all the class (and by extension, the associated images) are orthogonal and equidistant from each other. But this is not a reasonable approximation as not all the image pairs are equally similar or dissimilar.
+
+
+
Instead, the target vectors are uniformly sampled from a d-dimensional unit sphere, where d is the dimensionality of the feature representation. That is, the idea is to map the features to the manifold of the d-dimensional L2 sphere by using the K predefined representations as for the discrete approximation of the manifold.
+
+
+
Since each data point (image) is mapped to a new point on the manifold, the algorithm is suited for online training as well.
+
+
+
+
Optimisation
+
+
+
+
For the training, the number of target K is reduced to the number of images n and an assignment matrix P is learned which ensures that the mapping between the image to target is 1-to-1.
+
+
+
The resulting optimisation equation can be solved using the Hungarian Algorithm but at a high-cost O(n^3). An optimisation is to take a batch of b images and update the square matrix PB for dimension bXb (made of the images and their corresponding targets). This reduces the overall complexity of O(nb^2).
+
+
+
Other optimisation techniques, that are common to supervised learning, like batch norm used in this setting as well.
+
+
+
+
Implementation Detail
+
+
+
+
Used AlexNet with NATs to train the unsupervised model.
+
+
+
An MLP is trained on these features to learn the classifier.
+
+
+
Standard preprocessing techniques like random cropping/flipping are used.
+
+
+
+
Experimental Details
+
+
+
+
Dataset
+
+
+
+
ImageNet for training the AlexNet architecture with the proposed approach.
+
+
+
Pascal VOC 2007 for transfer learning experiments.
+
+
+
+
+
Baselines
+
+
+
+
Unsupervised approaches like autoencoder, GAN, BiGAN
+
+
+
Self-supervised
+
+
+
SOTA models using hand-made features SIFT with Fisher Vector.
+
+
+
+
+
+
Observation
+
+
+
+
Using squared loss instead of softmax does not deteriorate the performance too much.
+
+
+
The authors compare the effect of using discrete vs continuous target representations for transfer learning. For the discrete representation, elements of the canonical basis of a k-dimensional space (k=1000, 10000, 100000) are used. Experiments demonstrate that d-dimensional continuous vectors perform much better than the discrete vectors.
+
+
+
While training the unsupervised network, its features were extracted after every 20 iterations to evaluate the performance on transfer learning task. The test accuracy increases up to around 100 iterations then saturate.
+
+
+
Comparing the visualization of the first convolutional layer filters (for AlexNet with and without supervision) shows that while unsupervised filters are less sharp, they maintain the edge and orientation information.
+
+
+
The proposed unsupervised method outperforms all the unsupervised baselines and is competitive with respect to the supervised baseline. But it is still far behind the model using handcrafted features.
+
+
+
For transfer learning, on Pascal VOC, the proposed approach beats the supervised baseline and works at par with the supervised approach.
+
+
+
+
Notes
+
+
+
+
The paper proposed a simple unsupervised framework for learning discriminative features without having to rely on proxy tasks like image generation and without having to make an assumption about the input domain.
+
+
+
The key aspect of the proposed approach is that each image is assigned to a unique point in the d-dimensional manifold which means 2 images could be very close to each other on the manifold while being quite distinct in reality. It is interesting to see that such a simple strategy is able to give such good results.
+
+
diff --git a/_site/site/2018/04/08/Neural-Message-Passing-for-Quantum-Chemistry.html b/_site/site/2018/04/08/Neural-Message-Passing-for-Quantum-Chemistry.html
new file mode 100644
index 00000000..cf60f22d
--- /dev/null
+++ b/_site/site/2018/04/08/Neural-Message-Passing-for-Quantum-Chemistry.html
@@ -0,0 +1,162 @@
+
Introduction
+
+
+
+
The paper presents a general message passing architecture called as Message Passing Neural Networks (MPNNs) that unify various existing models for performing supervised learning on molecules.
+
+
+
Variants of the MPNN model achieve very good performance on the task of predicting the property of the molecules.
The input to the model is an undirected graph G where node features are represented as xv (corresponding to node v) and edge features are ev, w (corresponding to edge between nodes v, w).
+
+
+
The idea is to learn a representation (or feature vector) for all the nodes (and possibly edges) in the graph and use that for the downstream supervised learning task.
+
+
+
The model can be easily extended to the setting of directed graphs.
+
+
+
The model works in 2 phases:
+
+
+
+
Message Passing Phase
+
+
+
+
All nodes send a message to their neighbouring nodes. The message is a function of the feature vectors corresponding to the sender node (or vertex), the receiver node and the edge connecting the two nodes. The feature vectors can be combined to form the message using the message function which can be implemented as a neural network.
+
+
+
Once a node has received messages from all its neighbours, it updated its feature vector by aggregating all the message. The function used to aggregate and update the feature vector is called as the update function and can be implemented as a neural network.
+
+
+
After updating the feature vectors, the graph could initiate another round of message passing. After a sufficient number of message passing rounds, the Readout phase is invoked.
+
+
+
+
Readout Phase
+
+
+
+
The feature vectors corresponding to different nodes in the graph are aggregated into a single feature vector (corresponding to the feature vector of the graph) using the readout function.
+
+
+
The readout function can also be implemented using a neural network with the condition that it is invariant to the permutation of the nodes within the graph (to ensure that the MPNN is independent of the graph isomorphism).
Broadly speaking, the task is to predict the properties of given molecules (regression problem).
+
+
+
The QM9 dataset consists of 130K molecules whose properties have been measured using Quantum Mechanical Simulations (DFT).
+
+
+
Properties to be predicted include atomization energy, enthalpy, highest fundamental vibrational frequency etc.
+
+
+
There are two benchmarks for error:
+
+
+
+
DFT Error - Estimated average error of DFT approximation
+
+
+
Chemical Accuracy - As established by the chemistry community
+
+
+
+
+
+
Model
+
+
+
+
Following variants of message function are explored:
+
+
+
+
Matrix multiplication between Aevw and hv where A is the adjacency matrix hv is the feature corresponding to node v.
+
+
+
Edge Network which is same as matrix multiplication case with the difference that A is a learned matrix for each edge type.
+
+
+
Pair Network where the feature vector corresponding to the source node, target node and edge is fed to a neural network.
+
+
+
+
+
+
Virtual Elements
+
+
+
+
Since all messages are shared via edges, it could take a long time for the message to move between two ends of the graph. To fasten this process, virtual elements are provided.
+
+
+
In the first setting, “virtual edges” are inserted between nodes.
+
+
+
In the second setting, a “master” node connects to all the other nodes.
+
+
+
+
Message Passing Complexity
+
+
+
+
In a graph with n nodes and d dimensional feature vectors, a single step of message passing would have the worst case time complexity of O(n2d2.
+
+
+
This complexity can be reduced by breaking the d dimensional embedding into k different groups of d/k embeddings which can be updated in parallel. The complexity of the modified approach is O(n2d2/k.
+
+
+
+
Results
+
+
+
+
Best performing MPNN model uses edge network as the message function and set2set as the readout function.
+
+
+
Using group of embeddings helps to improve generalization. This effect could also be because of ensemble-like nature of the modified architecture.
+
+
+
The model performs worse without the virtual elements.
+
+
+
+
Takeaways
+
+
+
+
Long range interaction between vertices is necessary.
+
+
+
Scaling to larger molecule sizes is challenging because the model creates a fully connected graph by incorporating virtual elements.
+
+
diff --git a/_site/site/2018/05/06/Learning-to-Count-Objects-in-Natural-Images-for-Visual-Question-Answering.html b/_site/site/2018/05/06/Learning-to-Count-Objects-in-Natural-Images-for-Visual-Question-Answering.html
new file mode 100644
index 00000000..6d01ced7
--- /dev/null
+++ b/_site/site/2018/05/06/Learning-to-Count-Objects-in-Natural-Images-for-Visual-Question-Answering.html
@@ -0,0 +1,74 @@
+
Introduction
+
+
+
Most of the visual question-answering (VQA) models perform poorly on the task of counting objects in an image. The main reasons are:
+
+
Most VQA models use a soft attention mechanism to perform a weighted sum over the spatial features to obtain a single feature vector. These aggregated features helps in most category of questions but seems to hurt for counting based questions.
+
For the counting questions, we do not have a ground truth segmentation of where the objects to be counted are present on the image. This limits the scope of supervision.
+
+
+
+
Additionally, we need to ensure that any modification in the architecture, to enhance the performance on the counting questions, should not degrade the performance on other classes of questions.
+
+
+
The paper proposes to overcome these challenges by using the attention maps (and not the aggregated feature vectors) as input to a separate count module.
The basic idea is quite intuitive: when we perform weighted averaging based on different attention maps, we end up averaging the features corresponding to the difference instances of an object. This makes the feature vectors indistinguishable from the scenario where we had just one instance of the object in the image.
+
+
Even multiple glimpses (multiple attention steps) can not resolve this problem as the weights given to one feature vector would not depend on the other feature vectors (that are attended to). Hard attention could be more useful than soft-attention but there is not much empirical evidence in support of this hypothesis.
+
+
The proposed count module is a separate pipeline that can be integrated with most of the existing attention based VQA models without affecting the performance on non-count based questions.
+
+
The inputs to the count module are the attention maps and the object proposals (coming from some pre-trained model like the RCNN model) and the output is an count-feature vector which is used to answer the count based question.
+
+
The top level idea is the following - given the object proposals and the attention maps, create a graph where nodes are objects (object proposals) and edges capture how similar two object proposals are (how much do they overlap). The graph is transformed (by removing and scaling edges) so that the count of the object can be obtained easily.
+
+
To explain their methodology, the paper simplifies the setting by making two assumptions:
+
+
The first assumption is that the attention weights are either 1 (when the object is present in the proposal) or 0 (when the object is absent from the proposal).
+
The second assumption is that any two object proposals either overlap completely (in which case, they are corresponding to the exact same object and hence receive the exact same weights) or the two proposals have zero overlap (in which case, they must be corresponding to completely different objects).
+
+
+
These simplifying assumptions are made only for the sake of exposition and do not limit the capabilities of the count module.
+
+
Given the assumptions, the task of the count module is to handle the exact duplicates to prevent double-counting of objects.
+
+
As the first step, the attention weights (a) are used to generate an attention matrix (A) by performing an outer product between a and aT. This corresponds to the step of creating a graph from the input.
+
+
A corresponds to the adjacency matrix of that graph. The attention weight for the ith proposal corresponds to the ith node in the graph and the edge between the nodes i and j has the weight ai*aj.
+
+
Also note that the graph is a weighted directed graph and the subgraph of vertices satisfying the condition ai = 1 is a complete directed graph with self-loops. Given such a graph, the number of vertices, V = sqrt(E) where E could be computed by summing over the adjacency matrix.This implies that if the proposals are distinct, then the count can be obtained trivially by performing a sum over the adjacency matrix.
+
+
The objective is now to eliminate the edges such that the underlying objects are the vertices of a complete subgraph. This requires removing two type of duplicate edges - intra-object edges and inter-object edges.
+
+
Intra-object edges can be removed by computing a distance matrix, D, defined as 1 - IoU, where IoU matrix corresponds to the Intersection-over-Union matrix. A modified adjacency matrix A’ is obtained by performing the element-wise product between f1(A) and f2(D) where f1 and f2 are piece-wise linear functions that are learnt via backpropogation.
+
+
The inter-object edges are removed in the following manner:
+
+
+
Count the number of proposals that correspond of each instance of an object and then scale down the edges corresponding to the different instances by that number.
+
This creates the effect of reducing the weights of multiple proposals equivalent to a single proposal.
+
The number of proposals corresponding to an object is not available as an annotation in the training pipeline and is estimated based on the similarity between the different proposals (measured via the attention weights a, adjacency matrix A and distance matrix D).
+
The matrix corresponding to the similarity between proposals (simi, j) is transformed into a vector corresponding to the scaling factor of each node (si)
+
+
+
s can be converted into a matrix (by doing outer-product with itself) so as to scale both the incoming and the outgoing edges. The self edges (which were removed while computing A’ are added back (after scaling with s) to obtain a new transformed matrix C.
+
+
The transformed matrix C is a complete graph with self-loops where the nodes corresponds to all the relevant object instances and not to object proposals. The actual count can be obtained from C by performing a sum over all its values as described earlier. The original count problem was a regression problem but it is transformed into a classification problem to avoid scale issues. The network produces a k-hot n-dimensional vector called o where n is the number of object proposals that were feed into the module (and hence the upper limit on upto how large a number could the module count). In the ideal setting, k should be one, as the network would produce an integer value but in practice, the network produces a real number so k can be upto 2. If c is an exact integer, the output is a 1-hot vector with the value in index corresponding to c set to 1. If c is a real number, the output is a linear interpolation between two one-hot vectors (the one-hot vectors correspond to the two integers between which c lies).
+
+
count module supports computing the confidence of a prediction by defining two variables pa and pD which compute the average distance of f6(a) and $f7(D) from 0.5. The final output o’ is defined as f8(pa + pD) . o
+
+
All the different f functions are piece wise linear functions and are learnt via backpropagation.
+
+
Experiments
+
+
The authors created a new category of count-based questions by filtering the number-type questions to remove questions like “What is the time right now”. These questions do have a neumerical answer but do not fall under the purview of count based questions and hence are not targeted by the count model.
+
+
The authors augmented a state of the art VQA model with their count module and show substantial gains over the count-type questions for the VQA-v2 dataset. This augmentation does not drastically impact the performance on non-count questions.
+
+
The overall idea is quite crisp and intutive and the paper is easy to follow. It would be even better if there were some more abalation studies. For example, why are the piece-wise linear functions assumed to have 16 linear components? Would a smaller or larger number be better?
diff --git a/_site/site/2018/05/21/Net2Net-Accelerating-Learning-via-Knowledge-Transfer.html b/_site/site/2018/05/21/Net2Net-Accelerating-Learning-via-Knowledge-Transfer.html
new file mode 100644
index 00000000..3c404a37
--- /dev/null
+++ b/_site/site/2018/05/21/Net2Net-Accelerating-Learning-via-Knowledge-Transfer.html
@@ -0,0 +1,69 @@
+
Notes
+
+
+
+
The paper presents a simple yet effective approach for transferring knowledge from a trained neural network (referred to as the teacher network) to a large, untrained neural network (referred to as the student network).
+
+
+
The key idea is to use a function-preserving transformation that guarantees that for any given input, the output from the teacher network and the newly created student network would be the same.
The approach works as follows - Let us say that the teacher network was represented by the transformation y = f(x, θ) where θ refer to the parameters of the network. The task is to choose a new set of parameters θ’ for the student network g(x, θ’) such that for all x, f(x, θ) = g(x, θ’)
+
+
+
To start, we can assume that f and g are composed of standard linear layers. Layer i and i+1 are represented by weights Wmxni and Wnxpi+1
+
+
+
We want to grow layer i to have q output units (where q > n) and layer i+1 to have q input units. The new weight matrix would be Umxqi and Uqxpi+1
+
+
+
The first q columns (rows) of Wi (Wi+1) would be copied as it is into Ui(Ui+1).
+
+
+
For filling the remaining n-q slots, columns (rows) would be sampled randomly from Wi (Wi+1).
+
+
+
Finally, each layer in Ui is scaled by dividing by the corresponding replication factor to ensure that the output value of function remains unchanged by the operation.
+
+
+
Since convolutions can be seen as multiplication by a double block circulant matrix, the approach can be readily extended for convolutional networks.
+
+
+
The benefits of using this approach are the following:
+
+
+
The newly created student network performs at least as good as the teacher network.
+
Any changes to the network are guaranteed to be an improvement.
+
It is safe to optimize all the parameters in the network.
+
+
+
+
The variant discussed above is called the Net2WiderNet variant. There is another variant calledNet2DeeperNet that enables the network to grow in depth.
+
+
+
In that case, a new matrix, U, initialized as the identity matrix, is added to the network. Note that unlike the Net2WiderNet, this approach would not work with arbitrary activation function between the layers.
+
+
+
+
Strengths
+
+
+
+
The model can accelerate the training of neural networks, especially during development cycle when the designers try out different models.
+
+
+
The approach could potentially be used in life-long learning systems where the model is trained over a stream of data and needs to grow over time.
+
+
+
+
Limitations
+
+
+
The function preserving transformations need to be worked out manually. Extra care needs to be taken when operations like concatenation or batch norm are present.
+
diff --git a/_site/site/2018/06/09/Born-Again-Neural-Networks.html b/_site/site/2018/06/09/Born-Again-Neural-Networks.html
new file mode 100644
index 00000000..8cfc6968
--- /dev/null
+++ b/_site/site/2018/06/09/Born-Again-Neural-Networks.html
@@ -0,0 +1,123 @@
+
Introduction
+
+
+
+
The paper explores knowledge distillation (KD) from the perspective of transferring knowledge between 2 networks of identical capacity.
+
+
+
This is in contrast to much of the previous work in KD which has focused on transferring knowledge from a larger network to a smaller network.
+
+
+
The paper reports that these Born Again Networks (BANs) outperform their teachers by significant margins in many cases.
Start with an untrained network (or ensemble of networks) and train them for the given task. This network is referred to as the teacher network.
+
Now start with another untrained network (generally of smaller size than the teacher network) and train it using the output of the teacher network. This network is referred to as the student network.
+
+
+
+
The paper augments this setting with an extra cross-entropy loss between the output of the teacher and the student networks. The student tried to predict the correct answer while matching the output distribution of the teacher.
+
+
+
The resulting student network is referred to as BAN - Born Again Network.
+
+
+
The same approach can be used multiple times (with diminishing returns) where the kth generation student is initialized by knowledge transfer from (k-1)th generation student.
+
+
The output of multiple generation BANs are combined via averaging to produce BANE (Born Again Network Ensemble).
+
+
+
Dark Knowledge
+
+
+
+
Hinton et al suggested that even when the output of the teacher network is incorrect, it contains useful information about the similarity between the output classes. This information is referred to as the “dark knowledge”.
+
+
+
The current paper observed that the gradient of the correct output dimension during distillation and normal supervised training resembles the original gradient up to a weight factor. This sample specific weight is defined by the value of the teacher’s max output.
+
+
+
This suggests distillation may be performing some kind of importance weighing. To explore this further, the paper considers 2 cases:
+
+
+
+
Confidence Weighted By Teacher Max (CWTM) - where each example in the student’s loss function is weighted by the confidence that the teacher has on the prediction for that sample. The student incurs a higher loss if the teacher was more confident about the example.
+
+
+
Dark Knowledge with Permuted Predictions (DKPP) - The non-argmax output of teacher’s predictive distribution are permuted thus destroying the information about which output classes are related.
+
+
+
+
+
The key effect of these variations is that the covariance between the output classes is lost and classical knowledge distillation would not be sufficient to explain improvements (if any).
+
+
+
+
Experiments
+
+
Image Data
+
+
+
Datasets
+
+
CIFAR10
+
CIFAR100
+
+
+
Baselines
+
+
ResNets
+
DenseNets
+
+
+
BAN Variants
+
+
BAN-DenseNet and BAN-ResNet - Train a sequence of 2 or 3 BANs using DenseNets and ResNets. Different variants constrain BANs to be similar to their teacher or penalize l2-distance between student and teacher activations etc.
+
Two settings with CWTM and DKPP as explained earlier.
+
BAN-Resnet with DenseNet teacher and BAN-DenseNet with ResNet teacher
+
+
+
+
+
Text Data
+
+
+
Datasets:
+
+
PTB Dataset
+
+
+
Baselines
+
+
CNN-LSTM model
+
+
+
BAN Variant
+
+
LSTM
+
+
+
+
+
Results
+
+
+
BAN student models improved over their teachers in most of the configurations.
+
Training BANs across multiple generations leads to saturating improvements.
+
The student models exhibit improvements even in the control settings (CWTM and DKPP).
+
+
One reason could be that the permutation procedure did not remove the higher order moments of output distribution.
+
Improvements in the CWTM model suggests that the pre-trained models can be used to rebalance the training set by giving lesser weight for samples where the teacher’s output distribution is more spread.
+
+
+
+
diff --git a/_site/site/2018/07/04/Memory-Based-Parameter-Adaption.html b/_site/site/2018/07/04/Memory-Based-Parameter-Adaption.html
new file mode 100644
index 00000000..cd9ed18a
--- /dev/null
+++ b/_site/site/2018/07/04/Memory-Based-Parameter-Adaption.html
@@ -0,0 +1,146 @@
+
Introduction
+
+
+
+
Standard Deep Learning networks are not suitable for continual learning setting as the change in the data distribution leads to catastrophic forgetting.
+
+
+
The paper proposes Memory-based Parameter Adaptation (MbPA), a technique that augments a standard neural network with an episodic memory (containing examples from the previous tasks).
+
+
+
This episodic memory allows for rapid acquisition of new knowledge (corresponding to the current task) while preserving performance on the previous tasks.
f and g are parametric components while M is a non-parametric component.
+
+
+
M is a dynamically sized dictionary where the key represents the output of the embedding network and the value represents the desired output for a given input (input to the model).
+
+
+
When a new training tuple (xj, yj) is fed as input to the model, a key-value pair (hj, vj) is added to the memory. hj = f(xj)
+
+
+
The memory has a fixed size and acts as a circular buffer. When it gets filled up, earlier examples are dropped.
+
+
+
When accessing the memory using a key hkey, the k-nearest neighbours (in terms of distance from the given key) are retrieved.
+
+
+
+
Training Phase
+
+
+
During the training phase, the memory is only used to store the input examples and does not interfere with the training procedure.
+
+
+
Testing Phase
+
+
+
+
During testing, the memory is used to adapt the parameters of the output network g while the embedding network f remains the same.
+
+
+
Given the input x, obtain the embedding corresponding to x and using that as the key, retrieve the k-nearest neighbours from the memory.
+
+
+
Each retrived neighbour is a tuple of the form (hk, vk, wk) where wk is propotional to the closeness between the input query and the key corresponding to the retrived example.
+
+
+
The collection of all the retrieved examples are referred to as the context C.
+
+
+
The parameters of the output network g are adapted from θ to θx where θx = θ + δM(x, θ)
+
+
+
δM(x, θ) is referred to as the contextual update of parameters of the output network.
+
+
+
+
Interpretation of MbPA
+
+
+
+
MbPA can be interpreted as decreasing the weighted average of negative log likelihood over the retrieved neighbours in the context C.
+
+
+
The expression corresponding to δM(x, θ) can be obtained by performing gradient descent to minimise the max a posterior over the context C.
+
+
+
The a posterior expression can be written as a sum of two terms - one corresponding to a weighted likelihood of data in the context C and the other corresponding to a regularisation term to prevent overfitting the data.
+
+
+
This idea can be thought of as a generalisation of attention. Attention can be viewed as fitting a constant function over the neighbourhood of memories while MbPA fits a more general function which is parameterised by the output network of the given model. Refer appendix E in the paper for further details.
+
+
+
+
Experiments
+
+
+
+
MbPA aims to solve the fundamental problem of enabling the model to deal with changes in data distribution.
+
+
+
In that sense, it is evaluated on a wide range of settings: continual learning, incremental learning, unbalanced datasets and change in data distribution at test time.
+
+
+
Continual Learning:
+
+
+
+
In this setting, the model encounters a sequence of tasks and cannot revisit a previous task.
+
+
+
Permuted MNIST dataset was used.
+
+
+
The key takeaway is that once a task is catastrophically forgotten, only a few gradient updates on a carefully selected data, are sufficient to recover the performance.
+
+
+
+
+
Incremental Learning:
+
+
+
+
In this setting, the model is trained on a subset of classes and then introduced to novel, unseen classes. The model is tested to see if it can incorporate the new knowledge while retaining the knowledge about the previous classes.
+
+
+
Imagenet dataset with Resnet V1 model is used. It is first pretrained on 500 classes and then fine-tuned to see how quickly could it adapt to new classes.
+
+
+
+
+
Unbalanced Dataset:
+
+
+
This setting is similar to the incremental learning setting with the key difference that once the model has been trained on a part of the dataset and is to be finetuned to acquire new knowledge, the dataset used for finetuning is much smaller than the initial dataset thus creating the effect of unbalanced datasets.
+
+
+
+
Language Modelling:
+
+
+
MbPA is used to adapt to the shift in the word distribution that is common to language modelling tasks. PTB and WikiText datasets were used.
+
+
+
+
MbPA exhibits strong performance on all these tasks showing that the memory-based parameter adaption technique is effective across a range of tasks in supervised learning.
+
+
diff --git a/_site/site/2018/07/11/Learning-Independent-Causal-Mechanisms.html b/_site/site/2018/07/11/Learning-Independent-Causal-Mechanisms.html
new file mode 100644
index 00000000..dc2757e3
--- /dev/null
+++ b/_site/site/2018/07/11/Learning-Independent-Causal-Mechanisms.html
@@ -0,0 +1,124 @@
+
Introduction
+
+
+
+
The paper presents a very interesting approach for learning independent (inverse) data transformation from a set of transformed data points in an unsupervised manner.
We start with a given data distribution P (say the MNIST dataset) where each x ε Rd.
+
+
+
Consider N transformations M1, …, MN (functions that map input x to transformed input x’). Note that N need not be known before hand.
+
+
+
These transformations can be thought of as independent (from other transformations) causal mechanisms.
+
+
+
Applying these transformation would give N new distributions Q1, …, QN.
+
+
+
These individual distributions are combined to form a single transformed distribution Q which contains the union of samples from the individual distributions.
+
+
+
At training time, two datasets are created. One dataset corresponds to untransformed objects (sampled from P), referred to as DP. The other dataset corresponds to samples from the transformed distribution Q and is referred to as DQ.
+
+
+
Note that all the samples in DP and DQ are sampled independently and no supervising information is needed.
+
+
+
A series of N’ parametric models, called as experts, are initialized and would be trained to learn the different mechanisms.
+
+
+
For simplicity, assume that N = N’. If N > N’, some experts would learn more than one transformation or certain transformations would not be learnt. If N < N’, some experts would not learn anything or some experts would learn the same distribution. All of these cases can be diagnosed and corrected by changing the number of experts.
+
+
+
The experts are trained with the goal of maximizing an objective parameter c: Rd to R. c takes high values on the support of P and low values outside.
+
+
+
During training, an example xQ (from DQ) is fed to all the experts at the same time. Each expert produces a value cj = c(Ej(xQ))
+
+
+
The winning expert is the one whose output is the max among all the outputs. Its parameters are updated to maximise its output while the other experts are not updated.
+
+
+
This forces the best performing model to become even better and hence specialize.
+
+
+
The objective c comes from adversarial training where a discriminator network discriminates between the untransformed input and the output of the experts.
+
+
+
Each expert can be thought of as a GAN that conditions on the input xQ (and not on a noise vector). The output of the different experts is fed to the discriminator which provides both a selection mechanism and the gradients for training the experts.
+
+
+
+
Experiments
+
+
+
+
Experiments are performed on the MNIST dataset using the transformations like translation along 4 directions and along 4 diagonals, contrast shift and inversion.
+
+
+
The discriminator is further trained against the output of all the losing experts thereby furthering strengthing the winning expert.
+
+
+
+
Approximate Identity Initialization
+
+
+
+
The experts are initialized randomly and then pretrained to approximate the identity function by training with identical input-output pairs.
+
+
+
This ensures that the experts start from a similar level.
+
+
+
In practice, it seems necessary for the success of the proposed approach.
+
+
+
+
Observations
+
+
+
+
During the initial phase, there is a heavy competition between the experts and eventually different winners emerge for different transformations.
+
+
The approximate quality of reconstructed output was also evaluated using a downstream task.
+
+
3 type of inputs were created:
+
+
Untransformed images
+
Transformed images
+
Transformed images a being processed by experts.
+
+
+
These inputs are fed to a pretrained MNISTN classifier.
+
The classifier performs poorly on the transformed images while the performance for images processed by experts quickly catches up with the performance on untransformed images.
+
+
+
The experts Ei generalize on the data points from a different dataset as well.
+
+
To test the generalisation capabilities of the expert, a sample of data from the omniglot dataset is transformed and fed to experts (which are trained only on MNIST).
+
Each expert consistently applies the same transformation even though the inputs are outside the training domain.
+
This suggests that the experts have generalized to different transformations irrespective of the underlying dataset.
+
+
+
+
+
Comments
+
+
+
+
The experiments are quite limited in terms of complexity of dataset and complexity of transformation but it provides evidence for a promising connection between deep learning and causality.
+
+
+
Appendix mentions that in case there are too many experts, for most of the tasks, only one model specialises and the extra experts do not specialize at all. This is interesting as there is no explicit regularisation penalty which prevents the emergence of multiple experts per task.
+
+
diff --git a/_site/site/2018/07/19/Kronecker-Recurrent-Units.html b/_site/site/2018/07/19/Kronecker-Recurrent-Units.html
new file mode 100644
index 00000000..a88eb6ca
--- /dev/null
+++ b/_site/site/2018/07/19/Kronecker-Recurrent-Units.html
@@ -0,0 +1,156 @@
+
Introduction
+
+
+
+
Recurrent Neural Networks have two key issues:
+
+
+
+
Over parameterization which increases the time for training and inference.
+
+
+
Ill conditioned recurrent weight matrix which makes training difficult due to vanishing or exploding gradients.
+
+
+
+
+
The paper presents a flexible RNN model called as KRU (Kronecker Recurrent Units) which overcomes the above problems by using a Kronecker factored recurrent matrix and soft unitary constraints on the factors.
Training a neural network on the soft targets predicted by a big pre-trained network.
+
+
+
Low-bit precision training.
+
+
+
Hashing.
+
+
+
+
Existing solutions for vanishing and exploding gradients
+
+
+
+
Gating mechanism like in LSTMs.
+
+
+
Gradient Clipping.
+
+
+
Orthogonal Weight Initialization.
+
+
+
Parameterizing recurrent weight matrix.
+
+
+
+
KRU
+
+
+
+
Uses a Kronecker factored recurrent matrix which enables controlling the number of parameters and number of factor matrices.
+
+
+
Vanishing and exploding gradients are taken care of by using a soft unitary constraint.
+
+
+
Why not use strict unitary constraint:
+
+
+
+
Restricts the search space and makes learning process unstable.
+
+
+
+
Makes forgetting (irrelevant) information difficult.
+
+
+
Relaxing the strict constraint has shown to improve the convergence speed and generalization performance.
+
+
+
+
+
+
+
KRU can be easily plugged into RNNs, LSTMs and other variants.
+
+
+
The recurrent matrix W is paramterized as a kronecker product of F matrices W0, …, WF-1 where each Wf is a complex matrix of shape Pf x Qf and the product of all Pf and producto of all Qf are both equal to N.
+
+
+
Why is W a complex matrix?
+
+
+
+
In the real space, the set of all unitary matrices have the determinant as 1 or -1.
+
+
+
+
Given that determinant is a continuous function, the unitary set in the real space is disconnected.
+
+
+
The unitary set in the complex space is connected as its determinants are points on the unit circle.
+
+
+
+
+
+
+
+
Soft Unitary Constraint
+
+
+
+
+
+
+
A soft unitary constraint is introduced in the form of regularization term
+
+
WfHWf - I
+
+
2 (per kronecker factored recurrent matrix).
+
+
+
+
+
+
If each of the Kronecker factors is unitary, the resulting matrix W would also be unitary.
+
+
+
It is computationally inefficient to apply this constraint over the recurrent matrix W itself as the complexity of the regularizer is given as O(N3).
+
+
Use of Kronecker factorisation makes it computationally feasible to use this regulariser.
+
+
+
Experiment
+
+
+
+
The Kronecker recurrent model is compared against the existing recurrent models for multiple tasks including copy memory, adding memory, pixel-by-pixel MNIST, char level language models, polyphonic music modelling, and framewise phoneme classification.
+
+
+
For most of the task, KRU model produces results comparable to the best performing models despite using fewer parameters.
+
+
+
Using soft unitary constraints in KRU provides a principled alternative to gradient clipping (a common heuristic to avoid exploding gradients).
+
+
+
Further, recent theoretical results suggest the gradient descent converges to a global optimizer of linear recurrent networks even if the learning problem is non-convex provided that the spectral norm of the recurrent matrix is bound by 1.
+
+
+
The key take away from the paper is that state should be high dimensional so that high capacity network can be used for encoding and decoding the input and output. The recurrent dynamics should be implemented via a low capacity model.s per task.
+
+
diff --git a/_site/site/2018/08/08/Imagination-Augmented-Agents-for-Deep-Reinforcement-Learning.html b/_site/site/2018/08/08/Imagination-Augmented-Agents-for-Deep-Reinforcement-Learning.html
new file mode 100644
index 00000000..2a9e77e7
--- /dev/null
+++ b/_site/site/2018/08/08/Imagination-Augmented-Agents-for-Deep-Reinforcement-Learning.html
@@ -0,0 +1,82 @@
+
+
+
The paper presents I2A (Imagination Augmented Agent) that combines the model-based and model-free approaches leading to data efficiency and robustness even with imperfect models.
+
+
+
I2A agent uses the predictions from a learned environment model as an additional context in deep policy networks. This leads to improved data efficiency and robustness to imperfect models.
I2A agent has two main modules - Imagination module and the Policy module.
+
+
+
Imagination Module
+
+
+
Environment Model
+
+
This is a recurrent model, trained in an unsupervised manner using the agent trajectories. It can be used to predict the future state given the current state and action.
+
The environment model can be rolled out multiple times to obtain a simulated trajectory or an “imagined” trajectory.
+
During each rollout, the actions are chosen using a rollout policy πr.
+
+
+
Rollout Encoder
+
+
A rollout encoder E (LSTM) is used to process the entire imagined rollout.
+
+
+
The imagination module is used to generate n trajectories. Each trajectory is a sequence of outputs of the environment model.
+
These n trajectories are concatenated into a single “imagination” vector.
+
The training data for the environment model is generated from trajectories of a partially trained model-free agent.
+
Pretraining the environment model (instead of joint training with policy) leads to faster runtime.
+
+
+
+
Policy Module
+
+
+
This module uses the output of both model-based path and model-free path as its input. It generates the policy vector and value function.
+
+
+
Rollout Strategy
+
+
One rollout is performed for each possible action in the environment ie, the first action in the ith rollout is the ith action in the action set.
+
Subsequent actions are generated using a shared rollout policy π’
+
An effective strategy was to create a small model-free network π’(ot) and then add a KL loss component that encourages π’(ot)to be similar to the imagination augmented policy π(ot).
+
+
+
Baselines
+
+
Model-free agent
+
Copy-model agent - same as I2A but the environment model is replaced by a “copy” model that just returns the input observations.
+
+
+
Environments
+
+
Sokoban
+
+
Task is to push a number of boxes onto given target locations.
+
I2A outperforms the baselines and gains in performance as the number of unrolling steps increases (though at a diminishing rate).
+
In case of poor environment models, the agent seems to be able to ignore the later part of the rollout when the error starts to accumulate.
+
Monte Carlo search algorithm (without an explicit rollout encoder) performed poorly as compared to the model using rollout encoder.
+
Predicting the reward along with value function and action seems to speed up training.
+
If a near-perfect model is available, I2A agent’s performance can be improved by performing Monte Carlo search with the trained I2A agent for the rollout policy. The agent plays entire episodes in simulation and tries to find a successful action sequence within 10 retries.
+
+
+
MiniPacman
+
+
I2A agent is evaluated to see if a single model can be used to solve multiple tasks.
+
A new environment is designed to define multiple tasks in an environment with shared state transitions.
+
Each task is specified by a 5-dimensional reward vector that associates a reward with moving, eating food, eating a pill, eating a ghost and being eaten by a ghost.
+
A single environment model is trained to predict both observations (frames) and events (eg “eating a pill”). This way, the environment model is shared across all tasks.
+
Baseline agents and I2As are trained on each task separately. I2A architecture outperforms the standard agent in all tasks and the copy-model
+baseline in all but one task.
+
The improvement in performance is higher for tasks where rewards are sparse and where the anticipation
+of ghost dynamics is especially important indicating that the I2A agent can use the environment model to explore the environment more effectively.
+
+
+
+
+
diff --git a/_site/site/2018/08/16/Hierarchical-Graph-Representation-Learning-with-Differentiable-Pooling.html b/_site/site/2018/08/16/Hierarchical-Graph-Representation-Learning-with-Differentiable-Pooling.html
new file mode 100644
index 00000000..db40fe91
--- /dev/null
+++ b/_site/site/2018/08/16/Hierarchical-Graph-Representation-Learning-with-Differentiable-Pooling.html
@@ -0,0 +1,133 @@
+
Introduction
+
+
+
+
Most existing GNN (Graph Neural Network) methods are inherently flat and are unable to process the information in a hierarchical manner.
+
+
+
The paper proposes a differentiable graph pooling operation, DIFFPOOL, that can generate hierarchical graph representations and can be easily plugged into many GNN architectures.
CNNs have spatial pooling operation that allows for deep CNN architectures to operate on coarse graph representations of input images.
+
+
+
This notion cannot be applied as-is to graphs as they do not have a natural notion of spatial locality like images do.
+
+
+
DIFFPOOL attempts to resolve this problem by learning a differentiable soft-assignment at each layer which is equivalent to pooling the cluster of nodes to obtain a sparse representation.
+
+
+
+
Approach
+
+
+
+
Given a graph G(A, F), where A is the adjacency matrix and F is the feature matrix.
+
+
+
Given a permutation invariant GNN that follows the message passing architecture. The output of this GNN can be expressed as Z = GNN(A, X) where X is the current feature matrix.
+
+
+
Goal is to stack L GNN layers on top of each other such that the lth layer uses coarsened output from the (l-1)th layer.
+
+
+
This coarsening operation uses a cluster assignment matrix S.
+
+
+
The learned cluster assignment matrix at layer l is denoted at Sl
+
+
+
Given Sl, the embedding matrix for the (l+1)th layer is given as transpose(Sl)Zl and adjancecy matrix is given by transpose(Sl)AlSl
+
+
+
A new GNN, called as GNNpool is used to produce the assignment matrix S by taking a softmax over GNNpool(Al, Xl)
+
+
+
As long as the GNN model is permutation invariant, the resulting DIFFPOOL model is also permutation invariant.
+
+
+
+
Auxiliary Losses
+
+
+
+
The paper uses 2 auxiliary losses to push the model away from spurious local minima early in the training.
+
+
+
Link prediction objective - at each layer, link prediction loss ( = A - S(transpose(S))) is minimized with the intuition that the nearby nodes should be pooled together.
+
+
+
Ideally, the cluster assignment for each node should be a one-hot vector so the entropy for cluster assignment per node is regularized.
+
+
+
+
Baselines
+
+
+
GNN based models
+
+
GraphSage
+
+
Mean pooling
+
Set2Set pooling
+
Sort pooling
+
+
+
Structure2vec
+
Edge conditioned filters in CNN
+
PatchySan
+
+
+
Kernel based models
+
+
Graphlet, shortest path etc
+
+
+
+
+
Model Variants
+
+
+
GraphSage
+
+
Mean pool + Diff pool (3 or 2 layers)
+
+
+
Structure2Vec + Diffpool
+
Diffpool-Det
+
+
The assignment matrix S are generated using graph clustering algorithms.
+
+
+
Diffpool-NoLP
+
+
The link prediction objective function is turned off.
+
+
+
At each DiffPool layer, the number of classes is set to 25% of the number of nodes before the DiffPool layer.
+
+
+
Results
+
+
+
+
DiffPool obtains the highest average performance across all the pooling approaches and improves upon the base GraphSage architecture by an average of around 7%.
+
+
+
In terms of runtime complexity, the paper reports that DiffPool does not incur any significant additional running time. But given that now there are 2 GNN models per layer, the size of the model should increase.
+
+
+
DiffPool can capture hierarchical community structure even when trained on just the graph classification loss.
+
+
+
One advantage of DiffPool is that the nodes are pooled in a non-uniform way so densely connected group of nodes would collapse into one cluster while sparsely connected nodes can retain their identity.
+
+
diff --git a/_site/site/2018/08/21/A-Semantic-Loss-Function-for-Deep-Learning-with-Symbolic-Knowledge.html b/_site/site/2018/08/21/A-Semantic-Loss-Function-for-Deep-Learning-with-Symbolic-Knowledge.html
new file mode 100644
index 00000000..e2421dff
--- /dev/null
+++ b/_site/site/2018/08/21/A-Semantic-Loss-Function-for-Deep-Learning-with-Symbolic-Knowledge.html
@@ -0,0 +1,155 @@
+
Introduction
+
+
+
+
The paper proposes an approach for using symbolic knowledge in deep learning systems. These constraints are often expressed as boolean constraints on the output of the deep learning system and directly incorporating these constraints break the differentiability of the system.
The model is given some input data to perform predictions and symbolic knowledge is provided in form of boolean constraints like exactly-one constraint for one-hot output encoding.
+
+
+
Most approaches tend to encode the symbolic knowledge in the vector space embedding to keep the model pipeline differentiable. In this process, the precise meaning of symbolic knowledge is often lost.
+
+
+
A differentiable “semantic loss” is derived which captures the meaning of the constraint while being independent of its syntax.
+
+
+
+
Terminology
+
+
+
+
A state x (state refers to the instantiation of boolean variables) satisfies a sentence a if a evaluates to true when using the variables as specified by x.
+
+
+
A sentence a entails another sentence b if all states that satisfy a also satisfy b.
+
+
+
The row output vector of the neural network is denoted as p where each value in p denotes the probability of an output.
+
+
+
Three different output constraints are studied:
+
+
+
+
Exactly-one constraint
+
+
+
Exactly one value in p should be true.
+
Can be expressed in boolean logic as follows: Let (x1, x2, …, xn) be variables in p. Then (not xi or not xj) for all pair of variables and (x1 or x2 or … xn).
+
+
+
Valid Simple Path Constraint
+
+
Set of edges must form a valid path.
+
+
+
Ordering Constraint
+
+
Defining an ordering over the variables.
+
+
+
+
+
+
+
Semantic Loss
+
+
+
+
The semantic loss Ls(a, p) is a function of a propositional logic sentence a (the symbolic knowldge constraint) and p (output of the neural network).
+
+
+
a is defined over variables (x1, …, xn) and p is interpreted as a vector of probabilities corresponding to these variables xi’s.
+
+
+
The semantic loss is directly proportional to the negative log likelihood of generating a state that satisfies the constraints when sampling values according to the distribution p.
+
+
+
+
Main Axioms and Insights
+
+
+
Monotonicity
+
+
If a sentence a entails another sentence b then for any given p, Ls(a, p) > Ls(b, p) ie adding more constraints cannot decrease the semantic loss.
+
+
+
Semantic Equivalence
+
+
If two sentences are logically equivalent, their semantic loss is the same.
+
+
+
Identity
+
+
For any given sentence a, its representation as a sentence is equivalent to its representation as a deterministic vector ie writing the “one-hot” constraint as a boolean expression is equivalent to a one-hot vector.
+
+
+
Satisfaction
+
+
If p entails the sentence a then Ls(a, p) = 0.
+
+
+
Label-literal correspondence
+
+
When the constraint is defined in terms of a single variable, it can be interpreted as the supervised label.
+
Hence the semantic loss in case of a single variable should be equivalent to the cross-entropy loss.
+
+
+
Truth
+
+
The semantic loss of a true sentence is 0
+
+
+
Non-negativity
+
+
Semantic loss should always be non-negative.
+
+
+
+
Probabilities of variables that are not part of the constraint, do not affect the semantic loss.
+
+
It can be shown that the semantic loss function satisfies all these axioms (and the other axioms specified in the paper) and is the only function to do so, up to a multiplicative constant.
+
+
+
Experimental Evaluation
+
+
+
+
Semantic Loss is used in the semi-supervised setting for Permuted MNIST, Fashion MNIST and CIFAR-10.
+
+
+
The key takeaway is that using semantic loss improves the performance of the state-of-the-art models for Fashion MNIST and CIFAR-10.
+
+
+
One downside is that the effectiveness of the semantic loss in this type of constraint strongly depends on the performance of the underlying model. Further, the semantic loss does not improve the performance in case of fully supervised scenario.
+
+
+
Further experiments are performed to evaluate the performance of the semantic loss on complex constraints. Since these tasks aim to highlight the effect of using semantic loss, only simple models (MLPs) are evaluated.
+
+
+
+
Tractability of Semantic Loss
+
+
+
+
The semantic loss is similar to the automated reasoning task called as weight model counting (wmc).
+
+
+
Circuit compiler techniques can be used to compute wmc while allowing backpropagation.
+
+
+
+
Notes
+
+
+
The proposed idea is simple and intuitive and the results on semi-supervised classification task are quite good. It would be interesting to extend and scale this method for more complex constraints.
+
diff --git a/_site/site/2018/09/12/Emergence-of-Grounded-Compositional-Language-in-Multi-Agent-Populations.html b/_site/site/2018/09/12/Emergence-of-Grounded-Compositional-Language-in-Multi-Agent-Populations.html
new file mode 100644
index 00000000..96d69bb8
--- /dev/null
+++ b/_site/site/2018/09/12/Emergence-of-Grounded-Compositional-Language-in-Multi-Agent-Populations.html
@@ -0,0 +1,121 @@
+
Introduction
+
+
+
+
The paper provides a multi-agent learning environment and proposes a learning approach that facilitates the emergence of a basic compositional language.
+
+
+
The language is quite rudimentary and is essentially a sequence of abstract discrete symbols. But it does comprise of a defined vocabulary and syntax.
Cooperative, partially observable Markov game (multi-agent extension of MDP).
+
+
+
All agents have identical action and observation spaces, use the same policy and receive a shared reward.
+
+
+
+
Grounded Communication Environment
+
+
+
+
Physically simulated 2-D environment in continuous space and discrete time with N agents and M landmarks.
+
+
+
The agents and the landmarks would occupy some location and would have some attributes (colour, shape).
+
+
+
Within the environment, the agents can go to a location, look at a location or do nothing. Additionally, they can utter communication symbols c (from a shared vocabulary C). Agents themselves learn to assign a meaning to the symbols.
+
+
+
Each agent has an internal goal (which could require interaction with other agents to complete) which the other agents cannot see.
+
+
+
Goal for agent i consists of an action to perform, a landmark location where to perform the action and another agent who should be performing the action.
+
+
+
Since the agent is continuously emitting symbols, a memory module is provided and simple additive memory updates are done.
+
+
+
For interaction, the agents could use verbal utterances, non-verbal signals (gaze) or non-communicative strategies (pushing other agents).
+
+
+
+
Approach
+
+
+
+
A model of all agent and environment state dynamics is created over time and the return gradient is computed.
+
+
+
Gumbel-Softmax distribution is used to obtain categorical word emission c.
+
+
+
A multi-layer perceptron is used to model the policy which returns action, communication symbol and the memory update for each agent.
+
+
+
Since the number of agents (and hence the number of communication streams etc) can vary across instantiations, an identical model is instantiated per agent and per communication stream.
+
+
+
The output of individual processing modules are pooled into feature vectors corresponding to communication and physical observations. These pooled features and the goal vectors are fed to the final processing module from which actions and categorical symbols are sampled.
+
+
+
In practice, using an additional task (each agent predicts the goal for another agent) encouraged more meaningful communication utterances.
+
+
+
+
Compositionality and Vocabulary Size
+
+
+
+
Authors recommend using a large vocabulary with a soft penalty that discourages use of too many words. This leads to use of a large vocabulary in the intermediate state which converges to a small vocabulary.
+
+
+
Along the lines of rich gets richer dynamics, the communication symbol c’s are modelled as being generated by a Dirichlet process. The resulting reward across all agents is the log-likelihood of all communication utterances to have been generated by a Dirichlet process.
+
+
+
Since the agents can only communicate in discrete symbols and do not have a global positioning reference, they need to unambiguously communicate landmark references to other agents.
+
+
+
+
Case I - Agents can not see each other
+
+
+
+
Non-verbal communication is not possible.
+
+
+
When trained with just 2 agents, symbols are assigned for each landmark and action.
+
+
+
As the number of agents is increased, additional symbols are used to refer to agents.
+
+
+
If the agents of the same colour are asked to perform conflicting tasks, they perform the average of conflicting tasks. If distractor locations are added, the agents learn to ignore them.
+
+
+
+
Non-verbal communication
+
+
+
+
Agents are allowed to observe other agents’ position, gaze etc.
+
+
+
Now the location can be pointed to using gaze.
+
+
+
If gaze is disabled, the agent could indicate the goal landmark by moving to it.
+
+
+
Basically even when the communication is disabled the agents can come up with strategies to complete the task.
+
+
diff --git a/_site/site/2018/09/27/HoME-a-Household-Multimodal-Environment.html b/_site/site/2018/09/27/HoME-a-Household-Multimodal-Environment.html
new file mode 100644
index 00000000..a5964df2
--- /dev/null
+++ b/_site/site/2018/09/27/HoME-a-Household-Multimodal-Environment.html
@@ -0,0 +1,103 @@
+
Introduction
+
+
+
+
Environment for learning using modalities like vision, audio, semantics, physics and interaction with objects and other agents.
Humans learn by interacting with their surroundings (environment).
+
+
+
Similarly training an agent in an interactive multi-model environment (virtual embodiment) could be useful for a learning agent.
+
+
+
+
Characteristics
+
+
+
+
Open-source and Open-AI gym compatible
+
+
+
Built on top of 45000 3D house layouts from SUNCG dataset.
+
+
+
Provides both 3D visual and audio recording.
+
+
+
Semantic image segmentation and langauge description of objects.
+
+
+
+
Components
+
+
+
+
Rendering Engine
+
+
+
+
Implemented using Panda 3D game engine.
+
+
+
Renders RGB+depth scenes based on textures, multi-source lightings and shadows.
+
+
+
+
+
Acoustic Engine
+
+
+
+
Implemented using EVERT
+
+
+
Supports multiple microphones, sound sources, sound absorption based on material, atmospheric conditions etc.
+
+
+
+
+
Semantics Engine
+
+
+
Provides a short textual description for each object, along with information like color, category, material size, location etc.
+
+
+
+
Physics Engine
+
+
+
+
Implemented using Bullet3 Engine
+
+
+
Supports physical interaction, external forces like gravity and position and velocity information for multiple agents.
+
+
+
+
+
+
Potential Applications
+
+
+
+
Visual Question Answering
+
+
+
Conversational Agents
+
+
+
Training an agent to follow instructions
+
+
+
Multi-agent communication
+
+
diff --git a/_site/site/2018/10/04/When-Recurrent-Models-Don-t-Need-To-Be-Recurrent.html b/_site/site/2018/10/04/When-Recurrent-Models-Don-t-Need-To-Be-Recurrent.html
new file mode 100644
index 00000000..4f9bbcbf
--- /dev/null
+++ b/_site/site/2018/10/04/When-Recurrent-Models-Don-t-Need-To-Be-Recurrent.html
@@ -0,0 +1,62 @@
+
Introduction
+
+
+
+
The paper explores “if a well behaved RNN can be replaced by a feed-forward network of comparable size without loss in performance.”
+
+
+
“Well behaved” is defined in terms of control-theoretic notion of stability. This roughly requires that the gradients do not explode over time.
+
+
+
The paper shows that under the stability assumption, feedforward networks can approximate RNNs for both training and inference. The results are empirically validated as well.
Consider a general, non linear dynamical system given by a differential state transition map Φw. The hidden ht = Φw(ht-1, xt).
+
+
+
Assumptions:
+
+
+
Φ is smooth in w and h.
+
h0 = 0
+
Φw(0, 0) = 0 (can be ensured by translation)
+
+
+
+
Stable models are the ones where Φ is contractive ie Φw(h, x) - Φw(h’, x) is less than Λ * (h - h’)
+
+
+
For example, in RNN, stability would require that norm(w) is less than (Lp)-1 where Lp is the Lipschitz constant of the point-wise non linearity used.
+
+
+
The feedforward approximation uses a finite context (of length k) and is a truncated model.
+
+
+
A non-parametric function f maps the output of the recurrent model to prediction. If f is desired to be a parametric model, its parameters can be pushed to the recurrent model.
+
+
+
+
Theoretical Results
+
+
+
+
For a Λ-contractive system, it can be proved that for a large k (and additional Lipschitz assumptions) the difference in prediction between the recurrent and truncated mode is negligible.
+
+
+
If the recurrent model and truncated feed-forward network are initialized at the same point and trained over the same input for N-step, then for an optimal k, the weights of the two models would be very close in the Euclidean space. It can be shown that this small difference does not lead to large gradient differences during subsequent update steps.
+
+
+
This can be roughly interpreted as - if the gradient descent can train a stable recurrent network, it can also train a feedforward model and vice-versa.
+
+
+
The stability condition is important as, without that, truncated models would be bad (even for large values of k). Further, it is difficult to show that gradient descent converges to a stationary point.
+
+
diff --git a/_site/site/2018/10/11/Poincare-Embeddings-for-Learning-Hierarchical-Representations.html b/_site/site/2018/10/11/Poincare-Embeddings-for-Learning-Hierarchical-Representations.html
new file mode 100644
index 00000000..7ac9211d
--- /dev/null
+++ b/_site/site/2018/10/11/Poincare-Embeddings-for-Learning-Hierarchical-Representations.html
@@ -0,0 +1,130 @@
+
Introduction
+
+
+
+
Much of the work in representation leaning uses Euclidean vector spaces to embed datapoints (like words, nodes, entities etc).
+
+
+
This approach is not effective when data has a (latent) hierarchical structure.
+
+
+
The paper proposes to compute the embeddings in the hyperbolic space so as to preserve both the similarity and structure information.
Hyperbolic spaces are spaces with a constant negative curvature while Euclidean spaces have zero curvature.
+
+
+
The hyperbolic disc area and circle length increase exponentially with the radius r while in Euclidean space, it increases quadratically and linearly respectively.
+
+
+
This makes the hyperbolic space more suitable for embedding tree-like structures where the number of nodes increases as we move away from the root.
+
+
+
Hyperbolic spaces can be thought of as the continuous version of trees and trees can be thought of as the discrete version of hyperbolic spaces.
+
+
+
+
Poincare Embeddings
+
+
+
+
Poincare model is one of the several possible models of the hyperbolic space and is considered here as it is more amenable to gradient-based optimisation.
+
+
+
Distance between 2 pints change smoothly and is symmetric. Thus the hierarchical organisation only depends on the distance from the origin which makes the model applicable in settings where the hierarchical structure needs to be inferred from the data.
+
+
+
Eventually the norm of a point represents its hierarchy and distance between the points represents similarity.
+
+
+
+
Optimization
+
+
+
RSGD (Riemannian SGD) method is used.
+
Riemannian gradients can be computed from the Euclidean gradients by rescaling with the inverse of the Poincare ball metric tensor.
+
The embeddings are constrained to be within the Poincare ball by projection operation which normalizes the magnitude of embeddings to be 1.
+
+
+
Training Details
+
+
+
Initializing the embeddings close to 0 (by sampling uniformly from (-0.001, 0.001)) helps.
+
The model is trained for an initial burn-out period of 10 epochs with 0.1 times the learning rate so as to find a better initial angular layout.
+
+
+
Evaluation
+
+
+
+
Embedding taxonomy for wordnet task
+
+
+
+
Setup
+
+
+
Reconstruction
+
Link Prediction
+
+
+
+
The input data is a collection of a pair of words (u, v) which are related to each other.
+
+
+
For each word pair, 10 negative samples of the form (u, v’) are sampled and the training procedure uses a soft ranking loss that aims to bring the related objects closer together.
+
+
+
+
+
Network Embedding
+
+
+
+
Baselines
+
+
+
Euclidean Embeddings
+
Translational Embedding where a relation vector corresponding to the edge type is also learnt.
+
+
+
+
Datasets
+
+
+
ASTROPH
+
CONDMAT
+
GRQC
+
HEPPH
+
+
+
+
+
+
Lexical Entailment
+
+
+
+
* Hyperlex - Gold standard to evaluate how well the semantics models capture lexical entailment on a scale of [0, 10].
+
+* The key takeaway is that for all the datasets/setups, hyperbolic embeddings give a performance benefit when the embedding dimension is small.
+
+
+
Challenges
+
+
+
+
Hyperbolic embeddings are not suitable for all the datasets. Eg if the dataset is not tree-like or has cycles.
+
+
+
Hyperbolic embeddings are difficult to optimize as each operation needs to be modified to be usable in the hyperbolic space.
+
+
diff --git a/_site/site/2018/10/18/BabyAI-First-Steps-Towards-Grounded-Language-Learning-With-a-Human-In-the-Loop.html b/_site/site/2018/10/18/BabyAI-First-Steps-Towards-Grounded-Language-Learning-With-a-Human-In-the-Loop.html
new file mode 100644
index 00000000..b9642c52
--- /dev/null
+++ b/_site/site/2018/10/18/BabyAI-First-Steps-Towards-Grounded-Language-Learning-With-a-Human-In-the-Loop.html
@@ -0,0 +1,154 @@
+
Introduction
+
+
+
+
BabyAI is a research platform to investigate and support the feasibility of including humans in the loop for grounded language learning.
+
+
+
The setup is a series of levels (of increasing difficulty) to train the agent to acquire a synthetic language (Baby Language) which is a proper subset of English language.
BabyAI platform provides support for curriculum learning and interactive learning as part of its human-in-the-loop training setup.
+
+
+
Curriculum learning is incorporated by having a curriculum of levels of increasing difficulty.
+
+
+
Interactive learning is supported by including a heuristic expert which can provide new demonstrations on the fly to the learning agent.
+
+
+
The heuristic expert can be thought of as the human-in-the-loop which can guide the agent through the learning process.
+
+
+
One downside of human-in-the-loop is the poor sample complexity of the learning agent. The heuristic agent can be used to estimate the sample efficiency.
+
+
+
+
Contribution
+
+
+
+
BabyAI research platform for grounded language learning with a simulated human-in-the-loop.
+
+
+
Baseline results for performance and sample efficiency for the different tasks.
+
+
+
+
BabyAI Platform
+
+
Environment
+
+
+
+
MiniGrid - A partially observable 2D grid-world environment.
+
+
+
Entities - Agent, ball, box, door, keys
+
+
+
Actions - pick, drop or move objects, unlock doors etc.
+
+
+
+
Baby Language
+
+
+
+
Synthetic Language (a proper subset of English) - Used to give instructions to the agent
+
+
+
Support for verifying if the task (and the subtasks) are completed or not
+
+
+
+
Levels
+
+
+
+
A level is an instruction-following task.
+
+
+
Formally, a level is a distribution of missions - a combination of initial state of the environment and an instruction (in Baby Language)
+
+
+
Motivated by curriculum learning, the authors create a series of tasks (with increasing difficulty).
+
+
+
A subset of skills (competencies) is required for solving each task. The platform takes into account this constraint when creating a level.
+
+
+
+
Heuristic Expert
+
+
+
+
The platform supports a Heuristic expert that simulates the role of a human teacher and knows how to solve each task.
+
+
+
For any level, it can suggest actions or generate demonstrations (given the state of the environment).
+
+
+
+
Experiment
+
+
+
+
An imitation learning baseline is trained for each level.
+
+
+
Data requirement for each level and the benefits of curriculum learning and imitation learning are investigated (in terms of sample efficiency).
+
+
+
+
Model Architecture
+
+
+
+
GRU to encode the sentence, CNN to encode the input observation
+
+
+
FiLM layer to combine the two representations
+
+
+
LSTM to encode the per-timestep FiLM encoding (timesteps in the environment)
+
+
+
Two model variants are considered:
+
+
+
+
Large Model - Bidirectional GRU + attention + large hidden state
+
+
+
Small Model - Unidirectional GRU + No attention + small hidden state
+
+
+
+
+
Heuristic expert used to generate trajectory and the models are trained by imitation learning (to be used as baselines)
+
+
+
+
Results
+
+
+
+
The key takeaway is that the current deep learning approaches are extremely sample inefficient when learning a compositional language.
+
+
+
Data efficiency of RL methods is much worse than that of imitation learning methods showing that the current imitation learning and reinforcement learning methods scale and generalize poorly.
+
+
+
Curriculum-based pretraining and interactive learning was found to be useful in only some cases.
+
+
+
diff --git a/_site/site/2018/10/25/One-shot-Learning-with-Memory-Augmented-Neural-Networks.html b/_site/site/2018/10/25/One-shot-Learning-with-Memory-Augmented-Neural-Networks.html
new file mode 100644
index 00000000..2659a3d5
--- /dev/null
+++ b/_site/site/2018/10/25/One-shot-Learning-with-Memory-Augmented-Neural-Networks.html
@@ -0,0 +1,121 @@
+
Introduction
+
+
+
+
The paper demonstrates that Memory Augmented Neural Networks (MANN) are suitable for one-shot learning by introducing a new method for accessing an external memory.
+
+
+
This method focuses on memory content while earlier methods additionally used memory location based focusing mechanisms.
+
+
+
Here, MANN refers to neural networks that have an external memory. This includes Neural Turning Machines (NTMs) and excludes LSTMs.
In meta-learning, a learner is learning at two levels.
+
+
+
The learner is shown a sequence of tasks D1, D2, …, DT.
+
+
+
When it is training on one of the datasets (say DT), it learns to solve the current dataset.
+
+
+
At the same time, the learner tries to incorporate knowledge about how task structure changes across different datasets (second level of learning).
+
+
+
+
MANN + Meta Learning
+
+
+
+
Following are the desirable characteristics for a scalable, combined architecture:
+
+
+
+
Memory representation should be both stable and element-wise accessible.
+
+
+
Number of model parameters should not be tied to the size of the memory.
+
+
+
+
+
+
Task Setup
+
+
+
+
In standard learning, the goal is to reduce error on some dataset D. In meta-learning, the goal is to reduce the error across a distribution of datasets p(D).
+
+
+
Each dataset is presented to the model in the form (x1, null), (x1, y0), …, (xt+1, yt) where yt is the correct label (or value) corresponding to the inpuit xt.
+
+
+
Further, the data labels are shuffled from dataset to dataset.
+
+
+
The model must learn to hold the data samples in memory till the appropriate candidate labels are presented in the next step.
+
+
+
The idea is that a model that meta learns would learn to map data representation to correct labels regardless of the actual context of data representation or the label.
+
+
+
The paper uses NTM as the MANN with one modification.
+
+
+
In the original formulation, the memories were addressed by both context and location. Location-based addressing is not optimal for the current setup where information encoding is not independent of the sequence.
+
+
+
A new access module - LRUA - Least Recent Used Access - is used to write to memory.
+
+
+
LRUA is purely content-based and writes to either least used memory location (to preserve recent information) or most recently used memory location (to overwrite recent information with more relevant information). This is decided on the basis of interpolation between previous read weights and weights scaled according to the usage weight.
+
+
+
+
Datasets
+
+
+
+
Omniglot (classification)
+
+
+
Sampled functions from Gaussian Processes
+
+
+
+
Results
+
+
+
+
For the omniglot dataset, the model was trained with various combinations of randomly chosen classes with randomly chosen labels.
+
+
+
As baselines, following models were considered:
+
+
+
Regular NTM
+
LSTM
+
Feedforward RNN
+
Nearest Neighbour Classifier
+
+
+
+
Since each episode (dataset created by the combination of classes) contains unique classes (with their own unique labels) it is important to clear the memory across different episodes.
+
+
+
For the regression task, the data was generated from a GP prior with a fixed set of hyper-parameters which resulted in different functions.
+
+
+
For both the tasks, the MANN architecture outperforms the LSTM architecture baseline NTMs.
+
+
+
diff --git a/_site/site/2018/11/01/Learned-Optimizers-that-Scale-and-Generalize.html b/_site/site/2018/11/01/Learned-Optimizers-that-Scale-and-Generalize.html
new file mode 100644
index 00000000..4dd86fa6
--- /dev/null
+++ b/_site/site/2018/11/01/Learned-Optimizers-that-Scale-and-Generalize.html
@@ -0,0 +1,70 @@
+
Introduction
+
+
+
+
The paper introduces a learned gradient descent optimizer that has low memory and computational overhead and that generalizes well to new tasks.
Uses a hierarchial RNN architecture augmented by features like adapted input an output scaling, momentum etc.
+
+
+
A meta-learning set of small diverse optimization tasks, with diverse loss landscapes is developed. The learnt optimizer generalizes to much more complex tasks and setups.
+
+
+
+
Architecture
+
+
+
+
A hierarchical RNN is designed to act as a learned optimizer. This RNN is the meta-learner and its parameters are shared across different tasks.
+
+
+
The learned optimizer takes as input the gradient (and related metadata) for each parameter and outputs the update to the parameters.
+
+
+
At the lowest level of hierarchical, a small “parameter RNN” ingests the gradient (and related metadata).
+
+
+
One level up, an intermediate “Tensor RNN” incorporates information from a subset of Parameter RNNS (eg one Tensor RNN per layer of feedforward network).
+
+
+
At the highest level is the glocal RNN which receives input from all the Tensor RNNs and can keep track of weight updates across the task.
+
+
+
the input of each RNN is averaged and fed as input to the subsequent RNN and the output of each RNN is fed as bias to the previous RNN.
+
+
+
In practice, the hidden states are fixed at 10, 30 and 20 respectively.
+
+
+
+
Features inspired from existing optimizers
+
+
+
+
Attention and Nesterov’s momentum
+
+
+
+
Attention mechanism is incorporated by attending to new regions of the loss surface (which are an offset from previous parameter location).
+
+
+
To incorporate momentum on multiple timescales, the exponential moving average of the gradient at several timescales is also provided as input.
+
+
+
The average gradients are rescaled (as in RMSProp and Adam)
+
+
+
Relative log gradient magnitudes are also provided as input so that the optimizer can access how the gradient magnitude changes with time.
+
+
+
+
diff --git a/_site/site/2018/12/11/Representation-Tradeoffs-for-Hyperbolic-Embeddings.html b/_site/site/2018/12/11/Representation-Tradeoffs-for-Hyperbolic-Embeddings.html
new file mode 100644
index 00000000..93291e9d
--- /dev/null
+++ b/_site/site/2018/12/11/Representation-Tradeoffs-for-Hyperbolic-Embeddings.html
@@ -0,0 +1,181 @@
+
Introduction
+
+
+
+
The paper describes a combinatorial approach to embed trees into hyperbolic spaces without performing optimization.
+
+
+
The resulting mechanism is analyzed to obtain dimensionality-precision tradeoffs.
+
+
+
To embed any metric spaces in the hyperbolic spaces, a hyperbolic generalization of the multidimensional scaling (h-MDS) is proposed.
Have the “tree” like property ie the shortest path between a pair of points is almost the same as the path through the origin.
+
+
+
Generally, Poincare ball model is used given its advantages like conformity to the Euclidean spaces.
+
+
+
+
+
Fidelity Measures
+
+
+
+
Mean Average Precision - MAP
+
+
+
A local metric that ranks between distances of the immediate neighbors.
+
+
+
+
Distortion
+
+
+
A global metric that depends on the underlying distances and not just the local relationship between distances.
+
+
+
+
+
+
+
Combinatorial Construction for embedding hierarchies into Hyperbolic spaces
+
+
+
+
Embed the given graph G = (V, E) into a tree T.
+
+
+
Embed the tree T into the poincare ball Hd of dimensionality d.
+
+
+
+
Sarkar’s construction to embed points in a 2-d Poincare ball
+
+
+
+
Consider two points a and b (from the tree) where b is the parent of a.
+
+
+
Assume that a is embedded as f(a) and b is embedded as f(b) and the children of a needs to be embedded.
+
+
+
Reflect f(a) and f(b) across a geodesic such that f(a) is mapped to 0 (origin) while f(b) is mapped to some new point z.
+
+
+
Children of a are placed at points yi which are equally placed around a circle of radius (er - 1) / (er + 1) and maximally seperated from z, where r is the scaling factor.
+
+
+
Then all the points are reflected back across the geodesic so that all children are at a distance r from f(a).
+
+
+
To embed the tree itself, place the root node at the origin, place its children around it in a circle, then place their children and so on.
+
+
+
In this construct, precision scales logarithmically with the degree of the tree but linearly with the maximum path length.
+
+
+
+
d-dimensional hyperbolic spaces
+
+
+
+
In the d-dimensional space, the points are embedded into hyperspheres (instead of circles).
+
+
+
The number of children node that can be placed for a particular angle grows with the dimension.
+
+
+
Increasing dimension helps with bushy trees (with high node degree).
+
+
+
+
Hyperbolic multidimensional scaling (h-MDS)
+
+
+
+
Given the pairwise distance from a set of points in the hyperbolic space, how to recover the points?
+
+
+
The corresponding problem in the Euclidean space is solved using MDS.
+
+
+
A variant of MDS called as h-MDS is proposed.
+
+
+
MDS makes a centering assumption that points have 0 mean. In h-MDS, a new mean (called as the pseudo-Euclidean mean) is introduced to enable recovery via matrix factorization.
+
+
+
Instead of the Poincare model, the hyperboloid model is used (though the points can be mapped back and forth).
+
+
+
+
pseudo-Euclidean Mean
+
+
+
A set of points can always be centered without affecting their pairwise distance by simply finding their mean and sending it to 0 via isometry
+
+
+
Recovery via matrix factorization
+
+
+
+
Given the pairwise distances, a new matrix Y is constructed by applying cosh on the pairwise distances.
+
+
+
Running PCA on -Y recovers X up to rotation.
+
+
+
+
Dimensionality Reduction with PGA (Principal Geodesic Analysis)
+
+
+
+
PGA is the counterpart of PCA in the hyperbolic spaces.
+
+
+
First the Karcher mean of the given points is computed.
+
+
+
All points xi are reflected so that their mean is 0 in the Poincare disk model.
+
+
+
Combining that with Euclidean reflection formula and hyperbolic metrics leads to a non-convex loss function which can be optimized using gradient descent algorithm.
+
+
+
+
Experiments
+
+
+
+
Datasets
+
+
+
Trees: fully balanced and phylogenic trees expressing genetic heritage.
+
Tree-like hierarchy: WordNet hypernym and graph of Ph.D. advisor-advisee relationships.
+
No-tree like disease relationships, proteins interactions etc
+
+
+
+
Results
+
+
+
Combinatorial construction outperforms approaches based on optimization in terms of both MAP and distortion.
+
eg on WordNet, the combinatorial approach achieves a MAP of 0.989 with just 2 dimensions while the previous best was 0.87 with 200 dimensions.
+
+
+
+
diff --git a/_site/site/2018/12/18/Hindsight-Experience-Replay.html b/_site/site/2018/12/18/Hindsight-Experience-Replay.html
new file mode 100644
index 00000000..027f438c
--- /dev/null
+++ b/_site/site/2018/12/18/Hindsight-Experience-Replay.html
@@ -0,0 +1,76 @@
+
Introduction
+
+
+
+
Hindsight Experience Replay(HER) is a sample efficient technique to learn from sparse rewards.
Assume a footballer misses the goal narrowly. Even though the player does not get any “reward”(in terms of goal), the player realizes that had the goal post been shifted a bit, it would have resulted in a goal(reward).
+
+
+
The same intuition is applied for the RL agent - let us say that the true goal state was g while the agent ends up in the state s.
+
+
+
While the action sequence is not useful for reaching the goal state g, it is indeed useful for reaching state s. Hence the trajectory could be replayed with the goal as s(and not g).
+
+
+
+
Technical Details
+
+
+
+
Multi-goal policy trained using Universal Value Function Approximation (UVFA).
+
+
+
Every episode starts by sampling a start state and a goal state. Each goal has a different reward function.
+
+
+
Policy uses both the current state and the current goal state and leads to a state transition sequence s1, s2,…, sn.
+
+
+
Each of these transitions si -> si+1 are stored in a buffer with both the original goal and a subset of the other goals.
+
+
+
For the goal selection, following strategies are tried:
+
+
+
+
Future - goal state is the state k steps after observing the state transition.
+
+
+
Final - goal state is the final state of the current episode.
+
+
+
Episode - k random states are selected from the current episode.
+
+
+
Randon - k states are selected randomly.
+
+
+
+
+
Any off-policy algorithm can be used. Specifically, DDPG is used.
+
+
+
+
Experiments
+
+
+
+
Robotic arm simulated using MuJoCo for push, slide and pick and place tasks.
+
+
+
DDPG with and without HER evaluated on the 3 tasks.
+
+
+
DDPG with the HER variant significantly outperforms the baseline in all the cases.
+
+
diff --git a/_site/site/2018/12/25/Smooth-Loss-Functions-for-Deep-Top-k-Classification.html b/_site/site/2018/12/25/Smooth-Loss-Functions-for-Deep-Top-k-Classification.html
new file mode 100644
index 00000000..25cf763b
--- /dev/null
+++ b/_site/site/2018/12/25/Smooth-Loss-Functions-for-Deep-Top-k-Classification.html
@@ -0,0 +1,117 @@
+
Introduction
+
+
+
+
For top-k classification tasks, cross entropy is widely used as the learning objective even though it is the optimal metric only in the limit of infinite data.
+
+
+
The paper introduces a family of smoothed loss functions that are specially designed for top-k optimization.
Inspired by the multi-loss SVMs, a surrogate loss (lk) is introduced that creates a margin between the ground truth and the kth largest score.
+
+
+
+
+
+
+
Here s denotes the output of the classifier model to be learnt, y is the ground truth label, s[p] denotes the kth largest element of s and s\p denotes the vector s without pth element.
+
+
+
This lk loss has two limitations:
+
+
+
+
It is continous but not differentiable in s.
+
+
+
Its weak derivatives have at most 2-nonzero elements.
+
+
+
+
+
The loss can be reformulated by adding and subtracting the k-1 largest scores of s\y and sy and by introducing a temperature parameter τ.
+
+
+
+
+
+
Properties of Lkτ
+
+
+
+
For any τ > 0, Lkτ is infinite-differentiable and has non-sparse gradients.
+
+
+
Under mild conditions, Lkτ apporachs lk (in a pointwise sense) as τ approaches to 0++.
+
+
+
It is an upper bound on the actual loss (up to a constant factor).
+
+
+
It is a generalization of the cross-entropy loss for different values of k, and τ and higher margins.
+
+
+
+
Computational Challenges
+
+
+
+
nCk number of terms needs to be evaluated for computing the loss for one sample (n is number of classes).
+
+
+
Loss Lkτ can be expressed in terms of elementary symmetric polynomials σi(e) (sum of all products of i distinct elements of vector e). Thus the challenge is to compute σk efficiently.
+
+
+
+
Forward Computation
+
+
+
+
Compute σk(e) where e is a n-dimensional vector and k« n and e[i]!=0 for all i.
+
+
+
σi(e) can be computed using the coefficients of the polynomial (X+e1)(X+e2)…(X+en) by divide and conquer approach with polynomial multiplication.
+
+
+
With some more optimizations (eg log(n) levels of recursion and each level being parallelized on a GPU), the resulting algorithms scale well with n on a GPU.
+
+
+
Operations are performed in the log-space using the log-sum-exp trick to achieve numerical stability in single floating point precision.
+
+
+
+
Backward computation
+
+
+
+
The backward pass uses optimizations like computing derivative of σj with respect to ei in a recursive manner.
+
+
+
Appendix of the paper describes these techniques in detail.
+
+
+
+
Experiments
+
+
+
+
Experiments are performed on CIFAR-100 (with noise) and Imagenet.
+
+
+
For CIFAR-100 with noise, the labels are randomized with probability p (within the same top-level class).
+
+
+
The proposed loss function is very robust to both noise and reduction in the amount of training dataset as compared to cross-entropy loss function for both top-k and top-1 performance.
+
+
diff --git a/_site/site/2019/01/02/Pre-training-Graph-Neural-Networks-with-Kernels.html b/_site/site/2019/01/02/Pre-training-Graph-Neural-Networks-with-Kernels.html
new file mode 100644
index 00000000..d10533f7
--- /dev/null
+++ b/_site/site/2019/01/02/Pre-training-Graph-Neural-Networks-with-Kernels.html
@@ -0,0 +1,73 @@
+
Introduction
+
+
+
+
The paper proposes a pretraining technique that can be used with the GNN architecture for learning graph representation as induced by powerful graph kernels.
Graph Kernel methods can learn powerful representations of the input graphs but the learned representation is implicit as the kernel function actually computes the dot product between the representations.
+
+
+
GNNs are flexible and powerful in terms of the representations they can learn but they can easily overfit if a large amount of training data is not available as is commonly the case of graphs.
+
+
+
Kernel methods can be used to learn an unsupervised graph representation that can be finetuned using the GNN architectures for the supervised tasks.
+
+
+
+
Architecture
+
+
+
+
Given a dataset of graphs g1, g2, …, gn, use a relevant kernel function to compute k(gi, gj) for all pairs of graphs.
+
+
+
A siamese network is used to encode the pair of graphs into representations f(gi) and f(gj) such that dot(f(gi), f(gj)) equals k(gi, gj).
+
+
+
The function f is trained to learn the compressed representation of kernel’s feature space.
+
+
+
+
Experiments
+
+
Datasets
+
+
+
Biological node-labeled graphs representing chemical compounds - MUTAG, PTC, NCI1
Pretrained model performs better than the baselines for 2 datasets but lags behind WL method (which was used for pretraining) for the NCI1 dataset.
+
+
+
+
Notes
+
+
+
The idea is straightforward and intuitive. In general, this kind of pretraining should help the downstream model. It would be interesting to try it on more datasets/kernels/GNNs so that more conclusive results can be obtained.
+
diff --git a/_site/site/2019/01/08/Efficient-Lifelong-Learning-with-A-GEM.html b/_site/site/2019/01/08/Efficient-Lifelong-Learning-with-A-GEM.html
new file mode 100644
index 00000000..be4bbda1
--- /dev/null
+++ b/_site/site/2019/01/08/Efficient-Lifelong-Learning-with-A-GEM.html
@@ -0,0 +1,164 @@
+
Contributions
+
+
+
+
A new (and more realistic) evaluation protocol for lifelong learning where each data point is observed just once and a disjoint set of tasks are used for training and validation.
+
+
+
A new metric that focuses on the efficiency of the models - in terms of sample complexity and computational (and memory) costs.
+
+
+
Modification of Gradient Episodic Memory ie GEM which reduces the computational overhead of GEM without compromising on the results.
+
+
+
Empirical validation that using task descriptors help lifelong learning models and improve their few-shot learning capabilities.
AGEM outperforms other models on all the datasets expect MNIST where the Progressive Neural Networks lead. One reason could be that MNIST has a large number of training examples per task. But Progressive Neural Networks lead to bad utilization of capacity.
+
+
+
While AGEM and GEM have similar performance, GEM has a much higher computational and memory overhead.
+
+
+
Use of task descriptors improves the accuracy for all the models.
+
+
+
It seems that AGEM offers a good tradeoff between average accuracy performance and efficiency - in terms of sample efficiency, memory requirements and computational costs.
+
+
diff --git a/_site/site/2019/01/15/Hierarchical-RL-Using-an-Ensemble-of-Proprioceptive-Periodic-Policies.html b/_site/site/2019/01/15/Hierarchical-RL-Using-an-Ensemble-of-Proprioceptive-Periodic-Policies.html
new file mode 100644
index 00000000..46155f45
--- /dev/null
+++ b/_site/site/2019/01/15/Hierarchical-RL-Using-an-Ensemble-of-Proprioceptive-Periodic-Policies.html
@@ -0,0 +1,107 @@
+
Introduction
+
+
+
+
The paper proposes a simple and robust approach for hierarchically training an agent in the sparse reward setup.
+
+
+
The broad idea is to train low-level primitives that are sufficiently diverse (so that they can be composed for solving higher level tasks) and to train a high level primitive that learns to combine these primitives for any given downstream task.
The state can be divided into two components: proprioceptive states sp (measurement of agent’s own body that can be directly controlled by the agent) and the external states se/
+
+
+
Low-Level Policy Training
+
+
+
+
Low-level policies should be:
+
+
+
Diverse: should cover all the skills that the agent might have to perform.
+
Effective: can make significant changes to the environment.
+
Controllable: easy for high-level policies to use and control
+
+
+
+
For the low-level policy, the per-time step reward is directly proportional to change in the external state. The same reward is used for all the agents and environments(except regulated with environment specific controls and survival rewards).
+
+
+
+
Phase conditioned policies
+
+
+
+
Good movement policies are expected to be at least roughly periodic and phase input (or time index) is used to achieve periodicity.
+
+
+
Phase conditioned policy (=f(sp, φ)) where φ = {0, 1, …, k-1} is the phase index.
+
+
+
At each timestep t, the model receives observation sp and phase index φ = t%k. The phase index is represented by a vector bφ.
+
+
+
For phase conditioned policies, the agent state and actions are encouraged to be cyclic with the help of a cyclic loss.
+
+
+
+
Experiments
+
+
+
+
Environments: Ant and Humanoid from Mujoco.
+
+
+
Low-level control:
+
+
+
Using phase-conditioning is helpful when training low-level primitives.
+
+
+
+
High-level control:
+
+
+
+
Cross Maze Environment with fixed goals
+
+
+
+
3 goals along 3 paths
+
+
+
Proposed method converges faster and to a smaller final distance to the goal showing that it is both efficient and consistent (with smaller variance across random seeds).
+
+
+
+
+
Random Goal Maze
+
+
+
+
The goal is randomly drawn from a set of goals.
+
+
+
“Cross” (shaped) maze and “skull” (shaped) mazes are considered.
+
+
+
Even with velocity rewards and pretraining on low-level objectives (which can be thought of as exploration bonuses), the baseline fails to get close to the goal locations while the proposed model reach the goal most of the times.
+
+
+
The main results are reported using PPO though repeating the experiments with A2C and DQN show that the idea is fairly robust.
+
+
+
The paper reported that in their experiments, finetuning the lower level primitives did not help much though it might not be the case of other environments.
+
+
+
+
+
+
diff --git a/_site/site/2019/01/22/Modular-meta-learning.html b/_site/site/2019/01/22/Modular-meta-learning.html
new file mode 100644
index 00000000..52d61eef
--- /dev/null
+++ b/_site/site/2019/01/22/Modular-meta-learning.html
@@ -0,0 +1,196 @@
+
Introduction
+
+
+
+
The paper proposes an approach for learning neural networks (modules) that can be combined in different ways to solve different tasks (combinatorial generalization).
Each task is a joint distribution pT(x, y) over (x, y) data pairs.
+
+
+
Given data from m meta-training tasks, and a meta-test task, find a hypothesis h which performs well on the unseen data drawn from the meta-test task.
+
+
+
+
Structured Hypothesis
+
+
+
+
Given a compositional scheme C, a set of modules F1, …, Fk (represented as a whole by F) and the set of their respective parameters θ1, …, θk (represented as a whole by θ), (C, F, θ) represents the set of possible functional input-output mappings. These mappings form the hypothesis space.
+
+
+
A structured hypothesis model is specified by what modules to use and their parametric forms (but not the values).
+
+
+
+
Examples of compositional schemes
+
+
+
+
Choosing a single module for the task at hand.
+
+
+
Fixed compositional structure but different modules selected every time.
+
+
+
Weight ensemble (maybe using attention mechanism)
+
+
+
General function composition tree
+
+
+
+
Phases
+
+
+
+
Offline Meta Learning Phase:
+
+
+
+
Take training and validation dataset for the first k tasks and generate a parameterization for each module θ1, …, θk.
+
+
+
The hypothesis (or composition) to use comes from the online meta-test learning phase.
+
+
+
In this stage, find the best θ given a structure.
+
+
+
+
+
Online Meta-test Learning Phase
+
+
+
+
Given a hypothesis space and θ, the output is a compositional form (or hypothesis) that specifies how to compose the models.
+
+
+
In this stage, find the best structure, given a hypothesis space and θ.
+
+
+
+
+
+
Learning Algorithm
+
+
+
+
During Meta-test learning phase, simulated annealing is used to find the optimal structure, with temperature T decreased over time.
+
+
+
During meta-learning phrase, the actual objective function is replaced by a surrogate, smooth objective function (during the search step) to avoid local minima.
+
+
+
Once a structure has been picked, any gradient descent based approach can be used to optimize the modules.
+
+
+
Basically the state of optimization process comprises of the parameters and the temperature. Together, they are used to induce a distribution over the structures. Given a structure, θ is optimized and T is annealed over time.
+
+
+
The learning procedure can be improved upon by performing parameter tuning during the online (meta-test learning) phase as well. the resulting approach is referred to as MOMA - MOdular MAml.
+
+
+
+
Experiments
+
+
Approaches
+
+
+
+
Pooled - Single network using combined data of all the tasks.
+
+
+
MAML - Single network using MAML
+
+
+
BOUNCEGRAD - Modular Network without MAML adaptation in online learning.
+
+
+
MOMA - BOUNCEGRAD with MAML adaptation in online learning.
+
+
+
+
Domains
+
+
Simple Functional Relationships
+
+
+
+
Sine-function prediction problem
+
+
+
In general, MOMA outperforms other models.
+
+
+
With a small amount of online training data, BOUNCEGRAD outperforms other models as it has a better structural prior.
+
+
+
+
Predicting next frame of a kinematic skeleton (motion capture data)
+
+
+
+
11 different objects (with different shapes) on 4 surfaces with different friction properties.
+
+
+
2 meta-learning scenarios are considered. In the first case, the object-surface combination in the test case was present in some meta-training tasks and in the other case, it was not present.
+
+
+
For previously seen combinations, MOMA performs the best followed by BOUNCEGRAD and MAML.
+
+
+
For unseen combinations, all the 3 are equally good.
+
+
+
Compositional scheme is the attention mechanism.
+
+
+
An interesting result is that the modules seem to specialize (and activate more often) based on the shape of the object.
+
+
+
+
Predicting next frame of a kinematic selection (using motion capture data)
+
+
+
+
Composition Structure - generating kinematics subtrees for each body part (2 legs, 2 arms, 2 torsi).
+
+
+
Again 2 setups are used - one where all activities in the training and the meta-test task are shared while the other setup where the activities are not shared.
+
+
+
For known activities MOMA and BOUNCEGRAD perform the best while for unknown activities, MOMS performs the best.
+
+
+
+
Notes
+
+
+
+
While the approach is interesting, maybe a more suitable set of tasks (from the point of composition) would be more convincing.
+
+
+
It would be useful to see the computational tradeoff between MAML, BOUNCEGRAD, and MOMA.
+
+
diff --git a/_site/site/2019/01/29/Diversity-is-All-You-Need-Learning-Skills-without-a-Reward-Function.html b/_site/site/2019/01/29/Diversity-is-All-You-Need-Learning-Skills-without-a-Reward-Function.html
new file mode 100644
index 00000000..a8f0f7d0
--- /dev/null
+++ b/_site/site/2019/01/29/Diversity-is-All-You-Need-Learning-Skills-without-a-Reward-Function.html
@@ -0,0 +1,104 @@
+
Introduction
+
+
+
+
The paper proposes an approach to learn useful skills without a reward function by maximizing an information theoretic objective by using a maximum entropy policy.
+
+
+
Skills are defined as latent-conditioned policies that alter the state of the environment in a consistent way.
Unsupervised “exploration” stage followed by supervised stage.
+
+
+
Desirable Qualities of Skills
+
+
+
+
Skills should dictate the states that the agent visits. Different skills should visit different states to be distinguishable.
+
+
+
States (not actions) should be used to distinguish between skills as not all actions change the state (for the outside observer).
+
+
+
Skills are encouraged to be diverse and “exploratory” by learning skills that act randomly (have high entropy).
+
+
+
+
Loss Formulation
+
+
+
+
(S, A) - state and action
+
+
+
z ~ p(z) - latent variable to condition the policy.
+
+
+
Skill - policy conditioned on a fixed z.
+
+
+
Objective is to maximize the mutual information between skill and state (MI(A; Z)) ie skill should control which state is visited or the skill should be inferrable from the state visited.
+
+
+
Simultaneously minimize the mutual information between skills and actions given the state to ensure that the state (and not the action) is used to distinguish the skills.
+
+
+
Maximize the entropy of the mixture of policies (p(z) and all the skills).
+
+
+
+
Implementation
+
+
+
+
Policy π(a | s, z)
+
+
+
Task reward replaced by the pseduoreward logqφ(z | s) - log(p(z)).
+
+
+
During unsupervised training, z is sampled at the start of the episode and then not changed during the episode.
+
+
+
Learning agent gets rewards for visiting the states that are easy to discriminate while the discriminator updated to correctly predict z from the states visited.
+
+
+
+
Observations
+
+
Analysis of Learned Skills
+
+
+
+
The agent learns a diverse set of primitive behaviors for all tasks ranging from 2 DoF to 111 DoF.
+
+
+
for inverted pendulum and mountain car, the skills become increasingly diverse throughout training.
+
+
+
Use of uniform prior, in place of a learned prior, for p(z) allows for discovery of more diverse skills.
+
+
+
The proposed approach can be used as a pretraining technique where the best-performing primitives (from unsupervised training) can be finetuned with the task-specific rewards.
+
+
+
The discovered skills can be used for hierarchical RL by learning a meta-policy(which chooses the skill to execute for k steps).
+
+
+
Modifying the discriminator in the proposed formulation can be used to bias DIAYN towards discovering a particular type of policies. This provides a mechanism for incorporating “supervision” in the learning setup.
+
+
+
The “discovered” primitives can also be used for imitation learning.
+
+
diff --git a/_site/site/2019/02/05/Linguistic-Knowledge-as-Memory-for-Recurrent-Neural-Networks.html b/_site/site/2019/02/05/Linguistic-Knowledge-as-Memory-for-Recurrent-Neural-Networks.html
new file mode 100644
index 00000000..8ed339f8
--- /dev/null
+++ b/_site/site/2019/02/05/Linguistic-Knowledge-as-Memory-for-Recurrent-Neural-Networks.html
@@ -0,0 +1,59 @@
+
Training RNNs to model long term dependencies is difficult but in some cases, the information about dependencies between elements (of the sequence) may be present in the form of symbolic knowledge.
+
+
+
For example, when encoding sentences, coreference, and hypernymy relations can be extracted between tokens.
+
+
+
These elements(tokens) can be connected with each other with different kind of edges resulting in the graph data structure.
+
+
+
One approach could be to model this knowledge(encoded in the graph) using a graph neural network (GNN).
+
+
+
The authors prefer to encode the information into 2 DAGs (via topological sorting) as training the GNN could add some extra overhead.
+
+
+
This results into the Memory as Acyclic Graph Encoding RNN (MAGE-RNN) architecture. Its GRU version is referred to as MAGE-GRU.
+
+
+
Given an input sequence of tokens [x1, x2, …, xT] and information about which tokens relate to other tokens, a graph G is constructed with different (possibly typed) edges.
+
+
+
Given the graph G, two DFS orderings are computed - forward DFS and backward DFS.
+
+
+
MAGE-RNN uses separate networks for accessing the forward and backward DFS orders.
+
+
+
A separate hidden state is maintained for each entity type to separate memory content from addressing.
+
+
+
For any DFS order (forward or backward), the representation at time t is given as the concatenation of representation of different edge types at that time.
+
+
+
The hidden states (for different edge types at time t) are updated in the topological order using the current state of all incoming edges at xt.
+
+
+
The representation of the DFS order is given as the sequence of all the previous representations.
+
+
+
In some cases, elements across multiple sequences could be related to each other. In that case, the graph is decomposed into a collection of DAGs and use MAGE-GRU on the DAGs by taking one random permutation of the sequences and decomposing it into the forward and the backward graphs.
+
+
+
The model is evaluated on the task of text comprehension with coreference on bAbi dataset (story based QA), LAMBADA dataset (broad context language modeling) and CNN dataset (cloze-style QA).
+
+
+
MAGE-GRU was used as a replacement for GRU units in bi-directional GRUs and GA-Reader architecture.
+
+
+
DAG-RNN and shared version of MAGE-GRU (with shared edge types) are the other baselines.
+
+
+
For all the cases, the model with MAGE-GRU works the best.
+
+
diff --git a/_site/site/2019/02/19/TuckER-Tensor-Factorization-for-Knowledge-Graph-Completion.html b/_site/site/2019/02/19/TuckER-Tensor-Factorization-for-Knowledge-Graph-Completion.html
new file mode 100644
index 00000000..08bbde0c
--- /dev/null
+++ b/_site/site/2019/02/19/TuckER-Tensor-Factorization-for-Knowledge-Graph-Completion.html
@@ -0,0 +1,134 @@
+
Introduction
+
+
+
+
TuckER is a simple, yet powerful linear model that uses Tucker decomposition for the task of link prediction in knowledge graphs.
Let E be the set of all the entities and R be the set of all the relations in a given knowledge graph (KG).
+
+
+
The KG can be represented as a list of triples of the form (source entity, relation, object entity) or (es, r, eo).
+
+
+
The list of triples can be represented as a third-order tensor (of binary values) where each element corresponds to a triple and each element’s value corresponds to ether that element is present in the KG or not.
+
+
+
The link prediction task can be formulated as - given a set of all triples, learn a scoring function that assigns a score to each triple. The score indicates whether the triple is actually present in the KG or not.
+
+
+
+
TuckER Decomposition
+
+
+
+
Tucker decomposition factorizes a tensor into a set of factor matrices and a smaller core tensor.
+
+
+
In the specific case of three-mode tensors (alternate representation of a KG), the given original tensor X (of shape IxJxK) can be factorized into a core tensor W (of shape PxQxR) and 3 factor matrics - A (of shape IxP), B (of shape JxQ) and C (of shape KxR) such that X is approximately W x1A x2B x3C, where Xn denotes the tensor product along the nth mode.
+
+
+
Generally, P, Q, R are smaller than I, J K (respectively) and W can be seen as a compressed version of X.
+
+
+
+
TuckER Decomposition for Link Prediction
+
+
+
+
Two embedding matrics are used for embedding the entities and the relations respectively.
+
+
+
Entity embedding matrix E is shared for both subject and the object ie E = A = B.
+
+
+
The scoring function is gives as W x1es x2wr x3e0 where es, wr and eo are the embedding vectors corresonding to es, er and eo respectively. Note that both the core tensor and the factor matrices are to be learnt.
+
+
+
Model is trained with the standard negative log-likelihood loss given as (for one triple): y * log(p) + (1-y) * log(1-p)
+
+
+
To speed up training and increase accuracy, 1-N scoring is used. A given (es, r) is simultaneously scored for all the entities using the local-closed world assumption (knowledge graph is only locally complete).
+
+
+
Handling asymmetric relations is straightforward by learning a relation embedding alongside a relation-agnostic core tensor which enables knowledge sharing across relations.
+
+
+
+
Theoretical Analysis
+
+
+
+
One important consideration would be the expressive power of TuckER models, especially in relation to other models like ComplEx and SimplE.
+
+
+
It can be shown the TuckER is fully expressive ie give any ground truth over E and R, there exists a TuckER model which can perfectly represent the data - using 1-hot entity and relation embedding.
+
+
+
For full expressiveness, dimensionality of entity (relation) is nE (nR) where nE (nR) are the number of entities (relations). In comparsion, the required dimensionality for ComplEx is nE * nR (for both entity and relations) and for SimplE, it is min(E * nR, number of facts + 1) (for both entity and relations).
+
+
+
Many existing models like RESCAL, DistMult, ComplEx, SimplE etc can be seen as special cases of TuckER.
+
+
+
+
Experiments
+
+
Datasets
+
+
+
+
FB15k, FB15k-237, WN18, WN18RR
+
+
+
The max number of entities is around 41K and max number of relations is around 1.3K
+
+
+
+
Implementation
+
+
+
BatchNorm, Dropout and Learning rate decay are used.
+
+
+
Metrics
+
+
+
+
Mean Reciprocal Rank (MRR) - the average of the inverse of mean rank assigned to the true triple overall ne generated triples.
+
+
+
hits@k (k = 1, 3, 10) - percentage of times the true triple is ranked in the top k of the ne generated triples.
+
+
+
Higher is better for both the metrics.
+
+
+
+
Results
+
+
+
+
TuckER outperforms all the baseline models on all but one task.
+
+
+
Dropout is an important factor with higher dropout rates (0, 3, 0.4, 0.5) needed for datasets with fewer training examples per relation (hence more prone to overfitting).
+
+
+
TuckER improves performance more significantly when the number of relations is large.
+
+
+
Even with lower embedding dimensions, TuckER’s performance does not deteriorate as much as other models.
+
+
diff --git a/_site/site/2019/03/12/Model-Primitive-Hierarchical-Lifelong-Reinforcement-Learning.html b/_site/site/2019/03/12/Model-Primitive-Hierarchical-Lifelong-Reinforcement-Learning.html
new file mode 100644
index 00000000..2d1a0dc7
--- /dev/null
+++ b/_site/site/2019/03/12/Model-Primitive-Hierarchical-Lifelong-Reinforcement-Learning.html
@@ -0,0 +1,164 @@
+
Introduction
+
+
+
+
The paper presents a framework that uses diverse suboptimal world models that can be used to break complex policies into simpler and modular sub-policies.
+
+
+
Given a task, both the sub-policies and the controller are simultaneously learned in a bottom-up manner.
+
+
+
The framework is called as Model Primitive Hierarchical Reinforcement Learning (MPHRL).
Instead of learning a single transition model of the environment (aka world model) that can model the transitions very well, it is sufficient to learn several (say k) suboptimal models (aka model primitives).
+
+
+
Each model primitive will be good in only a small part of the state space (aka region of specialization).
+
+
+
These model primitives can then be used to train a gating mechanism for selecting sub-policies to solve a given task.
+
+
+
Since these model primitives are sub-optimal, they are not directly used with model-based RL but are used to obtain useful functional decompositions and sub-policies are trained with model-free approaches.
+
+
+
+
Single Task Learning
+
+
+
+
A gating controller is trained to choose the sub-policy whose model primitive makes the best prediction.
+
+
+
This requires modeling p(Mk | st, at, st+1) where p(Mk) denotes the probability of selecting the kth model primitive. This is hard to compute as the system does not have access to st+1 and at at time t before it has choosen the sub-policy.
+
+
+
Properly marginalizing st+1 and at would require expensive MC sampling. Hence an approximation is used and the gating controller is modeled as a categorical distribution - to produce p(Mk | st). This is trained via a conditional cross entropy loss where the ground truth distribution is obtained from transitions sampled in a rollout.
+
+
+
The paper notes that technique is biased but reports that it still works for the downstream tasks.
+
+
+
The gating controller composes the sub-policies as a mixture of Gaussians.
+
+
+
For learning, PPO algorithm is used with each model primitives gradient weighted by the probability from the gating controller.
+
+
+
+
Lifelong Learning
+
+
+
Different tasks could share common subtasks but may require a different composition of subtasks. Hence, the learned sub-policies are transferred across tasks but not the gating controller or the baseline estimator (from PPO).
+
+
+
Experiments
+
+
+
+
Domains:
+
+
+
+
Mujoco ant navigating different mazes.
+
+
+
Stacker arm picking up and placing different boxes.
+
+
+
+
+
Implementation Details:
+
+
+
+
Gaussian subpolicies
+
+
+
PPO as the baseline
+
+
+
Model primitives are hand-crafted using the true next state provided by the environment simulator.
+
+
+
+
+
Single Task
+
+
+
+
Only maze task is considered with the start position (of the ant) and the goal position is fixed.
+
+
+
Observation includes distance from the goal.
+
+
+
Forcing the agent to decompose the problem, when a more direct solution may be available, causes the sample complexity to increase on one task.
+
+
+
+
+
Lifelong Learning
+
+
+
+
Maze
+
+
+
+
10 random Mujoco ant mazes used as the task distribution.
+
+
+
MPHRL takes almost twice the number of steps (as compared to PPO baseline) to solve the first task but this cost gets amortized over the distribution and the model takes half the number of steps as compared to the baseline (summed over the 10 tasks).
+
+
+
+
+
Pick and Place
+
+
+
+
8 Pick and Place tasks are created with max 3 goal locations.
+
+
+
Observation includes the position of the goal.
+
+
+
+
+
+
+
Ablations
+
+
+
+
Overlapping model primitives can degrade the performance (to some extent). Similarly, the performance suffers when redundant primitives are introduced indicating that the gating mechanism is not very robust.
+
+
+
Sub-policies could quickly adapt to the previous tasks (on which they were trained initially) despite being finetuned on subsequent tasks.
+
+
+
The order of tasks (in the 10-Mazz task) does not degrage the performance.
+
+
+
Transfering the gating controller leads to negative transfer.
+
+
+
+
+
Notes
+
+
+
I think the biggest strength of the work is that accurate dynamics model are not needed (which are hard to train anyways!) through the experimental results are not conclusive given the limited number of domains on which the approach is tested.
+
+
+
diff --git a/_site/site/2019/03/16/To-Tune-or-Not-to-Tune-Adapting-Pretrained-Representations-to-Diverse-Tasks.html b/_site/site/2019/03/16/To-Tune-or-Not-to-Tune-Adapting-Pretrained-Representations-to-Diverse-Tasks.html
new file mode 100644
index 00000000..f7927cef
--- /dev/null
+++ b/_site/site/2019/03/16/To-Tune-or-Not-to-Tune-Adapting-Pretrained-Representations-to-Diverse-Tasks.html
@@ -0,0 +1,146 @@
+
The pretrained model is finetuned on the target task.
+
+
+
Task-specific models for ELMO
+
+
+
+
NER - CRF on top of LSTM states
+
+
+
SA - Max-pool over the language model states followed by a softmax layer
+
+
+
NLI, PD, STS - cross sentence bi-attention between the language model states followed by pooling and softmax layer.
+
+
+
+
+
Task-specific models for BERT
+
+
+
+
NER - Extract representation of the first-word piece of each token followed by the softmax layer
+
+
+
SA, NLI, PD, STS - standard BERT training
+
+
+
+
+
+
+
+
+
Main observations
+
+
+
+
Feature extraction and fine-tuning have comparable performance in most cases unless the two tasks are highly similar(fine-tuning is better) or highly dissimilar (feature extraction is better).
+
+
+
For ELMo, feature extraction consistently outperforms fine-tuning for the sentence pair tasks (NLI, PD, STS). The reverse trend is observed for BERT with fine-tuning being better on sentence pair tasks.
+
+
+
Adding extra parameters is helpful for feature extraction but not fine-tuning.
+
+
+
ELMo fine-tuning requires careful tuning and other tricks like triangular learning rates, gradual unfreezing and discriminative fine-tuning.
+
+
+
For the tasks considered, there is no correlation observed between the distance of the source and target domains and adaptation performance.
+
+
+
Training a diagnostic classifier (on the intermediate representations) suggests that fine-tuning improves the performance of the classifier at all the intermediate layers (which is sort of expected).
+
+
+
In terms of mutual information estimates, fine-tuned representations have a much higher mutual information as compared to the feature extraction based representations.
+
+
+
Knowledge for single sentence tasks seems to be mostly concentrated in the last layers while for pair classification tasks, the knowledge seems gradually build un in the intermediate layers, all the way up to the last layer.
+
+
+
+
diff --git a/_site/site/2019/03/26/GNN-Explainer-A-Tool-for-Post-hoc-Explanation-of-Graph-Neural-Networks.html b/_site/site/2019/03/26/GNN-Explainer-A-Tool-for-Post-hoc-Explanation-of-Graph-Neural-Networks.html
new file mode 100644
index 00000000..32c28481
--- /dev/null
+++ b/_site/site/2019/03/26/GNN-Explainer-A-Tool-for-Post-hoc-Explanation-of-Graph-Neural-Networks.html
@@ -0,0 +1,200 @@
+
Introduction
+
+
+
+
Graph Neural Network (GNN) is a family of powerful machine learning (ML) models for graphs that can combine node information with the structural information.
+
+
+
One downside of GNNs is that their predictions are hard to interpret.
+
+
+
The paper proposes GNN Explainer model for solving the problem of interpretability.
Local edge fidelity - identify the subgraph structure (ideally the smallest) that significantly affected the predictions of the GNN. ie identify the important edges in the graph (for a given prediction).
+
+
+
Local node fidelity - identify the import node features and correlations in the features of the neighboring nodes.
+
+
+
Single instance and multi-instance explanations - Support both single instance prediction tasks and multi-instance prediction tasks.
+
+
+
Model Agnostic - Support a large family of models (ideally all)
+
+
+
Task Agnostic - Support a large family of tasks (ideally all)
+
+
+
+
Approach
+
+
+
+
I first describe the single instance prediction case and use that as the base to describe the multiple instance prediction cases. All the discussion in this section assumes a single instance prediction task.
+
+
+
Input: Trained GNN, a single instance whose prediction is to be explained.
+
+
+
Task: Identify the small subgraph and the small subset of features that explain the prediction.
+
+
+
Idea: Maximize the mutual information (MI) between the GNN and the explanation by learning a graph mask which can be used for selecting the relevant subgraph (from the GNN’s computational graph) and features (from all layers of the GNN).
+
+
+
Computational graph of GNN (corresponding to a node) refers to the approx L-hop neighborhood of the node in the graph ie the subgraph formed by nodes and edges whose representation affected the representation of the given node.
+
+
+
+
Single-Instance Explanations
+
+
+
+
For a node v, the information used to predict its label y is completely described by its computation graph Gc(v) and the associated feature set Xc(v). The feature set includes the features of all the nodes in the computation graph.
+
+
+
When constructing the explaination, only Gc(v) and Xc(v) are used.
+
+
+
The task can be reformulated as identifying a subgraph GS (subset of Gc(v)) with associated features XS which are important when predicting the label y for node v.
+
+
+
“Importance” is measured in terms of MI
+
+
+
+
MI(Y, (GS, XS)) = H(Y) - H(Y | G = GS, X = XS) where H is the entropy and Y is a random variable representing the prediction.
+
+
+
+
A further constraint, | GS| < k is imposed to obtain consise explaintations.
+
+
+
Since H(Y) is fixed (recall that the network has already been trained and is now being used in the inference mode), maximizing MI is equivalent to minimizing the conditional entropy H(Y | G = GS, X = XS)
+
+
+
This is equivalent to selecting the subgraph that minimizes the uncertainty in the prediction of y when the computational graph is Gc(v)
+
+
+
+
Optimiation Process
+
+
+
+
Given the exponentially large number of possible subgraphs, we can not directly optimize the given equation.
+
+
+
A “relaxed”-adjacency matrix (whose values are real numbers in the range 0 to 1) is introduced where each element of this fractional adjacency matrix is smaller than the corresponding element of the original adjacency matrix. Gradient descent can be performed on this adjacency matrix.
+
+
+
The “relaxed” GS can be interpreted as a variational approximation of the subgraph distributions of Gc(v) and the objective can be written as min EGSH(Y | G = GS, X = XS)
+
+
+
Now the paper makes a big approximation that the GNN is convex so as to leverage the Jensen inequality and push the expectation inside the entropy term to get an upper bound and then minimize that ie min H(Y | G = Es[GS], X = XS)
+
+
+
The paper reports that the convexity approximation (along with discreteness constraint) works in practice.
+
+
+
Next, mean field approximation is used to decompose P(GS) as a multivariate Bernoulli distrbitution ie product of AS(i, j) for all (i, j) belonging to Gc(v). AS can be optimized directly and its values represent the expectation of the Bernoulli distrbitution on wether the edge ei, j exists.
+
+
+
Given the constraints on AS, it is easier to learn a mask matrix M and optimize that such that AS = M * Ac* Additionally, the sigmod operator can be applied on M.
+
+
+
Once M is learned, only the top k values are retained.
+
+
+
+
Including Node Features in the Explanation
+
+
+
+
Similar to the previous approach, another feature mask is learned (either one for entire GNN or one per node of the GNN) and is used as a feature selector.
+
+
+
The mask could either be learned such that same set of node features (in terms of dimensions) are selected or a different set of features are selected per node. The paper uses the former as it is more straightforward.
+
+
+
Just like before, a “relaxed” mask MT is trained to select features as MT * XS.
+
+
+
One tricky case is where one feature is important but its value is set to 0. In the case, the value will be masked even though it should not be
+
+
+
The workaround is to use Monte Carlo (MC) estimates of marginals of the missing features. This gives a way to assign importance scores to each feature dimension and a form of reparameterization trick is used to perform end-to-end learning.
+
+
+
Masks are encouraged to be discrete by regularizing their element-wise entropy.
+
+
+
Resulting computation graph is valid as in it allows message passing towards the central node v.
+
+
+
+
Multi-Instance Explanations
+
+
+
+
Given a set of nodes (having the label say y), the task is to obtain a global explanation of the predictions.
+
+
+
For the given class, a prototypical reference node is chosen by computing the mean of embeddings of all the nodes in the class and then selecting the node which is closest to the mean.
+
+
+
Now, compute the important computational graph corresponding to this node and align the computational subgraphs of all the other nodes (in the given class) to reference.
+
+
+
Let A* be the adjacency matrix and X* be the feature matrix for the explanation corresponding to the reference node. Let Av and Xv be the adjacency matrix and feature matrix of the to-ber-aligned computational graph.
+
+
+
A relaed alignment matrix P is optimized to align the nodes and features in the two graphs ie we minimize |PTAvP - A*| + *|PTXvP - X*|
+
+
+
Choosing concise explanations helps in efficient graph matching.
+
+
+
For GNNs that compute attention over the entire graph, edges with low attention weight can be pruned to increase efficiency.
GRAD - Compute the gradient of the model loss with respect to the adjacency matrix and the node features to be classified and fix the edges with the highest absolute gradient.
+
+
+
GAT - Graph Attention Network
+
+
+
+
+
The proposed model seems to outperform the baselines both qualitatively and quantitatively. But the results should be taken with a grain of salt as only 2 baselines are considered.
+
+
diff --git a/_site/site/2019/04/02/Meta-Learning-Update-Rules-for-Unsupervised-Representation-Learning.html b/_site/site/2019/04/02/Meta-Learning-Update-Rules-for-Unsupervised-Representation-Learning.html
new file mode 100644
index 00000000..a3242fc2
--- /dev/null
+++ b/_site/site/2019/04/02/Meta-Learning-Update-Rules-for-Unsupervised-Representation-Learning.html
@@ -0,0 +1,122 @@
+
Introduction
+
+
+
+
Standard unsupervised learning aims to learn transferable features. The paper proposes to learn a transferable learning rule (in an unsupervised manner) that can generalize across tasks and architectures.
Consider training the model with supervised learning - φt+1 = SupervisedUpdate(φt, xt, yt, θ).
+
+
+
Here t denotes the step, (x, y) denotes the data points, θ denotes the hyperparameters of the optimizer.
+
+
+
Extending this formulation for meta-learning, one could say that t is the step of the inner loop, θ are the parameters of the meta learning model.
+
+
+
Further, the paper proposes to use φt+1 = UnsupervisedUpdate(φt, xt, θ) ie yt is not used (or even assumed to be available as this is unsupervised learning).
+
+
+
The meta update rule is used to learn the weights of a meta-model by performing SGD on the sum of MetaObjective over the distribution of tasks (over the course of inner loop training).
+
+
+
+
Model
+
+
+
+
Base model: MLP with parameters φt
+
+
+
To ensure that it generalizes across architectures, the update rule is designed to be neural-local ie updates are a function of pre and postsynaptic neurons though, in practice, this constraint is relaxed to decorrelate neurons by using cross neural information.
+
+
+
Each neuron i in every layer l (in the base model) has an update network (MLP) which takes as input the feedforward activations, feedback weights and error signals. ie hbl(i) = MLP(xbl(i), zbl(i), vl+1,
+δl(i), θ)
+
+
+
b - index of the minibatch
+
xl - pre non-linearity activations
+
zl - post non-linearity activations
+
vl - feedback weights
+
δl - error signal
+
+
+
+
All the update networks share the meta parameters θ
+
+
+
The model is run in a standard feed-forward manner and the update network (corresponding to each unit) is used to generate the error signal δlb(i) = lin(hbl(i)).
+
+
+
This loss is backpropogated using the set of learned backward weights vl instead of the forward weights wl.
+
+
+
The weight update Δwl is also generated using a per-neuron update network.
+
+
+
+
Meta Objective
+
+
+
+
The MetaObjective is based on fitting a linear regression model to labeled examples with a small number of data points.
+
+
+
Given the emphasis on learning generalizable features, the weights (of linear regression) are estimated on one batch and evaluated on another batch.
+
+
+
The MetaObjective is to reduce the cosine distance between yb and vTxbL
+
+
+
+
yb - Actual lables on the evaluation batch
+
+
+
xbL - Features of the evaluation batch (using the base model)
+
+
+
v - parameters of the linear regression model (learned on train batch)
+
+
+
+
+
+
Practical Considerations
+
+
+
+
Meta gradients are approximated using truncated backdrop through time.
+
+
+
Increasing variation in the training dataset helps the meta optimization process. Data is augmented with shifts, rotations, and noise. Predicting these coefficients is an auxiliary (regression) task for training the meta-objective.
+
+
+
Training the system requires a lot of resources - 8 days with 512 workers.
+
+
+
+
Results
+
+
+
+
With standard unsupervised learning, the performance (on transfer task) starts declining after some time even though the performance (on the unsupervised task) is improving. This suggests that the objective function for the two tasks starts to mismatch.
+
+
+
UnsupervisedUpdate leads to a better generalization as compared to both VAE and supervised learning (followed by transfer).
+
+
+
UnsupervisedUpdate also leads to a positive transfer across domains (vision to language) when trained for a shorter duration of time (to ensure that the meta-objective does not overfit).
+
+
+
UnsupervisedUpdate also generalizes to larger model architectures and different activation functions.
+
+
diff --git a/_site/site/2019/04/09/Towards-a-natural-benchmark-for-continual-learning.html b/_site/site/2019/04/09/Towards-a-natural-benchmark-for-continual-learning.html
new file mode 100644
index 00000000..a0a48e7a
--- /dev/null
+++ b/_site/site/2019/04/09/Towards-a-natural-benchmark-for-continual-learning.html
@@ -0,0 +1,51 @@
+
Introduction
+
+
+
+
Continual Learning paradigm focuses on learning from a non-stationary stream of data with additional desiderata - transferring knowledge from previously seen task to unseen tasks and being resilient to catastrophic forgetting - all with a fixed memory and computational budget.
+
+
+
This is in contrast to the IID (independent and identically distributed) assumption in statistical learning.
+
+
+
One common example of the non-iid data is setups involving sequential decision making - eg Reinforcement learning.
Many existing benchmarks use MNIST as the underlying dataset (eg Permuted MNIST, Split MNIST, etc). These benchmarks lack complexity and make it hard to observe positive and negative backward transfer.
+
+
+
Most works focus only on the catastrophic forgetting challenge and ignore the other issues (like computation and memory footprint, the capacity of the network, etc).
+
+
+
The paper proposes a new benchmark based on Starcraft II video game to understand the different approaches for lifelong learning.
+
+
+
The sequence of tasks is designed to be a curriculum - the learning agent stats with learning simple skills and later move to more complex tasks. These complex tasks require remembering and composing skills learned in the earlier levels.
+
+
+
To evaluate for catastrophic forgetting, the tasks are designed such that not all the skills are needed for solving each task. Hence the learning agent needs to remember skills even though they are not needed at the current level.
+
+
+
Each level comes with a fixed computational budget of episodes and each episode has a fixed time limit. Once the budget is consumed the agent has to proceed to the next level. Hence agents with better sample efficiency would benefit.
+
+
+
The benchmark supports both RL and supervised learning version. In the supervised version, expert agents (pretrained on each level) are also provided.
+
+
+
Baselines are provided for distillation (using experts): sequential training (fine tuning), Dropout and SER. None of the baseline methods achieve positive or negative backward transfer.
+
+
+
When modeled as a pure RL task, the benchmark is extremely difficult to solve.
+
+
+
The paper suggests using a metric to record the amount of learning/data required to recover performance on the previous task.
+
+
diff --git a/_site/site/2019/05/14/Multiple-Model-Based-Reinforcement-Learning.html b/_site/site/2019/05/14/Multiple-Model-Based-Reinforcement-Learning.html
new file mode 100644
index 00000000..9ce04fb3
--- /dev/null
+++ b/_site/site/2019/05/14/Multiple-Model-Based-Reinforcement-Learning.html
@@ -0,0 +1,56 @@
+
+
+
The paper presents some general ideas and mechanisms for multiple model-based RL. Even though the task and model architecture may not be very relevant now, I find the general idea and the mechanisms to be quite useful. As such, I am focusing only on high-level ideas and not the implementation details themselves.
+
+
+
The main idea behind Multiple Model-based RL (MMRL) is to decompose complex tasks into multiple domains in space and time so that the environment dynamics within each domain is predictable.
MMRL proposes an RL architecture composes of multiple modules, each with its own state prediction model and RL controller.
+
+
+
The prediction error from each of the state prediction model defines the “responsibility signal” for each module.
+
+
+
This responsibility signal is used to:
+
+
+
+
Weigh the state prediction output ie the predicted state is the weighted sum of individual state predictions (weighted by the responsibility signal).
+
+
+
Weigh the parameter update of the environment models as well as the RL controllers.
+
+
+
Weighing the action output - ie predicted action is a weighted sum of individual actions.
+
+
+
+
+
The framework is amenable for incorporating prior knowledge about which module should be selected.
+
+
+
In the modular decomposition of a task, the modules should not change too frequently and some kind of spatial and temporal continuity is also desired.
+
+
+
Temporal continuity can be accounted for by using the previous responsibility signal as input during the current timestep.
+
+
+
Spatial continuity can b ensured by considering a spatial prior like the Gaussian spatial prior.
+
+
+
Though model-free methods could be used for learning the RL controllers, model-based methods could be more relevant given that the modules are learning state-prediction models as well.
+
+
+
Exploration can be ensured by using a stochastic version of greedy action selection.
+
+
+
One failure mode for such modular architectures is when a single module tries to perform well across all the tasks. The modules themselves should be relatively simplistic (eg linear models) which can learn quickly and generalize well.
+
+
+
Non-stationary hunting task in a grid world and non-linear, non-stationary control task of swinging up a pendulum provides the proof of concept for the proposed methods.
+
+
diff --git a/_site/site/2019/05/21/Good-Enough-Compositional-Data-Augmentation.html b/_site/site/2019/05/21/Good-Enough-Compositional-Data-Augmentation.html
new file mode 100644
index 00000000..fec0d400
--- /dev/null
+++ b/_site/site/2019/05/21/Good-Enough-Compositional-Data-Augmentation.html
@@ -0,0 +1,47 @@
+
Introduction
+
+
+
+
The paper introduces a simple data augmentation protocol that provides a good compositional inductive bias for sequential models.
+
+
+
Synthetic examples are created by taking real sequences and replacing the fragments in sequences which appear in similar environments. This operation is referred to as GECA (Good Enough Compositional Augmentation).
+
+
+
The underlying idea is that if two fragments of training examples occur in some environment, then any environment where the first fragment appears is also a valid environment for the second fragment.
Discover substitutable fragments (ie pairs of fragments that co-occur with a common fragment) and use them to generate new sequences by swapping fragments.
+
+
+
The current work uses very simple criteria to decide if fragments are substitutable - fragments should occur in at least one lexical environment that is exactly the same. A lexical environment is the k-word window around each span of the fragment.
+
+
+
Though the idea can be motivated by work in generative syntax and distributional semantics, it would not hold like a physical law when applied to the real data.
+
+
+
The authors view this tradeoff as a balance between the shortage of training data vs relative frequency of mistake in the proposed data augmentation approach.
+
+
+
+
Results
+
+
+
+
The approach is evaluated on the SCAN dataset when the model is trained on the short sequence of English commands. Though the dataset augmentation helps the baseline models, it is not surprising given the nature of the SCAN dataset.
+
+
+
More challenging tasks (for evaluating the proposed approach) are semantic parsing (where the query is represented in the form of λ calculus or SQL and low resource language modeling. While the improvement (in terms of metrics) is sometimes limited, the gains are consistent across different datasets.
+
+
+
Given that the proposed approach is relatively simple and straightforward, it appears to be quite promising.
+
+
diff --git a/_site/site/2019/06/01/Relational-Reinforcement-Learning.html b/_site/site/2019/06/01/Relational-Reinforcement-Learning.html
new file mode 100644
index 00000000..724c013d
--- /dev/null
+++ b/_site/site/2019/06/01/Relational-Reinforcement-Learning.html
@@ -0,0 +1,121 @@
+
Introduction
+
+
+
+
Relational Reinforcement Learning (RRL) paradigm uses relational state (and action) space and policy representation to leverage the generalization capability of relational learning for reinforcement learning.
+
+
+
The paper shows that effectiveness of RRL - in terms of generalization, sample efficiency and interplay - using box-world and StarCraft II minigames.
The main idea is to use neural network models that operate on structured representations and perform relational reasoning via iterated, message-passing style methods.
+
+
+
Use of non-local computations using a shared function (in terms of pairwise interactions between entities) provides a better inductive bias.
+
+
+
Multi-head dot product attention mechanism is used to model the pairwise interactions (with one or more attention blocks).
+
+
+
Iterative computations can be used to capture higher-order interactions between entities.
+
+
+
Entity extraction is based on the assumption that entities are things located at a particular point in space.
+
+
+
A CNN is used to parse the pixel space observation into k feature maps of size nxn. The (x, y) coordinates are concatenated to each k-dimensional pixel feature-vector to indicate the pixel’s position in the map.
+
+
+
The resulting n2 x k matrix acts as the entity matrix.
+
+
+
Actor-critic architecture (using distributed agent IMPALA) is used.
+
+
+
+
Environment
+
+
Box-World
+
+
+
+
12 x 12-pixel room with keys and boxes placed randomly.
+
+
+
Agent can move in 4 directions.
+
+
+
The task is to collect gems by unlocking boxes (which may contain keys to unlock other boxes).
+
+
+
Each level has a unique sequence in which boxes need to be opened as opening the wrong box could make the level unsolvable.
+
+
+
Difficulty of a level can be controlled using: (i) Number of boxes in the path to the goal. (ii) The number of distractor branches, (iii) Length of distractor branches.
+
+
+
+
StarCraft II minigames
+
+
+
9 mini games designed as specific scenarios in the Starcraft game are used.
+
+
+
Results
+
+
Box-World
+
+
+
+
RRL agents solve over 98% of the levels while the RL agent solves less than 95% of the levels.
+
+
+
Visualising the attention scores indicate that:
+
+
+
+
keys attend to locks they can unlock.
+
+
+
all objects attend to agent’s location.
+
+
+
agent and gem attend to each other (and themselves).
+
+
+
+
+
Generalization capacity is tested in two ways:
+
+
+
+
Performance on levels that require opening a larger sequence of boxes than it is trained on.
+
+
+
Performance on levels that require key-lock combinations not seen during training.
+
+
+
+
+
In both the scenarios, the RRL agent significantly outperforms the RL agent.
+
+
+
+
StarCraft
+
+
+
+
RLL agent achieves better or equal results that the RL agent in all but one game.
+
+
+
For testing generalization, the agent, that was trained for controlling two marines, was transferred on the task which requires it to control 5 marines. These results are not conclusive given the high variability.
+
+
diff --git a/_site/site/2019/06/08/Meta-Reinforcement-Learning-of-Structured-Exploration-Strategies.html b/_site/site/2019/06/08/Meta-Reinforcement-Learning-of-Structured-Exploration-Strategies.html
new file mode 100644
index 00000000..759c1ddf
--- /dev/null
+++ b/_site/site/2019/06/08/Meta-Reinforcement-Learning-of-Structured-Exploration-Strategies.html
@@ -0,0 +1,92 @@
+
Introduction
+
+
+
+
The paper looks at the problem of learning structured exploration policies for training RL agents.
Consider a stochastic, parameterized policy πθ(a|s) where θ represents the policy-parameters.
+
+
+
To encourage exploration, noise can be added to the policy at each time step t. But the noise added in such a manner does not have any notion of temporal coherence.
+
+
+
Another issue is that if the policy is represented by a simple distribution (say parameterized unimodal Gaussian), it can not model complex time-correlated stochastic processes.
+
+
+
The paper proposes to condition the policy on per-episode random variables (z) which are sampled from a learned latent distribution.
+
+
+
Consider a distibution over the tasks p(T). At the start of any episode of the ith task, a latent variable zi is sampled from the distribution N(μi, σi) where μi and σi are the learned parameters of the distribution and are referred to as the variation parameters.
+
+
+
Once sampled, the same zi is used to condition the policy for as long as the current episode lasts and the action is sampled from then distribution πθ(a|s, zi).
+
+
+
The intuition is that the latent variable zi would encode the notion of a task or goal that does not change arbitrarily during the episode.
+
+
+
+
Model Agnostic Exploration with Structured Noise
+
+
+
+
The paper focuses on the setting where the structured exploration policies are to be learned while leveraging the learning from prior tasks.
+
+
+
A meta-learning approach, called as model agnostic exploration with structured noise (MAESN) is proposed to learn a good initialization of the policy-parameters and to learn a latent space (for sampling the z from) that can inject structured stochasticity in the policy.
+
+
+
General meta-RL approaches have two limitations when it comes to “learning to explore”:
+
+
+
Casting meta-RL problems as RL problems lead to policies that do not exhibit sufficient variability to explore effectively.
+
Many current approaches try to meta-learn the entire learning algorithm which limits the asymptotic performance of the model.
+
+
+
+
Idea behind MAESN is to meta-train policy-parameters so that they learn to use the task-specific latent variables for exploration and can quickly adapt to a new task.
+
+
+
An important detail is that the parameters are optimized to maximize the expected rewards after one step of gradient update to ensure that the policy uses the latent variables for exploration.
+
+
+
For every iteration of meta-training, an “inner” gradient update is performed on the variational parameters and the post-inner-update parameters are used to perform the meta-update.
+
+
+
The authors report that performing the “inner” gradient update on the policy-parameters does not help the overall learning objective and that the step size for each parameter had to be meta-learned.
+
+
+
The variation parameters have the usual KL divergence loss which encourages them to be close to the prior distribution (unit Gaussian in this case).
+
+
+
After training, the variational parameters for each task are quite close to the prior probably because the training objective optimizes for the expected reward after one step of gradient descent on the variational parameters.
+
+
+
Another implementation detail is that reward shaping is used to ensure that the policy gets useful signal during meta-training. To be fair to the baselines, reward shaping is used while training baselines as well. Moreover, the policies trained with reward shaping generalizes to sparse reward setup as well (during meta-test time).
+
+
+
+
Experiments
+
+
+
+
Three tasks distributions: Robotic Manipulation, Wheeled Locomotion, and Legged Locomotion. Each task distribution has 100 meta-training tasks.
+
+
+
In the Manipulation task distribution, the learner has to push different blocks from different positions to different goal positions. In the Locomotion task distributions, the different tasks correspond to the different goal positions.
+
+
+
The experiments show that the proposed approach can adapt to new tasks quickly and the learn coherent exploration strategy.
+
+
+
+
• In some cases, learning from scratch also provides a strong asymptotic performance although learning from scratch takes much longer.
diff --git a/_site/site/2019/06/13/Extrapolating-Beyond-Suboptimal-Demonstrations-via-Inverse-Reinforcement-Learning-from-Observations.html b/_site/site/2019/06/13/Extrapolating-Beyond-Suboptimal-Demonstrations-via-Inverse-Reinforcement-Learning-from-Observations.html
new file mode 100644
index 00000000..a2a21f00
--- /dev/null
+++ b/_site/site/2019/06/13/Extrapolating-Beyond-Suboptimal-Demonstrations-via-Inverse-Reinforcement-Learning-from-Observations.html
@@ -0,0 +1,72 @@
+
Introduction
+
+
+
+
The paper proposes a new inverse RL (IRL) algorithm, called as Trajectory-ranked Reward EXtrapolation (T-REX) that learns a reward function from a collection of ranked trajectories.
+
+
+
Standard IRL approaches aim to learn a reward function that “justifies” the demonstration policy and hence those approaches cannot outperform the demonstration policy.
+
+
+
In contrast, T-REX aims to learn a reward function that “explains” the ranking over demonstrations and can learn a policy that outperforms the demonstration policy.
The input is a sequence of trajectories T1, … Tm which are ranked in the order of preference. That is, given any pair of trajectories, we know which of the two trajectories is better.
+
+
+
The setup is to learn from observations where the learning agent does not have access to the true reward function or the action taken by the demonstration policy.
+
+
+
Reward Inference
+
+
+
+
A parameterized reward function rθ is trained with the ranking information using a binary classification loss function which aims to predict which of the two given trajectory would be ranked higher.
+
+
+
Given a trajectory, the reward function predicts the reward for each state. The sum of rewards (corresponding to the two trajectories) is used used to predict the preferred trajectory.
+
+
+
T-REX uses partial trajectories instead of full trajectories as a data augmentation strategy.
+
+
+
+
+
Policy Optimization
+
+
+
Once a reward function has been learned, standard RL approaches can be used to train a new policy.
In terms of reward extrapolation, T-REX can predict the reward for trajectories which are better than the demonstration trajectories.
+
+
+
Some ablation studies considered the effect of adding noise (random swapping the preference between trajectories) and found that the model is somewhat robust to noise up to an extent.
+
+
diff --git a/_site/site/2019/06/20/Hamiltonian-Neural-Networks.html b/_site/site/2019/06/20/Hamiltonian-Neural-Networks.html
new file mode 100644
index 00000000..ee138e4d
--- /dev/null
+++ b/_site/site/2019/06/20/Hamiltonian-Neural-Networks.html
@@ -0,0 +1,79 @@
+
Introduction
+
+
+
+
The paper proposes a very cool idea at the intersection of deep learning and physics.
+
+
+
The idea is to train a neural network architecture that builds on the concept of Hamiltonian Mechanics (from Physics) to learn physical conservation laws in an unsupervised manner.
It is a branch of physics that can describe systems which follow some conservation laws and invariants.
+
+
+
Consider a set of N pair of coordinates [(q1, p1), …, (qN, pN)] where q = [q1, …, qN] dnotes the position of the set of objects while p = [p1, …, pN] denotes the momentum of the set of variables.
+
+
+
Together these N pairs completely describe the system.
+
+
+
A scalar function H(q, p), called as the Hamiltonian is defined such that the partial derivative of H with respect to p is equal to derivative of q with respect to time t and the negative of partial derivative of H with respect to q is equal to derivative of p with respect to time t.
+
+
+
This can be expressed in the form of the equation as follows:
+
+
+
+
+
+
+
The Hamiltonian can be tied to the total energy of the system and can be used in any system where the total energy is conserved.
+
+
+
Hamiltonian Neural Network (HNN)
+
+
+
+
The Hamiltonian H can be parameterized using a neural network and can learn conserved quantities from the data in an unsupervised manner.
+
+
+
The loss function looks as follows:
+
+
+
+
+
+
+
The partial derivatives can be obtained by computing the in-graph gradient of the output variables with respect to the input variables.
+
+
+
Observations
+
+
+
+
For setups where the energy must be conserved exactly, (eg ideal mass-spring and ideal pendulum), the HNN learn to preserve an energy-like scalar.
+
+
+
For setups where the energy need not be conserved exactly, the HNNs still learn to preserve the energy thus highlighting a limitation of HNNs.
+
+
+
In case of two body problems, the HNN model is shown to be much more robust when making predictions over longer time horizons as compared to the baselines.
+
+
+
In the final experiment, the model is trained on pixel observations and not state observations. In this case, two auxiliary losses are added: auto-encoder reconstruction loss and a loss on the latent space representations. Similar to the previous experiments, the HNN model makes robust predictions over much longer time horizons.
+
+
diff --git a/_site/site/2019/06/27/Measuring-Abstract-Reasoning-in-Neural-Networks.html b/_site/site/2019/06/27/Measuring-Abstract-Reasoning-in-Neural-Networks.html
new file mode 100644
index 00000000..70ab4f5e
--- /dev/null
+++ b/_site/site/2019/06/27/Measuring-Abstract-Reasoning-in-Neural-Networks.html
@@ -0,0 +1,165 @@
+
Introduction
+
+
+
+
The paper proposes a dataset to diagnose the abstract reasoning capabilities of learning systems.
+
+
+
The paper shows that a variant of the relational networks, explicitly designed for abstract reasoning, outperforms models like ResNets.
Visual reasoning tasks, that are inspired by the human IQ test, are used to evaluate the models in terms of generalization.
+
+
+
Let’s say that we want to test if the model understands the abstract notion of “increasing”. We could train the model on data that captures the notion of “increasing”, in terms of say increasing size (or quantities) of objects and then test it on a dataset where the notion is expressed in terms of increasing intensity of color.
+
+
+
The dataset is then used to evaluate if the models can find any solution to such abstract reasoning tasks and how well they generalize when the abstract content is specifically controlled.
+
+
+
+
Dataset
+
+
Raven’s Progressive Matrics (RPMs):
+
+
+
+
Consists of an incomplete 3x3 matrix of images where the missing image needs to be filled in, typically by choosing from a set of candidate images.
+
+
+
As such, it is possible to justify multiple answers to be correct though, in practice, the right answer is the one with the simplest explanation.
+
+
+
+
Procedurally Generated Matrices (PGMs)
+
+
+
+
Generating RPM like matrices procedurally by building an abstract structure for matrices.
+
+
+
+
+
+
The abstract structure S consists of 3 components: (i) Relation types (R), (ii) Object types (O) and (iii) Attribute types (A). ie *S = {(r, o, a)
+
r in R, o in O and a in A}*.
+
+
+
+
+
+
This can be read as: “Structure S is instantiated on attribute a of object o and exhibits the relation r”. For example, S is instantiated on “color” of object “shape” and exhibits the relation “increasing”.
+
+
+
In general, the structure could be made of more than one such tuple and more are the tuples, harder is the task.
+
+
+
Given the structure, sample values v for each attribute a while conforming with the relation r. For example, if the attribute is “color” and the relation is “increasing”, the intensity of color must increase.
+
+
The resulting structure is rendered as pixels.
+
+
+
Test for Generalization
+
+
+
+
The paper tests for the following generalization scenarios:
+
+
+
Neutral: The structure of the training and test data can contain any tuple.
+
+
+
Interpolation: The training data contains even-indexed members of the attribute values while the test data contains odd-indexed members of the attribute values.
+
+
+
Extrapolation: The training data contains first-half of the attribute values while the test data contains the second-half of the attribute values.
+
+
+
Heldout attribute: Training data contains no tuples with (o = shape, a = color) or (o = line, a = type).
+
+
+
Heldout triples: Out of 29 possible triples, 7 are held out from training and only used during testing.
+
+
+
Heldout pair-of-triples: Out of 400 possible sets of pair of triples, 40 were held out and used only during testing.
+
+
+
Heldout pair-of-triples: Out of 400 possible sets of pair of triples, 40 were held out and used only during testing.
+
+
+
Heldout attribute pair: Out of 20 (unordered) variable attribute pairs, 4 were held out and used only during testing.
+
+
+
+
Models
+
+
+
+
Input: 8 context panels (from the 3x3) matrix where the last panel needs to be filled.
+
+
+
CNN-MLP - 4 layer CNN with batchnorm and ReLU.
+
+
+
ResNet - ResNet-50 (as it perfomed better than ResNet-101 and ResNet-152).
+
+
+
LSTM
+
+
+
Wild Relation Network (WReN) - A CNN model encodes the 8 panels and the candidate answers and feeds them as input to a relational network.
+
+
+
Context-blind ResNet - ResNet network without the context (or the 8 input panels).
+
+
+
+
Results
+
+
+
+
WReN model outperforms the other models on the Neutral setup.
+
+
+
Models have a harder time differentiating between size than quantity.
+
+
+
WRen is the best performing models in all the setups and rest of the discussion only applies to that model.
+
+
+
Generalisation is easy in the context of interpolation while worst in case of extrapolation, hinting at the limited generalization capability of the models.
+
+
+
+
Auxiliary Training
+
+
+
+
The model is also trained to predict the relevant relation, object and attribute types using the meta-targets that encode this information.
+
+
+
The auxiliary training helps in all the cases. Further, the model’s accuracy on the main task is where in the cases where it solves the auxiliary tasks well.
+
+
+
+
Key Takeaway
+
+
+
+
For abstract visual reasoning tasks, the choice of models can make a large difference, the case in consideration of ResNets vs Relational Networks.
+
+
+
Using auxiliary loss that encourages the model to “explain” its reasoning (in this case by predicting the attributes, relations, etc) helps to improve the performance on the main task as well.
+
+
+
Given that the challenge is motivated by tasks used to measure human IQ, it would have been interesting to get an estimate of human performance on at least a subset of this dataset.
+
+
diff --git a/_site/site/2019/07/18/Set-Transformer-A-Framework-for-Attention-based-Permutation-Invariant-Neural-Networks.html b/_site/site/2019/07/18/Set-Transformer-A-Framework-for-Attention-based-Permutation-Invariant-Neural-Networks.html
new file mode 100644
index 00000000..02555698
--- /dev/null
+++ b/_site/site/2019/07/18/Set-Transformer-A-Framework-for-Attention-based-Permutation-Invariant-Neural-Networks.html
@@ -0,0 +1,103 @@
+
Introduction
+
+
+
+
Consider problems where the input to the model is a set. In such problems (referred to as the set-input problems), the model should be invariant to the permutation of the data points.
+
+
+
In “set pooling” methods (1, 2), each data point (in the input set) is encoded using a feed-forward network and the resulting set of encoded representations are pooled using the “sum” operator.
+
+
+
This approach can be shown to be bot permutation-invariant and a universal function approximator.
+
+
+
The paper proposes an attention-based network module, called as the Set Transformer, which can model the interactions between the elements of an input set while being permutation invariant.
An attention function Attn(Q, K, V) = (QKT)V is used to map queries Q to output using key-value pairs K, V.
+
+
+
In case of multi-head attention, the key, query, and value are projected into h different vectors and attention is applied on all these vectors. The output is a linear transformation of the concatenation of all the vectors.
+
+
+
+
Set Transformer
+
+
+
+
3 modules are introduced: MAB, SAB and ISAB.
+
+
+
Multihead Attention Block (MAB) is a module very similar to to the encoder in the Transformer, without the positional encoding and dropout.
+
+
+
Set Attention Block (SAB) is a module that takes as input a set and performs self-attention between the elements of the set to produce another set of the same size ie SAB(X) = MAB(X, X).
+
+
+
The time complexity of the SAB operation is O(n2) where n is the number of elements in the set. It can be reduced to O(m*n) by using Induced Set Attention Blocks (ISAB) with m induced point vectors (denoted as I).
+
+
+
ISABm = MAB(X, MAB(I, X)).
+
+
+
ISAB can be seen as performing a low-rank projection of inputs.
+
+
+
These modules can be used to model the interactions between data points in any given set.
+
+
+
+
Pooling by Multihead Attention (PMA)
+
+
+
+
Aggregation is performed by applying multi-head attention on a set of k seed vectors.
+
+
+
The interaction between the k outputs (from PMA) can be modeled by applying another SAB.
+
+
+
Thus the entire network is a stack of SABs and ISABs. Both the modules are permutation invariant and so is any network obtained by stacking them.
+
+
+
+
Experiments
+
+
+
+
Datasets include:
+
+
+
Predicting the maximum value from a set.
+
Counting unique (Omniglot) characters from an image.
+
Clustering with a mixture of Gaussians (synthetic points and CIFAR 100).
+
Set Anomaly detection (celebA).
+
+
+
+
Generally, increasing m (the number of inducing datapoints) improve performance, to some extent. This is somewhat expected.
+
+
+
The paper considers various ablations of the proposed approach (like disabling attention in the encoder or pooling layer) and shows that attention mechanism is needed during both the stages.
+
+
+
The work has two main benefits over prior work:
+
+
+
+
Reducing the O(n2) complexity to O(m*n) complexity.
+
+
+
Using self-attention mechanism for both encodings the inputs and for aggregating the encoded representations.
+
+
+
+
diff --git a/_site/site/2019/07/25/Quantifying-Generalization-in-Reinforcement-Learning.html b/_site/site/2019/07/25/Quantifying-Generalization-in-Reinforcement-Learning.html
new file mode 100644
index 00000000..5db404b6
--- /dev/null
+++ b/_site/site/2019/07/25/Quantifying-Generalization-in-Reinforcement-Learning.html
@@ -0,0 +1,128 @@
+
Introduction
+
+
+
+
The paper introduces a new, procedurally generated environment called as CoinRun that is designed to benchmark the generalization capabilities of RL algorithms.
+
+
+
The paper reports that deep convolutional architectures and techniques like L2 regularization, batch norm, etc (which were proposed in the context of generalization in supervised learning) are also useful for RL.
IMPALA-CNN agent always outperforms the Nature-CNN agent indicating that larger architecture has more capacity for generalization. But increasing the network size beyond a limit gives diminishing returns.
+
+
+
+
Evaluating Regularization
+
+
+
+
While both L2 regularization and Dropout helps to improve generalization, L2 regularization is more impactful.
+
+
+
A domain randomization/data augmentation approach is tested where rectangular regions of different sizes are masked and assigned a random color. This approach seems to improve performance.
+
+
+
Batch Normalization helps to improve performance as well.
+
+
+
Environment stochasticity is introduced by using sticky actions while policy stochasticity is introduced by controlling the entropy bonus. Both these forms of stochasticity boost performance.
+
+
+
While combining different regularization methods help, the gains are only marginally better than using just 1 regularization approach. This suggests that these different approaches induce similar generalization properties.
+
+
+
+
Additional Environments
+
+
+
+
Two additional environments are also considered to verify the high degree of overfitting observed in the CoinRun environment:
+
+
+
+
CoinRun-Platforms:
+
+
+
+
Unlike CoinRun, each episode can have multiple coins and the time limit is 0increased to 1000 steps.
+
+
+
Levels are larger as well so the agent might need to backtrack their steps.
+
+
+
+
+
RandomMazes:
+
+
+
+
Partially observed environment with square mazes of dimensions 3x3 to 25x25.
+
+
+
Timelimit of 500 steps
+
+
+
+
+
+
+
Overfitting is observed for both these environments as well.
+
+
diff --git a/_site/site/2019/08/01/Assessing-Generalization-in-Deep-Reinforcement-Learning.html b/_site/site/2019/08/01/Assessing-Generalization-in-Deep-Reinforcement-Learning.html
new file mode 100644
index 00000000..23fa865e
--- /dev/null
+++ b/_site/site/2019/08/01/Assessing-Generalization-in-Deep-Reinforcement-Learning.html
@@ -0,0 +1,141 @@
+
+
+
The paper presents a benchmark and experimental protocol (environments, metrics, baselines, training/testing setup) to evaluate RL algorithms for generalization.
+
+
+
Several RL algorithms are evaluated and the key takeaway is that the “vanilla” RL algorithms can generalize better than the RL algorithms that are specifically designed to generalize, given enough diversity in the distribution of the training environments.
The focus is on evaluating generalization to environmental changes that affect the system dynamics (and not the goal or rewards).
+
+
+
Two generalization regimes are considered:
+
+
+
+
Interpolation - parameters of the test environment are similar to the parameters of the training environment.
+
+
+
Extrapolation - parameters of the test environment are different from the parameters of the training environment.
+
+
+
+
+
Following algorithms are considered as part of the benchmark:
+
+
+
+
“Vanilla” RL algorithms - A2C, PPO
+
+
+
RL algorithms that are designed to generalize:
+
+
+
+
EPOpt - Learn a (robust) policy that maximizes the expected reward over the most difficult distribution of environments (ones with the worst expected reward).
+
+
+
RL2 - Learn an (adaptive) policy that can adapt to the current environment/task by considering the trajectory and not just the state transition sequence.
+
+
+
+
+
These specially designed RL algorithms can be optimized using either A2C or PPO leading to combinations like EPOpt-A2C or EPOpt-PPO etc.
+
+
+
The models are either composed of feedforward networks completely or feedforward + recurrent networks.
+
+
+
+
+
Environments
+
+
+
+
CartPole, MountainCar, Acrobot, and Pendulum from OpenAI Gym.
+
+
+
HalfCheetah and Hopper from OpenAI Roboschool.
+
+
+
Three versions of each environment are considered:
+
+
+
+
Deterministic: Environment parameters are fixed. This case corresponds to the standard environment setup in classical RL.
+
+
+
Random: Environment parameters are sampled randomly. This case corresponds to sampling from a distribution of environments.
+
+
+
Extreme: Environment parameters are sampled from their extreme values. This case corresponds to the edge-case environments which would not be encountered during training generally.
+
+
+
+
+
+
+
Performance Metrics
+
+
+
+
Average total reward per episode.
+
+
+
Success percentage: Percentage of episodes where a certain goal (or reward) is obtained.
+
+
+
+
+
Evaluation Metrics/Setups
+
+
+
+
Default: success percentage when training and evaluating the deterministic version of the environment.
+
+
+
Interpolation: success percentage when training and evaluating on the random version of the environment.
+
+
+
Extrapolation: the geometric mean of the success percentage of following three versions:
+
+
+
+
Train on deterministic and evaluate on the random version.
+
+
+
Train on deterministic and evaluate on extreme version.
+
+
+
Train on random and evaluate on the extreme version.
+
+
+
+
+
+
+
Observations
+
+
+
+
Extrapolation is harder than interpolation.
+
+
+
Increasing the diversity in the training environments improves the interpolation generalization of vanilla RL methods.
+
+
+
EPOpt improves generalization only for continuous control environments and only with PPO.
+
+
+
RL2 is difficult to train on the environments considered and did not provide a clear advantage in terms of generalization.
+
+
+
EPOpt-PPO outperforms PPO on only 3 environments and EPOpt-A2C does not
+
+
+
+
+
diff --git a/_site/site/2019/08/08/Deep-Reinforcement-Learning-in-a-Handful-of-Trials-using-Probabilistic-Dynamics-Models.html b/_site/site/2019/08/08/Deep-Reinforcement-Learning-in-a-Handful-of-Trials-using-Probabilistic-Dynamics-Models.html
new file mode 100644
index 00000000..ecfcd8ec
--- /dev/null
+++ b/_site/site/2019/08/08/Deep-Reinforcement-Learning-in-a-Handful-of-Trials-using-Probabilistic-Dynamics-Models.html
@@ -0,0 +1,81 @@
+
Introduction
+
+
+
+
The paper proposes a new algorithm called as Probabilistic Ensemble with Trajectory sampling (PETS) that combines uncertainty aware deep learning models (ensemble of deep learning models that encode uncertainty) with sampling-based uncertainty propagation.
+
+
+
PETS improves over other probabilistic MBRL approaches by isolating epistemic uncertainty (due to limited training data) and aleatoric uncertainty (inherent in the system).
Aleatoric uncertainty can be accounted for by learning a parameterized distribution (probabilistic neural network) trained with negative log-likelihood.
+
+
+
Epistemic uncertainty can be accounted for by either having an infinite amount of data or by using ensembles.
+
+
+
The paper uses a neural network to predict the mean and standard deviation of a gaussian distribution which defines the predictive model. This setup is referred to as the “probabilistic” model and denoted by P.
+
+
+
The alternate setup of the deterministic model is where a neural network is used to make a point prediction (and is denoted by D).
+
+
+
Ensemble of probabilistic models is denoted as PE while that of deterministic models is denoted as DE.
+
+
+
+
Planning and Control with learned Dynamics
+
+
+
+
Model Predictive Control (MPC) is used for planning.
+
+
+
Given a start state and an action sequence, the probabilistic dynamics model induces a distribution over the trajectories.
+
+
+
The first action, among the sequence of optimized actions, is executed.
Let us say there are B bootstrap models in the ensemble. Given the current state, P particles are created and each particle is propagated using one of the bootstrap models. Two variants are considered:
+
+
+
+
TS1 - At each timestep, each particle samples a bootstrap. In this case, particle separation can not be attributed to ti the compounding effects of the bootstraps.
+
+
+
TS$\infty$ - The bootstrapped model (per particle) is sampled just once and is not changed after that. This setup separates aleatoric and epistemic uncertainty. Aleatoric state variance is the average variance of the particles of the same bootstrap while epistemic state variance is the variance of the average of particles of same bootstrap indexes.
+
+
+
+
+
+
Result
+
+
+
+
The proposed approach reaches the asymptotic performance of state-of-the-art model-free algorithms in much fewer samples.
+
+
+
The general performance trend is probabilistic emsemble > probabilisitc model > deterministc ensemble > determinisitc model./.
+
+
+
Initial experiments for learning policy by propagating gradients through the ensemble of models did not work and has been left as future work.
+
+
diff --git a/_site/site/2019/08/15/Abductive-Commonsense-Reasoning.html b/_site/site/2019/08/15/Abductive-Commonsense-Reasoning.html
new file mode 100644
index 00000000..543daada
--- /dev/null
+++ b/_site/site/2019/08/15/Abductive-Commonsense-Reasoning.html
@@ -0,0 +1,80 @@
+
Introduction
+
+
+
+
The paper presents the task of abductive NLP (pronounced as alpha NLP) where the model needs to perform abductive reasoning.
+
+
+
Abductive reasoning is the inference to the most plausible explanation. Even though it is considered to be an important component for understanding narratives, the work in this domain is sparse.
+
+
+
A new dataset called as Abstractive Reasoning in narrative Text (ART) consisting of 20K narrative contexts and 200k explanations is also provided. The dataset models the task as multiple-choice questions to make the evaluation process easy.
Given a pair of observations O1 and O2 and two hypothesis h1 and h2, the task is to select the most plausible hypothesis.
+
+
+
In general, P(h | O1, O2) is propotional to P(h |O1)P(O2|h, O1).
+
+
+
Different independence assumptions can be imposed on the structure of the problem eg one assumption could be that the hypothesis is independent of the observations or the “fully connected” assumption would jointly model both the observations and the hypothesis.
+
+
+
+
Dataset
+
+
+
+
Along with crowdsourcing several plausible hypotheses for each observation instance pair, an adversarial filtering algorithm (AF) is used to remove weak pairs of hypothesis.
+
+
+
Observation pairs are created using the ROCStories dataset which is a collection of short, manually crafted stories of 5 sentences.
+
+
+
The average word length for both the content and the hypothesis is between 8 to 9.
+
+
+
To collect plausible hypothesis, the crowd workers were asked to fill in a plausible “in-between” sentence in natural language.
+
+
+
Given the plausible hypothesis, the crowd workers were asked to create an implausible hypothesis by editing fewer than 6 words.
+
+
+
Adversarial filtering approach from Zellers et al. is used with BERT as the adversary. A temperature parameter is introduced to control the maximum number of instances that can be changed in each adversarial filtering iteration.
+
+
+
+
Key Observations
+
+
+
+
Human performance: 91.4%
+
+
+
Baselines like SVM classifier, the bag-of-words classifier (using Glove) and max-pooling overt BiLSTM representation: approx 50%
+
+
+
Entailment NLI baseline: 59%. This highlights the additional complexity of abductive NLI as compared to entailment NLI.
+
+
+
BERT: 68.9%
+
+
+
GPT: 63.1%
+
+
+
Numerical and spatial knowledge-based data points are particularly hard.
+
+
+
The model is more likely to fail when the narrative created by the incorrect hypothesis is plausible
+
+
+
diff --git a/_site/site/2019/08/22/Large-Memory-Layers-with-Product-Keys.html b/_site/site/2019/08/22/Large-Memory-Layers-with-Product-Keys.html
new file mode 100644
index 00000000..e499a864
--- /dev/null
+++ b/_site/site/2019/08/22/Large-Memory-Layers-with-Product-Keys.html
@@ -0,0 +1,105 @@
+
Introduction
+
+
+
The paper proposes a structured key-value memory layer that:
+
Adding batch-norm on top of the query network helps to spread out keys.
+
+
+
+
Key selection module
+
+
+
Lets say there are a total of K keys of dimensionality dq of which we want to select top k keys.
+
Partition the set of keys into two sets of subkeys (say Q1 and Q2) where each subset has K keys of dimensionality d_q/2.
+
The query is split into two subqueries (say q1 and q2).
+
Each of these two queries are compared with every query in their corresponding set of subkeys.
+
For example, q1 is compared with every query is Q1.
+
Top k ranked keys are selected from each set to create two new sets C1 and C22.
+
The keys from these two sets are combined uder the concatenation operator to obtain k2 vectors.
+
the final top k (concatenated) keys are searched from these *k2* keys.
+
The overall complexity is $O((\sqrt K + k^2) \times d_q)$ where K is the total number of keys (whiuc)
+
+
+
+
Value lookup table
+
+
+
The values (corresponding to selected subkeys) are aggregated (using weighted sum operation) to obtain the output.
+
+
+
+
+
+
All the parameters are trainable, though, in practice, only the selected k memory slots are updated.
+
+
+
Using Multihead attention mechanism helps to improve the performance further.
+
+
+
+
Experiments
+
+
+
+
1 or more feedforward layers in transformers are placed by the memory layers.
+
+
+
The model is evaluated on large scale language modeling tasks with 140 Gb of data from common crawl corpora (28n billion words).
+
+
+
Evaluation metrics
+
+
+
+
Perplexity on the test set.
+
+
+
Fraction of accessed values.
+
+
+
KL divergence between the (normalized) weights of key access and uniform distribution.
+
+
+
The last two metrics are used together to determine how well the keys are utilized.
+
+
+
+
+
+
Results
+
+
+
+
Given the large size of the training dataset, adding more layers to the transformer model helps.
+
+
+
Effect of using memory layer is more powerful than the effect of adding new layers to the transformer. For example, a 12 layer transformer + memory layer outperforms a 24 layer transformer while being almost twice as fast.
+
+
+
The best position to place the memory is at an intermediate layer and placing the memory layer right after the input or just before the softmax layer does not work well in practice.
+
+
+
diff --git a/_site/site/2019/08/29/PHYRE-A-New-Benchmark-for-Physical-Reasoning.html b/_site/site/2019/08/29/PHYRE-A-New-Benchmark-for-Physical-Reasoning.html
new file mode 100644
index 00000000..41996628
--- /dev/null
+++ b/_site/site/2019/08/29/PHYRE-A-New-Benchmark-for-Physical-Reasoning.html
@@ -0,0 +1,164 @@
+
Introduction
+
+
+
+
The paper proposes the PHYRE (PHYsical REasoning) benchmark - consisting of classic mechanical puzzles in 2D physical environments - as a means to evaluate the physical reasoning ability of machine learning models.
Non-deformable objects that can be static (ie fixed) or dynamic (ie can move and are affected by collisions etc).
+
+
+
+
Task
+
+
+
+
The learning agent starts in some initial world state (ie configuration of objects).
+
+
+
Goal is described in the form of (subject, relation, object) where the agent’s task is to satisfy the relation between the subject and the object.
+
+
+
Currently, only the “touch” relation is supported.
+
+
+
+
Setup
+
+
+
+
The learning agent has to take a single action - placing one or more new dynamic objects in the world.
+
+
+
A simulator is run on the new configuration (for a fixed amount of time) to check if the goal condition is satisfied.
+
+
+
At the end of the simulation, a binary reward and intermediate observations (collected as the simulator executes) are provided to the learning agent.
+
+
+
These observations are 256*256 grids where each grid cell can take 1 of the 7 values (denoting different types of objects).
+
+
+
Since only one relation supported currently, the color is sufficient to encode the goal.
+
+
+
+
Benchmark Tiers
+
+
+
+
Two benchmark tiers are provided where each tier comprises of a combination of:
+
+
+
+
a predefined set of all the actions that the agent is allowed to perform.
+
+
+
set of tasks that can be solved by at least one action from the allowed action set.
+
+
+
+
+
PHYRE-B - The agent is allowed to place a single (ball of any radii) at any valid location.
+
+
+
PHYRE-2B - The agent is allowed to place 2 balls at any valid pair of locations.
+
+
+
Each of the two tiers has 25 task templates where each template comprises of variants of a single task (same goal but different initial conditions).
+
+
+
+
Evaluation
+
+
+
+
Two evaluation setups are considered:
+
+
+
+
within-template where the agent is trained on some tasks in a template and evaluated on a set of held-out tasks from the same template.
+
+
+
cross-template where the agent is evaluated on tasks from a different template.
+
+
+
+
+
In the training phase, the model has access to the simulator (but not to the correct solution). So the model could learn an action-prediction model or forward dynamics model or both.
+
+
+
In the testing phase, the model can query the simulator only a few times. Each query provides it with the binary reward and the intermediate observations.
+
+
+
+
Performance Measure
+
+
+
+
The emphasis is on solving more tasks (in few queries) during the test phase.
+
+
+
This requirement is captured using a metric called AUCCESS.
+
+
+
In general, the tasks in PHYRE-2B are harder than tasks in PHYRE-B.
+
+
+
+
Baseline Agents
+
+
+
+
Random Agent - Randomly samples actions
+
+
+
Non-parametric agent (MEM) - generates R actions at random and uses the simulator to check how many tasks can be solved using these R random actions. During testing, try the R actions in the decreasing order of the number of tasks they solve.
+
+
+
Non-parametric agent with online learning (MEM-O) - Variant of MEM where an online adaptation step is performed during test time (to update the rank of the actions).
+
+
+
Deep Q Networks with an action encoder, observation encoder and fusion model (combine action and observation representation).
+
+
+
DQN with online learning (DQN-0): Variant of DQN with online updates (during the test phase).
+
+
+
Contextual bandits.
+
+
+
Policy learning approaches like PPO and A2C.
+
+
+
+
Observations
+
+
+
+
Both Contextual bandits and policy-based approaches show poor training stability.
+
+
+
The best agent, DQN-O, reaches AUCCESS of 56.2\% on PHYRE-B and 39.26\% on PHYRE-2B. In general, agents with online adaptation perform better.
+
+
+
The tasks are designed such that 100000 attempts are sufficient to solve 100\% of tasks in PHYRE-B and 95\% of tasks in PHYRE-2B.
+
+
+
Even though only two tiers are provided right now, the benchmark is readily extensible and new tasks can be added in the future.
+
+
diff --git a/_site/site/2019/09/05/How-to-train-your-MAML.html b/_site/site/2019/09/05/How-to-train-your-MAML.html
new file mode 100644
index 00000000..77fc62ce
--- /dev/null
+++ b/_site/site/2019/09/05/How-to-train-your-MAML.html
@@ -0,0 +1,91 @@
+
Introduction
+
+
+
+
The paper proposes MAML++ - a modification of MAML algorithm that stabilizes its training improves generalization performance and reduces the computational overhead.
Training the outer loop requires unfolding the inner loop multiple times.
+
+
+
In absence of skip connections, the gradient is multiplied by the same parameter multiple times.
+
+
+
Large depth and absent skip connections could lead to exploding and vanishing gradients respectively.
+
+
+
The paper proposes to stabilize the gradient propagation by minimizing the target set loss computed by the base-network after every step towards a support set task.
+
+
+
It is important to anneal the contribution of earlier steps and increase the contribution of later steps over time.
+
+
+
+
Second Order derivatives are expensive to compute
+
+
+
+
While the first-order MAML is faster, the resulting model may not have as good a generalization error as the second-order MAML.
+
+
+
The paper proposes to use derivative order annealing where the first order gradients are used for the first 50 epochs and the network uses second-order gradients from thereon.
+
+
+
This derivative order annealing appears to be more stable than models that use second-order derivatives only.
+
+
+
+
Batch Normalization
+
+
+
+
In MAML, the statistics of the current batch are used for normalization instead of accumulating the running statistics.
+
+
+
The paper proposes to collect the statistics per step which can increase the convergence speed, stability, and generalization performance.
+
+
+
In MAML, the batch normalization biases are not updated in the inner-loop which can adversely impact the performance.
+
+
+
The paper proposes to learn a set of biases (per step) within the inner loop update.
+
+
+
+
Fixed Learning Rate
+
+
+
+
MAML uses a single learning rate across all the steps and all the parameters. This means there is one single learning rate that needs to be hyperparameter to work well for all the layers and steps.
+
+
+
An alternate solution would be to learn a separate learning rate per parameter but this can be impractical as it doubles the number of parameters to be learned.
+
+
+
The paper proposes to learn a learning rate and direction for each layer in the network, for each step it takes in the inner loop.
+
+
+
The paper also proposed to anneal the learning rate of the outer loop (using cosine annealing) as it helps to achieve better generalization.
+
+
+
+
Results
+
+
+
+
Using these modifications helps to outperform the MAML model on both Omniglot and MiniImagenet datasets.
+
+
+
The biggest benefit comes by learning the per-layer, per-step learning rates and by using the per-step batch normalization.
+
+
diff --git a/_site/site/2019/09/12/Gossip-based-Actor-Learner-Architectures-for-Deep-RL.html b/_site/site/2019/09/12/Gossip-based-Actor-Learner-Architectures-for-Deep-RL.html
new file mode 100644
index 00000000..6b725d8e
--- /dev/null
+++ b/_site/site/2019/09/12/Gossip-based-Actor-Learner-Architectures-for-Deep-RL.html
@@ -0,0 +1,62 @@
+
The paper considers the task of training an RL system by sampling data from multiple simulators (over parallel devices).
+
+
+
The setup is that of distributed RL setting with n agents or actor-learners (composed of a single learner and several actors). These agents are trying to maximize a common value function.
+
+
+
One (existing) approach is to perform on-policy updates with a shared policy. The policy could be updated in synchronous (does not scale well) or asynchronous manner (can be unstable due to stale gradients).
+
+
+
Off policy approaches allow for better computational efficiency but can be unstable during training.
+
+
+
The paper proposed Gossip based Actor-Learner Architecture (GALA) which uses asynchronous communication (gossip) between the n agents to improve the training of Deep RL models.
+
+
+
These agents are expected to converge to the same policy.
+
+
+
During training, the different agents are not required to share the same policy and it is sufficient that the agent’s policies remain $\epsilon$-close to each other. This relaxation allows the policies to be trained asynchronously.
+
+
+
GALA approach is combined with A2C agents resulting in GALA-A2C agents. They have better computational efficiency and scalability (as compared to A2C) and similar in performance to A3C and Impala.
+
+
+
Training alternates between one local policy-gradient (and TD update) and asynchronous gossip between agents.
+
+
+
During the gossip step, the agents send their parameters to some of the other agents (referred to as the peers) and update their parameters based on the parameters received from the other agents (for which the given agent is a peer).
+
+
+
GALA agents are implemented using non-blocking communication so that they can operate asynchronously.
+
+
+
The paper includes the proof that the policies learned by the different agents are within $\epsilon$ distance of each other (ie all the policies lie within an $\epsilon$-distance ball) thus ensuring that the policies do not diverge much from each other.
+
+
+
Six games from the Ataru 2600 games suite are used for the experiments.
+
+
+
Baselines: A2C, A3C, Impala
+
+
+
GALA agents are configured in a directed ring graph topology.
+
+
+
With A2C, as the number of simulators increases, the number of convergent runs (runs with a threshold reward) decreases.
+
+
+
Using gossip algorithms increases or maintains the number of convergent runs. It also improves the performance, sample efficiency and compute efficiency of A2C across all the six games.
+
+
+
When compared to Impala and A3C, GALA-A2C generally outperforms (or performs as well as) those baselines.
+
+
+
Given that the learned policies remain within an $\epsilon$ ball, the agent’s gradients are less correlated as compared to the A2C agents.
+
+
diff --git a/_site/site/2019/11/28/Contrastive-Learning-of-Structured-World-Models.html b/_site/site/2019/11/28/Contrastive-Learning-of-Structured-World-Models.html
new file mode 100644
index 00000000..8f4786ca
--- /dev/null
+++ b/_site/site/2019/11/28/Contrastive-Learning-of-Structured-World-Models.html
@@ -0,0 +1,131 @@
+
Introduction
+
+
+
+
The paper introduces Contrastively-trained Structured World Models (C-SWMs).
+
+
+
These models use a contrastive approach for learning representations in environments with compositional structure.
The training data is in the form of an experience buffer \(B = \{(s_t, a_t, s_{t+1})\}_{t=1}^T\) of state transition tuples.
+
+
+
The goal is to learn:
+
+
+
+
an encoder \(E\) that maps the observed states $s_t$ (pixel state observations) to latent state $z_t$.
+
+
+
a transition model \(T\) that predicts the dynamics in the hidden state.
+
+
+
+
+
The model defines the enegry of a tuple \((s_t, a_t, s_{t+1})\) as \(H = d(z_t + T(z_t, a_t), z_{t+1})\).
+
+
+
The model has an inductive bias for modeling the effect of action as translation in the abstract state space.
+
+
+
An extra hinge-loss term is added: \(max(0, \gamma - d(z^{~}_{t}, z_{t+1}))\) where \(z^{~}_{t} = E(s^{~}_{t})\) is a corrputed latent state corresponding to a randomly sampled state \(s^{~}_{t}\).
+
+
+
+
Object-Oriented State Factorization
+
+
+
+
The goal is to learn object-oriented representations where each state embedding is structured as a set of objects.
+
+
+
Assuming the number of object slots to be \(K\), the latent space, and the action space can be factored into \(K\) independent latent spaces (\(Z_1 \times ... \times Z_K\)) and action spaces (\(A_1 \times ... \times A_k\)) respectively.
+
+
+
There are K CNN-based object extractors and an MLP-based object encoder.
+
+
+
The actions are represented as one-hot vectors.
+
+
+
A fully connected graph is induced over K objects (representations) and the transition function is modeled as a Graph Neural Network (GNN) over this graph.
+
+
+
The transition function produces the change in the latent state representation of each object.
+
+
+
The factorization can be taken into account in the loss function by summing over the loss corresponding to each object.
+
+
+
+
Environments
+
+
+
+
Grid World Environments - 2D shapes, 3D blocks
+
+
+
Atari games - Pong and Space Invaders
+
+
+
3-body physics simulation
+
+
+
+
Setup
+
+
+
+
Random policy is used to collect the training data.
+
+
+
Evaluation is performed in the latent space (no reconstruction in the pixel space) using ranking metrics. The observations (to compare against) are randomly sampled from the buffer.
In the grid-world environments, C-SWM models the latent dynamics almost perfectly.
+
+
+
Removing either the state factorization or the GNN transition model hurts the performance.
+
+
+
C-SWM performs well on Atari as well but the results tend to have high variance.
+
+
+
The optimal values of $K$ should be obtained by hyperparameter tuning.
+
+
+
For the 3-body physics tasks, both the baselines and proposed models work quite well.
+
+
+
Interestingly, the paper has a section on limitations:
+
+
+
+
The object extractor module can not disambiguate between multiple instances of the same object (in a scene).
+
+
+
The current formulation of C-SWM can only be used with deterministic environments.
+
+
+
+
diff --git a/_site/site/2019/12/05/Mastering-Atari,-Go,-Chess-and-Shogi-by-Planning-with-a-Learned-Model.html b/_site/site/2019/12/05/Mastering-Atari,-Go,-Chess-and-Shogi-by-Planning-with-a-Learned-Model.html
new file mode 100644
index 00000000..95c202e5
--- /dev/null
+++ b/_site/site/2019/12/05/Mastering-Atari,-Go,-Chess-and-Shogi-by-Planning-with-a-Learned-Model.html
@@ -0,0 +1,121 @@
+
Introduction
+
+
+
+
The paper presents the MuZero algorithm that performs planning with a learned model.
+
+
+
The algorithm achieves state of the art results on Atari suite (where generally model-free approaches perform the best) and on planning-oriented games like Chess and Go (where generall planning approaches perform the best).
Model-based approaches generally focus on reconstructing the true environment state or the sequence of full observations.
+
+
+
MuZero focuses on predicting only those aspects that are most relevant for planning - policy, value functions, and rewards.
+
+
+
+
Approach
+
+
+
+
The model consists of three components: (representation) encoder, dynamics function, and the prediction network.
+
+
+
The learning agent has two kinds of interactions - real interactions (ie the actions that are actually executed in the real environment) and hypothetical or imaginary actions (ie the actions that are executed in the learned model or the dynamics function).
+
+
+
At any timestep t, the past observations o1, … ot are encoded into the state st using the encoder.
+
+
+
Now the model takes hypothetical actions for the next K timesteps by unrolling the model for K steps.
+
+
+
For each timestep k = 1, …, K, the dynamics model predicts the immediate reward rk and a new hidden state hk using the previous hidden state hk-1 and action ak.
+
+
+
At the same time, the policy pk and the value function vk are computed using the prediction network.
+
+
+
The initial hidden state h0 is initialized using the state st
+
+
+
Any MDP Planning algorithm can be used to search for optimal policy and value function given the state transitions and the rewards induced by the dynamics function.
+
+
+
Specifically, the MCTS (Monte Carlo Tree Search) algorithm is used and the action at+1 (ie the action that is executed in the actual environment) is selected from the policy outputted by MCTS.
+
+
+
+
Collecting Data for the Replay Buffer
+
+
+
+
At each timestep t, the MCTS algorithm is executed to choose the next action (which will be executed in the real environment).
+
+
+
The resulting next observation ot+1 and reward rt+1 are stored and the trajectory is written to the replay buffer (at the end of the episode).
+
+
+
+
Objective
+
+
+
+
For every hypothetical step k, match the predicted policy, value, and reward to the actual target values.
+
+
+
The target policy is generated by the MCTS algorithm.
+
+
+
The target value function and reward are generated by actually playing the game (or the MDP).
+
+
+
+
Relation to AlphaZero
+
+
+
+
MuZero leverages the search-based policy iteration from AlphaZero.
+
+
+
It extends AlphaZero to setups with a single agent (where self-play is not possible) and setups with a non-zero reward at the intermediate time steps.
+
+
+
The encoder and the predictions functions are similar to ones used by AlphZero.
+
+
+
+
Results
+
+
+
+
K is set to 5.
+
+
+
Environments: 57 games in Atari along with Chess, Go and Shogi
+
+
+
MuZero achieves the same level of performance as AlphaZero for Chess and Shogi. In Go, MuZero slightly outperforms AlphaZero despite doing fewer computations per node in the search tree.
+
+
+
In Atari, MuZero achieves a new state-of-the-art compared to both model-based and model-free approaches.
+
+
+
The paper considers a variant called MuZero Reanalyze that reanalyzes old trajectories by re-running the MCTS algorithm with the updated network parameter. The motivation is to have a better sample complexity.
+
+
+
MuZero performs well even when using a single simulation of MCTS (during inference).
+
+
+
During training, using more simulations of MCTS helps to achieve better performance through even just 6 simulations per move is sufficient to learn a good model for Ms. Pacman.
+
+
diff --git a/_site/site/2019/12/12/Everything-Happens-for-a-Reason-Discovering-the-Purpose-of-Actions-in-Procedural-Text.html b/_site/site/2019/12/12/Everything-Happens-for-a-Reason-Discovering-the-Purpose-of-Actions-in-Procedural-Text.html
new file mode 100644
index 00000000..c8c3c50a
--- /dev/null
+++ b/_site/site/2019/12/12/Everything-Happens-for-a-Reason-Discovering-the-Purpose-of-Actions-in-Procedural-Text.html
@@ -0,0 +1,204 @@
+
Introduction
+
+
+
+
Procedural text comprehension tasks focus on modeling the effect of actions and predicting what happens next.
+
+
+
But they do not consider why some actions need to happen before other actions.
+
+
+
The paper proposes a new model called XPAD (eXPlainable Action Dependency) that considers the purpose of actions while predicting their effect.
+
+
+
The model favors effects that:
+
+
+
+
explain more of actions in the text.
+
+
+
are more plausible given the context.
+
+
+
+
+
An existing procedural text benchmark dataset (Propara) is expanded by adding the task of explaining actions by predicting their dependencies.
Procedural (chronologically ordered text) sequence of T sentences.
+
+
+
List of N participant entities, whose state changes at some step.
+
+
+
+
+
Output
+
+
+
+
State change matrix $\pi(T \times N)$ with four possible states - move, create destroy, none.
+
+
+
This matrix tracks how property changes after each step.
+
+
+
+
+
Dependency Explanation Graph
+
+
+
+
Identify what steps are necessary to execute a given step (say si) and represent this dependency in the form of a dependency explanation graph G = <S, E>.
+
+
+
In this graph, each node is a step and the direction of edge describes the order of dependency.
+
+
+
+
+
+
Dependency Graph Dataset
+
+
+
+
Propara dataset is expanded to extract the dependency graph using both heuristic and automated methods.
+
+
+
The automated method is based on the coherence assumption that if step sj changes state of entity ek then sj is a precondition for the first subsequent step that changes the state of ek.
+
+
+
+
XPAD Model
+
+
+
+
The model is based on the ProStruct system and uses an encoder-decoder based architecture.
+
+
+
Encoder
+
+
+
+
Input: Sentence st and entity ej.
+
+
+
Sentence is encoded using the GloVe vectors and a BiLSTM model and the entity is encoded as an indicator variable.
+
+
+
The combined representation is denoted as ctj.
+
+
+
This representation is passed through an MLP to generate k logits that encode the probability of each entity j undergoing a state change at step t.
+
+
+
+
+
Decoder
+
+
+
+
Beam search is performed to decode the encoder representation into the state change matrix and dependency graph using a score function that ensures global consistency.
+
+
+
Score function has two components:
+
+
+
+
State change score - depends on the likelihood that the selected state changes at step t given the text and state change history from steps s1 to st-1.
+
+
+
Dependency graph score
+
+
+
+
This is based on the connectivity and likelihood of the resulting dependency explanation graph.
+
+
+
This score is used to bias the graph search towards:
+
+
+
+
predictions that have an identifiable purpose ie checking if a particular state change prediction leads to a connection in the dependency explanation graph.
+
+
+
graphs that are more likely according to the background knowledge to distinguish likely dependency links from the unlikely ones.
+
+
+
+
+
+
+
+
+
+
+
During training, XPAD has access to the correct path (in the search space) and learns to minimize the joint loss corresponding to predicting the state change and the dependency explanation graph.
+
+
+
During testing, XPAD performs beam search to predict the most likely state change and dependency explanation graph.
ALBERT architecture is similar to that of BERT with three major differences.
+
+
+
Factorized Embedding Parameterization
+
+
+
+
In BERT and followup works, the embedding size was tied to the size of the context vector.
+
+
+
Since context vector is expected to encoder the entire context, it needs to have a large dimensionality.
+
+
+
One consequence of this choice is that even the embedding layer (which encodes the representation for each token) has a large size. This increases the overall memory footprint of the model.
+
+
+
The paper proposed to factorize the embedding parameters into two smaller matrics.
+
+
+
The embedding layer learns a low dimensional representation of the tokens and this representation is projected into a high dimensional space.
+
+
+
+
+
Cross-layer parameter sharing
+
+
+
ALBERT shares all the parameters across the layers.
+
+
+
+
Inter-sentence coherence loss
+
+
+
+
BERT uses two losses - Masked Language Modeling loss (MLM) and Next Sentence Prediction (NSP).
+
+
+
In the NSP task, the model is provided a pair of sentences and it has to predict if the two sentences appear consecutively in the same document or not. Negative samples are created by sampling sentences from different documents.
+
+
+
The paper argues that NSP is not effective as a loss function as it merges topic prediction and coherence prediction into one task (as the two sentences come from different documents). The topic prediction is an easier task as compared to coherence prediction.
+
+
+
Hence the paper proposes to use the Sentence Order Prediction task where the model has to predict which of the two sentences comes first in a document. The negative samples are created by simply swapping the order in the positive samples. Hence both the sentences come from the same document and topic prediction alone can not be used to solve the task.
+
+
+
+
+
+
Setup
+
+
+
+
Different variants (in terms of size) of ALBERT and BERT models are compared (eg ALBERT, ALBERT-x, BERT-x, etc).
+
+
+
In general, ALBERT models have many-times fewer parameters as compared to the BERT models.
+
+
+
Datasets - BookCorpus, English Wikipedia.
+
+
+
+
Observations
+
+
+
+
ALBERT-xxlarge significantly outperforms the BERT-large model even though it has around 70% parameters as the BERT-large model.
+
+
+
BERT-xlarge performs worse than BERT-base hinting that it is difficult to train such large models.
+
+
+
ALBERT models also have better data throughput as compared to BERT models.
+
+
+
For the ALBERT models, an embedding size of 128 performs the best.
+
+
+
As the hidden dimension is increased, the model obtains better performance, but with diminishing returns.
+
+
+
Very wide ALBERT models (say with a context size of 1024) do not benefit much from depth.
+
+
+
Using additional training data boosts the performance for most of the downstream tasks.
+
+
+
The paper empirically shows that using dropout could hurt the performance of the ALBERT models. This observation may not hold for BERT as it does not share parameters across layers and hence may need regularization via dropout.
+
+
+
ALBERT also improves the state of the art performance on GLUE, SQuAD and RACE benchmarks, for both single-model and ensemble setup.
+
+
+
diff --git a/_site/site/2019/12/26/Towards-a-Unified-Theory-of-State-Abstraction-for-MDPs.html b/_site/site/2019/12/26/Towards-a-Unified-Theory-of-State-Abstraction-for-MDPs.html
new file mode 100644
index 00000000..7ea43cfd
--- /dev/null
+++ b/_site/site/2019/12/26/Towards-a-Unified-Theory-of-State-Abstraction-for-MDPs.html
@@ -0,0 +1,124 @@
+
Introduction
+
+
+
+
The paper studies five different techniques for stat abstraction in MDPs (Markov Decision Processes) and evaluates their usefulness for planning and learning.
+
+
+
The general idea behind abstraction is to map the actual (or observed) state to an abstract state that should be more amenable for learning.
+
+
+
It can be thought of as a mapping from one representation to another representation while preserving some useful properties.
Consider a MDP \(M = <S, A, P, R, \gamma>\) where \(S\) is the finite set of states, \(A\) is finite set of actions, \(P\) is the transition function, \(R\) is the bounded reward function and \(\gamma\) is the discount factor.
+
+
+
The abstract version of the MDP is \(\widetilde{M} = <\widetilde{S}, A, \widetilde{P}, \widetilde{R}, \gamma>\) where \(\widetilde{S}\) is the finite set if abstract states, \(\widetilde{P}\) is the transition function in the abstract state space and \(\widetilde{R}\) is the bounded reward function in the abstract reward space.
+
+
+
Abstraction function \(\phi\) is a function that maps a given state \(s\) to its abstract counterpart \(\widetilde{s}\).
+
+
+
The inverse image \(\phi^{-1}(\widetilde{s})\) is the set of ground states that map to the \(\widetilde{s}\) under the abstraction function \(\phi\).
+
+
+
A wieghing functioon \(w(s)\) is used to measure how much does a state \(s\) contribute to the abstract state \(\phi(s)\).
+
+
+
+
Topology of Abstraction Space
+
+
+
+
Given two abstraction functions \(\phi_{1}\) and \(\phi_{2}\), \(\phi_{1}\) is said to be finer than \(\phi_{2}\) iff for any states \(s_{1}, s_{2}\) if \(\phi_{1}(s_{1}) = \phi_{1}(s_{2})\) then \(\phi_{2}(s_{1}) = \phi_{2}(s_{2})\).
+
+
+
This finer relation is reflex, antisymmetric, transitive and partially ordered.
+
+
+
+
Five Types of Abstraction
+
+
+
+
While many abstractions are possible, not all abstractions are equally important.
+
+
+
Model-irrelevance abstraction \(\phi_{model}\):
+
+
+
+
If two states $s_{1}$ and $s_{2}$ have the same abstracted state, then their one-step model is preserved.
+
+
+
Consider any action \(a\) and any abstract state \(\widetilde{s}\), if \(\phi_{model}(s_{1} = \phi_{model}(s_{2})\) then \(R(s_1, a) = R(s_2, a)\) and \(\sum_{s' \in \phi_{model}^{-1}\widetilde(s)}P_{s_1, s'}^{a} = \sum_{s' \in \phi_{model}^{-1}\widetilde(s)}P_{s_2, s'}^{a}\).
+
+
+
+
+
\(Q^{\pi}\)-irrelevance abstraction:
+
+
+
+
It preserves the state-action value finction for all the states.
+
+
+
\(\phi_{Q^{\pi}}(s_1) = \phi_{Q^{\pi}}(s_2)\) implies \(Q^{\pi}(s_1, a) = Q^{\pi}(s_1, a)\).
+
+
+
+
+
\(Q^{*}\)-irrelevance abstraction:
+
+
+
It preserves the optimal state-action value function.
+
+
+
+
\(a^{*}\)-irrelevance abstraction:
+
+
+
It preserves the optimal action and its value function.
+
+
+
+
\(\phi_{\pi^{*}}\)-irrelevance abstraction:
+
+
+
It preserves the optimal action.
+
+
+
+
In terms of fineness, \(\phi_0 \geq \phi_{model} \geq \phi_{Q^{\pi}} \geq \phi_{Q^*} \geq \phi_{a^*} \geq \phi_{\pi^*}\). Here \(\phi_0\) is the identity mapping ie \(\phi_0(s) = s\)
+
+
+
If a property applies to any abstraction, it also applies to all the finer abstractions.
+
+
+
+
Key Theorems
+
+
+
+
As we go from finer to coarser abstractions, the information loss increases (ie fewer components can be recovered) while the state-space reduces (ie the efficiency of solving the problem increases). This leads to a tradeoff when selecting abstractions.
+
+
+
For example, with abstractions \(\phi_{model}, \phi_{Q^{\pi}}, \phi_{Q^*}, \phi_{a^*}\), the optimal abstract policy \(\widetilde(\pi)^*\) is optimal in the ground MDP.
+
+
+
Similarly, if each state-action pair is visited infinitely often and the step-size decays properly, Q-learning with \(\phi_{model}, \phi_{Q^{\pi}}, \phi_{Q^*}\) converges to the optimal state-action value functions in the MDP. More conditions are needed for convergence in the case of the remaining two abstractions.
+
+
+
For \(\phi_{model}, \phi_{Q^{\pi}}, \phi_{Q^*}, \phi_{a^*}\), the model built with the experience converges to the true abstract model with infinite experience if the weighing function \(w(s)\) is fixed.
+
+
+
diff --git a/_site/site/2020/01/02/Superposition-of-many-models-into-one.html b/_site/site/2020/01/02/Superposition-of-many-models-into-one.html
new file mode 100644
index 00000000..4169e198
--- /dev/null
+++ b/_site/site/2020/01/02/Superposition-of-many-models-into-one.html
@@ -0,0 +1,185 @@
+
Introduction
+
+
+
+
The paper proposes a technique (called Parameter Superposition or PSP) for training and storing multiple models within a single set (or instance) of parameters.
+
+
+
The different models exist in “superposition” and can be retrieved dynamically given task-specific context information.
Consider a task with input \(x \in R^N\) and parameter \(W$ \in R^{M \times N}\) where the output (target or features) are given as \(y=Wx\).
+
+
+
Now consider \(K\) such tasks with parameters \(W_1, W_2, \cdots W_K\).
+
+
+
If each \(W_k\) requires only a small subspace in \(R^N\), then a linear transformation \(C_k^{-1}\) can be used such that each \(W_kC_k^{-1}\) occupies a mutually orthogonal subspace in \(R^N\).
+
+
+
The set of parameters \(W_1, \cdots W_K\) can be represented by a single \(W^{M \times N}\) by adding \(W_kC_k^{-1}\).
+
+
+
The parameter corresponding to the \(k^{th}\) task can be retrived (with some noise) using the context \(C_k\) as \(W^{~}_k = WC_k\)
+
+
+
Even though the retrieval is noisy, the effect of noise is limited for the context vectors used in the paper.
Instead of learning \(K\) separate models, only \(K\) context vectors (along with 1 superimposed model) needs to be learned.
+
+
+
The key assumption is that \(N\) (in \(x \in R^N)\) is large enough such that each \(W_k\) requires only a small subspace of \(R^N\).
+
+
+
Since images and speech signals tend to occupy a low dimensional manifold, this requirement can be satisfied by over-parameterizing x.
+
+
+
+
Choice of Context C
+
+
+
+
Rotational Superposition (pspRotation)
+
+
+
+
Sample rotations uniformly from the orthogonal group \(O(M)\).
+
+
+
Downside is that if \(M \sim N\), it requires storing as many parameters as learning \(K\) individual models (since \(C\) is of the size of ##M \times M$$).
+
+
+
+
+
Complex Superposition (pspComplex)
+
+
+
+
The design of rotational superposition can be improved by choosing \(C_k\) to be a diagonal matrix ie \(C_k = diag(c_k)\) where \(c_k\) is a vector of size \(M\).
+
+
+
Choosing \(c_k\) to be a vector of complex numbers (of the form \(c_{k}^{j} = e^{i\phi_{j}(k)}\) where \(\phi_{j}(k)\) or the phase is sampled uniformly from \([-\pi, \pi]\)) leads to \(C_k\) being a digonal orthogonal matrix.
+
+
+
+
+
Powers of a single context
+
+
+
The memory footprint can be further reduced by choosing the context vectors to be integral powers of the first context vector.
+
+
+
+
Binary Superposition (pspBinary)
+
+
+
This is a special case of complex superposition where the context vectors are binary.
+
+
+
+
+
Neural Network Superposition
+
+
+
+
The parameter superposition principle can be applied to all the linear layers of a network.
+
+
+
For the convolutional layers, it makes more sense to apply superposition to the convolutional kernel and not to the input image (as the dimensionality of convolutional parameters is smaller than that of inputs).
+
+
+
+
Experiments
+
+
+
+
For all the experiments, the baseline is a standard supervised learning setup, unless mentioned otherwise.
+
+
+
The metric is the performance on the previous tasks when the model has been trained on the newer tasks.
+
+
+
Input Interference
+
+
+
+
The input distribution changes over time.
+
+
+
Permuted MNIST dataset is used where each permutation of the pixels corresponds to a new task.
+
+
+
A new task is sampled every 1000 mini-batches.
+
+
+
As the network size increases, the performance of Parameter Superposition (psp) outperforms the baseline significantly.
+
+
+
pspRotation > pspComplex > pspBinary in terms of both performance and the number of additional parameters required for each new task.
+
+
+
Given that pspBinary is the easiest to implement while being comparable to more sophisticated baselines like Elastic Weight Consolidation (EWC) and Synaptic Intelligence, the paper presents most of the results with the pspBinary model.
+
+
+
+
+
Continous Domain Shift
+
+
+
+
Rotating-MNIST and Rotating-FashionMNIST tasks are proposed to simulate continuous domain shift.
+
+
+
In these tasks, the input images are rotated in-plane by a small angle such that the rotation is complete after 1000 steps.
+
+
+
A new context is assigned after 100 steps as per step changes in the angle would be very small.
+
+
+
The 10 context vectors used in the first 1000 steps are reused for the subsequent steps.
+
+
+
+
+
Randomly changing the context vector
+
+
+
+
The paper considers an ablation where the context vector is randomly changed at every step (of the 1000 step cycle). This required the superposition model to store 1000 models.
+
+
+
This approach is better than the supervised learning baseline but not as good as the proposed psp* models.
+
+
+
+
+
Output Interference
+
+
+
+
This is the setup where the model transitions from one classification task to another.
+
+
+
Incremental CIFAR dataset is used with Resnet18 as the base model.
+
+
+
Baseline is a standard supervised learning model where a new classification head is used for each task (since the classes have a different meaning in each dataset). The model component before the classification layer is shared across the tasks.
+
+
+
Even though the labels are different across the datasets, the pspBinary model, trained with a single output layer, outperforms the multi-headed baseline.
+
+
+
+
diff --git a/_site/site/2020/01/09/Accurate-Large-Minibatch-SGD-Training-ImageNet-in-1-Hour.html b/_site/site/2020/01/09/Accurate-Large-Minibatch-SGD-Training-ImageNet-in-1-Hour.html
new file mode 100644
index 00000000..81179b39
--- /dev/null
+++ b/_site/site/2020/01/09/Accurate-Large-Minibatch-SGD-Training-ImageNet-in-1-Hour.html
@@ -0,0 +1,107 @@
+
Introduction
+
+
+
+
Training models with large minibatches (using distributed synchronous SGD) can lead to optimization issues.
+
+
+
The paper presents techniques for training models with large batch size while matching the accuracy of small minibatch setups.
+
+
+
The paper focuses on the ImageNet dataset, but many of the proposed ideas are applicable broadly.
When the minibatch size increases by a factor of k, the learning rate should also be increased by a factor of k (while keeping all other hyperparameters like weight decay fixed).
+
+
+
Note that this is an empirical rule and is not expected to hold under all conditions.
+
+
+
One such condition is when the model is changing rapidly during the first few epochs. In this case, a warmup phase is introduced to stabilize the model.
+
+
+
The paper verifies that the scaling rule is applicable to batch sizes as large as 8K.
+
+
+
+
Warmup
+
+
+
The learning rate should be gradually ramped up from a small value to a large value to allow convergence.
+
+
+
Batch Normalization
+
+
+
+
Batch normalization uses batch statistics to normalize the data. Hence, the loss corresponding to each data point (in the batch) is not independent. Thus, changing the batch size could change the underlying function being optimized.
+
+
+
In the distributed SGD setup, the per-GPU (or per-worker) batch size should be kept constant, and only one worker should compute the batch norm statistics.
+
+
+
+
Pitfalls when using distributed SGD
+
+
+
+
When using weight decay, scaling the cross-entropy loss is not the same as scaling the learning rate.
+
+
+
When using momentum, changing the learning rate could require “momentum correction.”
+
+
+
Ensure that the per-worker loss is normalized by the size of the total minibatch and not just by the size of minibatch that each worker sees.
+
+
+
For each epoch, uses a single random shuffling of the training data (before dividing between the workers).
+
+
+
+
Communication
+
+
+
+
The paper describes various techniques to speed up the training pipeline by reducing the communication overhead between nodes. (Each node can have one or more GPUs).
+
+
+
First, a node sums the gradient from all the GPUs it has.
+
+
+
The gradients are shared and summed across all the nodes.
+
+
+
Each node broadcasts the resulting gradient to all the GPUs it has.
+
+
+
Gradient Aggregation is performed in parallel with the backpropagation operator. While aggregating the gradient for one layer, the system starts computing the gradient of the next layer.
+
+
+
+
Results
+
+
+
+
Using these approaches, a Resnet50 model can be trained on the ImageNet dataset in an hour (using 256 workers).
+
+
+
When an appropriate warmup strategy is used, the training and the validation curves (for the large batch size setup) matches the corresponding curves for the small batch size setup.
+
+
+
The best performing warmup strategy is the one where training starts at a learning rate of 0.1 and linearly increases to 3.2 over five epochs.
+
+
+
The paper shows that the results are not specific to the Resnet50 model (experiments with Resnet101 model) or the use case (experiments with object detection and instance segmentation using Mask R-CNN).
+
+
+
Along with providing the empirical validation of the proposed ideas, the paper describes all the hyperparameters. It also includes the training and validation curves with the different configurations which enable others to replicate and build on this work.
+
+
diff --git a/_site/site/2020/01/16/Rapid-Learning-or-Feature-Reuse-Towards-Understanding-the-Effectiveness-of-MAML.html b/_site/site/2020/01/16/Rapid-Learning-or-Feature-Reuse-Towards-Understanding-the-Effectiveness-of-MAML.html
new file mode 100644
index 00000000..1cbb6ec7
--- /dev/null
+++ b/_site/site/2020/01/16/Rapid-Learning-or-Feature-Reuse-Towards-Understanding-the-Effectiveness-of-MAML.html
@@ -0,0 +1,141 @@
+
Introduction
+
+
+
+
The paper investigated two possible reasons behind the usefulness of MAML algorithm:
+
+
+
+
Rapid Learning - Does MAML learn features that are amenable for rapid learning?
+
+
+
Feature Reuse - Does the MAML initialization provide high-quality features that are useful for the unseen tasks.
+
+
+
+
+
This leads to a follow-up question: how much task-specific inner loop adaptation is needed.
In a standard few-shot learning setup, the different datasets have different classes. Hence, the top-most layer (or the head) of the learning model should be different for different tasks.
+
+
+
The subsequent discussion only applies to the body of the network (ie, network minus the head).
+
+
+
Freezing Layer Representations
+
+
+
+
In this setup, a subset (or all) of parameters are frozen (after MAML training) and are not adapted during the representation.
+
+
+
Even when the entire network is frozen, the performance drops only marginally.
+
+
+
This indicates that the representation learned by the meta-initialization is good enough to be useful on the test tasks (without requiring any adaptation step).
+
+
+
Note that the head of the network is still adapted during testing.
+
+
+
+
+
Representational Similarity
+
+
+
+
In this setup, the paper reports the change in the latent representation (learned by the network) during the inner loop update with a fully trained model.
+
+
+
Canonical Correlation Analysis (CCA) and Central Kernel Alignment (CKA) metrics are used to measure the similarity between the representations.
+
+
+
The main finding is that the representations in the body of the network are very similar before and after the inner loop updates while the representations in the head of the network are very different.
+
+
+
+
+
The above two observations indicate that feature reuse is the primary driving factor for the success of MAML.
+
+
+
When does feature reuse happen
+
+
+
+
The paper considers the model at different stages of training and compares the similarity in the representation (before and after the inner loop update).
+
+
+
Even early in training, the CCA similarity between the representations (before and after the inner loop update) is quite high. Similarly, freezing the layers (for the test time update), early in training, does not degrade the test time performance much. This hints that the feature reuse happens early in the learning process.
+
+
+
+
+
+
The ANIL (Almost No Inner Loop) Algorithm
+
+
+
+
The empirical evidence suggests that the success of MAML lies in the feature reuse.
+
+
+
The authors build on this observation and propose a simplification of the MAML algorithm: ANIL or Almost No Inner Loop Algorithm
+
+
+
In this algorithm, the inner loop updates are applied only to the head of the network.
+
+
+
Despite being much more straightforward, the performance of ANIL is close to the performance of MAML for both few-shot image classification and RL tasks.
+
+
+
Removing most of the inner loop parameters speed up the computation by a factor of 1.7 (during training) and 4.1 (during inference).
+
+
+
+
Removing the Inner Loop Update
+
+
+
+
Given that it is possible to remove most of the parameters from the inner loop update (without affecting the performance), the next step is to check if the inner loop update can be removed entirely.
+
+
+
This leads to the NIL (No Inner Loop) algorithm, which does not involve any inner loop adaptation steps.
+
+
+
+
Algorithm
+
+
+
+
A few-shot learning model is trained - either with MAML or ANIL.
+
+
+
During testing, the head is removed.
+
+
+
For each task, the K training examples are fed to the body to obtain class representations.
+
+
+
For a given test data point, the representation of the data point is compared with the different class representations to obtain the target class.
+
+
+
The NIL algorithm performs similar to the MAML and the ANIL algorithms for the few-shot image classification task.
+
+
+
Note that it is still important to use MAML/ANIL during training, even though the learned head is not used during evaluation.
+
+
+
+
Conclusion
+
+
+
The paper discusses the different classes of meta-learning approaches. It concludes with the observation that feature reuse (and not rapid adaptation) seems to be the common model of operation for both optimization-based meta-learning (e.g., MAML) and model-based meta-learning.
+
diff --git a/_site/site/2020/01/23/Observational-Overfitting-in-Reinforcement-Learning.html b/_site/site/2020/01/23/Observational-Overfitting-in-Reinforcement-Learning.html
new file mode 100644
index 00000000..75c9bc7f
--- /dev/null
+++ b/_site/site/2020/01/23/Observational-Overfitting-in-Reinforcement-Learning.html
@@ -0,0 +1,134 @@
+
Introduction
+
+
+
+
The paper studies observational overfitting: The phenomenon where an agent overfits to different observation spaces even though the underlying MDP remains fixed.
+
+
+
Unlike other works, the “background information” (in the pixel space) is correlated with the progress of the agent (and is not just noise).
Base MDP $M = (S, A, R, T)$ where $S$ is the state space, $A$ is the action space, $R$ is the reward function, and $T$ is the transition dynamics.
+
+
+
$M$ is parameterized using $\theta$. In practice, it means introducing an observation function $\phi_{\theta}$ ie $M_{\theta} = (M, \phi_{\theta})$.
+
+
+
A distribution over $\theta$ defines a distribution over the MDPs.
+
+
+
The learning agent has access to the pixel space observations and not the state space observations.
+
+
+
Generalization gap is defined as $J_{\theta}(\pi) - J_{\theta^{train}}(\pi)$ where $\pi$ is the learning agent, $\theta$ is the distribution over all the observation functions, $\theta^{train}$ is the distribution over the observation functions corresponding to the training environments. $J_{\theta}(\pi)$ is the average reward that the agent obtains over environments sampled from $M_{\theta}$.
+
+
+
$\phi_{\theta}$ considers two featurs - generalizable (invariant across $\theta$) and non-generalizable (depends on $\theta$) ie $\phi_{\theta}(s) = concat(f(s), g_{\theta}(s))$ where $f$ is the invariant function and $g$ is the non-generalizable function.
+
+
+
The problem is set up such that “explicit regularization” can easily solve it. The focus is on understanding the effect of “implicit regularization”.
+
+
+
+
Experiments
+
+
Overparameterized LQR
+
+
+
+
LQR is used as a proxy for deep RL architectures given its advantages like enabling exact gradient descent.
+
+
+
The functions are parameterized as follows:
+
+
+
+
$f(s) = W_c(s)$
+
+
+
$g_{\theta}(s) = W_{\theta}(s)$
+
+
+
+
+
Observation at time $t$ , $o_t$, is given as $[W_c W_{\theta}]^{-1} s_t$.
+
+
+
Action at time $t$ is given as $a_t = K o_{t}$ where $K$ is the policy matrix.
+
+
+
Dimensionality:
+
+
+
state $s$: $d_{state}$ 100
+
$f(s)$: $d_{state}$ 100
+
$g_{\theta}(s)$: $d_{noise}$ 100
+
observation $o$: $d_{state}$ + $d_{noise}$ 1100
+
+
+
+
In case of training on just one environment, multiple solutions exist, and overfitting happens.
+
+
+
Increasing $d_{noise}$ increases the generalization gap.
+
+
+
Overparameterizing the network decreases the generalization gap and also reduces the norm of the policy.
+
+
+
+
Projected Gym Environments
+
+
+
+
The base MDP is the Gym Environment.
+
+
+
$M_{\theta}$ is generated as before.
+
+
+
Increasing both width and depth for basic MLPs improves generalization.
+
+
+
Generalization also depends on the choice of activation function, residual layers, etc.
+
+
+
+
Deconvolutional Projections
+
+
+
+
In the Gym environment, the actual state is projected to a larger vector and reshaped into an 84x84 tensor (image).
+
+
+
The image from $f$ is concatenated with the image from $g$. This setup is referred to as the Gym-Deconv.
+
+
+
The relative order of performance between NatureCNN, IMPALA, and IMPALA-Large (on both CoinRun and Gym-Deconv) is the same as the order of the number of parameters they contain.
+
+
+
In an ablation, the policy is given access to only $g_{\theta}(s)$, which makes it impossible for the model to generalize. In this test of memorization capacity, implicit regularization seems to reduce the memorization effect.
+
+
+
+
Overparameterization in CoinRun
+
+
+
+
The pixel space observation in CoinRun is downsized from 64x64 to 32x32 and flattened into a vector.
+
+
+
In CoinRun, the dynamics change per level, and the noisy “irrelevant” features change location across the 1D input, making this setup more challenging than the previous ones.
+
+
+
Overparameterization improves generalization in this scenario as well.
+
+
diff --git a/_site/site/2020/01/30/Massively-Multilingual-Neural-Machine-Translation-in-the-Wild-Findings-and-Challenges.html b/_site/site/2020/01/30/Massively-Multilingual-Neural-Machine-Translation-in-the-Wild-Findings-and-Challenges.html
new file mode 100644
index 00000000..5527a04c
--- /dev/null
+++ b/_site/site/2020/01/30/Massively-Multilingual-Neural-Machine-Translation-in-the-Wild-Findings-and-Challenges.html
@@ -0,0 +1,179 @@
+
Introduction
+
+
+
+
The paper proposes to build a universal neural machine translation system that can translate between any pair of languages.
+
+
+
As a concrete instance, the paper prototypes a system that handles 103 languages (25 Billion translation pairs).
Hypothesis: The learning signal from one language should benefit the quality of other languages1
+
+
+
This positive transfer is evident for low resource languages but tends to hurt the performance for high resource languages.
+
+
+
In practice, adding new languages reduces the effective per-task capacity of the model.
+
+
+
+
Desiderata for Multilingual Translation Model
+
+
+
+
Maximize the number of languages within one model.
+
+
+
Maximize the positive transfer to low resource languages.
+
+
+
Minimize the negative interference to high resource languages.
+
+
+
Perform well ion the realistic, multi-domain settings.
+
+
+
+
Datasets
+
+
+
+
In-house corpus generated by crawling and extracting parallel sentences from the web.
+
+
+
102 languages, with 25 billion sentence pairs.
+
+
+
Compared with the existing datasets, this dataset is much larger, spans more domains, has a good variation in the amount of data available for different language pairs, and is noisier. These factors bring additional challenges to the universal NMT setup.
+
+
+
+
Baselines
+
+
+
+
Dedicated Bilingual models (variants of Transformers).
+
+
+
Most bilingual experiments used Transformer big and a shared source-target sentence-piece model (SPE).
+
+
+
For medium and low resource languages, the Transformer Base was also considered.
+
+
+
Batch size of 1 M tokes per-batch. Increasing the batch size improves model quality and speeds up convergence.
+
+
+
+
Effect of Transfer and Interference
+
+
+
+
The paper compares the following two setups with the baseline:
+
+
+
+
Combine all the datasets and train over them as if it is a single dataset.
+
+
+
Combine all the datasets but upsample low resource languages so all that all the languages are equally likely to appear in the combined dataset.
+
+
+
+
+
A target “index” is prepended with every input sentence to indicate which language it should be translated into.
+
+
+
Shared encoder and decoder are used across all the language pairs.
+
+
+
The two setups use a batch size of 4M tokens.
+
+
+
+
Results
+
+
+
+
When all the languages are equally sampled, the performance on the low resource languages increases, at the cost of performance on high resource languages.
+
+
+
Training over all the data at once reverse this trend.
+
+
+
+
Countering Interference
+
+
+
+
Temperature based sampling strategy is used to control the ratio of samples from different language pairs.
+
+
+
A balanced sampling strategy improves the performance for the high resource languages (though not as good as the multilingual baselines) while retaining the high transfer performance on the low resource languages.
+
+
+
Another reason behind the lagging performance (as compared to bilingual baselines) is the capacity of the multilingual models.
+
+
+
Some open problems to consider:
+
+
+
+
Task Scheduling - How to decide the order in which different language pairs should be trained.
+
+
+
Optimization for multitask learning - How to design optimizer, loss functions, etc. that can exploit task similarity.
+
+
+
Understanding Transfer:
+
+
+
+
For the low resource languages, translating multiple languages to English leads to improved performance than translating English to multiple languages.
+
+
+
This can be explained as follows: In the first case (many-to-one), the setup is that of a multi-domain model (each source language is a domain). In the second case (one-to-many), the setup is that of multitasking.
+
+
+
NMT models seem to be more amenable to transfer across multiple domains than transfer across tasks (since the decoder distribution does not change much).
+
+
+
In terms of zero-shot performance, the performance for most language pairs increases as the number of languages change from 10 to 102.
+
+
+
+
+
+
+
+
Effect of preprocessing and vocabulary
+
+
+
+
Sentence Piece Model (SPM) is used.
+
+
+
Temperature sampling is used to sample vocabulary from different languages.
+
+
+
Using smaller vocabulary (and hence smaller sub-word tokens) perform better for low resource languages, probably due to improved generalization.
+
+
+
Low and medium resource languages tend to perform better with higher temperatures.
+
+
+
+
Effect of Capacity
+
+
+
Using deeper models improves performance (as compared to the wider models with the same number of parameters) on most language pairs.
+
diff --git a/_site/site/2020/02/06/Your-Classifier-is-Secretly-an-Energy-Based-Model,-and-You-Should-Treat-it-Like-One.html b/_site/site/2020/02/06/Your-Classifier-is-Secretly-an-Energy-Based-Model,-and-You-Should-Treat-it-Like-One.html
new file mode 100644
index 00000000..f9de9301
--- /dev/null
+++ b/_site/site/2020/02/06/Your-Classifier-is-Secretly-an-Energy-Based-Model,-and-You-Should-Treat-it-Like-One.html
@@ -0,0 +1,112 @@
+
Introduction
+
+
+
+
The paper proposed a framework for joint modeling of labels and data by interpreting a discriminative classifier p(y|x) as an energy-based model p(x, y).
+
+
+
Joint modeling provides benefits like improved calibration (i.e., the predictive confidence should align with the miss classification rate), robustness, and out of order distribution.
Consider a standard classifier $f_{\theta}(x)$ which produces a k-dimensional vector of logits.
+
+
+
$p_{\theta}(y | x) = softmax(f_{\theta}(x)[y])$
+
+
+
Uisng concepts from energy based models, we write $p_{\theta}(x, y) = \frac{exp(-E_{\theta}(x, y))}{Z_{\theta}}$ where $E_{\theta}(x, y) = -f_{\theta}(x)[y]$
Note that in the standard discriminative setup, shiting the logits $f_{\theta}(x)$ does not affect the model but it affects $p_{\theta}(x)$.
+
+
+
Computing $p_{\theta}(y | x)$ using $p_{\theta}(x, y)$ and $p_{\theta}(x)$ gives back the same softmax parameterization as before.
+
+
+
This reinterpreted classifier is referred to as a Joint Energy-based Model (JEM).
+
+
+
+
Optimization
+
+
+
+
The log-liklihood of the data can be factoized as $log p_{\theta}(x, y) = log p_{\theta}(x) + log p_{\theta}(y | x)$.
+
+
+
The second factor can be trained using the standard CE loss. In contrast, the first factor can be trained using a sampler based on Stochastic Gradient Langevin Dynamics.
JEM outperforms generative, discriminative, and hybrid models on both generative and discriminative tasks.
+
+
+
+
Calibration
+
+
+
+
A calibrated classifier is the one where the predictive confidence aligns with the misclassification rate.
+
+
+
Dataset: CIFAR100
+
+
+
JEM improves calibration while retaining high accuracy.
+
+
+
+
Out of Distribution (OOD) Detection
+
+
+
+
One way to detect OOD samples is to learn a density model that assigns a higher likelihood to in-distribution examples and lower likelihood to out of distribution examples.
+
+
+
JEM consistently assigns a higher likelihood to in-distribution examples.
+
+
+
The paper also proposes an alternate metric called approximate mass to detect OOD examples.
+
+
+
The intuition is that a point could have likelihood but be impossible to sample because its surroundings have a very low density.
+
+
+
On the other hand, the in-distribution data points would lie in a region of high probability mass.
+
+
+
Hence the norm of the gradient of log density could provide a useful signal to detect OOD examples.
+
+
+
+
Robustness
+
+
+
JEM is more robust to adversarial attacks as compared to discriminative classifiers.
+
diff --git a/_site/site/2020/02/13/Gradient-based-sample-selection-for-online-continual-learning.html b/_site/site/2020/02/13/Gradient-based-sample-selection-for-online-continual-learning.html
new file mode 100644
index 00000000..1b28906a
--- /dev/null
+++ b/_site/site/2020/02/13/Gradient-based-sample-selection-for-online-continual-learning.html
@@ -0,0 +1,122 @@
+
Introduction
+
+
+
+
Use of replay buffer (and rehearsal) is a common technique for mitigating catastrophic forgetting.
+
+
+
The paper builds on this idea but focuses on the sample selection aspect ie, which data points to store in the replay buffer.
+
+
+
It formulates sample selection as a constraint minimization problem and shows that the proposed formulation is equivalent to maximizing the diversity of the samples with respect to parameter gradient.
Online stream of data (i.e., one or few datapoints accessed at a time).
+
+
+
When considering the $t^{th}$ task, the objective is: minimize the loss on the current task without increasing the loss on any of the previous tasks.
+
+
+
The above constraint can be rephrased as $dot(g_t, g_i) \gt 0 \forall i \in [0, t-1]$ where $g_t$ is the gradient for the $t^{th}$ task.
+
+
+
This is equivalent to saying that the current task gradient should not interfere negatively with the previous task gradient.
+
+
+
+
Approach
+
+
+
+
In practice, the gradient constraint is enforced only over the examples in the minibatch (and not the full dataset).
+
+
+
The paper interprets the constraint satisfaction problem as approximating an optimal feasible region (in the gradient space) where current task performance can be improved without hurting the performance on the previous tasks.
+
+
+
The approximate region (of the shape of a polyhedral convex cone) is determined using only the examples from the replay buffer. Hence, the optimal region (defined for the entire dataset) would be contained within the approximate region.
+
+
+
The size of the approximate region can be measured in terms of the solid angle defined by the intersection between the approximate region and a unit sphere.
+
+
+
The paper argues that the approximate region can be made smaller by reducing the angle between each pair of gradients.
+
+
+
The set of points, satisfying the constraint, can be computed using the Integer Quadratic Programming (IQP).
+
+
+
Given that the problem setup is online learning, using IDP for every new data point is not feasible.
+
+
+
An in-exact, greedy alternative is suggested where a score is maintained for each example in the buffer.
+
+
+
When a new datapoint comes in, the score is computed and used to decide if the existing datapoint in the buffer should be replaced.
+
+
+
The score is the maximal cosine similarity of the current example with a random sample in the buffer.
+
+
+
+
Results
+
+
+
+
Benchmarks
+
+
+
+
Disjoint MNIST
+
+
+
Permuted MNIST
+
+
+
Disjoint CIFAR10
+
+
+
+
+
Shared head setup
+
+
+
Baselines for sample selection
+
+
+
+
Randomly select examples to keep in the buffer.
+
+
+
Perform clustering - either in the feature space or in the gradient space.
+
+
+
Use IQP to select the examples. This approach is not used for CIFAR10, as it is computationally costly.
+
+
+
It would be interesting if the paper had considered baselines like selecting samples which had the largest loss.
+
+
+
+
+
The proposed greedy approach outperforms the other methods.
+
+
+
In an ablation experiment, the paper shows that the proposed approach works better than reservoir sampling (when the underlying data distribution is imbalanced).
+
+
+
Another experiment compares the proposed approach with Gradient Episodic Memory and iCaRL. For Permuted and Disjoint MNIST, the different methods perform quite similar though the proposed approach performs better on Disjoint CIFAR10.
+
+
+
diff --git a/_site/site/2020/02/20/ELECTRA-Pre-training-Text-Encoders-as-Discriminators-Rather-Than-Generators.html b/_site/site/2020/02/20/ELECTRA-Pre-training-Text-Encoders-as-Discriminators-Rather-Than-Generators.html
new file mode 100644
index 00000000..4c11a803
--- /dev/null
+++ b/_site/site/2020/02/20/ELECTRA-Pre-training-Text-Encoders-as-Discriminators-Rather-Than-Generators.html
@@ -0,0 +1,150 @@
+
Introduction
+
+
+
+
Masked Language Modeling (MLM) is a common technique for pre-training language-based models. The idea is to “corrupt” some tokens in the input text (around 15%) by replacing them with the [MASK] token and then training the network to reconstruct (or predict) the corrupted tokens.
+
+
+
Since the network learns from only about 15% of the tokens, the computational cost of training using MLM can be quite high.
+
+
+
The paper proposes to use a “replaced token detection” task where some tokens in the input text are replaced by other plausible tokens.
+
+
+
For each token in the modified text, the network has to predict if the token has been replaced or not.
+
+
+
The alternative token is generated using a small generator network.
+
+
+
Unlike the previous MLM setup, the proposed task is defined for all the input tokens, thus utilizing the training data more efficiently.
The proposed approach is called ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
+
+
+
Two neural networks - Generator (G) and Discriminator (D) are trained.
+
+
+
Each network has a Transformer-based text encoder that maps a sequence of words into a sequence of vectors.
+
+
+
Given an input sequence x (of length N), k indices are chosen for replacing the tokens.
+
+
+
For each index, the generator produces a distribution over tokens. A token is sampled to replace in the original sequence. The resulting sequence is referred to as the corrupted sequence.
+
+
+
Given the corrupted sequence, the Discriminator predicts which token comes from the data distribution and which comes from the generator.
+
+
+
The generator is trained using the MLM setup, and the Discriminator is trained using the discriminative loss.
+
+
+
After pre-training, only the Discriminator is finetuned on the downstream tasks.
+
+
+
+
Experiments
+
+
+
+
Datasets
+
+
+
+
GLUE Benchmark
+
+
+
Stanford QA dataset
+
+
+
+
+
Architecture Choices
+
+
+
+
Sharing word embeddings between generator and Discriminator helps.
+
+
+
Tying all the encoder weights leads to marginal improvement but forces the generator and the Discriminator to be of the same size. Hence only embeddings are shared.
+
+
+
Generator model is kept smaller than the discriminator model as a strong generator can make the training difficult for the Discriminator.
+
+
+
A two-stage training procedure was explored where only the generator is trained for n steps. Then the weights of the generator are used to initialize the Discriminator. The Discriminator is then trained for n steps while keeping the generator fixed.
+
+
+
This two-stage setup provides a nice curriculum for the Discriminator but does not outperform the joint training based setup.
+
+
+
An adversarial loss based setup is also explored but it does not work well probably because of the following reasons:
+
+
+
+
Adverserially trained generator is not as good as the MLM generator.
+
+
+
Adverserially trained generator produces a low entropy output distribution.
+
+
+
+
+
+
+
Results
+
+
+
Both small and large ELECTRA models outperform baselines models like BERT, RoBERTa, ELMo and GPT.
+
+
+
+
Ablations
+
+
+
+
ELECTRA-15 is a variant of ELECTRA where the Discriminator is trained on only 15% of the tokens (similar to the MLM setup). This reduces performance significantly.
+
+
+
Replace MLM setup
+
+
+
+
Perform MLM training, but instead of using [MASK], use a toke sampled from the generator.
+
+
+
This improves the performance marginally.
+
+
+
+
+
All-token MLM
+
+
+
+
In the MLM setup, replace the [MASK] token by the sampled tokens and train the MLM model to generate all the words.
+
+
+
In practice, the MLM model can either generate a word or copy the existing word.
+
+
+
This approach closes much of the gap between BERT and ELECTRA.
+
+
+
+
+
+
+
Interestingly, ELECTRA outperforms All-token MLM BERT suggesting the ELECTRA may be benefitting from parameter efficiency since it does not have to learn a distribution over all the words.
+
+
diff --git a/_site/site/2020/02/27/mixup-Beyond-Empirical-Risk-Minimization.html b/_site/site/2020/02/27/mixup-Beyond-Empirical-Risk-Minimization.html
new file mode 100644
index 00000000..cd6e6b69
--- /dev/null
+++ b/_site/site/2020/02/27/mixup-Beyond-Empirical-Risk-Minimization.html
@@ -0,0 +1,71 @@
+
Introduction
+
+
+
+
The paper proposes a simple and dataset-agnostic data augmentation mechanism called mixup.
Consider two training examples, $(x_1, y_1)$ and $(y_1, y_2)$, where $x_1$ and $x_2$ are the datapoints and $y_1$ and $y_2$ are the labels.
+
+
+
New training examples of the form $(\lambda \times x_1 + (1-\lambda) \times x_2, \lambda \times y_1 + (1-\lambda) \times y_2)$ are constructured by considering the linear interpolation of the datapoints and the labels. Here $\lambda \in [0, 1]$.
+
+
+
$\lambda$ is sampled from a Beta distribution $Beta(\alpha, \alpha)$ where $\alpha \in (0, \infty)$.
+
+
+
Setting $\lambda$ to 0 or 1 eliminates the effect of mixup.
+
+
+
Mixup encourages the neural network to favor linear behavior between the training examples.
+
+
+
+
Experiments
+
+
+
+
Supervised Learning
+
+
+
+
ImageNet for ResNet-50, ResNet-101 and ResNext-101.
+
+
+
CIFAR10/CIFAR100 for PreAct ResNet-18, WideResNet-28-10 and DenseNet.
+
+
+
Google command dataset for LeNet and VGG.
+
+
+
+
+
In all these setups, adding mixup improves the performance of the model.
+
+
+
Mixup makes the model more robust to noisy labels. Moreover, mixup + dropout improves over mixup alone. This hints that mixup’s benefits are complementary to those of dropout.
+
+
+
Mixup makes the network more robust to adversarial examples in both white-box and black-box settings (ImageNet + Resnet101).
+
+
+
Mixup also stabilizes the training of GANs by acting as a regularizer for the gradient of the discriminator.
+
+
+
+
Observations
+
+
+
+
Convex combination of three or more examples (with weights sampled from a Dirichlet distribution) does not provide gains over the case of two examples.
+
+
+
In the authors’ implementation, mixup is applied between images of the same batch (after shuffling).
+
+
+
Interpolating only between inputs, with the same labels, did not lead to the same kind of gains as mixup.
+
+
diff --git a/_site/site/2020/03/05/What-Does-Classifying-More-Than-10,000-Image-Categories-Tell-Us.html b/_site/site/2020/03/05/What-Does-Classifying-More-Than-10,000-Image-Categories-Tell-Us.html
new file mode 100644
index 00000000..ea9c212e
--- /dev/null
+++ b/_site/site/2020/03/05/What-Does-Classifying-More-Than-10,000-Image-Categories-Tell-Us.html
@@ -0,0 +1,44 @@
+
+
+
The paper is among the first to study image classification at a large scale (10000 classes and 9 million examples).
+
+
+
This is a relatively old paper (2010). Some of the findings may not be relevant anymore. For instance, specific scaling challenges have been significantly overcome. Moreover, the paper uses approaches like SVM and KNN (popular at that time) and not use CNNs.
+
+
+
Other observations of the paper are still very relevant, and it is an educating paper. For example, since ImagetNet classes are based on WordNet, the paper looks at the effect of semantic relations (tree) of categories on the performance of the training models.
The paper considers three variants of the ImageNet dataset - ImageNet 10K (10184 classes), ImageNet 7K (7404 classes) and ImageNet 1K (1000 classes).
+
+
+
They also consider smaller variants with randomly sampled classes or cases where the examples are sampled from one high-level category like vehicles.
+
+
+
SVM and KNN models are used with features like Bag of Words, GIST descriptors, and spatial pyramid of histograms.
+
+
+
Observations
+
+
+
+
A model that performs well on the smaller dataset (with fewer classes) may not perform well on the larger dataset (with more classes).
+
+
+
There seems to be an approximate correlation between the structure of the semantic hierarchy of the labels (obtained via WordNet) and visual confusion between the categories.
+
+
+
For example, consider two high-level concepts - says artifacts and animals. The model is less likely to confuse between the classes across the high-level concepts but more likely to confuse between the classes in the respective concepts.
+
+
+
For dense categories (categories where the classes are semantically more closely related to each other), the model tends to make more mistakes (even if the number of classes is fewer).
+
+
+
Accounting for the label hierarchy (in the loss function) improves the classification performance.
+
+
+
+
diff --git a/_site/site/2020/03/12/Competitive-Training-of-Mixtures-of-Independent-Deep-Generative-Models.html b/_site/site/2020/03/12/Competitive-Training-of-Mixtures-of-Independent-Deep-Generative-Models.html
new file mode 100644
index 00000000..66d161f2
--- /dev/null
+++ b/_site/site/2020/03/12/Competitive-Training-of-Mixtures-of-Independent-Deep-Generative-Models.html
@@ -0,0 +1,95 @@
+
Introduction
+
+
+
+
The paper proposes a Competitive training mechanism to train a mixture of independent generative models.
+
+
+
The idea is that this mixture of different models would divide the data distribution amongst themselves and specialize to their respective splits.
+
+
+
The training procedure is related to clustering-based methods.
In causal modeling, a common assumption is that the data is generated by a set of independent mechanisms.
+
+
+
It is not known which mechanism generates which datapoint and recovering the underlying mechanisms can be modeled as learning a structural causal generative model.
+
+
+
+
Setup
+
+
+
+
The paper assumes that the support of the different generators do not overlap, i.e., the underlying data distribution is factorized into non-overlapping regions.
+
+
+
This data factorization is learned using a set of discriminators.
+
+
+
If there are $k$ generators, $k$ binary partition functions $c_i, … c_k$ are used.
+
+
+
For a given datapoint $x$, if $c_i(x) = 1$ then $c_j(x) = 0$ for all other $j$ and $x$ is assigned to $i^{th}$ generator.
+
+
+
For a fixed partition function $c_j^t$ ($t$ denotes the partition function at time $t$), minimize the sum of f-divergence between the model and the data distribution (that is assigned to it). The loss formulation is an upper bound on the f-divergence of the mixture model.
+
+
+
In the next step, the data points are re-assigned to the generative models, based on the likelihood of each data point for each model.
+
+
+
The likelihood is estimated by training a discriminator that can distinguish the generated samples from the real samples.
+
+
+
+
Independence as an inductive bias
+
+
+
+
The independence assumption may be too restrictive because the low-level features will be common across the distribution splits.
+
+
+
This “violation” can be avoided by pretraining the model using a uniform random split of the dataset. In that case, the independence assumption will hold approximately after pretraining.
+
+
+
Another approach could be to share some parameters across the models.
+
+
+
A “load balancing” approach is also used where each model always keeps training on the data points assigned to it if not enough data points are assigned to it.
+
+
+
+
Comparison to VAEs and GANs
+
+
+
+
VAEs tend to be “overly inclusive” of the training distribution, i.e., they try to cover the entire support of the distribution.
+
+
+
GANs are prone to mode collapse where the model focuses only on one part of the distribution.
+
+
+
The proposed method provides a middle ground where the different generative models can focus on different parts of the distribution.
+
+
+
+
Experiments
+
+
+
+
The experiments seem to be limited. The paper shows that their proposed setup improves over the VAE and GAN baselines.
+
+
+
For datasets, the paper uses two-dimensional synthetic data, MNIST and CelebA
+
+
diff --git a/_site/site/2020/04/09/CURL-Contrastive-Unsupervised-Representations-for-Reinforcement-Learning.html b/_site/site/2020/04/09/CURL-Contrastive-Unsupervised-Representations-for-Reinforcement-Learning.html
new file mode 100644
index 00000000..49a83345
--- /dev/null
+++ b/_site/site/2020/04/09/CURL-Contrastive-Unsupervised-Representations-for-Reinforcement-Learning.html
@@ -0,0 +1,116 @@
+
Introduction
+
+
+
+
The paper proposes a contrastive learning approach, called CURL, for performing off-policy control from raw pixel observations (by transforming them into high dimensional features).
+
+
+
The idea is motivated by the application of contrastive losses in computer vision. But there are additional challenges:
+
+
+
+
The learning agent has to perform both unsupervised and reinforcement learning.
+
+
+
The “dataset” for unsupervised learning is not fixed and keeps changing with the policy of the agent.
+
+
+
+
+
Unlike prior work, CURL introduces fewer changes in the underlying RL pipeline and provides more significant sample efficiency gains. For example, CURL (trained on pixels) nearly matches the performance of SAC policy (trained on state-based features).
CURL uses instance discrimination. Deep RL algorithms commonly use a stack of temporally consecutive frames as input to the policy. In such cases, instance discrimination is applied to all the images in the stack.
+
+
+
For generating the positive and negative samples, random crop data augmentation is used.
+
+
+
Bilinear inner product is used as the similarity metric as it outperforms the commonly used normalized dot product.
+
+
+
For encoding the anchors and the samples, InfoNCE is used. It learns two encoders $f_q$ and $f_k$ that transform the query (base input) and the key (positive/negative samples) into latent representations. The similarity loss is applied to these latents.
+
+
+
Momentum contrast is used to update the parameters ($\theta_k$) of the $f_k$ network. ie $\theta_k = m \theta_k + (1-m) \theta_q$. $\theta_q$ are the parameters of the $f_q$ network and are updated in the usual way, using both the contrastive loss and the RL loss.
+
+
+
+
Experiment
+
+
+
+
DMControl100K and Atart100K refer to the setups where the agent is trained for 100K steps on DMControl and Atari, respectively.
+
+
+
Metrics:
+
+
+
+
Sample Efficiency - How many steps does the baseline need to match CURL’s performance after 100K steps.
+
+
+
Performance - Ratio of episodic returns by CURL vs. the baseline after 100K steps.
CURL outperforms all pixel-based RL algorithms by a significant margin for all environments on DMControl and most environments on Atari.
+
+
+
On DMControl, it closely matches the performance of the SAC agent trained on state-space observations.
+
+
+
On Atari, it achieves better median human normalizes score (HNS) than the other baselines and close to human efficiency in three environments.
+
+
+
+
+
+
diff --git a/_site/site/2020/04/30/Supervised-Contrastive-Learning.html b/_site/site/2020/04/30/Supervised-Contrastive-Learning.html
new file mode 100644
index 00000000..0c461c9a
--- /dev/null
+++ b/_site/site/2020/04/30/Supervised-Contrastive-Learning.html
@@ -0,0 +1,110 @@
+
Introduction
+
+
+
+
The paper builds on the prior work on self-supervised contrastive learning and extends it for the supervised learning case where many positive examples are available for each anchor.
The representation learning framework has the following components:
+
+
+
Data Augmentation Module
+
+
+
+
This module transforms the input example. The paper considers the following strategies:
+
+
+
Random crop, followed by resizing
+
Auto Augment - A method to search for data augmentation strategies.
+
Rand Augment - Randomly sampling a sequence of data augmentations, with repetition
+
SimAugment - Sequentially apply random color distortion and Gaussian blurring, followed by probabilistic sparse image wrap.
+
+
+
+
+
Encoder Network
+
+
* This module maps the input to a latent representation.
+
+* The same network is used to encode both the anchor and the sample.
+
+* The representation vector is normalized to lie on the unit hypersphere.
+
+
+
Projection Network
+
+
* This module maps the normalized representation to another representation, on which the contrastive loss is computed.
+
+* This network is only used for training the supervised contrastive loss.
+
+
+
Loss function
+
+
* The paper extends the standard contrastive loss formulation to handle multiple positive examples.
+
+* The main effect is that the modified loss accounts for all the same-class pairs (from within the sampled batch as well as the augmented batch).
+
+* The paper shows that the gradient (corresponding to the modified loss) causes the learning to focus more on hard examples. "Hard" cases are the ones where contrasting the anchor benefits the encoder more.
+
+* The proposed loss can also be seen as a generalization of the triplet loss.
+
+
+
Experiments
+
+
+
+
Dataset - ImageNet
+
+
+
Models - ResNet50, ResNet200
+
+
+
The network is “pretrained” using supervised contrastive loss.
+
+
+
After pre-training, the projection network is removed, and a linear classifier is added.
+
+
+
This classifier is trained with the CE loss while the rest of the network is kept fixed.
+
+
+
+
Results
+
+
+
+
Using supervised contrastive loss improves over all the baseline models and data augmentation approaches.
+
+
+
The resulting classifier is more robust to image corruptions, as shown by the mean Corruption Error (mCE) metric on the ImageNet-C dataset.
+
+
+
The model is more stable to the choice oh hyperparameter values (like optimizers, data augmentation, and learning rates).
+
+
+
+
Training Details
+
+
+
+
Supervised Contrastive loss is trained for 700 epochs during pre-training.
+
+
+
Each step is about 50% more expensive than performing CE.
+
+
+
The dense classifier layer can be trained in as few as ten epochs.
+
+
+
The temperature value is set to 0.07. Using a lower temperature is better than using a higher temperature.
+
+
+
diff --git a/_site/site/2020/06/18/On-the-Difficulty-of-Warm-Starting-Neural-Network-Training.html b/_site/site/2020/06/18/On-the-Difficulty-of-Warm-Starting-Neural-Network-Training.html
new file mode 100644
index 00000000..b38c47dc
--- /dev/null
+++ b/_site/site/2020/06/18/On-the-Difficulty-of-Warm-Starting-Neural-Network-Training.html
@@ -0,0 +1,136 @@
+
Introduction
+
+
+
+
The paper considers learning scenarios where the training data is available incrementally (and not at once).
+
+
+
For example, in some applications, new data is available periodically (e.g., latest news articles come out every day).
+
+
+
The paper highlights that, in such scenarios, the conventional wisdom of “warm start” does not apply.
+
+
+
When new data is available, it is better to train a new model from scratch than to update the model trained on previously available data.
+
+
+
While the two setups lead to similar training performance, the randomly initialized model has a much better generalization performance.
Create two random, equally-sized partitions of the training data.
+
+
+
Train the model till convergence on the first half of the data. Then train the model on the entire dataset.
+
+
+
Models: ResNet18, MLPs, Logisitic Regression (LR)
+
+
+
Dataset: CIFAR10, CIFAR100, SVHN
+
+
+
Optimizers: Adam, SGD
+
+
+
Warm starting hurts generalization in all the cases.
+
+
+
The effect is more pronounced in the case of ResNets and MLPs (compared to LR) and harder CIFAR 10 dataset (as compared to SVHN dataset).
+
+
+
+
Online Learning
+
+
Passive Online Learning
+
+
+
+
The model is given access to k new learning examples at each iteration.
+
+
+
A warm started model reuses the previously initialized model and trains (till convergence) on the new batch of k items.
+
+
+
A “randomly initialized” model is trained on all the examples (seen so far) from scratch.
+
+
+
Dataset: CIFAR10
+
+
+
Model: ResNet18
+
+
+
As more training data becomes available, the generalization gap between the two setups increases, and warmup starts hurting generalization.
+
+
+
+
Active Online Learning
+
+
+
+
In this setup, the learner is trained to sample k new examples to add to the training dataset (using margin-based sampling).
+
+
+
Like the previous setup, warmup strategy still hurts generalization.
+
+
+
+
Transfer Learning
+
+
+
+
Train a Resnet18 model on the CIFAR10 dataset and use this model to warm start training on the SVHN dataset.
+
+
+
When a small percentage of the SVHN dataset is used, the setup resembles pretraining / transfer learning and performs better than training from scratch.
+
+
+
As the percentage of the SVHN dataset increases, the warmup approach starts underperforming.
+
+
+
+
Overcoming warm start problem
+
+
+
+
ResNet18 model on CIFAR10 dataset
+
+
+
When performing a hyper-parameter sweep over the learning rate and batch size, it is possible to train warm start models to reach the same generalization performance as training from scratch.
+
+
+
Though, in that case, there are no computational savings as the warm-started models take about the same time (to converge) as the randomly initialized model.
+
+
+
The increased training time indicates that the warm started model probably needs to forget the knowledge from previous training rounds.
+
+
+
Warm start Resnet models, that generalize well, have a low correlation to their initialization stage (measured via Pearson correlation coefficient between the model weights).
+
+
+
Generalization is damaged even when using a model trained on incomplete data for only a few epochs.
+
+
+
For warm start models, the gradient (corresponding to the “new” data) is higher than that for randomly initialized models. This hints that regularisation may help to close the generalization gap. But in practice, regularization helps both the warmup and randomly initialized model.
+
+
+
Warm starting only a few layers also does not close the gap.
+
+
+
Adding some noise to the warm started model (with the motivation of having a partially random initialization) does help somewhat but also increases the training time.
+
+
+
Motivating the problem as an instance of catastrophic forgetting, the authors use the EWC algorithm but report that using EWC hurts model performance.
+
+
+
The paper does not propose a solution to the problem but provides a thorough analysis of the problem setup, which is quite useful for understanding the phenomenon itself.
+
+
diff --git a/_site/site/2020/06/25/Network-Randomization-A-Simple-Technique-for-Generalization-in-Deep-Reinforcement-Learning.html b/_site/site/2020/06/25/Network-Randomization-A-Simple-Technique-for-Generalization-in-Deep-Reinforcement-Learning.html
new file mode 100644
index 00000000..a63fdaa9
--- /dev/null
+++ b/_site/site/2020/06/25/Network-Randomization-A-Simple-Technique-for-Generalization-in-Deep-Reinforcement-Learning.html
@@ -0,0 +1,78 @@
+
Introduction
+
+
+
+
The paper proposed a Technique for improving the generalization ability of RL agents when evaluated on an unseen environment (which is similar to the training environment).
The key idea is to learn features that are invariant across environments by using a randomized CNN (f) that randomly perturbs the inputs.
+
+
+
The policy is trained using the randomized observations obtained using f.
+
+
+
Invariant features are learned using a feature matching (FM) loss that matches the feature representation of the original and randomized observations.
+
+
+
The random network’s parameters are initialized as $\alpha I + (1 - \alpha) N(0, \sqrt\frac{2}{n_{in} + n_{out}})$ where $\alpha \in [0, 1]$, $N$ denotes the Gaussian Distribution and $n_{in}, n_{out}$ denote the number of input and output channels respectively.
+
+
+
Xavier Normal distribution is used for randomization to maintain the variance between the input and the randomized input.
+
+
+
f is randomized per iteration.
+
+
+
During inference, the expected action is computed by approximating over M samples (i.e., randomizing the input M times).
+
+
+
+
Environments
+
+
+
+
2D CoinRun, 3D DeepMind Lab, 3D Robotics Control Task
+
+
+
The evaluation environments consist of different styles of backgrounds, objects, and floors.
Dataset Augmentation methods: Cutout, Gray out, Inversion, Color Jitter
+
+
+
+
Results
+
+
+
+
On CoinRun, the proposed approaches significantly outperforms the other baselines during evaluation. The performance improvement saturates around 10 M samples.
+
+
+
Cycle consistency is used to measure the similarity between two trajectories. The proposed method improves the cycle consistency as compared to the vanilla PPO baseline. It also produces sharper activation maps in the evaluation environments.
+
+
+
For the large-scale experiments, when evaluated on 500 levels of CoinRun, the proposed method improves the success rates from 39.8% to 58.7%.
+
+
+
On DeepMind Lab and Surreal robotics control tasks, the proposed method leads to agents that generalize better on the unseen environments (during evaluation).
+
+
diff --git a/_site/site/2020/07/02/When-to-use-parametric-models-in-reinforcement-learning.html b/_site/site/2020/07/02/When-to-use-parametric-models-in-reinforcement-learning.html
new file mode 100644
index 00000000..60fae34b
--- /dev/null
+++ b/_site/site/2020/07/02/When-to-use-parametric-models-in-reinforcement-learning.html
@@ -0,0 +1,106 @@
+
Introduction
+
+
+
+
The paper compares replay-based approaches with model-based approaches in Reinforcement Learning (RL).
+
+
+
It hypothesizes that if the parametric model is only used for generation transitions for the update rule, then under certain conditions, replay-based approaches will be as good as model-based approaches.
Planning: Any algorithm that uses additional computations (but not additional experience) to improve its performance.
+
+
+
Learning: Any algorithm that uses additional experience to improve its performance.
+
+
+
In some cases, a replay buffer can be seen as a model. For example, querying using state-action pair (from the replay buffer) is similar to querying the (expected) next-state and reward from a model. In general, the model will be more flexible as any arbitrary state-action pair can be used for querying.
+
+
+
+
Computation Properties
+
+
+
+
Parametric models require more computation than sampling from a replay buffer. In contrast, the cost of maintaining a replay buffer scales linearly with their capacity.
+
+
+
Parametric models are useful for planning multiple-steps into the future while it is much harder to do so with a replay buffer (even more so with pixel observations).
+
+
+
An imperfect model maybe be more suitable for selecting actions (instead of updating the policy) because the chosen action, when executed in the environment, will lead to transitions that would improve the model.
+
+
+
When planning with an imperfect model, it is better to plan backward, as the update is applied on an imaginary state (which would not be encountered if the model is poor).
+
+
+
If the model is accurate, forward and backward planning is equivalent. This distinction between forward and backward updates does not apply to replay buffers.
+
+
+
+
Failure to learn
+
+
+
+
When using a replay buffer and (i) uniformly replaying transitions, (ii) from a buffer containing only full episodes, and (iii) using TD updates, then the algorithm is stable.
+
+
+
When using a replay buffer and (i) uniformly replaying transitions, (ii) generating transitions using a model, and (iii) using TD updates, then the algorithm can diverge.
+
+
+
This case can be fixed by:
+
+
+
+
Repeatedly interating over the model and sampling transitions to and from the state model generates (not a satisfactory solution).
+
+
+
Using multiple-step returns (this can increase the variance).
+
+
+
Use algorithms specifically for stable off-policy learning (not a definitive solution).
+
+
+
+
+
+
Model-based algorithms at scale
+
+
+
+
The paper compares against SimPLe (model-based) with Rainbow DQN (replay-based).
+
+
+
The paper shows that when using a similar number of real interactions, Rainbow DQN needs fewer replay samples than model samples in SimPLe, making it more efficient (computation-wise).
+
+
Changes to Rainbow DQN:
+
+
Increase number of steps, for bootstrapping, from 3 to 20.
+
Reduce the number of steps, before sampling starts from the replay buffer, from 20K to 1600.
+
+
+
With these changes, Rainbow DQN outperforms SimPLe in 17 out of 26 games.
+
+
+
Conclusion
+
+
+
+
When using a parametric model in a replay-like setting (sampling observed states from the past), model-based learning can be unstable (in theory). Using a replay buffer is likely a better strategy under the state sampling distribution.
+
+
+
Parametric models are likely more useful when:
+
+
planning backward for credit assignment - even if the model is in-accurate, backward planning will only update fictional states.
+
planning forward for behavior - the resulting plan is only used to collect real experience in the environment (and not directly update the policy).
+
+
+
diff --git a/_site/site/2020/07/09/Decentralized-Reinforcement-Learning-Global-Decision-Making-via-Local-Economic-Transactions.html b/_site/site/2020/07/09/Decentralized-Reinforcement-Learning-Global-Decision-Making-via-Local-Economic-Transactions.html
new file mode 100644
index 00000000..78bb1586
--- /dev/null
+++ b/_site/site/2020/07/09/Decentralized-Reinforcement-Learning-Global-Decision-Making-via-Local-Economic-Transactions.html
@@ -0,0 +1,134 @@
+
Introduction
+
+
+
+
The paper explores the connections between the concepts of a single agent vs. society of agents.
+
+
+
A society of agents can be modeled as a single agent while a single agent can be modeled as a society of components (or sub-agents).
+
+
+
The paper focuses on mechanisms for training a society of self-interested agents to solve a given task – as if the system was a single task.
Societal-decision making framework relates the local optimization problem of a single agent with the global optimization problem of a society of agents.
+
+
+
Cloned Vickrey Society is proposed as a mechanism to guarantee that an agent’s dominant strategy equilibrium coincides with the group’s optimal policy.
+
+
+
A class of decentralized RL algorithms that optimize the MDP object of the society as a whole, as a consequence of individual agents optimizing their objectives.
+
+
+
Empirical evaluation of Cloned Vickrey Society using any implementation called Credit Conserving Vickery.
+
+
+
+
Terminology
+
+
+
+
Environment - a tuple that specifies an input space, an output space, and parameters for determining an objective.
+
+
+
A standard RL setup can be mapped to environment by mapping state space to input space, action space to output space and reward function, transition function, and discount factors to the parameters specifying the objective.
+
+
+
+
Agent - a function that maps input space to output space.
+
+
+
Objective - a functional that maps an agent to a real number.
+
+
+
In auction environments, the input space is a single auction item (say s), and the output space is bidding space B.
+
+
+
There are N agents who compete by bidding for an item s using their bidding policy.
+
+
+
$b$ is a vector of bids produced by the agents.
+
+
+
$v_s$ is a vector of agent’s valuations of item s.
+
+
+
The $i^{th}$ agent’s utility is given as $v_s^i \times X^i(b) - P^i(b)$. Here, $X^i(b)$ is the portion of $s$ allocated to $i^{th}$ agent and $P^i(b)$ is the price that $i^{th}$ agent is willing to pay.
+
+
+
+
Design Choices
+
+
+
+
Each agent is independently maximizing its utility.
+
+
+
In certain conditions (i.e., if the auction is dominant strategy incentive compatible), it is optimal for each agent to bid its valuation.
+
+
+
These conditions are satisfied by the Vickery auction where $P^i(b)$ is set to be the second-highest bid and $X^i(b) = 1$ if the $i^{th}$ agent wins (and 0 otherwise).
+
+
+
A society is a set of agents where each agent is a tuple of bidding policy $\psi$ and a transformation function.
+
+
+
The environment is modeled at two levels - (i) global environment (referred to as the global MDP) and local environment (referred to as local auction).
+
+
+
Each state $s$ in the global MDP is an auction item in a different auction. The winner (of local auction at $s$) transforms $s$ into some other state $s’$.
+
+
+
If these transformations are modeled as actions, then the proposed framework can be interpreted as a decentralized reinforcement learning framework.
+
+
+
Motivated by the design of market economy (where economic transactions determine wealth distribution), the paper proposes that, for an agent, the valuation of winning an auction is the revenue it can receive in the auction at the next timestep by selling the transformed state.
+
+
+
A global MDP that adhere to this design is referred to as the Market MDP.
+
+
+
There is a catch in the design of the market MDP - the winning agent, at time $t-1$, gets the amount that the highest bidder is willing to pay at time $t+1$. But the winner at time $t+1$ only paid the second-highest bid. Hence, the credit is not conserved.
+
+
+
This inconsistency can be fixed by introducing “duplicate” (or cloned) agents, and the society is called the Cloned Vickery Society.
+
+
+
The Cloned Vickrey Auction mechanism is compared against alternate bidding mechanisms like first price auction (where winner pays the bid they proposed), solitary version of Vickrey auction (no cloning), and Environment Reward where only environment reward is used, and there is no price term.
+
+
+
It is empirically shown that Cloned Vickrey Auction learns bids that are most close to their actual valuations. Moreover, solitary version leads bids which are more spread out than the ones learned by cloned version. This highlights the importance of competitive pressure to learn bid values.
+
+
+
Three different implementations of Cloned Vickrey Auction are considered:
+
+
+
+
Bucket Brigade (BB) - winner at timestep $t$ receives the highest bid at time step $t+1$, and the subsequent winner pays the highest bid. This case satisfies Credit Conservation and Bellman Optimality.
+
+
+
Vickrey (V) - winner at timestep $t$ receives the highest bid at time step $t+1$, and the subsequent winner pays the second-highest bid. This case satisfies Truthful Dominant Strategy and Bellman Optimality.
+
+
+
Credit Conserving Vickrey (CCV) - winner at timestep $t$ receives the second-highest bid at time step $t+1$, and the subsequent winner pays the second-highest bid. This case satisfies Truthful Dominant Strategy and Credit Conservation.
+
+
+
+
+
CCV implementation provides bid values closest to the optimal Q-values.
+
+
+
In one experiment, the paper explores the use of the proposed approach for selecting between sub-policies. It shows that CVV is more sample efficient for pretraining sub-policies and adapting them to transfer tasks.
+
+
+
In another experiment, the task is to transform MNIST images by composing two out of 6 affine transformations. The transformed images are fed to a pretrained classifier that predicts a label. The agent gets a reward of 1 if the classifier makes correct prediction and 0 otherwise. CCV implementation obtains a mean reward of 0.933, thus highlighting the effectiveness of the CCV model.
+
+
diff --git a/_site/site/2020/07/16/Averaging-Weights-leads-to-Wider-Optima-and-Better-Generalization.html b/_site/site/2020/07/16/Averaging-Weights-leads-to-Wider-Optima-and-Better-Generalization.html
new file mode 100644
index 00000000..371b9cc9
--- /dev/null
+++ b/_site/site/2020/07/16/Averaging-Weights-leads-to-Wider-Optima-and-Better-Generalization.html
@@ -0,0 +1,91 @@
+
Introduction
+
+
+
+
The paper proposes Stochastic Weight Averaging (SWA) procedure for improving the generalization performance of models trained with SGD (with cyclic or constant learning rate).
+
+
+
Specifically, the model is checkpointed at several points along the training trajectory, and these checkpoints are averaged (in the parameter space) to obtain a single model.
“Stochastic” in the name refers to the idea that with cyclical or constant learning rate, SGD proposals are approximately sampled from a neural network’s loss surface and are hence stochastic.
+
+
+
SWA uses a learning rate schedule that allows exploration in the weight space.
+
+
+
SGD with cyclical and constant learning rates explore points (model instances) at the periphery of high-performing networks.
+
+
+
With different initializations, SGD will find different points (of low training loss) on this boundary, but will not move inside it.
+
+
+
Averaging the points provide a mechanism to move inside this periphery.
+
+
+
The train and the test error surfaces, while being similar, are not perfectly aligned. Hence, averaging several models (along the optimization trajectory) could lead to a more robust model.
+
+
+
+
Algorithm
+
+
+
+
Given a model $w$ and some training budget $B$, train the model in the conventional way for approx 75% of the budget.
+
+
+
Starting from that point, continue training with the remaining budget, with a constant or cyclical learning rate.
+
+
+
For fixed learning rate, checkpoint models at each epoch. For cyclical learning rate, checkpoint the model at the lowest learning rate in the cycle.
+
+
+
Average all the models to get the SWA model.
+
+
+
If the model has Batch Normalization layers, run an additional pass to compute the SWA model’s running mean and standard deviation.
+
+
+
The computational and space complexity of computing the SWA model is relatively low.
+
+
+
The paper highlights the ensembling like the effect of SWA by showing that if the model checkpoints ($w_i$) are generated by training with Fast Geometric Ensembling (FGE), the difference between averaging the weights and averaging the predictions is of the order $O(\Delta)$ where $\Delta = max ||w_i - w_{SA}||$.
+
+
+
Note that SWA does not have the overhead of an extra-forward pass during inference.
Baselines: Conventional SGD, Exponentially decaying average with SGD and FGE.
+
+
+
In all the CIFAR experiments, SWA consistently outperforms SGD in one budget and consistently improves with training.
+
+
+
SWA also achieves performance comparable to FGE, despite FGE being an ensemble method.
+
+
+
On ImageNet, SWA is run on a pre-trained model, and it improves performance in all the cases.
+
+
+
An ablation experiment (on CIFAR-100) shows that it is possible to train a network (with SWA) using a fixed learning rate. In that setup, using SWA improves performance by 16%.
+
+
diff --git a/_site/site/2020/07/23/TASKNORM-Rethinking-Batch-Normalization-for-Meta-Learning.html b/_site/site/2020/07/23/TASKNORM-Rethinking-Batch-Normalization-for-Meta-Learning.html
new file mode 100644
index 00000000..4c229152
--- /dev/null
+++ b/_site/site/2020/07/23/TASKNORM-Rethinking-Batch-Normalization-for-Meta-Learning.html
@@ -0,0 +1,168 @@
+
Introduction
+
+
+
+
Meta-learning techniques are shown to benefit from the use of deep neural networks.
+
+
+
BatchNorm is a commonly used component when training deep networks, especially for vision tasks.
+
+
+
However, BatchNorm and meta-learning make contradictory assumptions, and their combination may not work well in practice.
+
+
+
The paper proposes TaskNorm, a normalization method that is designed explicitly for meta-learning.
Standard meta-learning setup with $k$ tasks, each task with its own context and target set.
+
+
+
Two sets of parameters are considered during meta-learning - (i) global parameters, and (ii) task-specific parameters.
+
+
+
Meta-learning setup can be viewed as an inference task, where the task-specific parameters are inferred using a context set and some additional (trainable) parameters.
+
+
+
Normalization layers are commonly used to accelerate the training of neural networks. The general approach is to use normalization moments (statistics) along with some learned parameters.
+
+
+
BatchNorm is a well-known and widely used normalization approach. It relies on the implicit assumption that the dataset comprises of iid samples from some underlying distribution.
+
+
+
However, in meta-learning, data points are assumed to be iid only within a specific task.
+
+
+
This leaves open the question of what moments to use during meta-train and meta-test time.
+
+
+
+
Variants of BatchNorm
+
+
Conventional BatchNorm (CBN)
+
+
+
+
Compute moments at meta train time and use during meta test time.
+
+
+
This is equivalent to lumping the moments with the global parameters. I.e., the running moments are shared globally, while the data is iid only locally.
+
+
+
Using CBN with MAML leads to poor results.
+
+
+
Moreover, meta-learning setup can some times require the use of a very small batch size. (e.g., 1-shot learning) In those cases, the computed statistics are likely to be inaccurate.
+
+
+
+
Transductive BatchNorm (TBN)
+
+
+
+
Use context/target set statistics at both meta-train and meta-test time.
+
+
+
This is the default BatchNorm mode used in MAML.
+
+
+
+
Instance-based normalization
+
+
+
+
Moments are computed separately for each instance.
+
+
+
This mode corresponds to treating the statistics as local at the observation level.
+
+
+
These methods provide only limited improvement in performance, and can sometimes have a large overhead.
+
+
+
+
Task Normalization (Proposed)
+
+
+
+
The normalization statistics are local at the task level, and statistics for a given data point should only depend on the context set’s data point. It should not depend on the other elements of the target set.
+
+
+
Meta-Batch Normalisation (METABN) is a precursor to TaskNorm where the context set alone is used to compute the normalization statistics for both the context and the target set (during both meta-test and meta-train time).
+
+
+
METABN does not perform well when used with small context sets.
+
+
+
TaskNorm overcomes this limitation by using a set of non-transductive, secondary moments (computed from the input being normalized).
+
+
+
When the context is small, using additional moments will help to improve the moment estimates.
+
+
+
In the general case, a trainable blending factor, $\alpha$, is used to combine the two sets of moments.
+
+
+
While the computational cost of TaskNorm is slightly more than CBN, it converges faster than CBN in practice.
+
+
+
Normalization mechanism in Reptile can be interpreted as a particular case of TaskNorm.
+
+
+
+
Experiments
+
+
+
+
Small scale few-shot classification experiments
+
+
+
+
Omniglot and imin ImageNet dataset
+
+
+
First order MAML, with different kinds of normalization schemes.
+
+
+
Transductive BatchNorm performs the best.
+
+
+
Among non-transductive approaches, TaskNorm using Instance Normalisation augmentation performs the best.
+
+
+
Similar trend holds for the speed of convergence as well.
+
+
+
+
+
Large scale few-shot classification experiments
+
+
+
+
MetaDataset dataset
+
+
+
CNAPs model
+
+
+
The context set’s size varies across tasks in this setup and can be as small as 5.
+
+
+
TaskNorm with Instance Normalisation ranks first in 10 (out of 13) datasets and is also the fastest to train.
+
+
+
While Instance-based methods (Instance Normalisation and Layer Normalisation) are the slowest to converge, they still outperform the running average based methods (conventional BatchNorm).
+
+
+
The results demonstrate that designing meta-learning specific normalization methods can significantly improve performance and that Transductive BatchNorm may not always be the optimal choice.
+
+
+
+
diff --git a/_site/site/2020/07/30/GradNorm-Gradient-Normalization-for-Adaptive-Loss-Balancing-in-Deep-Multitask-Networks.html b/_site/site/2020/07/30/GradNorm-Gradient-Normalization-for-Adaptive-Loss-Balancing-in-Deep-Multitask-Networks.html
new file mode 100644
index 00000000..e6ad85c2
--- /dev/null
+++ b/_site/site/2020/07/30/GradNorm-Gradient-Normalization-for-Adaptive-Loss-Balancing-in-Deep-Multitask-Networks.html
@@ -0,0 +1,99 @@
+
Introduction
+
+
+
+
The paper proposes GradNorm, a gradient normalization algorithm that improves multi-task training by dynamically tuning the magnitude of gradients corresponding to different tasks.
During multi-task training, some tasks can dominate the training, at the expense of others.
+
+
+
It is common to define the multi-task loss as a linearly weighted combination of the individual task losses.
+
+
+
The paper proposes two changes to this setup:
+
+
+
+
Adapt weight-coefficients, assigned to each loss term, at each training step.
+
+
+
Directly modify the gradient magnitudes, corresponding to different tasks, so that all the tasks are learning at similar rates.
+
+
+
+
+
Proposed GradNorm algorithm is similar to BatchNorm, but it performs normalization across tasks, not data batches.
+
+
+
+
Algorithm
+
+
+
+
Gradient norm at timestep $t$, for the $i^{th}$ task, is computed as the product between average gradient norm (across all tasks at timestep $t$) and $r_i(t) ^ {\alpha}$.
+
+
+
$r_i$ is the relative inverse training rate of task $i$. It is defined as the ratio between the loss ratio of task $i$ and the average loss ratio (across all the tasks).
+
+
+
$\alpha$ is a hyperparameter.
+
+
+
This computed per-task gradient norm is treated as the target value for actual gradient norms.
+
+
+
An additional $L_1$ loss is incorporated between the actual and the target gradient norms, summed over all the tasks, and optimizes the weight-coefficients only.
+
+
+
After every step, the weight-coefficients are renormalized to decouple the gradient normalization from the global learning rate.
+
+
+
Note that all the gradient norm computations are performed only for the layers on which GradNorm is applied. Generally, GradNorm is used with only the last shared layer of weights (to save on computational costs).
+
+
+
+
Experiments
+
+
+
+
Two variants of NYUv2 dataset – NYUv2+seg (small dataset) and NYUv2+kpts (big dataset).
+
+
+
Both regression and classification setups were used.
+
+
+
Models:
+
+
+
+
SegNet with a symmetric VGG16 encoder/decoder
+
+
+
FCN with modified ResNet-50 as the encoder and shallow ResNet as the decoder.
+
+
+
+
+
Standard pixel-wise losses for each task.
+
+
+
+
Results
+
+
+
+
GradNorm with $\alpha=1.5$ outperforms the equal-weight baseline and either surpasses or matches the best performance of single networks for each task.
+
+
+
Almost any value of 0 < $\alpha$ < 3 improves the network’s performance over an equal weight baseline.
+
+
diff --git a/_site/site/2020/08/06/Gradient-Surgery-for-Multi-Task-Learning.html b/_site/site/2020/08/06/Gradient-Surgery-for-Multi-Task-Learning.html
new file mode 100644
index 00000000..cb090973
--- /dev/null
+++ b/_site/site/2020/08/06/Gradient-Surgery-for-Multi-Task-Learning.html
@@ -0,0 +1,113 @@
+
+
+
The paper hypothesizes that main optimization challenges in multi-task learning arise because of negative interference between different tasks’ gradients.
+
+
+
It hypothesizes that negative interference happens when:
+
+
+
+
The gradients are conflicting (i.e., have a negative cosine similarity).
+
+
+
The gradients coincide with high positive curvature.
+
+
+
The difference in gradient magnitude is quite large.
+
+
+
+
+
The paper proses to work around this problem by performing “gradient surgery.”
+
+
+
If two gradients are conflicting, modify the gradients by projecting each onto the other’s normal plane.
+
+
+
This modification is equivalent to removing the conflicting component of the gradient.
+
+
+
This approach is referred to as projecting conflicting gradients (PCGrad).
The paper proves the local conditions under which PCGrad improves multi-task gradient descent in the two-task setup.
+
+
+
The conditions are:
+
+
+
+
Angle between the task gradients is not too small.
+
+
+
Difference in the magnitude of the gradients is sufficiently large.
+
+
+
Curvature of the multi-task gradient is large.
+
+
+
Large enough learning rate.
+
+
+
+
+
+
+
Experimental Setup
+
+
+
+
Multi-task supervised learning
+
+
+
+
MutliMNIST, Multi-task CIFAR100, NYUv2.
+
+
+
For Multi-task CIFAR-100, PCGrad is used with the shared parameters of the routing networks.
+
+
+
For NYUv2, PCGrad is combined with MTAN.
+
+
+
In all the cases, using PCGrad improves the performance.
+
+
+
+
+
Multi-task Reinforcement Learning
+
+
+
+
Meta-World Benchmark
+
+
+
PCGrad + SAC outperforms all other baselines.
+
+
+
In the context of SAC, the paper suggests learning temperature $\alpha$ on a per-task basis.
+
+
+
+
+
Goal-conditioned Reinforcement Learning
+
+
+
+
Goal-conditioned robotic pushing task with a Sawyer robot.
+
+
+
PCGrad + SAC outperforms vanilla SAC.
+
+
+
+
+
+
diff --git a/_site/site/2020/08/14/Outrageously-Large-Neural-Networks-The-Sparsely-Gated-Mixture-of-Experts-Layer.html b/_site/site/2020/08/14/Outrageously-Large-Neural-Networks-The-Sparsely-Gated-Mixture-of-Experts-Layer.html
new file mode 100644
index 00000000..447137c2
--- /dev/null
+++ b/_site/site/2020/08/14/Outrageously-Large-Neural-Networks-The-Sparsely-Gated-Mixture-of-Experts-Layer.html
@@ -0,0 +1,143 @@
+
Introduction
+
+
+
+
Conditional computation is a technique to increase a model’s capacity (without a proportional increase in computation) by activating parts of the network on a per example basis.
+
+
+
The paper describes (and address) the computational and algorithmic challenges in conditional computation. It introduces a sparsely-gated Mixture-of-Experts layer (MoE) with 1000s of feed-forward sub-networks.
GPUs are fast at matrix arithmetic but slow at branching.
+
+
+
Large batch sizes amortizes the cost of updates. Conditional computation reduces the effective batch size for different components of the model.
+
+
+
Network bandwidth can be a bottleneck with the network demand overshadowing the computational demand.
+
+
+
Additional losses may be needed to achieve the desired level of sparsity.
+
+
+
Conditional computation is most useful for large datasets.
+
+
+
+
Architecture
+
+
+
+
n Expert Networks - $E_1$, …, $E_n$.
+
+
+
Gating Network $G$ to select a sparse combination of experts.
+
+
+
Output of the MoE module is the weighted sum of predictions of experts (weighted by the output of the gate).
+
+
+
If the gating network’s output is sparse, then some of the experts’ value does not have to be computed.
+
+
+
In theory, one could use a hierarchical mixture of experts where a mixture of experts is trained at each level.
+
+
+
+
Choices for the Gating Network
+
+
+
+
Softmax Gating
+
+
+
Noisy top-k gating - Add tunable Gaussian noise to the output of softmax gating and retain only the top-k values. A second trainable weight matrix controls the amount of noise per component.
+
+
+
+
Addressing Performance Challenge
+
+
+
+
Shrinking Batch Problem
+
+
+
+
If the MoE selects k out of n experts, the effective batch size reduces by a factor of k / n.
+
+
+
This reduction in batch size is accounted for by combining data parallelism (for standard layers and gasting networks) and model parallelism (for experts in MoE). Thus, with d devices, the batch size changes by a factor of (k x d ) / n.
+
+
+
For hierarchical MoE, the primary gating network uses data parallelism while secondary MoEs use model parallelism.
+
+
+
The paper considers LSTM models where the MoE is applied once the previous layer has finished. This increases the batch size (for the current MoE layer) by a factor equal to the number of unrolling timesteps.
+
+
+
Network Bandwith limitations can be overcome by ensuring that the ratio of computation (of each expert) to the input and output size is greater than (or equal to) the ratio of computational to network capacity.
+
+
+
Computational efficiency can be improved by using larger hidden layers (or more hidden layers).
+
+
+
+
+
Balancing Expert Utilization
+
+
+
+
Importance of an expert (relative to a batch of training examples) is defined as the batchwise sum of the expert’s goal values.
+
+
+
An additional loss, called importance loss, is added to encourage the experts to have equal importance.
+
+
+
The importance loss is defined as the square of the coefficient of variation (of a set of importance values) multiplied by a (hand-tuned) scaling factor $w_{importance}$.
+
+
+
In practice, an additional loss called $L_{load}$ might be needed to ensure that the different experts get equal load (along with equal importance).
+
+
+
+
+
+
Experiments
+
+
+
+
Datasets
+
+
+
+
Billon Word Language modeling Benchmark
+
+
+
100 Billion word Google News Corpus
+
+
+
Machine Translation datasets
+
+
+
+
Single Language Pairs - WMT’14 En to Fr (36M sentence pairs) and En to De (5M sentence pairs).
+
+
+
Multilingual Machine Translation - large combine dataset of twelve language pairs.
+
+
+
+
+
+
+
In all the setups, the proposed MoE models achieve significantly better results than the baseline models, at a lower computational cost.
+
+
diff --git a/_site/site/2020/08/24/Alpha-Net-Adaptation-with-Composition-in-Classifier-Space.html b/_site/site/2020/08/24/Alpha-Net-Adaptation-with-Composition-in-Classifier-Space.html
new file mode 100644
index 00000000..b8e6ec7f
--- /dev/null
+++ b/_site/site/2020/08/24/Alpha-Net-Adaptation-with-Composition-in-Classifier-Space.html
@@ -0,0 +1,88 @@
+
Introduction
+
+
+
+
Common transfer learning method focuses on transferring knowledge in the model feature space.
+
+
+
In contrast, the paper argues that the learned knowledge is more concisely captured in the “classifier space” as the classifier is fitted for all the samples for a given class, while the feature representation is specific to each sample.
+
+
+
Building on this intuition, the paper proposes to combine strong classifiers (trained on large datasets) with weak classifiers (trained on smaller datasets) to improve the weak classifiers’ performance.
Given $n$ classifiers, $C_1, …, C_n$, trained with a large amount of data and a weak classifier $a$ trained for a class with few samples.
+
+
+
Find the nearest neighbors of $a$.
+
+
+
Train a new classifier by linearly combining $a$ with its nearest classifiers.
+
+
+
The coefficients (for linearly combining the classifiers) are learned using another classifier called as AlphaNet.
+
+
+
In theory, this approach can be used with any set of classifiers.
+
+
+
+
Setup
+
+
+
+
A long-tailed dataset is one where some classes (referred to as the tail classes) have very few examples—for example, ImageNet-LT and Places-LT.
+
+
+
Split the long-tailed dataset into two splits - “base” classes with $B$ (number of) classes and “few” classes with $F$ (number of) classes.
+
+
+
Total number of classes $N = B + F$.
+
+
+
Start with a pre-trained model, with classifiers $w_j$ and biases $b_j$ for $j \in (1, N)$.
+
+
+
For a given target class $j$, find its top $k$ nearest neighbor classifiers and concatenate their output.
+
+
+
For each “few” class, learn a feedforward network that takes the concatenated representation (of classifiers) as the input and returns a vector of $k \alpha$ values.
+
+
+
These $\alpha$ values are interpreted as the classifier’s strength (or confidence) in its nearest neighbors.
+
+
+
The (normalized) alpha values are used for defining the weight and bias for the classifier for the given “few” class.
+
+
+
The collection of all the “few” classifiers is referred to as the AlphaNet.
+
+
+
The paper outlines a degenerate case, where the confidence in the prediction of all the strong classifiers goes to 0. The paper proposes to counter this case by clamping the $\alpha$ values.
+
+
+
The entire setup is trained end-to-end using cross-entropy loss on AlphaNet.
+
+
+
+
Results
+
+
+
+
Given the proposed approach’s flexibility, it is used to combine the state-of-the-art models on ImageNet-LT, namely retraining classifiers on class-balanced samples and training models with weight normalization. The combined setup outperforms the individual models.
+
+
+
One interesting observation is that it is useful to include the weak classifiers, along with the strong classifiers, as AlphaNet adjusts the position of weak classifiers towards the appropriate strong classifier.
+
+
+
While the idea is described in the context of long-tail data distribution, the idea is useful in the general context of non-stationary data distribution. One instantiation could be lifelong class incremental learning where the model encounters new data classes during training. For some time duration (till sufficient data points are seen), the newly seen classes are the “few” classes. This approach can help with faster adaptation when the model is yet to see sufficient examples for the unseen classes.
+
+
diff --git a/_site/site/2020/08/31/Deep-Reinforcement-Learning-and-the-Deadly-Triad.html b/_site/site/2020/08/31/Deep-Reinforcement-Learning-and-the-Deadly-Triad.html
new file mode 100644
index 00000000..dde4f919
--- /dev/null
+++ b/_site/site/2020/08/31/Deep-Reinforcement-Learning-and-the-Deadly-Triad.html
@@ -0,0 +1,139 @@
+
Introduction
+
+
+
+
The paper investigates the practical impact of the deadly triad (function approximation, bootstrapping, and off-policy learning) in deep Q-networks (trained with experience replay).
+
+
+
The deadly triad is called so because when all the three components are combined, TD learning can diverge, and value estimates can become unbounded.
+
+
+
However, in practice, the component of the deadly triad has been combined successfully. An example is training DQN agents to play Atari.
The effect of each component of the triad can be regulated with some design choices:
+
+
+
+
Bootstrapping - by controlling the number of steps before bootstrapping.
+
+
+
Function approximation - by controlling the size of the neural network.
+
+
+
Off-policy learning - by controlling how data points are sampled from the replay buffer (i.e., using different prioritization approaches)
+
+
+
+
+
The problem is studied in two contexts: toy example and Atari 2600 games.
+
+
+
The paper makes several hypotheses about how different components may interact in the triad and evaluate these hypotheses by training DQN with different hyperparameters:
+
+
+
+
Number of steps before bootstrapping - 1, 3, 10
+
+
+
Four levels of prioritization (for sampling data from the replay buffer)
Network sizes-small, medium, large and extra-large.
+
+
+
+
+
Each experiment was run with three different seeds.
+
+
+
The paper formulates a series of hypotheses and designs experiments to support/reject the hypotheses.
+
+
+
+
Hypothesis 1: Combining Q learning with conventional deep RL function spaces does not commonly lead to divergence
+
+
+
+
Rewards are clipped between -1 and 1, and the discount factor is set to 0.99. Hence, the maximum absolute action value is bound to smaller than 100. This upper bound is used soft-divergence in the value estimates.
+
+
+
The paper reports that while soft-divergence does occur, the values do not become unbounded, thus supporting the hypothesis.
+
+
+
+
Hypothesis 2: There is less divergence when correcting for overestimation bias or when bootstrapping on separate networks.
+
+
+
+
One manifestation of bootstrapping on separate networks is target-Q learning. While using separate networks helps on Atari, it does not entirely solve the problem on the toy setup.
+
+
+
One manifestation of correcting for the overestimation bias is using double Q-learning.
+
+
+
In the standard form, double Q-learning benefits by bootstrapping on a separate network. To isolate the gains by using each component independently, an inverse double Q-learning update is used that does not use a separate target-network for bootstrapping.
+
+
+
Experimentally, Q-learning is the most unstable while target Q-learning and double Q-learning are the most stable. This observation supports the hypothesis.
+
+
+
+
Hypothesis 3: Longer multi-step returns will diverge easily
+
+
+
+
This hypothesis is intuitive as the dependence on bootstrapping is reduced with multi-step returns.
+
+
+
Experimental results support this hypothesis.
+
+
+
+
Hypothesis 4: Larger, more capacity networks will diverge less easily.
+
+
+
+
This hypothesis is based on the assumption that more flexible value function approximations may behave more like the tabular case.
+
+
+
In practice, smaller networks show fewer instances of instability than the larger networks.
+
+
+
The hypothesis is not supported by the experiments.
+
+
+
+
Hypothesis 5: Stronger prioritization of updates will diverge more easily.
+
+
+
This hypothesis is supported by the experiments for all the four updates.
+
+
+
Effect of the deadly triad on the agent’s performance
+
+
+
+
Generally, soft-divergence correlates with poor control performance.
+
+
+
For example, longer multi-step returns lead to fewer instances of instabilities and better performance.
+
+
+
The trend is more interesting in terms of network capacity. Large networks tend to diverge more but also perform the best.
+
+
+
While action-value estimates can grow to large values, they can recover to plausible values as training progresses.
+
+
diff --git a/_site/site/2020/09/07/Revisiting-Fundamentals-of-Experience-Replay.html b/_site/site/2020/09/07/Revisiting-Fundamentals-of-Experience-Replay.html
new file mode 100644
index 00000000..93564e53
--- /dev/null
+++ b/_site/site/2020/09/07/Revisiting-Fundamentals-of-Experience-Replay.html
@@ -0,0 +1,130 @@
+
Introduction
+
+
+
+
The paper presents an extensive study of the effects of experience replay in Q-learning based methods.
+
+
+
It focuses explicitly on the replay capacity and replay ratio (ratio of learning updates to experience collected).
Replay capacity is defined as the total number of transitions stored in the replay buffer.
+
+
+
Age of a transition (stored in the replay buffer) is defined as the number of gradient steps taken by the agent since the transition was stored.
+
+
+
More is the replay capacity, more will be the age of the oldest transition (also referred to as the age of the oldest policy).
+
+
+
More is the replay capacity, more will be the degree of “off-policyness” of the transitions in the buffer (with everything else held constant).
+
+
+
Replay ratio is the number of gradient updates per environment transition. This ratio can be used as a proxy for how often the agent uses old data (vs. collecting new data) and is related to off-policyness.
For experiments, a subset (of 14 games) is selected from Atari ALE (Arcade Learning Environment) with sticky actions.
+
+
+
Each experiment is repeated with three seeds.
+
+
+
Rainbow is used as the base algorithm.
+
+
+
Total number of gradient updates and batch size (per gradient update) are fixed for all the experiments.
+
+
+
Rainbow used replay capacity of 1M and oldest policy of age 250K.
+
+
+
In experiments, replay capacity varies from 0.1M to 10M ( 5 values), and the age of the oldest policy varies from 25K to 25M (4 values).
+
+
+
+
Observations
+
+
+
+
With the age of the oldest policy fixed, performance improves with higher replay capacity, probably due to increased state-action coverage.
+
+
+
With fixed replay capacity, reducing the oldest policy’s age improves performance, probably due to the reduced off-policyness of the data in the replay buffer.
+
+
+
However, in some specific instances (with sparse reward, hard exploration setup), performance can drop when reducing the oldest policy’s age.
+
+
+
Increasing replay capacity, while keeping the replay ratio fixed, provides varying improvements and depends on the particular values of replacy capacity and replay ratio.
+
+
+
The paper reports the effect of these choices for DQN as well.
+
+
+
Unlike Rainbow, DQN does not improve with larger replay capacity, irrespective of whether the replay ratio or age of the oldest policy is kept fixed.
+
+
+
Given that the Rainbow agent is a DQN agent with additional components, the paper explores which of these components leads to an improvement in Rainbow’s performance as replay capacity increases.
+
+
+
+
Additive Experiments
+
+
+
+
Four new DQN variants are created by adding each of Rainbow’s four components to the base DQN agent.
+
+
+
DQN with n-step returns is the only variant that benefits by increased replay capacity.
+
+
+
The usefulness of n-step returns is further validated by verifying that Rainbow agent without n-step returns does not benefit by increased replay capacity. While Rainbow agent without any other component benefits by the increased capacity.
+
+
+
Prioritized Experience Replay does not significantly affect the performance with increased replay capacity.
+
+
+
The observation that n-step returns are critical for taking advantage of larger replay sizes is surprising because the uncorrected n-step returns are theoretically not suitable for off-policy learning.
+
+
+
The paper tests the limits of increasing replay capacity (with n-step returns) by performing experiments in the offline-RL setup, the agent collects a dataset of about 200M frames. These frames are used to train another agent.
+
+
+
Even in this extreme setup, n-step returns improve the learning agent’s performance.
+
+
+
+
Why do n-step returns help?
+
+
+
+
Hypothesis 1: n-step returns help to counter the increased off-policyness produced by a larger replay buffer.
+
+
+
This hypothesis does not seem to hold as keeping the oldest policy fixed or using the same contrastive factor as an n-step update does not improve the 1-step update’s performance.
+
+
+
+
Hypothesis 2: Increasing the replay buffer’s capacity may reduce the variance of the n-step returns.
+
+
+
+
This hypothesis is evaluated by training on environments with lesser variance or by turning off the sticky actions in the atari domain.
+
+
+
While the hypothesis does explain the gains by using n-step returns to some extent, n-step gains are observed even in environments with low variance.
+
+
+
+
diff --git a/_site/site/2020/09/14/MONet-Unsupervised-Scene-Decomposition-and-Representation.html b/_site/site/2020/09/14/MONet-Unsupervised-Scene-Decomposition-and-Representation.html
new file mode 100644
index 00000000..311ec262
--- /dev/null
+++ b/_site/site/2020/09/14/MONet-Unsupervised-Scene-Decomposition-and-Representation.html
@@ -0,0 +1,91 @@
+
Introduction
+
+
+
+
The paper introduces Multi-Object Network (MONet) architecture that learns a modular representation of images by spatially decomposing scenes into objects and learning a representation for these objects.
Attention Module: generates spatial masks corresponding to the objects in the scene.
+
+
+
VAE: learn representation for each object.
+
+
+
+
+
VAE components:
+
+
+
+
Encoder: It takes as input the image and the attention mask generated by the attention module and produce the parameters for distribution over latent variable z.
+
+
+
Decoder: It takes as input the latent variable z and attempts to reproduce the image.
+
+
+
+
+
The decoder loss term is weighted by mask, i.e., the decoder tries to reproduce only those parts of the image that the attention mask focuses on.
+
+
+
The attention mechanism is auto-regressive with an ongoing state (called a scope) that tracks which parts of the image are not yet attended over.
+
+
+
In the last step, no attention mask is computed, and the previous scope is used as-is. This ensures that all the masks sum to 1.
+
+
+
The VAE also models the attention mask over the components, i.e., the probability that the pixels belong to a particular component.
+
+
+
+
Motivation
+
+
+
+
A model could efficiently process compositional visual scenes if it can exploit some recurring structures in the scene.
+
+
+
The paper validates this hypothesis by showing that an autoencoder performs better if it can build up the scenes compositionally, processing one mask at a time (these masks are ground-truth spatial masks) rather than processing the scene at once.
+
+
+
+
Results
+
+
+
+
VAE encoder parameterizes a diagonal Gaussian latent posterior with a spatial broadcast decoder that encourages the VAE to learn disentangled features.
+
+
+
MONet with seven slots is trained on Objects Room dataset with 1-3 objects.
+
+
+
+
It learns to generate different attention mask for different objects.
+
+
+
Combining the reconstructed components using the corresponding attention masks produces good quality reconstruction for the entire scene.
+
+
+
Since it is an autoregressive model, MONet can be evaluated for more slots. The model generalizes to novel scene configurations (not seen during training).
+
+
+
+
+
On the Multi-dSprites dataset (modification of the dSprites dataset), the model (post-training) distinguishes individual sprites and background.
+
+
+
On the CLEVER data (2-10 objects per image), the model generates good image segmentation and reconstructions and can distinguish between overlapping shapes.
+
+
diff --git a/_site/site/2020/09/21/Harvest,-Yield,-and-Scalable-Tolerant-Systems.html b/_site/site/2020/09/21/Harvest,-Yield,-and-Scalable-Tolerant-Systems.html
new file mode 100644
index 00000000..9d5131dc
--- /dev/null
+++ b/_site/site/2020/09/21/Harvest,-Yield,-and-Scalable-Tolerant-Systems.html
@@ -0,0 +1,82 @@
+
Introduction
+
+
+
+
A classic paper that looks into strategies for scaling large systems that can tolerate graceful degradation.
CAP refers to strong Consistency, high Availability, and Partitionability.
+
+
+
Strong consistency refers to single copy ACID consistency.
+
+
+
High availability means any consumer can access the data anytime. Generally, this is achieved by adding one or more data replicas.
+
+
+
Partitionability means that the system can survive a partition between the different replicas.
+
+
+
Strong CAP theorem states that any system can have only two out of three properties.
+
+
+
Weak CAP theorem says that stronger are the guarantees about any two properties, weaker are the third property’s guarantees.
+
+
+
+
Harvest, Yield, and CAP Theorem
+
+
+
+
Assume that the clients are making a request to a server.
+
+
+
There are two quantities of interest here:
+
+
+
Yield - the probability of completing a request.
+
Harvest - completeness of answer to a query.
+
+
+
+
In the presence of faults, a tradeoff can is made between yield and harvest. This tradeoff applies to both read and update queries.
+
+
+
+
Two strategies for scaling systems
+
+
Trading Harvest for Yield
+
+
+
+
In a hundred node cluster (without replication), a single-node failure reduces harvest by 1 %, and in the case of multi-node failure, the harvest degrades linearly.
+
+
+
The probability of losing high-priority data can be reduced by replicating it. However, replicating all the data would not n guarantee 100% harvest and yield despite significant costs.
+
+
+
+
Application Decomposition and Orthogonal Mechanisms
+
+
+
+
Decompose a large application into subcomponents so that each component can be provisioned separately. Strong consistency can only be applied only on the components that need it, instead of the application as a whole.
+
+
+
Further, failure of one or more components need not cause the application to fail as a whole.
+
+
+
Decomposition also provides the opportunity to use orthogonal mechanisms, i.e., mechanisms independent of other mechanisms with no runtime interface.
+
+
+
Composition of orthogonal subsystems improves the robustness of runtime interactions by locally containing the errors. For example, the orthogonal components can be restarted /replaced independently without affecting other running components.
+
+
diff --git a/_site/site/2020/09/28/A-Foliated-View-of-Transfer-Learning.html b/_site/site/2020/09/28/A-Foliated-View-of-Transfer-Learning.html
new file mode 100644
index 00000000..04468877
--- /dev/null
+++ b/_site/site/2020/09/28/A-Foliated-View-of-Transfer-Learning.html
@@ -0,0 +1,72 @@
+
Introduction
+
+
+
+
The paper presents a formalism for transfer learning, offers a definition of relatedness between tasks, and proposes foliations as a mathematical framework to represent the relationship between tasks.
The term representation denotes a mechanism for describing and realizing abstract objects, thus allowing manipulation and reasoning about the objects. This description goes beyond the usual meaning (in deep learning), where representation denotes some useful information about data.
+
+
+
Relatedness describes what changes between tasks. Consider a set of transformations (or functions) that convert one task to another. A relationship between two tasks is an element of this transformation set.
+
+
+
Given a transformation set, one can define a set of related tasks, which is the set of all the tasks that can be transformed into each other using the functions from the given transformation set. This set of tasks is an equivalence class, and the transformation set is the equivalence relationship.
+
+
+
Given two related tasks t1 and t2, denote the corresponding models (trained on those tasks) as m1 and m2. One can assume that m1 and m2 are related in the same way as t1 and t2 (equivariance).
+
+
+
Now, given a set of transformations, one can partition the space of continuous functions into non-overlapping spaces, which describe a set of related tasks. These spaces are referred to as the parallel spaces or transfer spaces.
+
+
+
The parallel space represents a lower dimension than the original space. So knowing which parallel space a model lies on can make it easier to find it. This is the primary motivation behind transfer learning - knowing the relationship between tasks can make it easier to find a solution to new tasks.
+
+
+
Another way of partitioning the set of transformations is to use tessellation (e.g., Voronoi diagrams). Tasks in the same partition are similar to each other as compared to a task from another partition.
+
+
+
Two tasks are defined as similar if the distance between them (under some distance metric) is small.
+
+
+
Similarity is a geometric notion, while relatedness is a transformative notion. Parallelized space is to relatedness what tessellation is to similarity.
+
+
+
The distinction between similarity and relatedness is quite nuanced, and the authors provide several examples to differentiate between them.
+
+
+
Similarity can only be measured in terms of a reference element (similar to what). For example, when one finetunes a pre-trained model on a new task, one assumes that the model’s pretraining task is similar to the current task.
+
+
+
Given a set (say T), a quantity (a function that maps elemenets of T to a k dimensional vector) is said to be invariant with respect to a transformation p (defined on T) if q(f) = q(p(f)) ie the value of f (belonging to T) does not change if f is transformed by p.
+
+
+
If one assumes that the set of transformations is a group, specifically a Lie group whose action on the set of tasks is locally free and regular, then one can define a parallel partitioning of the space of tasks and the space of models.
+
+
+
One can develop a hierarchial categorization scheme for the set of all considered tasks using the invariant quantities.
+
+
+
One can consider the space of tasks and models to be smooth manifolds as manifolds naturally give a notion of representation and transformations between them.
+
+
+
A manifold is a topological space that can be locally mapped to a Euclidean space using coordinate charts. One can define regular foliation by choosing charts that satisfy certain conditions. In that case, the manifold has immersed, connected, non-intersecting submanifolds called leaves.
+
+
+
The charts (that satisfies those conditions) give a set of rectified coordinates, where the notions of “which leaf a point is on” and “where on the leaf it is” are clearly separated.
+
+
+
Thus, foliation can provide the theoretical tools to work with parallel spaces.
+
+
+
How can the foliations be incorporated into theory and solutions for transfer learning is left aa future work.
+
+
diff --git a/_site/site/2020/10/12/Remembering-for-the-Right-Reasons-Explanations-Reduce-Catastrophic-Forgetting.html b/_site/site/2020/10/12/Remembering-for-the-Right-Reasons-Explanations-Reduce-Catastrophic-Forgetting.html
new file mode 100644
index 00000000..77e4a073
--- /dev/null
+++ b/_site/site/2020/10/12/Remembering-for-the-Right-Reasons-Explanations-Reduce-Catastrophic-Forgetting.html
@@ -0,0 +1,63 @@
+
Introduction
+
+
+
The paper hypothesizes that catastrophic forgetting can happen if the model can not rely on “reasoning” used for an old datapoint. If that is the case, catastrophic forgetting may be alleviated when the model “remembers” why it made a prediction previously.
+
The paper presents a simple instantiation of this hypothesis, in the form of a technique called Remembering for the Right Reasons (RRR).
+
The idea is to store model explanations, along with previous examples in the replay buffer. During replay, an additional explanation loss is used, along with the regular replay loss.
The model is trained over a sequence of data distributions in the class-incremental learning setup. A single-head architecture is used so that the task ID is not required during inference.
+
Along with the standard replay buffer (\(M^{rep}\)) for the raw input examples (from different tasks), another replay buffer (\(M^{RRR}\)) is maintained for storing the “explanations” (in the form of saliency maps), corresponding to examples in \(M^{rep}\).
+
RRR is implemented as an L1 loss on the error between the saliency map generated after training on the current task and the saliency map in \(M^{RRR}\).
+
Saliency maps need to be generated while the model is training. This requirement rules out black-box saliency methods, which can be used only after training.
+
The gradient-based white-box explainability techniques that are used include:
+
+
Vanilla backpropagation - Perform a forward pass through the model and take the gradient of the given output class with respect to the input.
+
Backpropagation with SmoothGrad - Saliency maps generated using Vanilla backpropagation can be visually noisy. These maps can be improved by adding pixel-wise Gaussian noise to n copies of the image and averaging the resulting gradients. The paper used n=40.
+
Gradient-weighted Class Activation Mapping (Grad-CAM) - Uses gradients to determine the importance of feature map activations on a given prediction.
+
+
+
RRR can be easily used with memory and regularization based approaches.
+
The paper combined RRR with the following standard Class Incremental Learning (CIL) models:
+
C-way K-shot class incremental learning with C classes and K training samples per class and b base classes to learn as the first task.
+
Caltech-UCSD Birds dataset with 100 base classes and remaining 100 classes divided into ten tasks, with three samples per class. The test set is not changed.
+
In teems of saliency maps., Grad-CAM is better than Vanilla Backpropagation, which in turn is comparable to SmoothGrad. The same trend is seen in terms of memory overhead, with Grad-CAM having the least memory overhead.
+
Adding the RRR loss improves the performance of all the baselines.
+
+
+
Standard Class Incremental Learning
+
+
+
CIFAR100 and ImageNet100 with a memory budget of 2000 samples.
+
Adding the RRR loss improves all the baselines’ performance, and the gains for ImageNet100 are more significant than the gains for CIFAR100.
+
+
+
How often does the model remember its decision for the right reason?
+
+
+
The paper uses the Pointing Game (PG) experiment, which uses the ground truth image segmentation to define the true object region.
+
If the maximum attention location (in the predicted saliency map) falls inside the objects, it is considered a hit, else a miss. A hit on a previous example is considered a proxy for the model remembering its decision for the right reason.
+
The precision and recall are reported for the hit metric. Using RRR increases both precision (i.e., less often the model makes the correct decision without looking at the right evidence) and recall (i.e., less frequently does the model makes an incorrect decision, despite looking at the proper evidence).
+
diff --git a/_site/site/2020/10/19/Learning-Explanations-That-Are-Hard-To-Vary.html b/_site/site/2020/10/19/Learning-Explanations-That-Are-Hard-To-Vary.html
new file mode 100644
index 00000000..b723cde7
--- /dev/null
+++ b/_site/site/2020/10/19/Learning-Explanations-That-Are-Hard-To-Vary.html
@@ -0,0 +1,86 @@
+
Introduction
+
+
+
The paper builds on the principle “good explanations are hard to vary” to propose that invariant mechanisms can be identified by finding explanations (say model parameters) that are hard to vary across examples.
Collection of d different datasets (from different environments). Each dataset is a collection of input-target tuples.
+
Objective is to learn a function f (also called mechanism) to map the input to the target (for all the environments).
+
The standard approach is to pool the loss for examples corresponding to the different environments and perform gradient updates on this average-pooled loss.
+
In this standard gradient-based setup, the model may not learn invariances due to the following reasons:
+
+
Model learned the spurious features first, and now the training loss is too small.
+
The pooled loss is generally computed by summing (or averaging) the loss corresponding to individual examples. Thus the gradient for each example is calculated independently. Each sample can be thought of as a dataset of size 1, for which all the features are relevant.
+
Gradient descent with averaging (of gradients across the environments) greedily maximizes for the learning speed and not invariance.
+
+
+
Performing arithmetic mean can be seen as performing an OR operation (i.e., the sum can be high if any one of the constituents is high), whereas performing geometric mean can be seen as performing an AND operation (i.e., the product can be high only if all the constituents are high).
+
+
+
Invariant Learning Consistency(ILC)
+
+
+
Given an algorithm \(A\), let \(\theta_{A}^{*}\) denote the set of convergence points of \(A\) when trained on all the environments.
+
Each convergence point is associated with a consistency score.
+
Intuitively, given a convergence point and an environment e, find the set of parameters equivalent to the convergence point (in terms of loss) with respect to e. Let’s call this set as S.
+
Evaluate the points in this set for all the remaining environments. For the given convergence point, an environment e’ is consistent with e if the maximum difference in the loss for two environments is small, for all points belonging to S.
+
This idea is used to define the invariant learning consistency score for algorithm \(A\), which measures the expected consistency of the converged points (on the pooled data) across all the environments.
+
The paper shows that the converged points’ consistency is linked to the Hessians’ geometric mean and that for the convex quadratic case, using the elementwise geometric mean of gradients improves consistency.
+
However, there are some practical challenges:
+
+
Geometric mean is defined only when all signs are consistent. This issue can potentially be handled by treating different signs as 0.
+
There is very little flexibility in “partial” agreement, and even a single zero gradient component can stop optimization for that component. This can probably be handled by not masking if many environments have a gradient for that component.
+
Geometric component needs to be computed in the log-domain (for numerical scalability), but that can be computationally more expensive.
+
When using adaptive optimizers like Adam, the exact magnitude of geometric mean will be ignored because of rescaling for the local curvature adaptation.
+
+
+
Some of these challenges can be handled using average gradients when the geometric mean would be 0 and masking out components based on the sign.
+
+
+
AND-mask
+
+
+
The ideas from the previous section can be used to develop a practical algorithm called AND-mask.
+
Zero-out gradients that have inconsistent signs across some threshold number (hyper-parameter) of environments.
+
In the presence of purely random gradient patterns, the AND-mask decreases the signals’ strength exponentially fast.
+
+
+
Experiments
+
+
Synthetic Memorization Dataset
+
+
+
This is a binary classification task with two kind of features: (i) “meaningful” features that are shared across environments but harder for the model to learn and (ii) “shortcut” features that are easy to learn but not shared across environments.
+
While the dataset may look simple, it is difficult to find the invariant mechanism because the “shortcut” features allow for a simple, linear decision boundary, with a large margin that is fast to learn, has perfect accuracy, robust to input noise, and no iid generalization gap.
+
Baselines:
+
+
MLPs trained with regularizers like dropout, L1, L2, and batch norm.
+
Domain Adversarial Neural Networks (DANN)
+
Invariant Risk Minimization (IRM)
+
+
+
In terms of results, AND-mask with L1/L2 regularizers gives the best results.
+
Empirically, the paper shows that the signal from the “meaningful” features is present when the gradients are averaged, but their magnitude is much smaller than the signal from the “shortcut” features.
+
+
+
Experiments on CIFAR-10
+
+
+
A ResNet model is trained on the CIFAR-10 dataset with random labels, with and without the AND-mask.
+
The model with the AND-mask did not memorize the data, whereas the model without the AND-mask did. As sanity, the paper ensured that both the models generalize well when trained with the original labels.
+
Note that for this experiment, every example was treated to have come from its own environment.
+
+
+
Behavioral Cloning on CoinRun
+
+
+
Train an expert policy using PPO for 400M steps on the full distribution of levels.
+
Generate a dataset of state-action pairs. Training data consists of 1000 states from each of the 64 levels, while the test data comes from 2000 levels.
+
A ResNet18 model is used as an imitation learning policy.
+
The exact implementation of the AND-mask is a little more involved, but the key takeaway is that model trained with AND-mask identifies invariant mechanisms across different levels.
+
diff --git a/_site/site/2020/11/02/One-Solution-is-Not-All-You-Need-Few-Shot-Extrapolation-via-Structured-MaxEnt-RL.html b/_site/site/2020/11/02/One-Solution-is-Not-All-You-Need-Few-Shot-Extrapolation-via-Structured-MaxEnt-RL.html
new file mode 100644
index 00000000..8c6c0253
--- /dev/null
+++ b/_site/site/2020/11/02/One-Solution-is-Not-All-You-Need-Few-Shot-Extrapolation-via-Structured-MaxEnt-RL.html
@@ -0,0 +1,119 @@
+
Introduction
+
+
+
+
Key idea: Practicing and remembering diverse solutions to a task can lead to robustness to that task’s variations.
+
+
+
The paper proposes a framework to implement this idea - train multiple policies such that they are collectively robust to a new distribution over environments while using a single training environment.
During training, the agent has access to only one MDP.
+
+
+
During the evaluation, the agent encounters a new MDP which has the same state and action space but may have a different reward and transition function.
+
+
+
The agent is allowed some interactions (say k) with the test MDP and is then evaluated on the test MDP. The setup is referred to as few-shot robustness.
+
+
+
+
Structured Maximum Entropy Reinforcement Learning (SMERL)
+
+
+
+
Represent a set of policies using a latent variable policy (i.e., a policy conditioned on a latent variable z).
+
+
+
This has two benefits: (i) Multiple policies can be represented by the same object, and (ii) diverse behaviors can be learned by encouraging the trajectories, corresponding to different z to be different, while being able to solve the task.
+
+
+
A diversity-inducing objective is used to encourage the agent to learn different trajectories for different z.
+
+
+
Specifically, the mutual information between p(Z) and marginal trajectory distribution for the latent variable policy is maximized, subject to the constraint that each policy achieves close to optimal returns in the train MDP.
+
+
+
The mutual information between p(Z) and marginal trajectory distribution for the latent variable policy is lower bounded by the sum of mutual information terms over individual states (appearing in the trajectory).
+
+
+
An unsupervised reward function is defined using the mutual information between states and latent variables.
+
+
+
\(r(s, a) = log(q_{\phi})(z\|s) - log(p(z))\) where \(q_{\phi}\) is a learned discriminator.
+
+
+
This unsupervised reward is optimized for only when the policy achieves close to an optimal return, i.e., the environment return is close to the optimal return. Otherwise, the agent optimizes only for the environment return.
+
+
+
+
Implementation
+
+
+
+
SMERL is implemented using SAC with a latent variable maximum entropy policy.
+
+
+
The set of latent variables is a fixed discrete set \(Z\) and \(p(z)\) is set to be a uniform distribution over this set.
+
+
+
At the start of an episode, a \(z\) is sampled and used throughout the episode.
+
+
+
Discriminator \(q_{\phi}(z\|s)\) is trained to infer \(z\) from the visited states.
+
+
+
A baseline SAC agent is trained beforehand to evaluate if the current training policy achieves close to optimal environment return.
+
+
+
During the evaluation, the policy corresponding to each latent variable is executed in the test MDP, and the policy with the maximum return is returned.
+
+
+
+
Theoretical Analysis
+
+
+
+
Given an MDP \(M\) and \(\epsilon>0\), the MDP robustness set is defined as the set of all MDPs \(M'\) where the optimal policy of \(M'\) produces the same trajectory distribution in \(M'\) as \(M\). Moreover, on the training MDP \(M\), the optimal policies (corresponding to \(M\) and \(M'\)) obtain similar returns.
+
+
+
The paper shows that SMERL generalizes to MDPs belong to the robustness set.
+
+
+
It also provides a simplified view of the optimization objective and shows how it naturally leads to a trajectory-centric mutual information objective.
On the 2D navigation environment, the paper shows that SMERL learns to use different trajectories to reach the goal.
+
+
+
On the Mujoco setup, the evaluation shows that SMERL generally outperforms the best-performing baseline or is close to the best-performing baseline on different tasks.
+
+
+
Generally, higher train performance does not correlate with higher test performance, and there is no single policy that performs the best across all the tasks. Thus, it should be beneficial to learn multiple diverse policies that can be selected from during testing.
+
+
diff --git a/_site/site/2020/11/09/Searching-for-Build-Debt-Experiences-Managing-Technical-Debt-at-Google.html b/_site/site/2020/11/09/Searching-for-Build-Debt-Experiences-Managing-Technical-Debt-at-Google.html
new file mode 100644
index 00000000..a529dcfe
--- /dev/null
+++ b/_site/site/2020/11/09/Searching-for-Build-Debt-Experiences-Managing-Technical-Debt-at-Google.html
@@ -0,0 +1,140 @@
+
Introduction
+
+
+
+
The paper describes the efforts to control and repay the technical debt in the build system at Google (called the Build Debt).
+
+
+
Guiding Principles:
+
+
+
+
Automate techniques to analyze and fix issues that contribute to technical debt.
+
+
+
Make it easier to do the right thing as developers can incur technical debt unknowingly.
+
+
+
Make it hard to do the wrong thing, e.g., by building stricter checks into the build process.
+
+
+
+
+
Note that some of the metrics and design decisions may be outdated now (the paper was written in 2012). However, the core message is still relevant.
BUILD files encapsulate the specifications for building software.
+
+
+
Generally, these files are maintained manually, and the dependencies may not be up-to-date over time.
+
+
+
In extreme cases, some of the build targets are not built for months. Such targets are called zombie targets.
+
+
+
Originally, any project could depend on any other project’s internal details, thus creating (sometimes unwanted) couplings.
+
+
+
If the lower-level project did not intend to expose some internal details, the unwanted couplings introduce technical debt and make it harder to modify the lower-level project.
+
+
+
One form of technical debt is the visibility debt or the cost of back-fitting visibility rules onto the existing build specifications to re-establish the appropriate encapsulations.
+
+
+
Another example of technical debt is dead code that can confuse the developers looking for useful APIs.
+
+
+
+
Dependency Debt
+
+
+
+
Over-declared or underutilized dependencies can slow the build and testing of systems.
+
+
+
Under-declared dependencies can make the build process brittle and make it difficult to remove over-declared dependencies.
+
+
+
Potential solutions for over-declared dependencies include:
+
+
+
+
Setting aside some dedicated time for fixing build rules. But this approach is not automated, and potential breakages make it harder for developers to do the right thing.
+
+
+
Automatically add all the under-declared dependencies to the BUILD files. The system can raise an error if a direct dependency is missing, making it harder to do the wrong thing.
+
+
+
Automation can be applied for finding/reporting the over-declared dependencies as well.
+
+
+
+
+
Potential solutions for underutilized dependencies include:
+
+
+
+
While it is challenging to automate fixing underutilized dependencies, automating the discovery of such dependencies is still useful.
+
+
+
Highlighting dependencies with high cost and low removal effort could incentivize developers to clean up their projects.
+
+
+
+
+
+
Zombie Targets
+
+
+
+
Zombie targets can be identified by query the results of build and test runs.
+
+
+
A target is marked as “dead” if the attempts to build it have failed for at least 90 days. Until then, build errors are considered to be transient.
+
+
+
A zombie target can be eliminated by deleting its definition from the BUILD and deleting the source files, which are reachable only via the zombie target.
+
+
+
+
Visibility Debt
+
+
+
+
Originally, the default visibility of all the targets was public, leading to unintended dependencies.
+
+
+
The visibility of all the existing builds was set to legacy_public, and the default visibility was changed to private.
+
+
+
This encouraged developers to explicitly consider if they wanted other projects to depend on their project.
+
+
+
+
Dead Flags
+
+
+
+
Google developed its command-line parsing utilities and defined a set of recognized command-line flags for libraries and binaries.
+
+
+
Overtime, the number of flags grew to half a million, and many of these flags are not useful anymore (i.e., dead).
+
+
+
These dead flags can it hard to understand and refactor code.
+
+
+
Existing flags are analyzed to check which ones have always been set to the same value and replaced by those contents, clearing about 150 thousand flags.
+
+
+
Removing dead flags also helps to clean up dead/unreachable code.
+
+
diff --git a/_site/site/2020/11/16/Data-Management-for-Internet-Scale-Single-Sign-On.html b/_site/site/2020/11/16/Data-Management-for-Internet-Scale-Single-Sign-On.html
new file mode 100644
index 00000000..8fe53e7f
--- /dev/null
+++ b/_site/site/2020/11/16/Data-Management-for-Internet-Scale-Single-Sign-On.html
@@ -0,0 +1,127 @@
+
Introduction
+
+
+
+
The paper describes the architecture of an erstwhile single-sign-on (SSO) service used by Google, called Google Accounts (2006).
+
+
+
Note that some of the metrics and design decisions may be outdated now (the paper was written in 2006). However, the core message is still relevant.
SSO’s availability affects the availability of all applications that require user sign-in.
+
+
+
Generally, systems can achieve high availability by sacrificing consistency, but given the nature of SSO (matching username/passwords), providing an inconsistent view is not a good option, and single-copy consistency is a usability requirement.
+
+
+
+
Berkeley DB
+
+
+
+
Berkeley DB is an embedded, high-performance, scalable, transactional storage system for key-value data and provides both keyed and sequential lookup.
+
+
+
It provides a primary copy replication model with a single writer (called master) and multiple read-only replicas.
+
+
+
All writes are sent to the master, which first applies the changes and then propagates them to the replicas.
+
+
+
The master and the replicas have identical logs, and in case of master failure, a new master is elected from the replicas.
+
+
+
Some synchronization may be needed between the replicas in case, e.g., the master dies in between a transaction.
+
+
+
+
SSO Architecture
+
+
+
+
SSO service maps usernames to user account data and services to service-specific data.
+
+
+
The SSO database is partitioned into shards, where each shard is a replicated Berkeley DB (having 5 to 15 replicas).
+
+
+
Each replica stores the data in a B+-link tree data structure.
+
+
+
Consistent reads must go to the master, while non-master replicas can serve “ stale” reads.
+
+
+
In the case of larger replication groups (say 15 replicas), only a subset of replicas can become master (“electable replicas”).
+
+
+
In general, replicas are spread geographically to handle machine-failure, network-failure, and data center-failure.
+
+
+
Replicas in a share are kept close to reduce the communication latency, which affects the time to commit a write operation or electing a new master.
+
+
+
Some of the shards implement ID-map, i.e., map of username to userid and userid to shards.
+
+
+
+
Database Integration
+
+
+
Berkeley DB leaves decisions regarding quorums, leases, etc., up to the application.
+
+
+
Quorums
+
+
+
+
SSO chooses a quorum protocol that guarantees that updates are never lost.
+
+
+
For the write queries, the master waits for a positive acknowledgment from a majority of the replicas, including itself, before marking the query as completed.
+
+
+
When selecting a new leader, SSO requires a majority of replicas to agree. Moreover, Berkeley DB elections always choose a replica with the latest log entry during an election, thus guaranteeing that the new master’s log will include all the previous master’s updates.
+
+
+
+
Leases
+
+
+
+
The master holds a master lease when responding to read queries and refreshes this lease periodically by communicating with a majority of replicas.
+
+
+
The lease guarantees that the master is not returning stale data if a partition or failure causes the master to lose its mastership, i.e., holding the lease guarantees that the master is still the master.
+
+
+
Moreover, elections can not be completed within the lease timeout interval.
+
+
+
+
Replica Group Membership
+
+
+
+
SSO maintains a replica configuration containing the logical (DNS) name and IP address of each replica.
+
+
+
In case of any changes to the configuration, the changes are specified in a file that the master reads periodically.
+
+
+
If the configuration changes, the master initiates a configuration change and update the database.
+
+
+
Non-master replicas can get the new configuration from the database.
+
+
+
A new replica or a replica that lost state (say due to a failure) starts as a non-voting replica and can not participate in an election till it has caught up with the master as of the time the replica joined (again).
+
+
diff --git a/_site/site/2020/11/23/Exploring-Simple-Siamese-Representation-Learning.html b/_site/site/2020/11/23/Exploring-Simple-Siamese-Representation-Learning.html
new file mode 100644
index 00000000..f99c1500
--- /dev/null
+++ b/_site/site/2020/11/23/Exploring-Simple-Siamese-Representation-Learning.html
@@ -0,0 +1,107 @@
+
Introduction
+
+
+
+
The paper shows that Siamese networks can be used for unsupervised learning with images without needing techniques like negative sample pairs, large batch training, or momentum encoders. The training mechanism is referred to as the SimSiam method.
Given an input image x, create two augmented views x1 and x2.
+
+
+
These views are processed by an encoder network f.
+
+
+
One of the views (say x1) is processed by the encoder f as well as a predictor MLP h to obtain a projection p1 ie p1 = h(f(x1)).
+
+
+
The second view (x2) is processed only by the encoder f to obtain an encoding z2 i.e., z2 = f(x2).
+
+
+
Negative cosine similarity is minimized between p1 and z2 with the catch that the resulting gradients are not used to update the encoder via z2. I.e., Loss = D(p1, stopgrad(z2)) where D is the negative cosine similarity and stopgrad is an operation that stops the flow of gradients.
+
+
+
In practice, both p1, z2 and p2, z1 pairs are used for computing the loss. ie Loss = 0.5 * (D(p1, stopgrad(z2)) + D(p2, stopgrad(z1))).
+
+
+
+
Implementation Details
+
+
+
+
Encoder uses batch norm in all the layers (including output) while projection MLP uses batch norm only in the hidden layers.
+
+
+
SGD optimizer with learning rate as 0.05 * batchsize / 256, cosine learning rate decay schedule and SGD momentum = 0.9.
+
+
+
Unsupervised pretraining on the ImageNet dataset followed by training a supervised linear classifier on the frozen representations.
+
+
+
+
Results
+
+
+
+
Stop-gradient operation is necessary to avoid a degenerate solution. Without stop-gradient, the model maps all inputs to a constant z.
+
+
+
If the projection layer is removed, the method does not work (because of the loss’s symmetric nature). If the loss is also made asymmetric, the method still does not work without the projection layer. However, asymmetric loss + projection layer works.
+
+
+
Keeping the projection layer fixed (i.e., not updating during training) avoids collapse but leads to poor validation performance.
+
+
+
Training the projection layer with a constant learning rate works better in practice, likely because the projection layer needs to keep adapting before the encoder layer is sufficiently trained.
+
+
+
The method works well across different batch sizes.
+
+
+
Removing batch norm layers from all the layers in all the networks does not lead to collapse, though the model’s performance degrades on the validation dataset. Adding batch norm to the hidden layers alone is sufficient.
+
+
+
Adding batch norm to the encoder’s output further improves the performance but adding batch norm to all the layers of all the networks makes the training unstable, with the loss oscillating.
+
+
+
Overall, while batch norm helps to improve performance, it is not sufficient to avoid collapse.
+
+
+
The setup does not collapse when the cross-entropy loss replaces the cosine loss.
+
+
+
+
What is SimSiam solving?
+
+
+
+
Given that the stop-gradient operation seems to be the critical ingredient for avoiding collapse, the paper hypothesizes that SimSiam is solving a different optimization problem.
+
+
+
The hypothesis is that SimSiam is implementing an Expectation-Maximisation (EM) algorithm with two sets of variables and two underlying sub-problems.
+
+
+
The paper performs several experiments to test this hypothesis. For example, they consider k SGD steps for the first problem before performing an update for the second problem, showing that the alternating optimization is a valid formulation, of which SimSiam is a particular case.
+
+
+
+
Comparison to other methods
+
+
+
+
SimSiam achieves the highest accuracy among SimCLR, MoCo, BYOL, and SwAV for training under 100 epochs. However, it lags behind other methods when trained longer.
+
+
+
SimSiam’s representations are transferable beyond the ImageNet tasks.
+
+
+
Adding projection layer and stop-gradient operator to SimCLR does not improve its performance.
+
+
diff --git a/_site/site/2020/11/30/Consistency-Tradeoffs-in-Modern-Distributed-Database-System-Design.html b/_site/site/2020/11/30/Consistency-Tradeoffs-in-Modern-Distributed-Database-System-Design.html
new file mode 100644
index 00000000..8f28c788
--- /dev/null
+++ b/_site/site/2020/11/30/Consistency-Tradeoffs-in-Modern-Distributed-Database-System-Design.html
@@ -0,0 +1,123 @@
+
Introduction
+
+
+
+
CAP theorem has been influential in the design decisions for distributed databases.
+
+
+
However, designers incorrectly assume that the CAP theorem “always” imposes restrictions in terms of the tradeoff between availability and consistency. In contrast, the tradeoff is applicable only in the case of partitions.
+
+
+
CAP theorem led to the development of highly available systems with reduced consistency models (and reduced ACID guarantees).
+
+
+
Another tradeoff - between latency and consistency - has also been influential for database design.
+
+
+
The paper unifies CAP and latency-consistency tradeoffs into a single formulation called PACELC.
+
+
+
Note that some of the observations, especially ones about the databases, may be outdated now (the paper was written in 2012). However, the core message is still relevant.
Low latency (or high availability) means that the system must replicate data.
+
+
+
In case of an update query, three possibilities arise:
+
+
+
+
The system can choose to send data updates to all the replicas at once. This leads to two possibilities:
+
+
+
+
A replica can receive the update queries in an arbitrary order, thus breaking consistency with other replicas.
+
+
+
Alternatively, the replicas could use some protocol to agree on the order of updates. However, this can introduce latency.
+
+
+
+
+
The update queries can be first sent to a master replica.
+
+
+
+
The master replica can apply the updates and send them to the other replicas using one of the following strategies:
+
+
+
+
Synchronous replication where the master waits for all the updates to be applied to a replica(s). However, this approach introduces latency.
+
+
+
Asynchronous replication where the master assumes the update to be complete before it completes. In this case, the latency-consistency tradeoff depends on how read queries are handled:
+
+
+
+
The system can send all read queries to the master. In this case, there are no consistency issues, but additional latency is introduced because all the read queries go to the same replica, thus potentially overloading it.
+
+
+
Alternatively, the read query can be served from any replica. While this improves read latency, the results can be inconsistent now.
+
+
+
+
+
Use a mix of Synchronous and Asynchronous replication - i.e., some of the write queries are Synchronous, and others are Asynchronous. In this case, the latency-consistency tradeoff depends on how read queries are handled:
+
+
+
+
If the read is routed to at least one replica that has been Synchrnously updated, the consistency can be preserved, with additional latency for discovering the updated replica, etc.
+
+
+
If the read query can not be routed to an updated replica (maybe because none of the replicas is updated), then either latency suffers or inconsistent read can be performed.
+
+
+
+
+
+
+
+
+
The update query is first sent to an arbitrary replica.
+
+
+
This is the same as the previous case, with the query going to an arbitrary replica instead of the master replica, and suffers from the same latency issues as the last case.
+
+
+
+
+
+
In a nutshell, the tradeoff between latency and consistency is always present, irrespective of network failure.
+
+
+
This contrasts with the CAP theorem, which imposes the tradeoff between availability and consistency only in the case of a network partition.
+
+
+
+
PACELC
+
+
+
+
If there is a partition (P), how does the system tradeoff availability (A) and consistency (C); else (E), when the system is running without failures, how does the system tradeoff latency (L) and consistency (C)?
+
+
+
The latency-consistency tradeoff (ELC) is relevant only when the data is replicated.
+
+
+
Default versions of Dynamo, Cassandra, and Riak were PA/EL systems, i.e., if a partition occurs, availability is prioritized. In the absence of partition, lower latency is prioritized.
+
+
+
Fully ACID systems (VoltDB, H-Store, and Megastore) and others like BigTable and HB are PC/EC, i.e., they prioritize consistency and give up availability and latency.
+
+
+
MongoDB can be classified as a PA/EC system, while PNUTS is a PC/EL system.
+
+
diff --git a/_site/site/2020/12/07/CAP-twelve-years-later-How-the-rules-have-changed.html b/_site/site/2020/12/07/CAP-twelve-years-later-How-the-rules-have-changed.html
new file mode 100644
index 00000000..efce6723
--- /dev/null
+++ b/_site/site/2020/12/07/CAP-twelve-years-later-How-the-rules-have-changed.html
@@ -0,0 +1,154 @@
+
Introduction
+
+
+
+
The CAP theorem states that any system sharing data over the network can only have at most two (out of three) desirable properties:
+
+
+
+
consistency (C), i.e., a single, up-to-date copy of the data;
+
+
+
high availability (A) of that data (for updates); and
+
+
+
tolerance to network partitions (P).
+
+
+
+
+
This “2 of 3” formulation is misleading as it oversimplifies the interplay between properties.
ACID is a design philosophy that focuses on consistency as reflected in the traditional relational databases.
+
+
+
The four properties in ACID are:
+
+
+
+
Atomicity (A), i.e., the operations are atomic, and either the entire operation succeeds or none of it succeeds.
+
+
+
Consistency (C), i.e., a transaction preserves all the rules. Note that the consistency in CAP is a subset of consistency in ACID.
+
+
+
Isolation (I), i.e., transactions occur in isolation and do not affect each other.
+
+
+
Durability (D), i.e., the transactions are durable irrespective of system failure.
+
+
+
+
+
BASE is an alternate design philosophy that focuses on availability as reflected in the NoSQL databases.
+
+
+
The four properties in BASE are:
+
+
+
+
Basic Availability (BA), i.e., the database appears to work most of the time.
+
+
+
Soft state (S), i.e., the system’s state can change over time as it becomes eventually consistent.
+
+
+
Eventual consistency (E), i.e., the system will eventually become consistent over time.
+
+
+
+
+
+
CAP confusion
+
+
+
+
Generally, partitionability is seen as a must-have, thus reducing the choice to be between availability and consistency.
+
+
+
This view is somewhat misleading because the choice between C, A, and P is not binary but granular.
+
+
+
The choice between C and A can occur at various granularity levels, and different components (of a larger system) can prioritize different aspects.
+
+
+
Similarly, the CAP theorem generally ignores latency even though it is closely related to partitionability. For example, failing to achieve consistency within a time-bound (i.e., latency) implies a partition.
+
+
+
In general, there is no global notion of partition - some subset of nodes may experience a partition, and others may not.
+
+
+
Once a partition is detected, the system can then choose between C and A.
+
+
+
+
Managing Partitions
+
+
+
+
Three-step process for managing partitions:
+
+
+
+
Detect the start of a partition.
+
+
+
Enter an explicit partition mode that may limit some operations.
+
+
+
+
Possible strategies:
+
+
+
+
Reduce availability by limiting some operations.
+
+
+
Record extra information that can be used during partition recovery.
+
+
+
+
+
The strategy depends on the invariants that the system should maintain.
+
+
+
For example, if the invariant is that the keys (in a table) should be unique, the system could allow duplicate keys for some time and perform a de-duplication step during partition recovery.
+
+
+
A counterexample is a monetary transaction (e.g., charging a credit card). In such cases, the system could disable the operation and record it for performing later. Sometimes this “unavailability” is not visible to the user.
+
+
+
History of operations (over replicas across different partitions) can be tracked using version vectors of the form (node, logical time). The system can easily recreate the order in which they were executed (or mark them as being concurrent).
+
+
+
+
+
Initiate partition recovery when communication is restored and make the state across the partitions consistent.
+
+
+
One common approach is to revert to the state when the partition was detected and apply the operations consistently across all the replicas.
+
+
+
This may require some extra effort to merge conflicts.
+
+
+
One workaround can be to constrain the use of certain operations so that the system does not encounter merge conflicts during recovery.
+
+
+
Sometimes, certain invariants may be violated when the system is in the partition mode and needs to be fixed during recovery.
+
+
+
The key takeaway is that when partitions exist, the choice between availability and consistency is not binary, and both can be optimized for.
+
+
+
+
diff --git a/_site/site/2020/12/14/Cassandra-a-decentralized-structured-storage-system.html b/_site/site/2020/12/14/Cassandra-a-decentralized-structured-storage-system.html
new file mode 100644
index 00000000..3bfd749e
--- /dev/null
+++ b/_site/site/2020/12/14/Cassandra-a-decentralized-structured-storage-system.html
@@ -0,0 +1,101 @@
+
Introduction
+
+
+
Cassandra is a distributed storage system that runs over cheap commodity servers and handles high write throughput while maintaining low latency for read operations.
+
At the time of writing, it was used to support the search for Facebook Inbox.
The key is a string (generally 16-36 bytes long), while the value is a structured object.
+
Every operation under a single row key is atomic per replica.
+
Columns are grouped together into sets called column families.
+
There are two types of columns families:
+
+
Simple families.
+
Super column families: visualized as a column family within a column family.
+
+
+
Columns can be sorted by name or time (used to display results in time sorted order).
+
The API supports insert, get and delete operations.
+
+
+
System Architecture
+
+
Handling Requests
+
+
+
Any read/write request gets routed to any node in the cluster. The node determines the replicas for a given key and routes the request.
+
For write query, the system waits for a quorum of replicas to acknowledge the writes’ completion.
+
For read query, the system either routes the requests to the closest replica (might fetch stale results) or routes the requests to all replicas and waits for a quorum of responses.
+
+
+
Partitioning
+
+
+
Cassandra partitions data across the cluster using consistent hashing with an order-preserving hash function.
+
The hash function’s output range is treated as a fixed circular ring, and each node is assigned a random position on the ring.
+
An incoming request specifies a key used to route requests.
+
One benefit of this approach is that the addition/removal of a node only affects its immediate neighbors.
+
However, randomly assigning nodes leads to non-uniform data and load distribution.
+
Cassandra uses the load information and moves lightly loaded nodes to reduce the load on other nodes.
+
+
+
Replication
+
+
+
Each data item is replicated at N hosts, where N is the per-instance replication factor.
+
Cassandra supports the following replication policies: Rack Unaware, Rack Aware (within a datacenter), and Datacenter Aware.
+
For “Rack Aware” and “Datacenter Aware” strategies, Zookeeper elects a leader among the nodes and holds metadata about which range a node is responsible for.
+
In case of node failure and network partitions, the quorum requirements are relaxed.
+
+
+
Membership
+
+
+
Cluster membership is based on Scuttlebutt, a very efficient anti-entropy Gossip based mechanism.
+
Cassandra uses a modified version of $\phi$ Accrual Failure Detector for detecting failures, which provides the suspicion level (of failure) for each node.
+
+
+
Bootstrapping
+
+
+
A node, starting for the first time, chooses a random position in the ring.
+
This information is persisted on the local disk, on Zookeeper, and gossiped around the cluster (so any node can route any query in the cluster).
+
During bootstrapping, the newly joined node reads a list of contact points (within the cluster) using a configuration file.
+
+
+
Local Persistence
+
+
+
Generally, a write operation involves a write into a commit log (for durability and recoverability), followed by a write into the in-memory data structures.
+
A read operation starts with querying the in-memory data and then looks into the filesystem.
+
Read queries on the filesystem use bloom filters.
+
Column indices are maintained to make it faster to look up relevant columns.
+
+
+
Implementation Details
+
+
+
Components implemented in Java.
+
System control messages use UDP while messages for replication and request routing uses TCP.
+
A new commit log is rolled out after the older one exceeds 128MB of size.
+
All the data is indexed using a primary key.
+
Data on the disk is chunked into sequences of blocks. Each block contains at most 128 keys and is demarcated by a block index.
+
When the data is written to the disk, a block index is generated and maintained in the memory for faster access.
+
A compaction process is performed to merge multiple files (on disk) into one file.
+
+
+
Practical Experience
+
+
+
Data from MySQL servers is added to Cassandra using MapReduce processes.
+
Although Cassandra is a completely decentralized system, adding some coordination (via Zookeeper) is helpful.
+
For Inbox Search, a per-user index is maintained for all the messages.
+
For “term search”, the key is the userid, and the words in the message become the super column.
+
For searching all the messages ever sent/received by a user, the key is the userid, and the recipient ids are the super columns.
+
diff --git a/_site/site/2020/12/21/Design-patterns-for-container-based-distributed-systems.html b/_site/site/2020/12/21/Design-patterns-for-container-based-distributed-systems.html
new file mode 100644
index 00000000..1d569013
--- /dev/null
+++ b/_site/site/2020/12/21/Design-patterns-for-container-based-distributed-systems.html
@@ -0,0 +1,68 @@
+
Introduction
+
+
+
The paper describes three design patterns for container-based distributed systems: single-container pattern, single-node pattern, and multi-node pattern.
Traditionally, containers have exposed three functions: run, pause and stop.
+
A richer API can be implemented to provide fine-grained control to system developers and operators.
+
Similarly, much more application information (including monitoring metrics) can be exposed.
+
The container interface can be used to define a contract for a complex lifecycle. For example, instead of arbitrarily shutting down the container, the system could signal that it will be terminated, giving the container some time to perform some cleanup/follow-up actions.
+
+
+
Single-node, multi-container pattern
+
+
Sidecar pattern
+
+
+
Multiple containers extend and enhance the main container.
+
For example, a web-server serves from the local disk (main container) while a side container updates the data.
+
Benefits:
+
+
independent development, deployment, and scaling of containers
+
possibility of combining different type of containers
+
failure containment boundary, i.e., one failing container, need not bring down the entire system.
+
+
+
+
+
Ambassador pattern
+
+
+
Proxy communication to and from the main container with the ambassador hiding the complexities of communication with a distributed (multi-shard system) that may be written in a different language.
+
+
+
Adapter pattern
+
+
+
Standardize output and interfaces across the containers to provide a simple, homogenized view to external applications.
+
A common example is using a single tool for collecting/processing metrics from multiple applications.
+
This is different from the adapter pattern, which aims to provide a simplified view of the external world to an application.
+
+
+
Multi-node application patterns
+
+
Leader election pattern
+
+
+
In a sharded (or replication-based) system, the system may have to elect a leader (or multiple leaders) among the replicas (or shards).
+
Instead of using a leader election library, a leader election container can be used (that communicates with other containers over, say, HTTP). This removes the restriction of using a leader election library compatible with the containers (e.g., using the same language).
+
+
+
Work queue pattern
+
+
+
A work coordinator container can queue different containers, each of which may have a different implementation or dependencies, thus removing the restriction that all the works use the same runtime.
+
+
+
Scatter/gather pattern
+
+
+
An external client sends a request to a root container.
+
This container fans out the request to many containers that may perform the computation in parallel.
+
The root container gathers these parallel computations’ results and aggregates them into a response to the external client.
+
diff --git a/_site/site/2021/01/04/Compositional-Explanations-of-Neurons.html b/_site/site/2021/01/04/Compositional-Explanations-of-Neurons.html
new file mode 100644
index 00000000..a1a6fb08
--- /dev/null
+++ b/_site/site/2021/01/04/Compositional-Explanations-of-Neurons.html
@@ -0,0 +1,155 @@
+
Introduction
+
+
+
+
The paper describes a method to explain/interpret the representations learned by individual neurons in deep neural networks.
+
+
+
The explanations are generated by searching for logical forms defined by a set of composition operators (like OR, AND, NOT) over primitive concepts (like water).
Given a neural network f, the goal is to explain a neuron’s behavior (of this network) in human-understandable terms.
+
+
+
Previous work builds on the idea that a good explanation is a description that identifies the inputs for which the neuron activates.
+
+
+
Given a set of pre-defined atomic concepts $c \in C$ and a similarity measure $\delta(n, c)$ where $n$ represents the activation of the $n^{th}$ neuron, the explanation, for the $n^{th}$ neuron, is the concept most similar to $n$.
+
+
+
For images, a concept could be represented as an image segmentation map. For example, the water concept can be represented by the segments of the images that show water.
+
+
+
The similarity can be measured by first thresholding the neuron activations (to get a neuron mask) and then computing the IoU score (or Jaccard Similarity) between the neuron mask and the concept.
+
+
+
One limitation of this approach is that the explanations are restricted to pre-defined concepts.
+
+
+
The paper expands the set of candidate concepts by considering the logical forms of the atomics concepts.
+
+
+
In theory, the search space would explode exponentially. In practice, it is restricted to explanations with at most $N$ atomics concepts, and beam search is performed (instead of exhaustive search).
+
+
+
+
Setup
+
+
+
+
Image Classification Setup
+
+
+
+
Neurons from the final 512-unit convolutional layer of a ResNet-18 trained on the Places365 dataset.
Probing the penultimate hidden layer (of the MLP component) for sentence-level explanations.
+
+
+
Concepts are created using the 2000 most common words in the validation split of the SNLI dataset.
+
+
+
Additional concepts are created based on the lexical overlap between premise and hypothesis.
+
+
+
+
+
+
Do neurons learn compositional concepts
+
+
+
+
Image Classification Setup
+
+
+
+
As $N$ increases, the mean IoU increases (i.e., the explanation quality increases) though the returns become diminishing beyond $N=10$.
+
+
+
Manual inspection of 128 neurons and their length 10 explanations show that 69% neurons learned some meaningful combination of concepts, while 31% learned some unrelated concepts.
+
+
+
The meaningful combination of concepts include:
+
+
+
+
perceptual abstraction that is also lexically coherent (e.g., “skyscraper OR lighthouse OR water tower”).
+
+
+
perceptual abstraction that is not lexically coherent (e.g., “cradle OR autobus OR fire escape”).
+
+
+
specialized abstraction of the form L1 AND NOT L2 (e.g. (water OR river) AND NOT blue).
+
+
+
+
+
+
+
NLI Setup
+
+
+
+
As $N$ increases, the mean IoU increases (as in the image classification setup) though the IoU keeps increasing past $N=30$.
+
+
+
Many neurons correspond to lexical features. For example, some neurons are gender-sensitive or activate for verbs like sitting, eating or sleeping. Some neurons are activated when the lexical overlap between premise and hypothesis is high.
+
+
+
+
+
+
Do interpretable neurons contribute to model accuracy?
+
+
+
+
In image classification setup, the more interpretable the neuron is, the more accurate is the model (when the neuron is active).
+
+
+
However, the opposite trend is seen in NLI models. i.e., the more interpretable neurons are less accurate.
+
+
+
Key takeaway - interpretability (as measured by the paper) is not correlated with performance. Given a concept space, the identified behaviors may be correlated or anti-correlated with the model’s performance.
+
+
+
+
Targeting explanations to change model behavior
+
+
+
+
The idea is to construct examples that activate (or inhibit) certain neurons, causing a change in the model’s predictions.
+
+
+
These adversarial examples are referred to as “copy-paste” adversarial examples.
+
+
+
For example, the neuron corresponding to “(water OR river) AND (NOT blue)” is a major contributor for detecting “swimming hole” classes. An adversarial example is created by making the water blue. This prompts the model to predict “grotto” instead of “swimming hole.”
+
+
+
Similarly, in the NLI model, a neuron detects the word “nobody” in the hypothesis as highly indicative of contradiction. An adversarial example can be created by adding the word “nobody” to the hypothesis, prompting the model to predict contradiction while the true label should be neutral.
+
+
+
These observations support the hypothesis that one can use explanations to create adversarial examples.
+
+
diff --git a/_site/site/2021/01/11/GPipe-Easy-Scaling-with-Micro-Batch-Pipeline-Parallelism.html b/_site/site/2021/01/11/GPipe-Easy-Scaling-with-Micro-Batch-Pipeline-Parallelism.html
new file mode 100644
index 00000000..02fc15f4
--- /dev/null
+++ b/_site/site/2021/01/11/GPipe-Easy-Scaling-with-Micro-Batch-Pipeline-Parallelism.html
@@ -0,0 +1,70 @@
+
Introduction
+
+
+
+
The paper introduces GPipe, a pipeline parallelism library for scaling networks that can be expressed as a sequence of layers.
Consider training a deep neural network with L layers using K accelerators (say GPUs).
+
+
+
Each of the ith layer has its forward function fi, backward function bi, weights wi and a cost ci (say the memory footprint or computational time).
+
+
+
GPipe partitions this network into K cells and places the ith cell on the ith accelerator. Output from the ith accelerator is passed to the i+1th accelerator as input.
+
+
+
During the forward pass, the input batch (of size N) is divided into M equal micro-batches. These micro-batches are pipelined through the K accelerators one after another.
+
+
+
During the backward pass, gradients are computed for each micro-batch. The gradients are accumulated and applied at the end of each minibatch.
+
+
+
In batch normalization, the statistics are computed over each micro-batch (used during training) and mini-batch (used during evaluation).
+
+
+
Micro-batching improves over the naive mode parallelism approach by reducing the underutilization of resources (due to the network’s sequential dependencies).
+
+
+
+
Performance Optimization
+
+
+
+
GPipe supports re-materialization (or checkpointing), i.e., during the forward pass, only the output activations (at partition boundaries) are stored.
+
+
+
During backward pass, the forward function is recomputed at each accelerator. This trades off the memory requirement with increased time.
+
+
+
One potential downside is that partitioning can introduce some idle time per accelerator (referred to as the bubble overhead). However, with a sufficiently large number of micro-batches ( more than 4 times the number of partitions), the bubble overhead is negligible.
+
+
+
+
Performance Analysis
+
+
+
+
Two different types of model architectures are compared: AmoebaNet convolutional model and Transformer sequence-to-sequence model.
+
+
+
For AmoebaNet, the size of the largest trainable model (on a single 8GB Cloud TPU v2) increases from 82M to 318M. Further, a 1.8 billion parameter model can be trained on 8 accelerators (25x improvement in size using GPipe).
+
+
+
For transformers, GPipe scales the model size to 83.9 B parameters with 128 partitions (298x improvement in size compared to a single accelerator).
+
+
+
Since the computation is evenly distributed across transformer layers, the training throughput scales almost linearly with the number of devices.
+
+
+
Quantitative experiments on ImageNet and multilingual machine translation show that models can be effectively trained using GPipe.
+
+
diff --git a/_site/site/2021/01/18/Energy-based-Models-for-Continual-Learning.html b/_site/site/2021/01/18/Energy-based-Models-for-Continual-Learning.html
new file mode 100644
index 00000000..3ac8b8ab
--- /dev/null
+++ b/_site/site/2021/01/18/Energy-based-Models-for-Continual-Learning.html
@@ -0,0 +1,134 @@
+
Introduction
+
+
+
+
The paper proposes to use Energy-based Models (EBMs) for Continual Learning.
+
+
+
In classification tasks, the standard approach uses a cross-entropy objective function along with a normalized probability distribution.
+
+
+
However, cross-entropy reduces all negative classes’ likelihood when updating the model for a given sample, potentially leading to catastrophic forgetting.
+
+
+
Classification can be seen as learning an EBM across separate classes.
+
+
+
During an update, the energy for a pair of samples and its ground truth class decreases while the energy corresponding to the pairs of sample and negative classes increases.
+
+
+
Unlike the cross-entropy loss, EBMs allow choosing the negative classes to update.
EBMs can be used for class-incremental learning without requiring a replay-buffer or generative model for replay.
+
+
+
EBMs can be used for continual learning in setups without task boundaries, i.e., setups where the data distribution can change without a clear separation between tasks.
+
+
+
+
EBMs
+
+
+
+
Boltzman distribution is used to define the conditional likelihood of label $y$, given an input $x$. ie, $p(y|x) = \frac{exp(E(x, y))}{Z(x)}$ where $Z(x) = \sum_{y \in Y}(-E(x, y))$. Here $E$ is the learnt energy function that maps an input-label pair to a scalar energy value.
+
+
+
During training, the contrastive divergence loss is used.
+
+
+
During inference, the class, for which the input-class pair has the least energy, is selected as the predicted class.
+
+
+
+
EBMs for Continual Learning
+
+
Selection of Negative Samples
+
+
+
+
The paper considers several strategies for the selection of negative samples:
+
+
+
+
one negative class per sample. The negative class is sampled from the current batch of data. This selection approach performs best.
+
+
+
all the negative classes in a batch are used for creating the negative samples.
+
+
+
all the classes seen so far in training are used as the negative samples. This approach works the worst in practice.
+
+
+
+
+
Given the flexibility of sampling the negative classes, EBMs can be used in the boundary-agnostic setups (where the data distribution can change smoothly without an explicit task boundary).
+
+
+
+
Energy Network
+
+
+
+
EBMs take both the sample and the class as the input. The class can be treated as an attention filter to select the most relevant information between the sample and the class.
+
+
+
In theory, EBMs can train for any number of classes without knowing the number of classes beforehand. This is an advantage over the softmax-based approaches, where adding new classes requires changing the size of the softmax output layer.
+
+
+
+
Inference
+
+
+
During inference, all the classes seen so far are evaluated via the energy function. The class, which corresponds to the least energy sample-class pair, is returned as the selected class.
+
+
+
Experiments
+
+
Datasets
+
+
+
+
Split MNIST
+
+
+
Permuted MNIST
+
+
+
CIFAR-10
+
+
+
CIFAR-100
+
+
+
+
Results in Boundary-Aware Setting
+
+
+
+
The paper outperforms the standard continual learning approaches that neither uses a replay-buffer nor a generative model.
+
+
+
Additionally, the paper shows that for the same number of parameters, the effective capacity of EMB models is higher than the effective capacity of standard classification models.
+
+
+
The paper also shows that standard classification models tend to assign a high probability to new classes for both old and new data. EBMs assign the probability more uniformly (and correctly) across the classes.
+
+
+
In an ablation study, the paper shows that both label conditioning and contrastive divergence loss help in improving the performance of EBMs.
+
+
+
+
Results in Boundary-Agnostic Setting
+
+
+
The performance gains in the boundary-agnostic setting are even more significant than the improvements in the boundary-aware setting.
+
diff --git a/_site/site/2021/01/25/HyperNetworks.html b/_site/site/2021/01/25/HyperNetworks.html
new file mode 100644
index 00000000..e50b0f77
--- /dev/null
+++ b/_site/site/2021/01/25/HyperNetworks.html
@@ -0,0 +1,83 @@
+
Introduction
+
+
+
+
The paper explores HyperNetworks. The idea is to use one network (HyperNetwork) to generate the weights for another network.
Consider a $D$ layer CNN where the parameters for the $j^{th}$ layer are stored in a matrix $K^j$ of the shape $N_{in}f_{size} \times N_{out}f_{size}$.
+
+
+
The HyperNetwork is implemented as a two-layer linear network where the input is a layer embedding $z^j$, and the output is $K^j$.
+
+
+
The first layer (of the HyperNetwork) maps the input to $N_{in}$ different outputs using $N_{in}$ weight matrices.
+
+
+
The second layer maps the different $N_{in}$ inputs to $K_{i}$ using a shared matrix. The resulting $N_{in}$ (number of) $K_{i}$ matrices are concatenated to obtain $K^j$.
+
+
+
As a side note, HyperNetworks have much fewer params than the network for which it produces weights.
+
+
+
In a general case, the kernel dimensions (across layers) are not of the same size but integer multiples of some basic sizes. In that case, the HyperNetwork can generate kernels for the basic size, which can be concatenated to form larger kernels. This would require additional input embeddings but not require a change in the architecture of HyperNetwork.
+
+
+
+
Dynamic HyperNetworks - HyperNetworks for RNNs
+
+
+
+
HyperRNNs/HyperLSTMs denote HyperNetworks that generates weights for RNNs/LSTMs.
+
+
+
HyperRNNs implement a form of relaxed weight sharing - an alternative to the full weight sharing of the traditional RNNs.
+
+
+
At any timestamp $t$, the input to the HyperRNN is the concatenated vector $x_{t}$ (input to the RNN at time $t$) and the hidden state $h_{t-1}$ of the RNN. The output is the weight for the main RNN at timestep $t$.
+
+
+
In practice, a weight scaling vector $d$ is used to reduce the memory footprint, which would otherwise be $dim$ times the memory of a standard RNN. $dim$ is the dimensionality of the embedding vector $z_j$.
+
+
+
+
Experiments
+
+
+
+
HyperNetworks are used to train standard CNNs for MNIST and ResNets for CIFAR 10. In these experiments, HyperNetworks slightly underperform the best performing models but uses much fewer parameters.
+
+
+
HyperLSTMs trained on the Penn Treebank dataset and Hutter Prize Wikipedia dataset outperform the stacked LSTMs and perform similar to layer-norm LSTMs. Interestingly, using HyperLSTMs with layer-norm improves performance over HyperLSTMs.
+
+
+
Given the similar performance of HyperLSTMs and layer-norm LSTMs, the paper conducted an ablation study to understand if HyperLSTMs learned a weight adjustment policy similar to the statistics-based approach used by layer-norm LSTMs.
+
+
+
However, the analysis of the histogram of the hidden states suggests that using layer-norm reduces the saturation effect while in HyperLSTMs, the cell is saturated most of the time. This indicates that the two models are learning different policies.
+
+
+
+
HyperLSTMs are also evaluated for handwriting sequence generation by training in the IAM online handwriting dataset.
+
+
+
While HyperLSTMs are quite effective on this task, combining them with layer-norm degrades the performance.
+
+
+
+
On the WMT’14 En-to-Fr machine translation task, HyperLSTMs outperform LSTM based approaches.
+
+
diff --git a/_site/site/2021/02/01/Zero-shot-Learning-by-Generating-Task-specific-Adapters.html b/_site/site/2021/02/01/Zero-shot-Learning-by-Generating-Task-specific-Adapters.html
new file mode 100644
index 00000000..59cbe826
--- /dev/null
+++ b/_site/site/2021/02/01/Zero-shot-Learning-by-Generating-Task-specific-Adapters.html
@@ -0,0 +1,117 @@
+
Introduction
+
+
+
+
The paper introduces HYPTER - a framework for zero-shot learning (ZSL) in text-to-text transformer models by training a HyperNetwork to generate task-specific adapters from task descriptions.
+
+
+
The focus is on in-task zero-shot learning (e.g., learning to predict an unseen class or relation) and not on cross-task learning (e.g., training on sentiment analysis and evaluating on question-answering task).
Task - a NLP task, like classification or question answering.
+
+
+
Sub-task
+
+
+
+
A class/relation/question within a task.
+
+
+
Denotes by a tuple $(d, D)$ where $d$ is the language description while $D$ represents the subtask’s dataset.
+
+
+
+
+
+
Setup
+
+
+
Develop ZSL approach for transfer to new subtasks within a task, using the task description available for each subtask.
+
+
+
Approach
+
+
+
+
HYPTER has two main parts:
+
+
+
+
Main network
+
+
+
+
A pretrained text-to-text network
+
+
+
Instantiated as a BERT-Base/Large
+
+
+
+
+
HyperNetwork
+
+
+
Generates the weights for adapter networks that will be plugged into the main network.
+
+
+
+
+
+
HyperNetwork has two parts:
+
+
+
+
Encoder
+
+
+
+
Encodes the task description
+
+
+
Instantiated as a RoBERTa-Base model
+
+
+
+
+
Decoder
+
+
+
+
Decodes the encoding into weights for multiple adapters (in parallel)
+
+
+
Instantiated as a Feedforward Network
+
+
+
+
+
+
+
The model trains in two phases:
+
+
+
+
Main network is trained on all the data by concatenating the task description with the input.
+
+
+
Adapters are trained by sampling a task from the train set while keeping the main network frozen.
+
+
+
+
+
+
Experiments
+
+
+
While the idea is very promising and interesting, the evaluation felt quite limited. It uses just two datasets Zero-shot learning from Task Descriptions and Zero-shot Relation Extraction and shows some improvements over the baseline of directly finetuning with task descriptions as the prompt.
+
diff --git a/_site/site/2021/02/08/Continual-learning-with-hypernetworks.html b/_site/site/2021/02/08/Continual-learning-with-hypernetworks.html
new file mode 100644
index 00000000..e16efe1d
--- /dev/null
+++ b/_site/site/2021/02/08/Continual-learning-with-hypernetworks.html
@@ -0,0 +1,120 @@
+
Introduction
+
+
+
+
The paper proposes the use of task-conditioned HyperNetworks for lifelong learning / continual learning setups.
+
+
+
The idea is, the HyperNetwork would only need to remember the task-conditioned weights and not the input-output mapping for all the data points.
$(X^{T}, Y^{T})$ denotes the training datapoints for the $T^{th}$ task.
+
+
+
$\beta_{output}$ is a hyperparameter to control the regularizer’s strength.
+
+
+
$\Theta_{h}^*$ denotes the optimal parameters after training on the $T-1$ tasks.
+
+
+
$\Theta_{h} + \Delta \Theta_{h}$ denotes the one-step update on the current $h$ model.
+
+
+
In practice, the task encoding $e^{t}$ is chunked into smaller vectors, and these vectors are fed as input to the HyperNetwork.
+
+
+
This enables the HyperNetwork to produce weights iteratively, instead of all at once, thus helping to scale to larger models.
+
+
+
The paper also considers the problem of inferring the task embedding from a given input pattern.
+
+
+
Specifically, the paper uses task-dependent uncertainty, where the task embedding with the least predictive uncertainty is chosen as the task embedding for the given unknown task. This approach is referred to as HNET+ENT.
+
+
+
The paper also considers using HyperNetworks to learn the weights for a task-specific generative model. This generative model will be used to generate pseudo samples for rehearsal-based approaches. The paper considers two cases:
+
+
+
+
HNET+R where the replay model (i.e., the generative model) is parameterized using a HyperNetwork.
+
+
+
HNET+TIR, where an auxiliary task inference classifier is used to predict the task identity.
+
+
+
+
+
+
Experiments
+
+
+
+
Three setups are considered
+
+
+
+
CL1 - Task identity is given to the model.
+
+
+
CL2 - Task identity is not given, but task-specific heads are used.
+
+
+
CL3 - Task identity needs to be explicitly inferred.
+
+
+
+
+
On the permuted MNIST task, the proposed approach outperforms baselines like Synaptic Intelligence and Online EWC, and the performance gap is more significant for larger task sequences.
+
+
+
Forward knowledge transfer is observed with the CIFAR datasets.
+
+
+
One potential limitation (which is more of a limitation of HyperNetworks) is that HyperNetworks may be harder to scale for larger models like ResNet50 or transformers, thus limiting their usefulness for lifelong learning use cases.
+
+
diff --git a/_site/site/2021/02/15/When-Do-Curricula-Work.html b/_site/site/2021/02/15/When-Do-Curricula-Work.html
new file mode 100644
index 00000000..485b58c1
--- /dev/null
+++ b/_site/site/2021/02/15/When-Do-Curricula-Work.html
@@ -0,0 +1,114 @@
+
Introduction
+
+
+
+
The paper systematically investigates when does curriculum learning help.
Implicit curricula refers to the order in which a network learns data points when trained using stochastic gradient descent, with iid sampling of data.
+
+
+
When training, let us say that the model makes a correct prediction for a given datapoint in the $i^{th}$ epoch (and correct prediction in all the subsequent epochs). The $i^{th}$ epoch is referred to as the learned iteration of the datapoint (iteration in which the datapoint was learned).
+
+
+
The paper studied multiple models (VGG, ResNet, WideResNet, DenseNet, and EfficientNet) with different optimizers (Adam and SGD with momentum).
+
+
+
The resulting implicit curricula are broadly consistent within the model families, making the following discussion less dependent on the model architecture.
+
+
+
+
Explicit Curricula
+
+
+
When defining an explicit curriculum, three important components stand out.
+
+
+
Scoring Function
+
+
+
+
Maps a data point to a numerical score of difficulty.
+
+
+
Choices:
+
+
+
+
Loss function for a model
+
+
+
learned iteration
+
+
+
Estimated c-score - It captures a given model’s consistency to correctly predict a given datapoint’s label when trained on an iid dataset (not containing the datapoint).
+
+
+
+
+
The three scoring functions are computed for two models on the CIFAR dataset.
+
+
+
The resulting six scores have a high Spearman Rank correlation. Hence for the rest of the discussion, only the c-score is used.
+
+
+
+
Pacing Function
+
+
+
+
This function, denoted by $g(t)$, controls the size of the training dataset at step $t$.
+
+
+
At step $t$, the model would be trained on the first $g(t)$ examples (as per the ordering).
+
+
+
Choices: logarithmic, exponential, step, linear, quadratic, and root.
+
+
+
+
Order
+
+
+
+
Order in which the data points are picked:
+
+
+
+
Curriculum - Ordering points from lowest score to highest and training on the easiest data points first.
+
+
+
Anti Curriculum - Ordering points from highest score to lowest and training on the hardest data points first.
+
+
+
Random - Randomly selecting the data points to train on.
+
+
+
+
+
+
Observations
+
+
+
+
The paper performed a hyperparameter sweep over 180 pacing functions and three orderings for three random seeds over the CIFAR10 and CIFAR100 datasets. For both the datasets, the best performance is obtained with random ordering, indicating that curricula did not give any benefits.
+
+
+
However, the curriculum is useful when the number of training iterations is small.
+
+
+
It also helps with noisy data training (which is simulated by randomly permuting the labels).
+
+
+
The observations for the smaller CIFAR10/100 dataset generalize to slightly larger datasets like FOOD101 and FOOD101N.
+
+
+
diff --git a/_site/site/2021/02/22/Anatomy-of-Catastrophic-Forgetting-Hidden-Representations-and-Task-Semantics.html b/_site/site/2021/02/22/Anatomy-of-Catastrophic-Forgetting-Hidden-Representations-and-Task-Semantics.html
new file mode 100644
index 00000000..7beb2a80
--- /dev/null
+++ b/_site/site/2021/02/22/Anatomy-of-Catastrophic-Forgetting-Hidden-Representations-and-Task-Semantics.html
@@ -0,0 +1,182 @@
+
Introduction
+
+
+
+
The paper studies the effect of catastrophic forgetting on representations in neural networks.
CIFAR-10 dataset is split into m (=2) tasks, where each task is a n way classification task.
+
+
+
The underlying network has a shared trunk with m heads, one head per task.
+
+
+
+
+
Split CIFAR-100 Distribution Shift
+
+
+
Each task requires distinguishing between n CIFAR-100 superclasses with training/test data corresponding to a subset of constituent classes.
+
+
+
+
+
+
Network Architecture
+
+
+
VGG, ResNet and DenseNet
+
+
+
+
+
Questions
+
+
+
+
Are all representations (throughout the network) equally responsible for forgetting?
+
+
+
+
Higher layer (layers closer to the output) are the primary source of catastrophic forgetting.
+
+
+
Central Kernel Alignment (CKA) technique is used to compare the similarity between the layer representations, before and after training on the second task.
+
+
+
Higher layer representations change significantly when training over two tasks while the lower layer representations remain stable.
+
+
+
When finetuning on the second task, freezing the lower layers has only a minor effect on the accuracy of the second task.
+
+
+
In layer reset experiments, after training on the second task, the weights of some of the layers are reset to their values after training on the first task.
+
+
+
Resetting the weights of higher layers leads to significant improvement in the performance on the first task.
+
+
+
+
+
+
Do common approaches for countering catastrophic forgetting work by stabilizing the higher layers?
+
+
+
+
Yes - both EWC and replay-based approaches counter catastrophic forgetting work by stabilizing the higher layers.
+
+
+
This is demonstrated by showing that as the quadratic penalty for EWC (or fraction of data from replay buffer) increases (to reduce catastrophic forgetting), the representations for higher layers change less during the second task.
+
+
+
+
+
When training over a sequence of tasks, are similar tasks more likely to be forgotten than different tasks?
+
+
+
+
Setup I
+
+
+
+
Training over a sequence of two binary classification tasks.
+
+
+
Task 1: Two related classes (say ship and truck)
+
+
+
Task 2: Two related classes, which may or may not be related to the classes for Task 1. For example, the classes could be
+
+
+
+
cat and horse (not related to classes of the first task)
+
+
+
plane and car (related to the classes of the first task)
+
+
+
+
+
Training over semantically similar tasks (here plane and car) leads to less forgetting.
+
+
+
+
+
Setup II
+
+
+
+
Training over a sequence of two classification tasks.
+
+
+
Task 1: Four classes where the classes can be grouped into two groups (say deer, dog, ship and truck)
+
+
+
Task 2: Two related classes, which may be related to group 1 or group 2. For example, the classes could be two animals or two objects.
+
+
+
After training on the second task, classes (from Task 1), which are in the different group as classes from Task 2, are forgotten less.
+
+
+
+
+
Conclusion
+
+
+
+
Task representational similarity is a function of both underlying data and optimization procedure.
+
+
+
Forgetting is most severe for task representations of intermediate similarity.
+
+
+
Representational similarity is necessary but not a sufficient condition for forgetting.
+
+
+
+
+
+
+
How does catastrophic forgetting change as the task similarity changes?
+
+
+
+
If the model learns different representations for dissimilar tasks, increasing dissimilarity can help to avoid forgetting.
+
+
+
When training the two-task, two-class (per task) CIFAR-10 setup with an “others” class (classes not already used in the setup), the forgetting is reduced.
+
+
+
+
diff --git a/_site/site/2021/03/01/Ad-Click-Prediction-a-View-from-the-Trenches.html b/_site/site/2021/03/01/Ad-Click-Prediction-a-View-from-the-Trenches.html
new file mode 100644
index 00000000..612ae485
--- /dev/null
+++ b/_site/site/2021/03/01/Ad-Click-Prediction-a-View-from-the-Trenches.html
@@ -0,0 +1,144 @@
+
Introduction
+
+
+
+
The paper presents case studies from the experience of deploying an ad click-through rate (CTR) prediction model at Google.
+
+
+
The paper focuses on themes related to memory footprint, performance analysis, calibration, confidence in the predictions, and feature engineering.
Features (corresponding to a given ad) include search query and the metadata in the ad. The features are very sparse.
+
+
+
Single layer, regularized Logistic Regression model is trained with Online Gradient Descent (same as Stochastic Gradient Descent, but in the online setting).
+
+
+
From a memory perspective, it is important to minimize the size of the final model.
+
+
+
Adding just the L1 penalty is not sufficient to produce weights that are precisely equal to 0.
Using per-coordinate learning rates improves the performance at the cost of memory as both the sum of gradients and the sum of the square of gradients are tracked for each feature.
+
+
+
+
In practice, some of the cost can be alleviated by approximating that all the events containing a given feature have the same probability.
+
+
+
In such a case, the sum of the square of gradients can be approximated using the counts of positive and negative events alone.
+
+
+
+
+
Some memory overhead can be reduced based on the following observation: the vast majority of features are extremely rare. Hence, it is not necessary to track the statistics for such rare features.
+
+
+
+
However, in an online setting, it is not known upfront as to which features will be sparse.
+
+
+
The paper proposes to use probabilistic feature inclusion - a feature is added to the model with probability $p$. Once it is added, the feature is not removed.
+
+
+
An alternative approach is to use a rolling set of counting Bloom filters to check if a feature has appeared at least $n$ times in training. Bloom filters are probabilistic data structures and can return false positives.
+
+
+
+
+
Memory can also be saved by using fewer bits for encoding weights.
+
+
+
+
Most of the weight coefficients lie in the range $(-2, 2)$, and a $16-$ bit encoding is used in place of $32$ or $64$ bit encoding.
+
+
+
This quantization approach needs to account for roundoff problems. The fix is easy to implement.
+
+
+
+
+
When training many models with similar hyperparameters, per-model learning rate counters can be replaced by statistics shared by all the models, thus reducing memory footprint.
+
+
+
A Single Value Structure is used to reduce the memory footprint when evaluating a very large set of model variants that differ only in addition/removal of a small subset of features.
+
+
+
+
All the models, that use a feature, share a single value structure corresponding to the feature. This reduces the memory overhead by order of magnitude.
+
+
+
During the update, each model computes the weight updates corresponding to all the features that it is using. The updated weight is averaged across all the models and used to update the single value structure.
+
+
+
+
+
Since CTR datasets are generally highly imbalanced, the training data (for the negative class) can be subsampled to reduce the amount of data to train over. The loss component (corresponding to negative class) can be appropriately scaled up.
Online loss is computed on the new training data (new incoming traffic) before training on it.
+
+
+
+
+
The confidence in the model’s prediction is estimated using a heuristic called uncertainty score. It can be measured using the dot product of the feature and the vector of learning rates.
+
+
+
+
The idea is that the learning rates already maintain a notion of uncertainty.
+
+
+
Features for which the learning rate is high are the features for which uncertainty is also high.
+
+
+
+
+
Calibrating Predictions
+
+
+
+
The calibration can be improved by applying correction functions $\tau_d(p)$ where $p$ is the predicted CTR, and $d$ is an element of a partition of the training data.
+
+
+
$\tau$ can be modeled as $\gamma^{\kappa}$ where $\gamma$ and $\kappa$ are learned using Poisson regression.
+
+
+
+
+
Unsuccessful Experiments
+
+
+
+
Aggressive feature hashing was tried to reduce the memory overhead. However, it leads to a significant loss in performance.
+
+
+
Using dropout did not help, probably because the features are sparse.
+
+
+
Using feature bagging hurt the AucLoss.
+
+
+
Feature vector normalization did not improve performance, probably because of per-coordinate learning rates and regularization.
+
+
+
+
diff --git a/_site/site/2021/03/08/Practical-Lessons-from-Predicting-Clicks-on-Ads-at-Facebook.html b/_site/site/2021/03/08/Practical-Lessons-from-Predicting-Clicks-on-Ads-at-Facebook.html
new file mode 100644
index 00000000..0b8c6193
--- /dev/null
+++ b/_site/site/2021/03/08/Practical-Lessons-from-Predicting-Clicks-on-Ads-at-Facebook.html
@@ -0,0 +1,180 @@
+
Introduction
+
+
+
+
The paper describes several design choices for developing a model for predicting user response (clicks) on ads.
Defined as the predictive log-loss per impression, divided by the entropy of the background CTR (click-through rate).
+
+
+
Background CTR is the average empirical CTR of the training data.
+
+
+
Lower normalized cross-entropy is better.
+
+
+
The normalization term is important to make the metric insensitive to the background CTR. Otherwise, the log loss can easily be made low when background CTR is close to 0 or 1.
+
+
+
NE can also be written as $RIG - 1$, where $RIG$ is the Relative Information Gain.
+
+
+
+
+
Calibration
+
+
+
Ratio of average estimated CTR and empirical CTR.
+
+
+
+
Area-Under-ROC (AUC) is a good metric for measuring ranking quality (among ads). However, it is not used as a metric to avoid over-delivery or under-delivery of ads.
+
+
+
+
+
+
Implementation Details
+
+
+
+
Feature Transformation
+
+
+
+
A given add impression, $e$, is transformed into a $n-$dimensional vector, $x$, where the $i^{th}$ index denotes the value of the $i^{th}$ categorical feature.
+
+
+
Continous features are binned, and the bin index is used as a categorical feature, thus applying a non-linear transformation to the features.
+
+
+
Categorical features that are tuple-like (i.e., have a tuple of values) can be converted into new categorical features by taking a cartesian product.
+
+
+
Boosted decision trees can be used to implement the previous two transformations in one go.
+
+
+
+
Each tree is used as a categorical feature that takes the value of the index of the leaf node than an ad maps to.
+
+
+
The paper used the Gradient Boosting Machine with the $L_2-$TreeBoost algorithm.
+
+
+
Using the tree feature transformation improves the Normalized Cross-Entropy by $3.4\%$.
+
+
+
+
+
+
+
Model
+
+
+
+
Logistic Regression (LR) or Bayesian online learning scheme for probit regression (BOPR) algorithms are used for training a linear classifier model.
+
+
+
While both LR and BOPR models provide similar performance, the LR model is half the BOPR model’s size and faster for performing training/inference.
+
+
+
+
+
+
Role of Data Freshness
+
+
+
+
When a model is trained on the data from a particular day and evaluated on data from the subsequent days, the model’s performance degrades as the delay between training and test set increases.
+
+
+
This highlights the importance of the freshness of the training data.
+
+
+
One straightforward approach can be to train the model every day.
+
+
+
Alternatively, the linear classifier can be trained using online learning, while the boosted decision tree can still be trained daily.
+
+
+
Different choices for setting the learning rate (for online training of linear classifier) are compared, and the per-coordinate learning rate is found to perform best in practice.
+
+
+
+
Generating Real-Time Training Data
+
+
+
+
An “online joiner” system is used to generate real-time training data for the linear classifier.
+
+
+
The challenging part is, while there are data points with a “positive” label (i.e., the user clicked on the ad), there are no datapoints with a “negative” label (since there is no “no-click” button that the user can click).
+
+
+
An impression is considered to have the “no-click” label if the user does not click on the ad within a (long) time window of seeing the ad.
+
+
+
Too short a time window could mislabel some impressions, while too long a time window will delay the real-time training data.
+
+
+
The online joiner performs a distributed stream-to-stream join on the stream of ad impressions and stream of ad clicks using a HashQueue.
+
+
+
A HashQueue:
+
+
+
+
comprises of a First-In-First-Out queue as a buffer window and a hash map for fast random access to label impressions.
+
+
+
supports three operations on key-value pairs: enqueue, dequeue, and lookup.
+
+
+
+
+
+
Memory and Latency
+
+
+
+
Increasing the number of boosting trees shows diminishing returns, and most of the improvements come from the first 500 trees.
+
+
+
Top 10 features account for half of the total feature importance, while the last 300 features add less than 1% feature importance.
+
+
+
Features in the boosting model can be broadly classified as contextual or historical.
+
+
+
Historical feature provides much more explanatory power than the contextual features through contextual features are helpful to handle the cold start problem.
+
+
+
Models trained with just the contextual features rely more heavily on data freshness than models trained with just the historical features.
+
+
+
Uniform subsampling and negative downsampling techniques are used to limit the amount of training data.
+
+
+
In the case of negative downsampling, the model needs to be re-calibrated as well.
+
+
diff --git a/_site/site/2021/03/15/The-Tail-at-Scale.html b/_site/site/2021/03/15/The-Tail-at-Scale.html
new file mode 100644
index 00000000..b62dd5f1
--- /dev/null
+++ b/_site/site/2021/03/15/The-Tail-at-Scale.html
@@ -0,0 +1,184 @@
+
Introduction
+
+
+
+
The paper presents some causes for (temporary) high-latency episodes in large-scale online systems and techniques to mitigate their impact so that the tail of latency distribution remains short.
Shared resources between processes on the same node
+
+
+
Background processes (daemons) could use cause a momentary spike in resource usage.
+
+
+
Processes running on different nodes may contend for global resources like shared file systems.
+
+
+
Maintenance activities like disk compaction or garbage collection.
+
+
+
Others like queueing, power limits, or energy management.
+
+
+
In the case of large-scale systems, the component-level variability is further amplified.
+
+
+
+
Reducing Component Variability
+
+
+
+
Use differentiated service classes to prioritize user requests over non-interactive requests.
+
+
+
Reduce head-of-line blocking by breaking long-running requests into smaller requests.
+
+
+
Synchronize maintenance jobs across nodes to minimize the window for high latency.
+
+
+
Caching generally does not help to address tail latency.
+
+
+
+
Adapting to Latency Variability
+
+
+
+
Two categories of adaptation approaches
+
+
+
+
Within Request Short-Term Adaptations
+
+
+
+
These approaches are more relevant for services that perform many read queries on loosely consistent datasets.
+
+
+
Hedged Request
+
+
+
+
Send the request to multiple replicas, and once one of the replicas returns the result, cancel the other requests.
+
+
+
In practice, start by sending the request to only one replica. Send the secondary requests if the first request is outstanding for more than $95^{th}$ percentile of expected latency.
+
+
+
This introduces an additional $5\%$ load while substantially shortening the latency tail.
+
+
+
This approach work because often, the cause of latency is not the query itself but other factors like overloaded nodes.
+
+
+
+
+
Tied Request
+
+
+
+
Hedged request approach makes a tradeoff regarding how long to wait before initiating requests to other replicas. The sooner the request is made, the lower should be the latency in serving the request, but more will be the overall load in the system.
+
+
+
The load in the system can be reduced by “tieing” requests (sent to different replicas) so that as soon as one replica starts processing the request, it can notify the other replicas, which could drop the request or deprioritize it.
+
+
+
In practice, “tieing” requests means that each replica has the identity of other replicas which may execute the request.
+
+
+
Note that there is a short window (of the average network message delay) when multiple replicas could start executing the request. This can be mitigated if the client (issuing the requests) introduces a delay to twice the average network message delay.
+
+
+
+
+
Submit the request to the least loaded replica
+
+
+
This is less effective for reasons like the load on a replica can change after the request is made but before it is executed.
+
+
+
+
+
+
Cross-Request Long-Term Adaptations
+
+
+
+
These approaches are more relevant for situations where different services have different throughput.
+
+
+
Micro-partitions
+
+
+
+
Generate more paritions than the number of nodes.
+
+
+
The partitions can be dynamically assigned to machines to ensure proper load balancing.
+
+
+
In case of machine failure, many nodes can be used to quickly re-create the micro-partitions instead of waiting on one machine to read one single large partition.
+
+
+
+
+
Selective Replication
+
+
+
With micro-partitioning, replicas for micro-partitions can be created ahead of time to achieve good load balancing.
+
+
+
+
Latency induced probation
+
+
+
In some cases, removing a slow node can improve the overall latency of the system. The probated node can be re-incorporated when its latency improves.
+
+
+
+
+
+
+
+
Large Information Retrieval Systems
+
+
+
+
In such systems, speed can be more critical than the quality of the result.
+
+
+
The system should return a “good enough” result that is available with low latency instead of waiting for the “best result” that is available with high latency.
+
+
+
In some cases, a request could trigger an unexpected code path or cause some other exception that could slow down the entire system.
+
+
+
In such cases, the canary request technique can be used where the system sends the request initially to only 1 or 2 nodes. The request is sent over to the other nodes only after receiving a successful response from the initial nodes.
+
+
+
+
+
Requests that update state are easier to handle for several reasons:
+
+
+
+
The scale of latency-critical modifications is generally small.
+
+
+
The update can be performed asynchronously after responding to the user.
+
+
+
Quorum-based approaches (often used for ensuring consistent updates) are inherently tail-tolerant.
+
+
+
+
diff --git a/_site/site/2021/03/22/Deep-Neural-Networks-for-YouTube-Recommendations.html b/_site/site/2021/03/22/Deep-Neural-Networks-for-YouTube-Recommendations.html
new file mode 100644
index 00000000..dfc9122d
--- /dev/null
+++ b/_site/site/2021/03/22/Deep-Neural-Networks-for-YouTube-Recommendations.html
@@ -0,0 +1,151 @@
+
Introduction
+
+
+
+
The paper describes YouTube’s deep learning-based recommendation system.
Freshness - Very large number of videos uploaded every hour. The recommendation system should take these new videos into account as well.
+
+
+
Noise - User satisfaction needs to be modeled from noisy implicit feedback signal as the explicit signal is very sparse.
+
+
+
+
System Overview
+
+
+
+
Two neural networks: one for candidate generation and another one for ranking.
+
+
+
Metrics
+
+
+
+
Offline metrics like precision, recall, ranking loss
+
+
+
A/B testing via live experiments
+
+
+
+
+
+
Candidate Generation
+
+
+
+
Input: events from a user’s YouTube activity history.
+
+
+
Output: small subset (hundreds) of videos.
+
+
+
Approach:
+
+
+
+
Recommendation is modeled as extreme multiclass classification.
+
+
+
Predict the video (from a corpus) that a user will watch at a given time.
+
+
+
The neural network’s task is to learn useful user embeddings, given the user’s context and history.
+
+
+
For each positive class (relevant video), negative classes (non-relevant videos) are sampled from the video corpus.
+
+
+
+
+
Model Architecture
+
+
+
+
A feedforward network with input as user embeddings and context embeddings (watch history).
+
+
+
Watch history is a variable-length sequence of video ids, where each video id is mapped to an embedding.
+
+
+
The sequence of video ids is mapped to a sequence of embeddings, and this sequence is averaged to obtain fixed-sized embedding.
+
+
+
Additional signals like demographic features and search query embeddings can be added along with the context embeddings.
+
+
+
The age of a video is also used as a feature during training to account for the freshness of the content. This feature is set to zero (or slightly negative) during inference.
+
+
+
+
+
Other Insights
+
+
+
+
Training examples are generated from all YouTube watches, including the watches from the videos embedded on other sites, to surface new content.
+
+
+
Generating the same number of training examples per user is important to avoid a small set of active users from dominating the model training.
+
+
+
Predicting a user’s next watch leads to better results than predicting a randomly held-out watch. This can be attributed to the general consumption pattern of videos (e.g., episodes are usually watched in order).
+
+
+
+
+
+
Ranking
+
+
+
+
Input: list of candidate videos to rank from.
+
+
+
Output: score for each video.
+
+
+
Approach
+
+
+
A feedforward network (similar to candidate generation model) trained using logistic regression loss.
+
+
+
+
Feature representation
+
+
+
+
Different types of features: categorical vs. continuous, univalent vs. multivalent, describes video vs. describes user or context.
+
+
+
Important signals include user’s interaction with the video (or similar videos), which source/channel added the video to the candidate set.
+
+
+
Embeddings are shared across features. For example, the representation for a video id remains the same, irrespective of whether it is being used for representing the “video to recommend” or the “last seen video.”
+
+
+
Feature normalization and transformations like exponents (square or square root) for continuous variables improve the performance.
+
+
+
+
+
To model the expected watch time, the logistic regression loss is weighted by the observed watch time. For example, if a video was watched, its weight is given by the observed watch time, and if the video was not watched, its weight is set to 1.
+
+
+
In practice, this means that the logistic regression model learns odds that approximate the expected watch time of the video.
+
+
diff --git a/_site/site/2021/03/29/Synthesized-Policies-for-Transfer-and-Adaptation-across-Tasks-and-Environments.html b/_site/site/2021/03/29/Synthesized-Policies-for-Transfer-and-Adaptation-across-Tasks-and-Environments.html
new file mode 100644
index 00000000..1289dc54
--- /dev/null
+++ b/_site/site/2021/03/29/Synthesized-Policies-for-Transfer-and-Adaptation-across-Tasks-and-Environments.html
@@ -0,0 +1,192 @@
+
Introduction
+
+
+
+
The paper studies transfer learning in RL, focusing on simultaneous transfer across both tasks and environments.
+
+
+
The key idea is to learn task and environment embeddings and compose them using a meta-rule, and the proposed approach is called SYNPO (Synthesized Policies).
S1: Transfer to a new (environment, task) pair when the agent has been trained on the environment and the task before (but not simultaneously).
+
+
+
S2: Transfer to a new (environment, task) pair where either the environment or the task is not seen previously.
+
+
+
S3: Transfer to a new (environment, task) pair where neither the environment nor the task is seen previously.
+
+
+
+
+
In the second and third settings, the agent is allowed to collect some data in the new environment or task.
+
+
+
The (environment, task) combinations that the agent has seen during training are referred to as seen combinations, while the remaining combinations are referred to as the unseen combinations.
+
+
+
The key idea is to:
+
+
+
+
learn embeddings of environments and tasks
+
+
+
use these embeddings to compose a policy (parameterized as the linear combination of the policy basis).
+
+
+
+
+
A disentanglement objective is used to decouple the task and environment embedding.
+
+
+
+
Policy Composition
+
+
+
+
Given an (environment, task) pair $z = (\epsilon, \tau)$, the policy is given as $\pi_z(a|s) \propto exp(\psi_s^TU(e_{\epsilon}, e_{\tau})\phi_{a} + b_{\pi} )) $.
+
+
+
Here $b_{\pi}$ is a scalar bias, $\psi_{s}$ and $\phi_{a}$ are state and action representations, $U$ is parameterized as the linear comination of $K$ basis matrices $\Theta_k$
Multi-task Learning where the distinction between the environments is ignored.
+
+
+
+
Results
+
+
+
+
GRIDWORLD
+
+
+
+
In the first setting (S1)
+
+
+
+
SYNPO outperforms all the baselines.
+
+
+
As the agent is trained on more (environment, task) combinations, its performance on the unseen combinations improves. This trend saturates when the seem/total ratio reaches about 0.4 (i.e., training on 40% of all the combinations).
+
+
+
Task disentanglement is more important than environment disentanglement.
+
+
+
+
+
In the second and third setting (S2 and S3)
+
+
+
+
The agent uses one demonstration from each test pair to finetune the embeddings.
+
+
+
S2 is an easier setting than S3.
+
+
+
Transfer learning across tasks is easier than transfer learning across environments.
+
+
+
+
+
+
+
THOR
+
+
+
SYNPO outperforms all the baselines on both seen and unseen combinations.
+
+
+
+
diff --git a/_site/site/2023/02/10/Toolformer-Language-Models-Can-Teach-Themselves-to-Use-Tools.html b/_site/site/2023/02/10/Toolformer-Language-Models-Can-Teach-Themselves-to-Use-Tools.html
new file mode 100644
index 00000000..ca331af6
--- /dev/null
+++ b/_site/site/2023/02/10/Toolformer-Language-Models-Can-Teach-Themselves-to-Use-Tools.html
@@ -0,0 +1,220 @@
+
Introduction
+
+
+
+
The paper presents Toolformer, a language model that uses simple APIs to use external tools (calculator, QA system, search engine, translation system, and calendar).
Starting with a language model, M, the goal is to enable the language model to use tools by invoking API calls.
+
+
+
An API call is denoted by the tuple $c =$ (api_name, api_input). It can be linearized as $e(c) =$ [api_name(api_input)$]$ or as $e(c, r) = [$api_name(api_input) $ -> r]$ where $r$ denotes the result of the API.
+
+
+
The given dataset of plain text, $C$, is converted into a dataset $C*$ augmented with the API calls using a three-step process.
+
+
+
In the first step, a position ($i$) and API call candidates (for the position $i$) are sampled.
+
+
+
+
Positions are sampled by (i) computing the probability that M assigns to starting an API call for each position and (ii) retaining the top-$k$ positions with a probability greater than a threshold value.
+
+
+
For each of the sampled positions (say $i$), API calls are sampled by concatenating a prompt to the tokens till index $i$ and sampling from the model M. Examples that do not generate the “end of the API” token (i.e.,”]”) are discarded.
+
+
+
+
+
In the second step, the API calls are executed to obtain response $r$ (text sequence).
+
+
+
API calls are filtered using the following criteria: if providing M with both the input and the output of the API makes it easier for M to predict the future token, compared to not using the API call at all or just using the input to the API, then the API call is helpful for M, and the example should be retained.
+
+
+
+
In the last step, the remaining API calls are merged to obtain the augmented dataset $C*$ that is used for finetuning M.
+
+
+
Note that $C*$ contains $C$, so M is finetuned on the original dataset and examples where a tool is helpful.
+
+
+
During inference, the model is used for decoding in the usual way. Decoding is stopped when it produces the “->” token, and the corresponding API is used to generate the response. The decoding process (using the model) resumes with the API output appended to the decoded text.
+
+
+
+
Tools
+
+
+
+
There are two constraints on the tools: (i) their input and output should be expressible as text, and (ii) few demonstrations can be obtained from the tools. The second constraint means that the tool should be useable or accessible.
+
+
+
The paper considered the following tools: a question-answering system, a Wikipedia search engine, a calculator, a calendar, and a machine translation system. Of these, only the calculator and calendar are non-neural network tools.
+
+
+
+
Experiments
+
+
+
+
Subset of CCNet is used as the language modeling dataset.
+
+
+
GPT-J is used as the language model.
+
+
+
For finetuning, the batch size is 128, the learning rate is 1e-5, and a linear warmup for the first 10% of training is used.
+
+
+
Following models are compared:
+
+
+
+
GPT-J: Regular GPT-J model without any finetuning.
+
+
+
GPT-J + CC: GPT-J finetuned on $C$ without any API calls.
+
+
+
Toolformer, i.e. GPT-J finetuned on $C*$.
+
+
+
Toolformer with API calls disabled during training.
+
+
+
OPT 66B
+
+
+
GPT-3
+
+
+
+
+
The models are evaluated in the prompted zero-shot setup, where models are instructed to solve a task without any in-context examples.
+
+
+
One difference from the standard greedy decoding is that the API call is used whenever it is one of the top-10 most likely next tokens. This is done to increase the use of API calls.
+
+
+
Evaluation Tasks
+
+
+
+
SQuAD, GoogleRE, and T-REx subsets of the LAMA benchmark where the model has to complete a short statement with a missing fact.
+
+
+
+
Since LAMA questions are based on Wikipedia, Toolformer isn’t allowed to use Wikipedia search.
+
+
+
The evaluation criteria is to check if the correct word is among the first five words predicted by the model.
+
+
+
Toolformer uses the question-answering tool for most cases, outperforming all the baselines.
+
+
+
+
+
Math Dataset
+
+
+
+
eSDiv, SVAMP, and MAWPS benchmarks.
+
+
+
The first number predicted by the model is considered to be the output.
+
+
+
Toolformer uses the calculator tool for most cases, thereby outperforming all the baselines.
+
+
+
+
+
Question Answering
+
+
+
+
Web Questions, Natural Questions, and TriviaQA datasets.
+
+
+
The evaluation criteria is to check if the correct word is among the first 20 words predicted by the model.
+
+
+
Question Answering tool is disabled for this setup.
+
+
+
Toolformer uses the Wikipedia tool for most cases, thereby outperforming all the baselines other than the much larger GPT-3 model.
+
+
+
+
+
Multilingual Question Answering
+
+
+
+
MLQA benchmark.
+
+
+
The evaluation criteria is to check if the correct word is among the first ten words predicted by the model.
+
+
+
Toolformer uses the translation tool for most of the questions, with questions in Hindi being an exception.
+
+
+
However, Toolformer does not consistently outperform the GPT-J baseline, likely because, for some languages, finetuning on CCNet could hurt performance.
+
+
+
+
+
Temporal Datasets
+
+
+
+
TEMPLAMA (cloze style queries where the answer changes with time) and DATESET (dataset generated through a series of templates and populated with random dates/durations).
+
+
+
While Toolformer outperforms the baselines for both datasets, it relies on the Wikipedia search and Question Answering tools (and not the calendar tool) for the LAMA dataset. On the DATESET dataset, it uses the calendar tool in the majority.
+
+
+
+
+
Language Modeling
+
+
+
+
WikiText and a subset of 10,000 randomly selected documents from CCNet (not used during training of M).
+
+
+
Training on $C*$ does not increase perplexity (compared to training on C). In this experiment, the API calls are disabled during inference.
+
+
+
+
+
+
+
Varying the size of the underlying models show that the ability to use tools emerges only around 755M parameters.
+
+
+
+
Future Work
+
+
+
+
Extending Toolformer to chain the use of tools and use tools interactively.
+
+
+
In some cases, the use of tools is very sample-inefficient.
+
+
+
Decision to use a tool does not account for the cost of using the tool.
+
+
diff --git a/_site/site/LICENSE.md b/_site/site/LICENSE.md
new file mode 100755
index 00000000..af1b0ec7
--- /dev/null
+++ b/_site/site/LICENSE.md
@@ -0,0 +1,9 @@
+# Released under MIT License
+
+Copyright (c) 2014 Mark Otto.
+
+Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
\ No newline at end of file
diff --git a/_site/site/README.md b/_site/site/README.md
new file mode 100755
index 00000000..b6c7d402
--- /dev/null
+++ b/_site/site/README.md
@@ -0,0 +1,134 @@
+# Lanyon
+
+Lanyon is an unassuming [Jekyll](http://jekyllrb.com) theme that places content first by tucking away navigation in a hidden drawer. It's based on [Poole](http://getpoole.com), the Jekyll butler.
+
+
+
+
+
+## Contents
+
+- [Usage](#usage)
+- [Options](#options)
+ - [Sidebar menu](#sidebar-menu)
+ - [Themes](#themes)
+ - [Reverse layout](#reverse-layout)
+- [Development](#development)
+- [Author](#author)
+- [License](#license)
+
+
+## Usage
+
+Lanyon is a theme built on top of [Poole](https://github.com/poole/poole), which provides a fully furnished Jekyll setup—just download and start the Jekyll server. See [the Poole usage guidelines](https://github.com/poole/poole#usage) for how to install and use Jekyll.
+
+
+## Options
+
+Lanyon includes some customizable options, typically applied via classes on the `` element.
+
+
+### Sidebar menu
+
+Create a list of nav links in the sidebar by assigning each Jekyll page the correct layout in the page's [front-matter](http://jekyllrb.com/docs/frontmatter/).
+
+```
+---
+layout: page
+title: About
+---
+```
+
+**Why require a specific layout?** Jekyll will return *all* pages, including the `atom.xml`, and with an alphabetical sort order. To ensure the first link is *Home*, we exclude the `index.html` page from this list by specifying the `page` layout.
+
+
+### Themes
+
+Lanyon ships with eight optional themes based on the [base16 color scheme](https://github.com/chriskempson/base16). Apply a theme to change the color scheme (mostly applies to sidebar and links).
+
+
+
+
+There are eight themes available at this time.
+
+
+
+To use a theme, add any one of the available theme classes to the `` element in the `default.html` layout, like so:
+
+```html
+
+ ...
+
+```
+
+To create your own theme, look to the Themes section of [included CSS file](https://github.com/poole/lanyon/blob/master/public/css/lanyon.css). Copy any existing theme (they're only a few lines of CSS), rename it, and change the provided colors.
+
+
+### Reverse layout
+
+
+
+
+Reverse the page orientation with a single class.
+
+```html
+
+ ...
+
+```
+
+
+### Sidebar overlay instead of push
+
+Make the sidebar overlap the viewport content with a single class:
+
+```html
+
+ ...
+
+```
+
+This will keep the content stationary and slide in the sidebar over the side content. It also adds a `box-shadow` based outline to the toggle for contrast against backgrounds, as well as a `box-shadow` on the sidebar for depth.
+
+It's also available for a reversed layout when you add both classes:
+
+```html
+
+ ...
+
+```
+
+### Sidebar open on page load
+
+Show an open sidebar on page load by modifying the `` tag within the `sidebar.html` layout to add the `checked` boolean attribute:
+
+```html
+
+```
+
+Using Liquid you can also conditionally show the sidebar open on a per-page basis. For example, here's how you could have it open on the homepage only:
+
+```html
+
+```
+
+## Development
+
+Lanyon has two branches, but only one is used for active development.
+
+- `master` for development. **All pull requests should be to submitted against `master`.**
+- `gh-pages` for our hosted site, which includes our analytics tracking code. **Please avoid using this branch.**
+
+
+## Author
+
+**Mark Otto**
+-
+-
+
+
+## License
+
+Open sourced under the [MIT license](LICENSE.md).
+
+<3
diff --git a/_site/site/archieve.html b/_site/site/archieve.html
new file mode 100644
index 00000000..1d529fb3
--- /dev/null
+++ b/_site/site/archieve.html
@@ -0,0 +1,439 @@
+
diff --git a/_site/site/atom.xml b/_site/site/atom.xml
new file mode 100644
index 00000000..7c28fad4
--- /dev/null
+++ b/_site/site/atom.xml
@@ -0,0 +1,17028 @@
+
+
+
+
+
+
+ 2023-02-12T14:07:39-05:00
+
+
+
+
+
+
+
+
+ Toolformer - Language Models Can Teach Themselves to Use Tools
+
+ 2023-02-10T00:00:00-05:00
+ /site/2023/02/10/Toolformer - Language Models Can Teach Themselves to Use Tools
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents Toolformer, a language model that uses simple APIs to use external tools (calculator, QA system, search engine, translation system, and calendar).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2302.04761">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>Starting with a language model, M, the goal is to enable the language model to use tools by invoking API calls.</p>
+ </li>
+ <li>
+ <p>An API call is denoted by the tuple $c =$ (api_name, api_input). It can be linearized as $e(c) =$ [api_name(api_input)$]$ or as $e(c, r) = [$api_name(api_input) $ -> r]$ where $r$ denotes the result of the API.</p>
+ </li>
+ <li>
+ <p>The given dataset of plain text, $C$, is converted into a dataset $C*$ augmented with the API calls using a three-step process.</p>
+ </li>
+ <li>
+ <p>In the first step, a position ($i$) and API call candidates (for the position $i$) are sampled.</p>
+
+ <ul>
+ <li>
+ <p>Positions are sampled by (i) computing the probability that M assigns to starting an API call for each position and (ii) retaining the top-$k$ positions with a probability greater than a threshold value.</p>
+ </li>
+ <li>
+ <p>For each of the sampled positions (say $i$), API calls are sampled by concatenating a prompt to the tokens till index $i$ and sampling from the model M. Examples that do not generate the “end of the API” token (i.e.,”]”) are discarded.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In the second step, the API calls are executed to obtain response $r$ (text sequence).</p>
+
+ <ul>
+ <li>API calls are filtered using the following criteria: if providing M with both the input and the output of the API makes it easier for M to predict the future token, compared to not using the API call at all or just using the input to the API, then the API call is helpful for M, and the example should be retained.</li>
+ </ul>
+ </li>
+ <li>
+ <p>In the last step, the remaining API calls are merged to obtain the augmented dataset $C*$ that is used for finetuning M.</p>
+ </li>
+ <li>
+ <p>Note that $C*$ contains $C$, so M is finetuned on the original dataset and examples where a tool is helpful.</p>
+ </li>
+ <li>
+ <p>During inference, the model is used for decoding in the usual way. Decoding is stopped when it produces the “->” token, and the corresponding API is used to generate the response. The decoding process (using the model) resumes with the API output appended to the decoded text.</p>
+ </li>
+</ul>
+
+<h2 id="tools">Tools</h2>
+
+<ul>
+ <li>
+ <p>There are two constraints on the tools: (i) their input and output should be expressible as text, and (ii) few demonstrations can be obtained from the tools. The second constraint means that the tool should be useable or accessible.</p>
+ </li>
+ <li>
+ <p>The paper considered the following tools: a question-answering system, a Wikipedia search engine, a calculator, a calendar, and a machine translation system. Of these, only the calculator and calendar are non-neural network tools.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Subset of CCNet is used as the language modeling dataset.</p>
+ </li>
+ <li>
+ <p>GPT-J is used as the language model.</p>
+ </li>
+ <li>
+ <p>For finetuning, the batch size is 128, the learning rate is 1e-5, and a linear warmup for the first 10% of training is used.</p>
+ </li>
+ <li>
+ <p>Following models are compared:</p>
+
+ <ul>
+ <li>
+ <p>GPT-J: Regular GPT-J model without any finetuning.</p>
+ </li>
+ <li>
+ <p>GPT-J + CC: GPT-J finetuned on $C$ without any API calls.</p>
+ </li>
+ <li>
+ <p>Toolformer, i.e. GPT-J finetuned on $C*$.</p>
+ </li>
+ <li>
+ <p>Toolformer with API calls disabled during training.</p>
+ </li>
+ <li>
+ <p>OPT 66B</p>
+ </li>
+ <li>
+ <p>GPT-3</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The models are evaluated in the prompted zero-shot setup, where models are instructed to solve a task without any in-context examples.</p>
+ </li>
+ <li>
+ <p>One difference from the standard greedy decoding is that the API call is used whenever it is one of the top-10 most likely next tokens. This is done to increase the use of API calls.</p>
+ </li>
+ <li>
+ <p>Evaluation Tasks</p>
+
+ <ul>
+ <li>
+ <p>SQuAD, GoogleRE, and T-REx subsets of the LAMA benchmark where the model has to complete a short statement with a missing fact.</p>
+
+ <ul>
+ <li>
+ <p>Since LAMA questions are based on Wikipedia, Toolformer isn’t allowed to use Wikipedia search.</p>
+ </li>
+ <li>
+ <p>The evaluation criteria is to check if the correct word is among the first five words predicted by the model.</p>
+ </li>
+ <li>
+ <p>Toolformer uses the question-answering tool for most cases, outperforming all the baselines.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Math Dataset</p>
+
+ <ul>
+ <li>
+ <p>eSDiv, SVAMP, and MAWPS benchmarks.</p>
+ </li>
+ <li>
+ <p>The first number predicted by the model is considered to be the output.</p>
+ </li>
+ <li>
+ <p>Toolformer uses the calculator tool for most cases, thereby outperforming all the baselines.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Question Answering</p>
+
+ <ul>
+ <li>
+ <p>Web Questions, Natural Questions, and TriviaQA datasets.</p>
+ </li>
+ <li>
+ <p>The evaluation criteria is to check if the correct word is among the first 20 words predicted by the model.</p>
+ </li>
+ <li>
+ <p>Question Answering tool is disabled for this setup.</p>
+ </li>
+ <li>
+ <p>Toolformer uses the Wikipedia tool for most cases, thereby outperforming all the baselines other than the much larger GPT-3 model.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Multilingual Question Answering</p>
+
+ <ul>
+ <li>
+ <p>MLQA benchmark.</p>
+ </li>
+ <li>
+ <p>The evaluation criteria is to check if the correct word is among the first ten words predicted by the model.</p>
+ </li>
+ <li>
+ <p>Toolformer uses the translation tool for most of the questions, with questions in Hindi being an exception.</p>
+ </li>
+ <li>
+ <p>However, Toolformer does not consistently outperform the GPT-J baseline, likely because, for some languages, finetuning on CCNet could hurt performance.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Temporal Datasets</p>
+
+ <ul>
+ <li>
+ <p>TEMPLAMA (cloze style queries where the answer changes with time) and DATESET (dataset generated through a series of templates and populated with random dates/durations).</p>
+ </li>
+ <li>
+ <p>While Toolformer outperforms the baselines for both datasets, it relies on the Wikipedia search and Question Answering tools (and not the calendar tool) for the LAMA dataset. On the DATESET dataset, it uses the calendar tool in the majority.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Language Modeling</p>
+
+ <ul>
+ <li>
+ <p>WikiText and a subset of 10,000 randomly selected documents from CCNet (not used during training of M).</p>
+ </li>
+ <li>
+ <p>Training on $C*$ does not increase perplexity (compared to training on C). In this experiment, the API calls are disabled during inference.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Varying the size of the underlying models show that the ability to use tools emerges only around 755M parameters.</p>
+ </li>
+</ul>
+
+<h2 id="future-work">Future Work</h2>
+
+<ul>
+ <li>
+ <p>Extending Toolformer to chain the use of tools and use tools interactively.</p>
+ </li>
+ <li>
+ <p>In some cases, the use of tools is very sample-inefficient.</p>
+ </li>
+ <li>
+ <p>Decision to use a tool does not account for the cost of using the tool.</p>
+ </li>
+</ul>
+
+
+
+
+ Synthesized Policies for Transfer and Adaptation across Tasks and Environments
+
+ 2021-03-29T00:00:00-04:00
+ /site/2021/03/29/Synthesized Policies for Transfer and Adaptation across Tasks and Environments
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper studies transfer learning in RL, focusing on simultaneous transfer across both tasks and environments.</p>
+ </li>
+ <li>
+ <p>The key idea is to learn task and environment embeddings and compose them using a meta-rule, and the proposed approach is called SYNPO (Synthesized Policies).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1904.03276">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Three settings considered:</p>
+
+ <ul>
+ <li>
+ <p><em>S1</em>: Transfer to a new (environment, task) pair when the agent has been trained on the environment and the task before (but not simultaneously).</p>
+ </li>
+ <li>
+ <p><em>S2</em>: Transfer to a new (environment, task) pair where either the environment or the task is not seen previously.</p>
+ </li>
+ <li>
+ <p><em>S3</em>: Transfer to a new (environment, task) pair where neither the environment nor the task is seen previously.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In the second and third settings, the agent is allowed to collect some data in the new environment or task.</p>
+ </li>
+ <li>
+ <p>The (environment, task) combinations that the agent has seen during training are referred to as <em>seen</em> combinations, while the remaining combinations are referred to as the <em>unseen</em> combinations.</p>
+ </li>
+ <li>
+ <p>The key idea is to:</p>
+
+ <ul>
+ <li>
+ <p>learn embeddings of environments and tasks</p>
+ </li>
+ <li>
+ <p>use these embeddings to compose a policy (parameterized as the linear combination of the policy basis).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>A disentanglement objective is used to decouple the task and environment embedding.</p>
+ </li>
+</ul>
+
+<h3 id="policy-composition">Policy Composition</h3>
+
+<ul>
+ <li>
+ <p>Given an (environment, task) pair $z = (\epsilon, \tau)$, the policy is given as $\pi_z(a|s) \propto exp(\psi_s^TU(e_{\epsilon}, e_{\tau})\phi_{a} + b_{\pi} )) $.</p>
+ </li>
+ <li>
+ <p>Here $b_{\pi}$ is a scalar bias, $\psi_{s}$ and $\phi_{a}$ are state and action representations, $U$ is parameterized as the linear comination of $K$ basis matrices $\Theta_k$</p>
+ </li>
+ <li>
+ <p>$U(e_{\epsilon}, e_{\tau}) = \sum_{k=1}^{K}\alpha_k(e_{\epsilon}, e_{\tau})\Theta_k$.</p>
+ </li>
+ <li>
+ <p>The basis matrices (denoted by $\Theta_k$) are shared across tasks while the coefficients ($\alpha_k$) are specific to the (environment, task) pair.</p>
+ </li>
+ <li>
+ <p>During training, the agent also predicts rewards using the same set of basis but different coefficients.</p>
+ </li>
+</ul>
+
+<h3 id="disentangling-environment-and-task-embeddings">Disentangling environment and task embeddings</h3>
+
+<ul>
+ <li>
+ <p>Given an (environment, task) pair, the agent is trained to decode the environment (and task) given the agent’s trajectory.</p>
+ </li>
+ <li>
+ <p>The sequence of state-action pairs (in the trajectory) is mapped to a sequence of state-action representations, given by $\psi_s^T\Theta_k\phi_{a}$</p>
+ </li>
+</ul>
+
+<h2 id="experiment-setup">Experiment Setup</h2>
+
+<ul>
+ <li>The agent is trained (and evaluated) on imitation learning (mostly) and reinforcement learning setup.</li>
+</ul>
+
+<h3 id="environments">Environments</h3>
+
+<ul>
+ <li>
+ <p>GRIDWORLD</p>
+
+ <ul>
+ <li>
+ <p>Twenty $16 \times 16$ gird-aligned mazes that are similar in appearance but differ in topology.</p>
+ </li>
+ <li>
+ <p>The task is to collect colored blocks in a given order. In each task, the starting position of the agent and the position of the blocks is randomized.</p>
+ </li>
+ <li>
+ <p>Each environment has 20 tasks, leading to a total of 400 (environment, task) combinations.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1712.05474">THOR</a></p>
+
+ <ul>
+ <li>
+ <p>This is a 3D simulator where the agent is placed in indoor photo-realistic scenes.</p>
+ </li>
+ <li>
+ <p>The task is the search for objects and perform actions like “put cabbage on the fridge.”</p>
+ </li>
+ <li>
+ <p>The setup uses 19 scenes (environments), with each environment comprising of 21 tasks.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="baselines">Baselines</h3>
+
+<ul>
+ <li>
+ <p>MLPs that concatenate state, environment embeddings, and task embedding.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1606.05312">Successor feature model</a></p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1609.07088">Module Network</a></p>
+ </li>
+ <li>
+ <p>Multi-task Learning where the distinction between the environments is ignored.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>GRIDWORLD</p>
+
+ <ul>
+ <li>
+ <p>In the first setting (<em>S1</em>)</p>
+
+ <ul>
+ <li>
+ <p>SYNPO outperforms all the baselines.</p>
+ </li>
+ <li>
+ <p>As the agent is trained on more (environment, task) combinations, its performance on the unseen combinations improves. This trend saturates when the <em>seem/total</em> ratio reaches about 0.4 (i.e., training on 40% of all the combinations).</p>
+ </li>
+ <li>
+ <p>Task disentanglement is more important than environment disentanglement.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In the second and third setting (<em>S2</em> and <em>S3</em>)</p>
+
+ <ul>
+ <li>
+ <p>The agent uses one demonstration from each test pair to finetune the embeddings.</p>
+ </li>
+ <li>
+ <p><em>S2</em> is an easier setting than <em>S3</em>.</p>
+ </li>
+ <li>
+ <p>Transfer learning across tasks is easier than transfer learning across environments.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>THOR</p>
+
+ <ul>
+ <li>SYNPO outperforms all the baselines on both seen and unseen combinations.</li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+
+ Deep Neural Networks for YouTube Recommendations
+
+ 2021-03-22T00:00:00-04:00
+ /site/2021/03/22/Deep Neural Networks for YouTube Recommendations
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper describes YouTube’s deep learning-based recommendation system.</p>
+ </li>
+ <li>
+ <p><a href="https://research.google/pubs/pub45530/">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="challenges">Challenges</h2>
+
+<ul>
+ <li>
+ <p>Scale - Very large number of users and videos.</p>
+ </li>
+ <li>
+ <p>Freshness - Very large number of videos uploaded every hour. The recommendation system should take these new videos into account as well.</p>
+ </li>
+ <li>
+ <p>Noise - User satisfaction needs to be modeled from noisy implicit feedback signal as the explicit signal is very sparse.</p>
+ </li>
+</ul>
+
+<h2 id="system-overview">System Overview</h2>
+
+<ul>
+ <li>
+ <p>Two neural networks: one for candidate generation and another one for ranking.</p>
+ </li>
+ <li>
+ <p>Metrics</p>
+
+ <ul>
+ <li>
+ <p>Offline metrics like precision, recall, ranking loss</p>
+ </li>
+ <li>
+ <p>A/B testing via live experiments</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="candidate-generation">Candidate Generation</h3>
+
+<ul>
+ <li>
+ <p>Input: events from a user’s YouTube activity history.</p>
+ </li>
+ <li>
+ <p>Output: small subset (hundreds) of videos.</p>
+ </li>
+ <li>
+ <p>Approach:</p>
+
+ <ul>
+ <li>
+ <p>Recommendation is modeled as extreme multiclass classification.</p>
+ </li>
+ <li>
+ <p>Predict the video (from a corpus) that a user will watch at a given time.</p>
+ </li>
+ <li>
+ <p>The neural network’s task is to learn useful user embeddings, given the user’s context and history.</p>
+ </li>
+ <li>
+ <p>For each positive class (relevant video), negative classes (non-relevant videos) are sampled from the video corpus.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Model Architecture</p>
+
+ <ul>
+ <li>
+ <p>A feedforward network with input as user embeddings and context embeddings (watch history).</p>
+ </li>
+ <li>
+ <p>Watch history is a variable-length sequence of video ids, where each video id is mapped to an embedding.</p>
+ </li>
+ <li>
+ <p>The sequence of video ids is mapped to a sequence of embeddings, and this sequence is averaged to obtain fixed-sized embedding.</p>
+ </li>
+ <li>
+ <p>Additional signals like demographic features and search query embeddings can be added along with the context embeddings.</p>
+ </li>
+ <li>
+ <p>The age of a video is also used as a feature during training to account for the freshness of the content. This feature is set to zero (or slightly negative) during inference.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Other Insights</p>
+
+ <ul>
+ <li>
+ <p>Training examples are generated from all YouTube watches, including the watches from the videos embedded on other sites, to surface new content.</p>
+ </li>
+ <li>
+ <p>Generating the same number of training examples per user is important to avoid a small set of active users from dominating the model training.</p>
+ </li>
+ <li>
+ <p>Predicting a user’s next watch leads to better results than predicting a randomly held-out watch. This can be attributed to the general consumption pattern of videos (e.g., episodes are usually watched in order).</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="ranking">Ranking</h3>
+
+<ul>
+ <li>
+ <p>Input: list of candidate videos to rank from.</p>
+ </li>
+ <li>
+ <p>Output: score for each video.</p>
+ </li>
+ <li>
+ <p>Approach</p>
+
+ <ul>
+ <li>A feedforward network (similar to candidate generation model) trained using logistic regression loss.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Feature representation</p>
+
+ <ul>
+ <li>
+ <p>Different types of features: categorical vs. continuous, univalent vs. multivalent, describes video vs. describes user or context.</p>
+ </li>
+ <li>
+ <p>Important signals include user’s interaction with the video (or similar videos), which source/channel added the video to the candidate set.</p>
+ </li>
+ <li>
+ <p>Embeddings are shared across features. For example, the representation for a video id remains the same, irrespective of whether it is being used for representing the “video to recommend” or the “last seen video.”</p>
+ </li>
+ <li>
+ <p>Feature normalization and transformations like exponents (square or square root) for continuous variables improve the performance.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>To model the expected watch time, the logistic regression loss is weighted by the observed watch time. For example, if a video was watched, its weight is given by the observed watch time, and if the video was not watched, its weight is set to 1.</p>
+ </li>
+ <li>
+ <p>In practice, this means that the logistic regression model learns odds that approximate the expected watch time of the video.</p>
+ </li>
+</ul>
+
+
+
+
+ The Tail at Scale
+
+ 2021-03-15T00:00:00-04:00
+ /site/2021/03/15/The Tail at Scale
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents some causes for (temporary) high-latency episodes in large-scale online systems and techniques to mitigate their impact so that the tail of latency distribution remains short.</p>
+ </li>
+ <li>
+ <p><a href="https://research.google/pubs/pub40801/">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="why-does-variability-in-response-time-exist">Why does variability in response time exist</h2>
+
+<ul>
+ <li>
+ <p>Shared resources between processes on the same node</p>
+ </li>
+ <li>
+ <p>Background processes (daemons) could use cause a momentary spike in resource usage.</p>
+ </li>
+ <li>
+ <p>Processes running on different nodes may contend for global resources like shared file systems.</p>
+ </li>
+ <li>
+ <p>Maintenance activities like disk compaction or garbage collection.</p>
+ </li>
+ <li>
+ <p>Others like queueing, power limits, or energy management.</p>
+ </li>
+ <li>
+ <p>In the case of large-scale systems, the component-level variability is further amplified.</p>
+ </li>
+</ul>
+
+<h2 id="reducing-component-variability">Reducing Component Variability</h2>
+
+<ul>
+ <li>
+ <p>Use differentiated service classes to prioritize user requests over non-interactive requests.</p>
+ </li>
+ <li>
+ <p>Reduce head-of-line blocking by breaking long-running requests into smaller requests.</p>
+ </li>
+ <li>
+ <p>Synchronize maintenance jobs across nodes to minimize the window for high latency.</p>
+ </li>
+ <li>
+ <p>Caching generally does not help to address tail latency.</p>
+ </li>
+</ul>
+
+<h2 id="adapting-to-latency-variability">Adapting to Latency Variability</h2>
+
+<ul>
+ <li>
+ <p>Two categories of adaptation approaches</p>
+
+ <ul>
+ <li>
+ <p>Within Request Short-Term Adaptations</p>
+
+ <ul>
+ <li>
+ <p>These approaches are more relevant for services that perform many read queries on loosely consistent datasets.</p>
+ </li>
+ <li>
+ <p>Hedged Request</p>
+
+ <ul>
+ <li>
+ <p>Send the request to multiple replicas, and once one of the replicas returns the result, cancel the other requests.</p>
+ </li>
+ <li>
+ <p>In practice, start by sending the request to only one replica. Send the secondary requests if the first request is outstanding for more than $95^{th}$ percentile of expected latency.</p>
+ </li>
+ <li>
+ <p>This introduces an additional $5\%$ load while substantially shortening the latency tail.</p>
+ </li>
+ <li>
+ <p>This approach work because often, the cause of latency is not the query itself but other factors like overloaded nodes.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Tied Request</p>
+
+ <ul>
+ <li>
+ <p>Hedged request approach makes a tradeoff regarding how long to wait before initiating requests to other replicas. The sooner the request is made, the lower should be the latency in serving the request, but more will be the overall load in the system.</p>
+ </li>
+ <li>
+ <p>The load in the system can be reduced by “tieing” requests (sent to different replicas) so that as soon as one replica starts processing the request, it can notify the other replicas, which could drop the request or deprioritize it.</p>
+ </li>
+ <li>
+ <p>In practice, “tieing” requests means that each replica has the identity of other replicas which may execute the request.</p>
+ </li>
+ <li>
+ <p>Note that there is a short window (of the average network message delay) when multiple replicas could start executing the request. This can be mitigated if the client (issuing the requests) introduces a delay to twice the average network message delay.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Submit the request to the least loaded replica</p>
+
+ <ul>
+ <li>This is less effective for reasons like the load on a replica can change after the request is made but before it is executed.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Cross-Request Long-Term Adaptations</p>
+
+ <ul>
+ <li>
+ <p>These approaches are more relevant for situations where different services have different throughput.</p>
+ </li>
+ <li>
+ <p>Micro-partitions</p>
+
+ <ul>
+ <li>
+ <p>Generate more paritions than the number of nodes.</p>
+ </li>
+ <li>
+ <p>The partitions can be dynamically assigned to machines to ensure proper load balancing.</p>
+ </li>
+ <li>
+ <p>In case of machine failure, many nodes can be used to quickly re-create the micro-partitions instead of waiting on one machine to read one single large partition.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Selective Replication</p>
+
+ <ul>
+ <li>With micro-partitioning, replicas for micro-partitions can be created ahead of time to achieve good load balancing.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Latency induced probation</p>
+
+ <ul>
+ <li>In some cases, removing a slow node can improve the overall latency of the system. The probated node can be re-incorporated when its latency improves.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Large Information Retrieval Systems</p>
+
+ <ul>
+ <li>
+ <p>In such systems, speed can be more critical than the quality of the result.</p>
+ </li>
+ <li>
+ <p>The system should return a “good enough” result that is available with low latency instead of waiting for the “best result” that is available with high latency.</p>
+ </li>
+ <li>
+ <p>In some cases, a request could trigger an unexpected code path or cause some other exception that could slow down the entire system.</p>
+ </li>
+ <li>
+ <p>In such cases, the <em>canary request</em> technique can be used where the system sends the request initially to only 1 or 2 nodes. The request is sent over to the other nodes only after receiving a successful response from the initial nodes.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Requests that update state are easier to handle for several reasons:</p>
+
+ <ul>
+ <li>
+ <p>The scale of latency-critical modifications is generally small.</p>
+ </li>
+ <li>
+ <p>The update can be performed asynchronously after responding to the user.</p>
+ </li>
+ <li>
+ <p>Quorum-based approaches (often used for ensuring consistent updates) are inherently tail-tolerant.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Practical Lessons from Predicting Clicks on Ads at Facebook
+
+ 2021-03-08T00:00:00-05:00
+ /site/2021/03/08/Practical Lessons from Predicting Clicks on Ads at Facebook
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper describes several design choices for developing a model for predicting user response (clicks) on ads.</p>
+ </li>
+ <li>
+ <p><a href="https://research.fb.com/publications/practical-lessons-from-predicting-clicks-on-ads-at-facebook/">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="experimental-setup">Experimental Setup</h2>
+
+<ul>
+ <li>
+ <p>The model is trained/evaluated on offline data.</p>
+ </li>
+ <li>
+ <p>Evaluation metrics:</p>
+
+ <ul>
+ <li>
+ <p>Normalized Cross-Entropy (or Normalized Entropy, NE)</p>
+
+ <ul>
+ <li>
+ <p>Defined as the predictive log-loss per impression, divided by the entropy of the background CTR (click-through rate).</p>
+ </li>
+ <li>
+ <p>Background CTR is the average empirical CTR of the training data.</p>
+ </li>
+ <li>
+ <p>Lower normalized cross-entropy is better.</p>
+ </li>
+ <li>
+ <p>The normalization term is important to make the metric insensitive to the background CTR. Otherwise, the log loss can easily be made low when background CTR is close to 0 or 1.</p>
+ </li>
+ <li>
+ <p>NE can also be written as $RIG - 1$, where $RIG$ is the Relative Information Gain.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Calibration</p>
+
+ <ul>
+ <li>Ratio of average estimated CTR and empirical CTR.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Area-Under-ROC (AUC) is a good metric for measuring ranking quality (among ads). However, it is <strong>not used</strong> as a metric to avoid over-delivery or under-delivery of ads.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="implementation-details">Implementation Details</h2>
+
+<ul>
+ <li>
+ <p>Feature Transformation</p>
+
+ <ul>
+ <li>
+ <p>A given add impression, $e$, is transformed into a $n-$dimensional vector, $x$, where the $i^{th}$ index denotes the value of the $i^{th}$ categorical feature.</p>
+ </li>
+ <li>
+ <p>Continous features are binned, and the bin index is used as a categorical feature, thus applying a non-linear transformation to the features.</p>
+ </li>
+ <li>
+ <p>Categorical features that are tuple-like (i.e., have a tuple of values) can be converted into new categorical features by taking a cartesian product.</p>
+ </li>
+ <li>
+ <p>Boosted decision trees can be used to implement the previous two transformations in one go.</p>
+
+ <ul>
+ <li>
+ <p>Each tree is used as a categorical feature that takes the value of the index of the leaf node than an ad maps to.</p>
+ </li>
+ <li>
+ <p>The paper used the Gradient Boosting Machine with the $L_2-$TreeBoost algorithm.</p>
+ </li>
+ <li>
+ <p>Using the tree feature transformation improves the Normalized Cross-Entropy by $3.4\%$.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Model</p>
+
+ <ul>
+ <li>
+ <p>Logistic Regression (LR) or Bayesian online learning scheme for probit regression (BOPR) algorithms are used for training a linear classifier model.</p>
+ </li>
+ <li>
+ <p>While both LR and BOPR models provide similar performance, the LR model is half the BOPR model’s size and faster for performing training/inference.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="role-of-data-freshness">Role of Data Freshness</h2>
+
+<ul>
+ <li>
+ <p>When a model is trained on the data from a particular day and evaluated on data from the subsequent days, the model’s performance degrades as the delay between training and test set increases.</p>
+ </li>
+ <li>
+ <p>This highlights the importance of the freshness of the training data.</p>
+ </li>
+ <li>
+ <p>One straightforward approach can be to train the model every day.</p>
+ </li>
+ <li>
+ <p>Alternatively, the linear classifier can be trained using online learning, while the boosted decision tree can still be trained daily.</p>
+ </li>
+ <li>
+ <p>Different choices for setting the learning rate (for online training of linear classifier) are compared, and the <a href="https://research.google/pubs/pub41159/">per-coordinate learning rate</a> is found to perform best in practice.</p>
+ </li>
+</ul>
+
+<h2 id="generating-real-time-training-data">Generating Real-Time Training Data</h2>
+
+<ul>
+ <li>
+ <p>An “online joiner” system is used to generate real-time training data for the linear classifier.</p>
+ </li>
+ <li>
+ <p>The challenging part is, while there are data points with a “positive” label (i.e., the user clicked on the ad), there are no datapoints with a “negative” label (since there is no “no-click” button that the user can click).</p>
+ </li>
+ <li>
+ <p>An impression is considered to have the “no-click” label if the user does not click on the ad within a (long) time window of seeing the ad.</p>
+ </li>
+ <li>
+ <p>Too short a time window could mislabel some impressions, while too long a time window will delay the real-time training data.</p>
+ </li>
+ <li>
+ <p>The online joiner performs a distributed stream-to-stream join on the stream of ad impressions and stream of ad clicks using a HashQueue.</p>
+ </li>
+ <li>
+ <p>A HashQueue:</p>
+
+ <ul>
+ <li>
+ <p>comprises of a First-In-First-Out queue as a buffer window and a hash map for fast random access to label impressions.</p>
+ </li>
+ <li>
+ <p>supports three operations on key-value pairs: enqueue, dequeue, and lookup.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="memory-and-latency">Memory and Latency</h2>
+
+<ul>
+ <li>
+ <p>Increasing the number of boosting trees shows diminishing returns, and most of the improvements come from the first 500 trees.</p>
+ </li>
+ <li>
+ <p>Top 10 features account for half of the total feature importance, while the last 300 features add less than 1% feature importance.</p>
+ </li>
+ <li>
+ <p>Features in the boosting model can be broadly classified as contextual or historical.</p>
+ </li>
+ <li>
+ <p>Historical feature provides much more explanatory power than the contextual features through contextual features are helpful to handle the cold start problem.</p>
+ </li>
+ <li>
+ <p>Models trained with just the contextual features rely more heavily on data freshness than models trained with just the historical features.</p>
+ </li>
+ <li>
+ <p>Uniform subsampling and negative downsampling techniques are used to limit the amount of training data.</p>
+ </li>
+ <li>
+ <p>In the case of negative downsampling, the model needs to be re-calibrated as well.</p>
+ </li>
+</ul>
+
+
+
+
+ Ad Click Prediction - a View from the Trenches
+
+ 2021-03-01T00:00:00-05:00
+ /site/2021/03/01/Ad Click Prediction - a View from the Trenches
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents case studies from the experience of deploying an ad click-through rate (CTR) prediction model at Google.</p>
+ </li>
+ <li>
+ <p>The paper focuses on themes related to memory footprint, performance analysis, calibration, confidence in the predictions, and feature engineering.</p>
+ </li>
+ <li>
+ <p><a href="https://research.google/pubs/pub41159/">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="system-overview">System Overview</h2>
+
+<ul>
+ <li>
+ <p>Features (corresponding to a given ad) include search query and the metadata in the ad. The features are very sparse.</p>
+ </li>
+ <li>
+ <p>Single layer, regularized Logistic Regression model is trained with Online Gradient Descent (same as Stochastic Gradient Descent, but in the online setting).</p>
+ </li>
+ <li>
+ <p>From a memory perspective, it is important to minimize the size of the final model.</p>
+ </li>
+ <li>
+ <p>Adding just the L1 penalty is not sufficient to produce weights that are precisely equal to 0.</p>
+ </li>
+ <li>
+ <p><a href="http://proceedings.mlr.press/v15/mcmahan11b.html">“Follow The (Proximally) Regularized Leader” algorithm or FTRL-Proximal algorithm</a> is used to learn sparse models without losing on the accuracy.</p>
+ </li>
+ <li>
+ <p>Using per-coordinate learning rates improves the performance at the cost of memory as both the sum of gradients and the sum of the square of gradients are tracked for each feature.</p>
+
+ <ul>
+ <li>
+ <p>In practice, some of the cost can be alleviated by approximating that all the events containing a given feature have the same probability.</p>
+ </li>
+ <li>
+ <p>In such a case, the sum of the square of gradients can be approximated using the counts of positive and negative events alone.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Some memory overhead can be reduced based on the following observation: the vast majority of features are extremely rare. Hence, it is not necessary to track the statistics for such rare features.</p>
+
+ <ul>
+ <li>
+ <p>However, in an online setting, it is not known upfront as to which features will be sparse.</p>
+ </li>
+ <li>
+ <p>The paper proposes to use probabilistic feature inclusion - a feature is added to the model with probability $p$. Once it is added, the feature is not removed.</p>
+ </li>
+ <li>
+ <p>An alternative approach is to use a rolling set of counting Bloom filters to check if a feature has appeared at least $n$ times in training. Bloom filters are probabilistic data structures and can return false positives.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Memory can also be saved by using fewer bits for encoding weights.</p>
+
+ <ul>
+ <li>
+ <p>Most of the weight coefficients lie in the range $(-2, 2)$, and a $16-$ bit encoding is used in place of $32$ or $64$ bit encoding.</p>
+ </li>
+ <li>
+ <p>This quantization approach needs to account for roundoff problems. The fix is easy to implement.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>When training many models with similar hyperparameters, per-model learning rate counters can be replaced by statistics shared by all the models, thus reducing memory footprint.</p>
+ </li>
+ <li>
+ <p>A Single Value Structure is used to reduce the memory footprint when evaluating a very large set of model variants that differ only in addition/removal of a small subset of features.</p>
+
+ <ul>
+ <li>
+ <p>All the models, that use a feature, share a single value structure corresponding to the feature. This reduces the memory overhead by order of magnitude.</p>
+ </li>
+ <li>
+ <p>During the update, each model computes the weight updates corresponding to all the features that it is using. The updated weight is averaged across all the models and used to update the single value structure.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Since CTR datasets are generally highly imbalanced, the training data (for the negative class) can be subsampled to reduce the amount of data to train over. The loss component (corresponding to negative class) can be appropriately scaled up.</p>
+ </li>
+ <li>
+ <p>Metrics</p>
+
+ <ul>
+ <li>
+ <p>Offline metrics like AucLoss (1 - AUC), Log Loss, Squared Error</p>
+ </li>
+ <li>
+ <p>Online loss is computed on the new training data (new incoming traffic) before training on it.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The confidence in the model’s prediction is estimated using a heuristic called <em>uncertainty score</em>. It can be measured using the dot product of the feature and the vector of learning rates.</p>
+
+ <ul>
+ <li>
+ <p>The idea is that the learning rates already maintain a notion of uncertainty.</p>
+ </li>
+ <li>
+ <p>Features for which the learning rate is high are the features for which uncertainty is also high.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Calibrating Predictions</p>
+
+ <ul>
+ <li>
+ <p>The calibration can be improved by applying correction functions $\tau_d(p)$ where $p$ is the predicted CTR, and $d$ is an element of a partition of the training data.</p>
+ </li>
+ <li>
+ <p>$\tau$ can be modeled as $\gamma^{\kappa}$ where $\gamma$ and $\kappa$ are learned using Poisson regression.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Unsuccessful Experiments</p>
+
+ <ul>
+ <li>
+ <p>Aggressive feature hashing was tried to reduce the memory overhead. However, it leads to a significant loss in performance.</p>
+ </li>
+ <li>
+ <p>Using dropout did not help, probably because the features are sparse.</p>
+ </li>
+ <li>
+ <p>Using feature bagging hurt the AucLoss.</p>
+ </li>
+ <li>
+ <p>Feature vector normalization did not improve performance, probably because of per-coordinate learning rates and regularization.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Anatomy of Catastrophic Forgetting - Hidden Representations and Task Semantics
+
+ 2021-02-22T00:00:00-05:00
+ /site/2021/02/22/Anatomy of Catastrophic Forgetting - Hidden Representations and Task Semantics
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper studies the effect of catastrophic forgetting on representations in neural networks.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2007.07400">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Techniques:</p>
+
+ <ul>
+ <li>
+ <p>Representational Similarity Measures</p>
+ </li>
+ <li>
+ <p>Layer Freezing</p>
+ </li>
+ <li>
+ <p>Layer Reset</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Datasets</p>
+
+ <ul>
+ <li>
+ <p>Split CIFAR-10</p>
+
+ <ul>
+ <li>
+ <p>CIFAR-10 dataset is split into <em>m</em> (=2) tasks, where each task is a <em>n</em> way classification task.</p>
+ </li>
+ <li>
+ <p>The underlying network has a shared trunk with <em>m</em> heads, one head per task.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Split CIFAR-100 Distribution Shift</p>
+
+ <ul>
+ <li>Each task requires distinguishing between <em>n</em> CIFAR-100 <em>superclasses</em> with training/test data corresponding to a <em>subset</em> of constituent classes.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Network Architecture</p>
+
+ <ul>
+ <li>VGG, ResNet and DenseNet</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="questions">Questions</h2>
+
+<ul>
+ <li>
+ <p>Are all representations (throughout the network) equally responsible for forgetting?</p>
+
+ <ul>
+ <li>
+ <p><em>Higher</em> layer (layers closer to the output) are the primary source of catastrophic forgetting.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1905.00414">Central Kernel Alignment (CKA)</a> technique is used to compare the similarity between the layer representations, before and after training on the second task.</p>
+ </li>
+ <li>
+ <p>Higher layer representations change significantly when training over two tasks while the lower layer representations remain stable.</p>
+ </li>
+ <li>
+ <p>When finetuning on the second task, freezing the lower layers has only a minor effect on the accuracy of the second task.</p>
+ </li>
+ <li>
+ <p>In <em>layer reset</em> experiments, after training on the second task, the weights of some of the layers are reset to their values after training on the first task.</p>
+
+ <ul>
+ <li>Resetting the weights of higher layers leads to significant improvement in the performance on the first task.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Do common approaches for countering catastrophic forgetting work by stabilizing the higher layers?</p>
+
+ <ul>
+ <li>
+ <p>Yes - both <a href="https://arxiv.org/abs/1612.00796">EWC</a> and replay-based approaches counter catastrophic forgetting work by stabilizing the higher layers.</p>
+ </li>
+ <li>
+ <p>This is demonstrated by showing that as the quadratic penalty for EWC (or fraction of data from replay buffer) increases (to reduce catastrophic forgetting), the representations for higher layers change less during the second task.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>When training over a sequence of tasks, are similar tasks more likely to be forgotten than different tasks?</p>
+
+ <ul>
+ <li>
+ <p>Setup I</p>
+
+ <ul>
+ <li>
+ <p>Training over a sequence of two binary classification tasks.</p>
+ </li>
+ <li>
+ <p>Task 1: Two related classes (say <code class="language-plaintext highlighter-rouge">ship</code> and <code class="language-plaintext highlighter-rouge">truck</code>)</p>
+ </li>
+ <li>
+ <p>Task 2: Two related classes, which may or may not be related to the classes for Task 1. For example, the classes could be</p>
+
+ <ul>
+ <li>
+ <p><code class="language-plaintext highlighter-rouge">cat</code> and <code class="language-plaintext highlighter-rouge">horse</code> (not related to classes of the first task)</p>
+ </li>
+ <li>
+ <p><code class="language-plaintext highlighter-rouge">plane</code> and <code class="language-plaintext highlighter-rouge">car</code> (related to the classes of the first task)</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Training over semantically similar tasks (here <code class="language-plaintext highlighter-rouge">plane</code> and <code class="language-plaintext highlighter-rouge">car</code>) leads to less forgetting.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Setup II</p>
+
+ <ul>
+ <li>
+ <p>Training over a sequence of two classification tasks.</p>
+ </li>
+ <li>
+ <p>Task 1: Four classes where the classes can be grouped into two groups (say <code class="language-plaintext highlighter-rouge">deer</code>, <code class="language-plaintext highlighter-rouge">dog</code>, <code class="language-plaintext highlighter-rouge">ship</code> and <code class="language-plaintext highlighter-rouge">truck</code>)</p>
+ </li>
+ <li>
+ <p>Task 2: Two related classes, which may be related to group 1 or group 2. For example, the classes could be two animals or two objects.</p>
+ </li>
+ <li>
+ <p>After training on the second task, classes (from Task 1), which are in the different group as classes from Task 2, are forgotten less.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Conclusion</p>
+
+ <ul>
+ <li>
+ <p>Task representational similarity is a function of both underlying data and optimization procedure.</p>
+ </li>
+ <li>
+ <p>Forgetting is most severe for task representations of intermediate similarity.</p>
+ </li>
+ <li>
+ <p>Representational similarity is necessary but not a sufficient condition for forgetting.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>How does catastrophic forgetting change as the task similarity changes?</p>
+
+ <ul>
+ <li>
+ <p>If the model learns different representations for dissimilar tasks, increasing dissimilarity can help to avoid forgetting.</p>
+ </li>
+ <li>
+ <p>When training the two-task, two-class (per task) CIFAR-10 setup with an “others” class (classes not already used in the setup), the forgetting is reduced.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ When Do Curricula Work?
+
+ 2021-02-15T00:00:00-05:00
+ /site/2021/02/15/When Do Curricula Work
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper systematically investigates when does curriculum learning help.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2012.03107">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="implicit-curricula">Implicit Curricula</h2>
+
+<ul>
+ <li>
+ <p>Implicit curricula refers to the order in which a network learns data points when trained using stochastic gradient descent, with iid sampling of data.</p>
+ </li>
+ <li>
+ <p>When training, let us say that the model makes a correct prediction for a given datapoint in the $i^{th}$ epoch (and correct prediction in all the subsequent epochs). The $i^{th}$ epoch is referred to as the <em>learned iteration</em> of the datapoint (iteration in which the datapoint was learned).</p>
+ </li>
+ <li>
+ <p>The paper studied multiple models (VGG, ResNet, WideResNet, DenseNet, and EfficientNet) with different optimizers (Adam and SGD with momentum).</p>
+ </li>
+ <li>
+ <p>The resulting implicit curricula are broadly consistent within the model families, making the following discussion less dependent on the model architecture.</p>
+ </li>
+</ul>
+
+<h2 id="explicit-curricula">Explicit Curricula</h2>
+
+<ul>
+ <li>When defining an explicit curriculum, three important components stand out.</li>
+</ul>
+
+<h3 id="scoring-function">Scoring Function</h3>
+
+<ul>
+ <li>
+ <p>Maps a data point to a numerical score of <em>difficulty</em>.</p>
+ </li>
+ <li>
+ <p>Choices:</p>
+
+ <ul>
+ <li>
+ <p>Loss function for a model</p>
+ </li>
+ <li>
+ <p><em>learned iteration</em></p>
+ </li>
+ <li>
+ <p>Estimated c-score - It captures a given model’s consistency to correctly predict a given datapoint’s label when trained on an iid dataset (not containing the datapoint).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The three scoring functions are computed for two models on the CIFAR dataset.</p>
+ </li>
+ <li>
+ <p>The resulting six scores have a high Spearman Rank correlation. Hence for the rest of the discussion, only the c-score is used.</p>
+ </li>
+</ul>
+
+<h3 id="pacing-function">Pacing Function</h3>
+
+<ul>
+ <li>
+ <p>This function, denoted by $g(t)$, controls the size of the training dataset at step $t$.</p>
+ </li>
+ <li>
+ <p>At step $t$, the model would be trained on the first $g(t)$ examples (as per the ordering).</p>
+ </li>
+ <li>
+ <p>Choices: logarithmic, exponential, step, linear, quadratic, and root.</p>
+ </li>
+</ul>
+
+<h3 id="order">Order</h3>
+
+<ul>
+ <li>
+ <p>Order in which the data points are picked:</p>
+
+ <ul>
+ <li>
+ <p><em>Curriculum</em> - Ordering points from lowest score to highest and training on the easiest data points first.</p>
+ </li>
+ <li>
+ <p><em>Anti Curriculum</em> - Ordering points from highest score to lowest and training on the hardest data points first.</p>
+ </li>
+ <li>
+ <p><em>Random</em> - Randomly selecting the data points to train on.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>The paper performed a hyperparameter sweep over 180 pacing functions and three orderings for three random seeds over the CIFAR10 and CIFAR100 datasets. For both the datasets, the best performance is obtained with random ordering, indicating that curricula did not give any benefits.</p>
+ </li>
+ <li>
+ <p>However, the curriculum is useful when the number of training iterations is small.</p>
+ </li>
+ <li>
+ <p>It also helps with noisy data training (which is simulated by randomly permuting the labels).</p>
+ </li>
+ <li>
+ <p>The observations for the smaller CIFAR10/100 dataset generalize to slightly larger datasets like FOOD101 and FOOD101N.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Continual learning with hypernetworks
+
+ 2021-02-08T00:00:00-05:00
+ /site/2021/02/08/Continual learning with hypernetworks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes the use of task-conditioned <a href="https://shagunsodhani.com/papers-I-read/HyperNetworks">HyperNetworks</a> for lifelong learning / continual learning setups.</p>
+ </li>
+ <li>
+ <p>The idea is, the HyperNetwork would only need to remember the task-conditioned weights and not the input-output mapping for all the data points.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1906.00695">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/chrhenning/hypercl">Author’s Implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="terminology">Terminology</h2>
+
+<ul>
+ <li>
+ <p>$f$ denotes the network for the given $t^{th}$ task.</p>
+ </li>
+ <li>
+ <p>$h$ denotes the HyperNetwork that generates the weights for $f$.</p>
+ </li>
+ <li>
+ <p>$\Theta_{h}$ denotes the parameters of $h$.</p>
+ </li>
+ <li>
+ <p>$e^{t}$ denotes the input task-embedding for the $t^{th}$ task.</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>When training on the $t^{th}$ task, the HyperNetworks generates the weights for the network $f$.</p>
+ </li>
+ <li>
+ <p>The current task loss is computed using the generated weights, and the candidate weight update ($\Delta \Theta_{h}$) is computed for $h$.</p>
+ </li>
+ <li>
+ <p>The actual parameter change is computed by the following expression:</p>
+ </li>
+</ul>
+
+<p>$L_{total} = L{task}(\Theta_{h}, e^{T}, X^{T}, Y^{T}) + \frac{\beta_{output}}{T-1} \sum_{t=1}^{T-1} | f_{h}(e^{t}, \Theta_{h}^*) - f_{h}(e^{(t)}, \Theta_{h} + \Delta \Theta_{h} ))|^2$</p>
+
+<ul>
+ <li>
+ <p>$L_{task}$ is the loss for the current task.</p>
+ </li>
+ <li>
+ <p>$(X^{T}, Y^{T})$ denotes the training datapoints for the $T^{th}$ task.</p>
+ </li>
+ <li>
+ <p>$\beta_{output}$ is a hyperparameter to control the regularizer’s strength.</p>
+ </li>
+ <li>
+ <p>$\Theta_{h}^*$ denotes the optimal parameters after training on the $T-1$ tasks.</p>
+ </li>
+ <li>
+ <p>$\Theta_{h} + \Delta \Theta_{h}$ denotes the one-step update on the current $h$ model.</p>
+ </li>
+ <li>
+ <p>In practice, the task encoding $e^{t}$ is chunked into smaller vectors, and these vectors are fed as input to the HyperNetwork.</p>
+ </li>
+ <li>
+ <p>This enables the HyperNetwork to produce weights iteratively, instead of all at once, thus helping to scale to larger models.</p>
+ </li>
+ <li>
+ <p>The paper also considers the problem of inferring the task embedding from a given input pattern.</p>
+ </li>
+ <li>
+ <p>Specifically, the paper uses task-dependent uncertainty, where the task embedding with the least predictive uncertainty is chosen as the task embedding for the given unknown task. This approach is referred to as HNET+ENT.</p>
+ </li>
+ <li>
+ <p>The paper also considers using HyperNetworks to learn the weights for a task-specific generative model. This generative model will be used to generate pseudo samples for rehearsal-based approaches. The paper considers two cases:</p>
+
+ <ul>
+ <li>
+ <p>HNET+R where the replay model (i.e., the generative model) is parameterized using a HyperNetwork.</p>
+ </li>
+ <li>
+ <p>HNET+TIR, where an auxiliary task inference classifier is used to predict the task identity.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Three setups are considered</p>
+
+ <ul>
+ <li>
+ <p>CL1 - Task identity is given to the model.</p>
+ </li>
+ <li>
+ <p>CL2 - Task identity is not given, but task-specific heads are used.</p>
+ </li>
+ <li>
+ <p>CL3 - Task identity needs to be explicitly inferred.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>On the permuted MNIST task, the proposed approach outperforms baselines like Synaptic Intelligence and Online EWC, and the performance gap is more significant for larger task sequences.</p>
+ </li>
+ <li>
+ <p>Forward knowledge transfer is observed with the CIFAR datasets.</p>
+ </li>
+ <li>
+ <p>One potential limitation (which is more of a limitation of HyperNetworks) is that HyperNetworks may be harder to scale for larger models like ResNet50 or transformers, thus limiting their usefulness for lifelong learning use cases.</p>
+ </li>
+</ul>
+
+
+
+
+ Zero-shot Learning by Generating Task-specific Adapters
+
+ 2021-02-01T00:00:00-05:00
+ /site/2021/02/01/Zero-shot Learning by Generating Task-specific Adapters
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces HYPTER - a framework for zero-shot learning (ZSL) in text-to-text transformer models by training a <a href="https://shagunsodhani.com/papers-I-read/HyperNetworks"><strong>Hyp</strong>erNetwork</a> to generate task-specific <a href="https://arxiv.org/abs/1902.00751">adap<strong>ter</strong>s</a> from task descriptions.</p>
+ </li>
+ <li>
+ <p>The focus is on <em>in-task</em> zero-shot learning (e.g., learning to predict an unseen class or relation) and not on <em>cross-task</em> learning (e.g., training on sentiment analysis and evaluating on question-answering task).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2101.00420">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="terminology">Terminology</h2>
+
+<ul>
+ <li>
+ <p><em>Task</em> - a NLP task, like classification or question answering.</p>
+ </li>
+ <li>
+ <p><em>Sub-task</em></p>
+
+ <ul>
+ <li>
+ <p>A class/relation/question within a task.</p>
+ </li>
+ <li>
+ <p>Denotes by a tuple $(d, D)$ where $d$ is the language description while $D$ represents the subtask’s dataset.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>Develop ZSL approach for transfer to new subtasks within a task, using the task description available for each subtask.</li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>HYPTER has two main parts:</p>
+
+ <ul>
+ <li>
+ <p>Main network</p>
+
+ <ul>
+ <li>
+ <p>A pretrained text-to-text network</p>
+ </li>
+ <li>
+ <p>Instantiated as a BERT-Base/Large</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>HyperNetwork</p>
+
+ <ul>
+ <li>Generates the weights for adapter networks that will be plugged into the main network.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>HyperNetwork has two parts:</p>
+
+ <ul>
+ <li>
+ <p>Encoder</p>
+
+ <ul>
+ <li>
+ <p>Encodes the task description</p>
+ </li>
+ <li>
+ <p>Instantiated as a RoBERTa-Base model</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Decoder</p>
+
+ <ul>
+ <li>
+ <p>Decodes the encoding into weights for multiple adapters (in parallel)</p>
+ </li>
+ <li>
+ <p>Instantiated as a Feedforward Network</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The model trains in two phases:</p>
+
+ <ul>
+ <li>
+ <p>Main network is trained on all the data by concatenating the task description with the input.</p>
+ </li>
+ <li>
+ <p>Adapters are trained by sampling a task from the train set while keeping the main network frozen.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>While the idea is very promising and interesting, the evaluation felt quite limited. It uses just two datasets <a href="https://leaderboard.allenai.org/zest/submissions/public">Zero-shot learning from Task Descriptions</a> and <a href="https://eval.ai/web/challenges/challenge-page/689/overview">Zero-shot Relation Extraction</a> and shows some improvements over the baseline of directly finetuning with task descriptions as the prompt.</li>
+</ul>
+
+
+
+
+ HyperNetworks
+
+ 2021-01-25T00:00:00-05:00
+ /site/2021/01/25/HyperNetworks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper explores HyperNetworks. The idea is to use one network (HyperNetwork) to generate the weights for another network.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1609.09106">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/hardmaru/supercell/blob/master/supercell.py">Author’s implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<h3 id="static-hypernetworks---hypernetworks-for-cnns">Static HyperNetworks - HyperNetworks for CNNs</h3>
+
+<ul>
+ <li>
+ <p>Consider a $D$ layer CNN where the parameters for the $j^{th}$ layer are stored in a matrix $K^j$ of the shape $N_{in}f_{size} \times N_{out}f_{size}$.</p>
+ </li>
+ <li>
+ <p>The HyperNetwork is implemented as a two-layer linear network where the input is a layer embedding $z^j$, and the output is $K^j$.</p>
+ </li>
+ <li>
+ <p>The first layer (of the HyperNetwork) maps the input to $N_{in}$ different outputs using $N_{in}$ weight matrices.</p>
+ </li>
+ <li>
+ <p>The second layer maps the different $N_{in}$ inputs to $K_{i}$ using a shared matrix. The resulting $N_{in}$ (number of) $K_{i}$ matrices are concatenated to obtain $K^j$.</p>
+ </li>
+ <li>
+ <p>As a side note, HyperNetworks have much fewer params than the network for which it produces weights.</p>
+ </li>
+ <li>
+ <p>In a general case, the kernel dimensions (across layers) are not of the same size but integer multiples of some basic sizes. In that case, the HyperNetwork can generate kernels for the basic size, which can be concatenated to form larger kernels. This would require additional input embeddings but not require a change in the architecture of HyperNetwork.</p>
+ </li>
+</ul>
+
+<h3 id="dynamic-hypernetworks---hypernetworks-for-rnns">Dynamic HyperNetworks - HyperNetworks for RNNs</h3>
+
+<ul>
+ <li>
+ <p>HyperRNNs/HyperLSTMs denote HyperNetworks that generates weights for RNNs/LSTMs.</p>
+ </li>
+ <li>
+ <p>HyperRNNs implement a form of relaxed weight sharing - an alternative to the full weight sharing of the traditional RNNs.</p>
+ </li>
+ <li>
+ <p>At any timestamp $t$, the input to the HyperRNN is the concatenated vector $x_{t}$ (input to the RNN at time $t$) and the hidden state $h_{t-1}$ of the RNN. The output is the weight for the main RNN at timestep $t$.</p>
+ </li>
+ <li>
+ <p>In practice, a <em>weight scaling vector</em> $d$ is used to reduce the memory footprint, which would otherwise be $dim$ times the memory of a standard RNN. $dim$ is the dimensionality of the embedding vector $z_j$.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>HyperNetworks are used to train standard CNNs for MNIST and ResNets for CIFAR 10. In these experiments, HyperNetworks slightly underperform the best performing models but uses much fewer parameters.</p>
+ </li>
+ <li>
+ <p>HyperLSTMs trained on the Penn Treebank dataset and Hutter Prize Wikipedia dataset outperform the stacked LSTMs and perform similar to layer-norm LSTMs. Interestingly, using HyperLSTMs with layer-norm improves performance over HyperLSTMs.</p>
+ </li>
+ <li>
+ <p>Given the similar performance of HyperLSTMs and layer-norm LSTMs, the paper conducted an ablation study to understand if HyperLSTMs learned a weight adjustment policy similar to the statistics-based approach used by layer-norm LSTMs.</p>
+
+ <ul>
+ <li>However, the analysis of the histogram of the hidden states suggests that using layer-norm reduces the saturation effect while in HyperLSTMs, the cell is saturated most of the time. This indicates that the two models are learning different policies.</li>
+ </ul>
+ </li>
+ <li>
+ <p>HyperLSTMs are also evaluated for handwriting sequence generation by training in the IAM online handwriting dataset.</p>
+
+ <ul>
+ <li>While HyperLSTMs are quite effective on this task, combining them with layer-norm degrades the performance.</li>
+ </ul>
+ </li>
+ <li>
+ <p>On the WMT’14 En-to-Fr machine translation task, HyperLSTMs outperform LSTM based approaches.</p>
+ </li>
+</ul>
+
+
+
+
+ Energy-based Models for Continual Learning
+
+ 2021-01-18T00:00:00-05:00
+ /site/2021/01/18/Energy-based Models for Continual Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes to use Energy-based Models (EBMs) for Continual Learning.</p>
+ </li>
+ <li>
+ <p>In classification tasks, the standard approach uses a cross-entropy objective function along with a normalized probability distribution.</p>
+ </li>
+ <li>
+ <p>However, cross-entropy reduces all negative classes’ likelihood when updating the model for a given sample, potentially leading to catastrophic forgetting.</p>
+ </li>
+ <li>
+ <p>Classification can be seen as learning an EBM across separate classes.</p>
+ </li>
+ <li>
+ <p>During an update, the energy for a pair of samples and its ground truth class decreases while the energy corresponding to the pairs of sample and negative classes increases.</p>
+ </li>
+ <li>
+ <p>Unlike the cross-entropy loss, EBMs allow choosing the negative classes to update.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2011.12216">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="applications-of-ebms-for-continual-learning">Applications of EBMs for Continual Learning</h2>
+
+<ul>
+ <li>
+ <p>EBMs can be used for class-incremental learning without requiring a replay-buffer or generative model for replay.</p>
+ </li>
+ <li>
+ <p>EBMs can be used for continual learning in setups without task boundaries, i.e., setups where the data distribution can change without a clear separation between tasks.</p>
+ </li>
+</ul>
+
+<h2 id="ebms">EBMs</h2>
+
+<ul>
+ <li>
+ <p>Boltzman distribution is used to define the conditional likelihood of label $y$, given an input $x$. ie, $p(y|x) = \frac{exp(E(x, y))}{Z(x)}$ where $Z(x) = \sum_{y \in Y}(-E(x, y))$. Here $E$ is the learnt energy function that maps an input-label pair to a scalar energy value.</p>
+ </li>
+ <li>
+ <p>During training, the contrastive divergence loss is used.</p>
+ </li>
+ <li>
+ <p>During inference, the class, for which the input-class pair has the least energy, is selected as the predicted class.</p>
+ </li>
+</ul>
+
+<h2 id="ebms-for-continual-learning">EBMs for Continual Learning</h2>
+
+<h3 id="selection-of-negative-samples">Selection of Negative Samples</h3>
+
+<ul>
+ <li>
+ <p>The paper considers several strategies for the selection of negative samples:</p>
+
+ <ul>
+ <li>
+ <p>one negative class per sample. The negative class is sampled from the current batch of data. This selection approach performs best.</p>
+ </li>
+ <li>
+ <p>all the negative classes in a batch are used for creating the negative samples.</p>
+ </li>
+ <li>
+ <p>all the classes seen so far in training are used as the negative samples. This approach works the worst in practice.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Given the flexibility of sampling the negative classes, EBMs can be used in the boundary-agnostic setups (where the data distribution can change smoothly without an explicit task boundary).</p>
+ </li>
+</ul>
+
+<h3 id="energy-network">Energy Network</h3>
+
+<ul>
+ <li>
+ <p>EBMs take both the sample and the class as the input. The class can be treated as an attention filter to select the most relevant information between the sample and the class.</p>
+ </li>
+ <li>
+ <p>In theory, EBMs can train for any number of classes without knowing the number of classes beforehand. This is an advantage over the softmax-based approaches, where adding new classes requires changing the size of the softmax output layer.</p>
+ </li>
+</ul>
+
+<h3 id="inference">Inference</h3>
+
+<ul>
+ <li>During inference, all the classes seen so far are evaluated via the energy function. The class, which corresponds to the least energy sample-class pair, is returned as the selected class.</li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="datasets">Datasets</h3>
+
+<ul>
+ <li>
+ <p>Split MNIST</p>
+ </li>
+ <li>
+ <p>Permuted MNIST</p>
+ </li>
+ <li>
+ <p>CIFAR-10</p>
+ </li>
+ <li>
+ <p>CIFAR-100</p>
+ </li>
+</ul>
+
+<h3 id="results-in-boundary-aware-setting">Results in Boundary-Aware Setting</h3>
+
+<ul>
+ <li>
+ <p>The paper outperforms the standard continual learning approaches that neither uses a replay-buffer nor a generative model.</p>
+ </li>
+ <li>
+ <p>Additionally, the paper shows that for the same number of parameters, the effective capacity of EMB models is higher than the effective capacity of standard classification models.</p>
+ </li>
+ <li>
+ <p>The paper also shows that standard classification models tend to assign a high probability to new classes for both old and new data. EBMs assign the probability more uniformly (and correctly) across the classes.</p>
+ </li>
+ <li>
+ <p>In an ablation study, the paper shows that both label conditioning and contrastive divergence loss help in improving the performance of EBMs.</p>
+ </li>
+</ul>
+
+<h3 id="results-in-boundary-agnostic-setting">Results in Boundary-Agnostic Setting</h3>
+
+<ul>
+ <li>The performance gains in the boundary-agnostic setting are even more significant than the improvements in the boundary-aware setting.</li>
+</ul>
+
+
+
+
+ GPipe - Easy Scaling with Micro-Batch Pipeline Parallelism
+
+ 2021-01-11T00:00:00-05:00
+ /site/2021/01/11/GPipe - Easy Scaling with Micro-Batch Pipeline Parallelism
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces GPipe, a pipeline parallelism library for scaling networks that can be expressed as a sequence of layers.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1811.06965">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="design">Design</h2>
+
+<ul>
+ <li>
+ <p>Consider training a deep neural network with <em>L</em> layers using <em>K</em> accelerators (say GPUs).</p>
+ </li>
+ <li>
+ <p>Each of the <em>i<sup>th</sup></em> layer has its <em>forward</em> function <em>f<sub>i</sub></em>, <em>backward</em> function <em>b<sub>i</sub></em>, weights <em>w<sub>i</sub></em> and a cost <em>c<sub>i</sub></em> (say the memory footprint or computational time).</p>
+ </li>
+ <li>
+ <p>GPipe partitions this network into <em>K</em> cells and places the <em>i<sup>th</sup></em> cell on the <em>i<sup>th</sup></em> accelerator. Output from the <em>i<sup>th</sup></em> accelerator is passed to the <em>i+1<sup>th</sup></em> accelerator as input.</p>
+ </li>
+ <li>
+ <p>During the forward pass, the input batch (of size <em>N</em>) is divided into <em>M</em> equal micro-batches. These micro-batches are pipelined through the <em>K</em> accelerators one after another.</p>
+ </li>
+ <li>
+ <p>During the backward pass, gradients are computed for each micro-batch. The gradients are accumulated and applied at the end of each minibatch.</p>
+ </li>
+ <li>
+ <p>In batch normalization, the statistics are computed over each micro-batch (used during training) and mini-batch (used during evaluation).</p>
+ </li>
+ <li>
+ <p>Micro-batching improves over the naive mode parallelism approach by reducing the underutilization of resources (due to the network’s sequential dependencies).</p>
+ </li>
+</ul>
+
+<h2 id="performance-optimization">Performance Optimization</h2>
+
+<ul>
+ <li>
+ <p>GPipe supports re-materialization (or checkpointing), i.e., during the forward pass, only the output activations (at partition boundaries) are stored.</p>
+ </li>
+ <li>
+ <p>During backward pass, the forward function is recomputed at each accelerator. This trades off the memory requirement with increased time.</p>
+ </li>
+ <li>
+ <p>One potential downside is that partitioning can introduce some idle time per accelerator (referred to as the bubble overhead). However, with a sufficiently large number of micro-batches ( more than 4 times the number of partitions), the bubble overhead is negligible.</p>
+ </li>
+</ul>
+
+<h2 id="performance-analysis">Performance Analysis</h2>
+
+<ul>
+ <li>
+ <p>Two different types of model architectures are compared: AmoebaNet convolutional model and Transformer sequence-to-sequence model.</p>
+ </li>
+ <li>
+ <p>For AmoebaNet, the size of the largest trainable model (on a single 8GB Cloud TPU v2) increases from 82M to 318M. Further, a 1.8 billion parameter model can be trained on 8 accelerators (25x improvement in size using GPipe).</p>
+ </li>
+ <li>
+ <p>For transformers, GPipe scales the model size to 83.9 B parameters with 128 partitions (298x improvement in size compared to a single accelerator).</p>
+ </li>
+ <li>
+ <p>Since the computation is evenly distributed across transformer layers, the training throughput scales almost linearly with the number of devices.</p>
+ </li>
+ <li>
+ <p>Quantitative experiments on ImageNet and multilingual machine translation show that models can be effectively trained using GPipe.</p>
+ </li>
+</ul>
+
+
+
+
+ Compositional Explanations of Neurons
+
+ 2021-01-04T00:00:00-05:00
+ /site/2021/01/04/Compositional Explanations of Neurons
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper describes a method to explain/interpret the representations learned by individual neurons in deep neural networks.</p>
+ </li>
+ <li>
+ <p>The explanations are generated by searching for logical forms defined by a set of composition operators (like OR, AND, NOT) over primitive concepts (like water).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2006.14032">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="generating-compositional-explanations">Generating compositional explanations</h2>
+
+<ul>
+ <li>
+ <p>Given a neural network <em>f</em>, the goal is to explain a neuron’s behavior (of this network) in human-understandable terms.</p>
+ </li>
+ <li>
+ <p><a href="http://netdissect.csail.mit.edu/">Previous work</a> builds on the idea that a good explanation is a description that identifies the inputs for which the neuron activates.</p>
+ </li>
+ <li>
+ <p>Given a set of pre-defined atomic concepts $c \in C$ and a similarity measure $\delta(n, c)$ where $n$ represents the activation of the $n^{th}$ neuron, the explanation, for the $n^{th}$ neuron, is the concept most similar to $n$.</p>
+ </li>
+ <li>
+ <p>For images, a concept could be represented as an image segmentation map. For example, the water concept can be represented by the segments of the images that show water.</p>
+ </li>
+ <li>
+ <p>The similarity can be measured by first thresholding the neuron activations (to get a neuron mask) and then computing the IoU score (or Jaccard Similarity) between the neuron mask and the concept.</p>
+ </li>
+ <li>
+ <p>One limitation of this approach is that the explanations are restricted to pre-defined concepts.</p>
+ </li>
+ <li>
+ <p>The paper expands the set of candidate concepts by considering the logical forms of the atomics concepts.</p>
+ </li>
+ <li>
+ <p>In theory, the search space would explode exponentially. In practice, it is restricted to explanations with at most $N$ atomics concepts, and beam search is performed (instead of exhaustive search).</p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p><strong>Image Classification Setup</strong></p>
+
+ <ul>
+ <li>
+ <p>Neurons from the final 512-unit convolutional layer of a ResNet-18 trained on the <a href="https://ieeexplore.ieee.org/abstract/document/7968387">Places365 dataset</a>.</p>
+ </li>
+ <li>
+ <p>Probing for concepts from <a href="https://openaccess.thecvf.com/content_cvpr_2017/html/Zhou_Scene_Parsing_Through_CVPR_2017_paper.html">ADE20k scenes dataset</a> with atomic concepts defined by annotations in the <a href="http://netdissect.csail.mit.edu/">Broden dataset</a></p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>NLI Setup</strong></p>
+
+ <ul>
+ <li>
+ <p>BiLSTM baseline followed by MLP layers trained on <a href="https://nlp.stanford.edu/projects/snli/">Stanford Natural Language Inference (SNLI) corpus</a>.</p>
+ </li>
+ <li>
+ <p>Probing the penultimate hidden layer (of the MLP component) for sentence-level explanations.</p>
+ </li>
+ <li>
+ <p>Concepts are created using the 2000 most common words in the validation split of the SNLI dataset.</p>
+ </li>
+ <li>
+ <p>Additional concepts are created based on the lexical overlap between premise and hypothesis.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="do-neurons-learn-compositional-concepts">Do neurons learn compositional concepts</h2>
+
+<ul>
+ <li>
+ <p><strong>Image Classification Setup</strong></p>
+
+ <ul>
+ <li>
+ <p>As $N$ increases, the mean IoU increases (i.e., the explanation quality increases) though the returns become diminishing beyond $N=10$.</p>
+ </li>
+ <li>
+ <p>Manual inspection of 128 neurons and their length 10 explanations show that 69% neurons learned some meaningful combination of concepts, while 31% learned some unrelated concepts.</p>
+ </li>
+ <li>
+ <p>The meaningful combination of concepts include:</p>
+
+ <ul>
+ <li>
+ <p>perceptual abstraction that is also lexically coherent (e.g., “skyscraper OR lighthouse OR water tower”).</p>
+ </li>
+ <li>
+ <p>perceptual abstraction that is not lexically coherent (e.g., “cradle OR autobus OR fire escape”).</p>
+ </li>
+ <li>
+ <p>specialized abstraction of the form L1 AND NOT L2 (e.g. (water OR river) AND NOT blue).</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>NLI Setup</strong></p>
+
+ <ul>
+ <li>
+ <p>As $N$ increases, the mean IoU increases (as in the image classification setup) though the IoU keeps increasing past $N=30$.</p>
+ </li>
+ <li>
+ <p>Many neurons correspond to lexical features. For example, some neurons are gender-sensitive or activate for verbs like sitting, eating or sleeping. Some neurons are activated when the lexical overlap between premise and hypothesis is high.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="do-interpretable-neurons-contribute-to-model-accuracy">Do interpretable neurons contribute to model accuracy?</h2>
+
+<ul>
+ <li>
+ <p>In image classification setup, the more interpretable the neuron is, the more accurate is the model (when the neuron is active).</p>
+ </li>
+ <li>
+ <p>However, the opposite trend is seen in NLI models. i.e., the more interpretable neurons are less accurate.</p>
+ </li>
+ <li>
+ <p>Key takeaway - interpretability (as measured by the paper) is not correlated with performance. Given a concept space, the identified behaviors may be correlated or anti-correlated with the model’s performance.</p>
+ </li>
+</ul>
+
+<h2 id="targeting-explanations-to-change-model-behavior">Targeting explanations to change model behavior</h2>
+
+<ul>
+ <li>
+ <p>The idea is to construct examples that activate (or inhibit) certain neurons, causing a change in the model’s predictions.</p>
+ </li>
+ <li>
+ <p>These adversarial examples are referred to as “copy-paste” adversarial examples.</p>
+ </li>
+ <li>
+ <p>For example, the neuron corresponding to “(water OR river) AND (NOT blue)” is a major contributor for detecting “swimming hole” classes. An adversarial example is created by making the water blue. This prompts the model to predict “grotto” instead of “swimming hole.”</p>
+ </li>
+ <li>
+ <p>Similarly, in the NLI model, a neuron detects the word “nobody” in the hypothesis as highly indicative of contradiction. An adversarial example can be created by adding the word “nobody” to the hypothesis, prompting the model to predict contradiction while the true label should be neutral.</p>
+ </li>
+ <li>
+ <p>These observations support the hypothesis that one can use explanations to create adversarial examples.</p>
+ </li>
+</ul>
+
+
+
+
+ Design patterns for container-based distributed systems
+
+ 2020-12-21T00:00:00-05:00
+ /site/2020/12/21/Design patterns for container-based distributed systems
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper describes three design patterns for container-based distributed systems: single-container pattern, single-node pattern, and multi-node pattern.</li>
+ <li><a href="https://www.usenix.org/conference/hotcloud16/workshop-program/presentation/burns">Link to the paper</a></li>
+</ul>
+
+<h2 id="single-container-management-patterns">Single-container management patterns</h2>
+
+<ul>
+ <li>Traditionally, containers have exposed three functions: run, pause and stop.</li>
+ <li>A richer API can be implemented to provide fine-grained control to system developers and operators.</li>
+ <li>Similarly, much more application information (including monitoring metrics) can be exposed.</li>
+ <li>The container interface can be used to define a contract for a complex lifecycle. For example, instead of arbitrarily shutting down the container, the system could signal that it will be terminated, giving the container some time to perform some cleanup/follow-up actions.</li>
+</ul>
+
+<h2 id="single-node-multi-container-pattern">Single-node, multi-container pattern</h2>
+
+<h3 id="sidecar-pattern">Sidecar pattern</h3>
+
+<ul>
+ <li>Multiple containers extend and enhance the main container.</li>
+ <li>For example, a web-server serves from the local disk (main container) while a side container updates the data.</li>
+ <li>Benefits:
+ <ul>
+ <li>independent development, deployment, and scaling of containers</li>
+ <li>possibility of combining different type of containers</li>
+ <li>failure containment boundary, i.e., one failing container, need not bring down the entire system.</li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="ambassador-pattern">Ambassador pattern</h3>
+
+<ul>
+ <li>Proxy communication to and from the main container with the ambassador hiding the complexities of communication with a distributed (multi-shard system) that may be written in a different language.</li>
+</ul>
+
+<h3 id="adapter-pattern">Adapter pattern</h3>
+
+<ul>
+ <li>Standardize output and interfaces across the containers to provide a simple, homogenized view to external applications.</li>
+ <li>A common example is using a single tool for collecting/processing metrics from multiple applications.</li>
+ <li>This is different from the adapter pattern, which aims to provide a simplified view of the external world to an application.</li>
+</ul>
+
+<h2 id="multi-node-application-patterns">Multi-node application patterns</h2>
+
+<h3 id="leader-election-pattern">Leader election pattern</h3>
+
+<ul>
+ <li>In a sharded (or replication-based) system, the system may have to elect a leader (or multiple leaders) among the replicas (or shards).</li>
+ <li>Instead of using a leader election library, a leader election container can be used (that communicates with other containers over, say, HTTP). This removes the restriction of using a leader election library compatible with the containers (e.g., using the same language).</li>
+</ul>
+
+<h3 id="work-queue-pattern">Work queue pattern</h3>
+
+<ul>
+ <li>A work coordinator container can queue different containers, each of which may have a different implementation or dependencies, thus removing the restriction that all the works use the same runtime.</li>
+</ul>
+
+<h3 id="scattergather-pattern">Scatter/gather pattern</h3>
+
+<ul>
+ <li>An external client sends a request to a root container.</li>
+ <li>This container fans out the request to many containers that may perform the computation in parallel.</li>
+ <li>The root container gathers these parallel computations’ results and aggregates them into a response to the external client.</li>
+</ul>
+
+
+
+
+ Cassandra - a decentralized structured storage system
+
+ 2020-12-14T00:00:00-05:00
+ /site/2020/12/14/Cassandra - a decentralized structured storage system
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>Cassandra is a distributed storage system that runs over cheap commodity servers and handles high write throughput while maintaining low latency for read operations.</li>
+ <li>At the time of writing, it was used to support the search for Facebook Inbox.</li>
+ <li><a href="https://dl.acm.org/doi/10.1145/1773912.1773922">Link to the paper</a></li>
+ <li><a href="https://cassandra.apache.org/">Link to the implementation</a></li>
+</ul>
+
+<h2 id="data-model">Data Model</h2>
+
+<ul>
+ <li>A table is a distributed multidimensional map.</li>
+ <li>The key is a string (generally 16-36 bytes long), while the value is a structured object.</li>
+ <li>Every operation under a single row key is atomic per replica.</li>
+ <li>Columns are grouped together into sets called column families.</li>
+ <li>There are two types of columns families:
+ <ul>
+ <li>Simple families.</li>
+ <li>Super column families: visualized as a column family within a column family.</li>
+ </ul>
+ </li>
+ <li>Columns can be sorted by name or time (used to display results in time sorted order).</li>
+ <li>The API supports insert, get and delete operations.</li>
+</ul>
+
+<h2 id="system-architecture">System Architecture</h2>
+
+<h3 id="handling-requests">Handling Requests</h3>
+
+<ul>
+ <li>Any read/write request gets routed to any node in the cluster. The node determines the replicas for a given key and routes the request.</li>
+ <li>For write query, the system waits for a quorum of replicas to acknowledge the writes’ completion.</li>
+ <li>For read query, the system either routes the requests to the closest replica (might fetch stale results) or routes the requests to all replicas and waits for a quorum of responses.</li>
+</ul>
+
+<h3 id="partitioning">Partitioning</h3>
+
+<ul>
+ <li>Cassandra partitions data across the cluster using consistent hashing with an order-preserving hash function.</li>
+ <li>The hash function’s output range is treated as a fixed circular ring, and each node is assigned a random position on the ring.</li>
+ <li>An incoming request specifies a key used to route requests.</li>
+ <li>One benefit of this approach is that the addition/removal of a node only affects its immediate neighbors.</li>
+ <li>However, randomly assigning nodes leads to non-uniform data and load distribution.</li>
+ <li>Cassandra uses the load information and moves lightly loaded nodes to reduce the load on other nodes.</li>
+</ul>
+
+<h3 id="replication">Replication</h3>
+
+<ul>
+ <li>Each data item is replicated at N hosts, where N is the per-instance replication factor.</li>
+ <li>Cassandra supports the following replication policies: Rack Unaware, Rack Aware (within a datacenter), and Datacenter Aware.</li>
+ <li>For “Rack Aware” and “Datacenter Aware” strategies, Zookeeper elects a leader among the nodes and holds metadata about which range a node is responsible for.</li>
+ <li>In case of node failure and network partitions, the quorum requirements are relaxed.</li>
+</ul>
+
+<h3 id="membership">Membership</h3>
+
+<ul>
+ <li>Cluster membership is based on Scuttlebutt, a very efficient anti-entropy Gossip based mechanism.</li>
+ <li>Cassandra uses a modified version of $\phi$ Accrual Failure Detector for detecting failures, which provides the suspicion level (of failure) for each node.</li>
+</ul>
+
+<h3 id="bootstrapping">Bootstrapping</h3>
+
+<ul>
+ <li>A node, starting for the first time, chooses a random position in the ring.</li>
+ <li>This information is persisted on the local disk, on Zookeeper, and gossiped around the cluster (so any node can route any query in the cluster).</li>
+ <li>During bootstrapping, the newly joined node reads a list of contact points (within the cluster) using a configuration file.</li>
+</ul>
+
+<h3 id="local-persistence">Local Persistence</h3>
+
+<ul>
+ <li>Generally, a write operation involves a write into a commit log (for durability and recoverability), followed by a write into the in-memory data structures.</li>
+ <li>A read operation starts with querying the in-memory data and then looks into the filesystem.</li>
+ <li>Read queries on the filesystem use bloom filters.</li>
+ <li>Column indices are maintained to make it faster to look up relevant columns.</li>
+</ul>
+
+<h2 id="implementation-details">Implementation Details</h2>
+
+<ul>
+ <li>Components implemented in Java.</li>
+ <li>System control messages use UDP while messages for replication and request routing uses TCP.</li>
+ <li>A new commit log is rolled out after the older one exceeds 128MB of size.</li>
+ <li>All the data is indexed using a primary key.</li>
+ <li>Data on the disk is chunked into sequences of blocks. Each block contains at most 128 keys and is demarcated by a block index.</li>
+ <li>When the data is written to the disk, a block index is generated and maintained in the memory for faster access.</li>
+ <li>A compaction process is performed to merge multiple files (on disk) into one file.</li>
+</ul>
+
+<h2 id="practical-experience">Practical Experience</h2>
+
+<ul>
+ <li>Data from MySQL servers is added to Cassandra using MapReduce processes.</li>
+ <li>Although Cassandra is a completely decentralized system, adding some coordination (via Zookeeper) is helpful.</li>
+ <li>For Inbox Search, a per-user index is maintained for all the messages.</li>
+ <li>For “term search”, the key is the userid, and the words in the message become the super column.</li>
+ <li>For searching all the messages ever sent/received by a user, the key is the userid, and the recipient ids are the super columns.</li>
+</ul>
+
+
+
+
+ CAP twelve years later - How the rules have changed
+
+ 2020-12-07T00:00:00-05:00
+ /site/2020/12/07/CAP twelve years later - How the rules have changed
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The CAP theorem states that any system sharing data over the network can only have at most two (out of three) desirable properties:</p>
+
+ <ul>
+ <li>
+ <p>consistency (C), i.e., a single, up-to-date copy of the data;</p>
+ </li>
+ <li>
+ <p>high availability (A) of that data (for updates); and</p>
+ </li>
+ <li>
+ <p>tolerance to network partitions (P).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>This “2 of 3” formulation is misleading as it oversimplifies the interplay between properties.</p>
+ </li>
+ <li>
+ <p><a href="https://ieeexplore.ieee.org/abstract/document/6133253">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="acid-vs-base">ACID vs. BASE</h2>
+
+<ul>
+ <li>
+ <p>ACID is a design philosophy that focuses on consistency as reflected in the traditional relational databases.</p>
+ </li>
+ <li>
+ <p>The four properties in ACID are:</p>
+
+ <ul>
+ <li>
+ <p>Atomicity (A), i.e., the operations are atomic, and either the entire operation succeeds or none of it succeeds.</p>
+ </li>
+ <li>
+ <p>Consistency (C), i.e., a transaction preserves all the rules. Note that the consistency in CAP is a subset of consistency in ACID.</p>
+ </li>
+ <li>
+ <p>Isolation (I), i.e., transactions occur in isolation and do not affect each other.</p>
+ </li>
+ <li>
+ <p>Durability (D), i.e., the transactions are durable irrespective of system failure.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>BASE is an alternate design philosophy that focuses on availability as reflected in the NoSQL databases.</p>
+ </li>
+ <li>
+ <p>The four properties in BASE are:</p>
+
+ <ul>
+ <li>
+ <p>Basic Availability (BA), i.e., the database appears to work most of the time.</p>
+ </li>
+ <li>
+ <p>Soft state (S), i.e., the system’s state can change over time as it becomes eventually consistent.</p>
+ </li>
+ <li>
+ <p>Eventual consistency (E), i.e., the system will eventually become consistent over time.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="cap-confusion">CAP confusion</h2>
+
+<ul>
+ <li>
+ <p>Generally, partitionability is seen as a must-have, thus reducing the choice to be between availability and consistency.</p>
+ </li>
+ <li>
+ <p>This view is somewhat misleading because the choice between C, A, and P is not binary but granular.</p>
+ </li>
+ <li>
+ <p>The choice between C and A can occur at various granularity levels, and different components (of a larger system) can prioritize different aspects.</p>
+ </li>
+ <li>
+ <p>Similarly, the CAP theorem generally ignores latency even though it is closely related to partitionability. For example, failing to achieve consistency within a time-bound (i.e., latency) implies a partition.</p>
+ </li>
+ <li>
+ <p>In general, there is no global notion of partition - some subset of nodes may experience a partition, and others may not.</p>
+ </li>
+ <li>
+ <p>Once a partition is detected, the system can then choose between C and A.</p>
+ </li>
+</ul>
+
+<h2 id="managing-partitions">Managing Partitions</h2>
+
+<ul>
+ <li>
+ <p>Three-step process for managing partitions:</p>
+
+ <ul>
+ <li>
+ <p>Detect the start of a partition.</p>
+ </li>
+ <li>
+ <p>Enter an explicit partition mode that may limit some operations.</p>
+
+ <ul>
+ <li>
+ <p>Possible strategies:</p>
+
+ <ul>
+ <li>
+ <p>Reduce availability by limiting some operations.</p>
+ </li>
+ <li>
+ <p>Record extra information that can be used during partition recovery.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The strategy depends on the invariants that the system should maintain.</p>
+ </li>
+ <li>
+ <p>For example, if the invariant is that the keys (in a table) should be unique, the system could allow duplicate keys for some time and perform a de-duplication step during partition recovery.</p>
+ </li>
+ <li>
+ <p>A counterexample is a monetary transaction (e.g., charging a credit card). In such cases, the system could disable the operation and record it for performing later. Sometimes this “unavailability” is not visible to the user.</p>
+ </li>
+ <li>
+ <p>History of operations (over replicas across different partitions) can be tracked using version vectors of the form (node, logical time). The system can easily recreate the order in which they were executed (or mark them as being concurrent).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Initiate partition recovery when communication is restored and make the state across the partitions consistent.</p>
+ </li>
+ <li>
+ <p>One common approach is to revert to the state when the partition was detected and apply the operations consistently across all the replicas.</p>
+ </li>
+ <li>
+ <p>This may require some extra effort to merge conflicts.</p>
+ </li>
+ <li>
+ <p>One workaround can be to constrain the use of certain operations so that the system does not encounter merge conflicts during recovery.</p>
+ </li>
+ <li>
+ <p>Sometimes, certain invariants may be violated when the system is in the partition mode and needs to be fixed during recovery.</p>
+ </li>
+ <li>
+ <p>The key takeaway is that when partitions exist, the choice between availability and consistency is not binary, and both can be optimized for.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Consistency Tradeoffs in Modern Distributed Database System Design
+
+ 2020-11-30T00:00:00-05:00
+ /site/2020/11/30/Consistency Tradeoffs in Modern Distributed Database System Design
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>CAP theorem has been influential in the design decisions for distributed databases.</p>
+ </li>
+ <li>
+ <p>However, designers incorrectly assume that the CAP theorem “always” imposes restrictions in terms of the tradeoff between availability and consistency. In contrast, the tradeoff is applicable only in the case of partitions.</p>
+ </li>
+ <li>
+ <p>CAP theorem led to the development of highly available systems with reduced consistency models (and reduced ACID guarantees).</p>
+ </li>
+ <li>
+ <p>Another tradeoff - between latency and consistency - has also been influential for database design.</p>
+ </li>
+ <li>
+ <p>The paper unifies CAP and latency-consistency tradeoffs into a single formulation called PACELC.</p>
+ </li>
+ <li>
+ <p>Note that some of the observations, especially ones about the databases, may be outdated now (the paper was written in 2012). However, the core message is still relevant.</p>
+ </li>
+ <li>
+ <p><a href="https://www.cs.umd.edu/~abadi/papers/abadi-pacelc.pdf">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="latency-consistency-tradeoff">Latency-Consistency Tradeoff</h2>
+
+<ul>
+ <li>
+ <p>Low latency (or high availability) means that the system must replicate data.</p>
+ </li>
+ <li>
+ <p>In case of an update query, three possibilities arise:</p>
+
+ <ul>
+ <li>
+ <p>The system can choose to send data updates to all the replicas at once. This leads to two possibilities:</p>
+
+ <ul>
+ <li>
+ <p>A replica can receive the update queries in an arbitrary order, thus breaking consistency with other replicas.</p>
+ </li>
+ <li>
+ <p>Alternatively, the replicas could use some protocol to agree on the order of updates. However, this can introduce latency.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The update queries can be first sent to a master replica.</p>
+
+ <ul>
+ <li>
+ <p>The master replica can apply the updates and send them to the other replicas using one of the following strategies:</p>
+
+ <ul>
+ <li>
+ <p>Synchronous replication where the master waits for all the updates to be applied to a replica(s). However, this approach introduces latency.</p>
+ </li>
+ <li>
+ <p>Asynchronous replication where the master assumes the update to be complete before it completes. In this case, the latency-consistency tradeoff depends on how read queries are handled:</p>
+
+ <ul>
+ <li>
+ <p>The system can send all read queries to the master. In this case, there are no consistency issues, but additional latency is introduced because all the read queries go to the same replica, thus potentially overloading it.</p>
+ </li>
+ <li>
+ <p>Alternatively, the read query can be served from any replica. While this improves read latency, the results can be inconsistent now.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Use a mix of Synchronous and Asynchronous replication - i.e., some of the write queries are Synchronous, and others are Asynchronous. In this case, the latency-consistency tradeoff depends on how read queries are handled:</p>
+
+ <ul>
+ <li>
+ <p>If the read is routed to at least one replica that has been Synchrnously updated, the consistency can be preserved, with additional latency for discovering the updated replica, etc.</p>
+ </li>
+ <li>
+ <p>If the read query can not be routed to an updated replica (maybe because none of the replicas is updated), then either latency suffers or inconsistent read can be performed.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The update query is first sent to an arbitrary replica.</p>
+
+ <ul>
+ <li>This is the same as the previous case, with the query going to an arbitrary replica instead of the master replica, and suffers from the same latency issues as the last case.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In a nutshell, the tradeoff between latency and consistency is always present, irrespective of network failure.</p>
+ </li>
+ <li>
+ <p>This contrasts with the CAP theorem, which imposes the tradeoff between availability and consistency only in the case of a network partition.</p>
+ </li>
+</ul>
+
+<h2 id="pacelc">PACELC</h2>
+
+<ul>
+ <li>
+ <p>If there is a partition (P), how does the system tradeoff availability (A) and consistency (C); else (E), when the system is running without failures, how does the system tradeoff latency (L) and consistency (C)?</p>
+ </li>
+ <li>
+ <p>The latency-consistency tradeoff (ELC) is relevant only when the data is replicated.</p>
+ </li>
+ <li>
+ <p>Default versions of Dynamo, Cassandra, and Riak were PA/EL systems, i.e., if a partition occurs, availability is prioritized. In the absence of partition, lower latency is prioritized.</p>
+ </li>
+ <li>
+ <p>Fully ACID systems (VoltDB, H-Store, and Megastore) and others like BigTable and HB are PC/EC, i.e., they prioritize consistency and give up availability and latency.</p>
+ </li>
+ <li>
+ <p>MongoDB can be classified as a PA/EC system, while PNUTS is a PC/EL system.</p>
+ </li>
+</ul>
+
+
+
+
+ Exploring Simple Siamese Representation Learning
+
+ 2020-11-23T00:00:00-05:00
+ /site/2020/11/23/Exploring Simple Siamese Representation Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper shows that Siamese networks can be used for unsupervised learning with images without needing techniques like negative sample pairs, large batch training, or momentum encoders. The training mechanism is referred to as the SimSiam method.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2011.10566">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="method">Method</h2>
+
+<ul>
+ <li>
+ <p>Given an input image <em>x</em>, create two augmented views <em>x1</em> and <em>x2</em>.</p>
+ </li>
+ <li>
+ <p>These views are processed by an encoder network <em>f</em>.</p>
+ </li>
+ <li>
+ <p>One of the views (say <em>x1</em>) is processed by the encoder <em>f</em> as well as a predictor MLP <em>h</em> to obtain a projection <em>p1</em> ie <em>p1 = h(f(x1))</em>.</p>
+ </li>
+ <li>
+ <p>The second view (<em>x2</em>) is processed only by the encoder <em>f</em> to obtain an encoding <em>z2</em> i.e., <em>z2 = f(x2)</em>.</p>
+ </li>
+ <li>
+ <p>Negative cosine similarity is minimized between <em>p1</em> and <em>z2</em> with the catch that the resulting gradients are not used to update the encoder via <em>z2</em>. I.e., Loss = <em>D(p1, stopgrad(z2))</em> where <em>D</em> is the negative cosine similarity and <em>stopgrad</em> is an operation that stops the flow of gradients.</p>
+ </li>
+ <li>
+ <p>In practice, both <em>p1, z2</em> and <em>p2, z1</em> pairs are used for computing the loss. ie Loss = <em>0.5 * (D(p1, stopgrad(z2)) + D(p2, stopgrad(z1)))</em>.</p>
+ </li>
+</ul>
+
+<h2 id="implementation-details">Implementation Details</h2>
+
+<ul>
+ <li>
+ <p>Encoder uses batch norm in all the layers (including output) while projection MLP uses batch norm only in the hidden layers.</p>
+ </li>
+ <li>
+ <p>SGD optimizer with learning rate as <em>0.05 * batchsize / 256</em>, cosine learning rate decay schedule and SGD momentum = 0.9.</p>
+ </li>
+ <li>
+ <p>Unsupervised pretraining on the ImageNet dataset followed by training a supervised linear classifier on the frozen representations.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Stop-gradient operation is necessary to avoid a degenerate solution. Without stop-gradient, the model maps all inputs to a constant <em>z</em>.</p>
+ </li>
+ <li>
+ <p>If the projection layer is removed, the method does not work (because of the loss’s symmetric nature). If the loss is also made asymmetric, the method still does not work without the projection layer. However, asymmetric loss + projection layer works.</p>
+ </li>
+ <li>
+ <p>Keeping the projection layer fixed (i.e., not updating during training) avoids collapse but leads to poor validation performance.</p>
+ </li>
+ <li>
+ <p>Training the projection layer with a constant learning rate works better in practice, likely because the projection layer needs to keep adapting before the encoder layer is sufficiently trained.</p>
+ </li>
+ <li>
+ <p>The method works well across different batch sizes.</p>
+ </li>
+ <li>
+ <p>Removing batch norm layers from all the layers in all the networks does not lead to collapse, though the model’s performance degrades on the validation dataset. Adding batch norm to the hidden layers alone is sufficient.</p>
+ </li>
+ <li>
+ <p>Adding batch norm to the encoder’s output further improves the performance but adding batch norm to all the layers of all the networks makes the training unstable, with the loss oscillating.</p>
+ </li>
+ <li>
+ <p>Overall, while batch norm helps to improve performance, it is not sufficient to avoid collapse.</p>
+ </li>
+ <li>
+ <p>The setup does not collapse when the cross-entropy loss replaces the cosine loss.</p>
+ </li>
+</ul>
+
+<h2 id="what-is-simsiam-solving">What is SimSiam solving?</h2>
+
+<ul>
+ <li>
+ <p>Given that the stop-gradient operation seems to be the critical ingredient for avoiding collapse, the paper hypothesizes that SimSiam is solving a different optimization problem.</p>
+ </li>
+ <li>
+ <p>The hypothesis is that SimSiam is implementing an Expectation-Maximisation (EM) algorithm with two sets of variables and two underlying sub-problems.</p>
+ </li>
+ <li>
+ <p>The paper performs several experiments to test this hypothesis. For example, they consider <em>k</em> SGD steps for the first problem before performing an update for the second problem, showing that the alternating optimization is a valid formulation, of which SimSiam is a particular case.</p>
+ </li>
+</ul>
+
+<h2 id="comparison-to-other-methods">Comparison to other methods</h2>
+
+<ul>
+ <li>
+ <p>SimSiam achieves the highest accuracy among SimCLR, MoCo, BYOL, and SwAV for training under 100 epochs. However, it lags behind other methods when trained longer.</p>
+ </li>
+ <li>
+ <p>SimSiam’s representations are transferable beyond the ImageNet tasks.</p>
+ </li>
+ <li>
+ <p>Adding projection layer and stop-gradient operator to SimCLR does not improve its performance.</p>
+ </li>
+</ul>
+
+
+
+
+ Data Management for Internet-Scale Single-Sign-On
+
+ 2020-11-16T00:00:00-05:00
+ /site/2020/11/16/Data Management for Internet-Scale Single-Sign-On
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper describes the architecture of an erstwhile single-sign-on (SSO) service used by Google, called Google Accounts (2006).</p>
+ </li>
+ <li>
+ <p>Note that some of the metrics and design decisions may be outdated now (the paper was written in 2006). However, the core message is still relevant.</p>
+ </li>
+ <li>
+ <p><a href="https://www.usenix.org/legacy/event/worlds06/tech/prelim_papers/perl/perl.pdf">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="operational-constraints">Operational Constraints</h2>
+
+<ul>
+ <li>
+ <p>SSO’s availability affects the availability of all applications that require user sign-in.</p>
+ </li>
+ <li>
+ <p>Generally, systems can achieve high availability by sacrificing consistency, but given the nature of SSO (matching username/passwords), providing an inconsistent view is not a good option, and single-copy consistency is a usability requirement.</p>
+ </li>
+</ul>
+
+<h2 id="berkeley-db">Berkeley DB</h2>
+
+<ul>
+ <li>
+ <p>Berkeley DB is an embedded, high-performance, scalable, transactional storage system for key-value data and provides both keyed and sequential lookup.</p>
+ </li>
+ <li>
+ <p>It provides a primary copy replication model with a single writer (called master) and multiple read-only replicas.</p>
+ </li>
+ <li>
+ <p>All writes are sent to the master, which first applies the changes and then propagates them to the replicas.</p>
+ </li>
+ <li>
+ <p>The master and the replicas have identical logs, and in case of master failure, a new master is elected from the replicas.</p>
+ </li>
+ <li>
+ <p>Some synchronization may be needed between the replicas in case, e.g., the master dies in between a transaction.</p>
+ </li>
+</ul>
+
+<h2 id="sso-architecture">SSO Architecture</h2>
+
+<ul>
+ <li>
+ <p>SSO service maps usernames to user account data and services to service-specific data.</p>
+ </li>
+ <li>
+ <p>The SSO database is partitioned into shards, where each shard is a replicated Berkeley DB (having 5 to 15 replicas).</p>
+ </li>
+ <li>
+ <p>Each replica stores the data in a B+-link tree data structure.</p>
+ </li>
+ <li>
+ <p>Consistent reads must go to the master, while non-master replicas can serve “ stale” reads.</p>
+ </li>
+ <li>
+ <p>In the case of larger replication groups (say 15 replicas), only a subset of replicas can become master (“electable replicas”).</p>
+ </li>
+ <li>
+ <p>In general, replicas are spread geographically to handle machine-failure, network-failure, and data center-failure.</p>
+ </li>
+ <li>
+ <p>Replicas in a share are kept close to reduce the communication latency, which affects the time to commit a write operation or electing a new master.</p>
+ </li>
+ <li>
+ <p>Some of the shards implement ID-map, i.e., map of username to userid and userid to shards.</p>
+ </li>
+</ul>
+
+<h2 id="database-integration">Database Integration</h2>
+
+<ul>
+ <li>Berkeley DB leaves decisions regarding quorums, leases, etc., up to the application.</li>
+</ul>
+
+<h3 id="quorums">Quorums</h3>
+
+<ul>
+ <li>
+ <p>SSO chooses a quorum protocol that guarantees that updates are never lost.</p>
+ </li>
+ <li>
+ <p>For the write queries, the master waits for a positive acknowledgment from a majority of the replicas, including itself, before marking the query as completed.</p>
+ </li>
+ <li>
+ <p>When selecting a new leader, SSO requires a majority of replicas to agree. Moreover, Berkeley DB elections always choose a replica with the latest log entry during an election, thus guaranteeing that the new master’s log will include all the previous master’s updates.</p>
+ </li>
+</ul>
+
+<h3 id="leases">Leases</h3>
+
+<ul>
+ <li>
+ <p>The master holds a <em>master lease</em> when responding to read queries and refreshes this lease periodically by communicating with a majority of replicas.</p>
+ </li>
+ <li>
+ <p>The lease guarantees that the master is not returning stale data if a partition or failure causes the master to lose its mastership, i.e., holding the lease guarantees that the master is still the master.</p>
+ </li>
+ <li>
+ <p>Moreover, elections can not be completed within the lease timeout interval.</p>
+ </li>
+</ul>
+
+<h3 id="replica-group-membership">Replica Group Membership</h3>
+
+<ul>
+ <li>
+ <p>SSO maintains a replica configuration containing the logical (DNS) name and IP address of each replica.</p>
+ </li>
+ <li>
+ <p>In case of any changes to the configuration, the changes are specified in a file that the master reads periodically.</p>
+ </li>
+ <li>
+ <p>If the configuration changes, the master initiates a configuration change and update the database.</p>
+ </li>
+ <li>
+ <p>Non-master replicas can get the new configuration from the database.</p>
+ </li>
+ <li>
+ <p>A new replica or a replica that lost state (say due to a failure) starts as a non-voting replica and can not participate in an election till it has caught up with the master as of the time the replica joined (again).</p>
+ </li>
+</ul>
+
+
+
+
+ Searching for Build Debt - Experiences Managing Technical Debt at Google
+
+ 2020-11-09T00:00:00-05:00
+ /site/2020/11/09/Searching for Build Debt - Experiences Managing Technical Debt at Google
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper describes the efforts to control and repay the technical debt in the build system at Google (called the Build Debt).</p>
+ </li>
+ <li>
+ <p>Guiding Principles:</p>
+
+ <ul>
+ <li>
+ <p>Automate techniques to analyze and fix issues that contribute to technical debt.</p>
+ </li>
+ <li>
+ <p>Make it easier to do the right thing as developers can incur technical debt unknowingly.</p>
+ </li>
+ <li>
+ <p>Make it hard to do the wrong thing, e.g., by building stricter checks into the build process.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Note that some of the metrics and design decisions may be outdated now (the paper was written in 2012). However, the core message is still relevant.</p>
+ </li>
+ <li>
+ <p><a href="https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/37755.pdf">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="googles-build-system-debt">Google’s Build System Debt</h2>
+
+<ul>
+ <li>
+ <p>BUILD files encapsulate the specifications for building software.</p>
+ </li>
+ <li>
+ <p>Generally, these files are maintained manually, and the dependencies may not be up-to-date over time.</p>
+ </li>
+ <li>
+ <p>In extreme cases, some of the build targets are not built for months. Such targets are called zombie targets.</p>
+ </li>
+ <li>
+ <p>Originally, any project could depend on any other project’s internal details, thus creating (sometimes unwanted) couplings.</p>
+ </li>
+ <li>
+ <p>If the lower-level project did not intend to expose some internal details, the unwanted couplings introduce technical debt and make it harder to modify the lower-level project.</p>
+ </li>
+ <li>
+ <p>One form of technical debt is the visibility debt or the cost of back-fitting visibility rules onto the existing build specifications to re-establish the appropriate encapsulations.</p>
+ </li>
+ <li>
+ <p>Another example of technical debt is dead code that can confuse the developers looking for useful APIs.</p>
+ </li>
+</ul>
+
+<h2 id="dependency-debt">Dependency Debt</h2>
+
+<ul>
+ <li>
+ <p><em>Over-declared</em> or <em>underutilized</em> dependencies can slow the build and testing of systems.</p>
+ </li>
+ <li>
+ <p><em>Under-declared</em> dependencies can make the build process brittle and make it difficult to remove <em>over-declared</em> dependencies.</p>
+ </li>
+ <li>
+ <p>Potential solutions for <em>over-declared</em> dependencies include:</p>
+
+ <ul>
+ <li>
+ <p>Setting aside some dedicated time for fixing build rules. But this approach is not automated, and potential breakages make it harder for developers to do the right thing.</p>
+ </li>
+ <li>
+ <p>Automatically add all the <em>under-declared</em> dependencies to the BUILD files. The system can raise an error if a direct dependency is missing, making it harder to do the wrong thing.</p>
+ </li>
+ <li>
+ <p>Automation can be applied for finding/reporting the over-declared dependencies as well.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Potential solutions for <em>underutilized</em> dependencies include:</p>
+
+ <ul>
+ <li>
+ <p>While it is challenging to automate fixing <em>underutilized</em> dependencies, automating the discovery of such dependencies is still useful.</p>
+ </li>
+ <li>
+ <p>Highlighting dependencies with high cost and low removal effort could incentivize developers to clean up their projects.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="zombie-targets">Zombie Targets</h2>
+
+<ul>
+ <li>
+ <p>Zombie targets can be identified by query the results of build and test runs.</p>
+ </li>
+ <li>
+ <p>A target is marked as “dead” if the attempts to build it have failed for at least 90 days. Until then, build errors are considered to be transient.</p>
+ </li>
+ <li>
+ <p>A zombie target can be eliminated by deleting its definition from the BUILD and deleting the source files, which are reachable only via the zombie target.</p>
+ </li>
+</ul>
+
+<h2 id="visibility-debt">Visibility Debt</h2>
+
+<ul>
+ <li>
+ <p>Originally, the default visibility of all the targets was public, leading to unintended dependencies.</p>
+ </li>
+ <li>
+ <p>The visibility of all the existing builds was set to <em>legacy_public</em>, and the default visibility was changed to private.</p>
+ </li>
+ <li>
+ <p>This encouraged developers to explicitly consider if they wanted other projects to depend on their project.</p>
+ </li>
+</ul>
+
+<h2 id="dead-flags">Dead Flags</h2>
+
+<ul>
+ <li>
+ <p>Google developed its command-line parsing utilities and defined a set of recognized command-line flags for libraries and binaries.</p>
+ </li>
+ <li>
+ <p>Overtime, the number of flags grew to half a million, and many of these flags are not useful anymore (i.e., dead).</p>
+ </li>
+ <li>
+ <p>These dead flags can it hard to understand and refactor code.</p>
+ </li>
+ <li>
+ <p>Existing flags are analyzed to check which ones have always been set to the same value and replaced by those contents, clearing about 150 thousand flags.</p>
+ </li>
+ <li>
+ <p>Removing dead flags also helps to clean up dead/unreachable code.</p>
+ </li>
+</ul>
+
+
+
+
+ One Solution is Not All You Need - Few-Shot Extrapolation via Structured MaxEnt RL
+
+ 2020-11-02T00:00:00-05:00
+ /site/2020/11/02/One Solution is Not All You Need: Few-Shot Extrapolation via Structured MaxEnt RL
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Key idea: Practicing and remembering diverse solutions to a task can lead to robustness to that task’s variations.</p>
+ </li>
+ <li>
+ <p>The paper proposes a framework to implement this idea - train multiple policies such that they are <em>collectively</em> robust to a new distribution over environments while using a single training environment.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2010.14484">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>During training, the agent has access to only one MDP.</p>
+ </li>
+ <li>
+ <p>During the evaluation, the agent encounters a new MDP which has the same state and action space but may have a different reward and transition function.</p>
+ </li>
+ <li>
+ <p>The agent is allowed some interactions (say <em>k</em>) with the test MDP and is then evaluated on the test MDP. The setup is referred to as <em>few-shot robustness</em>.</p>
+ </li>
+</ul>
+
+<h2 id="structured-maximum-entropy-reinforcement-learning-smerl">Structured Maximum Entropy Reinforcement Learning (SMERL)</h2>
+
+<ul>
+ <li>
+ <p>Represent a set of policies using a latent variable policy (i.e., a policy conditioned on a latent variable <em>z</em>).</p>
+ </li>
+ <li>
+ <p>This has two benefits: (i) Multiple policies can be represented by the same object, and (ii) diverse behaviors can be learned by encouraging the trajectories, corresponding to different <em>z</em> to be different, while being able to solve the task.</p>
+ </li>
+ <li>
+ <p>A diversity-inducing objective is used to encourage the agent to learn different trajectories for different <em>z</em>.</p>
+ </li>
+ <li>
+ <p>Specifically, the mutual information between <em>p(Z)</em> and marginal trajectory distribution for the latent variable policy is maximized, subject to the constraint that each policy achieves close to optimal returns in the train MDP.</p>
+ </li>
+ <li>
+ <p>The mutual information between <em>p(Z)</em> and marginal trajectory distribution for the latent variable policy is lower bounded by the sum of mutual information terms over individual states (appearing in the trajectory).</p>
+ </li>
+ <li>
+ <p>An unsupervised reward function is defined using the mutual information between states and latent variables.</p>
+ </li>
+ <li>
+ <p>\(r(s, a) = log(q_{\phi})(z\|s) - log(p(z))\) where \(q_{\phi}\) is a learned discriminator.</p>
+ </li>
+ <li>
+ <p>This unsupervised reward is optimized for only when the policy achieves close to an optimal return, i.e., the environment return is close to the optimal return. Otherwise, the agent optimizes only for the environment return.</p>
+ </li>
+</ul>
+
+<h3 id="implementation">Implementation</h3>
+
+<ul>
+ <li>
+ <p>SMERL is implemented using SAC with a latent variable maximum entropy policy.</p>
+ </li>
+ <li>
+ <p>The set of latent variables is a fixed discrete set \(Z\) and \(p(z)\) is set to be a uniform distribution over this set.</p>
+ </li>
+ <li>
+ <p>At the start of an episode, a \(z\) is sampled and used throughout the episode.</p>
+ </li>
+ <li>
+ <p>Discriminator \(q_{\phi}(z\|s)\) is trained to infer \(z\) from the visited states.</p>
+ </li>
+ <li>
+ <p>A baseline SAC agent is trained beforehand to evaluate if the current training policy achieves close to optimal environment return.</p>
+ </li>
+ <li>
+ <p>During the evaluation, the policy corresponding to each latent variable is executed in the test MDP, and the policy with the maximum return is returned.</p>
+ </li>
+</ul>
+
+<h2 id="theoretical-analysis">Theoretical Analysis</h2>
+
+<ul>
+ <li>
+ <p>Given an MDP \(M\) and \(\epsilon>0\), the MDP robustness set is defined as the set of all MDPs \(M'\) where the optimal policy of \(M'\) produces the same trajectory distribution in \(M'\) as \(M\). Moreover, on the training MDP \(M\), the optimal policies (corresponding to \(M\) and \(M'\)) obtain similar returns.</p>
+ </li>
+ <li>
+ <p>The paper shows that SMERL generalizes to MDPs belong to the robustness set.</p>
+ </li>
+ <li>
+ <p>It also provides a simplified view of the optimization objective and shows how it naturally leads to a trajectory-centric mutual information objective.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Environments</p>
+
+ <ul>
+ <li>
+ <p>2D navigation environments with point mass.</p>
+ </li>
+ <li>
+ <p>Mujoco Environments: HalfCheetah-Goal, Walker2d-Velocity, Hopper-Velocity.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>On the 2D navigation environment, the paper shows that SMERL learns to use different trajectories to reach the goal.</p>
+ </li>
+ <li>
+ <p>On the Mujoco setup, the evaluation shows that SMERL generally outperforms the best-performing baseline or is close to the best-performing baseline on different tasks.</p>
+ </li>
+ <li>
+ <p>Generally, higher train performance does not correlate with higher test performance, and there is no single policy that performs the best across all the tasks. Thus, it should be beneficial to learn multiple diverse policies that can be selected from during testing.</p>
+ </li>
+</ul>
+
+
+
+
+ Learning Explanations That Are Hard To Vary
+
+ 2020-10-19T00:00:00-04:00
+ /site/2020/10/19/Learning Explanations That Are Hard To Vary
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper builds on the principle “good explanations are hard to vary” to propose that <em>invariant mechanisms</em> can be identified by finding explanations (say model parameters) that are hard to vary across examples.</li>
+ <li><a href="https://arxiv.org/abs/2009.00329">Link to the paper</a></li>
+ <li><a href="https://github.com/gibipara92/learning-explanations-hard-to-vary">Link to the code</a></li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>Collection of <em>d</em> different datasets (from different environments). Each dataset is a collection of input-target tuples.</li>
+ <li>Objective is to learn a function <em>f</em> (also called <em>mechanism</em>) to map the input to the target (for all the environments).</li>
+ <li>The standard approach is to pool the loss for examples corresponding to the different environments and perform gradient updates on this average-pooled loss.</li>
+ <li>In this standard gradient-based setup, the model may not learn invariances due to the following reasons:
+ <ul>
+ <li>Model learned the spurious features first, and now the training loss is too small.</li>
+ <li>The pooled loss is generally computed by summing (or averaging) the loss corresponding to individual examples. Thus the gradient for each example is calculated independently. Each sample can be thought of as a dataset of size 1, for which all the features are relevant.</li>
+ <li>Gradient descent with averaging (of gradients across the environments) greedily maximizes for the learning speed and not invariance.</li>
+ </ul>
+ </li>
+ <li>Performing arithmetic mean can be seen as performing an OR operation (i.e., the sum can be high if any one of the constituents is high), whereas performing geometric mean can be seen as performing an AND operation (i.e., the product can be high only if all the constituents are high).</li>
+</ul>
+
+<h3 id="invariant-learning-consistencyilc">Invariant Learning Consistency(ILC)</h3>
+
+<ul>
+ <li>Given an algorithm \(A\), let \(\theta_{A}^{*}\) denote the set of convergence points of \(A\) when trained on all the environments.</li>
+ <li>Each convergence point is associated with a consistency score.</li>
+ <li>Intuitively, given a convergence point and an environment <em>e</em>, find the set of parameters equivalent to the convergence point (in terms of loss) with respect to <em>e</em>. Let’s call this set as <em>S</em>.</li>
+ <li>Evaluate the points in this set for all the remaining environments. For the given convergence point, an environment <em>e’</em> is consistent with <em>e</em> if the maximum difference in the loss for two environments is small, for all points belonging to <em>S</em>.</li>
+ <li>This idea is used to define the invariant learning consistency score for algorithm \(A\), which measures the expected consistency of the converged points (on the pooled data) across all the environments.</li>
+ <li>The paper shows that the converged points’ consistency is linked to the Hessians’ geometric mean and that for the convex quadratic case, using the elementwise geometric mean of gradients improves consistency.</li>
+ <li>However, there are some practical challenges:
+ <ul>
+ <li>Geometric mean is defined only when all signs are consistent. This issue can potentially be handled by treating different signs as 0.</li>
+ <li>There is very little flexibility in “partial” agreement, and even a single zero gradient component can stop optimization for that component. This can probably be handled by not masking if many environments have a gradient for that component.</li>
+ <li>Geometric component needs to be computed in the log-domain (for numerical scalability), but that can be computationally more expensive.</li>
+ <li>When using adaptive optimizers like Adam, the exact magnitude of geometric mean will be ignored because of rescaling for the local curvature adaptation.</li>
+ </ul>
+ </li>
+ <li>Some of these challenges can be handled using average gradients when the geometric mean would be 0 and masking out components based on the sign.</li>
+</ul>
+
+<h3 id="and-mask">AND-mask</h3>
+
+<ul>
+ <li>The ideas from the previous section can be used to develop a practical algorithm called AND-mask.</li>
+ <li>Zero-out gradients that have inconsistent signs across some threshold number (hyper-parameter) of environments.</li>
+ <li>In the presence of purely random gradient patterns, the AND-mask decreases the signals’ strength exponentially fast.</li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="synthetic-memorization-dataset">Synthetic Memorization Dataset</h3>
+
+<ul>
+ <li>This is a binary classification task with two kind of features: (i) “meaningful” features that are shared across environments but harder for the model to learn and (ii) “shortcut” features that are easy to learn but not shared across environments.</li>
+ <li>While the dataset may look simple, it is difficult to find the invariant mechanism because the “shortcut” features allow for a simple, linear decision boundary, with a large margin that is fast to learn, has perfect accuracy, robust to input noise, and no iid generalization gap.</li>
+ <li>Baselines:
+ <ul>
+ <li>MLPs trained with regularizers like dropout, L1, L2, and batch norm.</li>
+ <li>Domain Adversarial Neural Networks (DANN)</li>
+ <li>Invariant Risk Minimization (IRM)</li>
+ </ul>
+ </li>
+ <li>In terms of results, AND-mask with L1/L2 regularizers gives the best results.</li>
+ <li>Empirically, the paper shows that the signal from the “meaningful” features is present when the gradients are averaged, but their magnitude is much smaller than the signal from the “shortcut” features.</li>
+</ul>
+
+<h3 id="experiments-on-cifar-10">Experiments on CIFAR-10</h3>
+
+<ul>
+ <li>A ResNet model is trained on the CIFAR-10 dataset with random labels, with and without the AND-mask.</li>
+ <li>The model with the AND-mask did not memorize the data, whereas the model without the AND-mask did. As sanity, the paper ensured that both the models generalize well when trained with the original labels.</li>
+ <li>Note that for this experiment, every example was treated to have come from its own environment.</li>
+</ul>
+
+<h3 id="behavioral-cloning-on-coinrun">Behavioral Cloning on CoinRun</h3>
+
+<ul>
+ <li>Train an expert policy using PPO for 400M steps on the full distribution of levels.</li>
+ <li>Generate a dataset of state-action pairs. Training data consists of 1000 states from each of the 64 levels, while the test data comes from 2000 levels.</li>
+ <li>A ResNet18 model is used as an imitation learning policy.</li>
+ <li>The exact implementation of the AND-mask is a little more involved, but the key takeaway is that model trained with AND-mask identifies invariant mechanisms across different levels.</li>
+</ul>
+
+
+
+
+ Remembering for the Right Reasons - Explanations Reduce Catastrophic Forgetting
+
+ 2020-10-12T00:00:00-04:00
+ /site/2020/10/12/Remembering for the Right Reasons - Explanations Reduce Catastrophic Forgetting
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper hypothesizes that catastrophic forgetting can happen if the model can not rely on “reasoning” used for an old datapoint. If that is the case, catastrophic forgetting may be alleviated when the model “remembers” why it made a prediction previously.</li>
+ <li>The paper presents a simple instantiation of this hypothesis, in the form of a technique called Remembering for the Right Reasons (RRR).</li>
+ <li>The idea is to store model explanations, along with previous examples in the replay buffer. During replay, an additional <em>explanation loss</em> is used, along with the regular replay loss.</li>
+ <li><a href="https://arxiv.org/abs/2010.01528">Link to the paper</a></li>
+ <li><a href="https://github.com/SaynaEbrahimi/Remembering-for-the-Right-Reasons">Link to the code</a></li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>The model is trained over a sequence of data distributions in the class-incremental learning setup. A single-head architecture is used so that the task ID is not required during inference.</li>
+ <li>Along with the standard replay buffer (\(M^{rep}\)) for the raw input examples (from different tasks), another replay buffer (\(M^{RRR}\)) is maintained for storing the “explanations” (in the form of saliency maps), corresponding to examples in \(M^{rep}\).</li>
+ <li>RRR is implemented as an L1 loss on the error between the saliency map generated after training on the current task and the saliency map in \(M^{RRR}\).</li>
+ <li>Saliency maps need to be generated while the model is training. This requirement rules out black-box saliency methods, which can be used only after training.</li>
+ <li>The gradient-based white-box explainability techniques that are used include:
+ <ul>
+ <li>Vanilla backpropagation - Perform a forward pass through the model and take the gradient of the given output class with respect to the input.</li>
+ <li>Backpropagation with SmoothGrad - Saliency maps generated using Vanilla backpropagation can be visually noisy. These maps can be improved by adding pixel-wise Gaussian noise to <em>n</em> copies of the image and averaging the resulting gradients. The paper used <em>n=40</em>.</li>
+ <li>Gradient-weighted Class Activation Mapping (Grad-CAM) - Uses gradients to determine the importance of feature map activations on a given prediction.</li>
+ </ul>
+ </li>
+ <li>RRR can be easily used with memory and regularization based approaches.</li>
+ <li>The paper combined RRR with the following standard Class Incremental Learning (CIL) models:
+ <ul>
+ <li><a href="https://arxiv.org/abs/2003.11652">iTAML : An incremental task-agnostic meta-learning approach</a></li>
+ <li><a href="https://arxiv.org/abs/1807.09536">End-to-end incremental learning (EEIL)</a></li>
+ <li><a href="https://arxiv.org/abs/1905.13260">Large scale incremental learning (BiC)</a></li>
+ <li><a href="https://arxiv.org/abs/2004.10956">TOpology-Preserving knowledge InCrementer (TOPIC)</a></li>
+ <li><a href="https://arxiv.org/abs/1611.07725">iCaRL: Incremental Classifier and Representation Learning</a></li>
+ <li><a href="https://arxiv.org/abs/1612.00796">Elastic Weight Consolidation</a></li>
+ <li><a href="https://arxiv.org/abs/1606.09282">Learning without forgetting</a></li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="few-shiot-class-incremental-learning">Few-Shiot Class Incremental Learning</h3>
+
+<ul>
+ <li>C-way K-shot class incremental learning with C classes and K training samples per class and b base classes to learn as the first task.</li>
+ <li>Caltech-UCSD Birds dataset with 100 base classes and remaining 100 classes divided into ten tasks, with three samples per class. The test set is not changed.</li>
+ <li>In teems of saliency maps., Grad-CAM is better than Vanilla Backpropagation, which in turn is comparable to SmoothGrad. The same trend is seen in terms of memory overhead, with Grad-CAM having the least memory overhead.</li>
+ <li>Adding the RRR loss improves the performance of all the baselines.</li>
+</ul>
+
+<h3 id="standard-class-incremental-learning">Standard Class Incremental Learning</h3>
+
+<ul>
+ <li>CIFAR100 and ImageNet100 with a memory budget of 2000 samples.</li>
+ <li>Adding the RRR loss improves all the baselines’ performance, and the gains for ImageNet100 are more significant than the gains for CIFAR100.</li>
+</ul>
+
+<h3 id="how-often-does-the-model-remember-its-decision-for-the-right-reason">How often does the model remember its decision for the right reason?</h3>
+
+<ul>
+ <li>The paper uses the Pointing Game (PG) experiment, which uses the ground truth image segmentation to define the true object region.</li>
+ <li>If the maximum attention location (in the predicted saliency map) falls inside the objects, it is considered a <em>hit</em>, else a <em>miss</em>. A <em>hit</em> on a previous example is considered a proxy for the model remembering its decision for the right reason.</li>
+ <li>The precision and recall are reported for the <em>hit</em> metric. Using RRR increases both precision (i.e., less often the model makes the correct decision without looking at the right evidence) and recall (i.e., less frequently does the model makes an incorrect decision, despite looking at the proper evidence).</li>
+</ul>
+
+
+
+
+ A Foliated View of Transfer Learning
+
+ 2020-09-28T00:00:00-04:00
+ /site/2020/09/28/A Foliated View of Transfer Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a formalism for transfer learning, offers a definition of relatedness between tasks, and proposes foliations as a mathematical framework to represent the relationship between tasks.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2008.00546">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="summary">Summary</h2>
+
+<ul>
+ <li>
+ <p>The term <em>representation</em> denotes a mechanism for <em>describing</em> and <em>realizing</em> abstract objects, thus allowing manipulation and reasoning about the objects. This description goes beyond the usual meaning (in deep learning), where <em>representation</em> denotes some useful information about data.</p>
+ </li>
+ <li>
+ <p><em>Relatedness</em> describes <em>what</em> changes between tasks. Consider a set of transformations (or functions) that convert one task to another. A <em>relationship</em> between two tasks is an element of this transformation set.</p>
+ </li>
+ <li>
+ <p>Given a transformation set, one can define a <em>set of related tasks</em>, which is the set of all the tasks that can be transformed into each other using the functions from the given transformation set. This set of tasks is an equivalence class, and the transformation set is the equivalence relationship.</p>
+ </li>
+ <li>
+ <p>Given two related tasks <em>t1</em> and <em>t2</em>, denote the corresponding models (trained on those tasks) as <em>m1</em> and <em>m2</em>. One can assume that <em>m1</em> and <em>m2</em> are related in the same way as <em>t1</em> and <em>t2</em> (equivariance).</p>
+ </li>
+ <li>
+ <p>Now, given a set of transformations, one can partition the space of continuous functions into non-overlapping spaces, which describe a set of related tasks. These spaces are referred to as the <em>parallel spaces</em> or <em>transfer spaces</em>.</p>
+ </li>
+ <li>
+ <p>The parallel space represents a lower dimension than the original space. So knowing which parallel space a model lies on can make it easier to find it. This is the primary motivation behind transfer learning - knowing the relationship between tasks can make it easier to find a solution to new tasks.</p>
+ </li>
+ <li>
+ <p>Another way of partitioning the set of transformations is to use tessellation (e.g., Voronoi diagrams). Tasks in the same partition are similar to each other as compared to a task from another partition.</p>
+ </li>
+ <li>
+ <p>Two tasks are defined as <em>similar</em> if the distance between them (under some distance metric) is small.</p>
+ </li>
+ <li>
+ <p>Similarity is a <em>geometric</em> notion, while relatedness is a <em>transformative</em> notion. Parallelized space is to relatedness what tessellation is to similarity.</p>
+ </li>
+ <li>
+ <p>The distinction between similarity and relatedness is quite nuanced, and the authors provide several examples to differentiate between them.</p>
+ </li>
+ <li>
+ <p>Similarity can only be measured in terms of a reference element (similar to what). For example, when one finetunes a pre-trained model on a new task, one assumes that the model’s pretraining task is similar to the current task.</p>
+ </li>
+ <li>
+ <p>Given a set (say <em>T</em>), a <em>quantity</em> (a function that maps elemenets of <em>T</em> to a <em>k</em> dimensional vector) is said to be <em>invariant</em> with respect to a transformation <em>p</em> (defined on <em>T</em>) if <em>q(f) = q(p(f))</em> ie the value of <em>f</em> (belonging to <em>T</em>) does not change if <em>f</em> is transformed by <em>p</em>.</p>
+ </li>
+ <li>
+ <p>If one assumes that the set of transformations is a group, specifically a Lie group whose action on the set of tasks is locally free and regular, then one can define a parallel partitioning of the space of tasks and the space of models.</p>
+ </li>
+ <li>
+ <p>One can develop a hierarchial categorization scheme for the set of all considered tasks using the invariant quantities.</p>
+ </li>
+ <li>
+ <p>One can consider the space of tasks and models to be smooth manifolds as manifolds naturally give a notion of representation and transformations between them.</p>
+ </li>
+ <li>
+ <p>A manifold is a topological space that can be locally mapped to a Euclidean space using coordinate charts. One can define regular foliation by choosing charts that satisfy certain conditions. In that case, the manifold has immersed, connected, non-intersecting submanifolds called leaves.</p>
+ </li>
+ <li>
+ <p>The charts (that satisfies those conditions) give a set of rectified coordinates, where the notions of “which leaf a point is on” and “where on the leaf it is” are clearly separated.</p>
+ </li>
+ <li>
+ <p>Thus, foliation can provide the theoretical tools to work with parallel spaces.</p>
+ </li>
+ <li>
+ <p>How can the foliations be incorporated into theory and solutions for transfer learning is left aa future work.</p>
+ </li>
+</ul>
+
+
+
+
+ Harvest, Yield, and Scalable Tolerant Systems
+
+ 2020-09-21T00:00:00-04:00
+ /site/2020/09/21/Harvest, Yield, and Scalable Tolerant Systems
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>A classic paper that looks into strategies for scaling large systems that can tolerate graceful degradation.</p>
+ </li>
+ <li>
+ <p><a href="https://dl.acm.org/doi/10.5555/822076.822436">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="cap-theorem">CAP Theorem</h2>
+
+<ul>
+ <li>
+ <p>CAP refers to strong <strong>C</strong>onsistency, high <strong>A</strong>vailability, and <strong>P</strong>artitionability.</p>
+ </li>
+ <li>
+ <p>Strong consistency refers to single copy ACID consistency.</p>
+ </li>
+ <li>
+ <p>High availability means any consumer can access the data anytime. Generally, this is achieved by adding one or more data replicas.</p>
+ </li>
+ <li>
+ <p>Partitionability means that the system can survive a partition between the different replicas.</p>
+ </li>
+ <li>
+ <p>Strong CAP theorem states that any system can have only two out of three properties.</p>
+ </li>
+ <li>
+ <p>Weak CAP theorem says that stronger are the guarantees about any two properties, weaker are the third property’s guarantees.</p>
+ </li>
+</ul>
+
+<h2 id="harvest-yield-and-cap-theorem">Harvest, Yield, and CAP Theorem</h2>
+
+<ul>
+ <li>
+ <p>Assume that the clients are making a request to a server.</p>
+ </li>
+ <li>
+ <p>There are two quantities of interest here:</p>
+
+ <ul>
+ <li>Yield - the probability of completing a request.</li>
+ <li>Harvest - completeness of answer to a query.</li>
+ </ul>
+ </li>
+ <li>
+ <p>In the presence of faults, a tradeoff can is made between yield and harvest. This tradeoff applies to both read and update queries.</p>
+ </li>
+</ul>
+
+<h2 id="two-strategies-for-scaling-systems">Two strategies for scaling systems</h2>
+
+<h3 id="trading-harvest-for-yield">Trading Harvest for Yield</h3>
+
+<ul>
+ <li>
+ <p>In a hundred node cluster (without replication), a single-node failure reduces harvest by 1 %, and in the case of multi-node failure, the harvest degrades linearly.</p>
+ </li>
+ <li>
+ <p>The probability of losing high-priority data can be reduced by replicating it. However, replicating all the data would not n guarantee 100% harvest and yield despite significant costs.</p>
+ </li>
+</ul>
+
+<h3 id="application-decomposition-and-orthogonal-mechanisms">Application Decomposition and Orthogonal Mechanisms</h3>
+
+<ul>
+ <li>
+ <p>Decompose a large application into subcomponents so that each component can be provisioned separately. Strong consistency can only be applied only on the components that need it, instead of the application as a whole.</p>
+ </li>
+ <li>
+ <p>Further, failure of one or more components need not cause the application to fail as a whole.</p>
+ </li>
+ <li>
+ <p>Decomposition also provides the opportunity to use orthogonal mechanisms, i.e., mechanisms independent of other mechanisms with no runtime interface.</p>
+ </li>
+ <li>
+ <p>Composition of orthogonal subsystems improves the robustness of runtime interactions by <em>locally</em> containing the errors. For example, the orthogonal components can be restarted /replaced independently without affecting other running components.</p>
+ </li>
+</ul>
+
+
+
+
+ MONet - Unsupervised Scene Decomposition and Representation
+
+ 2020-09-14T00:00:00-04:00
+ /site/2020/09/14/MONet Unsupervised Scene Decomposition and Representation
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces Multi-Object Network (MONet) architecture that learns a modular representation of images by spatially decomposing scenes into <em>objects</em> and learning a representation for these <em>objects</em>.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1901.11390">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>Two components:</p>
+
+ <ul>
+ <li>
+ <p>Attention Module: generates spatial masks corresponding to the <em>objects</em> in the scene.</p>
+ </li>
+ <li>
+ <p>VAE: learn representation for each <em>object</em>.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>VAE components:</p>
+
+ <ul>
+ <li>
+ <p>Encoder: It takes as input the image and the attention mask generated by the attention module and produce the parameters for distribution over latent variable <em>z</em>.</p>
+ </li>
+ <li>
+ <p>Decoder: It takes as input the latent variable <em>z</em> and attempts to reproduce the image.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The decoder loss term is weighted by mask, i.e., the decoder tries to reproduce only those parts of the image that the attention mask focuses on.</p>
+ </li>
+ <li>
+ <p>The attention mechanism is auto-regressive with an ongoing state (called a scope) that tracks which parts of the image are not yet attended over.</p>
+ </li>
+ <li>
+ <p>In the last step, no attention mask is computed, and the previous scope is used as-is. This ensures that all the masks sum to 1.</p>
+ </li>
+ <li>
+ <p>The VAE also models the attention mask over the components, i.e., the probability that the pixels belong to a particular component.</p>
+ </li>
+</ul>
+
+<h2 id="motivation">Motivation</h2>
+
+<ul>
+ <li>
+ <p>A model could efficiently process compositional visual scenes if it can exploit some recurring structures in the scene.</p>
+ </li>
+ <li>
+ <p>The paper validates this hypothesis by showing that an autoencoder performs better if it can build up the scenes compositionally, processing one mask at a time (these masks are ground-truth spatial masks) rather than processing the scene at once.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>VAE encoder parameterizes a diagonal Gaussian latent posterior with a spatial broadcast decoder that encourages the VAE to learn disentangled features.</p>
+ </li>
+ <li>
+ <p>MONet with seven slots is trained on <em>Objects Room</em> dataset with 1-3 objects.</p>
+
+ <ul>
+ <li>
+ <p>It learns to generate different attention mask for different objects.</p>
+ </li>
+ <li>
+ <p>Combining the reconstructed components using the corresponding attention masks produces good quality reconstruction for the entire scene.</p>
+ </li>
+ <li>
+ <p>Since it is an autoregressive model, MONet can be evaluated for more slots. The model generalizes to novel scene configurations (not seen during training).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>On the Multi-dSprites dataset (modification of the dSprites dataset), the model (post-training) distinguishes individual sprites and background.</p>
+ </li>
+ <li>
+ <p>On the CLEVER data (2-10 objects per image), the model generates good image segmentation and reconstructions and can distinguish between overlapping shapes.</p>
+ </li>
+</ul>
+
+
+
+
+ Revisiting Fundamentals of Experience Replay
+
+ 2020-09-07T00:00:00-04:00
+ /site/2020/09/07/Revisiting Fundamentals of Experience Replay
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents an extensive study of the effects of experience replay in Q-learning based methods.</p>
+ </li>
+ <li>
+ <p>It focuses explicitly on the replay capacity and replay ratio (ratio of learning updates to experience collected).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2007.06700">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Replay capacity is defined as the total number of transitions stored in the replay buffer.</p>
+ </li>
+ <li>
+ <p>Age of a transition (stored in the replay buffer) is defined as the number of gradient steps taken by the agent since the transition was stored.</p>
+ </li>
+ <li>
+ <p>More is the replay capacity, more will be the age of the oldest transition (also referred to as the age of the oldest policy).</p>
+ </li>
+ <li>
+ <p>More is the replay capacity, more will be the degree of “off-policyness” of the transitions in the buffer (with everything else held constant).</p>
+ </li>
+ <li>
+ <p>Replay ratio is the number of gradient updates per environment transition. This ratio can be used as a proxy for how often the agent uses old data (vs. collecting new data) and is related to off-policyness.</p>
+ </li>
+ <li>
+ <p>In <a href="https://www.nature.com/articles/nature14236">DQN paper</a>, the replay ratio is set to be 0.25.</p>
+ </li>
+ <li>
+ <p>For experiments, a subset (of 14 games) is selected from Atari ALE (Arcade Learning Environment) with sticky actions.</p>
+ </li>
+ <li>
+ <p>Each experiment is repeated with three seeds.</p>
+ </li>
+ <li>
+ <p>Rainbow is used as the base algorithm.</p>
+ </li>
+ <li>
+ <p>Total number of gradient updates and batch size (per gradient update) are fixed for all the experiments.</p>
+ </li>
+ <li>
+ <p>Rainbow used replay capacity of 1M and oldest policy of age 250K.</p>
+ </li>
+ <li>
+ <p>In experiments, replay capacity varies from 0.1M to 10M ( 5 values), and the age of the oldest policy varies from 25K to 25M (4 values).</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>With the age of the oldest policy fixed, performance improves with higher replay capacity, probably due to increased state-action coverage.</p>
+ </li>
+ <li>
+ <p>With fixed replay capacity, reducing the oldest policy’s age improves performance, probably due to the reduced off-policyness of the data in the replay buffer.</p>
+ </li>
+ <li>
+ <p>However, in some specific instances (with sparse reward, hard exploration setup), performance can drop when reducing the oldest policy’s age.</p>
+ </li>
+ <li>
+ <p>Increasing replay capacity, while keeping the replay ratio fixed, provides varying improvements and depends on the particular values of replacy capacity and replay ratio.</p>
+ </li>
+ <li>
+ <p>The paper reports the effect of these choices for DQN as well.</p>
+ </li>
+ <li>
+ <p>Unlike Rainbow, DQN does not improve with larger replay capacity, irrespective of whether the replay ratio or age of the oldest policy is kept fixed.</p>
+ </li>
+ <li>
+ <p>Given that the Rainbow agent is a DQN agent with additional components, the paper explores which of these components leads to an improvement in Rainbow’s performance as replay capacity increases.</p>
+ </li>
+</ul>
+
+<h2 id="additive-experiments">Additive Experiments</h2>
+
+<ul>
+ <li>
+ <p>Four new DQN variants are created by adding each of Rainbow’s four components to the base DQN agent.</p>
+ </li>
+ <li>
+ <p>DQN with n-step returns is the only variant that benefits by increased replay capacity.</p>
+ </li>
+ <li>
+ <p>The usefulness of n-step returns is further validated by verifying that Rainbow agent without n-step returns does not benefit by increased replay capacity. While Rainbow agent without any other component benefits by the increased capacity.</p>
+ </li>
+ <li>
+ <p>Prioritized Experience Replay does not significantly affect the performance with increased replay capacity.</p>
+ </li>
+ <li>
+ <p>The observation that n-step returns are critical for taking advantage of larger replay sizes is surprising because the uncorrected n-step returns are theoretically not suitable for off-policy learning.</p>
+ </li>
+ <li>
+ <p>The paper tests the limits of increasing replay capacity (with n-step returns) by performing experiments in the offline-RL setup, the agent collects a dataset of about 200M frames. These frames are used to train another agent.</p>
+ </li>
+ <li>
+ <p>Even in this extreme setup, n-step returns improve the learning agent’s performance.</p>
+ </li>
+</ul>
+
+<h2 id="why-do-n-step-returns-help">Why do n-step returns help?</h2>
+
+<ul>
+ <li>
+ <p>Hypothesis 1: n-step returns help to counter the increased off-policyness produced by a larger replay buffer.</p>
+
+ <ul>
+ <li>This hypothesis does not seem to hold as keeping the oldest policy fixed or using the same contrastive factor as an n-step update does not improve the 1-step update’s performance.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Hypothesis 2: Increasing the replay buffer’s capacity may reduce the variance of the n-step returns.</p>
+
+ <ul>
+ <li>
+ <p>This hypothesis is evaluated by training on environments with lesser variance or by turning off the sticky actions in the atari domain.</p>
+ </li>
+ <li>
+ <p>While the hypothesis does explain the gains by using n-step returns to some extent, n-step gains are observed even in environments with low variance.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Deep Reinforcement Learning and the Deadly Triad
+
+ 2020-08-31T00:00:00-04:00
+ /site/2020/08/31/Deep Reinforcement Learning and the Deadly Triad
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper investigates the practical impact of the deadly triad (function approximation, bootstrapping, and off-policy learning) in deep Q-networks (trained with experience replay).</p>
+ </li>
+ <li>
+ <p>The deadly triad is called so because when all the three components are combined, TD learning can diverge, and value estimates can become unbounded.</p>
+ </li>
+ <li>
+ <p>However, in practice, the component of the deadly triad has been combined successfully. An example is training DQN agents to play Atari.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1812.02648">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>The effect of each component of the triad can be regulated with some design choices:</p>
+
+ <ul>
+ <li>
+ <p>Bootstrapping - by controlling the number of steps before bootstrapping.</p>
+ </li>
+ <li>
+ <p>Function approximation - by controlling the size of the neural network.</p>
+ </li>
+ <li>
+ <p>Off-policy learning - by controlling how data points are sampled from the replay buffer (i.e., using different prioritization approaches)</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The problem is studied in two contexts: toy example and Atari 2600 games.</p>
+ </li>
+ <li>
+ <p>The paper makes several hypotheses about how different components may interact in the triad and evaluate these hypotheses by training DQN with different hyperparameters:</p>
+
+ <ul>
+ <li>
+ <p>Number of steps before bootstrapping - 1, 3, 10</p>
+ </li>
+ <li>
+ <p>Four levels of prioritization (for sampling data from the replay buffer)</p>
+ </li>
+ <li>
+ <p>Bootstrap target - Q-learning, target Q-learning, inverse double Q-learning, and double Q-learning</p>
+ </li>
+ <li>
+ <p>Network sizes-small, medium, large and extra-large.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Each experiment was run with three different seeds.</p>
+ </li>
+ <li>
+ <p>The paper formulates a series of hypotheses and designs experiments to support/reject the hypotheses.</p>
+ </li>
+</ul>
+
+<h2 id="hypothesis-1-combining-q-learning-with-conventional-deep-rl-function-spaces-does-not-commonly-lead-to-divergence">Hypothesis 1: Combining Q learning with conventional deep RL function spaces does not commonly lead to divergence</h2>
+
+<ul>
+ <li>
+ <p>Rewards are clipped between -1 and 1, and the discount factor is set to 0.99. Hence, the maximum absolute action value is bound to smaller than 100. This upper bound is used soft-divergence in the value estimates.</p>
+ </li>
+ <li>
+ <p>The paper reports that while soft-divergence does occur, the values do not become unbounded, thus supporting the hypothesis.</p>
+ </li>
+</ul>
+
+<h2 id="hypothesis-2-there-is-less-divergence-when-correcting-for-overestimation-bias-or-when-bootstrapping-on-separate-networks">Hypothesis 2: There is less divergence when correcting for overestimation bias or when bootstrapping on separate networks.</h2>
+
+<ul>
+ <li>
+ <p>One manifestation of bootstrapping on separate networks is target-Q learning. While using separate networks helps on Atari, it does not entirely solve the problem on the toy setup.</p>
+ </li>
+ <li>
+ <p>One manifestation of correcting for the overestimation bias is using double Q-learning.</p>
+ </li>
+ <li>
+ <p>In the standard form, double Q-learning benefits by bootstrapping on a separate network. To isolate the gains by using each component independently, an inverse double Q-learning update is used that does not use a separate target-network for bootstrapping.</p>
+ </li>
+ <li>
+ <p>Experimentally, Q-learning is the most unstable while target Q-learning and double Q-learning are the most stable. This observation supports the hypothesis.</p>
+ </li>
+</ul>
+
+<h2 id="hypothesis-3-longer-multi-step-returns-will-diverge-easily">Hypothesis 3: Longer multi-step returns will diverge easily</h2>
+
+<ul>
+ <li>
+ <p>This hypothesis is intuitive as the dependence on bootstrapping is reduced with multi-step returns.</p>
+ </li>
+ <li>
+ <p>Experimental results support this hypothesis.</p>
+ </li>
+</ul>
+
+<h2 id="hypothesis-4-larger-more-capacity-networks-will-diverge-less-easily">Hypothesis 4: Larger, more capacity networks will diverge less easily.</h2>
+
+<ul>
+ <li>
+ <p>This hypothesis is based on the assumption that more flexible value function approximations may behave more like the tabular case.</p>
+ </li>
+ <li>
+ <p>In practice, smaller networks show fewer instances of instability than the larger networks.</p>
+ </li>
+ <li>
+ <p>The hypothesis is not supported by the experiments.</p>
+ </li>
+</ul>
+
+<h2 id="hypothesis-5-stronger-prioritization-of-updates-will-diverge-more-easily">Hypothesis 5: Stronger prioritization of updates will diverge more easily.</h2>
+
+<ul>
+ <li>This hypothesis is supported by the experiments for all the four updates.</li>
+</ul>
+
+<h2 id="effect-of-the-deadly-triad-on-the-agents-performance">Effect of the deadly triad on the agent’s performance</h2>
+
+<ul>
+ <li>
+ <p>Generally, soft-divergence correlates with poor control performance.</p>
+ </li>
+ <li>
+ <p>For example, longer multi-step returns lead to fewer instances of instabilities and better performance.</p>
+ </li>
+ <li>
+ <p>The trend is more interesting in terms of network capacity. Large networks tend to diverge more but also perform the best.</p>
+ </li>
+ <li>
+ <p>While action-value estimates can grow to large values, they can recover to plausible values as training progresses.</p>
+ </li>
+</ul>
+
+
+
+
+ Alpha Net--Adaptation with Composition in Classifier Space
+
+ 2020-08-24T00:00:00-04:00
+ /site/2020/08/24/Alpha Net--Adaptation with Composition in Classifier Space
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Common transfer learning method focuses on transferring knowledge in the model feature space.</p>
+ </li>
+ <li>
+ <p>In contrast, the paper argues that the learned knowledge is more concisely captured in the “classifier space” as the classifier is fitted for all the samples for a given class, while the feature representation is specific to each sample.</p>
+ </li>
+ <li>
+ <p>Building on this intuition, the paper proposes to combine strong classifiers (trained on large datasets) with weak classifiers (trained on smaller datasets) to improve the weak classifiers’ performance.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2008.07073">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="high-level-idea">High-Level Idea</h2>
+
+<ul>
+ <li>
+ <p>Given $n$ classifiers, $C_1, …, C_n$, trained with a large amount of data and a weak classifier $a$ trained for a class with few samples.</p>
+ </li>
+ <li>
+ <p>Find the nearest neighbors of $a$.</p>
+ </li>
+ <li>
+ <p>Train a new classifier by linearly combining $a$ with its nearest classifiers.</p>
+ </li>
+ <li>
+ <p>The coefficients (for linearly combining the classifiers) are learned using another classifier called as AlphaNet.</p>
+ </li>
+ <li>
+ <p>In theory, this approach can be used with any set of classifiers.</p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>A long-tailed dataset is one where some classes (referred to as the tail classes) have very few examples—for example, ImageNet-LT and Places-LT.</p>
+ </li>
+ <li>
+ <p>Split the long-tailed dataset into two splits - “base” classes with $B$ (number of) classes and “few” classes with $F$ (number of) classes.</p>
+ </li>
+ <li>
+ <p>Total number of classes $N = B + F$.</p>
+ </li>
+ <li>
+ <p>Start with a pre-trained model, with classifiers $w_j$ and biases $b_j$ for $j \in (1, N)$.</p>
+ </li>
+ <li>
+ <p>For a given target class $j$, find its top $k$ nearest neighbor classifiers and concatenate their output.</p>
+ </li>
+ <li>
+ <p>For each “few” class, learn a feedforward network that takes the concatenated representation (of classifiers) as the input and returns a vector of $k \alpha$ values.</p>
+ </li>
+ <li>
+ <p>These $\alpha$ values are interpreted as the classifier’s strength (or confidence) in its nearest neighbors.</p>
+ </li>
+ <li>
+ <p>The (normalized) alpha values are used for defining the weight and bias for the classifier for the given “few” class.</p>
+ </li>
+ <li>
+ <p>The collection of all the “few” classifiers is referred to as the AlphaNet.</p>
+ </li>
+ <li>
+ <p>The paper outlines a degenerate case, where the confidence in the prediction of all the strong classifiers goes to 0. The paper proposes to counter this case by clamping the $\alpha$ values.</p>
+ </li>
+ <li>
+ <p>The entire setup is trained end-to-end using cross-entropy loss on AlphaNet.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Given the proposed approach’s flexibility, it is used to combine the state-of-the-art models on ImageNet-LT, namely retraining classifiers on class-balanced samples and training models with weight normalization. The combined setup outperforms the individual models.</p>
+ </li>
+ <li>
+ <p>One interesting observation is that it is useful to include the weak classifiers, along with the strong classifiers, as AlphaNet adjusts the position of weak classifiers towards the appropriate strong classifier.</p>
+ </li>
+ <li>
+ <p>While the idea is described in the context of long-tail data distribution, the idea is useful in the general context of non-stationary data distribution. One instantiation could be lifelong class incremental learning where the model encounters new data classes during training. For some time duration (till sufficient data points are seen), the newly seen classes are the “few” classes. This approach can help with faster adaptation when the model is yet to see sufficient examples for the unseen classes.</p>
+ </li>
+</ul>
+
+
+
+
+ Outrageously Large Neural Networks--The Sparsely-Gated Mixture-of-Experts Layer
+
+ 2020-08-14T00:00:00-04:00
+ /site/2020/08/14/Outrageously Large Neural Networks--The Sparsely-Gated Mixture-of-Experts Layer
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Conditional computation is a technique to increase a model’s capacity (without a proportional increase in computation) by activating parts of the network on a per example basis.</p>
+ </li>
+ <li>
+ <p>The paper describes (and address) the computational and algorithmic challenges in conditional computation. It introduces a sparsely-gated Mixture-of-Experts layer (MoE) with 1000s of feed-forward sub-networks.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1701.06538">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="practical-challenges">Practical Challenges</h2>
+
+<ul>
+ <li>
+ <p>GPUs are fast at matrix arithmetic but slow at branching.</p>
+ </li>
+ <li>
+ <p>Large batch sizes amortizes the cost of updates. Conditional computation reduces the effective batch size for different components of the model.</p>
+ </li>
+ <li>
+ <p>Network bandwidth can be a bottleneck with the network demand overshadowing the computational demand.</p>
+ </li>
+ <li>
+ <p>Additional losses may be needed to achieve the desired level of sparsity.</p>
+ </li>
+ <li>
+ <p>Conditional computation is most useful for large datasets.</p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p><em>n</em> Expert Networks - $E_1$, …, $E_n$.</p>
+ </li>
+ <li>
+ <p>Gating Network $G$ to select a sparse combination of experts.</p>
+ </li>
+ <li>
+ <p>Output of the MoE module is the weighted sum of predictions of experts (weighted by the output of the gate).</p>
+ </li>
+ <li>
+ <p>If the gating network’s output is sparse, then some of the experts’ value does not have to be computed.</p>
+ </li>
+ <li>
+ <p>In theory, one could use a hierarchical mixture of experts where a mixture of experts is trained at each level.</p>
+ </li>
+</ul>
+
+<h3 id="choices-for-the-gating-network">Choices for the Gating Network</h3>
+
+<ul>
+ <li>
+ <p>Softmax Gating</p>
+ </li>
+ <li>
+ <p>Noisy top-k gating - Add tunable Gaussian noise to the output of softmax gating and retain only the top-k values. A second trainable weight matrix controls the amount of noise per component.</p>
+ </li>
+</ul>
+
+<h2 id="addressing-performance-challenge">Addressing Performance Challenge</h2>
+
+<ul>
+ <li>
+ <p>Shrinking Batch Problem</p>
+
+ <ul>
+ <li>
+ <p>If the MoE selects <em>k</em> out of <em>n</em> experts, the effective batch size reduces by a factor of <em>k</em> / <em>n</em>.</p>
+ </li>
+ <li>
+ <p>This reduction in batch size is accounted for by combining data parallelism (for standard layers and gasting networks) and model parallelism (for experts in MoE). Thus, with <em>d</em> devices, the batch size changes by a factor of (<em>k</em> x <em>d</em> ) / <em>n</em>.</p>
+ </li>
+ <li>
+ <p>For hierarchical MoE, the primary gating network uses data parallelism while secondary MoEs use model parallelism.</p>
+ </li>
+ <li>
+ <p>The paper considers LSTM models where the MoE is applied once the previous layer has finished. This increases the batch size (for the current MoE layer) by a factor equal to the number of unrolling timesteps.</p>
+ </li>
+ <li>
+ <p>Network Bandwith limitations can be overcome by ensuring that the ratio of computation (of each expert) to the input and output size is greater than (or equal to) the ratio of computational to network capacity.</p>
+ </li>
+ <li>
+ <p>Computational efficiency can be improved by using larger hidden layers (or more hidden layers).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Balancing Expert Utilization</p>
+
+ <ul>
+ <li>
+ <p>Importance of an expert (relative to a batch of training examples) is defined as the batchwise sum of the expert’s goal values.</p>
+ </li>
+ <li>
+ <p>An additional loss, called importance loss, is added to encourage the experts to have equal importance.</p>
+ </li>
+ <li>
+ <p>The importance loss is defined as the square of the coefficient of variation (of a set of importance values) multiplied by a (hand-tuned) scaling factor $w_{importance}$.</p>
+ </li>
+ <li>
+ <p>In practice, an additional loss called $L_{load}$ might be needed to ensure that the different experts get equal load (along with equal importance).</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Datasets</p>
+
+ <ul>
+ <li>
+ <p>Billon Word Language modeling Benchmark</p>
+ </li>
+ <li>
+ <p>100 Billion word Google News Corpus</p>
+ </li>
+ <li>
+ <p>Machine Translation datasets</p>
+
+ <ul>
+ <li>
+ <p>Single Language Pairs - WMT’14 En to Fr (36M sentence pairs) and En to De (5M sentence pairs).</p>
+ </li>
+ <li>
+ <p>Multilingual Machine Translation - large combine dataset of twelve language pairs.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In all the setups, the proposed MoE models achieve significantly better results than the baseline models, at a lower computational cost.</p>
+ </li>
+</ul>
+
+
+
+
+ Gradient Surgery for Multi-Task Learning
+
+ 2020-08-06T00:00:00-04:00
+ /site/2020/08/06/Gradient Surgery for Multi-Task Learning
+ <ul>
+ <li>
+ <p>The paper hypothesizes that main optimization challenges in multi-task learning arise because of negative interference between different tasks’ gradients.</p>
+ </li>
+ <li>
+ <p>It hypothesizes that negative interference happens when:</p>
+
+ <ul>
+ <li>
+ <p>The gradients are conflicting (i.e., have a negative cosine similarity).</p>
+ </li>
+ <li>
+ <p>The gradients coincide with high positive curvature.</p>
+ </li>
+ <li>
+ <p>The difference in gradient magnitude is quite large.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The paper proses to work around this problem by performing “gradient surgery.”</p>
+ </li>
+ <li>
+ <p>If two gradients are conflicting, modify the gradients by projecting each onto the other’s normal plane.</p>
+ </li>
+ <li>
+ <p>This modification is equivalent to removing the conflicting component of the gradient.</p>
+ </li>
+ <li>
+ <p>This approach is referred to as <em>projecting conflicting gradients</em> (PCGrad).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2001.06782">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>Theoretical Analysis</p>
+
+ <ul>
+ <li>
+ <p>The paper proves the local conditions under which PCGrad improves multi-task gradient descent in the two-task setup.</p>
+ </li>
+ <li>
+ <p>The conditions are:</p>
+
+ <ul>
+ <li>
+ <p>Angle between the task gradients is not too small.</p>
+ </li>
+ <li>
+ <p>Difference in the magnitude of the gradients is sufficiently large.</p>
+ </li>
+ <li>
+ <p>Curvature of the multi-task gradient is large.</p>
+ </li>
+ <li>
+ <p>Large enough learning rate.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Experimental Setup</p>
+
+ <ul>
+ <li>
+ <p>Multi-task supervised learning</p>
+
+ <ul>
+ <li>
+ <p>MutliMNIST, Multi-task CIFAR100, NYUv2.</p>
+ </li>
+ <li>
+ <p>For Multi-task CIFAR-100, PCGrad is used with the shared parameters of the routing networks.</p>
+ </li>
+ <li>
+ <p>For NYUv2, PCGrad is combined with MTAN.</p>
+ </li>
+ <li>
+ <p>In all the cases, using PCGrad improves the performance.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Multi-task Reinforcement Learning</p>
+
+ <ul>
+ <li>
+ <p>Meta-World Benchmark</p>
+ </li>
+ <li>
+ <p>PCGrad + SAC outperforms all other baselines.</p>
+ </li>
+ <li>
+ <p>In the context of SAC, the paper suggests learning temperature $\alpha$ on a per-task basis.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Goal-conditioned Reinforcement Learning</p>
+
+ <ul>
+ <li>
+ <p>Goal-conditioned robotic pushing task with a Sawyer robot.</p>
+ </li>
+ <li>
+ <p>PCGrad + SAC outperforms vanilla SAC.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ GradNorm--Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
+
+ 2020-07-30T00:00:00-04:00
+ /site/2020/07/30/GradNorm--Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes GradNorm, a gradient normalization algorithm that improves multi-task training by dynamically tuning the magnitude of gradients corresponding to different tasks.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1711.02257">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="motivation">Motivation</h2>
+
+<ul>
+ <li>
+ <p>During multi-task training, some tasks can dominate the training, at the expense of others.</p>
+ </li>
+ <li>
+ <p>It is common to define the multi-task loss as a linearly weighted combination of the individual task losses.</p>
+ </li>
+ <li>
+ <p>The paper proposes two changes to this setup:</p>
+
+ <ul>
+ <li>
+ <p>Adapt weight-coefficients, assigned to each loss term, at each training step.</p>
+ </li>
+ <li>
+ <p>Directly modify the gradient magnitudes, corresponding to different tasks, so that all the tasks are learning at similar rates.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Proposed GradNorm algorithm is similar to BatchNorm, but it performs normalization across tasks, not data batches.</p>
+ </li>
+</ul>
+
+<h2 id="algorithm">Algorithm</h2>
+
+<ul>
+ <li>
+ <p>Gradient norm at timestep $t$, for the $i^{th}$ task, is computed as the product between average gradient norm (across all tasks at timestep $t$) and $r_i(t) ^ {\alpha}$.</p>
+ </li>
+ <li>
+ <p>$r_i$ is the relative inverse training rate of task $i$. It is defined as the ratio between the loss ratio of task $i$ and the average loss ratio (across all the tasks).</p>
+ </li>
+ <li>
+ <p>$\alpha$ is a hyperparameter.</p>
+ </li>
+ <li>
+ <p>This computed per-task gradient norm is treated as the target value for actual gradient norms.</p>
+ </li>
+ <li>
+ <p>An additional $L_1$ loss is incorporated between the actual and the target gradient norms, summed over all the tasks, and optimizes the weight-coefficients only.</p>
+ </li>
+ <li>
+ <p>After every step, the weight-coefficients are renormalized to decouple the gradient normalization from the global learning rate.</p>
+ </li>
+ <li>
+ <p>Note that all the gradient norm computations are performed only for the layers on which GradNorm is applied. Generally, GradNorm is used with only the last shared layer of weights (to save on computational costs).</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Two variants of NYUv2 dataset – NYUv2+seg (small dataset) and NYUv2+kpts (big dataset).</p>
+ </li>
+ <li>
+ <p>Both regression and classification setups were used.</p>
+ </li>
+ <li>
+ <p>Models:</p>
+
+ <ul>
+ <li>
+ <p>SegNet with a symmetric VGG16 encoder/decoder</p>
+ </li>
+ <li>
+ <p>FCN with modified ResNet-50 as the encoder and shallow ResNet as the decoder.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Standard pixel-wise losses for each task.</p>
+ </li>
+</ul>
+
+<h3 id="results">Results</h3>
+
+<ul>
+ <li>
+ <p>GradNorm with $\alpha=1.5$ outperforms the equal-weight baseline and either surpasses or matches the best performance of single networks for each task.</p>
+ </li>
+ <li>
+ <p>Almost any value of 0 < $\alpha$ < 3 improves the network’s performance over an equal weight baseline.</p>
+ </li>
+</ul>
+
+
+
+
+ TaskNorm--Rethinking Batch Normalization for Meta-Learning
+
+ 2020-07-23T00:00:00-04:00
+ /site/2020/07/23/TASKNORM--Rethinking Batch Normalization for Meta-Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Meta-learning techniques are shown to benefit from the use of deep neural networks.</p>
+ </li>
+ <li>
+ <p>BatchNorm is a commonly used component when training deep networks, especially for vision tasks.</p>
+ </li>
+ <li>
+ <p>However, BatchNorm and meta-learning make contradictory assumptions, and their combination may not work well in practice.</p>
+ </li>
+ <li>
+ <p>The paper proposes TaskNorm, a normalization method that is designed explicitly for meta-learning.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2003.03284">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Standard meta-learning setup with $k$ tasks, each task with its own context and target set.</p>
+ </li>
+ <li>
+ <p>Two sets of parameters are considered during meta-learning - (i) global parameters, and (ii) task-specific parameters.</p>
+ </li>
+ <li>
+ <p>Meta-learning setup can be viewed as an inference task, where the task-specific parameters are inferred using a context set and some additional (trainable) parameters.</p>
+ </li>
+ <li>
+ <p>Normalization layers are commonly used to accelerate the training of neural networks. The general approach is to use normalization moments (statistics) along with some learned parameters.</p>
+ </li>
+ <li>
+ <p>BatchNorm is a well-known and widely used normalization approach. It relies on the implicit assumption that the dataset comprises of iid samples from some underlying distribution.</p>
+ </li>
+ <li>
+ <p>However, in meta-learning, data points are assumed to be iid only within a specific task.</p>
+ </li>
+ <li>
+ <p>This leaves open the question of what moments to use during meta-train and meta-test time.</p>
+ </li>
+</ul>
+
+<h2 id="variants-of-batchnorm">Variants of BatchNorm</h2>
+
+<h3 id="conventional-batchnorm-cbn">Conventional BatchNorm (CBN)</h3>
+
+<ul>
+ <li>
+ <p>Compute moments at meta train time and use during meta test time.</p>
+ </li>
+ <li>
+ <p>This is equivalent to lumping the moments with the global parameters. I.e., the running moments are shared globally, while the data is iid only locally.</p>
+ </li>
+ <li>
+ <p>Using CBN with MAML leads to poor results.</p>
+ </li>
+ <li>
+ <p>Moreover, meta-learning setup can some times require the use of a very small batch size. (e.g., 1-shot learning) In those cases, the computed statistics are likely to be inaccurate.</p>
+ </li>
+</ul>
+
+<h3 id="transductive-batchnorm-tbn">Transductive BatchNorm (TBN)</h3>
+
+<ul>
+ <li>
+ <p>Use context/target set statistics at both meta-train and meta-test time.</p>
+ </li>
+ <li>
+ <p>This is the default BatchNorm mode used in MAML.</p>
+ </li>
+</ul>
+
+<h3 id="instance-based-normalization">Instance-based normalization</h3>
+
+<ul>
+ <li>
+ <p>Moments are computed separately for each instance.</p>
+ </li>
+ <li>
+ <p>This mode corresponds to treating the statistics as local at the observation level.</p>
+ </li>
+ <li>
+ <p>These methods provide only limited improvement in performance, and can sometimes have a large overhead.</p>
+ </li>
+</ul>
+
+<h2 id="task-normalization-proposed">Task Normalization (Proposed)</h2>
+
+<ul>
+ <li>
+ <p>The normalization statistics are local at the task level, and statistics for a given data point should only depend on the context set’s data point. It should not depend on the other elements of the target set.</p>
+ </li>
+ <li>
+ <p>Meta-Batch Normalisation (METABN) is a precursor to TaskNorm where the context set alone is used to compute the normalization statistics for both the context and the target set (during both meta-test and meta-train time).</p>
+ </li>
+ <li>
+ <p>METABN does not perform well when used with small context sets.</p>
+ </li>
+ <li>
+ <p>TaskNorm overcomes this limitation by using a set of non-transductive, secondary moments (computed from the input being normalized).</p>
+ </li>
+ <li>
+ <p>When the context is small, using additional moments will help to improve the moment estimates.</p>
+ </li>
+ <li>
+ <p>In the general case, a trainable blending factor, $\alpha$, is used to combine the two sets of moments.</p>
+ </li>
+ <li>
+ <p>While the computational cost of TaskNorm is slightly more than CBN, it converges faster than CBN in practice.</p>
+ </li>
+ <li>
+ <p>Normalization mechanism in Reptile can be interpreted as a particular case of TaskNorm.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Small scale few-shot classification experiments</p>
+
+ <ul>
+ <li>
+ <p>Omniglot and imin ImageNet dataset</p>
+ </li>
+ <li>
+ <p>First order MAML, with different kinds of normalization schemes.</p>
+ </li>
+ <li>
+ <p>Transductive BatchNorm performs the best.</p>
+ </li>
+ <li>
+ <p>Among non-transductive approaches, TaskNorm using Instance Normalisation augmentation performs the best.</p>
+ </li>
+ <li>
+ <p>Similar trend holds for the speed of convergence as well.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Large scale few-shot classification experiments</p>
+
+ <ul>
+ <li>
+ <p>MetaDataset dataset</p>
+ </li>
+ <li>
+ <p>CNAPs model</p>
+ </li>
+ <li>
+ <p>The context set’s size varies across tasks in this setup and can be as small as 5.</p>
+ </li>
+ <li>
+ <p>TaskNorm with Instance Normalisation ranks first in 10 (out of 13) datasets and is also the fastest to train.</p>
+ </li>
+ <li>
+ <p>While Instance-based methods (Instance Normalisation and Layer Normalisation) are the slowest to converge, they still outperform the running average based methods (conventional BatchNorm).</p>
+ </li>
+ <li>
+ <p>The results demonstrate that designing meta-learning specific normalization methods can significantly improve performance and that Transductive BatchNorm may not always be the optimal choice.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Averaging Weights leads to Wider Optima and Better Generalization
+
+ 2020-07-16T00:00:00-04:00
+ /site/2020/07/16/Averaging Weights leads to Wider Optima and Better Generalization
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes Stochastic Weight Averaging (SWA) procedure for improving the generalization performance of models trained with SGD (with cyclic or constant learning rate).</p>
+ </li>
+ <li>
+ <p>Specifically, the model is checkpointed at several points along the training trajectory, and these checkpoints are averaged (in the parameter space) to obtain a single model.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1803.05407">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="idea">Idea</h2>
+
+<ul>
+ <li>
+ <p>“Stochastic” in the name refers to the idea that with cyclical or constant learning rate, SGD proposals are approximately sampled from a neural network’s loss surface and are hence stochastic.</p>
+ </li>
+ <li>
+ <p>SWA uses a learning rate schedule that allows exploration in the weight space.</p>
+ </li>
+ <li>
+ <p>SGD with cyclical and constant learning rates explore points (model instances) at the periphery of high-performing networks.</p>
+ </li>
+ <li>
+ <p>With different initializations, SGD will find different points (of low training loss) on this boundary, but will not move inside it.</p>
+ </li>
+ <li>
+ <p>Averaging the points provide a mechanism to move inside this periphery.</p>
+ </li>
+ <li>
+ <p>The train and the test error surfaces, while being similar, are not perfectly aligned. Hence, averaging several models (along the optimization trajectory) could lead to a more robust model.</p>
+ </li>
+</ul>
+
+<h2 id="algorithm">Algorithm</h2>
+
+<ul>
+ <li>
+ <p>Given a model $w$ and some training budget $B$, train the model in the conventional way for approx 75% of the budget.</p>
+ </li>
+ <li>
+ <p>Starting from that point, continue training with the remaining budget, with a constant or cyclical learning rate.</p>
+ </li>
+ <li>
+ <p>For fixed learning rate, checkpoint models at each epoch. For cyclical learning rate, checkpoint the model at the lowest learning rate in the cycle.</p>
+ </li>
+ <li>
+ <p>Average all the models to get the SWA model.</p>
+ </li>
+ <li>
+ <p>If the model has Batch Normalization layers, run an additional pass to compute the SWA model’s running mean and standard deviation.</p>
+ </li>
+ <li>
+ <p>The computational and space complexity of computing the SWA model is relatively low.</p>
+ </li>
+ <li>
+ <p>The paper highlights the ensembling like the effect of SWA by showing that if the model checkpoints ($w_i$) are generated by training with Fast Geometric Ensembling (FGE), the difference between averaging the weights and averaging the predictions is of the order $O(\Delta)$ where $\Delta = max ||w_i - w_{SA}||$.</p>
+ </li>
+ <li>
+ <p>Note that SWA does not have the overhead of an extra-forward pass during inference.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Datasets: CIFAR10, CIFAR100, ImageNet</p>
+ </li>
+ <li>
+ <p>Models: VGG16, WideResNet, 164-layer preactivation ResNet, ShakeShake, Pyramid Net.</p>
+ </li>
+ <li>
+ <p>Baselines: Conventional SGD, Exponentially decaying average with SGD and FGE.</p>
+ </li>
+ <li>
+ <p>In all the CIFAR experiments, SWA consistently outperforms SGD in one budget and consistently improves with training.</p>
+ </li>
+ <li>
+ <p>SWA also achieves performance comparable to FGE, despite FGE being an ensemble method.</p>
+ </li>
+ <li>
+ <p>On ImageNet, SWA is run on a pre-trained model, and it improves performance in all the cases.</p>
+ </li>
+ <li>
+ <p>An ablation experiment (on CIFAR-100) shows that it is possible to train a network (with SWA) using a fixed learning rate. In that setup, using SWA improves performance by 16%.</p>
+ </li>
+</ul>
+
+
+
+
+ Decentralized Reinforcement Learning -- Global Decision-Making via Local Economic Transactions
+
+ 2020-07-09T00:00:00-04:00
+ /site/2020/07/09/Decentralized Reinforcement Learning -- Global Decision-Making via Local Economic Transactions
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper explores the connections between the concepts of a single agent vs. society of agents.</p>
+ </li>
+ <li>
+ <p>A society of agents can be modeled as a single agent while a single agent can be modeled as a society of components (or sub-agents).</p>
+ </li>
+ <li>
+ <p>The paper focuses on mechanisms for training a society of self-interested agents to solve a given task – as if the system was a single task.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2007.02382">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="contributions">Contributions</h2>
+
+<ul>
+ <li>
+ <p><strong>Societal-decision making</strong> framework relates the local optimization problem of a single agent with the global optimization problem of a society of agents.</p>
+ </li>
+ <li>
+ <p><strong>Cloned Vickrey Society</strong> is proposed as a mechanism to guarantee that an agent’s dominant strategy equilibrium coincides with the group’s optimal policy.</p>
+ </li>
+ <li>
+ <p>A class of <strong>decentralized RL algorithms</strong> that optimize the MDP object of the society as a whole, as a consequence of individual agents optimizing their objectives.</p>
+ </li>
+ <li>
+ <p>Empirical evaluation of Cloned Vickrey Society using any implementation called <strong>Credit Conserving Vickery</strong>.</p>
+ </li>
+</ul>
+
+<h2 id="terminology">Terminology</h2>
+
+<ul>
+ <li>
+ <p><em>Environment</em> - a tuple that specifies an input space, an output space, and parameters for determining an objective.</p>
+
+ <ul>
+ <li>A standard RL setup can be mapped to <em>environment</em> by mapping state space to input space, action space to output space and reward function, transition function, and discount factors to the parameters specifying the objective.</li>
+ </ul>
+ </li>
+ <li>
+ <p><em>Agent</em> - a function that maps input space to output space.</p>
+ </li>
+ <li>
+ <p><em>Objective</em> - a functional that maps an agent to a real number.</p>
+ </li>
+ <li>
+ <p>In <em>auction environments</em>, the input space is a single auction item (say <em>s</em>), and the output space is bidding space <em>B</em>.</p>
+ </li>
+ <li>
+ <p>There are <em>N</em> agents who compete by bidding for an item <em>s</em> using their bidding policy.</p>
+ </li>
+ <li>
+ <p>$b$ is a vector of bids produced by the agents.</p>
+ </li>
+ <li>
+ <p>$v_s$ is a vector of agent’s valuations of item <em>s</em>.</p>
+ </li>
+ <li>
+ <p>The $i^{th}$ agent’s utility is given as $v_s^i \times X^i(b) - P^i(b)$. Here, $X^i(b)$ is the portion of $s$ allocated to $i^{th}$ agent and $P^i(b)$ is the price that $i^{th}$ agent is willing to pay.</p>
+ </li>
+</ul>
+
+<h2 id="design-choices">Design Choices</h2>
+
+<ul>
+ <li>
+ <p>Each agent is independently maximizing its utility.</p>
+ </li>
+ <li>
+ <p>In certain conditions (i.e., if the auction is dominant strategy incentive compatible), it is optimal for each agent to bid its valuation.</p>
+ </li>
+ <li>
+ <p>These conditions are satisfied by the Vickery auction where $P^i(b)$ is set to be the second-highest bid and $X^i(b) = 1$ if the $i^{th}$ agent wins (and 0 otherwise).</p>
+ </li>
+ <li>
+ <p>A <em>society</em> is a set of agents where each agent is a tuple of bidding policy $\psi$ and a transformation function.</p>
+ </li>
+ <li>
+ <p>The environment is modeled at two levels - (i) global environment (referred to as the global MDP) and local environment (referred to as local auction).</p>
+ </li>
+ <li>
+ <p>Each state $s$ in the global MDP is an auction item in a different auction. The winner (of local auction at $s$) transforms $s$ into some other state $s’$.</p>
+ </li>
+ <li>
+ <p>If these transformations are modeled as actions, then the proposed framework can be interpreted as a decentralized reinforcement learning framework.</p>
+ </li>
+ <li>
+ <p>Motivated by the design of market economy (where economic transactions determine wealth distribution), the paper proposes that, for an agent, the valuation of winning an auction is the revenue it can receive in the auction at the next timestep by selling the transformed state.</p>
+ </li>
+ <li>
+ <p>A global MDP that adhere to this design is referred to as the Market MDP.</p>
+ </li>
+ <li>
+ <p>There is a catch in the design of the market MDP - the winning agent, at time $t-1$, gets the amount that the highest bidder is willing to pay at time $t+1$. But the winner at time $t+1$ only paid the second-highest bid. Hence, the credit is not conserved.</p>
+ </li>
+ <li>
+ <p>This inconsistency can be fixed by introducing “duplicate” (or cloned) agents, and the society is called the Cloned Vickery Society.</p>
+ </li>
+ <li>
+ <p>The Cloned Vickrey Auction mechanism is compared against alternate bidding mechanisms like <em>first price auction</em> (where winner pays the bid they proposed), solitary version of Vickrey auction (no cloning), and <em>Environment Reward</em> where only environment reward is used, and there is no price term.</p>
+ </li>
+ <li>
+ <p>It is empirically shown that Cloned Vickrey Auction learns bids that are most close to their actual valuations. Moreover, solitary version leads bids which are more spread out than the ones learned by cloned version. This highlights the importance of competitive pressure to learn bid values.</p>
+ </li>
+ <li>
+ <p>Three different implementations of Cloned Vickrey Auction are considered:</p>
+
+ <ul>
+ <li>
+ <p>Bucket Brigade (BB) - winner at timestep $t$ receives the highest bid at time step $t+1$, and the subsequent winner pays the highest bid. This case satisfies Credit Conservation and Bellman Optimality.</p>
+ </li>
+ <li>
+ <p>Vickrey (V) - winner at timestep $t$ receives the highest bid at time step $t+1$, and the subsequent winner pays the second-highest bid. This case satisfies Truthful Dominant Strategy and Bellman Optimality.</p>
+ </li>
+ <li>
+ <p>Credit Conserving Vickrey (CCV) - winner at timestep $t$ receives the second-highest bid at time step $t+1$, and the subsequent winner pays the second-highest bid. This case satisfies Truthful Dominant Strategy and Credit Conservation.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>CCV implementation provides bid values closest to the optimal Q-values.</p>
+ </li>
+ <li>
+ <p>In one experiment, the paper explores the use of the proposed approach for selecting between sub-policies. It shows that CVV is more sample efficient for pretraining sub-policies and adapting them to transfer tasks.</p>
+ </li>
+ <li>
+ <p>In another experiment, the task is to transform MNIST images by composing two out of 6 affine transformations. The transformed images are fed to a pretrained classifier that predicts a label. The agent gets a reward of 1 if the classifier makes correct prediction and 0 otherwise. CCV implementation obtains a mean reward of 0.933, thus highlighting the effectiveness of the CCV model.</p>
+ </li>
+</ul>
+
+
+
+
+ When to use parametric models in reinforcement learning?
+
+ 2020-07-02T00:00:00-04:00
+ /site/2020/07/02/When to use parametric models in reinforcement learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper compares replay-based approaches with model-based approaches in Reinforcement Learning (RL).</p>
+ </li>
+ <li>
+ <p>It hypothesizes that if the parametric model is only used for generation transitions for the update rule, then under certain conditions, replay-based approaches will be as good as model-based approaches.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1906.05243">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="terminology">Terminology</h2>
+
+<ul>
+ <li>
+ <p>Planning: Any algorithm that uses additional computations (but not additional experience) to improve its performance.</p>
+ </li>
+ <li>
+ <p>Learning: Any algorithm that uses additional experience to improve its performance.</p>
+ </li>
+ <li>
+ <p>In some cases, a replay buffer can be seen as a model. For example, querying using state-action pair (from the replay buffer) is similar to querying the (expected) next-state and reward from a model. In general, the model will be more flexible as any arbitrary state-action pair can be used for querying.</p>
+ </li>
+</ul>
+
+<h2 id="computation-properties">Computation Properties</h2>
+
+<ul>
+ <li>
+ <p>Parametric models require more computation than sampling from a replay buffer. In contrast, the cost of maintaining a replay buffer scales linearly with their capacity.</p>
+ </li>
+ <li>
+ <p>Parametric models are useful for planning multiple-steps into the future while it is much harder to do so with a replay buffer (even more so with pixel observations).</p>
+ </li>
+ <li>
+ <p>An imperfect model maybe be more suitable for selecting actions (instead of updating the policy) because the chosen action, when executed in the environment, will lead to transitions that would improve the model.</p>
+ </li>
+ <li>
+ <p>When planning with an imperfect model, it is better to plan backward, as the update is applied on an imaginary state (which would not be encountered if the model is poor).</p>
+ </li>
+ <li>
+ <p>If the model is accurate, forward and backward planning is equivalent. This distinction between forward and backward updates does not apply to replay buffers.</p>
+ </li>
+</ul>
+
+<h2 id="failure-to-learn">Failure to learn</h2>
+
+<ul>
+ <li>
+ <p>When using a replay buffer and (i) uniformly replaying transitions, (ii) from a buffer containing only full episodes, and (iii) using TD updates, then the algorithm is stable.</p>
+ </li>
+ <li>
+ <p>When using a replay buffer and (i) uniformly replaying transitions, (ii) generating transitions using a model, and (iii) using TD updates, then the algorithm can diverge.</p>
+ </li>
+ <li>
+ <p>This case can be fixed by:</p>
+
+ <ul>
+ <li>
+ <p>Repeatedly interating over the model and sampling transitions <em>to</em> and <em>from</em> the state model generates (not a satisfactory solution).</p>
+ </li>
+ <li>
+ <p>Using multiple-step returns (this can increase the variance).</p>
+ </li>
+ <li>
+ <p>Use algorithms specifically for stable off-policy learning (not a definitive solution).</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="model-based-algorithms-at-scale">Model-based algorithms at scale</h2>
+
+<ul>
+ <li>
+ <p>The paper compares against SimPLe (model-based) with Rainbow DQN (replay-based).</p>
+ </li>
+ <li>
+ <p>The paper shows that when using a similar number of real interactions, Rainbow DQN needs fewer replay samples than model samples in SimPLe, making it more efficient (computation-wise).</p>
+ </li>
+ <li>Changes to Rainbow DQN:
+ <ul>
+ <li>Increase number of steps, for bootstrapping, from 3 to 20.</li>
+ <li>Reduce the number of steps, before sampling starts from the replay buffer, from 20K to 1600.</li>
+ </ul>
+ </li>
+ <li>With these changes, Rainbow DQN outperforms SimPLe in 17 out of 26 games.</li>
+</ul>
+
+<h2 id="conclusion">Conclusion</h2>
+
+<ul>
+ <li>
+ <p>When using a parametric model in a replay-like setting (sampling observed states from the past), model-based learning can be unstable (in theory). Using a replay buffer is likely a better strategy under the state sampling distribution.</p>
+ </li>
+ <li>
+ <p>Parametric models are likely more useful when:</p>
+ <ul>
+ <li>planning backward for credit assignment - even if the model is in-accurate, backward planning will only update fictional states.</li>
+ <li>planning forward for behavior - the resulting plan is only used to collect real <em>experience</em> in the environment (and not directly update the policy).</li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Network Randomization - A Simple Technique for Generalization in Deep Reinforcement Learning
+
+ 2020-06-25T00:00:00-04:00
+ /site/2020/06/25/Network Randomization-A Simple Technique for Generalization in Deep Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposed a Technique for improving the generalization ability of RL agents when evaluated on an unseen environment (which is similar to the training environment).</p>
+ </li>
+ <li>
+ <p><a href="https://openreview.net/forum?id=HJgcvJBFvB">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/pokaxpoka/netrand">Link to the code</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>The key idea is to learn features that are invariant across environments by using a randomized CNN (<em>f</em>) that randomly perturbs the inputs.</p>
+ </li>
+ <li>
+ <p>The policy is trained using the randomized observations obtained using <em>f</em>.</p>
+ </li>
+ <li>
+ <p>Invariant features are learned using a feature matching (FM) loss that matches the feature representation of the original and randomized observations.</p>
+ </li>
+ <li>
+ <p>The random network’s parameters are initialized as $\alpha I + (1 - \alpha) N(0, \sqrt\frac{2}{n_{in} + n_{out}})$ where $\alpha \in [0, 1]$, $N$ denotes the Gaussian Distribution and $n_{in}, n_{out}$ denote the number of input and output channels respectively.</p>
+ </li>
+ <li>
+ <p>Xavier Normal distribution is used for randomization to maintain the variance between the input and the randomized input.</p>
+ </li>
+ <li>
+ <p><em>f</em> is randomized per iteration.</p>
+ </li>
+ <li>
+ <p>During inference, the expected action is computed by approximating over <em>M</em> samples (i.e., randomizing the input <em>M</em> times).</p>
+ </li>
+</ul>
+
+<h2 id="environments">Environments</h2>
+
+<ul>
+ <li>
+ <p>2D CoinRun, 3D DeepMind Lab, 3D Robotics Control Task</p>
+ </li>
+ <li>
+ <p>The evaluation environments consist of different styles of backgrounds, objects, and floors.</p>
+ </li>
+</ul>
+
+<h2 id="baselines">Baselines</h2>
+
+<ul>
+ <li>
+ <p>Regularization methods: Dropout, L2 regularization, Batch Normalization</p>
+ </li>
+ <li>
+ <p>Dataset Augmentation methods: Cutout, Gray out, Inversion, Color Jitter</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>On CoinRun, the proposed approaches significantly outperforms the other baselines during evaluation. The performance improvement saturates around 10 <em>M</em> samples.</p>
+ </li>
+ <li>
+ <p>Cycle consistency is used to measure the similarity between two trajectories. The proposed method improves the cycle consistency as compared to the vanilla PPO baseline. It also produces sharper activation maps in the evaluation environments.</p>
+ </li>
+ <li>
+ <p>For the large-scale experiments, when evaluated on 500 levels of CoinRun, the proposed method improves the success rates from 39.8% to 58.7%.</p>
+ </li>
+ <li>
+ <p>On DeepMind Lab and Surreal robotics control tasks, the proposed method leads to agents that generalize better on the unseen environments (during evaluation).</p>
+ </li>
+</ul>
+
+
+
+
+ On the Difficulty of Warm-Starting Neural Network Training
+
+ 2020-06-18T00:00:00-04:00
+ /site/2020/06/18/On the Difficulty of Warm-Starting Neural Network Training
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper considers learning scenarios where the training data is available incrementally (and not at once).</p>
+ </li>
+ <li>
+ <p>For example, in some applications, new data is available periodically (e.g., latest news articles come out every day).</p>
+ </li>
+ <li>
+ <p>The paper highlights that, in such scenarios, the conventional wisdom of “warm start” does not apply.</p>
+ </li>
+ <li>
+ <p>When new data is available, it is better to train a new model from scratch than to update the model trained on previously available data.</p>
+ </li>
+ <li>
+ <p>While the two setups lead to similar training performance, the randomly initialized model has a much better generalization performance.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1910.08475">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="basic-batch-updating">Basic Batch Updating</h2>
+
+<ul>
+ <li>
+ <p>Create two random, equally-sized partitions of the training data.</p>
+ </li>
+ <li>
+ <p>Train the model till convergence on the first half of the data. Then train the model on the entire dataset.</p>
+ </li>
+ <li>
+ <p>Models: ResNet18, MLPs, Logisitic Regression (LR)</p>
+ </li>
+ <li>
+ <p>Dataset: CIFAR10, CIFAR100, SVHN</p>
+ </li>
+ <li>
+ <p>Optimizers: Adam, SGD</p>
+ </li>
+ <li>
+ <p>Warm starting hurts generalization in all the cases.</p>
+ </li>
+ <li>
+ <p>The effect is more pronounced in the case of ResNets and MLPs (compared to LR) and harder CIFAR 10 dataset (as compared to SVHN dataset).</p>
+ </li>
+</ul>
+
+<h2 id="online-learning">Online Learning</h2>
+
+<h3 id="passive-online-learning">Passive Online Learning</h3>
+
+<ul>
+ <li>
+ <p>The model is given access to k new learning examples at each iteration.</p>
+ </li>
+ <li>
+ <p>A warm started model reuses the previously initialized model and trains (till convergence) on the new batch of k items.</p>
+ </li>
+ <li>
+ <p>A “randomly initialized” model is trained on all the examples (seen so far) from scratch.</p>
+ </li>
+ <li>
+ <p>Dataset: CIFAR10</p>
+ </li>
+ <li>
+ <p>Model: ResNet18</p>
+ </li>
+ <li>
+ <p>As more training data becomes available, the generalization gap between the two setups increases, and warmup starts hurting generalization.</p>
+ </li>
+</ul>
+
+<h3 id="active-online-learning">Active Online Learning</h3>
+
+<ul>
+ <li>
+ <p>In this setup, the learner is trained to sample k new examples to add to the training dataset (using margin-based sampling).</p>
+ </li>
+ <li>
+ <p>Like the previous setup, warmup strategy still hurts generalization.</p>
+ </li>
+</ul>
+
+<h2 id="transfer-learning">Transfer Learning</h2>
+
+<ul>
+ <li>
+ <p>Train a Resnet18 model on the CIFAR10 dataset and use this model to warm start training on the SVHN dataset.</p>
+ </li>
+ <li>
+ <p>When a small percentage of the SVHN dataset is used, the setup resembles pretraining / transfer learning and performs better than training from scratch.</p>
+ </li>
+ <li>
+ <p>As the percentage of the SVHN dataset increases, the warmup approach starts underperforming.</p>
+ </li>
+</ul>
+
+<h2 id="overcoming-warm-start-problem">Overcoming warm start problem</h2>
+
+<ul>
+ <li>
+ <p>ResNet18 model on CIFAR10 dataset</p>
+ </li>
+ <li>
+ <p>When performing a hyper-parameter sweep over the learning rate and batch size, it is possible to train warm start models to reach the same generalization performance as training from scratch.</p>
+ </li>
+ <li>
+ <p>Though, in that case, there are no computational savings as the warm-started models take about the same time (to converge) as the randomly initialized model.</p>
+ </li>
+ <li>
+ <p>The increased training time indicates that the warm started model probably needs to forget the knowledge from previous training rounds.</p>
+ </li>
+ <li>
+ <p>Warm start Resnet models, that generalize well, have a low correlation to their initialization stage (measured via Pearson correlation coefficient between the model weights).</p>
+ </li>
+ <li>
+ <p>Generalization is damaged even when using a model trained on incomplete data for only a few epochs.</p>
+ </li>
+ <li>
+ <p>For warm start models, the gradient (corresponding to the “new” data) is higher than that for randomly initialized models. This hints that regularisation may help to close the generalization gap. But in practice, regularization helps both the warmup and randomly initialized model.</p>
+ </li>
+ <li>
+ <p>Warm starting only a few layers also does not close the gap.</p>
+ </li>
+ <li>
+ <p>Adding some noise to the warm started model (with the motivation of having a partially random initialization) does help somewhat but also increases the training time.</p>
+ </li>
+ <li>
+ <p>Motivating the problem as an instance of catastrophic forgetting, the authors use the EWC algorithm but report that using EWC hurts model performance.</p>
+ </li>
+ <li>
+ <p>The paper does not propose a solution to the problem but provides a thorough analysis of the problem setup, which is quite useful for understanding the phenomenon itself.</p>
+ </li>
+</ul>
+
+
+
+
+ Supervised Contrastive Learning
+
+ 2020-04-30T00:00:00-04:00
+ /site/2020/04/30/Supervised Contrastive Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper builds on the prior work on self-supervised contrastive learning and extends it for the supervised learning case where many positive examples are available for each anchor.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/2004.11362">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>The representation learning framework has the following components:</li>
+</ul>
+
+<h3 id="data-augmentation-module">Data Augmentation Module</h3>
+
+<ul>
+ <li>
+ <p>This module transforms the input example. The paper considers the following strategies:</p>
+
+ <ul>
+ <li>Random crop, followed by resizing</li>
+ <li><a href="https://arxiv.org/abs/1805.09501">Auto Augment</a> - A method to search for data augmentation strategies.</li>
+ <li><a href="https://arxiv.org/abs/1909.13719">Rand Augment</a> - Randomly sampling a sequence of data augmentations, with repetition</li>
+ <li>SimAugment - Sequentially apply random color distortion and Gaussian blurring, followed by probabilistic sparse image wrap.</li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="encoder-network">Encoder Network</h3>
+
+<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>* This module maps the input to a latent representation.
+
+* The same network is used to encode both the anchor and the sample.
+
+* The representation vector is normalized to lie on the unit hypersphere.
+</code></pre></div></div>
+
+<h3 id="projection-network">Projection Network</h3>
+
+<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>* This module maps the normalized representation to another representation, on which the contrastive loss is computed.
+
+* This network is only used for training the supervised contrastive loss.
+</code></pre></div></div>
+
+<h3 id="loss-function">Loss function</h3>
+
+<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>* The paper extends the standard contrastive loss formulation to handle multiple positive examples.
+
+* The main effect is that the modified loss accounts for all the same-class pairs (from within the sampled batch as well as the augmented batch).
+
+* The paper shows that the gradient (corresponding to the modified loss) causes the learning to focus more on hard examples. "Hard" cases are the ones where contrasting the anchor benefits the encoder more.
+
+* The proposed loss can also be seen as a generalization of the triplet loss.
+</code></pre></div></div>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Dataset - ImageNet</p>
+ </li>
+ <li>
+ <p>Models - ResNet50, ResNet200</p>
+ </li>
+ <li>
+ <p>The network is “pretrained” using supervised contrastive loss.</p>
+ </li>
+ <li>
+ <p>After pre-training, the projection network is removed, and a linear classifier is added.</p>
+ </li>
+ <li>
+ <p>This classifier is trained with the CE loss while the rest of the network is kept fixed.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Using supervised contrastive loss improves over all the baseline models and data augmentation approaches.</p>
+ </li>
+ <li>
+ <p>The resulting classifier is more robust to image corruptions, as shown by the mean Corruption Error (mCE) metric on the ImageNet-C dataset.</p>
+ </li>
+ <li>
+ <p>The model is more stable to the choice oh hyperparameter values (like optimizers, data augmentation, and learning rates).</p>
+ </li>
+</ul>
+
+<h2 id="training-details">Training Details</h2>
+
+<ul>
+ <li>
+ <p>Supervised Contrastive loss is trained for 700 epochs during pre-training.</p>
+ </li>
+ <li>
+ <p>Each step is about 50% more expensive than performing CE.</p>
+ </li>
+ <li>
+ <p>The dense classifier layer can be trained in as few as ten epochs.</p>
+ </li>
+ <li>
+ <p>The temperature value is set to 0.07. Using a lower temperature is better than using a higher temperature.</p>
+ </li>
+</ul>
+
+
+
+
+
+ CURL - Contrastive Unsupervised Representations for Reinforcement Learning
+
+ 2020-04-09T00:00:00-04:00
+ /site/2020/04/09/CURL Contrastive Unsupervised Representations for Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a contrastive learning approach, called CURL, for performing off-policy control from raw pixel observations (by transforming them into high dimensional features).</p>
+ </li>
+ <li>
+ <p>The idea is motivated by the application of contrastive losses in computer vision. But there are additional challenges:</p>
+
+ <ul>
+ <li>
+ <p>The learning agent has to perform both unsupervised and reinforcement learning.</p>
+ </li>
+ <li>
+ <p>The “dataset” for unsupervised learning is not fixed and keeps changing with the policy of the agent.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Unlike prior work, CURL introduces fewer changes in the underlying RL pipeline and provides more significant sample efficiency gains. For example, CURL (trained on pixels) nearly matches the performance of SAC policy (trained on state-based features).</p>
+ </li>
+ <li>
+ <p><a href="https://github.com/MishaLaskin/curl">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="implementation">Implementation</h2>
+
+<ul>
+ <li>
+ <p>CURL uses instance discrimination. Deep RL algorithms commonly use a stack of temporally consecutive frames as input to the policy. In such cases, instance discrimination is applied to all the images in the stack.</p>
+ </li>
+ <li>
+ <p>For generating the positive and negative samples, random crop data augmentation is used.</p>
+ </li>
+ <li>
+ <p>Bilinear inner product is used as the similarity metric as it outperforms the commonly used normalized dot product.</p>
+ </li>
+ <li>
+ <p>For encoding the anchors and the samples, InfoNCE is used. It learns two encoders $f_q$ and $f_k$ that transform the query (base input) and the key (positive/negative samples) into latent representations. The similarity loss is applied to these latents.</p>
+ </li>
+ <li>
+ <p>Momentum contrast is used to update the parameters ($\theta_k$) of the $f_k$ network. ie $\theta_k = m \theta_k + (1-m) \theta_q$. $\theta_q$ are the parameters of the $f_q$ network and are updated in the usual way, using both the contrastive loss and the RL loss.</p>
+ </li>
+</ul>
+
+<h2 id="experiment">Experiment</h2>
+
+<ul>
+ <li>
+ <p>DMControl100K and Atart100K refer to the setups where the agent is trained for 100K steps on DMControl and Atari, respectively.</p>
+ </li>
+ <li>
+ <p>Metrics:</p>
+
+ <ul>
+ <li>
+ <p>Sample Efficiency - How many steps does the baseline need to match CURL’s performance after 100K steps.</p>
+ </li>
+ <li>
+ <p>Performance - Ratio of episodic returns by CURL vs. the baseline after 100K steps.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Baselines:</p>
+
+ <ul>
+ <li>
+ <p>DMControl</p>
+
+ <ul>
+ <li><a href="https://arxiv.org/abs/1910.01741">SAC-AE</a></li>
+ <li><a href="https://arxiv.org/abs/1907.00953">SLAC</a></li>
+ <li><a href="https://planetrl.github.io/">PlaNet</a></li>
+ <li><a href="https://openreview.net/forum?id=S1lOTC4tDS">Dreamer</a></li>
+ <li><a href="https://arxiv.org/abs/1812.05905">Pixel SAC</a></li>
+ <li>SAC trained on state-space observations</li>
+ </ul>
+ </li>
+ <li>
+ <p>Atari</p>
+
+ <ul>
+ <li><a href="https://arxiv.org/abs/1903.00374">SimPLe</a></li>
+ <li><a href="https://arxiv.org/abs/1710.02298">RainbowDQN</a></li>
+ <li><a href="https://openreview.net/forum?id=Bke9u1HFwB">OTRainbow (Over Trained Rainbow)</a></li>
+ <li><a href="https://arxiv.org/abs/1906.05243">Efficient Rainbow</a></li>
+ <li>Random Agent</li>
+ <li>Human Performance</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Results</p>
+
+ <ul>
+ <li>
+ <p>DM Control</p>
+
+ <ul>
+ <li>
+ <p>CURL outperforms all pixel-based RL algorithms by a significant margin for all environments on DMControl and most environments on Atari.</p>
+ </li>
+ <li>
+ <p>On DMControl, it closely matches the performance of the SAC agent trained on state-space observations.</p>
+ </li>
+ <li>
+ <p>On Atari, it achieves better median human normalizes score (HNS) than the other baselines and close to human efficiency in three environments.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Competitive Training of Mixtures of Independent Deep Generative Models
+
+ 2020-03-12T00:00:00-04:00
+ /site/2020/03/12/Competitive Training of Mixtures of Independent Deep Generative Models
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a Competitive training mechanism to train a mixture of independent generative models.</p>
+ </li>
+ <li>
+ <p>The idea is that this mixture of different models would divide the data distribution amongst themselves and specialize to their respective splits.</p>
+ </li>
+ <li>
+ <p>The training procedure is related to clustering-based methods.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1804.11130">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="motivation">Motivation</h2>
+
+<ul>
+ <li>
+ <p>In causal modeling, a common assumption is that the data is generated by a set of independent mechanisms.</p>
+ </li>
+ <li>
+ <p>It is not known which mechanism generates which datapoint and recovering the underlying mechanisms can be modeled as learning a structural causal generative model.</p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>The paper assumes that the support of the different generators do not overlap, i.e., the underlying data distribution is factorized into non-overlapping regions.</p>
+ </li>
+ <li>
+ <p>This data factorization is learned using a set of discriminators.</p>
+ </li>
+ <li>
+ <p>If there are $k$ generators, $k$ binary partition functions $c_i, … c_k$ are used.</p>
+ </li>
+ <li>
+ <p>For a given datapoint $x$, if $c_i(x) = 1$ then $c_j(x) = 0$ for all other $j$ and $x$ is assigned to $i^{th}$ generator.</p>
+ </li>
+ <li>
+ <p>For a fixed partition function $c_j^t$ ($t$ denotes the partition function at time $t$), minimize the sum of f-divergence between the model and the data distribution (that is assigned to it). The loss formulation is an upper bound on the f-divergence of the mixture model.</p>
+ </li>
+ <li>
+ <p>In the next step, the data points are re-assigned to the generative models, based on the likelihood of each data point for each model.</p>
+ </li>
+ <li>
+ <p>The likelihood is estimated by training a discriminator that can distinguish the generated samples from the real samples.</p>
+ </li>
+</ul>
+
+<h3 id="independence-as-an-inductive-bias">Independence as an inductive bias</h3>
+
+<ul>
+ <li>
+ <p>The independence assumption may be too restrictive because the low-level features will be common across the distribution splits.</p>
+ </li>
+ <li>
+ <p>This “violation” can be avoided by pretraining the model using a uniform random split of the dataset. In that case, the independence assumption will hold approximately after pretraining.</p>
+ </li>
+ <li>
+ <p>Another approach could be to share some parameters across the models.</p>
+ </li>
+ <li>
+ <p>A “load balancing” approach is also used where each model always keeps training on the data points assigned to it if not enough data points are assigned to it.</p>
+ </li>
+</ul>
+
+<h3 id="comparison-to-vaes-and-gans">Comparison to VAEs and GANs</h3>
+
+<ul>
+ <li>
+ <p>VAEs tend to be “overly inclusive” of the training distribution, i.e., they try to cover the entire support of the distribution.</p>
+ </li>
+ <li>
+ <p>GANs are prone to mode collapse where the model focuses only on one part of the distribution.</p>
+ </li>
+ <li>
+ <p>The proposed method provides a middle ground where the different generative models can focus on different parts of the distribution.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>The experiments seem to be limited. The paper shows that their proposed setup improves over the VAE and GAN baselines.</p>
+ </li>
+ <li>
+ <p>For datasets, the paper uses two-dimensional synthetic data, MNIST and CelebA</p>
+ </li>
+</ul>
+
+
+
+
+ What Does Classifying More Than 10,000 Image Categories Tell Us?
+
+ 2020-03-05T00:00:00-05:00
+ /site/2020/03/05/What Does Classifying More Than 10,000 Image Categories Tell Us
+ <ul>
+ <li>
+ <p>The paper is among the first to study image classification at a large scale (10000 classes and 9 million examples).</p>
+ </li>
+ <li>
+ <p>This is a relatively old paper (2010). Some of the findings may not be relevant anymore. For instance, specific scaling challenges have been significantly overcome. Moreover, the paper uses approaches like SVM and KNN (popular at that time) and not use CNNs.</p>
+ </li>
+ <li>
+ <p>Other observations of the paper are still very relevant, and it is an educating paper. For example, since ImagetNet classes are based on WordNet, the paper looks at the effect of semantic relations (tree) of categories on the performance of the training models.</p>
+ </li>
+ <li>
+ <p><a href="http://openaccess.thecvf.com/content_cvpr_2015/papers/Jain_What_do_15000_2015_CVPR_paper.pdf">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>The paper considers three variants of the ImageNet dataset - ImageNet 10K (10184 classes), ImageNet 7K (7404 classes) and ImageNet 1K (1000 classes).</p>
+ </li>
+ <li>
+ <p>They also consider smaller variants with randomly sampled classes or cases where the examples are sampled from one high-level category like vehicles.</p>
+ </li>
+ <li>
+ <p>SVM and KNN models are used with features like Bag of Words, GIST descriptors, and spatial pyramid of histograms.</p>
+ </li>
+ <li>
+ <p>Observations</p>
+
+ <ul>
+ <li>
+ <p>A model that performs well on the smaller dataset (with fewer classes) may not perform well on the larger dataset (with more classes).</p>
+ </li>
+ <li>
+ <p>There seems to be an approximate correlation between the structure of the semantic hierarchy of the labels (obtained via WordNet) and visual confusion between the categories.</p>
+ </li>
+ <li>
+ <p>For example, consider two high-level concepts - says artifacts and animals. The model is less likely to confuse between the classes across the high-level concepts but more likely to confuse between the classes in the respective concepts.</p>
+ </li>
+ <li>
+ <p>For dense categories (categories where the classes are semantically more closely related to each other), the model tends to make more mistakes (even if the number of classes is fewer).</p>
+ </li>
+ <li>
+ <p>Accounting for the label hierarchy (in the loss function) improves the classification performance.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ mixup - Beyond Empirical Risk Minimization
+
+ 2020-02-27T00:00:00-05:00
+ /site/2020/02/27/mixup Beyond Empirical Risk Minimization
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a simple and dataset-agnostic data augmentation mechanism called <em>mixup</em>.</p>
+ </li>
+ <li>
+ <p><a href="">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>Consider two training examples, $(x_1, y_1)$ and $(y_1, y_2)$, where $x_1$ and $x_2$ are the datapoints and $y_1$ and $y_2$ are the labels.</p>
+ </li>
+ <li>
+ <p>New training examples of the form $(\lambda \times x_1 + (1-\lambda) \times x_2, \lambda \times y_1 + (1-\lambda) \times y_2)$ are constructured by considering the linear interpolation of the datapoints and the labels. Here $\lambda \in [0, 1]$.</p>
+ </li>
+ <li>
+ <p>$\lambda$ is sampled from a Beta distribution $Beta(\alpha, \alpha)$ where $\alpha \in (0, \infty)$.</p>
+ </li>
+ <li>
+ <p>Setting $\lambda$ to 0 or 1 eliminates the effect of <em>mixup</em>.</p>
+ </li>
+ <li>
+ <p>Mixup encourages the neural network to favor linear behavior between the training examples.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p><strong>Supervised Learning</strong></p>
+
+ <ul>
+ <li>
+ <p>ImageNet for ResNet-50, ResNet-101 and ResNext-101.</p>
+ </li>
+ <li>
+ <p>CIFAR10/CIFAR100 for PreAct ResNet-18, WideResNet-28-10 and DenseNet.</p>
+ </li>
+ <li>
+ <p>Google command dataset for LeNet and VGG.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In all these setups, adding <em>mixup</em> improves the performance of the model.</p>
+ </li>
+ <li>
+ <p><em>Mixup</em> makes the model more robust to noisy labels. Moreover, <em>mixup</em> + dropout improves over <em>mixup</em> alone. This hints that <em>mixup</em>’s benefits are complementary to those of dropout.</p>
+ </li>
+ <li>
+ <p><em>Mixup</em> makes the network more robust to adversarial examples in both white-box and black-box settings (ImageNet + Resnet101).</p>
+ </li>
+ <li>
+ <p><em>Mixup</em> also stabilizes the training of GANs by acting as a regularizer for the gradient of the discriminator.</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>Convex combination of three or more examples (with weights sampled from a Dirichlet distribution) does not provide gains over the case of two examples.</p>
+ </li>
+ <li>
+ <p>In the authors’ implementation, <em>mixup</em> is applied between images of the same batch (after shuffling).</p>
+ </li>
+ <li>
+ <p>Interpolating only between inputs, with the same labels, did not lead to the same kind of gains as <em>mixup</em>.</p>
+ </li>
+</ul>
+
+
+
+
+ ELECTRA - Pre-training Text Encoders as Discriminators Rather Than Generators
+
+ 2020-02-20T00:00:00-05:00
+ /site/2020/02/20/ELECTRA - Pre-training Text Encoders as Discriminators Rather Than Generators
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Masked Language Modeling (MLM) is a common technique for pre-training language-based models. The idea is to “corrupt” some tokens in the input text (around 15%) by replacing them with the [MASK] token and then training the network to reconstruct (or predict) the corrupted tokens.</p>
+ </li>
+ <li>
+ <p>Since the network learns from only about 15% of the tokens, the computational cost of training using MLM can be quite high.</p>
+ </li>
+ <li>
+ <p>The paper proposes to use a “replaced token detection” task where some tokens in the input text are replaced by other plausible tokens.</p>
+ </li>
+ <li>
+ <p>For each token in the modified text, the network has to predict if the token has been replaced or not.</p>
+ </li>
+ <li>
+ <p>The alternative token is generated using a small generator network.</p>
+ </li>
+ <li>
+ <p>Unlike the previous MLM setup, the proposed task is defined for all the input tokens, thus utilizing the training data more efficiently.</p>
+ </li>
+ <li>
+ <p><a href="https://openreview.net/forum?id=r1xMH1BtvB">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>The proposed approach is called ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)</p>
+ </li>
+ <li>
+ <p>Two neural networks - Generator (G) and Discriminator (D) are trained.</p>
+ </li>
+ <li>
+ <p>Each network has a Transformer-based text encoder that maps a sequence of words into a sequence of vectors.</p>
+ </li>
+ <li>
+ <p>Given an input sequence x (of length N), k indices are chosen for replacing the tokens.</p>
+ </li>
+ <li>
+ <p>For each index, the generator produces a distribution over tokens. A token is sampled to replace in the original sequence. The resulting sequence is referred to as the corrupted sequence.</p>
+ </li>
+ <li>
+ <p>Given the corrupted sequence, the Discriminator predicts which token comes from the data distribution and which comes from the generator.</p>
+ </li>
+ <li>
+ <p>The generator is trained using the MLM setup, and the Discriminator is trained using the discriminative loss.</p>
+ </li>
+ <li>
+ <p>After pre-training, only the Discriminator is finetuned on the downstream tasks.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Datasets</p>
+
+ <ul>
+ <li>
+ <p>GLUE Benchmark</p>
+ </li>
+ <li>
+ <p>Stanford QA dataset</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Architecture Choices</p>
+
+ <ul>
+ <li>
+ <p>Sharing word embeddings between generator and Discriminator helps.</p>
+ </li>
+ <li>
+ <p>Tying all the encoder weights leads to marginal improvement but forces the generator and the Discriminator to be of the same size. Hence only embeddings are shared.</p>
+ </li>
+ <li>
+ <p>Generator model is kept smaller than the discriminator model as a strong generator can make the training difficult for the Discriminator.</p>
+ </li>
+ <li>
+ <p>A two-stage training procedure was explored where only the generator is trained for n steps. Then the weights of the generator are used to initialize the Discriminator. The Discriminator is then trained for n steps while keeping the generator fixed.</p>
+ </li>
+ <li>
+ <p>This two-stage setup provides a nice curriculum for the Discriminator but does not outperform the joint training based setup.</p>
+ </li>
+ <li>
+ <p>An adversarial loss based setup is also explored but it does not work well probably because of the following reasons:</p>
+
+ <ul>
+ <li>
+ <p>Adverserially trained generator is not as good as the MLM generator.</p>
+ </li>
+ <li>
+ <p>Adverserially trained generator produces a low entropy output distribution.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Results</p>
+
+ <ul>
+ <li>Both small and large ELECTRA models outperform baselines models like <a href="https://arxiv.org/abs/1810.04805">BERT</a>, <a href="https://arxiv.org/abs/1907.11692">RoBERTa</a>, <a href="https://arxiv.org/abs/1802.05365">ELMo</a> and <a href="https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf">GPT</a>.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Ablations</p>
+
+ <ul>
+ <li>
+ <p>ELECTRA-15 is a variant of ELECTRA where the Discriminator is trained on only 15% of the tokens (similar to the MLM setup). This reduces performance significantly.</p>
+ </li>
+ <li>
+ <p>Replace MLM setup</p>
+
+ <ul>
+ <li>
+ <p>Perform MLM training, but instead of using [MASK], use a toke sampled from the generator.</p>
+ </li>
+ <li>
+ <p>This improves the performance marginally.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>All-token MLM</p>
+
+ <ul>
+ <li>
+ <p>In the MLM setup, replace the [MASK] token by the sampled tokens and train the MLM model to generate all the words.</p>
+ </li>
+ <li>
+ <p>In practice, the MLM model can either generate a word or copy the existing word.</p>
+ </li>
+ <li>
+ <p>This approach closes much of the gap between BERT and ELECTRA.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Interestingly, ELECTRA outperforms All-token MLM BERT suggesting the ELECTRA may be benefitting from parameter efficiency since it does not have to learn a distribution over all the words.</p>
+ </li>
+</ul>
+
+
+
+
+ Gradient based sample selection for online continual learning
+
+ 2020-02-13T00:00:00-05:00
+ /site/2020/02/13/Gradient based sample selection for online continual learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Use of replay buffer (and rehearsal) is a common technique for mitigating catastrophic forgetting.</p>
+ </li>
+ <li>
+ <p>The paper builds on this idea but focuses on the sample selection aspect ie, which data points to store in the replay buffer.</p>
+ </li>
+ <li>
+ <p>It formulates sample selection as a constraint minimization problem and shows that the proposed formulation is equivalent to maximizing the diversity of the samples with respect to parameter gradient.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1903.08671">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Supervised learning tasks</p>
+ </li>
+ <li>
+ <p>Online stream of data (i.e., one or few datapoints accessed at a time).</p>
+ </li>
+ <li>
+ <p>When considering the $t^{th}$ task, the objective is: minimize the loss on the current task without increasing the loss on any of the previous tasks.</p>
+ </li>
+ <li>
+ <p>The above constraint can be rephrased as $dot(g_t, g_i) \gt 0 \forall i \in [0, t-1]$ where $g_t$ is the gradient for the $t^{th}$ task.</p>
+ </li>
+ <li>
+ <p>This is equivalent to saying that the current task gradient should not interfere negatively with the previous task gradient.</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>In practice, the gradient constraint is enforced only over the examples in the minibatch (and not the full dataset).</p>
+ </li>
+ <li>
+ <p>The paper interprets the constraint satisfaction problem as approximating an optimal feasible region (in the gradient space) where current task performance can be improved without hurting the performance on the previous tasks.</p>
+ </li>
+ <li>
+ <p>The approximate region (of the shape of a polyhedral convex cone) is determined using only the examples from the replay buffer. Hence, the optimal region (defined for the entire dataset) would be contained within the approximate region.</p>
+ </li>
+ <li>
+ <p>The size of the approximate region can be measured in terms of the solid angle defined by the intersection between the approximate region and a unit sphere.</p>
+ </li>
+ <li>
+ <p>The paper argues that the approximate region can be made smaller by reducing the angle between each pair of gradients.</p>
+ </li>
+ <li>
+ <p>The set of points, satisfying the constraint, can be computed using the Integer Quadratic Programming (IQP).</p>
+ </li>
+ <li>
+ <p>Given that the problem setup is online learning, using IDP for every new data point is not feasible.</p>
+ </li>
+ <li>
+ <p>An in-exact, greedy alternative is suggested where a score is maintained for each example in the buffer.</p>
+ </li>
+ <li>
+ <p>When a new datapoint comes in, the score is computed and used to decide if the existing datapoint in the buffer should be replaced.</p>
+ </li>
+ <li>
+ <p>The score is the maximal cosine similarity of the current example with a random sample in the buffer.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Benchmarks</p>
+
+ <ul>
+ <li>
+ <p>Disjoint MNIST</p>
+ </li>
+ <li>
+ <p>Permuted MNIST</p>
+ </li>
+ <li>
+ <p>Disjoint CIFAR10</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Shared head setup</p>
+ </li>
+ <li>
+ <p>Baselines for sample selection</p>
+
+ <ul>
+ <li>
+ <p>Randomly select examples to keep in the buffer.</p>
+ </li>
+ <li>
+ <p>Perform clustering - either in the feature space or in the gradient space.</p>
+ </li>
+ <li>
+ <p>Use IQP to select the examples. This approach is not used for CIFAR10, as it is computationally costly.</p>
+ </li>
+ <li>
+ <p>It would be interesting if the paper had considered baselines like selecting samples which had the largest loss.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The proposed greedy approach outperforms the other methods.</p>
+ </li>
+ <li>
+ <p>In an ablation experiment, the paper shows that the proposed approach works better than reservoir sampling (when the underlying data distribution is imbalanced).</p>
+ </li>
+ <li>
+ <p>Another experiment compares the proposed approach with <a href="https://papers.nips.cc/paper/7225-gradient-episodic-memory-for-continual-learning.pdf">Gradient Episodic Memory</a> and <a href="https://arxiv.org/abs/1611.07725">iCaRL</a>. For Permuted and Disjoint MNIST, the different methods perform quite similar though the proposed approach performs better on Disjoint CIFAR10.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One
+
+ 2020-02-06T00:00:00-05:00
+ /site/2020/02/06/Your Classifier is Secretly an Energy-Based Model, and You Should Treat it Like One
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposed a framework for joint modeling of labels and data by interpreting a discriminative classifier <em>p(y|x)</em> as an energy-based model <em>p(x, y)</em>.</p>
+ </li>
+ <li>
+ <p>Joint modeling provides benefits like improved calibration (i.e., the predictive confidence should align with the miss classification rate), robustness, and out of order distribution.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1912.03263">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="motivation">Motivation</h2>
+
+<ul>
+ <li>
+ <p>Consider a standard classifier $f_{\theta}(x)$ which produces a k-dimensional vector of logits.</p>
+ </li>
+ <li>
+ <p>$p_{\theta}(y | x) = softmax(f_{\theta}(x)[y])$</p>
+ </li>
+ <li>
+ <p>Uisng concepts from energy based models, we write $p_{\theta}(x, y) = \frac{exp(-E_{\theta}(x, y))}{Z_{\theta}}$ where $E_{\theta}(x, y) = -f_{\theta}(x)[y]$</p>
+ </li>
+ <li>
+ <p>$p_{\theta}(x) = \sum_{y}{ \frac{exp(-E_{\theta}(x, y))}{Z_{\theta}}}$</p>
+ </li>
+ <li>
+ <p>$E_{\theta}(x) = -LogSumExp_y(f_{\theta}(x)[y])$</p>
+ </li>
+ <li>
+ <p>Note that in the standard discriminative setup, shiting the logits $f_{\theta}(x)$ does not affect the model but it affects $p_{\theta}(x)$.</p>
+ </li>
+ <li>
+ <p>Computing $p_{\theta}(y | x)$ using $p_{\theta}(x, y)$ and $p_{\theta}(x)$ gives back the same softmax parameterization as before.</p>
+ </li>
+ <li>
+ <p>This reinterpreted classifier is referred to as a Joint Energy-based Model (JEM).</p>
+ </li>
+</ul>
+
+<h2 id="optimization">Optimization</h2>
+
+<ul>
+ <li>
+ <p>The log-liklihood of the data can be factoized as $log p_{\theta}(x, y) = log p_{\theta}(x) + log p_{\theta}(y | x)$.</p>
+ </li>
+ <li>
+ <p>The second factor can be trained using the standard CE loss. In contrast, the first factor can be trained using a sampler based on Stochastic Gradient Langevin Dynamics.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<h3 id="hybrid-modelling">Hybrid Modelling</h3>
+
+<ul>
+ <li>
+ <p>Datasets: CIFAR10, CIFAR100, SVHN.</p>
+ </li>
+ <li>
+ <p>Metrics: Inception Score, Frechet Inception Distance</p>
+ </li>
+ <li>
+ <p>JEM outperforms generative, discriminative, and hybrid models on both generative and discriminative tasks.</p>
+ </li>
+</ul>
+
+<h3 id="calibration">Calibration</h3>
+
+<ul>
+ <li>
+ <p>A calibrated classifier is the one where the predictive confidence aligns with the misclassification rate.</p>
+ </li>
+ <li>
+ <p>Dataset: CIFAR100</p>
+ </li>
+ <li>
+ <p>JEM improves calibration while retaining high accuracy.</p>
+ </li>
+</ul>
+
+<h3 id="out-of-distribution-ood-detection">Out of Distribution (OOD) Detection</h3>
+
+<ul>
+ <li>
+ <p>One way to detect OOD samples is to learn a density model that assigns a higher likelihood to in-distribution examples and lower likelihood to out of distribution examples.</p>
+ </li>
+ <li>
+ <p>JEM consistently assigns a higher likelihood to in-distribution examples.</p>
+ </li>
+ <li>
+ <p>The paper also proposes an alternate metric called <em>approximate mass</em> to detect OOD examples.</p>
+ </li>
+ <li>
+ <p>The intuition is that a point could have likelihood but be impossible to sample because its surroundings have a very low density.</p>
+ </li>
+ <li>
+ <p>On the other hand, the in-distribution data points would lie in a region of high probability mass.</p>
+ </li>
+ <li>
+ <p>Hence the norm of the gradient of log density could provide a useful signal to detect OOD examples.</p>
+ </li>
+</ul>
+
+<h3 id="robustness">Robustness</h3>
+
+<ul>
+ <li>JEM is more robust to adversarial attacks as compared to discriminative classifiers.</li>
+</ul>
+
+
+
+
+ Massively Multilingual Neural Machine Translation in the Wild - Findings and Challenges
+
+ 2020-01-30T00:00:00-05:00
+ /site/2020/01/30/Massively Multilingual Neural Machine Translation in the Wild-Findings and Challenges
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes to build a universal neural machine translation system that can translate between any pair of languages.</p>
+ </li>
+ <li>
+ <p>As a concrete instance, the paper prototypes a system that handles 103 languages (25 Billion translation pairs).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1907.05019">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="why-universal-machine-translation">Why universal Machine Translation</h2>
+
+<ul>
+ <li>
+ <p>Hypothesis: <em>The learning signal from one language should benefit the quality of other languages</em><a href="https://link.springer.com/article/10.1023/A:1007379606734">1</a></p>
+ </li>
+ <li>
+ <p>This positive transfer is evident for low resource languages but tends to hurt the performance for high resource languages.</p>
+ </li>
+ <li>
+ <p>In practice, adding new languages reduces the effective per-task capacity of the model.</p>
+ </li>
+</ul>
+
+<h2 id="desiderata-for-multilingual-translation-model">Desiderata for Multilingual Translation Model</h2>
+
+<ul>
+ <li>
+ <p>Maximize the number of languages within one model.</p>
+ </li>
+ <li>
+ <p>Maximize the positive transfer to low resource languages.</p>
+ </li>
+ <li>
+ <p>Minimize the negative interference to high resource languages.</p>
+ </li>
+ <li>
+ <p>Perform well ion the realistic, multi-domain settings.</p>
+ </li>
+</ul>
+
+<h2 id="datasets">Datasets</h2>
+
+<ul>
+ <li>
+ <p>In-house corpus generated by crawling and extracting parallel sentences from the web.</p>
+ </li>
+ <li>
+ <p>102 languages, with 25 billion sentence pairs.</p>
+ </li>
+ <li>
+ <p>Compared with the existing datasets, this dataset is much larger, spans more domains, has a good variation in the amount of data available for different language pairs, and is noisier. These factors bring additional challenges to the universal NMT setup.</p>
+ </li>
+</ul>
+
+<h2 id="baselines">Baselines</h2>
+
+<ul>
+ <li>
+ <p>Dedicated Bilingual models (variants of Transformers).</p>
+ </li>
+ <li>
+ <p>Most bilingual experiments used Transformer big and a shared source-target sentence-piece model (SPE).</p>
+ </li>
+ <li>
+ <p>For medium and low resource languages, the Transformer Base was also considered.</p>
+ </li>
+ <li>
+ <p>Batch size of 1 M tokes per-batch. Increasing the batch size improves model quality and speeds up convergence.</p>
+ </li>
+</ul>
+
+<h2 id="effect-of-transfer-and-interference">Effect of Transfer and Interference</h2>
+
+<ul>
+ <li>
+ <p>The paper compares the following two setups with the baseline:</p>
+
+ <ul>
+ <li>
+ <p>Combine all the datasets and train over them as if it is a single dataset.</p>
+ </li>
+ <li>
+ <p>Combine all the datasets but upsample low resource languages so all that all the languages are equally likely to appear in the combined dataset.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>A target “index” is prepended with every input sentence to indicate which language it should be translated into.</p>
+ </li>
+ <li>
+ <p>Shared encoder and decoder are used across all the language pairs.</p>
+ </li>
+ <li>
+ <p>The two setups use a batch size of 4M tokens.</p>
+ </li>
+</ul>
+
+<h3 id="results">Results</h3>
+
+<ul>
+ <li>
+ <p>When all the languages are equally sampled, the performance on the low resource languages increases, at the cost of performance on high resource languages.</p>
+ </li>
+ <li>
+ <p>Training over all the data at once reverse this trend.</p>
+ </li>
+</ul>
+
+<h3 id="countering-interference">Countering Interference</h3>
+
+<ul>
+ <li>
+ <p>Temperature based sampling strategy is used to control the ratio of samples from different language pairs.</p>
+ </li>
+ <li>
+ <p>A balanced sampling strategy improves the performance for the high resource languages (though not as good as the multilingual baselines) while retaining the high transfer performance on the low resource languages.</p>
+ </li>
+ <li>
+ <p>Another reason behind the lagging performance (as compared to bilingual baselines) is the capacity of the multilingual models.</p>
+ </li>
+ <li>
+ <p>Some open problems to consider:</p>
+
+ <ul>
+ <li>
+ <p>Task Scheduling - How to decide the order in which different language pairs should be trained.</p>
+ </li>
+ <li>
+ <p>Optimization for multitask learning - How to design optimizer, loss functions, etc. that can exploit task similarity.</p>
+ </li>
+ <li>
+ <p>Understanding Transfer:</p>
+
+ <ul>
+ <li>
+ <p>For the low resource languages, translating multiple languages to English leads to improved performance than translating English to multiple languages.</p>
+ </li>
+ <li>
+ <p>This can be explained as follows: In the first case (many-to-one), the setup is that of a multi-domain model (each source language is a domain). In the second case (one-to-many), the setup is that of multitasking.</p>
+ </li>
+ <li>
+ <p>NMT models seem to be more amenable to transfer across multiple domains than transfer across tasks (since the decoder distribution does not change much).</p>
+ </li>
+ <li>
+ <p>In terms of zero-shot performance, the performance for most language pairs increases as the number of languages change from 10 to 102.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="effect-of-preprocessing-and-vocabulary">Effect of preprocessing and vocabulary</h2>
+
+<ul>
+ <li>
+ <p>Sentence Piece Model (SPM) is used.</p>
+ </li>
+ <li>
+ <p>Temperature sampling is used to sample vocabulary from different languages.</p>
+ </li>
+ <li>
+ <p>Using smaller vocabulary (and hence smaller sub-word tokens) perform better for low resource languages, probably due to improved generalization.</p>
+ </li>
+ <li>
+ <p>Low and medium resource languages tend to perform better with higher temperatures.</p>
+ </li>
+</ul>
+
+<h2 id="effect-of-capacity">Effect of Capacity</h2>
+
+<ul>
+ <li>Using deeper models improves performance (as compared to the wider models with the same number of parameters) on most language pairs.</li>
+</ul>
+
+
+
+
+ Observational Overfitting in Reinforcement Learning
+
+ 2020-01-23T00:00:00-05:00
+ /site/2020/01/23/Observational Overfitting in Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper studies <em>observational overfitting</em>: The phenomenon where an agent overfits to different observation spaces even though the underlying MDP remains fixed.</p>
+ </li>
+ <li>
+ <p>Unlike other works, the “background information” (in the pixel space) is correlated with the progress of the agent (and is not just noise).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1912.02975">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Base MDP $M = (S, A, R, T)$ where $S$ is the state space, $A$ is the action space, $R$ is the reward function, and $T$ is the transition dynamics.</p>
+ </li>
+ <li>
+ <p>$M$ is parameterized using $\theta$. In practice, it means introducing an observation function $\phi_{\theta}$ ie $M_{\theta} = (M, \phi_{\theta})$.</p>
+ </li>
+ <li>
+ <p>A distribution over $\theta$ defines a distribution over the MDPs.</p>
+ </li>
+ <li>
+ <p>The learning agent has access to the pixel space observations and not the state space observations.</p>
+ </li>
+ <li>
+ <p>Generalization gap is defined as $J_{\theta}(\pi) - J_{\theta^{train}}(\pi)$ where $\pi$ is the learning agent, $\theta$ is the distribution over all the observation functions, $\theta^{train}$ is the distribution over the observation functions corresponding to the training environments. $J_{\theta}(\pi)$ is the average reward that the agent obtains over environments sampled from $M_{\theta}$.</p>
+ </li>
+ <li>
+ <p>$\phi_{\theta}$ considers two featurs - generalizable (invariant across $\theta$) and non-generalizable (depends on $\theta$) ie $\phi_{\theta}(s) = concat(f(s), g_{\theta}(s))$ where $f$ is the invariant function and $g$ is the non-generalizable function.</p>
+ </li>
+ <li>
+ <p>The problem is set up such that “explicit regularization” can easily solve it. The focus is on understanding the effect of “implicit regularization”.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="overparameterized-lqr">Overparameterized LQR</h3>
+
+<ul>
+ <li>
+ <p>LQR is used as a proxy for deep RL architectures given its advantages like enabling exact gradient descent.</p>
+ </li>
+ <li>
+ <p>The functions are parameterized as follows:</p>
+
+ <ul>
+ <li>
+ <p>$f(s) = W_c(s)$</p>
+ </li>
+ <li>
+ <p>$g_{\theta}(s) = W_{\theta}(s)$</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Observation at time $t$ , $o_t$, is given as $[W_c W_{\theta}]^{-1} s_t$.</p>
+ </li>
+ <li>
+ <p>Action at time $t$ is given as $a_t = K o_{t}$ where $K$ is the policy matrix.</p>
+ </li>
+ <li>
+ <p>Dimensionality:</p>
+
+ <ul>
+ <li>state $s$: $d_{state}$ 100</li>
+ <li>$f(s)$: $d_{state}$ 100</li>
+ <li>$g_{\theta}(s)$: $d_{noise}$ 100</li>
+ <li>observation $o$: $d_{state}$ + $d_{noise}$ 1100</li>
+ </ul>
+ </li>
+ <li>
+ <p>In case of training on just one environment, multiple solutions exist, and overfitting happens.</p>
+ </li>
+ <li>
+ <p>Increasing $d_{noise}$ increases the generalization gap.</p>
+ </li>
+ <li>
+ <p>Overparameterizing the network decreases the generalization gap and also reduces the norm of the policy.</p>
+ </li>
+</ul>
+
+<h3 id="projected-gym-environments">Projected Gym Environments</h3>
+
+<ul>
+ <li>
+ <p>The base MDP is the Gym Environment.</p>
+ </li>
+ <li>
+ <p>$M_{\theta}$ is generated as before.</p>
+ </li>
+ <li>
+ <p>Increasing both width and depth for basic MLPs improves generalization.</p>
+ </li>
+ <li>
+ <p>Generalization also depends on the choice of activation function, residual layers, etc.</p>
+ </li>
+</ul>
+
+<h3 id="deconvolutional-projections">Deconvolutional Projections</h3>
+
+<ul>
+ <li>
+ <p>In the Gym environment, the actual state is projected to a larger vector and reshaped into an 84x84 tensor (image).</p>
+ </li>
+ <li>
+ <p>The image from $f$ is concatenated with the image from $g$. This setup is referred to as the Gym-Deconv.</p>
+ </li>
+ <li>
+ <p>The relative order of performance between NatureCNN, IMPALA, and IMPALA-Large (on both CoinRun and Gym-Deconv) is the same as the order of the number of parameters they contain.</p>
+ </li>
+ <li>
+ <p>In an ablation, the policy is given access to only $g_{\theta}(s)$, which makes it impossible for the model to generalize. In this test of memorization capacity, implicit regularization seems to reduce the memorization effect.</p>
+ </li>
+</ul>
+
+<h3 id="overparameterization-in-coinrun">Overparameterization in CoinRun</h3>
+
+<ul>
+ <li>
+ <p>The pixel space observation in CoinRun is downsized from 64x64 to 32x32 and flattened into a vector.</p>
+ </li>
+ <li>
+ <p>In CoinRun, the dynamics change per level, and the noisy “irrelevant” features change location across the 1D input, making this setup more challenging than the previous ones.</p>
+ </li>
+ <li>
+ <p>Overparameterization improves generalization in this scenario as well.</p>
+ </li>
+</ul>
+
+
+
+
+ Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
+
+ 2020-01-16T00:00:00-05:00
+ /site/2020/01/16/Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper investigated two possible reasons behind the usefulness of MAML algorithm:</p>
+
+ <ul>
+ <li>
+ <p><strong>Rapid Learning</strong> - Does MAML learn features that are amenable for rapid learning?</p>
+ </li>
+ <li>
+ <p><strong>Feature Reuse</strong> - Does the MAML initialization provide high-quality features that are useful for the unseen tasks.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>This leads to a follow-up question: how much task-specific inner loop adaptation is needed.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1909.09157">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>In a standard few-shot learning setup, the different datasets have different classes. Hence, the top-most layer (or the head) of the learning model should be different for different tasks.</p>
+ </li>
+ <li>
+ <p>The subsequent discussion only applies to the body of the network (ie, network minus the head).</p>
+ </li>
+ <li>
+ <p><strong>Freezing Layer Representations</strong></p>
+
+ <ul>
+ <li>
+ <p>In this setup, a subset (or all) of parameters are frozen (after MAML training) and are not adapted during the representation.</p>
+ </li>
+ <li>
+ <p>Even when the entire network is frozen, the performance drops only marginally.</p>
+ </li>
+ <li>
+ <p>This indicates that the representation learned by the meta-initialization is good enough to be useful on the test tasks (without requiring any adaptation step).</p>
+ </li>
+ <li>
+ <p>Note that the head of the network is still adapted during testing.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Representational Similarity</strong></p>
+
+ <ul>
+ <li>
+ <p>In this setup, the paper reports the change in the latent representation (learned by the network) during the inner loop update with a fully trained model.</p>
+ </li>
+ <li>
+ <p>Canonical Correlation Analysis (CCA) and Central Kernel Alignment (CKA) metrics are used to measure the similarity between the representations.</p>
+ </li>
+ <li>
+ <p>The main finding is that the representations in the body of the network are very similar before and after the inner loop updates while the representations in the head of the network are very different.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The above two observations indicate that feature reuse is the primary driving factor for the success of MAML.</p>
+ </li>
+ <li>
+ <p><strong>When does feature reuse happen</strong></p>
+
+ <ul>
+ <li>
+ <p>The paper considers the model at different stages of training and compares the similarity in the representation (before and after the inner loop update).</p>
+ </li>
+ <li>
+ <p>Even early in training, the CCA similarity between the representations (before and after the inner loop update) is quite high. Similarly, freezing the layers (for the test time update), early in training, does not degrade the test time performance much. This hints that the feature reuse happens early in the learning process.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="the-anil-almost-no-inner-loop-algorithm">The ANIL (Almost No Inner Loop) Algorithm</h2>
+
+<ul>
+ <li>
+ <p>The empirical evidence suggests that the success of MAML lies in the feature reuse.</p>
+ </li>
+ <li>
+ <p>The authors build on this observation and propose a simplification of the MAML algorithm: ANIL or Almost No Inner Loop Algorithm</p>
+ </li>
+ <li>
+ <p>In this algorithm, the inner loop updates are applied only to the head of the network.</p>
+ </li>
+ <li>
+ <p>Despite being much more straightforward, the performance of ANIL is close to the performance of MAML for both few-shot image classification and RL tasks.</p>
+ </li>
+ <li>
+ <p>Removing most of the inner loop parameters speed up the computation by a factor of 1.7 (during training) and 4.1 (during inference).</p>
+ </li>
+</ul>
+
+<h2 id="removing-the-inner-loop-update">Removing the Inner Loop Update</h2>
+
+<ul>
+ <li>
+ <p>Given that it is possible to remove most of the parameters from the inner loop update (without affecting the performance), the next step is to check if the inner loop update can be removed entirely.</p>
+ </li>
+ <li>
+ <p>This leads to the NIL (No Inner Loop) algorithm, which does not involve any inner loop adaptation steps.</p>
+ </li>
+</ul>
+
+<h3 id="algorithm">Algorithm</h3>
+
+<ul>
+ <li>
+ <p>A few-shot learning model is trained - either with MAML or ANIL.</p>
+ </li>
+ <li>
+ <p>During testing, the head is removed.</p>
+ </li>
+ <li>
+ <p>For each task, the K training examples are fed to the body to obtain class representations.</p>
+ </li>
+ <li>
+ <p>For a given test data point, the representation of the data point is compared with the different class representations to obtain the target class.</p>
+ </li>
+ <li>
+ <p>The NIL algorithm performs similar to the MAML and the ANIL algorithms for the few-shot image classification task.</p>
+ </li>
+ <li>
+ <p>Note that it is still important to use MAML/ANIL during training, even though the learned head is not used during evaluation.</p>
+ </li>
+</ul>
+
+<h2 id="conclusion">Conclusion</h2>
+
+<ul>
+ <li>The paper discusses the different classes of meta-learning approaches. It concludes with the observation that feature reuse (and not rapid adaptation) seems to be the common model of operation for both optimization-based meta-learning (e.g., MAML) and model-based meta-learning.</li>
+</ul>
+
+
+
+
+ Accurate, Large Minibatch SGD - Training ImageNet in 1 Hour
+
+ 2020-01-09T00:00:00-05:00
+ /site/2020/01/09/Accurate Large Minibatch SGD - Training ImageNet in 1 Hour
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Training models with large minibatches (using distributed synchronous SGD) can lead to optimization issues.</p>
+ </li>
+ <li>
+ <p>The paper presents techniques for training models with large batch size while matching the accuracy of small minibatch setups.</p>
+ </li>
+ <li>
+ <p>The paper focuses on the ImageNet dataset, but many of the proposed ideas are applicable broadly.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1706.02677">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="linear-scaling-rule">Linear Scaling Rule</h2>
+
+<ul>
+ <li>
+ <p>When the minibatch size increases by a factor of <em>k</em>, the learning rate should also be increased by a factor of <em>k</em> (while keeping all other hyperparameters like weight decay fixed).</p>
+ </li>
+ <li>
+ <p>Note that this is an empirical rule and is not expected to hold under all conditions.</p>
+ </li>
+ <li>
+ <p>One such condition is when the model is changing rapidly during the first few epochs. In this case, a warmup phase is introduced to stabilize the model.</p>
+ </li>
+ <li>
+ <p>The paper verifies that the scaling rule is applicable to batch sizes as large as 8K.</p>
+ </li>
+</ul>
+
+<h2 id="warmup">Warmup</h2>
+
+<ul>
+ <li>The learning rate should be gradually ramped up from a small value to a large value to allow convergence.</li>
+</ul>
+
+<h2 id="batch-normalization">Batch Normalization</h2>
+
+<ul>
+ <li>
+ <p>Batch normalization uses batch statistics to normalize the data. Hence, the loss corresponding to each data point (in the batch) is not independent. Thus, changing the batch size could change the underlying function being optimized.</p>
+ </li>
+ <li>
+ <p>In the distributed SGD setup, the per-GPU (or per-worker) batch size should be kept constant, and only one worker should compute the batch norm statistics.</p>
+ </li>
+</ul>
+
+<h2 id="pitfalls-when-using-distributed-sgd">Pitfalls when using distributed SGD</h2>
+
+<ul>
+ <li>
+ <p>When using weight decay, scaling the cross-entropy loss is not the same as scaling the learning rate.</p>
+ </li>
+ <li>
+ <p>When using momentum, changing the learning rate could require “momentum correction.”</p>
+ </li>
+ <li>
+ <p>Ensure that the per-worker loss is normalized by the size of the total minibatch and not just by the size of minibatch that each worker sees.</p>
+ </li>
+ <li>
+ <p>For each epoch, uses a single random shuffling of the training data (before dividing between the workers).</p>
+ </li>
+</ul>
+
+<h2 id="communication">Communication</h2>
+
+<ul>
+ <li>
+ <p>The paper describes various techniques to speed up the training pipeline by reducing the communication overhead between nodes. (Each node can have one or more GPUs).</p>
+ </li>
+ <li>
+ <p>First, a node sums the gradient from all the GPUs it has.</p>
+ </li>
+ <li>
+ <p>The gradients are shared and summed across all the nodes.</p>
+ </li>
+ <li>
+ <p>Each node broadcasts the resulting gradient to all the GPUs it has.</p>
+ </li>
+ <li>
+ <p>Gradient Aggregation is performed in parallel with the backpropagation operator. While aggregating the gradient for one layer, the system starts computing the gradient of the next layer.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Using these approaches, a Resnet50 model can be trained on the ImageNet dataset in an hour (using 256 workers).</p>
+ </li>
+ <li>
+ <p>When an appropriate warmup strategy is used, the training and the validation curves (for the large batch size setup) matches the corresponding curves for the small batch size setup.</p>
+ </li>
+ <li>
+ <p>The best performing warmup strategy is the one where training starts at a learning rate of 0.1 and linearly increases to 3.2 over five epochs.</p>
+ </li>
+ <li>
+ <p>The paper shows that the results are not specific to the Resnet50 model (experiments with Resnet101 model) or the use case (experiments with object detection and instance segmentation using Mask R-CNN).</p>
+ </li>
+ <li>
+ <p>Along with providing the empirical validation of the proposed ideas, the paper describes all the hyperparameters. It also includes the training and validation curves with the different configurations which enable others to replicate and build on this work.</p>
+ </li>
+</ul>
+
+
+
+
+ Superposition of many models into one
+
+ 2020-01-02T00:00:00-05:00
+ /site/2020/01/02/Superposition of many models into one
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a technique (called Parameter Superposition or PSP) for training and storing multiple models within a single set (or instance) of parameters.</p>
+ </li>
+ <li>
+ <p>The different models exist in “superposition” and can be retrieved dynamically given task-specific context information.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1902.05522">Link to the paper</a>.</p>
+ </li>
+</ul>
+
+<h2 id="parameter-substitution">Parameter Substitution</h2>
+
+<ul>
+ <li>
+ <p>Consider a task with input \(x \in R^N\) and parameter \(W$ \in R^{M \times N}\) where the output (target or features) are given as \(y=Wx\).</p>
+ </li>
+ <li>
+ <p>Now consider \(K\) such tasks with parameters \(W_1, W_2, \cdots W_K\).</p>
+ </li>
+ <li>
+ <p>If each \(W_k\) requires only a small subspace in \(R^N\), then a linear transformation \(C_k^{-1}\) can be used such that each \(W_kC_k^{-1}\) occupies a mutually orthogonal subspace in \(R^N\).</p>
+ </li>
+ <li>
+ <p>The set of parameters \(W_1, \cdots W_K\) can be represented by a single \(W^{M \times N}\) by adding \(W_kC_k^{-1}\).</p>
+ </li>
+ <li>
+ <p>The parameter corresponding to the \(k^{th}\) task can be retrived (with some noise) using the context \(C_k\) as \(W^{~}_k = WC_k\)</p>
+ </li>
+ <li>
+ <p>Even though the retrieval is noisy, the effect of noise is limited for the context vectors used in the paper.</p>
+ </li>
+ <li>
+ <p>Finally, \(\widetilde(y) = \widetilde(W)_{k}x = (WC_{k})x = W(C_{k}x)\)</p>
+ </li>
+ <li>
+ <p>Instead of learning \(K\) separate models, only \(K\) context vectors (along with 1 superimposed model) needs to be learned.</p>
+ </li>
+ <li>
+ <p>The key assumption is that \(N\) (in \(x \in R^N)\) is large enough such that each \(W_k\) requires only a small subspace of \(R^N\).</p>
+ </li>
+ <li>
+ <p>Since images and speech signals tend to occupy a low dimensional manifold, this requirement can be satisfied by over-parameterizing x.</p>
+ </li>
+</ul>
+
+<h2 id="choice-of-context-c">Choice of Context C</h2>
+
+<ul>
+ <li>
+ <p>Rotational Superposition (pspRotation)</p>
+
+ <ul>
+ <li>
+ <p>Sample rotations uniformly from the orthogonal group \(O(M)\).</p>
+ </li>
+ <li>
+ <p>Downside is that if \(M \sim N\), it requires storing as many parameters as learning \(K\) individual models (since \(C\) is of the size of ##M \times M$$).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Complex Superposition (pspComplex)</p>
+
+ <ul>
+ <li>
+ <p>The design of rotational superposition can be improved by choosing \(C_k\) to be a diagonal matrix ie \(C_k = diag(c_k)\) where \(c_k\) is a vector of size \(M\).</p>
+ </li>
+ <li>
+ <p>Choosing \(c_k\) to be a vector of complex numbers (of the form \(c_{k}^{j} = e^{i\phi_{j}(k)}\) where \(\phi_{j}(k)\) or the phase is sampled uniformly from \([-\pi, \pi]\)) leads to \(C_k\) being a digonal orthogonal matrix.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Powers of a single context</p>
+
+ <ul>
+ <li>The memory footprint can be further reduced by choosing the context vectors to be integral powers of the first context vector.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Binary Superposition (pspBinary)</p>
+
+ <ul>
+ <li>This is a special case of complex superposition where the context vectors are binary.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="neural-network-superposition">Neural Network Superposition</h2>
+
+<ul>
+ <li>
+ <p>The parameter superposition principle can be applied to all the linear layers of a network.</p>
+ </li>
+ <li>
+ <p>For the convolutional layers, it makes more sense to apply superposition to the convolutional kernel and not to the input image (as the dimensionality of convolutional parameters is smaller than that of inputs).</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>For all the experiments, the baseline is a standard supervised learning setup, unless mentioned otherwise.</p>
+ </li>
+ <li>
+ <p>The metric is the performance on the previous tasks when the model has been trained on the newer tasks.</p>
+ </li>
+ <li>
+ <p>Input Interference</p>
+
+ <ul>
+ <li>
+ <p>The input distribution changes over time.</p>
+ </li>
+ <li>
+ <p>Permuted MNIST dataset is used where each permutation of the pixels corresponds to a new task.</p>
+ </li>
+ <li>
+ <p>A new task is sampled every 1000 mini-batches.</p>
+ </li>
+ <li>
+ <p>As the network size increases, the performance of Parameter Superposition (psp) outperforms the baseline significantly.</p>
+ </li>
+ <li>
+ <p>pspRotation > pspComplex > pspBinary in terms of both performance and the number of additional parameters required for each new task.</p>
+ </li>
+ <li>
+ <p>Given that pspBinary is the easiest to implement while being comparable to more sophisticated baselines like Elastic Weight Consolidation (EWC) and Synaptic Intelligence, the paper presents most of the results with the pspBinary model.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Continous Domain Shift</p>
+
+ <ul>
+ <li>
+ <p>Rotating-MNIST and Rotating-FashionMNIST tasks are proposed to simulate continuous domain shift.</p>
+ </li>
+ <li>
+ <p>In these tasks, the input images are rotated in-plane by a small angle such that the rotation is complete after 1000 steps.</p>
+ </li>
+ <li>
+ <p>A new context is assigned after 100 steps as per step changes in the angle would be very small.</p>
+ </li>
+ <li>
+ <p>The 10 context vectors used in the first 1000 steps are reused for the subsequent steps.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Randomly changing the context vector</p>
+
+ <ul>
+ <li>
+ <p>The paper considers an ablation where the context vector is randomly changed at every step (of the 1000 step cycle). This required the superposition model to store 1000 models.</p>
+ </li>
+ <li>
+ <p>This approach is better than the supervised learning baseline but not as good as the proposed psp* models.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Output Interference</p>
+
+ <ul>
+ <li>
+ <p>This is the setup where the model transitions from one classification task to another.</p>
+ </li>
+ <li>
+ <p>Incremental CIFAR dataset is used with Resnet18 as the base model.</p>
+ </li>
+ <li>
+ <p>Baseline is a standard supervised learning model where a new classification head is used for each task (since the classes have a different meaning in each dataset). The model component before the classification layer is shared across the tasks.</p>
+ </li>
+ <li>
+ <p>Even though the labels are different across the datasets, the pspBinary model, trained with a single output layer, outperforms the multi-headed baseline.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Towards a Unified Theory of State Abstraction for MDPs
+
+ 2019-12-26T00:00:00-05:00
+ /site/2019/12/26/Towards a Unified Theory of State Abstraction for MDPs
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper studies five different techniques for stat abstraction in MDPs (Markov Decision Processes) and evaluates their usefulness for planning and learning.</p>
+ </li>
+ <li>
+ <p>The general idea behind abstraction is to map the actual (or observed) state to an abstract state that should be more amenable for learning.</p>
+ </li>
+ <li>
+ <p>It can be thought of as a mapping from one representation to another representation while preserving some useful properties.</p>
+ </li>
+ <li>
+ <p><a href="https://pdfs.semanticscholar.org/ca9a/2d326b9de48c095a6cb5912e1990d2c5ab46.pdf">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="general-definition">General Definition</h2>
+
+<ul>
+ <li>
+ <p>Consider a MDP \(M = <S, A, P, R, \gamma>\) where \(S\) is the finite set of states, \(A\) is finite set of actions, \(P\) is the transition function, \(R\) is the bounded reward function and \(\gamma\) is the discount factor.</p>
+ </li>
+ <li>
+ <p>The abstract version of the MDP is \(\widetilde{M} = <\widetilde{S}, A, \widetilde{P}, \widetilde{R}, \gamma>\) where \(\widetilde{S}\) is the finite set if abstract states, \(\widetilde{P}\) is the transition function in the abstract state space and \(\widetilde{R}\) is the bounded reward function in the abstract reward space.</p>
+ </li>
+ <li>
+ <p>Abstraction function \(\phi\) is a function that maps a given state \(s\) to its abstract counterpart \(\widetilde{s}\).</p>
+ </li>
+ <li>
+ <p>The inverse image \(\phi^{-1}(\widetilde{s})\) is the set of ground states that map to the \(\widetilde{s}\) under the abstraction function \(\phi\).</p>
+ </li>
+ <li>
+ <p>A wieghing functioon \(w(s)\) is used to measure how much does a state \(s\) contribute to the abstract state \(\phi(s)\).</p>
+ </li>
+</ul>
+
+<h2 id="topology-of-abstraction-space">Topology of Abstraction Space</h2>
+
+<ul>
+ <li>
+ <p>Given two abstraction functions \(\phi_{1}\) and \(\phi_{2}\), \(\phi_{1}\) is said to be <em>finer</em> than \(\phi_{2}\) iff for any states \(s_{1}, s_{2}\) if \(\phi_{1}(s_{1}) = \phi_{1}(s_{2})\) then \(\phi_{2}(s_{1}) = \phi_{2}(s_{2})\).</p>
+ </li>
+ <li>
+ <p>This <em>finer</em> relation is reflex, antisymmetric, transitive and partially ordered.</p>
+ </li>
+</ul>
+
+<h2 id="five-types-of-abstraction">Five Types of Abstraction</h2>
+
+<ul>
+ <li>
+ <p>While many abstractions are possible, not all abstractions are equally important.</p>
+ </li>
+ <li>
+ <p>Model-irrelevance abstraction \(\phi_{model}\):</p>
+
+ <ul>
+ <li>
+ <p>If two states $s_{1}$ and $s_{2}$ have the same abstracted state, then their one-step model is preserved.</p>
+ </li>
+ <li>
+ <p>Consider any action \(a\) and any abstract state \(\widetilde{s}\), if \(\phi_{model}(s_{1} = \phi_{model}(s_{2})\) then \(R(s_1, a) = R(s_2, a)\) and \(\sum_{s' \in \phi_{model}^{-1}\widetilde(s)}P_{s_1, s'}^{a} = \sum_{s' \in \phi_{model}^{-1}\widetilde(s)}P_{s_2, s'}^{a}\).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>\(Q^{\pi}\)-irrelevance abstraction:</p>
+
+ <ul>
+ <li>
+ <p>It preserves the state-action value finction for all the states.</p>
+ </li>
+ <li>
+ <p>\(\phi_{Q^{\pi}}(s_1) = \phi_{Q^{\pi}}(s_2)\) implies \(Q^{\pi}(s_1, a) = Q^{\pi}(s_1, a)\).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>\(Q^{*}\)-irrelevance abstraction:</p>
+
+ <ul>
+ <li>It preserves the optimal state-action value function.</li>
+ </ul>
+ </li>
+ <li>
+ <p>\(a^{*}\)-irrelevance abstraction:</p>
+
+ <ul>
+ <li>It preserves the optimal action and its value function.</li>
+ </ul>
+ </li>
+ <li>
+ <p>\(\phi_{\pi^{*}}\)-irrelevance abstraction:</p>
+
+ <ul>
+ <li>It preserves the optimal action.</li>
+ </ul>
+ </li>
+ <li>
+ <p>In terms of <em>fineness</em>, \(\phi_0 \geq \phi_{model} \geq \phi_{Q^{\pi}} \geq \phi_{Q^*} \geq \phi_{a^*} \geq \phi_{\pi^*}\). Here \(\phi_0\) is the identity mapping ie \(\phi_0(s) = s\)</p>
+ </li>
+ <li>
+ <p>If a property applies to any abstraction, it also applies to all the finer abstractions.</p>
+ </li>
+</ul>
+
+<h2 id="key-theorems">Key Theorems</h2>
+
+<ul>
+ <li>
+ <p>As we go from finer to coarser abstractions, the information loss increases (ie fewer components can be recovered) while the state-space reduces (ie the efficiency of solving the problem increases). This leads to a tradeoff when selecting abstractions.</p>
+ </li>
+ <li>
+ <p>For example, with abstractions \(\phi_{model}, \phi_{Q^{\pi}}, \phi_{Q^*}, \phi_{a^*}\), the optimal abstract policy \(\widetilde(\pi)^*\) is optimal in the ground MDP.</p>
+ </li>
+ <li>
+ <p>Similarly, if each state-action pair is visited infinitely often and the step-size decays properly, Q-learning with \(\phi_{model}, \phi_{Q^{\pi}}, \phi_{Q^*}\) converges to the optimal state-action value functions in the MDP. More conditions are needed for convergence in the case of the remaining two abstractions.</p>
+ </li>
+ <li>
+ <p>For \(\phi_{model}, \phi_{Q^{\pi}}, \phi_{Q^*}, \phi_{a^*}\), the model built with the experience converges to the true abstract model with infinite experience if the weighing function \(w(s)\) is fixed.</p>
+ </li>
+</ul>
+
+
+
+
+
+ ALBERT - A Lite BERT for Self-supervised Learning of Language Representations
+
+ 2019-12-19T00:00:00-05:00
+ /site/2019/12/19/ALBERT - A Lite BERT for Self-supervised Learning of Language Representations
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes parameter-reduction techniques to lower the memory consumption (and improve training speed) of BERT.</p>
+ </li>
+ <li>
+ <p>It also proposes to use a self-supervised loss (based on inter-sentence coherence) and argues that this loss is better than the NSP loss used by BERT.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1909.11942">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>ALBERT architecture is similar to that of BERT with three major differences.</p>
+ </li>
+ <li>
+ <p>Factorized Embedding Parameterization</p>
+
+ <ul>
+ <li>
+ <p>In BERT and followup works, the embedding size was tied to the size of the context vector.</p>
+ </li>
+ <li>
+ <p>Since context vector is expected to encoder the entire context, it needs to have a large dimensionality.</p>
+ </li>
+ <li>
+ <p>One consequence of this choice is that even the embedding layer (which encodes the representation for each token) has a large size. This increases the overall memory footprint of the model.</p>
+ </li>
+ <li>
+ <p>The paper proposed to factorize the embedding parameters into two smaller matrics.</p>
+ </li>
+ <li>
+ <p>The embedding layer learns a low dimensional representation of the tokens and this representation is projected into a high dimensional space.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Cross-layer parameter sharing</p>
+
+ <ul>
+ <li>ALBERT shares all the parameters across the layers.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Inter-sentence coherence loss</p>
+
+ <ul>
+ <li>
+ <p>BERT uses two losses - Masked Language Modeling loss (MLM) and Next Sentence Prediction (NSP).</p>
+ </li>
+ <li>
+ <p>In the NSP task, the model is provided a pair of sentences and it has to predict if the two sentences appear consecutively in the same document or not. Negative samples are created by sampling sentences from different documents.</p>
+ </li>
+ <li>
+ <p>The paper argues that NSP is not effective as a loss function as it merges topic prediction and coherence prediction into one task (as the two sentences come from different documents). The topic prediction is an easier task as compared to coherence prediction.</p>
+ </li>
+ <li>
+ <p>Hence the paper proposes to use the Sentence Order Prediction task where the model has to predict which of the two sentences comes first in a document. The negative samples are created by simply swapping the order in the positive samples. Hence both the sentences come from the same document and topic prediction alone can not be used to solve the task.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Different variants (in terms of size) of ALBERT and BERT models are compared (eg ALBERT, ALBERT-x, BERT-x, etc).</p>
+ </li>
+ <li>
+ <p>In general, ALBERT models have many-times fewer parameters as compared to the BERT models.</p>
+ </li>
+ <li>
+ <p>Datasets - BookCorpus, English Wikipedia.</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>ALBERT-xxlarge significantly outperforms the BERT-large model even though it has around 70% parameters as the BERT-large model.</p>
+ </li>
+ <li>
+ <p>BERT-xlarge performs worse than BERT-base hinting that it is difficult to train such large models.</p>
+ </li>
+ <li>
+ <p>ALBERT models also have better data throughput as compared to BERT models.</p>
+ </li>
+ <li>
+ <p>For the ALBERT models, an embedding size of 128 performs the best.</p>
+ </li>
+ <li>
+ <p>As the hidden dimension is increased, the model obtains better performance, but with diminishing returns.</p>
+ </li>
+ <li>
+ <p>Very wide ALBERT models (say with a context size of 1024) do not benefit much from depth.</p>
+ </li>
+ <li>
+ <p>Using additional training data boosts the performance for most of the downstream tasks.</p>
+ </li>
+ <li>
+ <p>The paper empirically shows that using dropout could hurt the performance of the ALBERT models. This observation may not hold for BERT as it does not share parameters across layers and hence may need regularization via dropout.</p>
+ </li>
+ <li>
+ <p>ALBERT also improves the state of the art performance on GLUE, SQuAD and RACE benchmarks, for both single-model and ensemble setup.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Everything Happens for a Reason - Discovering the Purpose of Actions in Procedural Text
+
+ 2019-12-12T00:00:00-05:00
+ /site/2019/12/12/Everything Happens for a Reason - Discovering the Purpose of Actions in Procedural Text
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Procedural text comprehension tasks focus on modeling the effect of actions and predicting what happens next.</p>
+ </li>
+ <li>
+ <p>But they do not consider <em>why</em> some actions need to happen before other actions.</p>
+ </li>
+ <li>
+ <p>The paper proposes a new model called XPAD (eXPlainable Action Dependency) that considers the <em>purpose</em> of actions while predicting their effect.</p>
+ </li>
+ <li>
+ <p>The model favors <em>effects</em> that:</p>
+
+ <ul>
+ <li>
+ <p>explain more of actions in the text.</p>
+ </li>
+ <li>
+ <p>are more plausible given the context.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>An existing procedural text benchmark dataset (Propara) is expanded by adding the task of explaining actions by predicting their dependencies.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1909.04745">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="http://data.allenai.org/propara/">Link to the dataset</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Input</p>
+
+ <ul>
+ <li>
+ <p>Procedural (chronologically ordered text) sequence of <em>T</em> sentences.</p>
+ </li>
+ <li>
+ <p>List of <em>N</em> participant entities, whose state changes at some step.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Output</p>
+
+ <ul>
+ <li>
+ <p>State change matrix $\pi(T \times N)$ with four possible states - move, create destroy, none.</p>
+ </li>
+ <li>
+ <p>This matrix tracks how property changes after each step.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Dependency Explanation Graph</p>
+
+ <ul>
+ <li>
+ <p>Identify what steps are necessary to execute a given step (say <em>s<sub>i</sub></em>) and represent this dependency in the form of a dependency explanation graph <em>G = <S, E></em>.</p>
+ </li>
+ <li>
+ <p>In this graph, each node is a step and the direction of edge describes the order of dependency.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="dependency-graph-dataset">Dependency Graph Dataset</h2>
+
+<ul>
+ <li>
+ <p><a href="https://arxiv.org/abs/1805.06975">Propara dataset</a> is expanded to extract the dependency graph using both heuristic and automated methods.</p>
+ </li>
+ <li>
+ <p>The automated method is based on the coherence assumption that if step <em>s<sub>j</sub></em> changes state of entity <em>e<sub>k</sub></em> then <em>s<sub>j</sub></em> is a precondition for the first subsequent step that changes the state of <em>e<sub>k</sub></em>.</p>
+ </li>
+</ul>
+
+<h2 id="xpad-model">XPAD Model</h2>
+
+<ul>
+ <li>
+ <p>The model is based on the ProStruct system and uses an encoder-decoder based architecture.</p>
+ </li>
+ <li>
+ <p>Encoder</p>
+
+ <ul>
+ <li>
+ <p>Input: Sentence <em>s<sub>t</sub></em> and entity <em>e<sub>j</sub></em>.</p>
+ </li>
+ <li>
+ <p>Sentence is encoded using the GloVe vectors and a BiLSTM model and the entity is encoded as an indicator variable.</p>
+ </li>
+ <li>
+ <p>The combined representation is denoted as <em>c<sub>tj</sub></em>.</p>
+ </li>
+ <li>
+ <p>This representation is passed through an MLP to generate <em>k</em> logits that encode the probability of each entity <em>j</em> undergoing a state change at step <em>t</em>.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Decoder</p>
+
+ <ul>
+ <li>
+ <p>Beam search is performed to decode the encoder representation into the state change matrix and dependency graph using a score function that ensures global consistency.</p>
+ </li>
+ <li>
+ <p>Score function has two components:</p>
+
+ <ul>
+ <li>
+ <p>State change score - depends on the likelihood that the selected state changes at step <em>t</em> given the text and state change history from steps <em>s<sub>1</sub></em> to <em>s<sub>t-1</sub></em>.</p>
+ </li>
+ <li>
+ <p>Dependency graph score</p>
+
+ <ul>
+ <li>
+ <p>This is based on the connectivity and likelihood of the resulting dependency explanation graph.</p>
+ </li>
+ <li>
+ <p>This score is used to bias the graph search towards:</p>
+
+ <ul>
+ <li>
+ <p>predictions that have an identifiable purpose ie checking if a particular state change prediction leads to a connection in the dependency explanation graph.</p>
+ </li>
+ <li>
+ <p>graphs that are more likely according to the background knowledge to distinguish likely dependency links from the unlikely ones.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>During training, XPAD has access to the correct path (in the search space) and learns to minimize the joint loss corresponding to predicting the state change and the dependency explanation graph.</p>
+ </li>
+ <li>
+ <p>During testing, XPAD performs beam search to predict the most likely state change and dependency explanation graph.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Tasks:</p>
+
+ <ul>
+ <li>
+ <p>State change prediction</p>
+ </li>
+ <li>
+ <p>Dependency explanation prediction</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Baselines:</p>
+
+ <ul>
+ <li>
+ <p><a href="https://arxiv.org/abs/1612.03969">Recurrent Entity Networks</a></p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1606.04582">Query-Reduction Networks</a></p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1805.06975">ProLocal and ProGlobal</a></p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1808.10012">ProStruct</a></p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>XPAD significantly outperforms all the baseline models on the dependency explanation task.</p>
+ </li>
+ <li>
+ <p>Improvements on the state change prediction task are less significant.</p>
+ </li>
+ <li>
+ <p>Removing dependency graph scores from XPAD leads to a drop in the F1 score.</p>
+ </li>
+ <li>
+ <p>The paper provides an elaborate discussion on the different types of errors that the XPAD system makes.</p>
+ </li>
+</ul>
+
+
+
+
+ Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
+
+ 2019-12-05T00:00:00-05:00
+ /site/2019/12/05/Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents the MuZero algorithm that performs planning with a learned model.</p>
+ </li>
+ <li>
+ <p>The algorithm achieves state of the art results on Atari suite (where generally model-free approaches perform the best) and on planning-oriented games like Chess and Go (where generall planning approaches perform the best).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1911.08265">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="relation-to-standard-model-based-approaches">Relation to standard Model-Based Approaches</h2>
+
+<ul>
+ <li>
+ <p>Model-based approaches generally focus on reconstructing the true environment state or the sequence of full observations.</p>
+ </li>
+ <li>
+ <p>MuZero focuses on predicting only those aspects that are most relevant for planning - policy, value functions, and rewards.</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>The model consists of three components: (representation) encoder, dynamics function, and the prediction network.</p>
+ </li>
+ <li>
+ <p>The learning agent has two kinds of interactions - real interactions (ie the actions that are actually executed in the real environment) and hypothetical or imaginary actions (ie the actions that are executed in the learned model or the dynamics function).</p>
+ </li>
+ <li>
+ <p>At any timestep <em>t</em>, the past observations <em>o<sub>1</sub></em>, … <em>o<sub>t</sub></em> are encoded into the state <em>s<sub>t</sub></em> using the encoder.</p>
+ </li>
+ <li>
+ <p>Now the model takes hypothetical actions for the next <em>K</em> timesteps by unrolling the model for <em>K</em> steps.</p>
+ </li>
+ <li>
+ <p>For each timestep <em>k = 1, …, K</em>, the dynamics model predicts the immediate reward <em>r<sub>k</sub></em> and a new hidden state <em>h<sub>k</sub></em> using the previous hidden state <em>h<sub>k-1</sub></em> and action <em>a<sub>k</sub></em>.</p>
+ </li>
+ <li>
+ <p>At the same time, the policy <em>p<sup>k</sup></em> and the value function <em>v<sup>k</sup></em> are computed using the prediction network.</p>
+ </li>
+ <li>
+ <p>The initial hidden state <em>h<sub>0</sub></em> is initialized using the state <em>s<sub>t</sub></em></p>
+ </li>
+ <li>
+ <p>Any MDP Planning algorithm can be used to search for optimal policy and value function given the state transitions and the rewards induced by the dynamics function.</p>
+ </li>
+ <li>
+ <p>Specifically, the MCTS (Monte Carlo Tree Search) algorithm is used and the action <em>a<sub>t+1</sub></em> (ie the action that is executed in the actual environment) is selected from the policy outputted by MCTS.</p>
+ </li>
+</ul>
+
+<h2 id="collecting-data-for-the-replay-buffer">Collecting Data for the Replay Buffer</h2>
+
+<ul>
+ <li>
+ <p>At each timestep <em>t</em>, the MCTS algorithm is executed to choose the next action (which will be executed in the real environment).</p>
+ </li>
+ <li>
+ <p>The resulting next observation <em>o<sub>t+1</sub></em> and reward <em>r<sub>t+1</sub></em> are stored and the trajectory is written to the replay buffer (at the end of the episode).</p>
+ </li>
+</ul>
+
+<h2 id="objective">Objective</h2>
+
+<ul>
+ <li>
+ <p>For every hypothetical step <em>k</em>, match the predicted policy, value, and reward to the actual target values.</p>
+ </li>
+ <li>
+ <p>The target policy is generated by the MCTS algorithm.</p>
+ </li>
+ <li>
+ <p>The target value function and reward are generated by actually playing the game (or the MDP).</p>
+ </li>
+</ul>
+
+<h2 id="relation-to-alphazero">Relation to AlphaZero</h2>
+
+<ul>
+ <li>
+ <p>MuZero leverages the search-based policy iteration from AlphaZero.</p>
+ </li>
+ <li>
+ <p>It extends AlphaZero to setups with a single agent (where self-play is not possible) and setups with a non-zero reward at the intermediate time steps.</p>
+ </li>
+ <li>
+ <p>The encoder and the predictions functions are similar to ones used by AlphZero.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p><em>K</em> is set to 5.</p>
+ </li>
+ <li>
+ <p>Environments: 57 games in Atari along with Chess, Go and Shogi</p>
+ </li>
+ <li>
+ <p>MuZero achieves the same level of performance as AlphaZero for Chess and Shogi. In Go, MuZero slightly outperforms AlphaZero despite doing fewer computations per node in the search tree.</p>
+ </li>
+ <li>
+ <p>In Atari, MuZero achieves a new state-of-the-art compared to both model-based and model-free approaches.</p>
+ </li>
+ <li>
+ <p>The paper considers a variant called MuZero Reanalyze that reanalyzes old trajectories by re-running the MCTS algorithm with the updated network parameter. The motivation is to have a better sample complexity.</p>
+ </li>
+ <li>
+ <p>MuZero performs well even when using a single simulation of MCTS (during inference).</p>
+ </li>
+ <li>
+ <p>During training, using more simulations of MCTS helps to achieve better performance through even just 6 simulations per move is sufficient to learn a good model for Ms. Pacman.</p>
+ </li>
+</ul>
+
+
+
+
+ Contrastive Learning of Structured World Models
+
+ 2019-11-28T00:00:00-05:00
+ /site/2019/11/28/Contrastive Learning of Structured World Models
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces Contrastively-trained Structured World Models (C-SWMs).</p>
+ </li>
+ <li>
+ <p>These models use a contrastive approach for learning representations in environments with compositional structure.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1911.12247">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/tkipf/c-swm">Link to the code</a>.</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>The training data is in the form of an experience buffer \(B = \{(s_t, a_t, s_{t+1})\}_{t=1}^T\) of state transition tuples.</p>
+ </li>
+ <li>
+ <p>The goal is to learn:</p>
+
+ <ul>
+ <li>
+ <p>an encoder \(E\) that maps the observed states $s_t$ (pixel state observations) to latent state $z_t$.</p>
+ </li>
+ <li>
+ <p>a transition model \(T\) that predicts the dynamics in the hidden state.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The model defines the enegry of a tuple \((s_t, a_t, s_{t+1})\) as \(H = d(z_t + T(z_t, a_t), z_{t+1})\).</p>
+ </li>
+ <li>
+ <p>The model has an inductive bias for modeling the effect of action as translation in the abstract state space.</p>
+ </li>
+ <li>
+ <p>An extra hinge-loss term is added: \(max(0, \gamma - d(z^{~}_{t}, z_{t+1}))\) where \(z^{~}_{t} = E(s^{~}_{t})\) is a corrputed latent state corresponding to a randomly sampled state \(s^{~}_{t}\).</p>
+ </li>
+</ul>
+
+<h2 id="object-oriented-state-factorization">Object-Oriented State Factorization</h2>
+
+<ul>
+ <li>
+ <p>The goal is to learn object-oriented representations where each state embedding is structured as a set of objects.</p>
+ </li>
+ <li>
+ <p>Assuming the number of object slots to be \(K\), the latent space, and the action space can be factored into \(K\) independent latent spaces (\(Z_1 \times ... \times Z_K\)) and action spaces (\(A_1 \times ... \times A_k\)) respectively.</p>
+ </li>
+ <li>
+ <p>There are <em>K</em> CNN-based object extractors and an MLP-based object encoder.</p>
+ </li>
+ <li>
+ <p>The actions are represented as one-hot vectors.</p>
+ </li>
+ <li>
+ <p>A fully connected graph is induced over <em>K</em> objects (representations) and the transition function is modeled as a Graph Neural Network (GNN) over this graph.</p>
+ </li>
+ <li>
+ <p>The transition function produces the change in the latent state representation of each object.</p>
+ </li>
+ <li>
+ <p>The factorization can be taken into account in the loss function by summing over the loss corresponding to each object.</p>
+ </li>
+</ul>
+
+<h2 id="environments">Environments</h2>
+
+<ul>
+ <li>
+ <p>Grid World Environments - 2D shapes, 3D blocks</p>
+ </li>
+ <li>
+ <p>Atari games - Pong and Space Invaders</p>
+ </li>
+ <li>
+ <p>3-body physics simulation</p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Random policy is used to collect the training data.</p>
+ </li>
+ <li>
+ <p>Evaluation is performed in the latent space (no reconstruction in the pixel space) using ranking metrics. The observations (to compare against) are randomly sampled from the buffer.</p>
+ </li>
+ <li>
+ <p>Baselines - auto-encoder based World Models and <a href="https://arxiv.org/abs/1905.11169">Physics as Inverse Graphics model</a>.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>In the grid-world environments, C-SWM models the latent dynamics almost perfectly.</p>
+ </li>
+ <li>
+ <p>Removing either the state factorization or the GNN transition model hurts the performance.</p>
+ </li>
+ <li>
+ <p>C-SWM performs well on Atari as well but the results tend to have high variance.</p>
+ </li>
+ <li>
+ <p>The optimal values of $K$ should be obtained by hyperparameter tuning.</p>
+ </li>
+ <li>
+ <p>For the 3-body physics tasks, both the baselines and proposed models work quite well.</p>
+ </li>
+ <li>
+ <p>Interestingly, the paper has a section on limitations:</p>
+
+ <ul>
+ <li>
+ <p>The object extractor module can not disambiguate between multiple instances of the same object (in a scene).</p>
+ </li>
+ <li>
+ <p>The current formulation of C-SWM can only be used with deterministic environments.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Gossip based Actor-Learner Architectures for Deep RL
+
+ 2019-09-12T00:00:00-04:00
+ /site/2019/09/12/Gossip based Actor-Learner Architectures for Deep RL
+ <ul>
+ <li>
+ <p><a href="https://arxiv.org/abs/1906.04585">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>The paper considers the task of training an RL system by sampling data from multiple simulators (over parallel devices).</p>
+ </li>
+ <li>
+ <p>The setup is that of distributed RL setting with <em>n</em> agents or actor-learners (composed of a single learner and several actors). These agents are trying to maximize a common value function.</p>
+ </li>
+ <li>
+ <p>One (existing) approach is to perform on-policy updates with a shared policy. The policy could be updated in synchronous (does not scale well) or asynchronous manner (can be unstable due to stale gradients).</p>
+ </li>
+ <li>
+ <p>Off policy approaches allow for better computational efficiency but can be unstable during training.</p>
+ </li>
+ <li>
+ <p>The paper proposed Gossip based Actor-Learner Architecture (GALA) which uses asynchronous communication (gossip) between the <em>n</em> agents to improve the training of Deep RL models.</p>
+ </li>
+ <li>
+ <p>These agents are expected to converge to the same policy.</p>
+ </li>
+ <li>
+ <p>During training, the different agents are not required to share the same policy and it is sufficient that the agent’s policies remain $\epsilon$-close to each other. This relaxation allows the policies to be trained asynchronously.</p>
+ </li>
+ <li>
+ <p>GALA approach is combined with A2C agents resulting in GALA-A2C agents. They have better computational efficiency and scalability (as compared to A2C) and similar in performance to A3C and Impala.</p>
+ </li>
+ <li>
+ <p>Training alternates between one local policy-gradient (and TD update) and asynchronous gossip between agents.</p>
+ </li>
+ <li>
+ <p>During the gossip step, the agents send their parameters to some of the other agents (referred to as the peers) and update their parameters based on the parameters received from the other agents (for which the given agent is a peer).</p>
+ </li>
+ <li>
+ <p>GALA agents are implemented using non-blocking communication so that they can operate asynchronously.</p>
+ </li>
+ <li>
+ <p>The paper includes the proof that the policies learned by the different agents are within $\epsilon$ distance of each other (ie all the policies lie within an $\epsilon$-distance ball) thus ensuring that the policies do not diverge much from each other.</p>
+ </li>
+ <li>
+ <p>Six games from the Ataru 2600 games suite are used for the experiments.</p>
+ </li>
+ <li>
+ <p>Baselines: A2C, A3C, Impala</p>
+ </li>
+ <li>
+ <p>GALA agents are configured in a directed ring graph topology.</p>
+ </li>
+ <li>
+ <p>With A2C, as the number of simulators increases, the number of convergent runs (runs with a threshold reward) decreases.</p>
+ </li>
+ <li>
+ <p>Using gossip algorithms increases or maintains the number of convergent runs. It also improves the performance, sample efficiency and compute efficiency of A2C across all the six games.</p>
+ </li>
+ <li>
+ <p>When compared to Impala and A3C, GALA-A2C generally outperforms (or performs as well as) those baselines.</p>
+ </li>
+ <li>
+ <p>Given that the learned policies remain within an $\epsilon$ ball, the agent’s gradients are less correlated as compared to the A2C agents.</p>
+ </li>
+</ul>
+
+
+
+
+ How to train your MAML
+
+ 2019-09-05T00:00:00-04:00
+ /site/2019/09/05/How to train your MAML
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes MAML++ - a modification of MAML algorithm that stabilizes its training improves generalization performance and reduces the computational overhead.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1810.09502">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<h3 id="unstable-training">Unstable Training</h3>
+
+<ul>
+ <li>
+ <p>Training the outer loop requires unfolding the inner loop multiple times.</p>
+ </li>
+ <li>
+ <p>In absence of skip connections, the gradient is multiplied by the same parameter multiple times.</p>
+ </li>
+ <li>
+ <p>Large depth and absent skip connections could lead to exploding and vanishing gradients respectively.</p>
+ </li>
+ <li>
+ <p>The paper proposes to stabilize the gradient propagation by minimizing the target set loss computed by the base-network after every step towards a support set task.</p>
+ </li>
+ <li>
+ <p>It is important to anneal the contribution of earlier steps and increase the contribution of later steps over time.</p>
+ </li>
+</ul>
+
+<h3 id="second-order-derivatives-are-expensive-to-compute">Second Order derivatives are expensive to compute</h3>
+
+<ul>
+ <li>
+ <p>While the first-order MAML is faster, the resulting model may not have as good a generalization error as the second-order MAML.</p>
+ </li>
+ <li>
+ <p>The paper proposes to use derivative order annealing where the first order gradients are used for the first 50 epochs and the network uses second-order gradients from thereon.</p>
+ </li>
+ <li>
+ <p>This derivative order annealing appears to be more stable than models that use second-order derivatives only.</p>
+ </li>
+</ul>
+
+<h3 id="batch-normalization">Batch Normalization</h3>
+
+<ul>
+ <li>
+ <p>In MAML, the statistics of the current batch are used for normalization instead of accumulating the running statistics.</p>
+ </li>
+ <li>
+ <p>The paper proposes to collect the statistics per step which can increase the convergence speed, stability, and generalization performance.</p>
+ </li>
+ <li>
+ <p>In MAML, the batch normalization biases are not updated in the inner-loop which can adversely impact the performance.</p>
+ </li>
+ <li>
+ <p>The paper proposes to learn a set of biases (per step) within the inner loop update.</p>
+ </li>
+</ul>
+
+<h3 id="fixed-learning-rate">Fixed Learning Rate</h3>
+
+<ul>
+ <li>
+ <p>MAML uses a single learning rate across all the steps and all the parameters. This means there is one single learning rate that needs to be hyperparameter to work well for all the layers and steps.</p>
+ </li>
+ <li>
+ <p>An alternate solution would be to learn a separate learning rate per parameter but this can be impractical as it doubles the number of parameters to be learned.</p>
+ </li>
+ <li>
+ <p>The paper proposes to learn a learning rate and direction for each layer in the network, for each step it takes in the inner loop.</p>
+ </li>
+ <li>
+ <p>The paper also proposed to anneal the learning rate of the outer loop (using cosine annealing) as it helps to achieve better generalization.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Using these modifications helps to outperform the MAML model on both Omniglot and MiniImagenet datasets.</p>
+ </li>
+ <li>
+ <p>The biggest benefit comes by learning the per-layer, per-step learning rates and by using the per-step batch normalization.</p>
+ </li>
+</ul>
+
+
+
+
+ PHYRE - A New Benchmark for Physical Reasoning
+
+ 2019-08-29T00:00:00-04:00
+ /site/2019/08/29/PHYRE - A New Benchmark for Physical Reasoning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes the PHYRE (PHYsical REasoning) benchmark - consisting of classic mechanical puzzles in 2D physical environments - as a means to evaluate the physical reasoning ability of machine learning models.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1908.05656">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="environment">Environment</h2>
+
+<ul>
+ <li>
+ <p>2D world that obeys Newtonian mechanics.</p>
+ </li>
+ <li>
+ <p>Gravitational force + Friction.</p>
+ </li>
+ <li>
+ <p>Non-deformable objects that can be static (ie fixed) or dynamic (ie can move and are affected by collisions etc).</p>
+ </li>
+</ul>
+
+<h2 id="task">Task</h2>
+
+<ul>
+ <li>
+ <p>The learning agent starts in some initial world state (ie configuration of objects).</p>
+ </li>
+ <li>
+ <p>Goal is described in the form of (<code class="language-plaintext highlighter-rouge">subject</code>, <code class="language-plaintext highlighter-rouge">relation</code>, <code class="language-plaintext highlighter-rouge">object</code>) where the agent’s task is to satisfy the <code class="language-plaintext highlighter-rouge">relation</code> between the <code class="language-plaintext highlighter-rouge">subject</code> and the <code class="language-plaintext highlighter-rouge">object</code>.</p>
+ </li>
+ <li>
+ <p>Currently, only the “touch” <code class="language-plaintext highlighter-rouge">relation</code> is supported.</p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>The learning agent has to take a single action - placing one or more new dynamic objects in the world.</p>
+ </li>
+ <li>
+ <p>A simulator is run on the new configuration (for a fixed amount of time) to check if the goal condition is satisfied.</p>
+ </li>
+ <li>
+ <p>At the end of the simulation, a binary reward and intermediate observations (collected as the simulator executes) are provided to the learning agent.</p>
+ </li>
+ <li>
+ <p>These observations are 256*256 grids where each grid cell can take 1 of the 7 values (denoting different types of objects).</p>
+ </li>
+ <li>
+ <p>Since only one relation supported currently, the color is sufficient to encode the goal.</p>
+ </li>
+</ul>
+
+<h2 id="benchmark-tiers">Benchmark Tiers</h2>
+
+<ul>
+ <li>
+ <p>Two benchmark tiers are provided where each tier comprises of a combination of:</p>
+
+ <ul>
+ <li>
+ <p>a predefined set of all the actions that the agent is allowed to perform.</p>
+ </li>
+ <li>
+ <p>set of tasks that can be solved by at least one action from the allowed action set.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>PHYRE-B</strong> - The agent is allowed to place a single (ball of any radii) at any valid location.</p>
+ </li>
+ <li>
+ <p><strong>PHYRE-2B</strong> - The agent is allowed to place 2 balls at any valid pair of locations.</p>
+ </li>
+ <li>
+ <p>Each of the two tiers has 25 task templates where each template comprises of variants of a single task (same goal but different initial conditions).</p>
+ </li>
+</ul>
+
+<h2 id="evaluation">Evaluation</h2>
+
+<ul>
+ <li>
+ <p>Two evaluation setups are considered:</p>
+
+ <ul>
+ <li>
+ <p><strong>within-template</strong> where the agent is trained on some tasks in a template and evaluated on a set of held-out tasks from the same template.</p>
+ </li>
+ <li>
+ <p><strong>cross-template</strong> where the agent is evaluated on tasks from a different template.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In the training phase, the model has access to the simulator (but not to the correct solution). So the model could learn an action-prediction model or forward dynamics model or both.</p>
+ </li>
+ <li>
+ <p>In the testing phase, the model can query the simulator only a few times. Each query provides it with the binary reward and the intermediate observations.</p>
+ </li>
+</ul>
+
+<h2 id="performance-measure">Performance Measure</h2>
+
+<ul>
+ <li>
+ <p>The emphasis is on solving more tasks (in few queries) during the test phase.</p>
+ </li>
+ <li>
+ <p>This requirement is captured using a metric called AUCCESS.</p>
+ </li>
+ <li>
+ <p>In general, the tasks in PHYRE-2B are harder than tasks in PHYRE-B.</p>
+ </li>
+</ul>
+
+<h2 id="baseline-agents">Baseline Agents</h2>
+
+<ul>
+ <li>
+ <p>Random Agent - Randomly samples actions</p>
+ </li>
+ <li>
+ <p>Non-parametric agent (MEM) - generates R actions at random and uses the simulator to check how many tasks can be solved using these R random actions. During testing, try the R actions in the decreasing order of the number of tasks they solve.</p>
+ </li>
+ <li>
+ <p>Non-parametric agent with online learning (MEM-O) - Variant of MEM where an online adaptation step is performed during test time (to update the rank of the actions).</p>
+ </li>
+ <li>
+ <p>Deep Q Networks with an action encoder, observation encoder and fusion model (combine action and observation representation).</p>
+ </li>
+ <li>
+ <p>DQN with online learning (DQN-0): Variant of DQN with online updates (during the test phase).</p>
+ </li>
+ <li>
+ <p>Contextual bandits.</p>
+ </li>
+ <li>
+ <p>Policy learning approaches like PPO and A2C.</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>Both Contextual bandits and policy-based approaches show poor training stability.</p>
+ </li>
+ <li>
+ <p>The best agent, DQN-O, reaches AUCCESS of 56.2\% on PHYRE-B and 39.26\% on PHYRE-2B. In general, agents with online adaptation perform better.</p>
+ </li>
+ <li>
+ <p>The tasks are designed such that 100000 attempts are sufficient to solve 100\% of tasks in PHYRE-B and 95\% of tasks in PHYRE-2B.</p>
+ </li>
+ <li>
+ <p>Even though only two tiers are provided right now, the benchmark is readily extensible and new tasks can be added in the future.</p>
+ </li>
+</ul>
+
+
+
+
+ Large Memory Layers with Product Keys
+
+ 2019-08-22T00:00:00-04:00
+ /site/2019/08/22/Large Memory Layers with Product Keys
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper proposes a structured key-value memory layer that:
+ <ul>
+ <li>Can scale to a very large size (and capacity).</li>
+ <li>Has very low computational overhead.</li>
+ <li>Supports exact search in the keyspace.</li>
+ <li>Can be easily integrated with neural networks.</li>
+ </ul>
+ </li>
+ <li><a href="https://arxiv.org/abs/1907.05242">Link to the paper</a></li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>The memory layer is composed of 3 components:</p>
+
+ <ul>
+ <li>
+ <p><strong>Query Network</strong></p>
+
+ <ul>
+ <li>Maps input to a latent space.</li>
+ <li>Can be implemented as a feed-forward network.</li>
+ <li>Adding batch-norm on top of the query network helps to spread out keys.</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Key selection module</strong></p>
+
+ <ul>
+ <li>Lets say there are a total of <em>K</em> keys of dimensionality <em>d<sub>q</sub></em> of which we want to select top <em>k</em> keys.</li>
+ <li>Partition the set of keys into two sets of <em>subkeys</em> (say <em>Q<sub>1</sub></em> and <em>Q<sub>2</sub></em>) where each subset has <em>K</em> keys of dimensionality <em>d_q/2</em>.</li>
+ <li>The query is split into two subqueries (say <em>q<sub>1</sub></em> and <em>q<sub>2</sub></em>).</li>
+ <li>Each of these two queries are compared with every query in their corresponding set of <em>subkeys</em>.</li>
+ <li>For example, <em>q<sub>1</sub></em> is compared with every query is <em>Q<sub>1</sub></em>.</li>
+ <li>Top <em>k</em> ranked keys are selected from each set to create two new sets <em>C<sub>1</sub></em> and <em>C2<sub>2</sub></em>.</li>
+ <li>The keys from these two sets are combined uder the concatenation operator to obtain <em>k<sub>2</sub></em> vectors.</li>
+ <li>the final top <em>k</em> (concatenated) keys are searched from these *k<sup>2* keys.</sup></li>
+ <li>The overall complexity is $O((\sqrt K + k^2) \times d_q)$ where <em>K</em> is the total number of keys (whiuc)</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Value lookup table</strong></p>
+
+ <ul>
+ <li>The values (corresponding to selected subkeys) are aggregated (using weighted sum operation) to obtain the output.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>All the parameters are trainable, though, in practice, only the selected <em>k</em> memory slots are updated.</p>
+ </li>
+ <li>
+ <p>Using Multihead attention mechanism helps to improve the performance further.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>1 or more feedforward layers in transformers are placed by the memory layers.</p>
+ </li>
+ <li>
+ <p>The model is evaluated on large scale language modeling tasks with 140 Gb of data from common crawl corpora (28n billion words).</p>
+ </li>
+ <li>
+ <p>Evaluation metrics</p>
+
+ <ul>
+ <li>
+ <p>Perplexity on the test set.</p>
+ </li>
+ <li>
+ <p>Fraction of accessed values.</p>
+ </li>
+ <li>
+ <p>KL divergence between the (normalized) weights of key access and uniform distribution.</p>
+ </li>
+ <li>
+ <p>The last two metrics are used together to determine how well the keys are utilized.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Given the large size of the training dataset, adding more layers to the transformer model helps.</p>
+ </li>
+ <li>
+ <p>Effect of using memory layer is more powerful than the effect of adding new layers to the transformer. For example, a 12 layer transformer + memory layer outperforms a 24 layer transformer while being almost twice as fast.</p>
+ </li>
+ <li>
+ <p>The best position to place the memory is at an intermediate layer and placing the memory layer right after the input or just before the softmax layer does not work well in practice.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Abductive Commonsense Reasoning
+
+ 2019-08-15T00:00:00-04:00
+ /site/2019/08/15/Abductive Commonsense Reasoning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents the task of abductive NLP (pronounced as <em>alpha NLP</em>) where the model needs to perform abductive reasoning.</p>
+ </li>
+ <li>
+ <p>Abductive reasoning is the inference to the most plausible explanation. Even though it is considered to be an important component for understanding narratives, the work in this domain is sparse.</p>
+ </li>
+ <li>
+ <p>A new dataset called as Abstractive Reasoning in narrative Text (ART) consisting of 20K narrative contexts and 200k explanations is also provided. The dataset models the task as multiple-choice questions to make the evaluation process easy.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1908.05739">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="task-setup">Task Setup</h2>
+
+<ul>
+ <li>
+ <p>Given a pair of observations <em>O<sub>1</sub></em> and <em>O<sub>2</sub></em> and two hypothesis <em>h<sub>1</sub></em> and <em>h<sub>2</sub></em>, the task is to select the most plausible hypothesis.</p>
+ </li>
+ <li>
+ <p>In general, <em>P(h | O<sub>1</sub>, O<sub>2</sub>)</em> is propotional to <em>P(h |O<sub>1</sub>)P(O<sub>2</sub>|h, O<sub>1</sub>)</em>.</p>
+ </li>
+ <li>
+ <p>Different independence assumptions can be imposed on the structure of the problem eg one assumption could be that the hypothesis is independent of the observations or the “fully connected” assumption would jointly model both the observations and the hypothesis.</p>
+ </li>
+</ul>
+
+<h2 id="dataset">Dataset</h2>
+
+<ul>
+ <li>
+ <p>Along with crowdsourcing several plausible hypotheses for each observation instance pair, an adversarial filtering algorithm (AF) is used to remove weak pairs of hypothesis.</p>
+ </li>
+ <li>
+ <p>Observation pairs are created using the <a href="https://aclweb.org/anthology/N16-1098">ROCStories dataset</a> which is a collection of short, manually crafted stories of 5 sentences.</p>
+ </li>
+ <li>
+ <p>The average word length for both the content and the hypothesis is between 8 to 9.</p>
+ </li>
+ <li>
+ <p>To collect plausible hypothesis, the crowd workers were asked to fill in a plausible “in-between” sentence in natural language.</p>
+ </li>
+ <li>
+ <p>Given the plausible hypothesis, the crowd workers were asked to create an implausible hypothesis by editing fewer than 6 words.</p>
+ </li>
+ <li>
+ <p>Adversarial filtering approach from <a href="https://aclweb.org/anthology/D18-1009">Zellers et al.</a> is used with BERT as the adversary. A temperature parameter is introduced to control the maximum number of instances that can be changed in each adversarial filtering iteration.</p>
+ </li>
+</ul>
+
+<h2 id="key-observations">Key Observations</h2>
+
+<ul>
+ <li>
+ <p>Human performance: 91.4%</p>
+ </li>
+ <li>
+ <p>Baselines like SVM classifier, the bag-of-words classifier (using Glove) and max-pooling overt BiLSTM representation: approx 50%</p>
+ </li>
+ <li>
+ <p>Entailment NLI baseline: 59%. This highlights the additional complexity of abductive NLI as compared to entailment NLI.</p>
+ </li>
+ <li>
+ <p>BERT: 68.9%</p>
+ </li>
+ <li>
+ <p>GPT: 63.1%</p>
+ </li>
+ <li>
+ <p>Numerical and spatial knowledge-based data points are particularly hard.</p>
+ </li>
+ <li>
+ <p>The model is more likely to fail when the narrative created by the incorrect hypothesis is plausible</p>
+ </li>
+</ul>
+
+
+
+
+
+ Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
+
+ 2019-08-08T00:00:00-04:00
+ /site/2019/08/08/Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a new algorithm called as Probabilistic Ensemble with Trajectory sampling (PETS) that combines uncertainty aware deep learning models (ensemble of deep learning models that encode uncertainty) with sampling-based uncertainty propagation.</p>
+ </li>
+ <li>
+ <p>PETS improves over other probabilistic MBRL approaches by isolating epistemic uncertainty (due to limited training data) and aleatoric uncertainty (inherent in the system).</p>
+ </li>
+ <li>
+ <p><a href="">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="uncertainty-aware-neural-network-dynamics-model">Uncertainty-Aware Neural Network Dynamics Model</h2>
+
+<ul>
+ <li>
+ <p>Aleatoric uncertainty can be accounted for by learning a parameterized distribution (probabilistic neural network) trained with negative log-likelihood.</p>
+ </li>
+ <li>
+ <p>Epistemic uncertainty can be accounted for by either having an infinite amount of data or by using ensembles.</p>
+ </li>
+ <li>
+ <p>The paper uses a neural network to predict the mean and standard deviation of a gaussian distribution which defines the predictive model. This setup is referred to as the “probabilistic” model and denoted by <strong>P</strong>.</p>
+ </li>
+ <li>
+ <p>The alternate setup of the deterministic model is where a neural network is used to make a point prediction (and is denoted by <strong>D</strong>).</p>
+ </li>
+ <li>
+ <p>Ensemble of probabilistic models is denoted as <strong>PE</strong> while that of deterministic models is denoted as <strong>DE</strong>.</p>
+ </li>
+</ul>
+
+<h2 id="planning-and-control-with-learned-dynamics">Planning and Control with learned Dynamics</h2>
+
+<ul>
+ <li>
+ <p>Model Predictive Control (MPC) is used for planning.</p>
+ </li>
+ <li>
+ <p>Given a start state and an action sequence, the probabilistic dynamics model induces a distribution over the trajectories.</p>
+ </li>
+ <li>
+ <p>The first action, among the sequence of optimized actions, is executed.</p>
+ </li>
+ <li>
+ <p>Instead of random shooting, <a href="https://www.sciencedirect.com/science/article/pii/B9780444538598000035">Cross Entropy Method (CEM)</a> is used.</p>
+ </li>
+</ul>
+
+<h2 id="trajectory-sampling">Trajectory Sampling</h2>
+
+<ul>
+ <li>
+ <p>Let us say there are B bootstrap models in the ensemble. Given the current state, P particles are created and each particle is propagated using one of the bootstrap models. Two variants are considered:</p>
+
+ <ul>
+ <li>
+ <p>TS1 - At each timestep, each particle samples a bootstrap. In this case, particle separation can not be attributed to ti the compounding effects of the bootstraps.</p>
+ </li>
+ <li>
+ <p>TS$\infty$ - The bootstrapped model (per particle) is sampled just once and is not changed after that. This setup separates aleatoric and epistemic uncertainty. Aleatoric state variance is the average variance of the particles of the same bootstrap while epistemic state variance is the variance of the average of particles of same bootstrap indexes.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="result">Result</h2>
+
+<ul>
+ <li>
+ <p>The proposed approach reaches the asymptotic performance of state-of-the-art model-free algorithms in much fewer samples.</p>
+ </li>
+ <li>
+ <p>The general performance trend is probabilistic emsemble > probabilisitc model > deterministc ensemble > determinisitc model./.</p>
+ </li>
+ <li>
+ <p>Initial experiments for learning policy by propagating gradients through the ensemble of models did not work and has been left as future work.</p>
+ </li>
+</ul>
+
+
+
+
+ Assessing Generalization in Deep Reinforcement Learning
+
+ 2019-08-01T00:00:00-04:00
+ /site/2019/08/01/Assessing Generalization in Deep Reinforcement Learning
+ <ul>
+ <li>
+ <p>The paper presents a benchmark and experimental protocol (environments, metrics, baselines, training/testing setup) to evaluate RL algorithms for generalization.</p>
+ </li>
+ <li>
+ <p>Several RL algorithms are evaluated and the key takeaway is that the “vanilla” RL algorithms can generalize better than the RL algorithms that are specifically designed to generalize, given enough diversity in the distribution of the training environments.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1810.12282">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>The focus is on evaluating generalization to environmental changes that affect the system dynamics (and not the goal or rewards).</p>
+ </li>
+ <li>
+ <p>Two generalization regimes are considered:</p>
+
+ <ul>
+ <li>
+ <p>Interpolation - parameters of the test environment are similar to the parameters of the training environment.</p>
+ </li>
+ <li>
+ <p>Extrapolation - parameters of the test environment are different from the parameters of the training environment.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Following algorithms are considered as part of the benchmark:</p>
+
+ <ul>
+ <li>
+ <p>“Vanilla” RL algorithms - A2C, PPO</p>
+ </li>
+ <li>
+ <p>RL algorithms that are designed to generalize:</p>
+
+ <ul>
+ <li>
+ <p>EPOpt - Learn a (robust) policy that maximizes the expected reward over the most difficult distribution of environments (ones with the worst expected reward).</p>
+ </li>
+ <li>
+ <p>RL<sup>2</sup> - Learn an (adaptive) policy that can adapt to the current environment/task by considering the trajectory and not just the state transition sequence.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>These specially designed RL algorithms can be optimized using either A2C or PPO leading to combinations like EPOpt-A2C or EPOpt-PPO etc.</p>
+ </li>
+ <li>
+ <p>The models are either composed of feedforward networks completely or feedforward + recurrent networks.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Environments</p>
+
+ <ul>
+ <li>
+ <p>CartPole, MountainCar, Acrobot, and Pendulum from OpenAI Gym.</p>
+ </li>
+ <li>
+ <p>HalfCheetah and Hopper from OpenAI Roboschool.</p>
+ </li>
+ <li>
+ <p>Three versions of each environment are considered:</p>
+
+ <ul>
+ <li>
+ <p>Deterministic: Environment parameters are fixed. This case corresponds to the standard environment setup in classical RL.</p>
+ </li>
+ <li>
+ <p>Random: Environment parameters are sampled randomly. This case corresponds to sampling from a distribution of environments.</p>
+ </li>
+ <li>
+ <p>Extreme: Environment parameters are sampled from their extreme values. This case corresponds to the edge-case environments which would not be encountered during training generally.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Performance Metrics</p>
+
+ <ul>
+ <li>
+ <p>Average total reward per episode.</p>
+ </li>
+ <li>
+ <p>Success percentage: Percentage of episodes where a certain goal (or reward) is obtained.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Evaluation Metrics/Setups</p>
+
+ <ul>
+ <li>
+ <p>Default: success percentage when training and evaluating the deterministic version of the environment.</p>
+ </li>
+ <li>
+ <p>Interpolation: success percentage when training and evaluating on the random version of the environment.</p>
+ </li>
+ <li>
+ <p>Extrapolation: the geometric mean of the success percentage of following three versions:</p>
+
+ <ul>
+ <li>
+ <p>Train on deterministic and evaluate on the random version.</p>
+ </li>
+ <li>
+ <p>Train on deterministic and evaluate on extreme version.</p>
+ </li>
+ <li>
+ <p>Train on random and evaluate on the extreme version.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Observations</p>
+
+ <ul>
+ <li>
+ <p>Extrapolation is harder than interpolation.</p>
+ </li>
+ <li>
+ <p>Increasing the diversity in the training environments improves the interpolation generalization of vanilla RL methods.</p>
+ </li>
+ <li>
+ <p>EPOpt improves generalization only for continuous control environments and only with PPO.</p>
+ </li>
+ <li>
+ <p>RL<sup>2</sup> is difficult to train on the environments considered and did not provide a clear advantage in terms of generalization.</p>
+ </li>
+ <li>
+ <p>EPOpt-PPO outperforms PPO on only 3 environments and EPOpt-A2C does not</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+
+ Quantifying Generalization in Reinforcement Learning
+
+ 2019-07-25T00:00:00-04:00
+ /site/2019/07/25/Quantifying Generalization in Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces a new, procedurally generated environment called as CoinRun that is designed to benchmark the generalization capabilities of RL algorithms.</p>
+ </li>
+ <li>
+ <p>The paper reports that deep convolutional architectures and techniques like L2 regularization, batch norm, etc (which were proposed in the context of generalization in supervised learning) are also useful for RL.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1812.02341">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="coinrun-environment">CoinRun Environment</h2>
+
+<ul>
+ <li>
+ <p>CoinRun is made of multiple levels.</p>
+ </li>
+ <li>
+ <p>In each level, the agent spawns on the far left side and needs to collect a single coin that lies on the far right side.</p>
+ </li>
+ <li>
+ <p>There are many obstacles in between and colliding with an obstacle leads to agent’s death.</p>
+ </li>
+ <li>
+ <p>Each episode extends for a maximum for 1000 steps.</p>
+ </li>
+ <li>
+ <p>CoinRun is designed such that given sufficient training time and levels, a near-optimal policy can be learned for all the levels.</p>
+ </li>
+</ul>
+
+<h2 id="generalization">Generalization</h2>
+
+<ul>
+ <li>
+ <p>Generalization can be measure by training an agent on a given set of training tasks and evaluating on an unseen set of test tasks.</p>
+ </li>
+ <li>
+ <p>9 agents are trained to play CoinRun, on different training sets (each with a different number of levels).</p>
+ </li>
+ <li>
+ <p>The first 8 agents are trained on sets of size 100 to 16000 levels while the last agent is trained on an unbounded set of levels.</p>
+ </li>
+ <li>
+ <p>Training a model on an unbounded set of levels provides a good proxy for the train-to-test generalization performance.</p>
+ </li>
+</ul>
+
+<h2 id="evaluating-architectures">Evaluating Architectures</h2>
+
+<ul>
+ <li>
+ <p>Two convolutional architectures (of different sizes) are compared:</p>
+
+ <ul>
+ <li>
+ <p>Nature-CNN: The CNN architecture used in the <a href="https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf">Deep Q Network</a>. This is the smaller network among the two models.</p>
+ </li>
+ <li>
+ <p>IMPALA-CNN: The CNN architecture used in the <a href="https://arxiv.org/abs/1802.01561">Imapla architecture</a>.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>IMPALA-CNN agent always outperforms the Nature-CNN agent indicating that larger architecture has more capacity for generalization. But increasing the network size beyond a limit gives diminishing returns.</p>
+ </li>
+</ul>
+
+<h2 id="evaluating-regularization">Evaluating Regularization</h2>
+
+<ul>
+ <li>
+ <p>While both L2 regularization and Dropout helps to improve generalization, L2 regularization is more impactful.</p>
+ </li>
+ <li>
+ <p>A domain randomization/data augmentation approach is tested where rectangular regions of different sizes are masked and assigned a random color. This approach seems to improve performance.</p>
+ </li>
+ <li>
+ <p>Batch Normalization helps to improve performance as well.</p>
+ </li>
+ <li>
+ <p>Environment stochasticity is introduced by using sticky actions while policy stochasticity is introduced by controlling the entropy bonus. Both these forms of stochasticity boost performance.</p>
+ </li>
+ <li>
+ <p>While combining different regularization methods help, the gains are only marginally better than using just 1 regularization approach. This suggests that these different approaches induce similar generalization properties.</p>
+ </li>
+</ul>
+
+<h2 id="additional-environments">Additional Environments</h2>
+
+<ul>
+ <li>
+ <p>Two additional environments are also considered to verify the high degree of overfitting observed in the CoinRun environment:</p>
+
+ <ul>
+ <li>
+ <p>CoinRun-Platforms:</p>
+
+ <ul>
+ <li>
+ <p>Unlike CoinRun, each episode can have multiple coins and the time limit is 0increased to 1000 steps.</p>
+ </li>
+ <li>
+ <p>Levels are larger as well so the agent might need to backtrack their steps.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>RandomMazes:</p>
+
+ <ul>
+ <li>
+ <p>Partially observed environment with square mazes of dimensions 3x3 to 25x25.</p>
+ </li>
+ <li>
+ <p>Timelimit of 500 steps</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Overfitting is observed for both these environments as well.</p>
+ </li>
+</ul>
+
+
+
+
+ Set Transformer - A Framework for Attention-based Permutation-Invariant Neural Networks
+
+ 2019-07-18T00:00:00-04:00
+ /site/2019/07/18/Set Transformer A Framework for Attention-based Permutation-Invariant Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Consider problems where the input to the model is a set. In such problems (referred to as the set-input problems), the model should be invariant to the permutation of the data points.</p>
+ </li>
+ <li>
+ <p>In “set pooling” methods (<a href="https://arxiv.org/abs/1606.02185">1</a>, <a href="https://arxiv.org/abs/1703.06114">2</a>), each data point (in the input set) is encoded using a feed-forward network and the resulting set of encoded representations are pooled using the “sum” operator.</p>
+ </li>
+ <li>
+ <p>This approach can be shown to be bot permutation-invariant and a universal function approximator.</p>
+ </li>
+ <li>
+ <p>The paper proposes an attention-based network module, called as the Set Transformer, which can model the interactions between the elements of an input set while being permutation invariant.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1810.00825">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="transformer">Transformer</h2>
+
+<ul>
+ <li>
+ <p>An attention function <em>Attn(Q, K, V) = (QK<sup>T</sup>)V</em> is used to map queries <em>Q</em> to output using key-value pairs <em>K, V</em>.</p>
+ </li>
+ <li>
+ <p>In case of multi-head attention, the key, query, and value are projected into <em>h</em> different vectors and attention is applied on all these vectors. The output is a linear transformation of the concatenation of all the vectors.</p>
+ </li>
+</ul>
+
+<h2 id="set-transformer">Set Transformer</h2>
+
+<ul>
+ <li>
+ <p>3 modules are introduced: MAB, SAB and ISAB.</p>
+ </li>
+ <li>
+ <p>Multihead Attention Block (MAB) is a module very similar to to the encoder in the Transformer, without the positional encoding and dropout.</p>
+ </li>
+ <li>
+ <p>Set Attention Block (SAB) is a module that takes as input a set and performs self-attention between the elements of the set to produce another set of the same size ie <em>SAB(X) = MAB(X, X)</em>.</p>
+ </li>
+ <li>
+ <p>The time complexity of the SAB operation is <em>O(n<sup>2</sup>)</em> where <em>n</em> is the number of elements in the set. It can be reduced to <em>O(m*n)</em> by using Induced Set Attention Blocks (ISAB) with <em>m</em> induced point vectors (denoted as I).</p>
+ </li>
+ <li>
+ <p><em>ISAB<sub>m</sub> = MAB(X, MAB(I, X))</em>.</p>
+ </li>
+ <li>
+ <p>ISAB can be seen as performing a low-rank projection of inputs.</p>
+ </li>
+ <li>
+ <p>These modules can be used to model the interactions between data points in any given set.</p>
+ </li>
+</ul>
+
+<h2 id="pooling-by-multihead-attention-pma">Pooling by Multihead Attention (PMA)</h2>
+
+<ul>
+ <li>
+ <p>Aggregation is performed by applying multi-head attention on a set of <em>k</em> seed vectors.</p>
+ </li>
+ <li>
+ <p>The interaction between the <em>k</em> outputs (from PMA) can be modeled by applying another SAB.</p>
+ </li>
+ <li>
+ <p>Thus the entire network is a stack of SABs and ISABs. Both the modules are permutation invariant and so is any network obtained by stacking them.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Datasets include:</p>
+
+ <ul>
+ <li>Predicting the maximum value from a set.</li>
+ <li>Counting unique (Omniglot) characters from an image.</li>
+ <li>Clustering with a mixture of Gaussians (synthetic points and CIFAR 100).</li>
+ <li>Set Anomaly detection (celebA).</li>
+ </ul>
+ </li>
+ <li>
+ <p>Generally, increasing <em>m</em> (the number of inducing datapoints) improve performance, to some extent. This is somewhat expected.</p>
+ </li>
+ <li>
+ <p>The paper considers various ablations of the proposed approach (like disabling attention in the encoder or pooling layer) and shows that attention mechanism is needed during both the stages.</p>
+ </li>
+ <li>
+ <p>The work has two main benefits over prior work:</p>
+
+ <ul>
+ <li>
+ <p>Reducing the <em>O(n<sup>2</sup>)</em> complexity to <em>O(m*n)</em> complexity.</p>
+ </li>
+ <li>
+ <p>Using self-attention mechanism for both encodings the inputs and for aggregating the encoded representations.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Measuring abstract reasoning in neural networks
+
+ 2019-06-27T00:00:00-04:00
+ /site/2019/06/27/Measuring Abstract Reasoning in Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a dataset to diagnose the abstract reasoning capabilities of learning systems.</p>
+ </li>
+ <li>
+ <p>The paper shows that a variant of the relational networks, explicitly designed for abstract reasoning, outperforms models like ResNets.</p>
+ </li>
+ <li>
+ <p><a href="http://proceedings.mlr.press/v80/santoro18a/santoro18a.pdf">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="idea">Idea</h2>
+
+<ul>
+ <li>
+ <p>Visual reasoning tasks, that are inspired by the human IQ test, are used to evaluate the models in terms of generalization.</p>
+ </li>
+ <li>
+ <p>Let’s say that we want to test if the model understands the abstract notion of “increasing”. We could train the model on data that captures the notion of “increasing”, in terms of say increasing size (or quantities) of objects and then test it on a dataset where the notion is expressed in terms of increasing intensity of color.</p>
+ </li>
+ <li>
+ <p>The dataset is then used to evaluate if the models can find any solution to such abstract reasoning tasks and how well they generalize when the abstract content is specifically controlled.</p>
+ </li>
+</ul>
+
+<h2 id="dataset">Dataset</h2>
+
+<h3 id="ravens-progressive-matrics-rpms">Raven’s Progressive Matrics (RPMs):</h3>
+
+<ul>
+ <li>
+ <p>Consists of an incomplete 3x3 matrix of images where the missing image needs to be filled in, typically by choosing from a set of candidate images.</p>
+ </li>
+ <li>
+ <p>As such, it is possible to justify multiple answers to be correct though, in practice, the right answer is the one with the simplest explanation.</p>
+ </li>
+</ul>
+
+<h3 id="procedurally-generated-matrices-pgms">Procedurally Generated Matrices (PGMs)</h3>
+
+<ul>
+ <li>
+ <p>Generating RPM like matrices procedurally by building an abstract structure for matrices.</p>
+ </li>
+ <li>
+ <table>
+ <tbody>
+ <tr>
+ <td>The abstract structure <em>S</em> consists of 3 components: (i) Relation types (<em>R</em>), (ii) Object types (<em>O</em>) and (iii) Attribute types (<em>A</em>). ie *S = {(r, o, a)</td>
+ <td>r in R, o in O and a in A}*.</td>
+ </tr>
+ </tbody>
+ </table>
+ </li>
+ <li>
+ <p>This can be read as: “Structure <em>S</em> is instantiated on attribute <em>a</em> of object <em>o</em> and exhibits the relation <em>r</em>”. For example, <em>S</em> is instantiated on “color” of object “shape” and exhibits the relation “increasing”.</p>
+ </li>
+ <li>
+ <p>In general, the structure could be made of more than one such tuple and more are the tuples, harder is the task.</p>
+ </li>
+ <li>
+ <p>Given the structure, sample values <em>v</em> for each attribute <em>a</em> while conforming with the relation <em>r</em>. For example, if the attribute is “color” and the relation is “increasing”, the intensity of color must increase.</p>
+ </li>
+ <li>The resulting structure is rendered as pixels.</li>
+</ul>
+
+<h2 id="test-for-generalization">Test for Generalization</h2>
+
+<ul>
+ <li>
+ <p>The paper tests for the following generalization scenarios:</p>
+ </li>
+ <li>
+ <p>Neutral: The structure of the training and test data can contain any tuple.</p>
+ </li>
+ <li>
+ <p>Interpolation: The training data contains even-indexed members of the attribute values while the test data contains odd-indexed members of the attribute values.</p>
+ </li>
+ <li>
+ <p>Extrapolation: The training data contains first-half of the attribute values while the test data contains the second-half of the attribute values.</p>
+ </li>
+ <li>
+ <p>Heldout attribute: Training data contains no tuples with (o = shape, a = color) or (o = line, a = type).</p>
+ </li>
+ <li>
+ <p>Heldout triples: Out of 29 possible triples, 7 are held out from training and only used during testing.</p>
+ </li>
+ <li>
+ <p>Heldout pair-of-triples: Out of 400 possible sets of pair of triples, 40 were held out and used only during testing.</p>
+ </li>
+ <li>
+ <p>Heldout pair-of-triples: Out of 400 possible sets of pair of triples, 40 were held out and used only during testing.</p>
+ </li>
+ <li>
+ <p>Heldout attribute pair: Out of 20 (unordered) variable attribute pairs, 4 were held out and used only during testing.</p>
+ </li>
+</ul>
+
+<h2 id="models">Models</h2>
+
+<ul>
+ <li>
+ <p><strong>Input</strong>: 8 context panels (from the 3x3) matrix where the last panel needs to be filled.</p>
+ </li>
+ <li>
+ <p>CNN-MLP - 4 layer CNN with batchnorm and ReLU.</p>
+ </li>
+ <li>
+ <p>ResNet - ResNet-50 (as it perfomed better than ResNet-101 and ResNet-152).</p>
+ </li>
+ <li>
+ <p>LSTM</p>
+ </li>
+ <li>
+ <p>Wild Relation Network (WReN) - A CNN model encodes the 8 panels and the candidate answers and feeds them as input to a relational network.</p>
+ </li>
+ <li>
+ <p>Context-blind ResNet - ResNet network without the context (or the 8 input panels).</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>WReN model outperforms the other models on the Neutral setup.</p>
+ </li>
+ <li>
+ <p>Models have a harder time differentiating between size than quantity.</p>
+ </li>
+ <li>
+ <p>WRen is the best performing models in all the setups and rest of the discussion only applies to that model.</p>
+ </li>
+ <li>
+ <p>Generalisation is easy in the context of interpolation while worst in case of extrapolation, hinting at the limited generalization capability of the models.</p>
+ </li>
+</ul>
+
+<h2 id="auxiliary-training">Auxiliary Training</h2>
+
+<ul>
+ <li>
+ <p>The model is also trained to predict the relevant relation, object and attribute types using the meta-targets that encode this information.</p>
+ </li>
+ <li>
+ <p>The auxiliary training helps in all the cases. Further, the model’s accuracy on the main task is where in the cases where it solves the auxiliary tasks well.</p>
+ </li>
+</ul>
+
+<h2 id="key-takeaway">Key Takeaway</h2>
+
+<ul>
+ <li>
+ <p>For abstract visual reasoning tasks, the choice of models can make a large difference, the case in consideration of ResNets vs Relational Networks.</p>
+ </li>
+ <li>
+ <p>Using auxiliary loss that encourages the model to “explain” its reasoning (in this case by predicting the attributes, relations, etc) helps to improve the performance on the main task as well.</p>
+ </li>
+ <li>
+ <p>Given that the challenge is motivated by tasks used to measure human IQ, it would have been interesting to get an estimate of human performance on at least a subset of this dataset.</p>
+ </li>
+</ul>
+
+
+
+
+ Hamiltonian Neural Networks
+
+ 2019-06-20T00:00:00-04:00
+ /site/2019/06/20/Hamiltonian Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a very cool idea at the intersection of deep learning and physics.</p>
+ </li>
+ <li>
+ <p>The idea is to train a neural network architecture that builds on the concept of Hamiltonian Mechanics (from Physics) to learn physical conservation laws in an unsupervised manner.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1906.01563">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/greydanus/hamiltonian-nn">Link to the code</a></p>
+ </li>
+ <li>
+ <p><a href="https://greydanus.github.io/2019/05/15/hamiltonian-nns/">Link to author’s blog</a></p>
+ </li>
+</ul>
+
+<h2 id="hamiltonian-mechanics">Hamiltonian Mechanics</h2>
+
+<ul>
+ <li>
+ <p>It is a branch of physics that can describe systems which follow some conservation laws and invariants.</p>
+ </li>
+ <li>
+ <p>Consider a set of <em>N</em> pair of coordinates [(q<sub>1</sub>, p<sub>1</sub>), …, (q<sub>N</sub>, p<sub>N</sub>)] where <strong>q</strong> = [q<sub>1</sub>, …, q<sub>N</sub>] dnotes the position of the set of objects while <strong>p</strong> = [p<sub>1</sub>, …, p<sub>N</sub>] denotes the momentum of the set of variables.</p>
+ </li>
+ <li>
+ <p>Together these <em>N</em> pairs completely describe the system.</p>
+ </li>
+ <li>
+ <p>A scalar function <em>H(<strong>q</strong>, <strong>p</strong>)</em>, called as the Hamiltonian is defined such that the partial derivative of <em>H</em> with respect to <strong>p</strong> is equal to derivative of <strong>q</strong> with respect to time <em>t</em> and the negative of partial derivative of <em>H</em> with respect to <strong>q</strong> is equal to derivative of <strong>p</strong> with respect to time <em>t</em>.</p>
+ </li>
+ <li>
+ <p>This can be expressed in the form of the equation as follows:</p>
+ </li>
+</ul>
+
+<p><img src="https://raw.githubusercontent.com/shagunsodhani/papers-I-read/master/assets/HNN/equation1.png" alt="equation1" width="100" height="100" /></p>
+
+<ul>
+ <li>The Hamiltonian can be tied to the total energy of the system and can be used in any system where the total energy is conserved.</li>
+</ul>
+
+<h2 id="hamiltonian-neural-network-hnn">Hamiltonian Neural Network (HNN)</h2>
+
+<ul>
+ <li>
+ <p>The Hamiltonian <em>H</em> can be parameterized using a neural network and can learn conserved quantities from the data in an unsupervised manner.</p>
+ </li>
+ <li>
+ <p>The loss function looks as follows:</p>
+ </li>
+</ul>
+
+<p><img src="https://raw.githubusercontent.com/shagunsodhani/papers-I-read/master/assets/HNN/equation2.png" alt="equation2" width="400" height="50" /></p>
+
+<ul>
+ <li>The partial derivatives can be obtained by computing the <em>in-graph</em> gradient of the output variables with respect to the input variables.</li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>For setups where the energy must be conserved exactly, (eg ideal mass-spring and ideal pendulum), the HNN learn to preserve an energy-like scalar.</p>
+ </li>
+ <li>
+ <p>For setups where the energy need not be conserved exactly, the HNNs still learn to preserve the energy thus highlighting a limitation of HNNs.</p>
+ </li>
+ <li>
+ <p>In case of two body problems, the HNN model is shown to be much more robust when making predictions over longer time horizons as compared to the baselines.</p>
+ </li>
+ <li>
+ <p>In the final experiment, the model is trained on pixel observations and not state observations. In this case, two auxiliary losses are added: auto-encoder reconstruction loss and a loss on the latent space representations. Similar to the previous experiments, the HNN model makes robust predictions over much longer time horizons.</p>
+ </li>
+</ul>
+
+
+
+
+ Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations
+
+ 2019-06-13T00:00:00-04:00
+ /site/2019/06/13/Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a new inverse RL (IRL) algorithm, called as Trajectory-ranked Reward EXtrapolation (T-REX) that learns a reward function from a collection of ranked trajectories.</p>
+ </li>
+ <li>
+ <p>Standard IRL approaches aim to learn a reward function that “justifies” the demonstration policy and hence those approaches cannot outperform the demonstration policy.</p>
+ </li>
+ <li>
+ <p>In contrast, T-REX aims to learn a reward function that “explains” the ranking over demonstrations and can learn a policy that outperforms the demonstration policy.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1904.06387">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>The input is a sequence of trajectories <em>T<sub>1</sub>, … T<sub>m</sub></em> which are ranked in the order of preference. That is, given any pair of trajectories, we know which of the two trajectories is better.</p>
+ </li>
+ <li>
+ <p>The setup is to learn from observations where the learning agent does not have access to the true reward function or the action taken by the demonstration policy.</p>
+ </li>
+ <li>
+ <p>Reward Inference</p>
+
+ <ul>
+ <li>
+ <p>A parameterized reward function <em>r<sub>θ</sub></em> is trained with the ranking information using a binary classification loss function which aims to predict which of the two given trajectory would be ranked higher.</p>
+ </li>
+ <li>
+ <p>Given a trajectory, the reward function predicts the reward for each state. The sum of rewards (corresponding to the two trajectories) is used used to predict the preferred trajectory.</p>
+ </li>
+ <li>
+ <p>T-REX uses partial trajectories instead of full trajectories as a data augmentation strategy.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Policy Optimization</p>
+
+ <ul>
+ <li>Once a reward function has been learned, standard RL approaches can be used to train a new policy.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>Environments: Mujoco (Half Cheetah, Ant, Hooper), Atari</p>
+ </li>
+ <li>
+ <p>Demonstrations generated using PPO (checkpointed at different stages of training).</p>
+ </li>
+ <li>
+ <p>Ensemble of networks used to learn the reward functions.</p>
+ </li>
+ <li>
+ <p>The proposed approach outperforms the baselines <a href="https://arxiv.org/abs/1805.01954">Behaviour Cloning from Observations</a> and <a href="https://arxiv.org/abs/1606.03476">Generative Adversarial Imitation Learning</a>.</p>
+ </li>
+ <li>
+ <p>In terms of reward extrapolation, T-REX can predict the reward for trajectories which are better than the demonstration trajectories.</p>
+ </li>
+ <li>
+ <p>Some ablation studies considered the effect of adding noise (random swapping the preference between trajectories) and found that the model is somewhat robust to noise up to an extent.</p>
+ </li>
+</ul>
+
+
+
+
+ Meta-Reinforcement Learning of Structured Exploration Strategies
+
+ 2019-06-08T00:00:00-04:00
+ /site/2019/06/08/Meta-Reinforcement Learning of Structured Exploration Strategies
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper looks at the problem of learning structured exploration policies for training RL agents.</p>
+ </li>
+ <li>
+ <p>Link to the <a href="https://arxiv.org/abs/1802.07245">paper</a></p>
+ </li>
+</ul>
+
+<h2 id="structured-exploration">Structured Exploration</h2>
+
+<ul>
+ <li>
+ <p>Consider a stochastic, parameterized policy π<sub>θ</sub>(a|s) where θ represents the <em>policy-parameters</em>.</p>
+ </li>
+ <li>
+ <p>To encourage exploration, noise can be added to the policy at each time step t. But the noise added in such a manner does not have any notion of temporal coherence.</p>
+ </li>
+ <li>
+ <p>Another issue is that if the policy is represented by a simple distribution (say parameterized unimodal Gaussian), it can not model complex time-correlated stochastic processes.</p>
+ </li>
+ <li>
+ <p>The paper proposes to condition the policy on per-episode random variables (z) which are sampled from a learned latent distribution.</p>
+ </li>
+ <li>
+ <p>Consider a distibution over the tasks p(T). At the start of any episode of the i<sup>th</sup> task, a latent variable z<sub>i</sub> is sampled from the distribution <em>N(μ<sub>i</sub>, σ<sub>i</sub>)</em> where μ<sub>i</sub> and σ<sub>i</sub> are the learned parameters of the distribution and are referred to as the <em>variation parameters</em>.</p>
+ </li>
+ <li>
+ <p>Once sampled, the same <em>z<sub>i</sub></em> is used to condition the policy for as long as the current episode lasts and the action is sampled from then distribution π<sub>θ</sub>(a|s, z<sub>i</sub>).</p>
+ </li>
+ <li>
+ <p>The intuition is that the latent variable z<sub>i</sub> would encode the notion of a task or goal that does not change arbitrarily during the episode.</p>
+ </li>
+</ul>
+
+<h2 id="model-agnostic-exploration-with-structured-noise">Model Agnostic Exploration with Structured Noise</h2>
+
+<ul>
+ <li>
+ <p>The paper focuses on the setting where the structured exploration policies are to be learned while leveraging the learning from prior tasks.</p>
+ </li>
+ <li>
+ <p>A meta-learning approach, called as model agnostic exploration with structured noise (MAESN) is proposed to learn a good initialization of the <em>policy-parameters</em> and to learn a latent space (for sampling the z from) that can inject structured stochasticity in the policy.</p>
+ </li>
+ <li>
+ <p>General meta-RL approaches have two limitations when it comes to “learning to explore”:</p>
+
+ <ul>
+ <li>Casting meta-RL problems as RL problems lead to policies that do not exhibit sufficient variability to explore effectively.</li>
+ <li>Many current approaches try to meta-learn the entire learning algorithm which limits the asymptotic performance of the model.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Idea behind MAESN is to meta-train <em>policy-parameters</em> so that they learn to use the task-specific <em>latent variables</em> for exploration and can quickly adapt to a new task.</p>
+ </li>
+ <li>
+ <p>An important detail is that the parameters are optimized to maximize the expected rewards after one step of gradient update to ensure that the policy uses the latent variables for exploration.</p>
+ </li>
+ <li>
+ <p>For every iteration of meta-training, an “inner” gradient update is performed on the variational parameters and the <em>post-inner-update</em> parameters are used to perform the meta-update.</p>
+ </li>
+ <li>
+ <p>The authors report that performing the “inner” gradient update on the <em>policy-parameters</em> does not help the overall learning objective and that the step size for each parameter had to be meta-learned.</p>
+ </li>
+ <li>
+ <p>The variation parameters have the usual KL divergence loss which encourages them to be close to the prior distribution (unit Gaussian in this case).</p>
+ </li>
+ <li>
+ <p>After training, the <em>variational parameters</em> for each task are quite close to the prior probably because the training objective optimizes for the expected reward after one step of gradient descent on the <em>variational parameters</em>.</p>
+ </li>
+ <li>
+ <p>Another implementation detail is that reward shaping is used to ensure that the policy gets useful signal during meta-training. To be fair to the baselines, reward shaping is used while training baselines as well. Moreover, the policies trained with reward shaping generalizes to sparse reward setup as well (during meta-test time).</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Three tasks distributions: Robotic Manipulation, Wheeled Locomotion, and Legged Locomotion. Each task distribution has 100 meta-training tasks.</p>
+ </li>
+ <li>
+ <p>In the Manipulation task distribution, the learner has to push different blocks from different positions to different goal positions. In the Locomotion task distributions, the different tasks correspond to the different goal positions.</p>
+ </li>
+ <li>
+ <p>The experiments show that the proposed approach can adapt to new tasks quickly and the learn coherent exploration strategy.</p>
+ </li>
+</ul>
+
+<p>• In some cases, learning from scratch also provides a strong asymptotic performance although learning from scratch takes much longer.</p>
+
+
+
+
+ Relational Reinforcement Learning
+
+ 2019-06-01T00:00:00-04:00
+ /site/2019/06/01/Relational Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Relational Reinforcement Learning (RRL) paradigm uses relational state (and action) space and policy representation to leverage the generalization capability of relational learning for reinforcement learning.</p>
+ </li>
+ <li>
+ <p>The paper shows that effectiveness of RRL - in terms of generalization, sample efficiency and interplay - using box-world and StarCraft II minigames.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1806.01830">Link to the paper</a>.</p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>The main idea is to use neural network models that operate on structured representations and perform relational reasoning via iterated, message-passing style methods.</p>
+ </li>
+ <li>
+ <p>Use of non-local computations using a shared function (in terms of pairwise interactions between entities) provides a better inductive bias.</p>
+ </li>
+ <li>
+ <p>Multi-head dot product attention mechanism is used to model the pairwise interactions (with one or more attention blocks).</p>
+ </li>
+ <li>
+ <p>Iterative computations can be used to capture higher-order interactions between entities.</p>
+ </li>
+ <li>
+ <p>Entity extraction is based on the assumption that entities are things located at a particular point in space.</p>
+ </li>
+ <li>
+ <p>A CNN is used to parse the pixel space observation into <em>k</em> feature maps of size <em>nxn</em>. The <em>(x, y)</em> coordinates are concatenated to each <em>k-</em>dimensional pixel feature-vector to indicate the pixel’s position in the map.</p>
+ </li>
+ <li>
+ <p>The resulting <em>n<sup>2</sup> x k</em> matrix acts as the entity matrix.</p>
+ </li>
+ <li>
+ <p>Actor-critic architecture (using distributed agent IMPALA) is used.</p>
+ </li>
+</ul>
+
+<h2 id="environment">Environment</h2>
+
+<h3 id="box-world">Box-World</h3>
+
+<ul>
+ <li>
+ <p>12 x 12-pixel room with keys and boxes placed randomly.</p>
+ </li>
+ <li>
+ <p>Agent can move in 4 directions.</p>
+ </li>
+ <li>
+ <p>The task is to collect gems by unlocking boxes (which may contain keys to unlock other boxes).</p>
+ </li>
+ <li>
+ <p>Each level has a unique sequence in which boxes need to be opened as opening the wrong box could make the level unsolvable.</p>
+ </li>
+ <li>
+ <p>Difficulty of a level can be controlled using: (i) Number of boxes in the path to the goal. (ii) The number of distractor branches, (iii) Length of distractor branches.</p>
+ </li>
+</ul>
+
+<h3 id="starcraft-ii-minigames">StarCraft II minigames</h3>
+
+<ul>
+ <li>9 mini games designed as specific scenarios in the Starcraft game are used.</li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<h3 id="box-world-1">Box-World</h3>
+
+<ul>
+ <li>
+ <p>RRL agents solve over 98% of the levels while the RL agent solves less than 95% of the levels.</p>
+ </li>
+ <li>
+ <p>Visualising the attention scores indicate that:</p>
+
+ <ul>
+ <li>
+ <p>keys attend to locks they can unlock.</p>
+ </li>
+ <li>
+ <p>all objects attend to agent’s location.</p>
+ </li>
+ <li>
+ <p>agent and gem attend to each other (and themselves).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Generalization capacity is tested in two ways:</p>
+
+ <ul>
+ <li>
+ <p>Performance on levels that require opening a larger sequence of boxes than it is trained on.</p>
+ </li>
+ <li>
+ <p>Performance on levels that require key-lock combinations not seen during training.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>In both the scenarios, the RRL agent significantly outperforms the RL agent.</p>
+ </li>
+</ul>
+
+<h2 id="starcraft">StarCraft</h2>
+
+<ul>
+ <li>
+ <p>RLL agent achieves better or equal results that the RL agent in all but one game.</p>
+ </li>
+ <li>
+ <p>For testing generalization, the agent, that was trained for controlling two marines, was transferred on the task which requires it to control 5 marines. These results are not conclusive given the high variability.</p>
+ </li>
+</ul>
+
+
+
+
+ Good-Enough Compositional Data Augmentation
+
+ 2019-05-21T00:00:00-04:00
+ /site/2019/05/21/Good-Enough Compositional Data Augmentation
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces a simple data augmentation protocol that provides a good compositional inductive bias for sequential models.</p>
+ </li>
+ <li>
+ <p>Synthetic examples are created by taking real sequences and replacing the fragments in sequences which appear in similar environments. This operation is referred to as GECA (Good Enough Compositional Augmentation).</p>
+ </li>
+ <li>
+ <p>The underlying idea is that if two fragments of training examples occur in some environment, then any environment where the first fragment appears is also a valid environment for the second fragment.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1904.09545">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>Discover substitutable fragments (ie pairs of fragments that co-occur with a common fragment) and use them to generate new sequences by swapping fragments.</p>
+ </li>
+ <li>
+ <p>The current work uses very simple criteria to decide if fragments are substitutable - fragments should occur in at least one lexical environment that is exactly the same. A lexical environment is the k-word window around each span of the fragment.</p>
+ </li>
+ <li>
+ <p>Though the idea can be motivated by work in generative syntax and distributional semantics, it would not hold like a physical law when applied to the real data.</p>
+ </li>
+ <li>
+ <p>The authors view this tradeoff as a balance between the shortage of training data vs relative frequency of mistake in the proposed data augmentation approach.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>The approach is evaluated on the SCAN dataset when the model is trained on the short sequence of English commands. Though the dataset augmentation helps the baseline models, it is not surprising given the nature of the SCAN dataset.</p>
+ </li>
+ <li>
+ <p>More challenging tasks (for evaluating the proposed approach) are semantic parsing (where the query is represented in the form of λ calculus or SQL and low resource language modeling. While the improvement (in terms of metrics) is sometimes limited, the gains are consistent across different datasets.</p>
+ </li>
+ <li>
+ <p>Given that the proposed approach is relatively simple and straightforward, it appears to be quite promising.</p>
+ </li>
+</ul>
+
+
+
+
+ Multiple Model-Based Reinforcement Learning
+
+ 2019-05-14T00:00:00-04:00
+ /site/2019/05/14/Multiple Model-Based Reinforcement Learning
+ <ul>
+ <li>
+ <p>The paper presents some general ideas and mechanisms for multiple model-based RL. Even though the task and model architecture may not be very relevant now, I find the general idea and the mechanisms to be quite useful. As such, I am focusing only on high-level ideas and not the implementation details themselves.</p>
+ </li>
+ <li>
+ <p>The main idea behind Multiple Model-based RL (MMRL) is to decompose complex tasks into multiple domains in space and time so that the environment dynamics within each domain is predictable.</p>
+ </li>
+ <li>
+ <p><a href="https://www.mitpressjournals.org/doi/abs/10.1162/089976602753712972">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>MMRL proposes an RL architecture composes of multiple modules, each with its own state prediction model and RL controller.</p>
+ </li>
+ <li>
+ <p>The prediction error from each of the state prediction model defines the “responsibility signal” for each module.</p>
+ </li>
+ <li>
+ <p>This responsibility signal is used to:</p>
+
+ <ul>
+ <li>
+ <p>Weigh the state prediction output ie the predicted state is the weighted sum of individual state predictions (weighted by the responsibility signal).</p>
+ </li>
+ <li>
+ <p>Weigh the parameter update of the environment models as well as the RL controllers.</p>
+ </li>
+ <li>
+ <p>Weighing the action output - ie predicted action is a weighted sum of individual actions.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The framework is amenable for incorporating prior knowledge about which module should be selected.</p>
+ </li>
+ <li>
+ <p>In the modular decomposition of a task, the modules should not change too frequently and some kind of spatial and temporal continuity is also desired.</p>
+ </li>
+ <li>
+ <p>Temporal continuity can be accounted for by using the previous responsibility signal as input during the current timestep.</p>
+ </li>
+ <li>
+ <p>Spatial continuity can b ensured by considering a spatial prior like the Gaussian spatial prior.</p>
+ </li>
+ <li>
+ <p>Though model-free methods could be used for learning the RL controllers, model-based methods could be more relevant given that the modules are learning state-prediction models as well.</p>
+ </li>
+ <li>
+ <p>Exploration can be ensured by using a stochastic version of greedy action selection.</p>
+ </li>
+ <li>
+ <p>One failure mode for such modular architectures is when a single module tries to perform well across all the tasks. The modules themselves should be relatively simplistic (eg linear models) which can learn quickly and generalize well.</p>
+ </li>
+ <li>
+ <p>Non-stationary hunting task in a grid world and non-linear, non-stationary control task of swinging up a pendulum provides the proof of concept for the proposed methods.</p>
+ </li>
+</ul>
+
+
+
+
+ Towards a natural benchmark for continual learning
+
+ 2019-04-09T00:00:00-04:00
+ /site/2019/04/09/Towards a natural benchmark for continual learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Continual Learning paradigm focuses on learning from a non-stationary stream of data with additional desiderata - transferring knowledge from previously seen task to unseen tasks and being resilient to catastrophic forgetting - all with a fixed memory and computational budget.</p>
+ </li>
+ <li>
+ <p>This is in contrast to the IID (independent and identically distributed) assumption in statistical learning.</p>
+ </li>
+ <li>
+ <p>One common example of the non-iid data is setups involving sequential decision making - eg Reinforcement learning.</p>
+ </li>
+ <li>
+ <p><a href="https://marcpickett.com/cl2018/CL-2018_paper_48.pdf">Paper</a></p>
+ </li>
+</ul>
+
+<h2 id="benchmark">Benchmark</h2>
+
+<ul>
+ <li>
+ <p>Many existing benchmarks use MNIST as the underlying dataset (eg Permuted MNIST, Split MNIST, etc). These benchmarks lack complexity and make it hard to observe positive and negative backward transfer.</p>
+ </li>
+ <li>
+ <p>Most works focus only on the catastrophic forgetting challenge and ignore the other issues (like computation and memory footprint, the capacity of the network, etc).</p>
+ </li>
+ <li>
+ <p>The paper proposes a new benchmark based on Starcraft II video game to understand the different approaches for lifelong learning.</p>
+ </li>
+ <li>
+ <p>The sequence of tasks is designed to be a curriculum - the learning agent stats with learning simple skills and later move to more complex tasks. These complex tasks require remembering and composing skills learned in the earlier levels.</p>
+ </li>
+ <li>
+ <p>To evaluate for catastrophic forgetting, the tasks are designed such that not all the skills are needed for solving each task. Hence the learning agent needs to remember skills even though they are not needed at the current level.</p>
+ </li>
+ <li>
+ <p>Each level comes with a fixed computational budget of episodes and each episode has a fixed time limit. Once the budget is consumed the agent has to proceed to the next level. Hence agents with better sample efficiency would benefit.</p>
+ </li>
+ <li>
+ <p>The benchmark supports both RL and supervised learning version. In the supervised version, expert agents (pretrained on each level) are also provided.</p>
+ </li>
+ <li>
+ <p>Baselines are provided for distillation (using experts): sequential training (fine tuning), Dropout and SER. None of the baseline methods achieve positive or negative backward transfer.</p>
+ </li>
+ <li>
+ <p>When modeled as a pure RL task, the benchmark is extremely difficult to solve.</p>
+ </li>
+ <li>
+ <p>The paper suggests using a metric to record the amount of learning/data required to recover performance on the previous task.</p>
+ </li>
+</ul>
+
+
+
+
+ Meta-Learning Update Rules for Unsupervised Representation Learning
+
+ 2019-04-02T00:00:00-04:00
+ /site/2019/04/02/Meta-Learning Update Rules for Unsupervised Representation Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Standard unsupervised learning aims to learn transferable features. The paper proposes to learn a transferable learning rule (in an unsupervised manner) that can generalize across tasks and architectures.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1804.00222">Paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>Consider training the model with supervised learning - <em>φ<sub>t+1</sub> = SupervisedUpdate(φ<sub>t</sub>, x<sub>t</sub>, y<sub>t</sub>, θ)</em>.</p>
+ </li>
+ <li>
+ <p>Here <em>t</em> denotes the step, <em>(x, y)</em> denotes the data points, <em>θ</em> denotes the hyperparameters of the optimizer.</p>
+ </li>
+ <li>
+ <p>Extending this formulation for meta-learning, one could say that <em>t</em> is the step of the inner loop, <em>θ</em> are the parameters of the meta learning model.</p>
+ </li>
+ <li>
+ <p>Further, the paper proposes to use <em>φ<sub>t+1</sub> = UnsupervisedUpdate(φ<sub>t</sub>, x<sub>t</sub>, θ)</em> ie <em>y<sub>t</sub></em> is not used (or even assumed to be available as this is unsupervised learning).</p>
+ </li>
+ <li>
+ <p>The meta update rule is used to learn the weights of a meta-model by performing SGD on the sum of <em>MetaObjective</em> over the distribution of tasks (over the course of inner loop training).</p>
+ </li>
+</ul>
+
+<h2 id="model">Model</h2>
+
+<ul>
+ <li>
+ <p>Base model: MLP with parameters <em>φ<sub>t</sub></em></p>
+ </li>
+ <li>
+ <p>To ensure that it generalizes across architectures, the update rule is designed to be neural-local ie updates are a function of pre and postsynaptic neurons though, in practice, this constraint is relaxed to decorrelate neurons by using cross neural information.</p>
+ </li>
+ <li>
+ <p>Each neuron <em>i</em> in every layer <em>l</em> (in the base model) has an update network (MLP) which takes as input the feedforward activations, feedback weights and error signals. ie <em>h<sub>b</sub><sup>l</sup>(i) = MLP(x<sub>b</sub><sup>l</sup>(i), z<sub>b</sub><sup>l</sup>(i), v<sup>l+1</sup>,
+δ<sup>l</sup>(i), θ)</em></p>
+
+ <ul>
+ <li><em>b</em> - index of the minibatch</li>
+ <li><em>x<sup>l</sup></em> - pre non-linearity activations</li>
+ <li><em>z<sup>l</sup></em> - post non-linearity activations</li>
+ <li><em>v<sup>l</sup></em> - feedback weights</li>
+ <li><em>δ<sup>l</sup></em> - error signal</li>
+ </ul>
+ </li>
+ <li>
+ <p>All the update networks share the meta parameters <em>θ</em></p>
+ </li>
+ <li>
+ <p>The model is run in a standard feed-forward manner and the update network (corresponding to each unit) is used to generate the error signal <em>δ<sup>l</sup><sub>b</sub>(i) = lin(h<sub>b</sub><sup>l</sup>(i))</em>.</p>
+ </li>
+ <li>
+ <p>This loss is backpropogated using the set of learned backward weights <em>v<sup>l</sup></em> instead of the forward weights <em>w<sub>l</sub></em>.</p>
+ </li>
+ <li>
+ <p>The weight update <em>Δw<sub>l</sub></em> is also generated using a per-neuron update network.</p>
+ </li>
+</ul>
+
+<h2 id="meta-objective">Meta Objective</h2>
+
+<ul>
+ <li>
+ <p>The <em>MetaObjective</em> is based on fitting a linear regression model to labeled examples with a small number of data points.</p>
+ </li>
+ <li>
+ <p>Given the emphasis on learning generalizable features, the weights (of linear regression) are estimated on one batch and evaluated on another batch.</p>
+ </li>
+ <li>
+ <p>The <em>MetaObjective</em> is to reduce the cosine distance between <em>y<sub>b</sub></em> and <em>v<sup>T</sup>x<sub>b</sub><sup>L</sup></em></p>
+
+ <ul>
+ <li>
+ <p><em>y<sub>b</sub></em> - Actual lables on the evaluation batch</p>
+ </li>
+ <li>
+ <p><em>x<sub>b</sub><sup>L</sup></em> - Features of the evaluation batch (using the base model)</p>
+ </li>
+ <li>
+ <p><em>v</em> - parameters of the linear regression model (learned on train batch)</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="practical-considerations">Practical Considerations</h2>
+
+<ul>
+ <li>
+ <p>Meta gradients are approximated using truncated backdrop through time.</p>
+ </li>
+ <li>
+ <p>Increasing variation in the training dataset helps the meta optimization process. Data is augmented with shifts, rotations, and noise. Predicting these coefficients is an auxiliary (regression) task for training the meta-objective.</p>
+ </li>
+ <li>
+ <p>Training the system requires a lot of resources - 8 days with 512 workers.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>With standard unsupervised learning, the performance (on transfer task) starts declining after some time even though the performance (on the unsupervised task) is improving. This suggests that the objective function for the two tasks starts to mismatch.</p>
+ </li>
+ <li>
+ <p><em>UnsupervisedUpdate</em> leads to a better generalization as compared to both VAE and supervised learning (followed by transfer).</p>
+ </li>
+ <li>
+ <p><em>UnsupervisedUpdate</em> also leads to a positive transfer across domains (vision to language) when trained for a shorter duration of time (to ensure that the meta-objective does not overfit).</p>
+ </li>
+ <li>
+ <p><em>UnsupervisedUpdate</em> also generalizes to larger model architectures and different activation functions.</p>
+ </li>
+</ul>
+
+
+
+
+ GNN Explainer - A Tool for Post-hoc Explanation of Graph Neural Networks
+
+ 2019-03-26T00:00:00-04:00
+ /site/2019/03/26/GNN Explainer - A Tool for Post-hoc Explanation of Graph Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Graph Neural Network (GNN) is a family of powerful machine learning (ML) models for graphs that can combine node information with the structural information.</p>
+ </li>
+ <li>
+ <p>One downside of GNNs is that their predictions are hard to interpret.</p>
+ </li>
+ <li>
+ <p>The paper proposes GNN Explainer model for solving the problem of interpretability.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1903.03894">Paper</a></p>
+ </li>
+</ul>
+
+<h2 id="desiderata-for-gnn-explanations">Desiderata for GNN explanations</h2>
+
+<ul>
+ <li>
+ <p><strong>Local edge fidelity</strong> - identify the subgraph structure (ideally the smallest) that significantly affected the predictions of the GNN. ie identify the important edges in the graph (for a given prediction).</p>
+ </li>
+ <li>
+ <p><strong>Local node fidelity</strong> - identify the import node features and correlations in the features of the neighboring nodes.</p>
+ </li>
+ <li>
+ <p><strong>Single instance and multi-instance explanations</strong> - Support both single instance prediction tasks and multi-instance prediction tasks.</p>
+ </li>
+ <li>
+ <p><strong>Model Agnostic</strong> - Support a large family of models (ideally all)</p>
+ </li>
+ <li>
+ <p><strong>Task Agnostic</strong> - Support a large family of tasks (ideally all)</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>I first describe the single instance prediction case and use that as the base to describe the multiple instance prediction cases. All the discussion in this section assumes a single instance prediction task.</p>
+ </li>
+ <li>
+ <p><strong>Input</strong>: Trained GNN, a single instance whose prediction is to be explained.</p>
+ </li>
+ <li>
+ <p><strong>Task</strong>: Identify the small subgraph and the small subset of features that explain the prediction.</p>
+ </li>
+ <li>
+ <p><strong>Idea</strong>: Maximize the mutual information (MI) between the GNN and the explanation by learning a <em>graph mask</em> which can be used for selecting the relevant subgraph (from the GNN’s computational graph) and features (from all layers of the GNN).</p>
+ </li>
+ <li>
+ <p>Computational graph of GNN (corresponding to a node) refers to the approx L-hop neighborhood of the node in the graph ie the subgraph formed by nodes and edges whose representation affected the representation of the given node.</p>
+ </li>
+</ul>
+
+<h3 id="single-instance-explanations">Single-Instance Explanations</h3>
+
+<ul>
+ <li>
+ <p>For a node <em>v</em>, the information used to predict its label <em>y</em> is completely described by its computation graph <em>G<sub>c</sub>(v)</em> and the associated feature set <em>X<sub>c</sub>(v)</em>. The feature set includes the features of all the nodes in the computation graph.</p>
+ </li>
+ <li>
+ <p>When constructing the explaination, only <em>G<sub>c</sub>(v)</em> and <em>X<sub>c</sub>(v)</em> are used.</p>
+ </li>
+ <li>
+ <p>The task can be reformulated as identifying a subgraph <em>G<sub>S</sub></em> (subset of <em>G<sub>c</sub>(v)</em>) with associated features <em>X<sub>S</sub></em> which are important when predicting the label <em>y</em> for node <em>v</em>.</p>
+ </li>
+ <li>
+ <p>“Importance” is measured in terms of MI</p>
+ </li>
+</ul>
+
+<p><em>MI(Y, (G<sub>S</sub>, X<sub>S</sub>)) = H(Y) - H(Y | G = G<sub>S</sub>, X = X<sub>S</sub>)</em> where <em>H</em> is the entropy and <em>Y</em> is a random variable representing the prediction.</p>
+
+<ul>
+ <li>
+ <p>A further constraint, <em>| G<sub>S</sub>| < k</em> is imposed to obtain consise explaintations.</p>
+ </li>
+ <li>
+ <p>Since <em>H(Y)</em> is fixed (recall that the network has already been trained and is now being used in the inference mode), maximizing MI is equivalent to minimizing the conditional entropy <em>H(Y | G = G<sub>S</sub>, X = X<sub>S</sub>)</em></p>
+ </li>
+ <li>
+ <p>This is equivalent to selecting the subgraph that minimizes the uncertainty in the prediction of <em>y</em> when the computational graph is <em>G<sub>c</sub>(v)</em></p>
+ </li>
+</ul>
+
+<h4 id="optimiation-process">Optimiation Process</h4>
+
+<ul>
+ <li>
+ <p>Given the exponentially large number of possible subgraphs, we can not directly optimize the given equation.</p>
+ </li>
+ <li>
+ <p>A “relaxed”-adjacency matrix (whose values are real numbers in the range 0 to 1) is introduced where each element of this fractional adjacency matrix is smaller than the corresponding element of the original adjacency matrix. Gradient descent can be performed on this adjacency matrix.</p>
+ </li>
+ <li>
+ <p>The “relaxed” <em>G<sub>S</sub></em> can be interpreted as a variational approximation of the subgraph distributions of <em>G<sub>c</sub>(v)</em> and the objective can be written as <em>min E<sub>G<sub>S</sub></sub>H(Y | G = G<sub>S</sub>, X = X<sub>S</sub>)</em></p>
+ </li>
+ <li>
+ <p>Now the paper makes a big approximation that the GNN is convex so as to leverage the Jensen inequality and push the expectation inside the entropy term to get an upper bound and then minimize that ie <em>min H(Y | G = E<sub>s</sub>[G<sub>S</sub>], X = X<sub>S</sub>)</em></p>
+ </li>
+ <li>
+ <p>The paper reports that the convexity approximation (along with discreteness constraint) works in practice.</p>
+ </li>
+ <li>
+ <p>Next, mean field approximation is used to decompose <em>P(G<sub>S</sub>)</em> as a multivariate Bernoulli distrbitution ie product of <em>A<sub>S</sub>(i, j)</em> for all <em>(i, j)</em> belonging to <em>G<sub>c</sub>(v)</em>. <em>A<sub>S</sub></em> can be optimized directly and its values represent the expectation of the Bernoulli distrbitution on wether the edge <em>e<sub>i, j</sub></em> exists.</p>
+ </li>
+ <li>
+ <p>Given the constraints on <em>A<sub>S</sub></em>, it is easier to learn a mask matrix <em>M</em> and optimize that such that <em>A<sub>S</sub></em> = M * A<sub>c</sub>* Additionally, the sigmod operator can be applied on <em>M</em>.</p>
+ </li>
+ <li>
+ <p>Once <em>M</em> is learned, only the top <em>k</em> values are retained.</p>
+ </li>
+</ul>
+
+<h4 id="including-node-features-in-the-explanation">Including Node Features in the Explanation</h4>
+
+<ul>
+ <li>
+ <p>Similar to the previous approach, another feature mask is learned (either one for entire GNN or one per node of the GNN) and is used as a feature selector.</p>
+ </li>
+ <li>
+ <p>The mask could either be learned such that same set of node features (in terms of dimensions) are selected or a different set of features are selected per node. The paper uses the former as it is more straightforward.</p>
+ </li>
+ <li>
+ <p>Just like before, a “relaxed” mask <em>M<sub>T</sub></em> is trained to select features as <em>M<sub>T</sub> * X<sub>S</sub></em>.</p>
+ </li>
+ <li>
+ <p>One tricky case is where one feature is important but its value is set to 0. In the case, the value will be masked even though it should not be</p>
+ </li>
+ <li>
+ <p>The workaround is to use Monte Carlo (MC) estimates of marginals of the missing features. This gives a way to assign importance scores to each feature dimension and a form of reparameterization trick is used to perform end-to-end learning.</p>
+ </li>
+ <li>
+ <p>Masks are encouraged to be discrete by regularizing their element-wise entropy.</p>
+ </li>
+ <li>
+ <p>Resulting computation graph is valid as in it allows message passing towards the central node <em>v</em>.</p>
+ </li>
+</ul>
+
+<h2 id="multi-instance-explanations">Multi-Instance Explanations</h2>
+
+<ul>
+ <li>
+ <p>Given a set of nodes (having the label say <em>y</em>), the task is to obtain a global explanation of the predictions.</p>
+ </li>
+ <li>
+ <p>For the given class, a prototypical reference node is chosen by computing the mean of embeddings of all the nodes in the class and then selecting the node which is closest to the mean.</p>
+ </li>
+ <li>
+ <p>Now, compute the important computational graph corresponding to this node and align the computational subgraphs of all the other nodes (in the given class) to reference.</p>
+ </li>
+ <li>
+ <p>Let <em>A*</em> be the adjacency matrix and <em>X*</em> be the feature matrix for the explanation corresponding to the reference node. Let <em>A<sub>v</sub></em> and <em>X<sub>v</sub></em> be the adjacency matrix and feature matrix of the to-ber-aligned computational graph.</p>
+ </li>
+ <li>
+ <p>A relaed alignment matrix <em>P</em> is optimized to align the nodes and features in the two graphs ie we minimize <em>|P<sup>T</sup>A<sub>v</sub>P - A*| + *|P<sup>T</sup>X<sub>v</sub>P - X*|</em></p>
+ </li>
+ <li>
+ <p>Choosing concise explanations helps in efficient graph matching.</p>
+ </li>
+ <li>
+ <p>For GNNs that compute attention over the entire graph, edges with low attention weight can be pruned to increase efficiency.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Datasets</p>
+
+ <ul>
+ <li>
+ <p>Node classification: BA-Shapes, BA-Community, Tree-Cycles, Tree-Grid</p>
+ </li>
+ <li>
+ <p>Graph classification: MUTAG, Reddit-Binary</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Baselines</p>
+
+ <ul>
+ <li>
+ <p>GRAD - Compute the gradient of the model loss with respect to the adjacency matrix and the node features to be classified and fix the edges with the highest absolute gradient.</p>
+ </li>
+ <li>
+ <p>GAT - Graph Attention Network</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The proposed model seems to outperform the baselines both qualitatively and quantitatively. But the results should be taken with a grain of salt as only 2 baselines are considered.</p>
+ </li>
+</ul>
+
+
+
+
+ To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks
+
+ 2019-03-16T00:00:00-04:00
+ /site/2019/03/16/To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks
+ <ul>
+ <li>
+ <p><a href="https://arxiv.org/abs/1903.05987">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>The paper provides useful empirical advice for adapting pretrained language models for a given target task.</p>
+ </li>
+ <li>
+ <p>Pre-trained models considered</p>
+
+ <ul>
+ <li>
+ <p>ELMo</p>
+ </li>
+ <li>
+ <p>BERT</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Tasks considered</p>
+
+ <ul>
+ <li>
+ <p>Named Entity Recognition (NER) - CoNLL 2003 dataset</p>
+ </li>
+ <li>
+ <p>Sentiment Analysis (SA) - Stanford Sentiment Treebank (SST-2) dataset</p>
+ </li>
+ <li>
+ <p>Natural Language Inference (NLI) - MultiNLI and Sentences Involving Compositional Knowledge (SICK-E) dataset</p>
+ </li>
+ <li>
+ <p>Paraphrase Detection (PD) - Microsoft Research Paraphrase Corpus (MRPC)</p>
+ </li>
+ <li>
+ <p>Semantic Textual Similarity (STS) - Semantic Textual Similarity Benchmark (STS-B) and SICK-R</p>
+ </li>
+ <li>
+ <p>The last 3 tasks (NLI, PD, STS) are defined for sentence pairs.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Adaptation Strategies</p>
+
+ <ul>
+ <li>
+ <p>Feature Extraction</p>
+
+ <ul>
+ <li>
+ <p>The pretrained model is only used for extracting features and its weights are kept fixed.</p>
+ </li>
+ <li>
+ <p>For both ELMo and BERT, the contextual representation of the words from all the layers are extracted.</p>
+ </li>
+ <li>
+ <p>A weighted combination of these layers is used as an input to the task-specific model.</p>
+ </li>
+ <li>
+ <p>Task-specific models</p>
+
+ <ul>
+ <li>
+ <p>NER - BiLSTM with CRF layer</p>
+ </li>
+ <li>
+ <p>SA - bi-attentive classification network</p>
+ </li>
+ <li>
+ <p>NLI, PD, STS - <a href="https://arxiv.org/abs/1609.06038">Enhanced Sequential Inference Model (ESIM)</a></p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Fine-tuning</p>
+
+ <ul>
+ <li>
+ <p>The pretrained model is finetuned on the target task.</p>
+ </li>
+ <li>
+ <p>Task-specific models for ELMO</p>
+
+ <ul>
+ <li>
+ <p>NER - CRF on top of LSTM states</p>
+ </li>
+ <li>
+ <p>SA - Max-pool over the language model states followed by a softmax layer</p>
+ </li>
+ <li>
+ <p>NLI, PD, STS - cross sentence bi-attention between the language model states followed by pooling and softmax layer.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Task-specific models for BERT</p>
+
+ <ul>
+ <li>
+ <p>NER - Extract representation of the first-word piece of each token followed by the softmax layer</p>
+ </li>
+ <li>
+ <p>SA, NLI, PD, STS - standard BERT training</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Main observations</p>
+
+ <ul>
+ <li>
+ <p>Feature extraction and fine-tuning have comparable performance in most cases unless the two tasks are highly similar(fine-tuning is better) or highly dissimilar (feature extraction is better).</p>
+ </li>
+ <li>
+ <p>For ELMo, feature extraction consistently outperforms fine-tuning for the sentence pair tasks (NLI, PD, STS). The reverse trend is observed for BERT with fine-tuning being better on sentence pair tasks.</p>
+ </li>
+ <li>
+ <p>Adding extra parameters is helpful for feature extraction but not fine-tuning.</p>
+ </li>
+ <li>
+ <p>ELMo fine-tuning requires careful tuning and other tricks like triangular learning rates, gradual unfreezing and discriminative fine-tuning.</p>
+ </li>
+ <li>
+ <p>For the tasks considered, there is no correlation observed between the distance of the source and target domains and adaptation performance.</p>
+ </li>
+ <li>
+ <p>Training a diagnostic classifier (on the intermediate representations) suggests that fine-tuning improves the performance of the classifier at all the intermediate layers (which is sort of expected).</p>
+ </li>
+ <li>
+ <p>In terms of mutual information estimates, fine-tuned representations have a much higher mutual information as compared to the feature extraction based representations.</p>
+ </li>
+ <li>
+ <p>Knowledge for single sentence tasks seems to be mostly concentrated in the last layers while for pair classification tasks, the knowledge seems gradually build un in the intermediate layers, all the way up to the last layer.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Model Primitive Hierarchical Lifelong Reinforcement Learning
+
+ 2019-03-12T00:00:00-04:00
+ /site/2019/03/12/Model Primitive Hierarchical Lifelong Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a framework that uses diverse suboptimal world models that can be used to break complex policies into simpler and modular sub-policies.</p>
+ </li>
+ <li>
+ <p>Given a task, both the sub-policies and the controller are simultaneously learned in a bottom-up manner.</p>
+ </li>
+ <li>
+ <p>The framework is called as Model Primitive Hierarchical Reinforcement Learning (MPHRL).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1903.01567">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="idea">Idea</h2>
+
+<ul>
+ <li>
+ <p>Instead of learning a single transition model of the environment (aka <em>world model</em>) that can model the transitions very well, it is sufficient to learn several (say <em>k</em>) suboptimal models (aka <em>model primitives</em>).</p>
+ </li>
+ <li>
+ <p>Each <em>model primitive</em> will be good in only a small part of the state space (aka <em>region of specialization</em>).</p>
+ </li>
+ <li>
+ <p>These <em>model primitives</em> can then be used to train a gating mechanism for selecting sub-policies to solve a given task.</p>
+ </li>
+ <li>
+ <p>Since these <em>model primitives</em> are sub-optimal, they are not directly used with model-based RL but are used to obtain useful functional decompositions and sub-policies are trained with model-free approaches.</p>
+ </li>
+</ul>
+
+<h2 id="single-task-learning">Single Task Learning</h2>
+
+<ul>
+ <li>
+ <p>A gating controller is trained to choose the sub-policy whose <em>model primitive</em> makes the best prediction.</p>
+ </li>
+ <li>
+ <p>This requires modeling <em>p(M<sub>k</sub> | s<sub>t</sub>, a<sub>t</sub>, s<sub>t+1</sub>)</em> where <em>p(M<sub>k</sub>)</em> denotes the probability of selecting the <em>k<sup>th</sup> model primitive</em>. This is hard to compute as the system does not have access to <em>s<sub>t+1</sub></em> and <em>a<sub>t</sub></em> at time <em>t</em> before it has choosen the sub-policy.</p>
+ </li>
+ <li>
+ <p>Properly marginalizing <em>s<sub>t+1</sub></em> and <em>a<sub>t</sub></em> would require expensive MC sampling. Hence an approximation is used and the gating controller is modeled as a categorical distribution - to produce <em>p(M<sub>k</sub> | s<sub>t</sub>)</em>. This is trained via a conditional cross entropy loss where the ground truth distribution is obtained from transitions sampled in a rollout.</p>
+ </li>
+ <li>
+ <p>The paper notes that technique is biased but reports that it still works for the downstream tasks.</p>
+ </li>
+ <li>
+ <p>The gating controller composes the sub-policies as a mixture of Gaussians.</p>
+ </li>
+ <li>
+ <p>For learning, PPO algorithm is used with each <em>model primitives</em> gradient weighted by the probability from the gating controller.</p>
+ </li>
+</ul>
+
+<h2 id="lifelong-learning">Lifelong Learning</h2>
+
+<ul>
+ <li>Different tasks could share common subtasks but may require a different composition of subtasks. Hence, the learned sub-policies are transferred across tasks but not the gating controller or the baseline estimator (from PPO).</li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Domains:</p>
+
+ <ul>
+ <li>
+ <p>Mujoco ant navigating different mazes.</p>
+ </li>
+ <li>
+ <p>Stacker arm picking up and placing different boxes.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Implementation Details:</p>
+
+ <ul>
+ <li>
+ <p>Gaussian subpolicies</p>
+ </li>
+ <li>
+ <p>PPO as the baseline</p>
+ </li>
+ <li>
+ <p>Model primitives are hand-crafted using the true next state provided by the environment simulator.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Single Task</p>
+
+ <ul>
+ <li>
+ <p>Only maze task is considered with the start position (of the ant) and the goal position is fixed.</p>
+ </li>
+ <li>
+ <p>Observation includes distance from the goal.</p>
+ </li>
+ <li>
+ <p>Forcing the agent to decompose the problem, when a more direct solution may be available, causes the sample complexity to increase on one task.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Lifelong Learning</p>
+
+ <ul>
+ <li>
+ <p>Maze</p>
+
+ <ul>
+ <li>
+ <p>10 random Mujoco ant mazes used as the task distribution.</p>
+ </li>
+ <li>
+ <p>MPHRL takes almost twice the number of steps (as compared to PPO baseline) to solve the first task but this cost gets amortized over the distribution and the model takes half the number of steps as compared to the baseline (summed over the 10 tasks).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Pick and Place</p>
+
+ <ul>
+ <li>
+ <p>8 Pick and Place tasks are created with max 3 goal locations.</p>
+ </li>
+ <li>
+ <p>Observation includes the position of the goal.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Ablations</p>
+
+ <ul>
+ <li>
+ <p>Overlapping <em>model primitives</em> can degrade the performance (to some extent). Similarly, the performance suffers when redundant primitives are introduced indicating that the gating mechanism is not very robust.</p>
+ </li>
+ <li>
+ <p>Sub-policies could quickly adapt to the previous tasks (on which they were trained initially) despite being finetuned on subsequent tasks.</p>
+ </li>
+ <li>
+ <p>The order of tasks (in the 10-Mazz task) does not degrage the performance.</p>
+ </li>
+ <li>
+ <p>Transfering the gating controller leads to negative transfer.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Notes</p>
+
+ <ul>
+ <li>I think the biggest strength of the work is that accurate dynamics model are not needed (which are hard to train anyways!) through the experimental results are not conclusive given the limited number of domains on which the approach is tested.</li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ TuckER - Tensor Factorization for Knowledge Graph Completion
+
+ 2019-02-19T00:00:00-05:00
+ /site/2019/02/19/TuckER-Tensor Factorization for Knowledge Graph Completion
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>TuckER is a simple, yet powerful linear model that uses Tucker decomposition for the task of link prediction in knowledge graphs.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1901.09590">Paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/ibalazevic/TuckER">Implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="knowledge-graph-as-a-tensor">Knowledge Graph as a Tensor</h2>
+
+<ul>
+ <li>
+ <p>Let E be the set of all the entities and R be the set of all the relations in a given knowledge graph (KG).</p>
+ </li>
+ <li>
+ <p>The KG can be represented as a list of triples of the form (source entity, relation, object entity) or (e<sub>s</sub>, r, e<sub>o</sub>).</p>
+ </li>
+ <li>
+ <p>The list of triples can be represented as a third-order tensor (of binary values) where each element corresponds to a triple and each element’s value corresponds to ether that element is present in the KG or not.</p>
+ </li>
+ <li>
+ <p>The link prediction task can be formulated as - given a set of all triples, learn a scoring function that assigns a score to each triple. The score indicates whether the triple is actually present in the KG or not.</p>
+ </li>
+</ul>
+
+<h2 id="tucker-decomposition">TuckER Decomposition</h2>
+
+<ul>
+ <li>
+ <p>Tucker decomposition factorizes a tensor into a set of factor matrices and a smaller core tensor.</p>
+ </li>
+ <li>
+ <p>In the specific case of three-mode tensors (alternate representation of a KG), the given original tensor <strong>X</strong> (of shape <em>IxJxK</em>) can be factorized into a core tensor <strong>W</strong> (of shape <em>PxQxR</em>) and 3 factor matrics - <strong>A</strong> (of shape <em>IxP</em>), <strong>B</strong> (of shape <em>JxQ</em>) and <strong>C</strong> (of shape <em>KxR</em>) such that <strong>X</strong> is approximately <strong>W</strong> x<sub>1</sub> <strong>A</strong> x<sub>2</sub> <strong>B</strong> x<sub>3</sub> <strong>C</strong>, where X<sub>n</sub> denotes the tensor product along the nth mode.</p>
+ </li>
+ <li>
+ <p>Generally, <em>P, Q, R</em> are smaller than <em>I, J K</em> (respectively) and <strong>W</strong> can be seen as a compressed version of <strong>X</strong>.</p>
+ </li>
+</ul>
+
+<h2 id="tucker-decomposition-for-link-prediction">TuckER Decomposition for Link Prediction</h2>
+
+<ul>
+ <li>
+ <p>Two embedding matrics are used for embedding the entities and the relations respectively.</p>
+ </li>
+ <li>
+ <p>Entity embedding matrix <strong>E</strong> is shared for both subject and the object ie <strong>E</strong> = <strong>A</strong> = <strong>B</strong>.</p>
+ </li>
+ <li>
+ <p>The scoring function is gives as <strong>W</strong> x<sub>1</sub> <strong>e<sub>s</sub></strong> x<sub>2</sub> <strong>w<sub>r</sub></strong> x<sub>3</sub> <strong>e<sub>0</sub></strong> where <strong>e<sub>s</sub></strong>, <strong>w<sub>r</sub></strong> and <strong>e<sub>o</sub></strong> are the embedding vectors corresonding to e<sub>s</sub>, e<sub>r</sub> and e<sub>o</sub> respectively. Note that both the core tensor and the factor matrices are to be learnt.</p>
+ </li>
+ <li>
+ <p>Model is trained with the standard negative log-likelihood loss given as (for one triple): y * log(p) + (1-y) * log(1-p)</p>
+ </li>
+ <li>
+ <p>To speed up training and increase accuracy, 1-N scoring is used. A given (e<sub>s</sub>, r) is simultaneously scored for all the entities using the local-closed world assumption (knowledge graph is only locally complete).</p>
+ </li>
+ <li>
+ <p>Handling asymmetric relations is straightforward by learning a relation embedding alongside a relation-agnostic core tensor which enables knowledge sharing across relations.</p>
+ </li>
+</ul>
+
+<h2 id="theoretical-analysis">Theoretical Analysis</h2>
+
+<ul>
+ <li>
+ <p>One important consideration would be the expressive power of TuckER models, especially in relation to other models like ComplEx and SimplE.</p>
+ </li>
+ <li>
+ <p>It can be shown the TuckER is fully expressive ie give any ground truth over E and R, there exists a TuckER model which can perfectly represent the data - using 1-hot entity and relation embedding.</p>
+ </li>
+ <li>
+ <p>For full expressiveness, dimensionality of entity (relation) is n<sub>E</sub> (n<sub>R</sub>) where n<sub>E</sub> (n<sub>R</sub>) are the number of entities (relations). In comparsion, the required dimensionality for ComplEx is n<sub>E</sub> * n<sub>R</sub> (for both entity and relations) and for SimplE, it is min(<sub>E</sub> * n<sub>R</sub>, number of facts + 1) (for both entity and relations).</p>
+ </li>
+ <li>
+ <p>Many existing models like RESCAL, DistMult, ComplEx, SimplE etc can be seen as special cases of TuckER.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="datasets">Datasets</h3>
+
+<ul>
+ <li>
+ <p>FB15k, FB15k-237, WN18, WN18RR</p>
+ </li>
+ <li>
+ <p>The max number of entities is around 41K and max number of relations is around 1.3K</p>
+ </li>
+</ul>
+
+<h3 id="implementation">Implementation</h3>
+
+<ul>
+ <li>BatchNorm, Dropout and Learning rate decay are used.</li>
+</ul>
+
+<h3 id="metrics">Metrics</h3>
+
+<ul>
+ <li>
+ <p>Mean Reciprocal Rank (MRR) - the average of the inverse of mean rank assigned to the true triple overall n<sub>e</sub> generated triples.</p>
+ </li>
+ <li>
+ <p>hits@k (k = 1, 3, 10) - percentage of times the true triple is ranked in the top k of the n<sub>e</sub> generated triples.</p>
+ </li>
+ <li>
+ <p>Higher is better for both the metrics.</p>
+ </li>
+</ul>
+
+<h3 id="results">Results</h3>
+
+<ul>
+ <li>
+ <p>TuckER outperforms all the baseline models on all but one task.</p>
+ </li>
+ <li>
+ <p>Dropout is an important factor with higher dropout rates (0, 3, 0.4, 0.5) needed for datasets with fewer training examples per relation (hence more prone to overfitting).</p>
+ </li>
+ <li>
+ <p>TuckER improves performance more significantly when the number of relations is large.</p>
+ </li>
+ <li>
+ <p>Even with lower embedding dimensions, TuckER’s performance does not deteriorate as much as other models.</p>
+ </li>
+</ul>
+
+
+
+
+ Linguistic Knowledge as Memory for Recurrent Neural Networks
+
+ 2019-02-05T00:00:00-05:00
+ /site/2019/02/05/Linguistic Knowledge as Memory for Recurrent Neural Networks
+ <ul>
+ <li>
+ <p><a href="https://arxiv.org/abs/1703.02620">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>Training RNNs to model long term dependencies is difficult but in some cases, the information about dependencies between elements (of the sequence) may be present in the form of symbolic knowledge.</p>
+ </li>
+ <li>
+ <p>For example, when encoding sentences, coreference, and hypernymy relations can be extracted between tokens.</p>
+ </li>
+ <li>
+ <p>These elements(tokens) can be connected with each other with different kind of edges resulting in the graph data structure.</p>
+ </li>
+ <li>
+ <p>One approach could be to model this knowledge(encoded in the graph) using a graph neural network (GNN).</p>
+ </li>
+ <li>
+ <p>The authors prefer to encode the information into 2 DAGs (via topological sorting) as training the GNN could add some extra overhead.</p>
+ </li>
+ <li>
+ <p>This results into the Memory as Acyclic Graph Encoding RNN (MAGE-RNN) architecture. Its GRU version is referred to as MAGE-GRU.</p>
+ </li>
+ <li>
+ <p>Given an input sequence of tokens [x<sub>1</sub>, x<sub>2</sub>, …, x<sub>T</sub>] and information about which tokens relate to other tokens, a graph G is constructed with different (possibly typed) edges.</p>
+ </li>
+ <li>
+ <p>Given the graph <em>G</em>, two DFS orderings are computed - forward DFS and backward DFS.</p>
+ </li>
+ <li>
+ <p>MAGE-RNN uses separate networks for accessing the forward and backward DFS orders.</p>
+ </li>
+ <li>
+ <p>A separate hidden state is maintained for each entity type to separate memory content from addressing.</p>
+ </li>
+ <li>
+ <p>For any DFS order (forward or backward), the representation at time <em>t</em> is given as the concatenation of representation of different edge types at that time.</p>
+ </li>
+ <li>
+ <p>The hidden states (for different edge types at time t) are updated in the topological order using the current state of all incoming edges at x<sub>t</sub>.</p>
+ </li>
+ <li>
+ <p>The representation of the DFS order is given as the sequence of all the previous representations.</p>
+ </li>
+ <li>
+ <p>In some cases, elements across multiple sequences could be related to each other. In that case, the graph is decomposed into a collection of DAGs and use MAGE-GRU on the DAGs by taking one random permutation of the sequences and decomposing it into the forward and the backward graphs.</p>
+ </li>
+ <li>
+ <p>The model is evaluated on the task of text comprehension with coreference on bAbi dataset (story based QA), LAMBADA dataset (broad context language modeling) and CNN dataset (cloze-style QA).</p>
+ </li>
+ <li>
+ <p>MAGE-GRU was used as a replacement for GRU units in bi-directional GRUs and GA-Reader architecture.</p>
+ </li>
+ <li>
+ <p>DAG-RNN and shared version of MAGE-GRU (with shared edge types) are the other baselines.</p>
+ </li>
+ <li>
+ <p>For all the cases, the model with MAGE-GRU works the best.</p>
+ </li>
+</ul>
+
+
+
+
+ Diversity is All You Need - Learning Skills without a Reward Function
+
+ 2019-01-29T00:00:00-05:00
+ /site/2019/01/29/Diversity is All You Need - Learning Skills without a Reward Function
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes an approach to learn useful skills without a reward function by maximizing an information theoretic objective by using a maximum entropy policy.</p>
+ </li>
+ <li>
+ <p>Skills are defined as latent-conditioned policies that alter the state of the environment in a consistent way.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1802.06070">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/ben-eysenbach/sac">Link to the code</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>Unsupervised “exploration” stage followed by supervised stage.</li>
+</ul>
+
+<h2 id="desirable-qualities-of-skills">Desirable Qualities of Skills</h2>
+
+<ul>
+ <li>
+ <p>Skills should dictate the states that the agent visits. Different skills should visit different states to be distinguishable.</p>
+ </li>
+ <li>
+ <p>States (not actions) should be used to distinguish between skills as not all actions change the state (for the outside observer).</p>
+ </li>
+ <li>
+ <p>Skills are encouraged to be diverse and “exploratory” by learning skills that act randomly (have high entropy).</p>
+ </li>
+</ul>
+
+<h2 id="loss-formulation">Loss Formulation</h2>
+
+<ul>
+ <li>
+ <p>(S, A) - state and action</p>
+ </li>
+ <li>
+ <p>z ~ p(z) - latent variable to condition the policy.</p>
+ </li>
+ <li>
+ <p>Skill - policy conditioned on a fixed z.</p>
+ </li>
+ <li>
+ <p>Objective is to maximize the mutual information between skill and state (MI(A; Z)) ie skill should control which state is visited or the skill should be inferrable from the state visited.</p>
+ </li>
+ <li>
+ <p>Simultaneously minimize the mutual information between skills and actions given the state to ensure that the state (and not the action) is used to distinguish the skills.</p>
+ </li>
+ <li>
+ <p>Maximize the entropy of the mixture of policies (p(z) and all the skills).</p>
+ </li>
+</ul>
+
+<h2 id="implementation">Implementation</h2>
+
+<ul>
+ <li>
+ <p>Policy π(a | s, z)</p>
+ </li>
+ <li>
+ <p>Task reward replaced by the pseduoreward logq<sub>φ</sub>(z | s) - log(p(z)).</p>
+ </li>
+ <li>
+ <p>During unsupervised training, z is sampled at the start of the episode and then not changed during the episode.</p>
+ </li>
+ <li>
+ <p>Learning agent gets rewards for visiting the states that are easy to discriminate while the discriminator updated to correctly predict z from the states visited.</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<h3 id="analysis-of-learned-skills">Analysis of Learned Skills</h3>
+
+<ul>
+ <li>
+ <p>The agent learns a diverse set of primitive behaviors for all tasks ranging from 2 DoF to 111 DoF.</p>
+ </li>
+ <li>
+ <p>for inverted pendulum and mountain car, the skills become increasingly diverse throughout training.</p>
+ </li>
+ <li>
+ <p>Use of uniform prior, in place of a learned prior, for p(z) allows for discovery of more diverse skills.</p>
+ </li>
+ <li>
+ <p>The proposed approach can be used as a pretraining technique where the best-performing primitives (from unsupervised training) can be finetuned with the task-specific rewards.</p>
+ </li>
+ <li>
+ <p>The discovered skills can be used for hierarchical RL by learning a meta-policy(which chooses the skill to execute for k steps).</p>
+ </li>
+ <li>
+ <p>Modifying the discriminator in the proposed formulation can be used to bias DIAYN towards discovering a particular type of policies. This provides a mechanism for incorporating “supervision” in the learning setup.</p>
+ </li>
+ <li>
+ <p>The “discovered” primitives can also be used for imitation learning.</p>
+ </li>
+</ul>
+
+
+
+
+ Modular meta-learning
+
+ 2019-01-22T00:00:00-05:00
+ /site/2019/01/22/Modular meta-learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes an approach for learning neural networks (modules) that can be combined in different ways to solve different tasks (combinatorial generalization).</p>
+ </li>
+ <li>
+ <p>The proposed model is called as BOUNCEGRAD.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1806.10166">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/FerranAlet/modular-metalearning">Link to the code</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Focuses on supervised learning.</p>
+ </li>
+ <li>
+ <p>Task distribution <em>p(T)</em>.</p>
+ </li>
+ <li>
+ <p>Each task is a joint distribution <em>p<sub>T</sub>(x, y)</em> over <em>(x, y)</em> data pairs.</p>
+ </li>
+ <li>
+ <p>Given data from <em>m</em> meta-training tasks, and a meta-test task, find a hypothesis <em>h</em> which performs well on the unseen data drawn from the meta-test task.</p>
+ </li>
+</ul>
+
+<h2 id="structured-hypothesis">Structured Hypothesis</h2>
+
+<ul>
+ <li>
+ <p>Given a compositional scheme <em>C</em>, a set of modules <em>F<sub>1</sub>, …, F<sub>k</sub></em> (represented as a whole by <em>F</em>) and the set of their respective parameters θ<sub>1</sub>, …, θ<sub>k</sub> (represented as a whole by θ), <em>(C, F, θ)</em> represents the set of possible functional input-output mappings. These mappings form the hypothesis space.</p>
+ </li>
+ <li>
+ <p>A structured hypothesis model is specified by what modules to use and their parametric forms (but not the values).</p>
+ </li>
+</ul>
+
+<h3 id="examples-of-compositional-schemes">Examples of compositional schemes</h3>
+
+<ul>
+ <li>
+ <p>Choosing a single module for the task at hand.</p>
+ </li>
+ <li>
+ <p>Fixed compositional structure but different modules selected every time.</p>
+ </li>
+ <li>
+ <p>Weight ensemble (maybe using attention mechanism)</p>
+ </li>
+ <li>
+ <p>General function composition tree</p>
+ </li>
+</ul>
+
+<h3 id="phases">Phases</h3>
+
+<ul>
+ <li>
+ <p>Offline Meta Learning Phase:</p>
+
+ <ul>
+ <li>
+ <p>Take training and validation dataset for the first <em>k</em> tasks and generate a parameterization for each module <em>θ<sub>1</sub>, …, θ<sub>k</sub></em>.</p>
+ </li>
+ <li>
+ <p>The hypothesis (or composition) to use comes from the online meta-test learning phase.</p>
+ </li>
+ <li>
+ <p>In this stage, find the best θ given a structure.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Online Meta-test Learning Phase</p>
+
+ <ul>
+ <li>
+ <p>Given a hypothesis space and θ, the output is a compositional form (or hypothesis) that specifies how to compose the models.</p>
+ </li>
+ <li>
+ <p>In this stage, find the best structure, given a hypothesis space and θ.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="learning-algorithm">Learning Algorithm</h2>
+
+<ul>
+ <li>
+ <p>During Meta-test learning phase, simulated annealing is used to find the optimal structure, with temperature <em>T</em> decreased over time.</p>
+ </li>
+ <li>
+ <p>During meta-learning phrase, the actual objective function is replaced by a surrogate, smooth objective function (during the search step) to avoid local minima.</p>
+ </li>
+ <li>
+ <p>Once a structure has been picked, any gradient descent based approach can be used to optimize the modules.</p>
+ </li>
+ <li>
+ <p>Basically the state of optimization process comprises of the parameters and the temperature. Together, they are used to induce a distribution over the structures. Given a structure, θ is optimized and <em>T</em> is annealed over time.</p>
+ </li>
+ <li>
+ <p>The learning procedure can be improved upon by performing parameter tuning during the online (meta-test learning) phase as well. the resulting approach is referred to as MOMA - MOdular MAml.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="approaches">Approaches</h3>
+
+<ul>
+ <li>
+ <p>Pooled - Single network using combined data of all the tasks.</p>
+ </li>
+ <li>
+ <p>MAML - Single network using MAML</p>
+ </li>
+ <li>
+ <p>BOUNCEGRAD - Modular Network without MAML adaptation in online learning.</p>
+ </li>
+ <li>
+ <p>MOMA - BOUNCEGRAD with MAML adaptation in online learning.</p>
+ </li>
+</ul>
+
+<h3 id="domains">Domains</h3>
+
+<h4 id="simple-functional-relationships">Simple Functional Relationships</h4>
+
+<ul>
+ <li>
+ <p>Sine-function prediction problem</p>
+ </li>
+ <li>
+ <p>In general, MOMA outperforms other models.</p>
+ </li>
+ <li>
+ <p>With a small amount of online training data, BOUNCEGRAD outperforms other models as it has a better structural prior.</p>
+ </li>
+</ul>
+
+<h4 id="predicting-next-frame-of-a-kinematic-skeleton-motion-capture-data">Predicting next frame of a kinematic skeleton (motion capture data)</h4>
+
+<ul>
+ <li>
+ <p>11 different objects (with different shapes) on 4 surfaces with different friction properties.</p>
+ </li>
+ <li>
+ <p>2 meta-learning scenarios are considered. In the first case, the object-surface combination in the test case was present in some meta-training tasks and in the other case, it was not present.</p>
+ </li>
+ <li>
+ <p>For previously seen combinations, MOMA performs the best followed by BOUNCEGRAD and MAML.</p>
+ </li>
+ <li>
+ <p>For unseen combinations, all the 3 are equally good.</p>
+ </li>
+ <li>
+ <p>Compositional scheme is the attention mechanism.</p>
+ </li>
+ <li>
+ <p>An interesting result is that the modules seem to specialize (and activate more often) based on the shape of the object.</p>
+ </li>
+</ul>
+
+<h3 id="predicting-next-frame-of-a-kinematic-selection-using-motion-capture-data">Predicting next frame of a kinematic selection (using motion capture data)</h3>
+
+<ul>
+ <li>
+ <p>Composition Structure - generating kinematics subtrees for each body part (2 legs, 2 arms, 2 torsi).</p>
+ </li>
+ <li>
+ <p>Again 2 setups are used - one where all activities in the training and the meta-test task are shared while the other setup where the activities are not shared.</p>
+ </li>
+ <li>
+ <p>For known activities MOMA and BOUNCEGRAD perform the best while for unknown activities, MOMS performs the best.</p>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<ul>
+ <li>
+ <p>While the approach is interesting, maybe a more suitable set of tasks (from the point of composition) would be more convincing.</p>
+ </li>
+ <li>
+ <p>It would be useful to see the computational tradeoff between MAML, BOUNCEGRAD, and MOMA.</p>
+ </li>
+</ul>
+
+
+
+
+ Hierarchical RL Using an Ensemble of Proprioceptive Periodic Policies
+
+ 2019-01-15T00:00:00-05:00
+ /site/2019/01/15/Hierarchical RL Using an Ensemble of Proprioceptive Periodic Policies
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a simple and robust approach for hierarchically training an agent in the sparse reward setup.</p>
+ </li>
+ <li>
+ <p>The broad idea is to train low-level primitives that are sufficiently diverse (so that they can be composed for solving higher level tasks) and to train a high level primitive that learns to combine these primitives for any given downstream task.</p>
+ </li>
+ <li>
+ <p><a href="https://openreview.net/forum?id=SJz1x20cFQ">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>The state can be divided into two components: proprioceptive states s<sup>p</sup> (measurement of agent’s own body that can be directly controlled by the agent) and the external states s<sup>e</sup>/</li>
+</ul>
+
+<h3 id="low-level-policy-training">Low-Level Policy Training</h3>
+
+<ul>
+ <li>
+ <p>Low-level policies should be:</p>
+
+ <ul>
+ <li>Diverse: should cover all the skills that the agent might have to perform.</li>
+ <li>Effective: can make significant changes to the environment.</li>
+ <li>Controllable: easy for high-level policies to use and control</li>
+ </ul>
+ </li>
+ <li>
+ <p>For the low-level policy, the per-time step reward is directly proportional to change in the external state. The same reward is used for all the agents and environments(except regulated with environment specific controls and survival rewards).</p>
+ </li>
+</ul>
+
+<h3 id="phase-conditioned-policies">Phase conditioned policies</h3>
+
+<ul>
+ <li>
+ <p>Good movement policies are expected to be at least roughly periodic and phase input (or time index) is used to achieve periodicity.</p>
+ </li>
+ <li>
+ <p>Phase conditioned policy (=f(s<sup>p</sup>, φ)) where φ = {0, 1, …, k-1} is the phase index.</p>
+ </li>
+ <li>
+ <p>At each timestep <em>t</em>, the model receives observation s<sup>p</sup> and phase index φ = t%k. The phase index is represented by a vector b<sub>φ</sub>.</p>
+ </li>
+ <li>
+ <p>For phase conditioned policies, the agent state and actions are encouraged to be cyclic with the help of a cyclic loss.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Environments: Ant and Humanoid from Mujoco.</p>
+ </li>
+ <li>
+ <p>Low-level control:</p>
+
+ <ul>
+ <li>Using phase-conditioning is helpful when training low-level primitives.</li>
+ </ul>
+ </li>
+ <li>
+ <p>High-level control:</p>
+
+ <ul>
+ <li>
+ <p>Cross Maze Environment with fixed goals</p>
+
+ <ul>
+ <li>
+ <p>3 goals along 3 paths</p>
+ </li>
+ <li>
+ <p>Proposed method converges faster and to a smaller final distance to the goal showing that it is both efficient and consistent (with smaller variance across random seeds).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Random Goal Maze</p>
+
+ <ul>
+ <li>
+ <p>The goal is randomly drawn from a set of goals.</p>
+ </li>
+ <li>
+ <p>“Cross” (shaped) maze and “skull” (shaped) mazes are considered.</p>
+ </li>
+ <li>
+ <p>Even with velocity rewards and pretraining on low-level objectives (which can be thought of as exploration bonuses), the baseline fails to get close to the goal locations while the proposed model reach the goal most of the times.</p>
+ </li>
+ <li>
+ <p>The main results are reported using PPO though repeating the experiments with A2C and DQN show that the idea is fairly robust.</p>
+ </li>
+ <li>
+ <p>The paper reported that in their experiments, finetuning the lower level primitives did not help much though it might not be the case of other environments.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Efficient Lifelong Learning with A-GEM
+
+ 2019-01-08T00:00:00-05:00
+ /site/2019/01/08/Efficient Lifelong Learning with A-GEM
+ <h2 id="contributions">Contributions</h2>
+
+<ul>
+ <li>
+ <p>A new (and more realistic) evaluation protocol for lifelong learning where each data point is observed just once and a disjoint set of tasks are used for training and validation.</p>
+ </li>
+ <li>
+ <p>A new metric that focuses on the efficiency of the models - in terms of sample complexity and computational (and memory) costs.</p>
+ </li>
+ <li>
+ <p>Modification of <a href="https://arxiv.org/abs/1706.08840">Gradient Episodic Memory ie GEM</a> which reduces the computational overhead of GEM without compromising on the results.</p>
+ </li>
+ <li>
+ <p>Empirical validation that using task descriptors help lifelong learning models and improve their few-shot learning capabilities.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1812.00420">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/facebookresearch/agem/">Link to the code</a></p>
+ </li>
+</ul>
+
+<h2 id="learning-protocol">Learning Protocol</h2>
+
+<ul>
+ <li>
+ <p>Two group of datasets - one for training and evaluation (D<sup>EV</sup>) and other for cross validation (D<sup>CV</sup>).</p>
+ </li>
+ <li>
+ <p>Data can be sampled multiple times for cross-validation dataset but only once from the training dataset.</p>
+ </li>
+ <li>
+ <p>Each group of dataset (say D<sup>EV</sup> or D<sup>CV</sup>) is a list of task-specific datasets D<sub>k</sub> (k is the task index).</p>
+ </li>
+ <li>
+ <p>Each sample in D<sub>k</sub> is of the form (x, t, y) where x is the data, t is the task descriptor and y is the output.</p>
+ </li>
+ <li>
+ <p>D<sub>k</sub> contains B<sup>k</sup> minibatches of data.</p>
+ </li>
+</ul>
+
+<h2 id="metrics">Metrics</h2>
+
+<h3 id="accuracy">Accuracy</h3>
+
+<ul>
+ <li>
+ <p>a<sub>k,i,j</sub> = accuracy on test task j after training on ith minibatch of training task k.</p>
+ </li>
+ <li>
+ <p>A<sub>k</sub> = mean over all j = 1 to k (a<sub>k, B<sub>k</sub>, j</sub>) ie train the model on data for task k and then test it on all the tasks.</p>
+ </li>
+</ul>
+
+<h3 id="forgetting-measure">Forgetting Measure</h3>
+
+<ul>
+ <li>
+ <p>f<sub>j</sub><sup>k</sup> = forgetting on task j after training on all minibatches upto task k.</p>
+ </li>
+ <li>
+ <p>f<sub>j</sub><sup>k</sup> = max over all l = 1 to k-1 (a<sub>l, B<sub>l</sub>j</sub> - a<sub>k, B<sub>k</sub>j</sub>)</p>
+ </li>
+ <li>
+ <p>Forgetting = F<sub>k</sub> = mean over all j = 1 to k-1 (f<sub>j</sub><sup>k</sup>)</p>
+ </li>
+</ul>
+
+<h3 id="lca---learning-curve-area">LCA - Learning Curve Area</h3>
+
+<ul>
+ <li>
+ <p>Z<sub>b</sub> = average b shot performance where b is the minibatch number.</p>
+ </li>
+ <li>
+ <p>Z<sub>b</sub> = mean over all k = 0 to T (a<sub>k, b, k</sub>)</p>
+ </li>
+ <li>
+ <p>LCA<sub>β</sub> = mean over all b = 0 to β (Z<sub>b</sub>)</p>
+ </li>
+ <li>
+ <p>One special case is LCA<sub>0</sub> which is the forward transfer performance or performance on the unseen task.</p>
+ </li>
+ <li>
+ <p>In experiments, β is kept small as we want the model to learn from few examples.</p>
+ </li>
+</ul>
+
+<h2 id="model">Model</h2>
+
+<ul>
+ <li>
+ <p>GEM has been shown to be very effective in single epoch setting but introduces a very high computational overhead.</p>
+ </li>
+ <li>
+ <p>Average GEM (AGEM) reduces this overhead by sampling (and using) only some examples from the episodic memory instead of using all the examples.</p>
+ </li>
+ <li>
+ <p>While GEM provides better guarantees in terms of worst-case forgetting, AGEM provides better guarantees in terms of average accuracy.</p>
+ </li>
+</ul>
+
+<h2 id="joint-embedding-model-using-compositional-task-descriptors">Joint Embedding Model Using Compositional Task Descriptors</h2>
+
+<ul>
+ <li>
+ <p>Compositional Task Descriptors are used to speed training on the subsequent tasks.</p>
+ </li>
+ <li>
+ <p>A matrix specifying the attribute value of objects (to be recognized in the task) are used.</p>
+ </li>
+ <li>
+ <p>A joint-embedding space between image features and attribute embeddings is learned.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="datasets">Datasets</h3>
+
+<ul>
+ <li>
+ <p><a href="https://arxiv.org/abs/1612.00796">Permuted MNIST</a></p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1703.04200">Split CIFAR</a></p>
+ </li>
+ <li>
+ <p><a href="http://www.vision.caltech.edu/visipedia/CUB-200-2011.html">Split CUB</a></p>
+ </li>
+ <li>
+ <p><a href="http://cvml.ist.ac.at/papers/lampert-cvpr2009.pdf">Split AWA</a></p>
+ </li>
+</ul>
+
+<h3 id="setup">Setup</h3>
+
+<ul>
+ <li>
+ <p>Integer task descriptors for MNIST and CIFAR and class attributes as descriptors for CUB and AWA</p>
+ </li>
+ <li>
+ <p>Baselines include <a href="https://arxiv.org/abs/1706.08840">GEM</a>, <a href="https://arxiv.org/abs/1611.07725">iCaRL</a>, <a href="https://arxiv.org/pdf/1612.00796.pdf">Elastic Weight Consolidation</a>, <a href="https://arxiv.org/abs/1606.04671">Progressive Neural Networks</a> etc.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>AGEM outperforms other models on all the datasets expect MNIST where the Progressive Neural Networks lead. One reason could be that MNIST has a large number of training examples per task. But Progressive Neural Networks lead to bad utilization of capacity.</p>
+ </li>
+ <li>
+ <p>While AGEM and GEM have similar performance, GEM has a much higher computational and memory overhead.</p>
+ </li>
+ <li>
+ <p>Use of task descriptors improves the accuracy for all the models.</p>
+ </li>
+ <li>
+ <p>It seems that AGEM offers a good tradeoff between average accuracy performance and efficiency - in terms of sample efficiency, memory requirements and computational costs.</p>
+ </li>
+</ul>
+
+
+
+
+ Pre-training Graph Neural Networks with Kernels
+
+ 2019-01-02T00:00:00-05:00
+ /site/2019/01/02/Pre-training Graph Neural Networks with Kernels
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes a pretraining technique that can be used with the <a href="https://shagunsodhani.in/papers-I-read/Neural-Message-Passing-for-Quantum-Chemistry">GNN</a> architecture for learning graph representation as induced by powerful graph kernels.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1811.06930">Paper</a></p>
+ </li>
+</ul>
+
+<h2 id="idea">Idea</h2>
+
+<ul>
+ <li>
+ <p>Graph Kernel methods can learn powerful representations of the input graphs but the learned representation is implicit as the kernel function actually computes the dot product between the representations.</p>
+ </li>
+ <li>
+ <p>GNNs are flexible and powerful in terms of the representations they can learn but they can easily overfit if a large amount of training data is not available as is commonly the case of graphs.</p>
+ </li>
+ <li>
+ <p>Kernel methods can be used to learn an unsupervised graph representation that can be finetuned using the GNN architectures for the supervised tasks.</p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>Given a dataset of graphs <em>g<sub>1</sub>, g<sub>2</sub>, …, g<sub>n</sub></em>, use a relevant kernel function to compute <em>k(g<sub>i</sub>, g<sub>j</sub>)</em> for all pairs of graphs.</p>
+ </li>
+ <li>
+ <p>A siamese network is used to encode the pair of graphs into representations <em>f(g<sub>i</sub>)</em> and <em>f(g<sub>j</sub>)</em> such that <em>dot(f(g<sub>i</sub>), f(g<sub>j</sub>))</em> equals <em>k(g<sub>i</sub>, g<sub>j</sub>)</em>.</p>
+ </li>
+ <li>
+ <p>The function <em>f</em> is trained to learn the compressed representation of kernel’s feature space.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="datasets">Datasets</h3>
+
+<ul>
+ <li>Biological node-labeled graphs representing chemical compounds - MUTAG, PTC, NCI1</li>
+</ul>
+
+<h3 id="baselines">Baselines</h3>
+
+<ul>
+ <li><a href="https://www.cse.wustl.edu/~muhan/papers/AAAI_2018_DGCNN.pdf">DGCNN</a></li>
+ <li>Graphlet Kernel (GK)</li>
+ <li>Random Walk Kernel</li>
+ <li>Propogation Kernel</li>
+ <li>Weisfeiler-Lehman subtree kernel (WL)</li>
+</ul>
+
+<h3 id="results">Results</h3>
+
+<ul>
+ <li>
+ <p>Pretraining uses the WL kernel</p>
+ </li>
+ <li>
+ <p>Pretrained model performs better than the baselines for 2 datasets but lags behind WL method (which was used for pretraining) for the NCI1 dataset.</p>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<ul>
+ <li>The idea is straightforward and intuitive. In general, this kind of pretraining should help the downstream model. It would be interesting to try it on more datasets/kernels/GNNs so that more conclusive results can be obtained.</li>
+</ul>
+
+
+
+
+ Smooth Loss Functions for Deep Top-k Classification
+
+ 2018-12-25T00:00:00-05:00
+ /site/2018/12/25/Smooth Loss Functions for Deep Top-k Classification
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>For top-k classification tasks, cross entropy is widely used as the learning objective even though it is the optimal metric only in the limit of infinite data.</p>
+ </li>
+ <li>
+ <p>The paper introduces a family of smoothed loss functions that are specially designed for top-k optimization.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1802.07595">Paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/oval-group/smooth-topk">Code</a></p>
+ </li>
+</ul>
+
+<h2 id="idea">Idea</h2>
+
+<ul>
+ <li>Inspired by the multi-loss SVMs, a surrogate loss (l<sub>k</sub>) is introduced that creates a margin between the ground truth and the kth largest score.</li>
+</ul>
+
+<p><img src="https://github.com/shagunsodhani/papers-I-read/raw/master/assets/topk/eq1.png" alt="Equation 1" /></p>
+
+<ul>
+ <li>
+ <p>Here <strong>s</strong> denotes the output of the classifier model to be learnt, <em>y</em> is the ground truth label, <em>s[p]</em> denotes the kth largest element of <strong>s</strong> and <strong>s\p</strong> denotes the vector <strong>s</strong> without <em>p</em>th element.</p>
+ </li>
+ <li>
+ <p>This l<sub>k</sub> loss has two limitations:</p>
+
+ <ul>
+ <li>
+ <p>It is continous but not differentiable in <em>s</em>.</p>
+ </li>
+ <li>
+ <p>Its weak derivatives have at most 2-nonzero elements.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The loss can be reformulated by adding and subtracting the k-1 largest scores of <strong>s\y</strong> and <em>s<sub>y</sub></em> and by introducing a temperature parameter τ.</p>
+ </li>
+</ul>
+
+<p><img src="https://github.com/shagunsodhani/papers-I-read/raw/master/assets/topk/eq2.png" alt="Equation 2" /></p>
+
+<h2 id="properties-of-lkτ">Properties of L<sub>kτ</sub></h2>
+
+<ul>
+ <li>
+ <p>For any τ > 0, L<sub>kτ</sub> is infinite-differentiable and has non-sparse gradients.</p>
+ </li>
+ <li>
+ <p>Under mild conditions, L<sub>kτ</sub> apporachs l<sub>k</sub> (in a pointwise sense) as τ approaches to 0+<sup>+</sup>.</p>
+ </li>
+ <li>
+ <p>It is an upper bound on the actual loss (up to a constant factor).</p>
+ </li>
+ <li>
+ <p>It is a generalization of the cross-entropy loss for different values of k, and τ and higher margins.</p>
+ </li>
+</ul>
+
+<h2 id="computational-challenges">Computational Challenges</h2>
+
+<ul>
+ <li>
+ <p><em>nCk</em> number of terms needs to be evaluated for computing the loss for one sample (n is number of classes).</p>
+ </li>
+ <li>
+ <p>Loss L<sub>kτ</sub> can be expressed in terms of elementary symmetric polynomials σ<sub>i</sub>(<strong>e</strong>) (sum of all products of i distinct elements of vector e). Thus the challenge is to compute σ<sub>k</sub> efficiently.</p>
+ </li>
+</ul>
+
+<h3 id="forward-computation">Forward Computation</h3>
+
+<ul>
+ <li>
+ <p>Compute σ<sub>k</sub>(<strong>e</strong>) where <strong>e</strong> is a n-dimensional vector and k« n and e[i]!=0 for all i.</p>
+ </li>
+ <li>
+ <p>σ<sub>i</sub>(<em>e</em>) can be computed using the coefficients of the polynomial (X+e<sub>1</sub>)(X+e<sub>2</sub>)…(X+e<sub>n</sub>) by divide and conquer approach with polynomial multiplication.</p>
+ </li>
+ <li>
+ <p>With some more optimizations (eg log(n) levels of recursion and each level being parallelized on a GPU), the resulting algorithms scale well with n on a GPU.</p>
+ </li>
+ <li>
+ <p>Operations are performed in the log-space using the log-sum-exp trick to achieve numerical stability in single floating point precision.</p>
+ </li>
+</ul>
+
+<h3 id="backward-computation">Backward computation</h3>
+
+<ul>
+ <li>
+ <p>The backward pass uses optimizations like computing derivative of σ<sub>j</sub> with respect to e<sub>i</sub> in a recursive manner.</p>
+ </li>
+ <li>
+ <p>Appendix of the paper describes these techniques in detail.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Experiments are performed on CIFAR-100 (with noise) and Imagenet.</p>
+ </li>
+ <li>
+ <p>For CIFAR-100 with noise, the labels are randomized with probability p (within the same top-level class).</p>
+ </li>
+ <li>
+ <p>The proposed loss function is very robust to both noise and reduction in the amount of training dataset as compared to cross-entropy loss function for both top-k and top-1 performance.</p>
+ </li>
+</ul>
+
+
+
+
+ Hindsight Experience Replay
+
+ 2018-12-18T00:00:00-05:00
+ /site/2018/12/18/Hindsight Experience Replay
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Hindsight Experience Replay(HER) is a sample efficient technique to learn from sparse rewards.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1707.01495">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="idea">Idea</h2>
+
+<ul>
+ <li>
+ <p>Assume a footballer misses the goal narrowly. Even though the player does not get any “reward”(in terms of goal), the player realizes that had the goal post been shifted a bit, it would have resulted in a goal(reward).</p>
+ </li>
+ <li>
+ <p>The same intuition is applied for the RL agent - let us say that the true goal state was <em>g</em> while the agent ends up in the state <em>s</em>.</p>
+ </li>
+ <li>
+ <p>While the action sequence is not useful for reaching the goal state <em>g</em>, it is indeed useful for reaching state <em>s</em>. Hence the trajectory could be replayed with the goal as <em>s</em>(and not <em>g</em>).</p>
+ </li>
+</ul>
+
+<h2 id="technical-details">Technical Details</h2>
+
+<ul>
+ <li>
+ <p>Multi-goal policy trained using Universal Value Function Approximation (UVFA).</p>
+ </li>
+ <li>
+ <p>Every episode starts by sampling a start state and a goal state. Each goal has a different reward function.</p>
+ </li>
+ <li>
+ <p>Policy uses both the current state and the current goal state and leads to a state transition sequence <em>s<sub>1</sub>, s<sub>2</sub>,…, s<sub>n</sub></em>.</p>
+ </li>
+ <li>
+ <p>Each of these transitions <em>s<sub>i</sub> -> s<sub>i+1</sub></em> are stored in a buffer with both the original goal and a subset of the other goals.</p>
+ </li>
+ <li>
+ <p>For the goal selection, following strategies are tried:</p>
+
+ <ul>
+ <li>
+ <p><em>Future</em> - goal state is the state <em>k</em> steps after observing the state transition.</p>
+ </li>
+ <li>
+ <p><em>Final</em> - goal state is the final state of the current episode.</p>
+ </li>
+ <li>
+ <p><em>Episode</em> - <em>k</em> random states are selected from the current episode.</p>
+ </li>
+ <li>
+ <p><em>Randon</em> - <em>k</em> states are selected randomly.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Any off-policy algorithm can be used. Specifically, DDPG is used.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Robotic arm simulated using MuJoCo for <em>push</em>, <em>slide</em> and <em>pick and place</em> tasks.</p>
+ </li>
+ <li>
+ <p>DDPG with and without HER evaluated on the 3 tasks.</p>
+ </li>
+ <li>
+ <p>DDPG with the HER variant significantly outperforms the baseline in all the cases.</p>
+ </li>
+</ul>
+
+
+
+
+ Representation Tradeoffs for Hyperbolic Embeddings
+
+ 2018-12-11T00:00:00-05:00
+ /site/2018/12/11/Representation Tradeoffs for Hyperbolic Embeddings
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper describes a combinatorial approach to embed trees into hyperbolic spaces without performing optimization.</p>
+ </li>
+ <li>
+ <p>The resulting mechanism is analyzed to obtain dimensionality-precision tradeoffs.</p>
+ </li>
+ <li>
+ <p>To embed any metric spaces in the hyperbolic spaces, a hyperbolic generalization of the multidimensional scaling (h-MDS) is proposed.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1804.03329">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="preliminaries">Preliminaries</h2>
+
+<ul>
+ <li>
+ <p>Hyperbolic Spaces</p>
+
+ <ul>
+ <li>
+ <p>Have the “tree” like property ie the shortest path between a pair of points is almost the same as the path through the origin.</p>
+ </li>
+ <li>
+ <p>Generally, Poincare ball model is used given its advantages like conformity to the Euclidean spaces.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Fidelity Measures</p>
+
+ <ul>
+ <li>
+ <p>Mean Average Precision - MAP</p>
+
+ <ul>
+ <li>A local metric that ranks between distances of the immediate neighbors.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Distortion</p>
+
+ <ul>
+ <li>A global metric that depends on the underlying distances and not just the local relationship between distances.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="combinatorial-construction-for-embedding-hierarchies-into-hyperbolic-spaces">Combinatorial Construction for embedding hierarchies into Hyperbolic spaces</h2>
+
+<ul>
+ <li>
+ <p>Embed the given graph <em>G = (V, E)</em> into a tree <em>T</em>.</p>
+ </li>
+ <li>
+ <p>Embed the tree <em>T</em> into the poincare ball <em>H<sub>d</sub></em> of dimensionality <em>d</em>.</p>
+ </li>
+</ul>
+
+<h3 id="sarkars-construction-to-embed-points-in-a-2-d-poincare-ball">Sarkar’s construction to embed points in a 2-d Poincare ball</h3>
+
+<ul>
+ <li>
+ <p>Consider two points <em>a</em> and <em>b</em> (from the tree) where <em>b</em> is the parent of <em>a</em>.</p>
+ </li>
+ <li>
+ <p>Assume that <em>a</em> is embedded as <em>f(a)</em> and <em>b</em> is embedded as <em>f(b)</em> and the children of <em>a</em> needs to be embedded.</p>
+ </li>
+ <li>
+ <p>Reflect <em>f(a)</em> and <em>f(b)</em> across a geodesic such that <em>f(a)</em> is mapped to 0 (origin) while <em>f(b)</em> is mapped to some new point <em>z</em>.</p>
+ </li>
+ <li>
+ <p>Children of <em>a</em> are placed at points <em>y<sub>i</sub></em> which are equally placed around a circle of radius <em>(e<sup>r</sup> - 1) / (e<sup>r</sup> + 1)</em> and maximally seperated from <em>z</em>, where <em>r</em> is the scaling factor.</p>
+ </li>
+ <li>
+ <p>Then all the points are reflected back across the geodesic so that all children are at a distance <em>r</em> from <em>f(a)</em>.</p>
+ </li>
+ <li>
+ <p>To embed the tree itself, place the root node at the origin, place its children around it in a circle, then place their children and so on.</p>
+ </li>
+ <li>
+ <p>In this construct, precision scales logarithmically with the degree of the tree but linearly with the maximum path length.</p>
+ </li>
+</ul>
+
+<h3 id="d-dimensional-hyperbolic-spaces"><em>d</em>-dimensional hyperbolic spaces</h3>
+
+<ul>
+ <li>
+ <p>In the <em>d</em>-dimensional space, the points are embedded into hyperspheres (instead of circles).</p>
+ </li>
+ <li>
+ <p>The number of children node that can be placed for a particular angle grows with the dimension.</p>
+ </li>
+ <li>
+ <p>Increasing dimension helps with bushy trees (with high node degree).</p>
+ </li>
+</ul>
+
+<h2 id="hyperbolic-multidimensional-scaling-h-mds">Hyperbolic multidimensional scaling (h-MDS)</h2>
+
+<ul>
+ <li>
+ <p>Given the pairwise distance from a set of points in the hyperbolic space, how to recover the points?</p>
+ </li>
+ <li>
+ <p>The corresponding problem in the Euclidean space is solved using MDS.</p>
+ </li>
+ <li>
+ <p>A variant of MDS called as h-MDS is proposed.</p>
+ </li>
+ <li>
+ <p>MDS makes a centering assumption that points have 0 mean. In h-MDS, a new mean (called as the pseudo-Euclidean mean) is introduced to enable recovery via matrix factorization.</p>
+ </li>
+ <li>
+ <p>Instead of the Poincare model, the hyperboloid model is used (though the points can be mapped back and forth).</p>
+ </li>
+</ul>
+
+<h3 id="pseudo-euclidean-mean">pseudo-Euclidean Mean</h3>
+
+<ul>
+ <li>A set of points can always be centered without affecting their pairwise distance by simply finding their mean and sending it to 0 via isometry</li>
+</ul>
+
+<h3 id="recovery-via-matrix-factorization">Recovery via matrix factorization</h3>
+
+<ul>
+ <li>
+ <p>Given the pairwise distances, a new matrix <em>Y</em> is constructed by applying <em>cosh</em> on the pairwise distances.</p>
+ </li>
+ <li>
+ <p>Running PCA on <em>-Y</em> recovers X up to rotation.</p>
+ </li>
+</ul>
+
+<h2 id="dimensionality-reduction-with-pga-principal-geodesic-analysis">Dimensionality Reduction with PGA (Principal Geodesic Analysis)</h2>
+
+<ul>
+ <li>
+ <p>PGA is the counterpart of PCA in the hyperbolic spaces.</p>
+ </li>
+ <li>
+ <p>First the <em>Karcher</em> mean of the given points is computed.</p>
+ </li>
+ <li>
+ <p>All points <em>x<sub>i</sub></em> are reflected so that their mean is 0 in the Poincare disk model.</p>
+ </li>
+ <li>
+ <p>Combining that with Euclidean reflection formula and hyperbolic metrics leads to a non-convex loss function which can be optimized using gradient descent algorithm.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Datasets</p>
+
+ <ul>
+ <li>Trees: fully balanced and phylogenic trees expressing genetic heritage.</li>
+ <li>Tree-like hierarchy: WordNet hypernym and graph of Ph.D. advisor-advisee relationships.</li>
+ <li>No-tree like disease relationships, proteins interactions etc</li>
+ </ul>
+ </li>
+ <li>
+ <p>Results</p>
+
+ <ul>
+ <li>Combinatorial construction outperforms approaches based on optimization in terms of both MAP and distortion.</li>
+ <li>eg on WordNet, the combinatorial approach achieves a MAP of 0.989 with just 2 dimensions while the previous best was 0.87 with 200 dimensions.</li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+
+ Learned Optimizers that Scale and Generalize
+
+ 2018-11-01T00:00:00-04:00
+ /site/2018/11/01/Learned Optimizers that Scale and Generalize
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces a learned gradient descent optimizer that has low memory and computational overhead and that generalizes well to new tasks.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1703.04813">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="key-advantage">Key Advantage</h2>
+
+<ul>
+ <li>
+ <p>Uses a hierarchial RNN architecture augmented by features like adapted input an output scaling, momentum etc.</p>
+ </li>
+ <li>
+ <p>A meta-learning set of small diverse optimization tasks, with diverse loss landscapes is developed. The learnt optimizer generalizes to much more complex tasks and setups.</p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>A hierarchical RNN is designed to act as a learned optimizer. This RNN is the meta-learner and its parameters are shared across different tasks.</p>
+ </li>
+ <li>
+ <p>The learned optimizer takes as input the gradient (and related metadata) for each parameter and outputs the update to the parameters.</p>
+ </li>
+ <li>
+ <p>At the lowest level of hierarchical, a small “parameter RNN” ingests the gradient (and related metadata).</p>
+ </li>
+ <li>
+ <p>One level up, an intermediate “Tensor RNN” incorporates information from a subset of Parameter RNNS (eg one Tensor RNN per layer of feedforward network).</p>
+ </li>
+ <li>
+ <p>At the highest level is the glocal RNN which receives input from all the Tensor RNNs and can keep track of weight updates across the task.</p>
+ </li>
+ <li>
+ <p>the input of each RNN is averaged and fed as input to the subsequent RNN and the output of each RNN is fed as bias to the previous RNN.</p>
+ </li>
+ <li>
+ <p>In practice, the hidden states are fixed at 10, 30 and 20 respectively.</p>
+ </li>
+</ul>
+
+<h2 id="features-inspired-from-existing-optimizers">Features inspired from existing optimizers</h2>
+
+<ul>
+ <li>
+ <p>Attention and Nesterov’s momentum</p>
+
+ <ul>
+ <li>
+ <p>Attention mechanism is incorporated by attending to new regions of the loss surface (which are an offset from previous parameter location).</p>
+ </li>
+ <li>
+ <p>To incorporate momentum on multiple timescales, the exponential moving average of the gradient at several timescales is also provided as input.</p>
+ </li>
+ <li>
+ <p>The average gradients are rescaled (as in RMSProp and Adam)</p>
+ </li>
+ <li>
+ <p>Relative log gradient magnitudes are also provided as input so that the optimizer can access how the gradient magnitude changes with time.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ One-shot Learning with Memory-Augmented Neural Networks
+
+ 2018-10-25T00:00:00-04:00
+ /site/2018/10/25/One-shot Learning with Memory-Augmented Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper demonstrates that Memory Augmented Neural Networks (MANN) are suitable for one-shot learning by introducing a new method for accessing an external memory.</p>
+ </li>
+ <li>
+ <p>This method focuses on memory content while earlier methods additionally used memory location based focusing mechanisms.</p>
+ </li>
+ <li>
+ <p>Here, MANN refers to neural networks that have an external memory. This includes Neural Turning Machines (NTMs) and excludes LSTMs.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1605.06065">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="meta-learning">Meta-Learning</h2>
+
+<ul>
+ <li>
+ <p>In meta-learning, a learner is learning at two levels.</p>
+ </li>
+ <li>
+ <p>The learner is shown a sequence of tasks D<sub>1</sub>, D<sub>2</sub>, …, D<sub>T</sub>.</p>
+ </li>
+ <li>
+ <p>When it is training on one of the datasets (say D<sub>T</sub>), it learns to solve the current dataset.</p>
+ </li>
+ <li>
+ <p>At the same time, the learner tries to incorporate knowledge about how task structure changes across different datasets (second level of learning).</p>
+ </li>
+</ul>
+
+<h2 id="mann--meta-learning">MANN + Meta Learning</h2>
+
+<ul>
+ <li>
+ <p>Following are the desirable characteristics for a scalable, combined architecture:</p>
+
+ <ul>
+ <li>
+ <p>Memory representation should be both stable and element-wise accessible.</p>
+ </li>
+ <li>
+ <p>Number of model parameters should not be tied to the size of the memory.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="task-setup">Task Setup</h2>
+
+<ul>
+ <li>
+ <p>In standard learning, the goal is to reduce error on some dataset D. In meta-learning, the goal is to reduce the error across a distribution of datasets p(D).</p>
+ </li>
+ <li>
+ <p>Each dataset is presented to the model in the form (x<sub>1</sub>, null), (x<sub>1</sub>, y<sub>0</sub>), …, (x<sub>t+1</sub>, y<sub>t</sub>) where y<sub>t</sub> is the correct label (or value) corresponding to the inpuit x<sub>t</sub>.</p>
+ </li>
+ <li>
+ <p>Further, the data labels are shuffled from dataset to dataset.</p>
+ </li>
+ <li>
+ <p>The model must learn to hold the data samples in memory till the appropriate candidate labels are presented in the next step.</p>
+ </li>
+ <li>
+ <p>The idea is that a model that meta learns would learn to map data representation to correct labels regardless of the actual context of data representation or the label.</p>
+ </li>
+ <li>
+ <p>The paper uses NTM as the MANN with one modification.</p>
+ </li>
+ <li>
+ <p>In the original formulation, the memories were addressed by both context and location. Location-based addressing is not optimal for the current setup where information encoding is not independent of the sequence.</p>
+ </li>
+ <li>
+ <p>A new access module - LRUA - Least Recent Used Access - is used to write to memory.</p>
+ </li>
+ <li>
+ <p>LRUA is purely content-based and writes to either least used memory location (to preserve recent information) or most recently used memory location (to overwrite recent information with more relevant information). This is decided on the basis of interpolation between previous read weights and weights scaled according to the usage weight.</p>
+ </li>
+</ul>
+
+<h2 id="datasets">Datasets</h2>
+
+<ul>
+ <li>
+ <p>Omniglot (classification)</p>
+ </li>
+ <li>
+ <p>Sampled functions from Gaussian Processes</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>For the omniglot dataset, the model was trained with various combinations of randomly chosen classes with randomly chosen labels.</p>
+ </li>
+ <li>
+ <p>As baselines, following models were considered:</p>
+
+ <ul>
+ <li>Regular NTM</li>
+ <li>LSTM</li>
+ <li>Feedforward RNN</li>
+ <li>Nearest Neighbour Classifier</li>
+ </ul>
+ </li>
+ <li>
+ <p>Since each episode (dataset created by the combination of classes) contains unique classes (with their own unique labels) it is important to clear the memory across different episodes.</p>
+ </li>
+ <li>
+ <p>For the regression task, the data was generated from a GP prior with a fixed set of hyper-parameters which resulted in different functions.</p>
+ </li>
+ <li>
+ <p>For both the tasks, the MANN architecture outperforms the LSTM architecture baseline NTMs.</p>
+ </li>
+</ul>
+
+
+
+
+
+ BabyAI - First Steps Towards Grounded Language Learning With a Human In the Loop
+
+ 2018-10-18T00:00:00-04:00
+ /site/2018/10/18/BabyAI-First Steps Towards Grounded Language Learning With a Human In the Loop
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>BabyAI is a research platform to investigate and support the feasibility of including humans in the loop for grounded language learning.</p>
+ </li>
+ <li>
+ <p>The setup is a series of levels (of increasing difficulty) to train the agent to acquire a synthetic language (Baby Language) which is a proper subset of English language.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1810.08272">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="motivation">Motivation</h2>
+
+<ul>
+ <li>
+ <p>BabyAI platform provides support for curriculum learning and interactive learning as part of its human-in-the-loop training setup.</p>
+ </li>
+ <li>
+ <p>Curriculum learning is incorporated by having a curriculum of levels of increasing difficulty.</p>
+ </li>
+ <li>
+ <p>Interactive learning is supported by including a heuristic expert which can provide new demonstrations on the fly to the learning agent.</p>
+ </li>
+ <li>
+ <p>The heuristic expert can be thought of as the human-in-the-loop which can guide the agent through the learning process.</p>
+ </li>
+ <li>
+ <p>One downside of human-in-the-loop is the poor sample complexity of the learning agent. The heuristic agent can be used to estimate the sample efficiency.</p>
+ </li>
+</ul>
+
+<h2 id="contribution">Contribution</h2>
+
+<ul>
+ <li>
+ <p>BabyAI research platform for grounded language learning with a simulated human-in-the-loop.</p>
+ </li>
+ <li>
+ <p>Baseline results for performance and sample efficiency for the different tasks.</p>
+ </li>
+</ul>
+
+<h2 id="babyai-platform">BabyAI Platform</h2>
+
+<h3 id="environment">Environment</h3>
+
+<ul>
+ <li>
+ <p>MiniGrid - A partially observable 2D grid-world environment.</p>
+ </li>
+ <li>
+ <p>Entities - Agent, ball, box, door, keys</p>
+ </li>
+ <li>
+ <p>Actions - pick, drop or move objects, unlock doors etc.</p>
+ </li>
+</ul>
+
+<h3 id="baby-language">Baby Language</h3>
+
+<ul>
+ <li>
+ <p>Synthetic Language (a proper subset of English) - Used to give instructions to the agent</p>
+ </li>
+ <li>
+ <p>Support for verifying if the task (and the subtasks) are completed or not</p>
+ </li>
+</ul>
+
+<h3 id="levels">Levels</h3>
+
+<ul>
+ <li>
+ <p>A level is an instruction-following task.</p>
+ </li>
+ <li>
+ <p>Formally, a level is a distribution of missions - a combination of initial state of the environment and an instruction (in Baby Language)</p>
+ </li>
+ <li>
+ <p>Motivated by curriculum learning, the authors create a series of tasks (with increasing difficulty).</p>
+ </li>
+ <li>
+ <p>A subset of skills (competencies) is required for solving each task. The platform takes into account this constraint when creating a level.</p>
+ </li>
+</ul>
+
+<h3 id="heuristic-expert">Heuristic Expert</h3>
+
+<ul>
+ <li>
+ <p>The platform supports a Heuristic expert that simulates the role of a human teacher and knows how to solve each task.</p>
+ </li>
+ <li>
+ <p>For any level, it can suggest actions or generate demonstrations (given the state of the environment).</p>
+ </li>
+</ul>
+
+<h2 id="experiment">Experiment</h2>
+
+<ul>
+ <li>
+ <p>An imitation learning baseline is trained for each level.</p>
+ </li>
+ <li>
+ <p>Data requirement for each level and the benefits of curriculum learning and imitation learning are investigated (in terms of sample efficiency).</p>
+ </li>
+</ul>
+
+<h2 id="model-architecture">Model Architecture</h2>
+
+<ul>
+ <li>
+ <p>GRU to encode the sentence, CNN to encode the input observation</p>
+ </li>
+ <li>
+ <p>FiLM layer to combine the two representations</p>
+ </li>
+ <li>
+ <p>LSTM to encode the per-timestep FiLM encoding (timesteps in the environment)</p>
+ </li>
+ <li>
+ <p>Two model variants are considered:</p>
+
+ <ul>
+ <li>
+ <p>Large Model - Bidirectional GRU + attention + large hidden state</p>
+ </li>
+ <li>
+ <p>Small Model - Unidirectional GRU + No attention + small hidden state</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Heuristic expert used to generate trajectory and the models are trained by imitation learning (to be used as baselines)</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>The key takeaway is that the current deep learning approaches are extremely sample inefficient when learning a compositional language.</p>
+ </li>
+ <li>
+ <p>Data efficiency of RL methods is much worse than that of imitation learning methods showing that the current imitation learning and reinforcement learning methods scale and generalize poorly.</p>
+ </li>
+ <li>
+ <p>Curriculum-based pretraining and interactive learning was found to be useful in only some cases.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Poincaré Embeddings for Learning Hierarchical Representations
+
+ 2018-10-11T00:00:00-04:00
+ /site/2018/10/11/Poincare Embeddings for Learning Hierarchical Representations
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Much of the work in representation leaning uses Euclidean vector spaces to embed datapoints (like words, nodes, entities etc).</p>
+ </li>
+ <li>
+ <p>This approach is not effective when data has a (latent) hierarchical structure.</p>
+ </li>
+ <li>
+ <p>The paper proposes to compute the embeddings in the hyperbolic space so as to preserve both the similarity and structure information.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/pdf/1705.08039.pdf">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="hyperbolic-geometry">Hyperbolic Geometry</h2>
+
+<ul>
+ <li>
+ <p>Hyperbolic spaces are spaces with a constant negative curvature while Euclidean spaces have zero curvature.</p>
+ </li>
+ <li>
+ <p>The hyperbolic disc area and circle length increase exponentially with the radius r while in Euclidean space, it increases quadratically and linearly respectively.</p>
+ </li>
+ <li>
+ <p>This makes the hyperbolic space more suitable for embedding tree-like structures where the number of nodes increases as we move away from the root.</p>
+ </li>
+ <li>
+ <p>Hyperbolic spaces can be thought of as the continuous version of trees and trees can be thought of as the discrete version of hyperbolic spaces.</p>
+ </li>
+</ul>
+
+<h2 id="poincare-embeddings">Poincare Embeddings</h2>
+
+<ul>
+ <li>
+ <p>Poincare model is one of the several possible models of the hyperbolic space and is considered here as it is more amenable to gradient-based optimisation.</p>
+ </li>
+ <li>
+ <p>Distance between 2 pints change smoothly and is symmetric. Thus the hierarchical organisation only depends on the distance from the origin which makes the model applicable in settings where the hierarchical structure needs to be inferred from the data.</p>
+ </li>
+ <li>
+ <p>Eventually the norm of a point represents its hierarchy and distance between the points represents similarity.</p>
+ </li>
+</ul>
+
+<h2 id="optimization">Optimization</h2>
+
+<ul>
+ <li>RSGD (Riemannian SGD) method is used.</li>
+ <li>Riemannian gradients can be computed from the Euclidean gradients by rescaling with the inverse of the Poincare ball metric tensor.</li>
+ <li>The embeddings are constrained to be within the Poincare ball by projection operation which normalizes the magnitude of embeddings to be 1.</li>
+</ul>
+
+<h2 id="training-details">Training Details</h2>
+
+<ul>
+ <li>Initializing the embeddings close to 0 (by sampling uniformly from (-0.001, 0.001)) helps.</li>
+ <li>The model is trained for an initial burn-out period of 10 epochs with 0.1 times the learning rate so as to find a better initial angular layout.</li>
+</ul>
+
+<h2 id="evaluation">Evaluation</h2>
+
+<ul>
+ <li>
+ <p>Embedding taxonomy for wordnet task</p>
+
+ <ul>
+ <li>
+ <p>Setup</p>
+
+ <ul>
+ <li>Reconstruction</li>
+ <li>Link Prediction</li>
+ </ul>
+ </li>
+ <li>
+ <p>The input data is a collection of a pair of words (u, v) which are related to each other.</p>
+ </li>
+ <li>
+ <p>For each word pair, 10 negative samples of the form (u, v’) are sampled and the training procedure uses a soft ranking loss that aims to bring the related objects closer together.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Network Embedding</p>
+
+ <ul>
+ <li>
+ <p>Baselines</p>
+
+ <ul>
+ <li>Euclidean Embeddings</li>
+ <li>Translational Embedding where a relation vector corresponding to the edge type is also learnt.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Datasets</p>
+
+ <ul>
+ <li>ASTROPH</li>
+ <li>CONDMAT</li>
+ <li>GRQC</li>
+ <li>HEPPH</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Lexical Entailment</p>
+ </li>
+</ul>
+
+<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>* Hyperlex - Gold standard to evaluate how well the semantics models capture lexical entailment on a scale of [0, 10].
+
+* The key takeaway is that for all the datasets/setups, hyperbolic embeddings give a performance benefit when the embedding dimension is small.
+</code></pre></div></div>
+
+<h2 id="challenges">Challenges</h2>
+
+<ul>
+ <li>
+ <p>Hyperbolic embeddings are not suitable for all the datasets. Eg if the dataset is not tree-like or has cycles.</p>
+ </li>
+ <li>
+ <p>Hyperbolic embeddings are difficult to optimize as each operation needs to be modified to be usable in the hyperbolic space.</p>
+ </li>
+</ul>
+
+
+
+
+ When Recurrent Models Don’t Need To Be Recurrent
+
+ 2018-10-04T00:00:00-04:00
+ /site/2018/10/04/When Recurrent Models Don’t Need To Be Recurrent
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper explores “if a well behaved RNN can be replaced by a feed-forward network of comparable size without loss in performance.”</p>
+ </li>
+ <li>
+ <p>“Well behaved” is defined in terms of control-theoretic notion of stability. This roughly requires that the gradients do not explode over time.</p>
+ </li>
+ <li>
+ <p>The paper shows that under the stability assumption, feedforward networks can approximate RNNs for both training and inference. The results are empirically validated as well.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1805.10369">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="problem-setting">Problem Setting</h2>
+
+<ul>
+ <li>
+ <p>Consider a general, non linear dynamical system given by a differential state transition map Φ<sub>w</sub>. The hidden h<sub>t</sub> = Φ<sub>w</sub>(h<sub>t-1</sub>, x<sub>t</sub>).</p>
+ </li>
+ <li>
+ <p>Assumptions:</p>
+
+ <ul>
+ <li>Φ is smooth in w and h.</li>
+ <li>h<sub>0</sub> = 0</li>
+ <li>Φ<sub>w</sub>(0, 0) = 0 (can be ensured by translation)</li>
+ </ul>
+ </li>
+ <li>
+ <p>Stable models are the ones where Φ is contractive ie Φ<sub>w</sub>(h, x) - Φ<sub>w</sub>(h’, x) is less than Λ * (h - h’)</p>
+ </li>
+ <li>
+ <p>For example, in RNN, stability would require that norm(w) is less than (L<sub>p</sub>)<sup>-1</sup> where L<sub>p</sub> is the Lipschitz constant of the point-wise non linearity used.</p>
+ </li>
+ <li>
+ <p>The feedforward approximation uses a finite context (of length k) and is a truncated model.</p>
+ </li>
+ <li>
+ <p>A non-parametric function f maps the output of the recurrent model to prediction. If f is desired to be a parametric model, its parameters can be pushed to the recurrent model.</p>
+ </li>
+</ul>
+
+<h2 id="theoretical-results">Theoretical Results</h2>
+
+<ul>
+ <li>
+ <p>For a Λ-contractive system, it can be proved that for a large k (and additional Lipschitz assumptions) the difference in prediction between the recurrent and truncated mode is negligible.</p>
+ </li>
+ <li>
+ <p>If the recurrent model and truncated feed-forward network are initialized at the same point and trained over the same input for N-step, then for an optimal k, the weights of the two models would be very close in the Euclidean space. It can be shown that this small difference does not lead to large gradient differences during subsequent update steps.</p>
+ </li>
+ <li>
+ <p>This can be roughly interpreted as - if the gradient descent can train a stable recurrent network, it can also train a feedforward model and vice-versa.</p>
+ </li>
+ <li>
+ <p>The stability condition is important as, without that, truncated models would be bad (even for large values of k). Further, it is difficult to show that gradient descent converges to a stationary point.</p>
+ </li>
+</ul>
+
+
+
+
+ HoME - a Household Multimodal Environment
+
+ 2018-09-27T00:00:00-04:00
+ /site/2018/09/27/HoME - a Household Multimodal Environment
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Environment for learning using modalities like vision, audio, semantics, physics and interaction with objects and other agents.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1711.11017">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="motivation">Motivation</h2>
+
+<ul>
+ <li>
+ <p>Humans learn by interacting with their surroundings (environment).</p>
+ </li>
+ <li>
+ <p>Similarly training an agent in an interactive multi-model environment (virtual embodiment) could be useful for a learning agent.</p>
+ </li>
+</ul>
+
+<h2 id="characteristics">Characteristics</h2>
+
+<ul>
+ <li>
+ <p>Open-source and Open-AI gym compatible</p>
+ </li>
+ <li>
+ <p>Built on top of 45000 3D house layouts from SUNCG dataset.</p>
+ </li>
+ <li>
+ <p>Provides both 3D visual and audio recording.</p>
+ </li>
+ <li>
+ <p>Semantic image segmentation and langauge description of objects.</p>
+ </li>
+</ul>
+
+<h2 id="components">Components</h2>
+
+<ul>
+ <li>
+ <p>Rendering Engine</p>
+
+ <ul>
+ <li>
+ <p>Implemented using Panda 3D game engine.</p>
+ </li>
+ <li>
+ <p>Renders RGB+depth scenes based on textures, multi-source lightings and shadows.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Acoustic Engine</p>
+
+ <ul>
+ <li>
+ <p>Implemented using EVERT</p>
+ </li>
+ <li>
+ <p>Supports multiple microphones, sound sources, sound absorption based on material, atmospheric conditions etc.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Semantics Engine</p>
+
+ <ul>
+ <li>Provides a short textual description for each object, along with information like color, category, material size, location etc.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Physics Engine</p>
+
+ <ul>
+ <li>
+ <p>Implemented using Bullet3 Engine</p>
+ </li>
+ <li>
+ <p>Supports physical interaction, external forces like gravity and position and velocity information for multiple agents.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="potential-applications">Potential Applications</h2>
+
+<ul>
+ <li>
+ <p>Visual Question Answering</p>
+ </li>
+ <li>
+ <p>Conversational Agents</p>
+ </li>
+ <li>
+ <p>Training an agent to follow instructions</p>
+ </li>
+ <li>
+ <p>Multi-agent communication</p>
+ </li>
+</ul>
+
+
+
+
+ Emergence of Grounded Compositional Language in Multi-Agent Populations
+
+ 2018-09-12T00:00:00-04:00
+ /site/2018/09/12/Emergence of Grounded Compositional Language in Multi-Agent Populations
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper provides a multi-agent learning environment and proposes a learning approach that facilitates the emergence of a basic compositional language.</p>
+ </li>
+ <li>
+ <p>The language is quite rudimentary and is essentially a sequence of abstract discrete symbols. But it does comprise of a defined vocabulary and syntax.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1703.04908">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Cooperative, partially observable Markov game (multi-agent extension of MDP).</p>
+ </li>
+ <li>
+ <p>All agents have identical action and observation spaces, use the same policy and receive a shared reward.</p>
+ </li>
+</ul>
+
+<h3 id="grounded-communication-environment">Grounded Communication Environment</h3>
+
+<ul>
+ <li>
+ <p>Physically simulated 2-D environment in continuous space and discrete time with N agents and M landmarks.</p>
+ </li>
+ <li>
+ <p>The agents and the landmarks would occupy some location and would have some attributes (colour, shape).</p>
+ </li>
+ <li>
+ <p>Within the environment, the agents can <em>go to</em> a location, <em>look</em> at a location or <em>do nothing</em>. Additionally, they can utter communication symbols c (from a shared vocabulary C). Agents themselves learn to assign a meaning to the symbols.</p>
+ </li>
+ <li>
+ <p>Each agent has an internal goal (which could require interaction with other agents to complete) which the other agents cannot see.</p>
+ </li>
+ <li>
+ <p>Goal for agent <em>i</em> consists of an action to perform, a landmark location where to perform the action and another agent who should be performing the action.</p>
+ </li>
+ <li>
+ <p>Since the agent is continuously emitting symbols, a memory module is provided and simple additive memory updates are done.</p>
+ </li>
+ <li>
+ <p>For interaction, the agents could use verbal utterances, non-verbal signals (gaze) or non-communicative strategies (pushing other agents).</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>A model of all agent and environment state dynamics is created over time and the return gradient is computed.</p>
+ </li>
+ <li>
+ <p>Gumbel-Softmax distribution is used to obtain categorical word emission c.</p>
+ </li>
+ <li>
+ <p>A multi-layer perceptron is used to model the policy which returns action, communication symbol and the memory update for each agent.</p>
+ </li>
+ <li>
+ <p>Since the number of agents (and hence the number of communication streams etc) can vary across instantiations, an identical model is instantiated per agent and per communication stream.</p>
+ </li>
+ <li>
+ <p>The output of individual processing modules are pooled into feature vectors corresponding to communication and physical observations. These pooled features and the goal vectors are fed to the final processing module from which actions and categorical symbols are sampled.</p>
+ </li>
+ <li>
+ <p>In practice, using an additional task (each agent predicts the goal for another agent) encouraged more meaningful communication utterances.</p>
+ </li>
+</ul>
+
+<h3 id="compositionality-and-vocabulary-size">Compositionality and Vocabulary Size</h3>
+
+<ul>
+ <li>
+ <p>Authors recommend using a large vocabulary with a soft penalty that discourages use of too many words. This leads to use of a large vocabulary in the intermediate state which converges to a small vocabulary.</p>
+ </li>
+ <li>
+ <p>Along the lines of rich gets richer dynamics, the communication symbol c’s are modelled as being generated by a Dirichlet process. The resulting reward across all agents is the log-likelihood of all communication utterances to have been generated by a Dirichlet process.</p>
+ </li>
+ <li>
+ <p>Since the agents can only communicate in discrete symbols and do not have a global positioning reference, they need to unambiguously communicate landmark references to other agents.</p>
+ </li>
+</ul>
+
+<h2 id="case-i---agents-can-not-see-each-other">Case I - Agents can not see each other</h2>
+
+<ul>
+ <li>
+ <p>Non-verbal communication is not possible.</p>
+ </li>
+ <li>
+ <p>When trained with just 2 agents, symbols are assigned for each landmark and action.</p>
+ </li>
+ <li>
+ <p>As the number of agents is increased, additional symbols are used to refer to agents.</p>
+ </li>
+ <li>
+ <p>If the agents of the same colour are asked to perform conflicting tasks, they perform the average of conflicting tasks. If distractor locations are added, the agents learn to ignore them.</p>
+ </li>
+</ul>
+
+<h2 id="non-verbal-communication">Non-verbal communication</h2>
+
+<ul>
+ <li>
+ <p>Agents are allowed to observe other agents’ position, gaze etc.</p>
+ </li>
+ <li>
+ <p>Now the location can be pointed to using gaze.</p>
+ </li>
+ <li>
+ <p>If gaze is disabled, the agent could indicate the goal landmark by moving to it.</p>
+ </li>
+ <li>
+ <p>Basically even when the communication is disabled the agents can come up with strategies to complete the task.</p>
+ </li>
+</ul>
+
+
+
+
+ A Semantic Loss Function for Deep Learning with Symbolic Knowledge
+
+ 2018-08-21T00:00:00-04:00
+ /site/2018/08/21/A Semantic Loss Function for Deep Learning with Symbolic Knowledge
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper proposes an approach for using symbolic knowledge in deep learning systems. These constraints are often expressed as boolean constraints on the output of the deep learning system and directly incorporating these constraints break the differentiability of the system.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1711.11157">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="problem-setting">Problem Setting</h2>
+
+<ul>
+ <li>
+ <p>The model is given some input data to perform predictions and symbolic knowledge is provided in form of boolean constraints like exactly-one constraint for one-hot output encoding.</p>
+ </li>
+ <li>
+ <p>Most approaches tend to encode the symbolic knowledge in the vector space embedding to keep the model pipeline differentiable. In this process, the precise meaning of symbolic knowledge is often lost.</p>
+ </li>
+ <li>
+ <p>A differentiable “semantic loss” is derived which captures the meaning of the constraint while being independent of its syntax.</p>
+ </li>
+</ul>
+
+<h2 id="terminology">Terminology</h2>
+
+<ul>
+ <li>
+ <p>A state <strong>x</strong> (state refers to the instantiation of boolean variables) satisfies a sentence <em>a</em> if <em>a</em> evaluates to true when using the variables as specified by <strong>x</strong>.</p>
+ </li>
+ <li>
+ <p>A sentence <em>a</em> entails another sentence <em>b</em> if all states that satisfy <em>a</em> also satisfy <em>b</em>.</p>
+ </li>
+ <li>
+ <p>The row output vector of the neural network is denoted as <em>p</em> where each value in <em>p</em> denotes the probability of an output.</p>
+ </li>
+ <li>
+ <p>Three different output constraints are studied:</p>
+
+ <ul>
+ <li>
+ <p><em>Exactly-one constraint</em></p>
+
+ <ul>
+ <li>Exactly one value in <em>p</em> should be true.</li>
+ <li>Can be expressed in boolean logic as follows: Let (x1, x2, …, xn) be variables in <em>p</em>. Then (not xi or not xj) for all pair of variables and (x1 or x2 or … xn).</li>
+ </ul>
+ </li>
+ <li><em>Valid Simple Path Constraint</em>
+ <ul>
+ <li>Set of edges must form a valid path.</li>
+ </ul>
+ </li>
+ <li><em>Ordering Constraint</em>
+ <ul>
+ <li>Defining an ordering over the variables.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="semantic-loss">Semantic Loss</h2>
+
+<ul>
+ <li>
+ <p>The semantic loss <em>L<sup>s</sup>(a, p)</em> is a function of a propositional logic sentence <em>a</em> (the symbolic knowldge constraint) and <em>p</em> (output of the neural network).</p>
+ </li>
+ <li>
+ <p><em>a</em> is defined over variables (x1, …, xn) and <em>p</em> is interpreted as a vector of probabilities corresponding to these variables <em>xi’s</em>.</p>
+ </li>
+ <li>
+ <p>The semantic loss is directly proportional to the negative log likelihood of generating a state that satisfies the constraints when sampling values according to the distribution <em>p</em>.</p>
+ </li>
+</ul>
+
+<h2 id="main-axioms-and-insights">Main Axioms and Insights</h2>
+
+<ul>
+ <li><strong>Monotonicity</strong>
+ <ul>
+ <li>If a sentence <em>a</em> entails another sentence <em>b</em> then for any given <em>p</em>, <em>L<sup>s</sup>(a, p) > L<sup>s</sup>(b, p)</em> ie adding more constraints cannot decrease the semantic loss.</li>
+ </ul>
+ </li>
+ <li><strong>Semantic Equivalence</strong>
+ <ul>
+ <li>If two sentences are logically equivalent, their semantic loss is the same.</li>
+ </ul>
+ </li>
+ <li><strong>Identity</strong>
+ <ul>
+ <li>For any given sentence <em>a</em>, its representation as a sentence is equivalent to its representation as a deterministic vector ie writing the “one-hot” constraint as a boolean expression is equivalent to a one-hot vector.</li>
+ </ul>
+ </li>
+ <li><strong>Satisfaction</strong>
+ <ul>
+ <li>If <em>p</em> entails the sentence <em>a</em> then <em>L<sup>s</sup>(a, p) = 0</em>.</li>
+ </ul>
+ </li>
+ <li><strong>Label-literal correspondence</strong>
+ <ul>
+ <li>When the constraint is defined in terms of a single variable, it can be interpreted as the supervised label.</li>
+ <li>Hence the semantic loss in case of a single variable should be equivalent to the cross-entropy loss.</li>
+ </ul>
+ </li>
+ <li><strong>Truth</strong>
+ <ul>
+ <li>The semantic loss of a true sentence is 0</li>
+ </ul>
+ </li>
+ <li><strong>Non-negativity</strong>
+ <ul>
+ <li>Semantic loss should always be non-negative.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Probabilities of variables that are not part of the constraint, do not affect the semantic loss.</p>
+ </li>
+ <li>It can be shown that the semantic loss function satisfies all these axioms (and the other axioms specified in the paper) and is the only function to do so, up to a multiplicative constant.</li>
+</ul>
+
+<h2 id="experimental-evaluation">Experimental Evaluation</h2>
+
+<ul>
+ <li>
+ <p>Semantic Loss is used in the semi-supervised setting for Permuted MNIST, Fashion MNIST and CIFAR-10.</p>
+ </li>
+ <li>
+ <p>The key takeaway is that using semantic loss improves the performance of the state-of-the-art models for Fashion MNIST and CIFAR-10.</p>
+ </li>
+ <li>
+ <p>One downside is that the effectiveness of the semantic loss in this type of constraint strongly depends on the performance of the underlying model. Further, the semantic loss does not improve the performance in case of fully supervised scenario.</p>
+ </li>
+ <li>
+ <p>Further experiments are performed to evaluate the performance of the semantic loss on complex constraints. Since these tasks aim to highlight the effect of using semantic loss, only simple models (MLPs) are evaluated.</p>
+ </li>
+</ul>
+
+<h2 id="tractability-of-semantic-loss">Tractability of Semantic Loss</h2>
+
+<ul>
+ <li>
+ <p>The semantic loss is similar to the automated reasoning task called as weight model counting (wmc).</p>
+ </li>
+ <li>
+ <p>Circuit compiler techniques can be used to compute wmc while allowing backpropagation.</p>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<ul>
+ <li>The proposed idea is simple and intuitive and the results on semi-supervised classification task are quite good. It would be interesting to extend and scale this method for more complex constraints.</li>
+</ul>
+
+
+
+
+ Hierarchical Graph Representation Learning with Differentiable Pooling
+
+ 2018-08-16T00:00:00-04:00
+ /site/2018/08/16/Hierarchical Graph Representation Learning with Differentiable Pooling
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Most existing GNN (Graph Neural Network) methods are inherently flat and are unable to process the information in a hierarchical manner.</p>
+ </li>
+ <li>
+ <p>The paper proposes a differentiable graph pooling operation, DIFFPOOL, that can generate hierarchical graph representations and can be easily plugged into many GNN architectures.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1806.08804">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="key-idea">Key Idea</h2>
+
+<ul>
+ <li>
+ <p>CNNs have spatial pooling operation that allows for deep CNN architectures to operate on coarse graph representations of input images.</p>
+ </li>
+ <li>
+ <p>This notion cannot be applied as-is to graphs as they do not have a natural notion of spatial locality like images do.</p>
+ </li>
+ <li>
+ <p>DIFFPOOL attempts to resolve this problem by learning a differentiable soft-assignment at each layer which is equivalent to pooling the cluster of nodes to obtain a sparse representation.</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>Given a graph <em>G(A, F)</em>, where <em>A</em> is the adjacency matrix and <em>F</em> is the feature matrix.</p>
+ </li>
+ <li>
+ <p>Given a permutation invariant GNN that follows the message passing architecture. The output of this GNN can be expressed as <em>Z = GNN(A, X)</em> where <em>X</em> is the current feature matrix.</p>
+ </li>
+ <li>
+ <p>Goal is to stack <em>L</em> GNN layers on top of each other such that the <em>l<sup>th</sup></em> layer uses coarsened output from the <em>(l-1)<sup>th</sup></em> layer.</p>
+ </li>
+ <li>
+ <p>This coarsening operation uses a cluster assignment matrix <em>S</em>.</p>
+ </li>
+ <li>
+ <p>The learned cluster assignment matrix at layer <em>l</em> is denoted at <em>S<sup>l</sup></em></p>
+ </li>
+ <li>
+ <p>Given <em>S<sup>l</sup></em>, the embedding matrix for the <em>(l+1)<sup>th</sup></em> layer is given as <em>transpose(S<sub>l</sub>)Z<sub>l</sub></em> and adjancecy matrix is given by <em>transpose(S<sub>l</sub>)A<sub>l</sub>S<sub>l</sub></em></p>
+ </li>
+ <li>
+ <p>A new GNN, called as GNN<sub>pool</sub> is used to produce the assignment matrix <em>S</em> by taking a softmax over <em>GNN<sub>pool</sub>(A<sup>l</sup>, X<sup>l</sup>)</em></p>
+ </li>
+ <li>
+ <p>As long as the GNN model is permutation invariant, the resulting DIFFPOOL model is also permutation invariant.</p>
+ </li>
+</ul>
+
+<h2 id="auxiliary-losses">Auxiliary Losses</h2>
+
+<ul>
+ <li>
+ <p>The paper uses 2 auxiliary losses to push the model away from spurious local minima early in the training.</p>
+ </li>
+ <li>
+ <p>Link prediction objective - at each layer, link prediction loss ( = A - S(transpose(S))) is minimized with the intuition that the nearby nodes should be pooled together.</p>
+ </li>
+ <li>
+ <p>Ideally, the cluster assignment for each node should be a one-hot vector so the entropy for cluster assignment per node is regularized.</p>
+ </li>
+</ul>
+
+<h2 id="baselines">Baselines</h2>
+
+<ul>
+ <li>GNN based models
+ <ul>
+ <li>GraphSage
+ <ul>
+ <li>Mean pooling</li>
+ <li>Set2Set pooling</li>
+ <li>Sort pooling</li>
+ </ul>
+ </li>
+ <li>Structure2vec</li>
+ <li>Edge conditioned filters in CNN</li>
+ <li>PatchySan</li>
+ </ul>
+ </li>
+ <li>Kernel based models
+ <ul>
+ <li>Graphlet, shortest path etc</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="model-variants">Model Variants</h2>
+
+<ul>
+ <li>GraphSage
+ <ul>
+ <li>Mean pool + Diff pool (3 or 2 layers)</li>
+ </ul>
+ </li>
+ <li>Structure2Vec + Diffpool</li>
+ <li>Diffpool-Det
+ <ul>
+ <li>The assignment matrix <em>S</em> are generated using graph clustering algorithms.</li>
+ </ul>
+ </li>
+ <li>Diffpool-NoLP
+ <ul>
+ <li>The link prediction objective function is turned off.</li>
+ </ul>
+ </li>
+ <li>At each DiffPool layer, the number of classes is set to 25% of the number of nodes before the DiffPool layer.</li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>DiffPool obtains the highest average performance across all the pooling approaches and improves upon the base GraphSage architecture by an average of around 7%.</p>
+ </li>
+ <li>
+ <p>In terms of runtime complexity, the paper reports that DiffPool does not incur any significant additional running time. But given that now there are 2 GNN models per layer, the size of the model should increase.</p>
+ </li>
+ <li>
+ <p>DiffPool can capture hierarchical community structure even when trained on just the graph classification loss.</p>
+ </li>
+ <li>
+ <p>One advantage of DiffPool is that the nodes are pooled in a non-uniform way so densely connected group of nodes would collapse into one cluster while sparsely connected nodes can retain their identity.</p>
+ </li>
+</ul>
+
+
+
+
+ Imagination-Augmented Agents for Deep Reinforcement Learning
+
+ 2018-08-08T00:00:00-04:00
+ /site/2018/08/08/Imagination-Augmented Agents for Deep Reinforcement Learning
+ <ul>
+ <li>
+ <p>The paper presents I2A (Imagination Augmented Agent) that combines the model-based and model-free approaches leading to data efficiency and robustness even with imperfect models.</p>
+ </li>
+ <li>
+ <p>I2A agent uses the predictions from a learned environment model as an additional context in deep policy networks. This leads to improved data efficiency and robustness to imperfect models.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1707.06203">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>I2A agent has two main modules - Imagination module and the Policy module.</p>
+ </li>
+ <li>
+ <p><strong>Imagination Module</strong></p>
+
+ <ul>
+ <li><strong>Environment Model</strong>
+ <ul>
+ <li>This is a recurrent model, trained in an unsupervised manner using the agent trajectories. It can be used to predict the future state given the current state and action.</li>
+ <li>The environment model can be rolled out multiple times to obtain a simulated trajectory or an “imagined” trajectory.</li>
+ <li>During each rollout, the actions are chosen using a rollout policy π<sub>r</sub>.</li>
+ </ul>
+ </li>
+ <li><strong>Rollout Encoder</strong>
+ <ul>
+ <li>A rollout encoder <em>E</em> (LSTM) is used to process the entire imagined rollout.</li>
+ </ul>
+ </li>
+ <li>The imagination module is used to generate <em>n</em> trajectories. Each trajectory is a sequence of outputs of the environment model.</li>
+ <li>These <em>n</em> trajectories are concatenated into a single “imagination” vector.</li>
+ <li>The training data for the environment model is generated from trajectories of a partially trained model-free agent.</li>
+ <li>Pretraining the environment model (instead of joint training with policy) leads to faster runtime.</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Policy Module</strong></p>
+
+ <ul>
+ <li>This module uses the output of both model-based path and model-free path as its input. It generates the policy vector and value function.</li>
+ </ul>
+ </li>
+ <li><strong>Rollout Strategy</strong>
+ <ul>
+ <li>One rollout is performed for each possible action in the environment ie, the first action in the i<sup>th</sup> rollout is the i<sup>th</sup> action in the action set.</li>
+ <li>Subsequent actions are generated using a shared rollout policy π<sub>’</sub></li>
+ <li>An effective strategy was to create a small model-free network π<sub>’</sub>(o<sub>t</sub>) and then add a KL loss component that encourages π<sub>’</sub>(o<sub>t</sub>)to be similar to the imagination augmented policy π(o<sub>t</sub>).</li>
+ </ul>
+ </li>
+ <li><strong>Baselines</strong>
+ <ul>
+ <li>Model-free agent</li>
+ <li>Copy-model agent - same as I2A but the environment model is replaced by a “copy” model that just returns the input observations.</li>
+ </ul>
+ </li>
+ <li><strong>Environments</strong>
+ <ul>
+ <li>Sokoban
+ <ul>
+ <li>Task is to push a number of boxes onto given target locations.</li>
+ <li>I2A outperforms the baselines and gains in performance as the number of unrolling steps increases (though at a diminishing rate).</li>
+ <li>In case of poor environment models, the agent seems to be able to ignore the later part of the rollout when the error starts to accumulate.</li>
+ <li>Monte Carlo search algorithm (without an explicit rollout encoder) performed poorly as compared to the model using rollout encoder.</li>
+ <li>Predicting the reward along with value function and action seems to speed up training.</li>
+ <li>If a near-perfect model is available, I2A agent’s performance can be improved by performing Monte Carlo search with the trained I2A agent for the rollout policy. The agent plays entire episodes in simulation and tries to find a successful action sequence within 10 retries.</li>
+ </ul>
+ </li>
+ <li><strong>MiniPacman</strong>
+ <ul>
+ <li>I2A agent is evaluated to see if a single model can be used to solve multiple tasks.</li>
+ <li>A new environment is designed to define multiple tasks in an environment with shared state transitions.</li>
+ <li>Each task is specified by a 5-dimensional reward vector that associates a reward with moving, eating food, eating a pill, eating a ghost and being eaten by a ghost.</li>
+ <li>A single environment model is trained to predict both observations (frames) and events (eg “eating a pill”). This way, the environment model is shared across all tasks.</li>
+ <li>Baseline agents and I2As are trained on each task separately. I2A architecture outperforms the standard agent in all tasks and the copy-model
+baseline in all but one task.</li>
+ <li>The improvement in performance is higher for tasks where rewards are sparse and where the anticipation
+of ghost dynamics is especially important indicating that the I2A agent can use the environment model to explore the environment more effectively.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Kronecker Recurrent Units
+
+ 2018-07-19T00:00:00-04:00
+ /site/2018/07/19/Kronecker Recurrent Units
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Recurrent Neural Networks have two key issues:</p>
+
+ <ul>
+ <li>
+ <p><strong>Over parameterization</strong> which increases the time for training and inference.</p>
+ </li>
+ <li>
+ <p><strong>Ill conditioned</strong> recurrent weight matrix which makes training difficult due to vanishing or exploding gradients.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The paper presents a flexible RNN model called as KRU (Kronecker Recurrent Units) which overcomes the above problems by using a Kronecker factored recurrent matrix and soft unitary constraints on the factors.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1705.10142">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="related-work">Related Work</h2>
+
+<h3 id="existing-solutions-for-overparameterization">Existing solutions for overparameterization</h3>
+
+<ul>
+ <li>
+ <p>Low-rank decomposition.</p>
+ </li>
+ <li>
+ <p>Training a neural network on the soft targets predicted by a big pre-trained network.</p>
+ </li>
+ <li>
+ <p>Low-bit precision training.</p>
+ </li>
+ <li>
+ <p>Hashing.</p>
+ </li>
+</ul>
+
+<h3 id="existing-solutions-for-vanishing-and-exploding-gradients">Existing solutions for vanishing and exploding gradients</h3>
+
+<ul>
+ <li>
+ <p>Gating mechanism like in LSTMs.</p>
+ </li>
+ <li>
+ <p>Gradient Clipping.</p>
+ </li>
+ <li>
+ <p>Orthogonal Weight Initialization.</p>
+ </li>
+ <li>
+ <p>Parameterizing recurrent weight matrix.</p>
+ </li>
+</ul>
+
+<h2 id="kru">KRU</h2>
+
+<ul>
+ <li>
+ <p>Uses a Kronecker factored recurrent matrix which enables controlling the number of parameters and number of factor matrices.</p>
+ </li>
+ <li>
+ <p>Vanishing and exploding gradients are taken care of by using a soft unitary constraint.</p>
+ </li>
+ <li>
+ <p>Why not use strict unitary constraint:</p>
+
+ <ul>
+ <li>
+ <p>Restricts the search space and makes learning process unstable.</p>
+
+ <ul>
+ <li>
+ <p>Makes forgetting (irrelevant) information difficult.</p>
+ </li>
+ <li>
+ <p>Relaxing the strict constraint has shown to improve the convergence speed and generalization performance.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>KRU can be easily plugged into RNNs, LSTMs and other variants.</p>
+ </li>
+ <li>
+ <p>The recurrent matrix <em>W</em> is paramterized as a kronecker product of <em>F</em> matrices <em>W<sub>0</sub>, …, W<sub>F-1</sub></em> where each <em>W<sub>f</sub></em> is a complex matrix of shape <em>P<sub>f</sub> x Q<sub>f</sub></em> and the product of all <em>P<sub>f</sub></em> and producto of all <em>Q<sub>f</sub></em> are both equal to <em>N</em>.</p>
+ </li>
+ <li>
+ <p>Why is <em>W</em> a complex matrix?</p>
+
+ <ul>
+ <li>
+ <p>In the real space, the set of all unitary matrices have the determinant as 1 or -1.</p>
+
+ <ul>
+ <li>
+ <p>Given that determinant is a continuous function, the unitary set in the real space is disconnected.</p>
+ </li>
+ <li>
+ <p>The unitary set in the complex space is connected as its determinants are points on the unit circle.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="soft-unitary-constraint">Soft Unitary Constraint</h3>
+
+<ul>
+ <li>
+ <table>
+ <tbody>
+ <tr>
+ <td>A soft unitary constraint is introduced in the form of regularization term</td>
+ <td> </td>
+ <td>W<sub>f</sub><sup>H</sup>W<sub>f</sub> - I</td>
+ <td> </td>
+ <td><sup>2</sup> (per kronecker factored recurrent matrix).</td>
+ </tr>
+ </tbody>
+ </table>
+ </li>
+ <li>
+ <p>If each of the Kronecker factors is unitary, the resulting matrix <em>W</em> would also be unitary.</p>
+ </li>
+ <li>
+ <p>It is computationally inefficient to apply this constraint over the recurrent matrix <em>W</em> itself as the complexity of the regularizer is given as <em>O(N<sup>3</sup>)</em>.</p>
+ </li>
+ <li>Use of Kronecker factorisation makes it computationally feasible to use this regulariser.</li>
+</ul>
+
+<h2 id="experiment">Experiment</h2>
+
+<ul>
+ <li>
+ <p>The Kronecker recurrent model is compared against the existing recurrent models for multiple tasks including copy memory, adding memory, pixel-by-pixel MNIST, char level language models, polyphonic music modelling, and framewise phoneme classification.</p>
+ </li>
+ <li>
+ <p>For most of the task, KRU model produces results comparable to the best performing models despite using fewer parameters.</p>
+ </li>
+ <li>
+ <p>Using soft unitary constraints in KRU provides a principled alternative to gradient clipping (a common heuristic to avoid exploding gradients).</p>
+ </li>
+ <li>
+ <p>Further, recent theoretical results suggest the gradient descent converges to a global optimizer of linear recurrent networks even if the learning problem is non-convex provided that the spectral norm of the recurrent matrix is bound by 1.</p>
+ </li>
+ <li>
+ <p>The key take away from the paper is that state should be high dimensional so that high capacity network can be used for encoding and decoding the input and output. The recurrent dynamics should be implemented via a low capacity model.s per task.</p>
+ </li>
+</ul>
+
+
+
+
+ Learning Independent Causal Mechanisms
+
+ 2018-07-11T00:00:00-04:00
+ /site/2018/07/11/Learning Independent Causal Mechanisms
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a very interesting approach for learning independent (inverse) data transformation from a set of transformed data points in an unsupervised manner.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1712.00961">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="formulation">Formulation</h2>
+
+<ul>
+ <li>
+ <p>We start with a given data distribution <em>P</em> (say the MNIST dataset) where each x ε R<sup>d</sup>.</p>
+ </li>
+ <li>
+ <p>Consider N transformations M<sub>1</sub>, …, M<sub>N</sub> (functions that map input x to transformed input x’). Note that N need not be known before hand.</p>
+ </li>
+ <li>
+ <p>These transformations can be thought of as independent (from other transformations) causal mechanisms.</p>
+ </li>
+ <li>
+ <p>Applying these transformation would give N new distributions Q<sub>1</sub>, …, Q<sub>N</sub>.</p>
+ </li>
+ <li>
+ <p>These individual distributions are combined to form a single transformed distribution Q which contains the union of samples from the individual distributions.</p>
+ </li>
+ <li>
+ <p>At training time, two datasets are created. One dataset corresponds to untransformed objects (sampled from <em>P</em>), referred to as <em>D<sub>P</sub></em>. The other dataset corresponds to samples from the transformed distribution <em>Q</em> and is referred to as <em>D<sub>Q</sub></em>.</p>
+ </li>
+ <li>
+ <p>Note that all the samples in <em>D<sub>P</sub></em> and <em>D<sub>Q</sub></em> are sampled independently and no supervising information is needed.</p>
+ </li>
+ <li>
+ <p>A series of N’ parametric models, called as experts, are initialized and would be trained to learn the different mechanisms.</p>
+ </li>
+ <li>
+ <p>For simplicity, assume that N = N’. If N > N’, some experts would learn more than one transformation or certain transformations would not be learnt. If N < N’, some experts would not learn anything or some experts would learn the same distribution. All of these cases can be diagnosed and corrected by changing the number of experts.</p>
+ </li>
+ <li>
+ <p>The experts are trained with the goal of maximizing an objective parameter <em>c</em>: R<sup>d</sup> to R. <em>c</em> takes high values on the support of <em>P</em> and low values outside.</p>
+ </li>
+ <li>
+ <p>During training, an example x<sub>Q</sub> (from D<sub>Q</sub>) is fed to all the experts at the same time. Each expert produces a value <em>c<sub>j</sub> = c(E<sub>j</sub>(x<sub>Q</sub>))</em></p>
+ </li>
+ <li>
+ <p>The winning expert is the one whose output is the max among all the outputs. Its parameters are updated to maximise its output while the other experts are not updated.</p>
+ </li>
+ <li>
+ <p>This forces the best performing model to become even better and hence specialize.</p>
+ </li>
+ <li>
+ <p>The objective <em>c</em> comes from adversarial training where a discriminator network discriminates between the untransformed input and the output of the experts.</p>
+ </li>
+ <li>
+ <p>Each expert can be thought of as a GAN that conditions on the input x<sub>Q</sub> (and not on a noise vector). The output of the different experts is fed to the discriminator which provides both a selection mechanism and the gradients for training the experts.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Experiments are performed on the MNIST dataset using the transformations like translation along 4 directions and along 4 diagonals, contrast shift and inversion.</p>
+ </li>
+ <li>
+ <p>The discriminator is further trained against the output of all the losing experts thereby furthering strengthing the winning expert.</p>
+ </li>
+</ul>
+
+<h3 id="approximate-identity-initialization">Approximate Identity Initialization</h3>
+
+<ul>
+ <li>
+ <p>The experts are initialized randomly and then pretrained to approximate the identity function by training with identical input-output pairs.</p>
+ </li>
+ <li>
+ <p>This ensures that the experts start from a similar level.</p>
+ </li>
+ <li>
+ <p>In practice, it seems necessary for the success of the proposed approach.</p>
+ </li>
+</ul>
+
+<h3 id="observations">Observations</h3>
+
+<ul>
+ <li>
+ <p>During the initial phase, there is a heavy competition between the experts and eventually different winners emerge for different transformations.</p>
+ </li>
+ <li>The approximate quality of reconstructed output was also evaluated using a downstream task.
+ <ul>
+ <li>3 type of inputs were created:
+ <ul>
+ <li>Untransformed images</li>
+ <li>Transformed images</li>
+ <li>Transformed images a being processed by experts.</li>
+ </ul>
+ </li>
+ <li>These inputs are fed to a pretrained MNISTN classifier.</li>
+ <li>The classifier performs poorly on the transformed images while the performance for images processed by experts quickly catches up with the performance on untransformed images.</li>
+ </ul>
+ </li>
+ <li>The experts E<sub>i</sub> generalize on the data points from a different dataset as well.
+ <ul>
+ <li>To test the generalisation capabilities of the expert, a sample of data from the omniglot dataset is transformed and fed to experts (which are trained only on MNIST).</li>
+ <li>Each expert consistently applies the same transformation even though the inputs are outside the training domain.</li>
+ <li>This suggests that the experts have generalized to different transformations irrespective of the underlying dataset.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="comments">Comments</h2>
+
+<ul>
+ <li>
+ <p>The experiments are quite limited in terms of complexity of dataset and complexity of transformation but it provides evidence for a promising connection between deep learning and causality.</p>
+ </li>
+ <li>
+ <p>Appendix mentions that in case there are too many experts, for most of the tasks, only one model specialises and the extra experts do not specialize at all. This is interesting as there is no explicit regularisation penalty which prevents the emergence of multiple experts per task.</p>
+ </li>
+</ul>
+
+
+
+
+ Memory-based Parameter Adaptation
+
+ 2018-07-04T00:00:00-04:00
+ /site/2018/07/04/Memory-Based Parameter Adaption
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Standard Deep Learning networks are not suitable for continual learning setting as the change in the data distribution leads to catastrophic forgetting.</p>
+ </li>
+ <li>
+ <p>The paper proposes Memory-based Parameter Adaptation (MbPA), a technique that augments a standard neural network with an episodic memory (containing examples from the previous tasks).</p>
+ </li>
+ <li>
+ <p>This episodic memory allows for rapid acquisition of new knowledge (corresponding to the current task) while preserving performance on the previous tasks.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1802.10542">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>MbPA consists of 3 components:</p>
+
+ <ul>
+ <li>Embedding Network <em>f</em></li>
+ <li>Memory <em>M</em></li>
+ <li>Output network <em>g</em></li>
+ </ul>
+ </li>
+ <li>
+ <p><em>f</em> and <em>g</em> are parametric components while <em>M</em> is a non-parametric component.</p>
+ </li>
+ <li>
+ <p><em>M</em> is a dynamically sized dictionary where the key represents the output of the embedding network and the value represents the desired output for a given input (input to the model).</p>
+ </li>
+ <li>
+ <p>When a new training tuple (x<sub>j</sub>, y<sub>j</sub>) is fed as input to the model, a key-value pair (h<sub>j</sub>, v<sub>j</sub>) is added to the memory. h<sub>j</sub> = f(x<sub>j</sub>)</p>
+ </li>
+ <li>
+ <p>The memory has a fixed size and acts as a circular buffer. When it gets filled up, earlier examples are dropped.</p>
+ </li>
+ <li>
+ <p>When accessing the memory using a key <em>h<sub>key</sub></em>, the k-nearest neighbours (in terms of distance from the given key) are retrieved.</p>
+ </li>
+</ul>
+
+<h2 id="training-phase">Training Phase</h2>
+
+<ul>
+ <li>During the training phase, the memory is only used to store the input examples and does not interfere with the training procedure.</li>
+</ul>
+
+<h2 id="testing-phase">Testing Phase</h2>
+
+<ul>
+ <li>
+ <p>During testing, the memory is used to adapt the parameters of the output network <em>g</em> while the embedding network <em>f</em> remains the same.</p>
+ </li>
+ <li>
+ <p>Given the input x, obtain the embedding corresponding to x and using that as the key, retrieve the k-nearest neighbours from the memory.</p>
+ </li>
+ <li>
+ <p>Each retrived neighbour is a tuple of the form (h<sub>k</sub>, v<sub>k</sub>, w<sub>k</sub>) where w<sub>k</sub> is propotional to the closeness between the input query and the key corresponding to the retrived example.</p>
+ </li>
+ <li>
+ <p>The collection of all the retrieved examples are referred to as the context <em>C</em>.</p>
+ </li>
+ <li>
+ <p>The parameters of the output network <em>g</em> are adapted from θ to θ<sub>x</sub> where θ<sub>x</sub> = θ + δ<sub>M</sub>(x, θ)</p>
+ </li>
+ <li>
+ <p>δ<sub>M</sub>(x, θ) is referred to as the contextual update of parameters of the output network.</p>
+ </li>
+</ul>
+
+<h2 id="interpretation-of-mbpa">Interpretation of MbPA</h2>
+
+<ul>
+ <li>
+ <p>MbPA can be interpreted as decreasing the weighted average of negative log likelihood over the retrieved neighbours in the context C.</p>
+ </li>
+ <li>
+ <p>The expression corresponding to δ<sub>M</sub>(x, θ) can be obtained by performing gradient descent to minimise the max a posterior over the context C.</p>
+ </li>
+ <li>
+ <p>The a posterior expression can be written as a sum of two terms - one corresponding to a weighted likelihood of data in the context C and the other corresponding to a regularisation term to prevent overfitting the data.</p>
+ </li>
+ <li>
+ <p>This idea can be thought of as a generalisation of attention. Attention can be viewed as fitting a constant function over the neighbourhood of memories while MbPA fits a more general function which is parameterised by the output network of the given model. Refer appendix E in the paper for further details.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>MbPA aims to solve the fundamental problem of enabling the model to deal with changes in data distribution.</p>
+ </li>
+ <li>
+ <p>In that sense, it is evaluated on a wide range of settings: continual learning, incremental learning, unbalanced datasets and change in data distribution at test time.</p>
+ </li>
+ <li>
+ <p>Continual Learning:</p>
+
+ <ul>
+ <li>
+ <p>In this setting, the model encounters a sequence of tasks and cannot revisit a previous task.</p>
+ </li>
+ <li>
+ <p>Permuted MNIST dataset was used.</p>
+ </li>
+ <li>
+ <p>The key takeaway is that once a task is catastrophically forgotten, only a few gradient updates on a carefully selected data, are sufficient to recover the performance.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Incremental Learning:</p>
+
+ <ul>
+ <li>
+ <p>In this setting, the model is trained on a subset of classes and then introduced to novel, unseen classes. The model is tested to see if it can incorporate the new knowledge while retaining the knowledge about the previous classes.</p>
+ </li>
+ <li>
+ <p>Imagenet dataset with Resnet V1 model is used. It is first pretrained on 500 classes and then fine-tuned to see how quickly could it adapt to new classes.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Unbalanced Dataset:</p>
+
+ <ul>
+ <li>This setting is similar to the incremental learning setting with the key difference that once the model has been trained on a part of the dataset and is to be finetuned to acquire new knowledge, the dataset used for finetuning is much smaller than the initial dataset thus creating the effect of unbalanced datasets.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Language Modelling:</p>
+
+ <ul>
+ <li>MbPA is used to adapt to the shift in the word distribution that is common to language modelling tasks. PTB and WikiText datasets were used.</li>
+ </ul>
+ </li>
+ <li>
+ <p>MbPA exhibits strong performance on all these tasks showing that the memory-based parameter adaption technique is effective across a range of tasks in supervised learning.</p>
+ </li>
+</ul>
+
+
+
+
+ Born Again Neural Networks
+
+ 2018-06-09T00:00:00-04:00
+ /site/2018/06/09/Born Again Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper explores knowledge distillation (KD) from the perspective of transferring knowledge between 2 networks of identical capacity.</p>
+ </li>
+ <li>
+ <p>This is in contrast to much of the previous work in KD which has focused on transferring knowledge from a larger network to a smaller network.</p>
+ </li>
+ <li>
+ <p>The paper reports that these Born Again Networks (BANs) outperform their teachers by significant margins in many cases.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1805.04770">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>The standard KD setting is as follows:
+ <ul>
+ <li>Start with an untrained network (or ensemble of networks) and train them for the given task. This network is referred to as the teacher network.</li>
+ <li>Now start with another untrained network (generally of smaller size than the teacher network) and train it using the output of the teacher network. This network is referred to as the student network.</li>
+ </ul>
+ </li>
+ <li>
+ <p>The paper augments this setting with an extra cross-entropy loss between the output of the teacher and the student networks. The student tried to predict the correct answer while matching the output distribution of the teacher.</p>
+ </li>
+ <li>
+ <p>The resulting student network is referred to as BAN - Born Again Network.</p>
+ </li>
+ <li>
+ <p>The same approach can be used multiple times (with diminishing returns) where the kth generation student is initialized by knowledge transfer from (k-1)th generation student.</p>
+ </li>
+ <li>The output of multiple generation BANs are combined via averaging to produce BANE (Born Again Network Ensemble).</li>
+</ul>
+
+<h2 id="dark-knowledge">Dark Knowledge</h2>
+
+<ul>
+ <li>
+ <p><a href="https://shagunsodhani.in/papers-I-read/Distilling-the-Knowledge-in-a-Neural-Network">Hinton et al</a> suggested that even when the output of the teacher network is incorrect, it contains useful information about the similarity between the output classes. This information is referred to as the “dark knowledge”.</p>
+ </li>
+ <li>
+ <p>The current paper observed that the gradient of the correct output dimension during distillation and normal supervised training resembles the original gradient up to a weight factor. This sample specific weight is defined by the value of the teacher’s max output.</p>
+ </li>
+ <li>
+ <p>This suggests distillation may be performing some kind of importance weighing. To explore this further, the paper considers 2 cases:</p>
+
+ <ul>
+ <li>
+ <p>Confidence Weighted By Teacher Max (CWTM) - where each example in the student’s loss function is weighted by the confidence that the teacher has on the prediction for that sample. The student incurs a higher loss if the teacher was more confident about the example.</p>
+ </li>
+ <li>
+ <p>Dark Knowledge with Permuted Predictions (DKPP) - The non-argmax output of teacher’s predictive distribution are permuted thus destroying the information about which output classes are related.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The key effect of these variations is that the covariance between the output classes is lost and classical knowledge distillation would not be sufficient to explain improvements (if any).</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="image-data">Image Data</h3>
+
+<ul>
+ <li>Datasets
+ <ul>
+ <li>CIFAR10</li>
+ <li>CIFAR100</li>
+ </ul>
+ </li>
+ <li>Baselines
+ <ul>
+ <li>ResNets</li>
+ <li>DenseNets</li>
+ </ul>
+ </li>
+ <li>BAN Variants
+ <ul>
+ <li>BAN-DenseNet and BAN-ResNet - Train a sequence of 2 or 3 BANs using DenseNets and ResNets. Different variants constrain BANs to be similar to their teacher or penalize l2-distance between student and teacher activations etc.</li>
+ <li>Two settings with CWTM and DKPP as explained earlier.</li>
+ <li>BAN-Resnet with DenseNet teacher and BAN-DenseNet with ResNet teacher</li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="text-data">Text Data</h3>
+
+<ul>
+ <li>Datasets:
+ <ul>
+ <li>PTB Dataset</li>
+ </ul>
+ </li>
+ <li>Baselines
+ <ul>
+ <li>CNN-LSTM model</li>
+ </ul>
+ </li>
+ <li>BAN Variant
+ <ul>
+ <li>LSTM</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>BAN student models improved over their teachers in most of the configurations.</li>
+ <li>Training BANs across multiple generations leads to saturating improvements.</li>
+ <li>The student models exhibit improvements even in the control settings (CWTM and DKPP).
+ <ul>
+ <li>One reason could be that the permutation procedure did not remove the higher order moments of output distribution.</li>
+ <li>Improvements in the CWTM model suggests that the pre-trained models can be used to rebalance the training set by giving lesser weight for samples where the teacher’s output distribution is more spread.</li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+
+ Net2Net-Accelerating Learning via Knowledge Transfer
+
+ 2018-05-21T00:00:00-04:00
+ /site/2018/05/21/Net2Net - Accelerating Learning via Knowledge Transfer
+ <h2 id="notes">Notes</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a simple yet effective approach for transferring knowledge from a trained neural network (referred to as the teacher network) to a large, untrained neural network (referred to as the student network).</p>
+ </li>
+ <li>
+ <p>The key idea is to use a function-preserving transformation that guarantees that for any given input, the output from the teacher network and the newly created student network would be the same.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1511.05641">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/paengs/Net2Net">Link to an implementation</a></p>
+ </li>
+ <li>
+ <p>The approach works as follows - Let us say that the teacher network was represented by the transformation <em>y = f(x, θ)</em> where <em>θ</em> refer to the parameters of the network. The task is to choose a new set of parameters <em>θ’</em> for the student network <em>g(x, θ’)</em> such that for all <em>x, f(x, θ) = g(x, θ’)</em></p>
+ </li>
+ <li>
+ <p>To start, we can assume that <em>f</em> and <em>g</em> are composed of standard linear layers. Layer <em>i</em> and <em>i+1</em> are represented by weights <em>W<sub>mxn</sub><sup>i</sup></em> and <em>W<sub>nxp</sub><sup>i+1</sup></em></p>
+ </li>
+ <li>
+ <p>We want to grow layer <em>i</em> to have <em>q</em> output units (where <em>q</em> > <em>n</em>) and layer <em>i+1</em> to have <em>q</em> input units. The new weight matrix would be <em>U<sub>mxq</sub><sup>i</sup></em> and <em>U<sub>qxp</sub><sup>i+1</sup></em></p>
+ </li>
+ <li>
+ <p>The first <em>q</em> columns (rows) of <em>W<sup>i</sup></em> (<em>W<sup>i+1</sup></em>) would be copied as it is into <em>U<sup>i</sup></em>(<em>U<sup>i+1</sup></em>).</p>
+ </li>
+ <li>
+ <p>For filling the remaining <em>n-q</em> slots, columns (rows) would be sampled randomly from <em>W<sup>i</sup></em> (<em>W<sup>i+1</sup></em>).</p>
+ </li>
+ <li>
+ <p>Finally, each layer in <em>U<sup>i</sup></em> is scaled by dividing by the corresponding replication factor to ensure that the output value of function remains unchanged by the operation.</p>
+ </li>
+ <li>
+ <p>Since convolutions can be seen as multiplication by a double block circulant matrix, the approach can be readily extended for convolutional networks.</p>
+ </li>
+ <li>
+ <p>The benefits of using this approach are the following:</p>
+
+ <ul>
+ <li>The newly created student network performs at least as good as the teacher network.</li>
+ <li>Any changes to the network are guaranteed to be an improvement.</li>
+ <li>It is safe to optimize all the parameters in the network.</li>
+ </ul>
+ </li>
+ <li>
+ <p>The variant discussed above is called the <strong>Net2WiderNet</strong> variant. There is another variant called<strong>Net2DeeperNet</strong> that enables the network to grow in depth.</p>
+ </li>
+ <li>
+ <p>In that case, a new matrix, <em>U</em>, initialized as the identity matrix, is added to the network. Note that unlike the <strong>Net2WiderNet</strong>, this approach would not work with arbitrary activation function between the layers.</p>
+ </li>
+</ul>
+
+<h2 id="strengths">Strengths</h2>
+
+<ul>
+ <li>
+ <p>The model can accelerate the training of neural networks, especially during development cycle when the designers try out different models.</p>
+ </li>
+ <li>
+ <p>The approach could potentially be used in life-long learning systems where the model is trained over a stream of data and needs to grow over time.</p>
+ </li>
+</ul>
+
+<h2 id="limitations">Limitations</h2>
+
+<ul>
+ <li>The function preserving transformations need to be worked out manually. Extra care needs to be taken when operations like concatenation or batch norm are present.</li>
+</ul>
+
+
+
+
+ Learning to Count Objects in Natural Images for Visual Question Answering
+
+ 2018-05-06T00:00:00-04:00
+ /site/2018/05/06/Learning to Count Objects in Natural Images for Visual Question Answering
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>Most of the visual question-answering (VQA) models perform poorly on the task of counting objects in an image. The main reasons are:
+ <ul>
+ <li>Most VQA models use a soft attention mechanism to perform a weighted sum over the spatial features to obtain a single feature vector. These aggregated features helps in most category of questions but seems to hurt for counting based questions.</li>
+ <li>For the counting questions, we do not have a ground truth segmentation of where the objects to be counted are present on the image. This limits the scope of supervision.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Additionally, we need to ensure that any modification in the architecture, to enhance the performance on the counting questions, should not degrade the performance on other classes of questions.</p>
+ </li>
+ <li>
+ <p>The paper proposes to overcome these challenges by using the attention maps (and not the aggregated feature vectors) as input to a separate <strong>count</strong> module.</p>
+ </li>
+ <li><a href="https://arxiv.org/abs/1802.05766">Link to the paper</a></li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<p>The basic idea is quite intuitive: when we perform weighted averaging based on different attention maps, we end up averaging the features corresponding to the difference instances of an object. This makes the feature vectors indistinguishable from the scenario where we had just one instance of the object in the image.</p>
+
+<p>Even multiple glimpses (multiple attention steps) can not resolve this problem as the weights given to one feature vector would not depend on the other feature vectors (that are attended to). Hard attention could be more useful than soft-attention but there is not much empirical evidence in support of this hypothesis.</p>
+
+<p>The proposed <strong>count</strong> module is a separate pipeline that can be integrated with most of the existing attention based VQA models without affecting the performance on non-count based questions.</p>
+
+<p>The inputs to the <strong>count</strong> module are the attention maps and the object proposals (coming from some pre-trained model like the RCNN model) and the output is an count-feature vector which is used to answer the count based question.</p>
+
+<p>The top level idea is the following - given the object proposals and the attention maps, create a graph where nodes are objects (object proposals) and edges capture how similar two object proposals are (how much do they overlap). The graph is transformed (by removing and scaling edges) so that the count of the object can be obtained easily.</p>
+
+<p>To explain their methodology, the paper simplifies the setting by making two assumptions:</p>
+<ul>
+ <li>The first assumption is that the attention weights are either 1 (when the object is present in the proposal) or 0 (when the object is absent from the proposal).</li>
+ <li>The second assumption is that any two object proposals either overlap completely (in which case, they are corresponding to the exact same object and hence receive the exact same weights) or the two proposals have zero overlap (in which case, they must be corresponding to completely different objects).</li>
+</ul>
+
+<p>These simplifying assumptions are made only for the sake of exposition and do not limit the capabilities of the <strong>count</strong> module.</p>
+
+<p>Given the assumptions, the task of the count module is to handle the exact duplicates to prevent double-counting of objects.</p>
+
+<p>As the first step, the attention weights (<strong>a</strong>) are used to generate an attention matrix (<strong>A</strong>) by performing an outer product between <strong>a</strong> and <strong>a<sup>T</sup></strong>. This corresponds to the step of creating a graph from the input.</p>
+
+<p><strong>A</strong> corresponds to the adjacency matrix of that graph. The attention weight for the <em>i<sup>th</sup></em> proposal corresponds to the <em>i<sup>th</sup></em> node in the graph and the edge between the nodes <em>i</em> and <em>j</em> has the weight <strong>a<sub>i</sub>*a<sub>j</sub></strong>.</p>
+
+<p>Also note that the graph is a weighted directed graph and the subgraph of vertices satisfying the condition <strong>a<sub>i</sub></strong> = 1 is a complete directed graph with self-loops. Given such a graph, the number of vertices, <em>V = sqrt(E)</em> where <em>E</em> could be computed by summing over the adjacency matrix.This implies that if the proposals are distinct, then the count can be obtained trivially by performing a sum over the adjacency matrix.</p>
+
+<p>The objective is now to eliminate the edges such that the underlying objects are the vertices of a complete subgraph. This requires removing two type of duplicate edges - intra-object edges and inter-object edges.</p>
+
+<p>Intra-object edges can be removed by computing a distance matrix, <strong>D</strong>, defined as 1 - IoU, where IoU matrix corresponds to the Intersection-over-Union matrix. A modified adjacency matrix <strong>A’</strong> is obtained by performing the element-wise product between f<sub>1</sub>(<strong>A</strong>) and f<sub>2</sub>(<strong>D</strong>) where f<sub>1</sub> and f<sub>2</sub> are piece-wise linear functions that are learnt via backpropogation.</p>
+
+<p>The inter-object edges are removed in the following manner:</p>
+
+<ul>
+ <li>Count the number of proposals that correspond of each instance of an object and then scale down the edges corresponding to the different instances by that number.</li>
+ <li>This creates the effect of reducing the weights of multiple proposals equivalent to a single proposal.</li>
+ <li>The number of proposals corresponding to an object is not available as an annotation in the training pipeline and is estimated based on the similarity between the different proposals (measured via the attention weights <strong>a</strong>, adjacency matrix <strong>A</strong> and distance matrix <strong>D</strong>).</li>
+ <li>The matrix corresponding to the similarity between proposals (<strong>sim<sub>i, j</sub></strong>) is transformed into a vector corresponding to the scaling factor of each node (<strong>s<sub>i</sub></strong>)</li>
+</ul>
+
+<p><strong>s</strong> can be converted into a matrix (by doing outer-product with itself) so as to scale both the incoming and the outgoing edges. The self edges (which were removed while computing <strong>A’</strong> are added back (after scaling with <strong>s</strong>) to obtain a new transformed matrix <strong>C</strong>.</p>
+
+<p>The transformed matrix <strong>C</strong> is a complete graph with self-loops where the nodes corresponds to all the relevant object instances and not to object proposals. The actual count can be obtained from <strong>C</strong> by performing a sum over all its values as described earlier. The original count problem was a regression problem but it is transformed into a classification problem to avoid scale issues. The network produces a <strong>k</strong>-hot <strong>n</strong>-dimensional vector called <strong>o</strong> where <strong>n</strong> is the number of object proposals that were feed into the module (and hence the upper limit on upto how large a number could the module count). In the ideal setting, <strong>k</strong> should be one, as the network would produce an integer value but in practice, the network produces a real number so <strong>k</strong> can be upto 2. If <strong>c</strong> is an exact integer, the output is a 1-hot vector with the value in index corresponding to <strong>c</strong> set to 1. If <strong>c</strong> is a real number, the output is a linear interpolation between two one-hot vectors (the one-hot vectors correspond to the two integers between which <strong>c</strong> lies).</p>
+
+<p><strong>count</strong> module supports computing the confidence of a prediction by defining two variables p<sub><strong>a</strong></sub> and p<sub><strong>D</strong></sub> which compute the average distance of f<sub>6</sub>(<strong>a</strong>) and $f<sub>7</sub>(<strong>D</strong>) from 0.5. The final output <strong>o’</strong> is defined as f<sub>8</sub>(p<sub><strong>a</strong></sub> + p<sub><strong>D</strong></sub>) . <strong>o</strong></p>
+
+<p>All the different f functions are piece wise linear functions and are learnt via backpropagation.</p>
+
+<h2 id="experiments">Experiments</h2>
+
+<p>The authors created a new category of count-based questions by filtering the number-type questions to remove questions like “What is the time right now”. These questions do have a neumerical answer but do not fall under the purview of count based questions and hence are not targeted by the <strong>count</strong> model.</p>
+
+<p>The authors augmented a state of the art <a href="https://arxiv.org/abs/1704.03162">VQA model</a> with their <strong>count</strong> module and show substantial gains over the count-type questions for the <a href="https://arxiv.org/abs/1612.00837">VQA-v2 dataset</a>. This augmentation does not drastically impact the performance on non-count questions.</p>
+
+<p>The overall idea is quite crisp and intutive and the paper is easy to follow. It would be even better if there were some more abalation studies. For example, why are the piece-wise linear functions assumed to have 16 linear components? Would a smaller or larger number be better?</p>
+
+
+
+
+ Neural Message Passing for Quantum Chemistry
+
+ 2018-04-08T00:00:00-04:00
+ /site/2018/04/08/Neural Message Passing for Quantum Chemistry
+ <h1 id="introduction">Introduction</h1>
+
+<ul>
+ <li>
+ <p>The paper presents a general message passing architecture called as Message Passing Neural Networks (MPNNs) that unify various existing models for performing supervised learning on molecules.</p>
+ </li>
+ <li>
+ <p>Variants of the MPNN model achieve very good performance on the task of predicting the property of the molecules.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1704.01212">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h1 id="mpnn">MPNN</h1>
+
+<h2 id="setting">Setting</h2>
+
+<ul>
+ <li>
+ <p>The input to the model is an undirected graph <em>G</em> where node features are represented as <em>x<sub>v</sub></em> (corresponding to node <em>v</em>) and edge features are <em>e<sub>v, w</sub></em> (corresponding to edge between nodes <em>v, w</em>).</p>
+ </li>
+ <li>
+ <p>The idea is to learn a representation (or feature vector) for all the nodes (and possibly edges) in the graph and use that for the downstream supervised learning task.</p>
+ </li>
+ <li>
+ <p>The model can be easily extended to the setting of directed graphs.</p>
+ </li>
+ <li>
+ <p>The model works in 2 phases:</p>
+ </li>
+</ul>
+
+<h2 id="message-passing-phase">Message Passing Phase</h2>
+
+<ul>
+ <li>
+ <p>All nodes send a <em>message</em> to their neighbouring nodes. The message is a function of the feature vectors corresponding to the sender node (or vertex), the receiver node and the edge connecting the two nodes. The feature vectors can be combined to form the message using the <em>message function</em> which can be implemented as a neural network.</p>
+ </li>
+ <li>
+ <p>Once a node has received messages from all its neighbours, it updated its feature vector by aggregating all the message. The function used to aggregate and update the feature vector is called as the <em>update function</em> and can be implemented as a neural network.</p>
+ </li>
+ <li>
+ <p>After updating the feature vectors, the graph could initiate another round of message passing. After a sufficient number of message passing rounds, the Readout phase is invoked.</p>
+ </li>
+</ul>
+
+<h2 id="readout-phase">Readout Phase</h2>
+
+<ul>
+ <li>
+ <p>The feature vectors corresponding to different nodes in the graph are aggregated into a single feature vector (corresponding to the feature vector of the graph) using the <em>readout function</em>.</p>
+ </li>
+ <li>
+ <p>The <em>readout function</em> can also be implemented using a neural network with the condition that it is invariant to the permutation of the nodes within the graph (to ensure that the MPNN is independent of the graph isomorphism).</p>
+ </li>
+</ul>
+
+<h1 id="existing-variants-in-literature">Existing Variants in literature</h1>
+
+<ul>
+ <li>The paper provides various examples where the existing architectures could be explained in terms of the message passing framework. This includes examples like <a href="https://arxiv.org/abs/1509.09292">Convolutional Networks on Graphs for Learning Molecular Fingerprints</a>, <a href="https://arxiv.org/abs/1511.05493">
+Gated Graph Sequence Neural Networks</a>, <a href="http://tkipf.github.io/graph-convolutional-networks/">Graph Convolutional Networks</a> etc.</li>
+</ul>
+
+<h1 id="experiments">Experiments</h1>
+
+<h2 id="setup">Setup</h2>
+
+<ul>
+ <li>
+ <p>Broadly speaking, the task is to predict the properties of given molecules (regression problem).</p>
+ </li>
+ <li>
+ <p>The QM9 dataset consists of 130K molecules whose properties have been measured using Quantum Mechanical Simulations (DFT).</p>
+ </li>
+ <li>
+ <p>Properties to be predicted include atomization energy, enthalpy, highest fundamental vibrational frequency etc.</p>
+ </li>
+ <li>
+ <p>There are two benchmarks for error:</p>
+
+ <ul>
+ <li>
+ <p>DFT Error - Estimated average error of DFT approximation</p>
+ </li>
+ <li>
+ <p>Chemical Accuracy - As established by the chemistry community</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="model">Model</h2>
+
+<ul>
+ <li>
+ <p>Following variants of <em>message function</em> are explored:</p>
+
+ <ul>
+ <li>
+ <p>Matrix multiplication between <em>A<sub>evw</sub></em> and <em>h<sub>v</sub></em> where <em>A</em> is the adjacency matrix <em>h<sub>v</sub></em> is the feature corresponding to node <em>v</em>.</p>
+ </li>
+ <li>
+ <p>Edge Network which is same as matrix multiplication case with the difference that <em>A</em> is a learned matrix for each edge type.</p>
+ </li>
+ <li>
+ <p>Pair Network where the feature vector corresponding to the source node, target node and edge is fed to a neural network.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="virtual-elements">Virtual Elements</h2>
+
+<ul>
+ <li>
+ <p>Since all messages are shared via edges, it could take a long time for the message to move between two ends of the graph. To fasten this process, virtual elements are provided.</p>
+ </li>
+ <li>
+ <p>In the first setting, “virtual edges” are inserted between nodes.</p>
+ </li>
+ <li>
+ <p>In the second setting, a “master” node connects to all the other nodes.</p>
+ </li>
+</ul>
+
+<h2 id="message-passing-complexity">Message Passing Complexity</h2>
+
+<ul>
+ <li>
+ <p>In a graph with <em>n</em> nodes and <em>d</em> dimensional feature vectors, a single step of message passing would have the worst case time complexity of <em>O(n<sup>2</sup>d<sup>2</sup></em>.</p>
+ </li>
+ <li>
+ <p>This complexity can be reduced by breaking the <em>d</em> dimensional embedding into <em>k</em> different groups of <em>d/k</em> embeddings which can be updated in parallel. The complexity of the modified approach is <em>O(n<sup>2</sup>d<sup>2</sup>/k</em>.</p>
+ </li>
+</ul>
+
+<h1 id="results">Results</h1>
+
+<ul>
+ <li>
+ <p>Best performing MPNN model uses edge network as the <em>message function</em> and <a href="https://arxiv.org/abs/1511.06391">set2set</a> as the <em>readout function</em>.</p>
+ </li>
+ <li>
+ <p>Using group of embeddings helps to improve generalization. This effect could also be because of ensemble-like nature of the modified architecture.</p>
+ </li>
+ <li>
+ <p>The model performs worse without the virtual elements.</p>
+ </li>
+</ul>
+
+<h1 id="takeaways">Takeaways</h1>
+
+<ul>
+ <li>
+ <p>Long range interaction between vertices is necessary.</p>
+ </li>
+ <li>
+ <p>Scaling to larger molecule sizes is challenging because the model creates a fully connected graph by incorporating virtual elements.</p>
+ </li>
+</ul>
+
+
+
+
+ Unsupervised Learning by Predicting Noise
+
+ 2018-04-02T00:00:00-04:00
+ /site/2018/04/02/Unsupervised Learning By Predicting Noise
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Convolutional Neural Networks are extremely good feature extractors in the sense that features extracted for one task (say image classification) can be easily transferred to another task (say image segmentation).</p>
+ </li>
+ <li>
+ <p>Existing unsupervised approaches do not aim to learn discriminative features and supervised approaches for discriminative features do not scale well.</p>
+ </li>
+ <li>
+ <p>The paper presents an approach to learn features in an unsupervised setting by using a set of target representations called as Noise As Target (NAT) which acts as a kind of proxy supervising signal.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1704.05310">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<h3 id="unsupervised-setting">Unsupervised Setting</h3>
+
+<ul>
+ <li>Given a collection of image X (x<sub>1</sub>, x<sub>2</sub>, …, x<sub>n</sub>), we want to learn a parameterized mapping <em>f</em> such that <em>f(x<sub>i</sub>)</em> gives the features of image <em>x<sub>i</sub></em>. We would jointly learn the target vectors <em>y<sub>i</sub></em> (more on it later).</li>
+</ul>
+
+<h3 id="loss-function">Loss Function</h3>
+
+<ul>
+ <li>Squared L2 norm is used as the distance measure while making sure that final activations are unit normalized.</li>
+</ul>
+
+<h3 id="fixed-target-representation">Fixed Target Representation</h3>
+
+<ul>
+ <li>
+ <p>In the setting of the problem where we are learning both the features and the target representation, a trivial solution would be the one where all the input images map to the same target and are assigned the same representation. No discriminative features are learned in this case.</p>
+ </li>
+ <li>
+ <p>To avoid such situations, a set of k predefined target representations are chosen and each image is mapped to one of these k representations (based on the features).</p>
+ </li>
+ <li>
+ <p>There is an assumption that k > n so that each image is assigned a different target.</p>
+ </li>
+ <li>
+ <p>One simple choice of target representation is the standard one-hot vector which implies that all the class (and by extension, the associated images) are orthogonal and equidistant from each other. But this is not a reasonable approximation as not all the image pairs are equally similar or dissimilar.</p>
+ </li>
+ <li>
+ <p>Instead, the target vectors are uniformly sampled from a d-dimensional unit sphere, where d is the dimensionality of the feature representation. That is, the idea is to map the features to the manifold of the d-dimensional L2 sphere by using the K predefined representations as for the discrete approximation of the manifold.</p>
+ </li>
+ <li>
+ <p>Since each data point (image) is mapped to a new point on the manifold, the algorithm is suited for online training as well.</p>
+ </li>
+</ul>
+
+<h3 id="optimisation">Optimisation</h3>
+
+<ul>
+ <li>
+ <p>For the training, the number of target K is reduced to the number of images n and an assignment matrix P is learned which ensures that the mapping between the image to target is 1-to-1.</p>
+ </li>
+ <li>
+ <p>The resulting optimisation equation can be solved using the Hungarian Algorithm but at a high-cost O(n^3). An optimisation is to take a batch of b images and update the square matrix P<sub>B</sub> for dimension bXb (made of the images and their corresponding targets). This reduces the overall complexity of O(nb^2).</p>
+ </li>
+ <li>
+ <p>Other optimisation techniques, that are common to supervised learning, like batch norm used in this setting as well.</p>
+ </li>
+</ul>
+
+<h3 id="implementation-detail">Implementation Detail</h3>
+
+<ul>
+ <li>
+ <p>Used AlexNet with NATs to train the unsupervised model.</p>
+ </li>
+ <li>
+ <p>An MLP is trained on these features to learn the classifier.</p>
+ </li>
+ <li>
+ <p>Standard preprocessing techniques like random cropping/flipping are used.</p>
+ </li>
+</ul>
+
+<h3 id="experimental-details">Experimental Details</h3>
+
+<ul>
+ <li>
+ <p>Dataset</p>
+
+ <ul>
+ <li>
+ <p>ImageNet for training the AlexNet architecture with the proposed approach.</p>
+ </li>
+ <li>
+ <p>Pascal VOC 2007 for transfer learning experiments.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Baselines</p>
+
+ <ul>
+ <li>
+ <p>Unsupervised approaches like autoencoder, GAN, BiGAN</p>
+ </li>
+ <li>
+ <p>Self-supervised</p>
+ </li>
+ <li>
+ <p>SOTA models using hand-made features SIFT with Fisher Vector.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="observation">Observation</h2>
+
+<ul>
+ <li>
+ <p>Using squared loss instead of softmax does not deteriorate the performance too much.</p>
+ </li>
+ <li>
+ <p>The authors compare the effect of using discrete vs continuous target representations for transfer learning. For the discrete representation, elements of the canonical basis of a k-dimensional space (k=1000, 10000, 100000) are used. Experiments demonstrate that d-dimensional continuous vectors perform much better than the discrete vectors.</p>
+ </li>
+ <li>
+ <p>While training the unsupervised network, its features were extracted after every 20 iterations to evaluate the performance on transfer learning task. The test accuracy increases up to around 100 iterations then saturate.</p>
+ </li>
+ <li>
+ <p>Comparing the visualization of the first convolutional layer filters (for AlexNet with and without supervision) shows that while unsupervised filters are less sharp, they maintain the edge and orientation information.</p>
+ </li>
+ <li>
+ <p>The proposed unsupervised method outperforms all the unsupervised baselines and is competitive with respect to the supervised baseline. But it is still far behind the model using handcrafted features.</p>
+ </li>
+ <li>
+ <p>For transfer learning, on Pascal VOC, the proposed approach beats the supervised baseline and works at par with the supervised approach.</p>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<ul>
+ <li>
+ <p>The paper proposed a simple unsupervised framework for learning discriminative features without having to rely on proxy tasks like image generation and without having to make an assumption about the input domain.</p>
+ </li>
+ <li>
+ <p>The key aspect of the proposed approach is that each image is assigned to a unique point in the d-dimensional manifold which means 2 images could be very close to each other on the manifold while being quite distinct in reality. It is interesting to see that such a simple strategy is able to give such good results.</p>
+ </li>
+</ul>
+
+
+
+
+ The Lottery Ticket Hypothesis - Training Pruned Neural Networks
+
+ 2018-03-25T00:00:00-04:00
+ /site/2018/03/25/The Lottery Ticket Hypothesis - Training Pruned Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Empirical evidence indicates that at training time, the neural networks need to be of significantly larger size than necessary.</p>
+ </li>
+ <li>
+ <p>The paper purposes a hypothesis called the <em>lottery ticket hypothesis</em> to explain this behaviour.</p>
+ </li>
+ <li>
+ <p>The idea is the following - Successful training of a neural network depends on a <em>lucky</em> random initialization of a subcomponent of the network. Such components are referred to as <em>lottery tickets</em>.</p>
+ </li>
+ <li>
+ <p>Larger networks are more likely to have these <em>lottery tickets</em> and hence are easier to train.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1803.03635">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="methodology">Methodology</h2>
+
+<ul>
+ <li>
+ <p>Various aspects of the hypothesis are explored empirically.</p>
+ </li>
+ <li>
+ <p>Two tasks are considered - MNIST and XOR.</p>
+ </li>
+ <li>
+ <p>For each task, the paper considers networks of different sizes and empirically shows that larger networks are more likely to converge (or have better performance) for a fixed number of epochs as compared to the smaller networks.</p>
+ </li>
+ <li>
+ <p>Given a large, trained network, some weights (or units) of the network are pruned and the resulting network is reset to its initial random weights.</p>
+ </li>
+ <li>
+ <p>The resulting network is the <em>lottery-ticket</em> in the sense that when the pruned network is trained, it is more likely to converge than an otherwise randomly initialised network of the same size. Further, it is more likely to match the original, larger network in terms of performance.</p>
+ </li>
+ <li>
+ <p>The paper explores different aspects of this experiment:</p>
+
+ <ul>
+ <li>Pruning Strategies:
+ <ul>
+ <li>One-shot strategy prunes the network in one-go while the iterative strategy prunes the network iteratively.</li>
+ <li>Though the latter is computationally more intensive, it is more likely to find a lottery ticket.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Size of the pruned network affects the speed of convergence when training the <em>lottery ticket</em>.</p>
+ </li>
+ <li>
+ <p>If only the architecture or only the initial weights of the <em>lottery ticket</em> are used, the resulting network tends to converge more slowly and achieves a lower level of performance.</p>
+ </li>
+ <li>This indicates that the lottery ticket depends on both the network architecture and the weight initialization.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="discussion">Discussion</h2>
+
+<ul>
+ <li>
+ <p>The paper includes some more interesting experiments. For instance, the distribution of the initialization in the weights that survived the pruning suggests that small weights from before training tend to remain small after training.</p>
+ </li>
+ <li>
+ <p>One interesting experiment would be to show the performance of the pruned network before resetting its weights and retraining again. This performance should be compared with the performance of the initial large network and the performance of the <em>lottery ticket</em> after training.</p>
+ </li>
+ <li>
+ <p>Overall, the experiments are not sufficient to conclude anything about the correctness of the hypothesis. The proposition itself is very interesting and could enhance our understanding of how the neural networks work.</p>
+ </li>
+</ul>
+
+
+
+
+ Cyclical Learning Rates for Training Neural Networks
+
+ 2018-03-18T00:00:00-04:00
+ /site/2018/03/18/Cyclical Learning Rates for Training Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Conventional wisdom says that when training neural networks, learning rate should monotonically decrease. This insight forms the basis of the different type of adaptive learning rates.</p>
+ </li>
+ <li>
+ <p>Counter to this expected behaviour, the paper demonstrates that using a cyclical learning rate (CLR), varying between a minimum and a maximum value, helps to train the neural network faster without requiring fine-tuning of learning rate.</p>
+ </li>
+ <li>
+ <p>The paper also provides a simple approach to estimate the lower and upper bound for CLR.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1506.01186">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/bckenstler/CLR">Link to the implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="intution">Intution</h2>
+
+<ul>
+ <li>
+ <p>Difficulty in minimizing the loss arises from saddle points and not from local minima. <a href="http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf">[Ref]</a></p>
+ </li>
+ <li>
+ <p>Increasing the learning rate allows for rapid traversal of saddle points.</p>
+ </li>
+ <li>
+ <p>Alternatively, the optimal learning rate is expected to be between bounds of CLR and thus the learning rate would always be close to the optimal learning rate.</p>
+ </li>
+</ul>
+
+<h2 id="parameter-estimation">Parameter Estimation</h2>
+
+<ul>
+ <li>
+ <p>Cycle Length = Number of iterations till learning rate returns to the initial value = 2 * step_size</p>
+ </li>
+ <li>
+ <p>step_size should be set to 2-10 times the number of iterations in an epoch.</p>
+ </li>
+ <li>
+ <p>Estimating the CLR boundary values:</p>
+
+ <ul>
+ <li>
+ <p>Run the model for several epochs while increasing the learning rate between the allowed low and high values.</p>
+ </li>
+ <li>
+ <p>Plot accuracy vs learning rate and note the learning rate values when the accuracy starts to fall.</p>
+ </li>
+ <li>
+ <p>This gives a good candidate value for upper and lower bound. Alternatively, the lower bound could be set to be 1/3 or 3/4 of the upper bound. But it is difficult to judge if the model has run for the sufficient number of epochs in the first place.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<ul>
+ <li>The idea in itself is very simple and straight-forward to add to any existing model which makes it very appealing.</li>
+ <li>The author has experimented with various architectures and datasets (from vision domain) and has reported faster training results.</li>
+</ul>
+
+
+
+
+ Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning
+
+ 2018-03-11T00:00:00-05:00
+ /site/2018/03/11/Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Information Extraction - Given a query to be answered and an external search engine, information extraction entails the task of issuing search queries, extracting information from new sources and reconciling the extracted values till we are sufficiently confident about the extracted values.</p>
+ </li>
+ <li>
+ <p>The paper proposes the use of Reinforcement Learning (RL) to solve this task.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1603.07954">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/karthikncode/DeepRL-InformationExtraction">Implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="key-aspect">Key Aspect</h2>
+
+<ul>
+ <li>Use of Reinforcement Learning to resolve the ambiguity inherent in the textual documents.</li>
+ <li>Given a query, the RL agent would use template statement to formulate the queries (to be performed on the black box search engine). It would further resolve and combine the result for the query from the set of retrieved documents.</li>
+</ul>
+
+<h2 id="datasets">Datasets</h2>
+
+<ul>
+ <li>Database of Mass Shootings in the United States.</li>
+ <li>Food Shield database of illegal food adulteration.</li>
+</ul>
+
+<h2 id="framework">Framework</h2>
+
+<ul>
+ <li>
+ <p>Information extraction task is modelled as a Markov Decision Process (MDP) <S, A, T, R></p>
+ </li>
+ <li><strong>S</strong> - Set of all possible states
+ <ul>
+ <li>The state consists of:
+ <ul>
+ <li>Extractor’s confidence in predicted entity values.</li>
+ <li>Context from which values are extracted.</li>
+ <li>Similarity between the new document (extracted just now from the search engine) and the original document accompanying the given query.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li><strong>A</strong> - Set of all possible actions
+ <ul>
+ <li>Reconciliation decision - d
+ <ul>
+ <li>Accept all entities values.</li>
+ <li>Reject all entities values.</li>
+ <li>Stop the current episode.</li>
+ </ul>
+ </li>
+ <li>Query choice - q
+ <ul>
+ <li>Choose the next query from a set of automatically generated alternatives.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li><strong>R</strong> - Rewards
+ <ul>
+ <li>Maximise the final extraction accuracy while minimising the number of queries.</li>
+ </ul>
+ </li>
+ <li><strong>Q</strong> - Queries
+ <ul>
+ <li>Generated using a template.</li>
+ <li>The query is searched on a search engine and the top k links are retrieved.</li>
+ </ul>
+ </li>
+ <li><strong>Transition</strong>
+ <ul>
+ <li>Start with a single source article x<sub>i</sub> and extract the initial set of entities.</li>
+ <li>At each timestep, the agent is given the state (s) on basis of which it chooses the action (d, q). The episode stops whenever the action is a stop action.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Deep Q Network is used.</p>
+ </li>
+ <li>Parameters are learned using SGD and RMSProp.</li>
+</ul>
+
+<h2 id="experimental-setup">Experimental Setup</h2>
+
+<h3 id="extraction-model">Extraction Model</h3>
+
+<ul>
+ <li>Max Entropy Classifier is used as the base extraction system.</li>
+ <li>First, all the words in the document are tagged as one of the entity types and the mode of these values is used to obtain the set of extracted entities.</li>
+</ul>
+
+<h3 id="baseline">Baseline</h3>
+
+<ul>
+ <li>Basic Extractors</li>
+ <li>Aggregation System which either chooses the entity value with the highest confidence or takes a majority vote over all extracted values.</li>
+ <li>Meta-Classifier which operates over the same input state space and produces the same set of reconciliation decisions as the DQN.</li>
+ <li>Oracle Extractor which is computed assuming perfect reconciliation and query decisions on the top of the Maxnet base extractor.</li>
+</ul>
+
+<h3 id="rl-models">RL Models</h3>
+
+<ul>
+ <li>RL Basic - Only reconciliation decision.</li>
+ <li>RL Query - Only query decision with a fixed reconciliation strategy.</li>
+ <li>RL Extract - the full system with both reconciliation and query decision.</li>
+</ul>
+
+<h2 id="result">Result</h2>
+
+<ul>
+ <li>RL Extract obtains substantial gains eg up to 11% over Maxnet.</li>
+ <li>Simple aggregation schemes do not handle the task well.</li>
+ <li>In terms of reward structure, providing rewards after each step works better than a single delayed reward.</li>
+</ul>
+
+
+
+
+ An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
+
+ 2018-03-05T00:00:00-05:00
+ /site/2018/03/05/An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p><em>Catastrophic Forgetting</em> refers to the phenomenon where when a learning system is trained on two tasks in succession, it may forget how to perform the first task.</p>
+ </li>
+ <li>
+ <p>The paper investigates this behaviour for different learning activations in presence and absence of dropout.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1312.6211">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/goodfeli/forgetting">Link to the implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="experiment-formulation">Experiment Formulation</h2>
+
+<ul>
+ <li>
+ <p>For each experiment, two tasks are defined - “old” task and “new” task.</p>
+ </li>
+ <li>
+ <p>The network is first trained on the “old” task until the validation set error has not improved for the last 100 epochs.</p>
+ </li>
+ <li>
+ <p>The “best” performing model is then trained for the “new” task until the combined error on the “old” and the “new” validation datasets has not improved in the last 100 epochs.</p>
+ </li>
+ <li>
+ <p>All the tasks used the same model architecture - 2 hidden layers followed by a softmax layer.</p>
+ </li>
+ <li>Following activations were tested:
+ <ul>
+ <li>Sigmoid</li>
+ <li>ReLU</li>
+ <li>Hard Local Winner Takes It All</li>
+ <li>Maxout</li>
+ </ul>
+ </li>
+ <li>
+ <p>Models were trained using SGD with or without dropout.</p>
+ </li>
+ <li>
+ <p>For each combination of the model, activation and the training mechanism, a random hyper param search was performed with set of 25 hyperparams.</p>
+ </li>
+ <li>The authors took care to keep the hyperparams and other settings consistent and comparable across different experiments. Deviations, wherever applicable, and their reasons were documented.</li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>In terms of the relationship between the “old” and the “new” tasks, three kinds of settings are considered:</p>
+
+ <ul>
+ <li>
+ <p>The tasks are very very similar but the input is processed in a different format. For this setting, MNIST dataset was used with a different permutation of pixels for the “old” and the “new” task.</p>
+ </li>
+ <li>
+ <p>The tasks are similar but not exactly the same. For this setting, the task was to predict sentiments of reviews across 2 different product categories.</p>
+ </li>
+ <li>
+ <p>In the last setting, 2 dissimilar tasks were used. One task was to predict sentiment of reviews and another task was to perform classification over MNIST dataset (reduced to 2 classes).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Using Dropout improved the overall validation performance for all the models for all the tasks.</p>
+ </li>
+ <li>
+ <p>Using Dropout also increase the size of the optimal model across all the activations indicating that maybe the increased size of the model could explain the increased resistance to forgetting. It would have been interesting to check if dropout always selected the largest model possible given the set of the hyperparams.</p>
+ </li>
+ <li>
+ <p>On the dissimilar task, dropout improved the performance while reducing the model size so it might have other properties as well that helps to prevent forgetting.</p>
+ </li>
+ <li>
+ <p>As compared to the choice of training technique, the activation function has a less consistent effect on resistance to forgetting. The paper recommends performing cross-validation for the choice of the activation function. If that is not feasible, maxout activation function with dropout could be used.</p>
+ </li>
+</ul>
+
+
+
+
+ Learning an SAT Solver from Single-Bit Supervision
+
+ 2018-02-24T00:00:00-05:00
+ /site/2018/02/24/Learning a SAT Solver from Single-Bit Supervision
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents NeuroSAT, a message passing neural network that is trained to predict if a given SAT can be solved. As a side effect of training, the model also learns how to solve the SAT problem itself without any extra supervision.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1802.03685">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="background">Background</h2>
+
+<ul>
+ <li>
+ <p>Given an expression in the propositional logic, the task is to predict if there exists a substitution of variables that make the expression true.</p>
+ </li>
+ <li>
+ <p>The expression itself can be written as a conjunction of disjunctions (“and” over “or”) where each conjunct is called a clause and each variable within a clause is called a literal.</p>
+ </li>
+ <li>
+ <p>Invariants</p>
+
+ <ul>
+ <li>
+ <p>The variables or clauses or literals (within the clauses) can be permuted.</p>
+ </li>
+ <li>
+ <p>Every occurrence of a variable can be negated.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="model">Model</h2>
+
+<ul>
+ <li>
+ <p>Given the SAT problem, create an undirected graph of literals, their negations and the clauses they belong to.</p>
+ </li>
+ <li>
+ <p>Put an edge between every literal and the clause to which it belongs and another kind of edge between every literal and its negation.</p>
+ </li>
+ <li>
+ <p>Perform message passing between nodes to obtain vector representations corresponding to each node. Specifically, first, each clause received a message from its neighbours (literals) and updates its embeddings. Then every literal receives a message from its neighbours (both literals and clauses) and updates its embeddings.</p>
+ </li>
+ <li>
+ <p>After T iterations, the nodes vote to decide the prediction of the model as a whole.</p>
+ </li>
+ <li>
+ <p>The model is trained end-to-end using the cross-entropy loss between logit and the true label.</p>
+ </li>
+ <li>
+ <p>Permutation invariance is ensured by operating on the nodes and the edges in the topological order and negation invariance is ensured by treating all literals as the same.</p>
+ </li>
+</ul>
+
+<h2 id="decoding-satisfying-assignment">Decoding Satisfying Assignment</h2>
+
+<ul>
+ <li>
+ <p>The most interesting aspect of this work is that even though the model was trained to predict if the SAT problem can be satisfied, it is actually possible to extract the correct assignment from the classifier.</p>
+ </li>
+ <li>
+ <p>In the early iterations, all the nodes vote “unsolvable” with low confidence. Then a few nodes start voting “solvable” and then a phase transition happens where most of the nodes start voting “solvable” with high confidence.</p>
+ </li>
+ <li>
+ <p>The model never becomes highly confident that problem is “unsolvable” and almost never guesses “solvable” on an “unsolvable” problem. So in some sense, the model is looking for the combination of literals that actually solves the problem.</p>
+ </li>
+ <li>
+ <p>The authors found that the 2 dimensional PCA projections of the literal embeddings are initially mixed up but become more and more linearly separable as the phase transition happens.</p>
+ </li>
+ <li>
+ <p>Based on this insight, the authors propose to obtain cluster centres C1 and C2, partition the variables according to the cluster centres and then try assignments from both the partitions.</p>
+ </li>
+ <li>
+ <p>This alone provides a satisfying solution in over 70% of the cases when though there is no explicit supervising signal about how to solve the problem.</p>
+ </li>
+ <li>
+ <p>The other strengths of the paper includes</p>
+
+ <ul>
+ <li>
+ <p>Generalizing to longer and more difficult SAT problems (than those seen during training).</p>
+ </li>
+ <li>
+ <p>Generalizing to another kind of search problems like graph colouring, clique detection etc (over small random graphs).</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>The paper also reports that by adding supervising signal about which clauses in the given expression are unsatisfiable, it is possible to decode the literals which prove the “unsatisfiability” of an expression at test time. Though not a lot of details have been provided about this part and would probably be covered in the next iteration of the paper.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Neural Relational Inference for Interacting Systems
+
+ 2018-02-17T00:00:00-05:00
+ /site/2018/02/17/Neural Relational Inference for Interacting Systems
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents Neural Relational Inference (NRI) model which can infer underlying interactions in a dynamical system in an unsupervised manner, using just the observational data in terms of the trajectories.</p>
+ </li>
+ <li>
+ <p>For instance, consider a simulated system where the particles are connected to each other by springs. The observational data does not explicitly specify which particles are connected to each other and only contains information like position and velocity of each particle at different timesteps.</p>
+ </li>
+ <li>
+ <p>The task is to explicitly infer the interaction structure (in this example, which pair of particles are connected to each other) while learning the dynamical model of the system itself.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1802.04687">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/ethanfetaya/nri">Link to the implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="model">Model</h2>
+
+<ul>
+ <li>
+ <p>The model consists of an encoder that encodes the given trajectories into an interaction graph and a decoder that decodes the dynamical model given the interaction graph.</p>
+ </li>
+ <li>
+ <p>The model starts by assuming that a full connected interaction graph exists between the objects in the system.</p>
+ </li>
+ <li>
+ <p>For this latent graph <strong>z</strong>, <em>z<sub>i, j</sub></em> denotes the (discrete) edge type between object <em>v<sub>i</sub></em> and <em>v<sub>j</sub></em> with the assumption that there are <em>K</em> edge types.</p>
+ </li>
+ <li>
+ <p>The object <em>v<sub>i</sub></em> has a feature vector <em>x<sub>i</sub><sup>t</sup></em> associated with it at time <em>t</em>. This feature vector captures information like location and velocity.</p>
+ </li>
+</ul>
+
+<h3 id="encoder">Encoder</h3>
+
+<ul>
+ <li>
+ <p>A Graph Neural Network (GNN) acts on the fully connected latent graph <em>z</em>, performs message passing from node to node via edges and predicts the discrete label for each edge.</p>
+ </li>
+ <li>
+ <p>The GNN architecture may itself use MLPs or ConvNets and returns a factorised distribution over the edge types <em>q<sub>φ</sub>(z|x)</em>.</p>
+ </li>
+</ul>
+
+<h3 id="decoder">Decoder</h3>
+
+<ul>
+ <li>
+ <p>The decoder is another GNN (with separate params for each edge type) that predicts the future dynamics of the system and returns <em>p<sub>θ</sub>(x|z)</em>.</p>
+ </li>
+ <li>The overall model is a VAE that optimizes the ELBO given as:</li>
+ <li>
+ <p>E<sub>q<sub>φ</sub>(z|x)</sub>[log p<sub>θ</sub>(x|z)] − KL[q<sub>φ</sub>(z|x)||p<sub>θ</sub>(z)]</p>
+ </li>
+ <li>
+ <p><em>p<sub>θ</sub>(x)</em> is the prior which is assumed to be uniform distribution over the edge types.</p>
+ </li>
+ <li>
+ <p>Instead of predicting the dynamics of the system for just the next timestep, the paper chooses to use the prediction multiple steps (10) in the future. This ensures that the interactions can have a significant effect on the dynamics of the system.</p>
+ </li>
+ <li>In some cases, like real humans playing a physical sport, the dynamics of the system need not be Markovian and a recurrent decoder is used to model the time dependence.</li>
+</ul>
+
+<h2 id="pipeline">Pipeline</h2>
+
+<ul>
+ <li>
+ <p>Given the dynamical system, run the encoder to obtain <em>q<sub>φ</sub>(z|x)</em>.</p>
+ </li>
+ <li>
+ <p>Sample <em>z<sub>i, j</sub></em> from <em>q<sub>φ</sub>(z|x)</em>.</p>
+ </li>
+ <li>
+ <p>Run the decoder to predict the future dynamics for the next T timesteps.</p>
+ </li>
+ <li>
+ <p>Optimise the ELBO loss.</p>
+ </li>
+ <li>
+ <p>Note that since the latent variables (edge labels) are discrete in this case, the sampling is done from a continuous approximation of the discrete distribution and reparameterization trick is applied over this discrete approximation to get the (biased) gradients.</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>Experiments are performed using simulated systems like particles connected to springs, phase coupled oscillators and charged particles and using real-world data like CMU Motion Capture database and NBA tracking data.</p>
+ </li>
+ <li>
+ <p>The NRI system effectively predicts the dynamics of the systems and is able to reconstruct the ground truth interaction graph (for simulated systems).</p>
+ </li>
+</ul>
+
+
+
+
+ Stylistic Transfer in Natural Language Generation Systems Using Recurrent Neural Networks
+
+ 2018-02-11T00:00:00-05:00
+ /site/2018/02/11/Stylistic Transfer in Natural Language Generation Systems Using Recurrent Neural Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li><a href="https://aclweb.org/anthology/W/W16/W16-6010.pdf">This workshop paper</a> explores the problem of style transfer in natural language generation (NLG).</li>
+ <li>One possible manifestation would be rewriting technical articles in an easy-to-understate manner.</li>
+</ul>
+
+<h2 id="challenges">Challenges</h2>
+
+<ul>
+ <li>Identifying relevant stylistic cues and using them to control text generation in NLG systems.</li>
+ <li>Absence of a large amount of training data.</li>
+</ul>
+
+<h2 id="pitch">Pitch</h2>
+
+<ul>
+ <li>Using Recurrent Neural Networks (RNNs) to disentangle the style from semantic content.</li>
+ <li>Autoencoder model with two components - one for learning style and another for learning content.</li>
+ <li>This allows for “style” component to be replaced while keeping the “content” component same, resulting in a style transfer.</li>
+ <li>One way to think about this is - the encoder generates a 100-dimensional vector. In this, the first 50 entries, correspond to the “style” component and remaining to the “content” component.</li>
+ <li>The proposal is that the loss function should be modified to include a cross-covariance term for ensuring disentanglement.</li>
+ <li>I think one way of doing this is to have two loss functions:
+ <ul>
+ <li>The <strong>first loss</strong> function ensures that the input sentence is decoded properly into the target sentence. This loss is computed for each sentence.</li>
+ <li>The <strong>second loss</strong> ensures that the first 50 entries across all the encoded represenations are are correlated. This loss operates at the batch level.</li>
+ <li>The <strong>total loss</strong> is the weighted sum of these 2 losses.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="possible-datasets">Possible Datasets</h2>
+
+<ul>
+ <li><a href="http://norvig.com/ngrams/shakespeare.txt">Complete works of Shakespeare</a></li>
+ <li><a href="https://www.kaggle.com/c/wikichallenge/data">Wikpedia Kaggle dataset</a></li>
+ <li><a href="https://ota.ox.ac.uk/">Oxford Text Archive</a></li>
+ <li>Twitter data</li>
+</ul>
+
+<h2 id="possible-metrics">Possible Metrics</h2>
+
+<ul>
+ <li>Soundness - is the generated text entailed with the input sentence.</li>
+ <li>Coherence - free of grammatical errors, proper word usage etc.</li>
+ <li>Effectiveness - how effective was the style transfer</li>
+ <li>Since some of the metrics are subjective, human evaluators also need to be employed.</li>
+</ul>
+
+
+
+
+ Get To The Point - Summarization with Pointer-Generator Networks
+
+ 2018-02-05T00:00:00-05:00
+ /site/2018/02/05/Get To The Point-Summarization with Pointer-Generator Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p><a href="https://gist.github.com/shagunsodhani/a2915921d7d0ac5cfd0e379025acfb9f">Sequence-to-Sequence models</a> have made abstract summarization viable but they still suffer from issues like <em>out of vocabulary</em> words and repetitive sentences.</p>
+ </li>
+ <li>
+ <p>The paper proposes to overcome these limitations by using a hybrid Pointer-Generator network (to copy words from the source text) and a <em>coverage</em> vector that keeps track of content that has already been summarized so as to discourage repetition.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1704.04368">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/abisee/pointer-generator">Code</a></p>
+ </li>
+</ul>
+
+<h2 id="model">Model</h2>
+
+<h3 id="pointer-generator-network">Pointer Generator Network</h3>
+
+<ul>
+ <li>
+ <p>It is a hybrid model between the Sequence-to-Sequence network and <a href="https://shagunsodhani.in/papers-I-read/Pointer-Networks">Pointer Network</a> such that when generating a word, the model decides whether the word would be generated using the softmax vocabulary (Sequence-to-Sequence) or using the source vocabulary (Pointer Network).</p>
+ </li>
+ <li>
+ <p>Since the model can choose a word from the source vocabulary, the issue of <em>out of vocabulary</em> words is handled.</p>
+ </li>
+</ul>
+
+<h3 id="coverage-mechanism">Coverage Mechanism</h3>
+
+<ul>
+ <li>
+ <p>The model maintains a <em>coverage</em> vector which is the sum of attention distributions over all previous decoder timesteps.</p>
+ </li>
+ <li>
+ <p>This <em>coverage</em> vector is fed as an input to the attention mechanism.</p>
+ </li>
+ <li>
+ <p>A <em>coverage loss</em> is added to prevent the model from repeatedly attending to the same word.</p>
+ </li>
+ <li>
+ <p>The idea is to capture how much coverage different words have already received from the attention mechanism.</p>
+ </li>
+</ul>
+
+<h2 id="observation">Observation</h2>
+
+<ul>
+ <li>
+ <p>Model when evaluated on CNN/Daily Mail summarization task, outperforms the state-of-the-art by at least 2 ROUGE points though it still does not outperform the lead-3 baseline.</p>
+ </li>
+ <li>
+ <p>Lead-3 baseline uses first 3 sentences as the summary of the article which should be a strong baseline given that the dataset is actually about news articles.</p>
+ </li>
+ <li>
+ <p>The model is initially trained without coverage and then finetuned with the coverage loss.</p>
+ </li>
+ <li>
+ <p>During training, the model first learns how to copy words and then how to generate words (p<sup>gen</sup> starts from 0.3 and converges to 0.53).</p>
+ </li>
+ <li>
+ <p>During testing, the model strongly prefers copying over generating (p<sup>gen</sup> = 0.17).</p>
+ </li>
+ <li>
+ <p>Further, whenever the model is at beginning of sentences or at the join between switched-together fragments, it prefers to generate a word instead of copying one from the source language.</p>
+ </li>
+ <li>
+ <p>The overall model is very simple, neat and interpretable and also performs well in practice.</p>
+ </li>
+</ul>
+
+
+
+
+ StarSpace - Embed All The Things!
+
+ 2018-01-29T00:00:00-05:00
+ /site/2018/01/29/StarSpace - Embed All The Things
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper describes a general purpose neural embedding model where different type of entities (described in terms of discrete features) are embedded in a common vector space.</p>
+ </li>
+ <li>
+ <p>A similarity function is learnt to compare these entities in a meaningful way and score their similarity. The definition of the similarity function could depend on the downstream task where the embeddings are used.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1709.03856">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><a href="https://github.com/facebookresearch/StarSpace">Link to the implementation</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>Each entity is described as a set of discrete features. For example, for the recommendation use case, the users may be described as a bag-of-words of movies they have liked. For the search use case, the document may be described as a bag-of-words of words they are made up of.</p>
+ </li>
+ <li>
+ <p>Given a dataset and a task at hand, generate a set of positive samples <em>E = (a, b)</em> such that <em>a</em> is the input to the task (from the dataset) and <em>b</em> is the expected label(answer/entity) for the given task.</p>
+ </li>
+ <li>
+ <p>Similarly, generate another set of negative samples <em>E <sup>-</sup> = (a, b<sub>i</sub><sup>-</sup>)</em> such that <em>b<sub>i</sub><sup>-</sup></em> is one of the incorrect label(answer/entity) for the given task. The incorrect entity can be sampled randomly from the set of candidate entities. Multiple incorrect samples could be generated for each positive example. These incorrect samples are indexed using <em>i</em>.</p>
+ </li>
+ <li>
+ <p>For example, in case of supervised learning problem like document classification, <em>a</em> would be one of the documents (probably described in terms of words), <em>b</em> is the correct label and <em>b<sub>i</sub><sup>-</sup>)</em> is one of the randomly sampled label from set of all the labels (excluding the correct label).</p>
+ </li>
+ <li>
+ <p>In case of collaborative filtering, <em>a</em> would be the user (either described as a discrete entity like a userid or in terms of items purchased so far), <em>b</em> is the next item the user purchases and <em>b<sub>i</sub><sup>-</sup>)</em> is one of the randomly sampled item from the set of all the items.</p>
+ </li>
+ <li>
+ <p>A similarity function is chosen to compare the representation of entities of type <em>a</em> and <em>b</em>. The paper considered cosine similarity and inner product and observed that cosine similarity works better for the case with a large number of entities.</p>
+ </li>
+ <li>
+ <p>A loss function compares the similarity between positive pairs <em>(a, b)</em> and <em>(a, b<sub>i</sub><sup>-</sup>)</em>. The paper considered margin ranking loss and negative log loss of softmax and reported that margin ranking loss works better.</p>
+ </li>
+ <li>
+ <p>The norm of embeddings is capped at 1.</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>The same model architecture is applied to a variety of tasks including multi-class classification, multi-label classification, collaborative filtering, content-based recommendation, link prediction, information retrieval, word embeddings and sentence embeddings.</p>
+ </li>
+ <li>
+ <p>The model provides a strong baseline on all the tasks and performs at par with much more complicated and task-specific networks.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Emotional Chatting Machine - Emotional Conversation Generation with Internal and External Memory
+
+ 2018-01-22T00:00:00-05:00
+ /site/2018/01/22/Emotional Chatting Machine-Emotional Conversation Generation with Internal and External Memory
+ <ul>
+ <li>
+ <p>The paper proposes ECM (Emotional Chatting Machine) which can generate both semantically and emotionally appropriate responses in a dialogue setting.</p>
+ </li>
+ <li>
+ <p>More specifically, given an input utterance or dialogue and the desired emotional category of the response, ECM is to generate an appropriate response that conforms to the given emotional category.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1704.01074">Link to the paper</a></p>
+ </li>
+ <li>
+ <p>Much of the recent, deep learning based work on conversational agents has focused on the use of encoder-decoder framework where the input utterance (given sequence of words) is mapped to a response utterance (target sequence of words). This is the so-called seq2seq family of models.</p>
+ </li>
+ <li>
+ <p>ECM model can sit within this framework and introduces 3 new components:</p>
+
+ <ul>
+ <li><strong>Emotion Category Embedding</strong>
+ <ul>
+ <li>Embed the emotion categories into a real-valued, low-dimensional vector space.</li>
+ <li>These embeddings are used as input to the decoder and are learnt along with rest of the model.</li>
+ </ul>
+ </li>
+ <li><strong>Internal Memory</strong>
+ <ul>
+ <li>Physiological, emotional responses are relatively short-lived and involve changes.</li>
+ <li>ECM accounts for this effect by adding an Internal Memory which captures this dynamics of emotions during decoding.</li>
+ <li>It starts with “full” emotions in the beginning and keeps decaying the emotion value over time.</li>
+ <li>How much of the emotion value is to be decayed is determined by a sigmoid gate.</li>
+ <li>By the time the sentence is decoded, the value becomes zero, signifying that the emotion has been completely expressed.</li>
+ </ul>
+ </li>
+ <li><strong>External Memory</strong>
+ <ul>
+ <li>Emotional responses are expected to carry emotionally strong words along with generic, neutral words.</li>
+ <li>An external memory is used to include the emotionally strong words explicitly by using 2 non-overlapping vocabularies - <em>generic</em> vocabulary and the <em>emotion</em> vocabulary (read from the external memory).</li>
+ <li>Both these vocabularies are assigned different generation probabilities and an output gate controls the weights of <em>generic</em> and <em>emotion</em> words.</li>
+ <li>This way the <em>emotion</em> words are included in an otherwise neutral response.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Loss function</strong></p>
+
+ <ul>
+ <li>The first component is the cross-entropy loss between predicted and target token distribution.</li>
+ <li>A regularization term on internal memory to make sure the emotional state decays to 0 at the end of the decoding process.</li>
+ <li>Another regularization term on external memory to supervise the probability of selection of a <em>generic</em> vs <em>emotion</em> word.</li>
+ </ul>
+ </li>
+ <li><em>*Dataset</em>
+ <ul>
+ <li>STC Dataset (~220K posts and ~4300K responses) annotated by the emotional classifier. Any error on the part of the classifier degrades the quality of the training dataset.</li>
+ <li>NLPCC Dataset - Emotion classification dataset with 23105 sentences.</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Metric</strong></p>
+
+ <ul>
+ <li>Perplexity to evaluate the model at the content level.</li>
+ <li>Emotion accuracy to evaluate the model at the emotional level.</li>
+ </ul>
+ </li>
+ <li>
+ <p>ECM achieves a perplexity of 65.9 and emotional accuracy of 0.773.</p>
+ </li>
+ <li>
+ <p>Based on human evaluations, ECM statistically outperforms the seq2seq baselines on both naturalness (likeliness of response being generated by a human) and emotion accuracy.</p>
+ </li>
+ <li>
+ <p>Notes</p>
+
+ <ul>
+ <li>It is an interesting idea to let the sigmoid gate decide how the emotion “value” be spent while decoding. It seems similar to the idea of how much do we want to “attend” to the emotion value the key difference being that your total attention is limited. It would be interesting to see the shape of the distribution of how much of the emotion value is spent at each decoding time step. If the curve is highly biased towards say using most of the emotion value towards the end of the decoding process, maybe another regularisation term is needed to ensure a more balanced distribution of how the emotion is spent.</li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Exploring Models and Data for Image Question Answering
+
+ 2018-01-14T00:00:00-05:00
+ /site/2018/01/14/Exploring Models and Data for Image Question Answering
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p><strong>Problem Statement</strong>: Given an image, answer a given question about the image.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1505.02074">Link to the paper</a></p>
+ </li>
+ <li>
+ <p><strong>Assumptions</strong>:</p>
+ <ul>
+ <li>The answer is assumed to be a single word thereby bypassing the evaluation issues of multi-word generation tasks.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="vis-lstm-model">VIS-LSTM Model</h2>
+
+<ul>
+ <li>Treat the input image as the first word in the question.</li>
+ <li>Obtain the vector representation (skip-gram) for words in the question.</li>
+ <li>Obtain the VGG Net embeddings of the image and use a linear transformation (dimensionality reduction weight matrix) to match the dimensions of word embeddings.</li>
+ <li>Keep image embedding frozen during training and use an LSTM to combine the word vectors.</li>
+ <li>LSTM outputs are fed into a softmax layer which generates the answer.</li>
+</ul>
+
+<h2 id="dataset">Dataset</h2>
+
+<ul>
+ <li>DAtaset for QUestion Ansering on Real-world images (DAQUAR)
+ <ul>
+ <li>1300 images and 7000 questions with 37 object classes.</li>
+ <li>Downside is that even guess work can yield good results.</li>
+ </ul>
+ </li>
+ <li>The paper proposed an algorithm for generating questions using MS-COCO dataset.
+ <ul>
+ <li>Perform preprocessing steps like breaking large sentences and changing indefinite determines to definite ones.</li>
+ <li><em>object</em> questions, <em>number</em> questions, <em>colour</em> questions and <em>location</em> questions can be generated by searching for nouns, numbers, colours and prepositions respectively.</li>
+ <li>Resulting dataset has ~120K questions across above 4 semantic types.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="models">Models</h2>
+
+<ul>
+ <li>VIS+LSTM - explained above</li>
+ <li>2-VIS+BLSTM - Add the image features twice, in beginning and in the end (using different linear transformations) plus use bidirectional LSTM</li>
+ <li>IMG+BOW - Multinomial logistic regression on image features without dimensionality reduction + bag of words (averaging word vectors).</li>
+ <li>FULL - Simple average of above 2 models.</li>
+</ul>
+
+<h3 id="baseline">Baseline</h3>
+
+<ul>
+ <li>Includes models where the answer is guessed, or only image or question features are used or image features along with prior knowledge of object are used.</li>
+ <li>Also includes a KNN model where the system finds the nearest (image, question) pair.</li>
+</ul>
+
+<h3 id="metrics">Metrics</h3>
+
+<ul>
+ <li>Accuracy</li>
+ <li>Wu-Palmer similarity measure</li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>The VIS-LSTM model outperforms the baselines while the FULL model benefits from averaging across all the models.</li>
+ <li>Some useful information seems to be lost when downsizing the VGG vectors.</li>
+ <li>Fine tuning the word vectors helps with performance.</li>
+ <li>Normalising CNN hidden image features into zero mean and unit variance leads to faster training.</li>
+ <li>Model does not perform well on the task of considering spatial relations between multiple objects and counting objects when multiple objects are present</li>
+</ul>
+
+
+
+
+ How transferable are features in deep neural networks
+
+ 2018-01-06T00:00:00-05:00
+ /site/2018/01/06/How transferable are features in deep neural networks
+ <h1 id="introduction">Introduction</h1>
+
+<ul>
+ <li>
+ <p>When neural networks are trained on images, they tend to learn the same kind of features for the first layer (corresponding to Gabor filters or colour blobs). The first layer features are “general” irrespective of the task/optimizer etc.</p>
+ </li>
+ <li>
+ <p>The final layer features tend to be “specific” in the sense that they strongly depend on the task.</p>
+ </li>
+ <li>
+ <p>The paper studies the transition of generalization property across layers in the network. This could be useful in the domain of transfer learning where features are reused across tasks.</p>
+ </li>
+ <li>
+ <p><a href="http://papers.nips.cc/paper/5347-how-transferable-are-features-in-deep-neural-networks.pdf">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h1 id="setup">Setup</h1>
+
+<ul>
+ <li>
+ <p>Degree of generality of a set of features, learned on task A, is defined as the extent to which these features can be used for another task B.</p>
+ </li>
+ <li>
+ <p>Randomly split 1000 ImageNet classes into 2 groups (corresponding to tasks A and B). Each group has 500 classes and half the total number of examples.</p>
+ </li>
+ <li>
+ <p>Two 8-layer convolutional networks are trained on the two datasets and labelled as baseA and baseB respectively.</p>
+ </li>
+ <li>
+ <p>Now choose a layer numbered n from {1, 2…7}.</p>
+ </li>
+ <li>
+ <p>For each layer n, train the following two networks:</p>
+
+ <ul>
+ <li><strong>Selffer Network BnB</strong>
+ <ul>
+ <li>Copy (and freeze) first n layers from baseB. The remaining layers are initialized randomly and trained on B.</li>
+ <li>This serves as the control group.</li>
+ </ul>
+ </li>
+ <li><strong>Transfer Network AnB</strong>
+ <ul>
+ <li>Copy (and freeze) first n layers from baseA. The remaining layers are initialized randomly and trained on B.</li>
+ <li>This corresponds to transferring features from A to B.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>If AnB performs well, n<sup>th</sup> layer features are “general”.</p>
+ </li>
+ <li>
+ <p>In another setting, the transferred layers are also fine-tuned (BnB<sup>+</sup> and AnB<sup>+</sup>).</p>
+ </li>
+ <li>
+ <p>ImageNet dataset contains a hierarchy of classes which allow for creating the datasets A and B with high and low similarity.</p>
+ </li>
+</ul>
+
+<h1 id="observation">Observation</h1>
+
+<h2 id="dataset-a-and-b-are-similar">Dataset A and B are similar</h2>
+
+<ul>
+ <li>
+ <p>For n = {1, 2}, the performance of the BnB model is same as baseB model. For n = {3, 4, 5, 6}, the performance of BnB model is worse.</p>
+ </li>
+ <li>
+ <p>This indicates the presence of “fragile co-adaption” features on successive layers where features interact with each other in a complex way and can not be easily separated across layers. This is more prominent across middle layers and less across the first and the last layers.</p>
+ </li>
+ <li>
+ <p>For model AnB, the performance of baseB for n = {1, 2}. Beyond that, the performance begins to drop.</p>
+ </li>
+ <li>
+ <p>Transfer learning of features followed by fine-tuning gives better results than training the network from scratch.</p>
+ </li>
+</ul>
+
+<h2 id="dataset-a-and-b-are-dissimilar">Dataset A and B are dissimilar</h2>
+
+<ul>
+ <li>Effectiveness of feature transfer decreases as the two tasks become less similar.</li>
+</ul>
+
+<h2 id="random-weights">Random Weights</h2>
+
+<ul>
+ <li>
+ <p>Instead of using transferred weights in BnB and BnA, the first n layers were initialized randomly.</p>
+ </li>
+ <li>
+ <p>The performance falls for layer 1 and 2. It further drops to near-random level for layers 3 and beyond.</p>
+ </li>
+ <li>
+ <p>Another interesting insight is that even for dissimilar tasks, transferring features is better than using random features.</p>
+ </li>
+</ul>
+
+
+
+
+ Distilling the Knowledge in a Neural Network
+
+ 2017-12-31T00:00:00-05:00
+ /site/2017/12/31/Distilling the Knowledge in a Neural Network
+ <h1 id="introduction">Introduction</h1>
+
+<ul>
+ <li>
+ <p>In machine learning, it is common to train a single large model (with a large number of parameters) or ensemble of multiple smaller models using the same dataset.</p>
+ </li>
+ <li>
+ <p>While such large models help to improve the performance of the system, they also make it difficult and computationally expensive to deploy the system.</p>
+ </li>
+ <li>
+ <p>The paper proposes to transfer the knowledge from such “cumbersome” models into a single, “simpler” model which is more suitable for deployment. This transfer of knowledge is referred to as “distillation”.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1503.02531">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h1 id="idea">Idea</h1>
+
+<ul>
+ <li>
+ <p>Train the cumbersome model using the given training data in the usual way.</p>
+ </li>
+ <li>
+ <p>Train the simpler, distilled model using the class probabilities (from the cumbersome model) as the soft target. Thus, the simpler model is trained to generalise the same way as the cumbersome model.</p>
+ </li>
+ <li>
+ <p>If the soft targets have high entropy, they provide much more information than the hard targets and the gradient (between training examples) would vary lesser.</p>
+ </li>
+ <li>
+ <p>One approach is to minimise the L2 difference between logits produced by the cumbersome model and the simpler model. This approach was pursued by <a href="https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf">Buciluǎ et al.</a></p>
+ </li>
+ <li>
+ <p>The paper proposes a more general solution which they name “distillation”. The temperature of the final softmax is increased till the cumbersome model produces a set of soft targets (from the final softmax layer). These soft targets are then used to train the simpler model.</p>
+ </li>
+ <li>
+ <p>It also shows that the proposed approach is, in fact, a more general case of the first approach.</p>
+ </li>
+</ul>
+
+<h1 id="approach">Approach</h1>
+
+<ul>
+ <li>
+ <p>In the simplest setting, the cumbersome model is first trained with a high value of temperature and then the same temperature value is used to train the simpler model. The temperature is set to 1 when making predictions using the simpler model.</p>
+ </li>
+ <li>
+ <p>It helps to add an auxiliary objective function which corresponds to the cross-entropy loss with the correct labels. The second objective function should be given a much lower weight though. Further, the magnitude of the soft targets needs to be scaled by multiplying with the square of temperature.</p>
+ </li>
+</ul>
+
+<h1 id="experiment">Experiment</h1>
+
+<ul>
+ <li>
+ <p>The paper reports favourable results for distillation task for the following domains:</p>
+
+ <ul>
+ <li>
+ <p>Image Classification (on MNIST dataset)</p>
+
+ <ul>
+ <li>An extra experiment is performed where the simpler model is not shown any images of “3” but the model fails for only 133 cases out of 1010 cases involving “3”.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Automatic Speech Recognition (ASR)</p>
+
+ <ul>
+ <li>
+ <p>An extra experiment is performed where the baseline model is trained using both hard targets and soft targets alternatively. Further, only 3% of the total dataset is used.</p>
+ </li>
+ <li>
+ <p>The model using hard targets overfits and has poor test accuracy while the model using soft targets does not overfit and gets much better test accuracy. This shows the regularizing effect of soft targets.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Training ensemble specialists for very large datasets (JFT dataset - an internal dataset at Google)</p>
+
+ <ul>
+ <li>
+ <p>The experiment shows that while training a single large model would take a lot of time, the performance of the model can be improved by learning a small number of specialised networks (which are faster to train).</p>
+ </li>
+ <li>
+ <p>Though it is yet to be shown that the knowledge of such specialist models can be distilled back into a single model.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ PTE - Predictive Text Embedding through Large-scale Heterogeneous Text Networks
+
+ 2017-12-24T00:00:00-05:00
+ /site/2017/12/24/PTE - Predictive Text Embedding through Large-scale Heterogeneous Text Networks
+ <h1 id="introduction">Introduction</h1>
+
+<ul>
+ <li>
+ <p>Unsupervised text embeddings can be generalized for different tasks but they have weaker predictive powers (as compared to end-to-end trained deep learning methods) for any particular task. But the deep learning techniques are expensive and need a large amount of supervised data and a large number of parameters to tune.</p>
+ </li>
+ <li>
+ <p>The paper introduces Predictive Text Embedding (PTE) - a semi-supervised approach which learns an effective low dimensional representation using a large amount of unsupervised data and a small amount of supervised data.</p>
+ </li>
+ <li>
+ <p>The work can be extended to general information networks as well as classic techniques like MDS, Iso-map, Laplacian EigenMaps etc do not scale well for large graphs.</p>
+ </li>
+ <li>
+ <p>Further, this model can be applied to heterogeneous networks as well unlike the previous works <a href="https://arxiv.org/abs/1503.03578">LINE</a> and <a href="https://arxiv.org/abs/1403.6652">DeepWalk</a> which work on homogeneous networks only.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1508.00200">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h1 id="approach">Approach</h1>
+
+<ul>
+ <li>
+ <p>The paper proposes 3 different kinds of networks:</p>
+
+ <ul>
+ <li><strong>Word-Word Network</strong> which captures the word co-occurrence information (local level).</li>
+ <li><strong>Word-Document Network</strong> which captures the word-document co-occurrence information (local + document level).</li>
+ <li><strong>Word-Label Network</strong> which captures the word-label co-occurrence information (bipartite graph).</li>
+ </ul>
+ </li>
+ <li>
+ <p>All 3 graphs are integrated into one heterogeneous text network.</p>
+ </li>
+ <li>
+ <p>First, the authors extend their previous work, LINE, for heterogenous bipartite text networks as explained:</p>
+
+ <ul>
+ <li>
+ <p>Given a bipartite graph <em>G = (V<sub>A</sub> \bigcup V<sub>B</sub>, E)</em> , where <em>V<sub>A</sub> and V<sub>B</sub></em> are disjoint set of vertices, the conditional probability of <em>v<sub>a</sub></em> (in set <em>V<sub>A</sub></em>) being generated by <em>v<sub>b</sub></em> (in set <em>V<sub>B</sub></em>) is given as the softmax score between embeddings of <em>v<sub>a</sub></em> and <em>v<sub>b</sub></em> and normalised by the sum of exponentials of dot products between <em>v<sub>b</sub></em> and all nodes in <em>V<sub>A</sub></em>.</p>
+ </li>
+ <li>
+ <table>
+ <tbody>
+ <tr>
+ <td>The second order proximity can be determined by the conditional distributions *p(.</td>
+ <td>v<sub>j</sub>)*p(.</td>
+ <td>v<sub>j</sub>)*.</td>
+ </tr>
+ </tbody>
+ </table>
+ </li>
+ <li>
+ <p>The objective to be minimised the KL divergence between the conditional distribution <em>p(.\v<sub>j</sub>)</em> and the emperical distribution <em>p<sup>^</sup>(.\v<sub>j</sub>)</em> (given as w<sub>i, j</sub>/deg<sub>j</sub>).</p>
+ </li>
+ <li>The objective can be further simplified and optimised using SGD with edge sampling and negative sampling.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Now, the 3 individual networks can all be interpreted as bipartite networks. So node representation of all the 3 individual networks is obtained as described above.</p>
+ </li>
+ <li>
+ <p>For the word-label network, since the training data is sparse, one could either train the unlabelled networks first and then the labelled network or they all could be trained jointly.</p>
+ </li>
+ <li>
+ <p>For the case of joint training, the edges are sampled from the 3 networks alternatively.</p>
+ </li>
+ <li>
+ <p>For the fine-tuning case, the edges are first sampled from the unlabelled network and then from the labelled network.</p>
+ </li>
+ <li>
+ <p>Once the word embeddings are obtained, the text embeddings may be obtained by simply averaging the word embeddings.</p>
+ </li>
+</ul>
+
+<h1 id="evaluation">Evaluation</h1>
+
+<ul>
+ <li>
+ <p><strong>Baseline Models</strong></p>
+
+ <ul>
+ <li>Local word co-occurence based methods - SkipGram, LINE(Gww)</li>
+ <li>Document word co-occurence based methods - LINE(Gwd), PV-DBOW</li>
+ <li>Combined method - LINE (Gww + Gwd)</li>
+ <li>CNN</li>
+ <li>PTE</li>
+ </ul>
+ </li>
+ <li>
+ <p>For long documents, PTE (joint) outperforms CNN and other PTE variants and is around 10 times faster than CNN model.</p>
+ </li>
+ <li>
+ <p>For short documents, PTE (joint) does not always outperform CNN model probably because the word sense ambiguity is more relevant in the short documents.</p>
+ </li>
+</ul>
+
+
+
+
+ Revisiting Semi-Supervised Learning with Graph Embeddings
+
+ 2017-12-11T00:00:00-05:00
+ /site/2017/12/11/Revisiting Semi-Supervised Learning with Graph Embeddings
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a semi-supervised learning framework for graphs where the node embeddings are used to jointly predict both the class labels and neighbourhood context. Usually, graph embeddings are learnt in an unsupervised manner and can not leverage the supervising signal coming from the labelled data.</p>
+ </li>
+ <li>
+ <p>The framework is called <a href="https://github.com/kimiyoung/planetoid">Planetoid (Predicting Labels And Neighbors with Embeddings Transductively Or Inductively from Data)</a>.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1603.08861">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="problem-setting">Problem Setting</h2>
+
+<ul>
+ <li>
+ <p>Given a graph G = (V, E) and x<sub>L</sub> and x<sub>U</sub> as feature vectors for labelled and unlabelled nodes and y<sub>L</sub> as labels for the labelled nodes, the problem is to learn a mapping (classifier) f: x -> y</p>
+ </li>
+ <li>
+ <p>There are two settings possible:</p>
+
+ <ul>
+ <li>
+ <p><strong>Transductive</strong> - Predictions are made only for those nodes which are already observed in the graph at training time.</p>
+ </li>
+ <li>
+ <p><strong>Inductive</strong> - Predictions are made for nodes whether they have been observed in the graph at training time or not.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>The general semi-supervised learning loss would be <em>L<sub>S</sub> + λL<sub>U</sub></em> where <em>L<sub>S</sub></em> is the supervised learning loss while <em>L<sub>U</sub></em> is the unsupervised learning loss.</p>
+ </li>
+ <li>
+ <p>The unsupervised loss is a variant of the Skip-gram loss with negative edge sampling.</p>
+ </li>
+ <li>
+ <p>More specifically, first a random walk sequence S is sampled. Then either a positive edge is sampled from S (within a given context distance) or a negative edge is sampled.</p>
+ </li>
+ <li>
+ <p>The label information is injected by using the label as a context and minimising the distance between the positive edges (edges where the nodes have the same label) and maximising the distance between the negative edges (edges where the nodes have different labels).</p>
+ </li>
+</ul>
+
+<h3 id="transductive-formulation">Transductive Formulation</h3>
+
+<ul>
+ <li>
+ <p>Two separate fully connected networks are applied over the node features and node embeddings.</p>
+ </li>
+ <li>
+ <p>These 2 representations are then concatenated and fed to a softmax classifier to predict the class label.</p>
+ </li>
+</ul>
+
+<h3 id="inductive-formulation">Inductive Formulation</h3>
+
+<ul>
+ <li>
+ <p>In the inductive setting, it is difficult to obtain the node embeddings at test time. One naive approach is to retrain the network to obtain the embeddings on the previously unobserved nodes but that is inefficient.</p>
+ </li>
+ <li>
+ <p>The embeddings of node x are parameterized as a function of its input feature vector and is learnt by applying a fully connected neural network on the node feature vector.</p>
+ </li>
+ <li>
+ <p>This provides a simple way to extend the original approach to the inductive setting.</p>
+ </li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>
+ <p>The proposed approach is evaluated in 3 settings (text classification, distantly supervised entity extraction and entity classification) and it consistently outperforms approaches that use just node features or node embeddings.</p>
+ </li>
+ <li>
+ <p>The key takeaway is that the joint training in the semi-supervised setting has several benefits over the unsupervised setting and that using the graph context (in terms of node embeddings) is much more effective than using graph Laplacian-based regularization term.</p>
+ </li>
+</ul>
+
+
+
+
+ Two-Stage Synthesis Networks for Transfer Learning in Machine Comprehension
+
+ 2017-11-28T00:00:00-05:00
+ /site/2017/11/28/Two-Stage Synthesis Networks for Transfer Learning in Machine Comprehension
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper proposes a two-stage synthesis network that can perform transfer learning for the task of machine comprehension.</li>
+ <li>
+ <p>The problem is the following:</p>
+
+ <ul>
+ <li>
+ <p>We have a domain D<sub>S</sub> for which we have labelled dataset of question-answer pairs and another domain D<sub>T</sub> for which we do not have any labelled dataset.</p>
+ </li>
+ <li>
+ <p>We use the data for domain D<sub>S</sub> to train SynNet and use that to generate synthetic question-answer pairs for domain D<sub>T</sub>.</p>
+ </li>
+ <li>
+ <p>Now we can train a machine comprehension model M on D<sub>S</sub> and finetune using the synthetic data for D<sub>T</sub>.</p>
+ </li>
+ </ul>
+ </li>
+ <li><a href="https://www.microsoft.com/en-us/research/publication/two-stage-synthesis-networks-transfer-learning-machine-comprehension/">Link to the paper</a></li>
+</ul>
+
+<h2 id="synnet">SynNet</h2>
+
+<ul>
+ <li>
+ <p>Works in two stages:</p>
+
+ <ul>
+ <li>Answer Synthesis - Given a text paragraph, generate an answer.</li>
+ <li>Question Synthesis - Given a text paragraph and an answer, generate a question.</li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="answer-synthesis-network">Answer Synthesis Network</h3>
+
+<ul>
+ <li>Given the labelled dataset for D<sub>S</sub>, generate a labelled dataset of <word, tag> pair such that each word in the given paragraph is assigned one of the 4 tags:
+ <ul>
+ <li>IOB<sub>start</sub> - if it is the starting word of an answer</li>
+ <li>IOB<sub>mid</sub> - if it is the intermediate word of an answer</li>
+ <li>IOB<sub>end</sub> - if it is the ending word of an answer</li>
+ <li>IOB<sub>none</sub> - if it is not part of any answer</li>
+ </ul>
+ </li>
+ <li>
+ <p>For training, map the words to their GloVe embeddings and pass through a Bi-LSTM. Next, pass them through two-FC layers followed by a softmax layer.</p>
+ </li>
+ <li>For the target domain D<sub>T</sub>, all the consecutive word spans where no label is IOB<sub>none</sub> are returned as candidate answers.</li>
+</ul>
+
+<h3 id="question-synthesis-network">Question Synthesis Network</h3>
+
+<ul>
+ <li>
+ <p>Given an input paragraph and a candidate answer, Question Synthesis network generates question one word at a time.</p>
+ </li>
+ <li>
+ <p>Map each word in the paragraph to their GloVe embedding. After the word vector, append a ‘1’ if the word was part of the candidate answer else append a ‘0’.</p>
+ </li>
+ <li>
+ <p>Feed to a Bi-LSTM network (encoder-decoder) where the decoder conditions on the representation generated by the encoder as well as the question tokens generated so far. Decoding is stopped when “END” token is produced.</p>
+ </li>
+ <li>
+ <p>The paragraph may contain some named entities or rare words which do not appear in the softmax vocabulary. To account for such words, a copying mechanism is also incorporated.</p>
+ </li>
+ <li>
+ <p>At each time step, a Pointer Network (C<sub>P</sub>) and a Vocabulary Predictor (V<sub>P</sub>) are used to generate probability distribution for the next word and a Latent Predictor Network is used to decide which of the two networks would be used for the prediction.</p>
+ </li>
+ <li>
+ <p>At inference time, a greedy decoding is used where the most likely predictor is chosen and then the most likely word from that predictor is chosen.</p>
+ </li>
+</ul>
+
+<h3 id="machine-comprehension-model">Machine Comprehension Model</h3>
+
+<ul>
+ <li>Given any MC model, first train it over domain D<sub>S</sub> and then fine-tune using the artificial questions generated using D<sub>T</sub>.</li>
+</ul>
+
+<h3 id="implementation-details">Implementation Details</h3>
+
+<ul>
+ <li>
+ <p><strong>Data Regularization</strong> - There is a need to alternate between mini batches from source and target domain while fine-tuning the MC model.</p>
+ </li>
+ <li>
+ <p>At inference time, the fine-tuned MC model is used to get the distribution P(i=start) and P(i=end) (corresponding to the likelihood of choosing word I as the starting or ending word for the answer) for all the words and DP is used to find the optimal answer span.</p>
+ </li>
+ <li>
+ <p><strong>Checkpoint Averaging</strong> - Use the different checkpointed models to average the answer likelihood before running DP.</p>
+ </li>
+ <li>
+ <p>Using the synthetically generated dataset helps to gain a 2% improvement in terms of F-score (from SQuAD -> NewsQA). Using checkpointed models further improves the performance to overall 46.6% F score which closes the gap with respect to the performance of model trained on NewsQA itself (~52.3% F score)</p>
+ </li>
+</ul>
+
+
+
+
+
+ Higher-order organization of complex networks
+
+ 2017-11-19T00:00:00-05:00
+ /site/2017/11/19/Higher-order organization of complex networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a generalized framework for graph clustering (clusters of network motifs) on the basis of higher-order connectivity patterns.</p>
+ </li>
+ <li>
+ <p><a href="http://science.sciencemag.org/content/353/6295/163">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>Given a <a href="https://shagunsodhani.in/papers-I-read/Network-Motifs-Simple-Building-Blocks-of-Complex-Networks">motif M</a>, the framework aims to find a cluster of the set of nodes S such that nodes of S participate in many instances of M and avoid cutting instances of M (that is only a subset of nodes in instances of M appears in S).</p>
+ </li>
+ <li>
+ <p>Mathematically, the aim is to minimise the motif conductance metric given as <em>cut<sub>M</sub>(S, S’) / min[vol<sub>M</sub>(S), vol<sub>M</sub>(S’)]</em> where <em>S’</em> is complement of <em>S</em>, <em>cut<sub>M</sub>(S, S’)</em> = number of instances of M which have atleast one node from both <em>S</em> and <em>S’</em> and <em>vol<sub>M</sub>(S)</em> = Number of nodes in instances of M that belong only to S.</p>
+ </li>
+ <li>
+ <p>Solving the above equation is computationally infeasible and an approximate solution is proposed using eigenvalues and matrices.</p>
+ </li>
+ <li>
+ <p>The approximate solution is easy to implement, efficient and guaranteed to find clusters that are at most a quadratic factor away from the optimal.</p>
+ </li>
+</ul>
+
+<h2 id="algorithm">Algorithm</h2>
+
+<ul>
+ <li>
+ <p>Given the network and motif M, form a motif adjacency matrix W<sub>M</sub> where W<sub>M</sub>(i, j) is the number of instances of M that contains i and j.</p>
+ </li>
+ <li>
+ <p>Compute spectral ordering of the nodes from normalized motif laplacian matrix.</p>
+ </li>
+ <li>
+ <p>Compute prefix set of spectral ordering with small motif conductance.</p>
+ </li>
+</ul>
+
+<h2 id="scalability">Scalability</h2>
+
+<ul>
+ <li>Worst case <em>O(m<sup>1.5</sup>)</em>, based on experiments <em>O(m<sup>1.2</sup>)</em> where <em>m</em> is the number of edges.</li>
+</ul>
+
+<h2 id="advantages">Advantages</h2>
+
+<ul>
+ <li>
+ <p>Applicable to directed, undirected and weighted graphs (allows for negative edge weights as well).</p>
+ </li>
+ <li>
+ <p>In case the motif is not known beforehand, the framework can be used to compute significant motifs.</p>
+ </li>
+ <li>
+ <p>The proposed framework unifies the two fundamental tools of network science (motif analysis and network partitioning) along with some worst-case guarantees for the approximations employed and can be extended to identify higher order modular organization of networks.</p>
+ </li>
+</ul>
+
+
+
+
+
+ Network Motifs - Simple Building Blocks of Complex Networks
+
+ 2017-11-12T00:00:00-05:00
+ /site/2017/11/12/Network Motifs-Simple Building Blocks of Complex Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper presents the concept of “network motifs” to understand the structural design of a network or a graph.</li>
+ <li><a href="http://science.sciencemag.org/content/298/5594/824">Link to the paper</a></li>
+</ul>
+
+<h2 id="idea">Idea</h2>
+
+<ul>
+ <li>
+ <p>A network motif is defined as “a pattern of inter-connections occurring in complex networks in numbers that are significantly higher than those in randomized networks”.</p>
+ </li>
+ <li>
+ <p>In the practical setting, given an input network, we first create randomized networks which have same single node characteristics (like a number of incoming and outgoing edges) as the input network.</p>
+ </li>
+ <li>
+ <p>The patterns that occur at a much higher frequency in the input graph (than the randomized graphs) are reported as motifs.</p>
+ </li>
+ <li>
+ <p>More specifically, the patterns for which the probability of appearing in a randomized network an equal or more number of times than in the real network is lower than a cutoff value (say 0.01).</p>
+ </li>
+</ul>
+
+<h2 id="motivation">Motivation</h2>
+
+<ul>
+ <li>
+ <p>Real-life networks exhibit properties like “small world” property ( the majority of nodes are within a distance of fewer than 7 hops from each other) and “scale-free” property (fraction of nodes having k edges decays as a power-law).</p>
+ </li>
+ <li>
+ <p>Motifs are one such structural property that is exhibited by networks in biochemistry, neurobiology, ecology, and engineering. Further, motifs shared by graphs of different domains are different which hints at the usefulness of motifs as a fundamental structural property of the graph and relates to the process of evolution of the graph.</p>
+ </li>
+</ul>
+
+
+
+
+ Word Representations via Gaussian Embedding
+
+ 2017-11-05T00:00:00-04:00
+ /site/2017/11/05/Word Representations via Gaussian Embedding
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>Existing word embedding models like <a href="https://gist.github.com/shagunsodhani/176a283e2c158a75a0a6">Skip-Gram</a>, <a href="https://gist.github.com/shagunsodhani/efea5a42d17e0fcf18374df8e3e4b3e8">GloVe</a> etc map words to fixed sized vectors in a low dimensional vector space.</li>
+ <li>This fixed point setting cannot capture uncertainty about representation.</li>
+ <li>Further, these fixed point vectors are compared with measures like dot product and cosine similarity which are not suitable for capturing asymmetric properties like textual entailment and inclusion.</li>
+ <li>The paper proposes to learn Gaussian function embeddings (with diagonal covariance) for the word vectors.</li>
+ <li>This way, the words are mapped to soft regions in the embedding space which enables modeling uncertainty and asymmetric properties like inclusion and uncertainty.</li>
+ <li><a href="https://arxiv.org/abs/1412.6623">Link to the paper</a></li>
+ <li><a href="https://github.com/seomoz/word2gauss">Implementation</a></li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>KL divergence is used as the asymmetric distance function for comparing the distributions.</li>
+ <li>Unlike the Word2Vec model, the proposed model uses ranking-based loss.</li>
+</ul>
+
+<h3 id="similarity-measures-used">Similarity Measures used</h3>
+
+<ul>
+ <li>
+ <p><strong>Symmetric Similarity</strong></p>
+ </li>
+ <li>For two gaussian distributions, <em>P<sub>i</sub></em> and <em>P<sub>j</sub></em>, compute the inner product <em>E(P<sub>i</sub>, P<sub>j</sub>)</em> as <em>N(0; mean<sub>i</sub> - mean<sub>j</sub>, sigma<sub>i</sub> + sigma<sub>j</sub>)</em>.</li>
+ <li>Compute the gradient of <em>mean</em> and <em>sigma</em> with respect to <em>log(E)</em>.</li>
+ <li>
+ <p>The resulting loss function can be interpreted as pushing the means closer which encouraging the two gaussians to be more concentrated.</p>
+ </li>
+ <li>
+ <p><strong>Asymmetric Similarity</strong></p>
+ </li>
+ <li>Use KL divergence to encode the context distribution.</li>
+ <li>The benefit over the symmetric setting is that now entailment type relations can also be modeled.</li>
+ <li>For example, a low KL divergence from x to y indicates that y can be encoded as x or that y “entails” x.</li>
+</ul>
+
+<h2 id="learning">Learning</h2>
+
+<ul>
+ <li>One of the two notions of similarity is chosen and max-margin is used as the loss function.</li>
+ <li>Mean is regularized by adding a simple constraint on the L2-norm.</li>
+ <li>For covariance matrix, the eigenvalues are constrained to lie within a hypercube. This ensures that the positive-definite property of the covariance matrix is maintained while having a constraint on the size.</li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>Polysemous words have higher variance in their word embeddings as compared to specific words.</li>
+ <li>KL divergence (with diagonal covariance) outperforms other models.</li>
+ <li>Simple tree hierarchies can also be modeled by embedding into the Gaussian space. A Gaussian is created for each node with randomly initialized mean and the same set of embeddings is used for nodes and context.</li>
+ <li>For word similarity benchmarks, embeddings with spherical covariance have a slight edge over embeddings with diagonal covariance and outperform the Skip-Gram model in all the cases.</li>
+</ul>
+
+<h2 id="future-work">Future Work</h2>
+
+<ul>
+ <li>Use combinations of low rank and diagonal matrices for covariances.</li>
+ <li>Improved optimisation strategies.</li>
+ <li>Trying other distributions like Student’s-t distribution.</li>
+</ul>
+
+
+
+
+ HARP - Hierarchical Representation Learning for Networks
+
+ 2017-10-28T00:00:00-04:00
+ /site/2017/10/28/HARP - Hierarchical Representation Learning for Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>HARP is an architecture to learn low-dimensional node embeddings by compressing the input graph into smaller graphs.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1706.07845">Link to the paper</a>.</p>
+ </li>
+ <li>
+ <p>Given a graph <em>G = (V, E)</em>, compute a series of successively smaller (coarse) graphs <em>G<sub>0</sub>, …, G<sub>L</sub></em>. Learn the node representations in <em>G<sub>L</sub></em> and successively refine the embeddings for larger graphs in the series.</p>
+ </li>
+ <li>
+ <p>The architecture is independent of the algorithms used to embed the nodes or to refine the node representations.</p>
+ </li>
+ <li>
+ <p><strong>Graph coarsening technique that preserves global structure</strong></p>
+
+ <ul>
+ <li>
+ <p>Collapse edges and stars to preserve first and second order proximity.</p>
+ </li>
+ <li>
+ <p><strong>Edge collapsing</strong> - select the subset of <em>E</em> such that no two edges are incident on the same vertex and merge their nodes into a single node and merge their edges as well.</p>
+ </li>
+ <li>
+ <p><strong>Star collapsing</strong> - given star structure, collapse the pairs of neighboring nodes (of the central node).</p>
+ </li>
+ <li>
+ <p>In practice, first apply star collapsing, followed by edge collapsing.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Extending node representation from coarse graph to finer graph</strong></p>
+
+ <ul>
+ <li>
+ <p>Lets say <em>node1</em> and <em>node2</em> were merged into <em>node12</em> during coarsening. First copy the representation of <em>node12</em> into <em>node1</em>, <em>node2</em>.</p>
+ </li>
+ <li>
+ <p>Additionally, if hierarchical softmax was used, extend the B-tree such that <em>node12</em> is replaced by 2 child nodes <em>node1</em> and <em>node2</em>.</p>
+ </li>
+ <li>
+ <p>Time complexity for HARP + DeepWalk is <em>O(number of walks * |V|)</em> while for HARP + LINE is <em>O(number of iterations * |E|)</em>.</p>
+ </li>
+ <li>
+ <p>The asymptotic complexity remains the same as the HARP-less version for the two cases.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Multilabel classification task shows that HAR improves all the node embedding technique with gains up to 14%.</p>
+ </li>
+</ul>
+
+
+
+
+ Swish - a Self-Gated Activation Function
+
+ 2017-10-22T00:00:00-04:00
+ /site/2017/10/22/Swish-A self gated activation function
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a new activation function called Swish with formulation <em>f(x) = x.sigmod(x)</em> and its parameterised version called Swish-β where <em>f(x, β) = 2x.sigmoid(β.x)</em> and β is a training parameter.</p>
+ </li>
+ <li>
+ <p>The paper shows that Swish is consistently able to outperform RELU and other activations functions over a variety of datasets (CIFAR, ImageNet, WMT2014) though by small margins only in some cases.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1710.05941">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="properties-of-swish">Properties of Swish</h2>
+
+<ul>
+ <li>
+ <p><img src="https://raw.githubusercontent.com/shagunsodhani/papers-I-read/master/assets/Swish/plot.png" alt="Plot Of Swish" /></p>
+ </li>
+ <li>
+ <p>Smooth, non-monotonic function.</p>
+ </li>
+ <li>
+ <p>Swish-β can be thought of as a smooth function that interpolates between a linear function and RELU.</p>
+ </li>
+ <li>
+ <p>Uses self-gating mechanism (that is, it uses its own value to gate itself). Gating generally uses multiple scalar inputs but since self-gating uses a single scalar input, it can be used to replace activation functions which are generally pointwise.</p>
+ </li>
+ <li>
+ <p>Being unbounded on the x>0 side, it avoids saturation when training is slow due to near 0 gradients.</p>
+ </li>
+ <li>
+ <p>Being bounded below induces a kind of regularization effect as large, negative inputs are forgotten.</p>
+ </li>
+ <li>
+ <p>Since the Swish function is smooth, the output landscape and the loss landscape are also smooth. A smooth landscape should be more traversable and less sensitive to initialization and learning rates.</p>
+ </li>
+</ul>
+
+<h2 id="criticism">Criticism</h2>
+
+<ul>
+ <li>Swish is much more complicated than ReLU (when weighted against the small improvements that are provided) so it might not end up with as strong an adoption as ReLU.</li>
+</ul>
+
+
+
+
+ Reading Wikipedia to Answer Open-Domain Questions
+
+ 2017-10-15T00:00:00-04:00
+ /site/2017/10/15/Reading Wikipedia to Answer Open-Domain Questions
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper presents a new machine comprehension dataset for question answering in real life setting (say when interacting with Cortana/Siri).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1704.00051">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="unique-aspects-of-the-dataset">Unique Aspects of the dataset</h2>
+
+<ul>
+ <li>
+ <p>Existing machine comprehension (MC) datasets are either too small or synthetic (with a distribution different from that or real-questions posted by humans). MARCO questions are sampled from real, anonymized user queries.</p>
+ </li>
+ <li>
+ <p>Most datasets would provide a comparatively small and clean context to answer the question. In MARCO, the context documents (which may or may not contain the answer) are extracted using Bing from real-world documents. As such the questions and the context documents are noisy.</p>
+ </li>
+ <li>
+ <p>In general, the answer to the questions are restricted to an entity or text span within the document. In case of MARCO, the human judges are encouraged to generate complete sentences as answers.</p>
+ </li>
+</ul>
+
+<h2 id="dataset-description">Dataset Description</h2>
+
+<ul>
+ <li>
+ <p>First release consists of 100K questions with the aim of releasing 1M questions in the future releases.</p>
+ </li>
+ <li>
+ <p>All questions are tagged with segment information.</p>
+ </li>
+ <li>
+ <p>A subset of questions has multiple answers and another subset has no answers at all.</p>
+ </li>
+ <li>
+ <p>Each record in the dataset contains the following information:</p>
+
+ <ul>
+ <li><strong>Query</strong> - The actual question</li>
+ <li><strong>Passage</strong> - Top 10 contextual passages extracted from web search engine (which may or may not contain the answer to the question).</li>
+ <li><strong>Document URLs</strong> - URLs for the top documents (which are the source of the contextual passages).</li>
+ <li><strong>Answer</strong> - Answer synthesised by human evaluators.</li>
+ <li><strong>Segment</strong> - Query type, description, neumeric, entity, location, person.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="experimental-results">Experimental Results</h2>
+
+<ul>
+ <li>
+ <p>Metrics</p>
+
+ <ul>
+ <li>Accuracy and precision/recall for numeric questions</li>
+ <li>ROGUE-L/paraphrasing aware evaluation framework for long, textual answers.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Among generative models, Memory Networks performed better than seq-to-seq.</p>
+ </li>
+ <li>
+ <p>In the cloze-style test, <a href="https://arxiv.org/abs/1609.05284">ReasoNet</a> achieved an accuracy of approx. 59% while <a href="ASR">Attention Sum Reader</a> achieved an accuracy of approx 55%.</p>
+ </li>
+ <li>
+ <p>Current QA systems (including the ones using memory and attention) derive their power from supervised data and are very different from how humans do reasoning.</p>
+ </li>
+ <li>
+ <p>Imagenet dataset pushed the state-of-the-art performance on object classification to beyond human accuracy. Similar was the case with speech recognition dataset from DARPA which led to the advancement of speech recognition. Having a large, diverse and human-like questions dataset is a fundamental requirement to advance the field and the paper aims to provide just the right kind of dataset.</p>
+ </li>
+</ul>
+
+
+
+
+ Task-Oriented Query Reformulation with Reinforcement Learning
+
+ 2017-10-01T00:00:00-04:00
+ /site/2017/10/01/Task-Oriented Query Reformulation with Reinforcement Learning
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper introduces a query reformulation system that rewrites a query to maximise the number of “relevant” documents that are extracted from a given black box search engine.</li>
+ <li>A Reinforcement Learning (RL) agent selects the terms that are to be added to the reformulated query and the rewards are decided on the basis of document recall.</li>
+ <li><a href="https://arxiv.org/abs/1704.04572">Link to the paper</a></li>
+ <li><a href="https://github.com/nyu-dl/QueryReformulator">Implementation</a></li>
+</ul>
+
+<h2 id="key-aspect">Key Aspect</h2>
+
+<ul>
+ <li>The underlying problem is as follows: when the end user makes a query to a search engine, the engine often relies on word matching techniques to perform retrieval. This means relevant documents could be missed if there is no exactly matching words between the query and the document.</li>
+ <li>This problem can be handled at two levels: First, the search engine itself takes care of query semantics. Alternatively, we assume the search engine to be dumb and instead have a system in place that can improve the original queries (automatic query reformulation).</li>
+ <li>The paper takes the latter approach and expands the original query by adding terms from the set of retrieved documents (pseudo relevance feedback).</li>
+</ul>
+
+<h2 id="datasets">Datasets</h2>
+
+<ul>
+ <li>TREC - Complex Answer Retrieval (TREC-CAR)</li>
+ <li>Jeopardy Q&A dataset</li>
+ <li>Microsoft Academic (MSA) dataset - created by the authors using papers crawled from Microsoft Academic API</li>
+</ul>
+
+<h2 id="framework">Framework</h2>
+
+<ul>
+ <li>Query Reformulation task is modeled as an RL problem where:
+ <ul>
+ <li>Environment is the search engine.</li>
+ <li>Actions are whether a word is to be added to the query or not and if yes, then what word is added.</li>
+ <li>Reward is the retrieval accuracy.</li>
+ </ul>
+ </li>
+ <li>The input to the system is a query q<sub>0</sub> consisting of a sequence of words w<sub>1</sub>, …, w<sub>n</sub> and a candidate term t<sub>i</sub> with some context words.</li>
+ <li>Candidate terms are all the terms that appear in the original query and the documents retrieved using the query.</li>
+ <li>The words are mapped to vectors and then a fixed size representation is obtained for the sequence using CNN’s or RNNs.</li>
+ <li>Similarly, a representation is obtained for the candidate words by feeding them and their context words to the CNN or RNNs.</li>
+ <li>Finally, a sigmoidal score is computed for all the candidate words.</li>
+ <li>An RNN sequentially applies this model to emit query words till an end token is emitted.</li>
+ <li>Vocabulary is used only from the extracted documents and not the entire vocabulary set, to keep the inference fast.</li>
+</ul>
+
+<h2 id="training">Training</h2>
+
+<ul>
+ <li>The model is trained using REINFORCE algorithm which minimizes the <em>C<sub>a</sub> = (R − R~) * sum(log(P(t|q))) where R~ is the baseline.</em></li>
+ <li>Value network minimises <em>C<sub>b</sub> = &\alpha(||R-R~||<sup>2</sup>)</em></li>
+ <li><em>C<sub>a</sub></em> and <em>C<sub>b</sub></em> are minimised using SGD.</li>
+ <li>An entropy regulation term is added to prevent the probability distribution from reaching the peak.</li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="baseline-methods">Baseline Methods</h3>
+
+<ul>
+ <li>
+ <p><strong>Raw</strong> - Original query is fed to the search engine without any modification.</p>
+ </li>
+ <li>
+ <p><strong>Pseudo-Relevance Feedback (PRF-TFIDF)</strong> - The query is expanded using the top-N TF-IDF terms.</p>
+ </li>
+ <li>
+ <p><strong>PRF-Relevance Model (PRF-RM)</strong> - Probability of adding token <em>t</em> to the query <em>q0</em> is given by <em>P(t|q0) = (1 − λ)P′(t|q0) + λ sum (P(d)P(t|d)P(q0|d))</em></p>
+ </li>
+</ul>
+
+<h3 id="proposed-methods">Proposed Methods</h3>
+
+<ul>
+ <li><strong>Supervised Learning</strong>
+ <ul>
+ <li>Assumes that the query words contribute indepently to the query retrival performace. (Too strong an assumption).</li>
+ <li>A term is marked as relevant if <em>(R(new_query) - R(old_query))/R(old_query) > 0.005</em></li>
+ </ul>
+ </li>
+ <li><strong>Reinforcement Learning</strong>
+ <ul>
+ <li>RL-RNN/CNN - RL Framework + RNN/CNN to encode the input features.</li>
+ <li>RL-RNN-SEQ - Add a sequential generator.</li>
+ </ul>
+ </li>
+ <li><strong>Metrics</strong>
+ <ul>
+ <li>Recall@K</li>
+ <li>Precision@K</li>
+ <li>Mean Average Precision@K</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Reward</strong> - The paper uses Recall@K as a reward when training the RL-based models with the argument that the “metric has shown to be effective in improving the other metrics as well”, without any justification though.</p>
+ </li>
+ <li>
+ <p><strong>SL-Oracle</strong> - classifier that perfectly selects terms that will increase performance based on the supervised learning approach.</p>
+ </li>
+ <li><strong>RL-Oracle</strong> - Produces a conservative upper-bound for the performance of the RL Agent. It splits the test data into N subsets and trains an RL agent for each subset. Then, the reward is averaged over all the N subsets.</li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>Reformulation based methods > original query</li>
+ <li>RL methods > Supervised methods > unsupervised methods</li>
+ <li>RL-RNN-SEQ performs slightly worse than RL-RNN but is much faster (as it produces shorter queries).</li>
+ <li>RL-based model benefits from more candidate terms while the classical PRF method quickly saturates.</li>
+</ul>
+
+<h2 id="comments">Comments</h2>
+
+<ul>
+ <li>Interestingly, for each raw query, they carried out the reformulation step just once and not multiple times. The number of times a query is reformulated could also have become a part of the RL framework.</li>
+</ul>
+
+
+
+
+ Refining Source Representations with Relation Networks for Neural Machine Translation
+
+ 2017-09-22T00:00:00-04:00
+ /site/2017/09/22/Refining Source Representations with Relation Networks for Neural Machine Translation
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>The paper introduces Relation Network (RN) that refines the encoding representation of the given source document (or sentence).</li>
+ <li>This refined source representation can then be used in Neural Machine Translation (NMT) systems to counter the problem of RNNs forgetting old information.</li>
+ <li><a href="https://arxiv.org/abs/1709.03980">Link to the paper</a></li>
+</ul>
+
+<h2 id="limitations-of-existing-nmt-models">Limitations of existing NMT models</h2>
+
+<ul>
+ <li>The RNN encoder-decoder architecture is the standard choice for NMT systems. But the RNNs are prone to forgetting old information.</li>
+ <li>In NMT models, the attention is modeled in the unit of words while the use of phrases (instead of words) would be a better choice.</li>
+ <li>While NMT systems might be able to capture certain relationships between words, they are not explicitly designed to capture such information.</li>
+</ul>
+
+<h2 id="contributions-of-the-paper">Contributions of the paper</h2>
+
+<ul>
+ <li>Learn the relationship between the source words using the context (neighboring words).</li>
+ <li>Relation Networks (RNs) build pairwise relations between source words using the representations generated by the RNNs. The RN would sit between the encoder and the attention layer of the encoder-decoder framework thereby keeping the main architecture unaffected.</li>
+</ul>
+
+<h2 id="relation-network">Relation Network</h2>
+
+<ul>
+ <li>Neural network which is desgined for relational reasoning.</li>
+ <li>Given a set of inputs * O = o<sub>1</sub>, …, o<sub>n</sub> *, RN is formed as a composition of inputs:
+ RN(O) = f(sum(g(o<sub>i</sub>, o<sub>j</sub>))), f and g are functions used to learn the relations (feed forward networks)</li>
+ <li><em>g</em> learns how the objects are related hence the name “relation”.</li>
+ <li><strong>Components</strong>:
+ <ul>
+ <li>CNN Layer
+ <ul>
+ <li>Extract information from the words surrounding the given word (context).</li>
+ <li>The final output of this layer is the sequence of vectors for different kernel width.</li>
+ </ul>
+ </li>
+ <li>Graph Propagation (GP) Layer
+ <ul>
+ <li>Connect all the words with each other in the form of a graph.</li>
+ <li>Each output vector from the CNN corresponds to a node in the graph and there is an edge between all possible pair of nodes.</li>
+ <li>The information flows between the nodes of the graph in a message passing sort of fashion (graph propagation) to obtain a new set of vectors for each node.</li>
+ </ul>
+ </li>
+ <li>Multi-Layer Perceptron (MLP) Layer
+ <ul>
+ <li>The representation from the GP Layer is fed to the MLP layer.</li>
+ <li>The layer uses residual connections from previous layers in form of concatenation.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="datasets">Datasets</h2>
+
+<ul>
+ <li>IWSLT Data - 44K sentences from tourism and travel domain.</li>
+ <li>NIST Data - 1M Chinese-English parallel sentence pairs.</li>
+</ul>
+
+<h2 id="models">Models</h2>
+
+<ul>
+ <li>MOSES - Open source translation system - http://www.statmt.org/moses/</li>
+ <li>NMT - Attention based NMT</li>
+ <li>NMT+ - NMT with improved decoder</li>
+ <li>TRANSFORMER - Google’s new NMT</li>
+ <li>RNMT+ - Relation Network integrated with NMT+</li>
+</ul>
+
+<h2 id="evaluation-metric">Evaluation Metric</h2>
+
+<ul>
+ <li>case-insensitive 4-gram BLEU score</li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>As sentences become larger (more than 50 words), RNMT clearly outperforms other baselines.</li>
+ <li>Qualitative evaluation shows that RNMT+ model captures the word alignment better than the NMT+ models.</li>
+ <li>Similarly, NMT+ system tends to miss some information from the source sentence (more so for longer sentences). While both CNNs and RNNs are weak at capturing long-term dependency, using the relation layer mitigates this issue to some extent.</li>
+</ul>
+
+
+
+
+ Pointer Networks
+
+ 2017-08-27T00:00:00-04:00
+ /site/2017/08/27/Pointer Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>The paper introduces a novel architecture that generates an output sequence such that the elements of the output sequence are discrete tokens corresponding to positions in the input sequence.</p>
+ </li>
+ <li>
+ <p>Such a problem can not be solved using <a href="https://gist.github.com/shagunsodhani/a2915921d7d0ac5cfd0e379025acfb9f">Seq2Seq</a> or Neural Turing Machines as the size of the output softmax is variable (as it depends on the size of the input sequence).</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1506.03134">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>Traditional attention-base sequence-to-sequence models compute an attention vector for each step of the output decoder and use that to blend the individual context vectors of the input into a single, consolidated attention vector. This attention vector is used to compute a fixed size softmax.</p>
+ </li>
+ <li>
+ <p>In Pointer Nets, the normalized attention vector (over all the tokens in the input sequence) is normalized and treated as the softmax output over the input tokens.</p>
+ </li>
+ <li>
+ <p>So Pointer Net is a very simple modification of the attention model.</p>
+ </li>
+</ul>
+
+<h2 id="application">Application</h2>
+
+<ul>
+ <li>
+ <p>Any problem where the size of the output depends on the size of the input because of which fixed length softmax is ruled out.</p>
+ </li>
+ <li>
+ <p>eg combinatorial problems such as planar convex hull where the size of the output would depend on the size of the input.</p>
+ </li>
+</ul>
+
+<h2 id="evaluation">Evaluation</h2>
+
+<ul>
+ <li>
+ <p>The paper considers the following 3 problems:</p>
+
+ <ul>
+ <li>Convex Hull</li>
+ <li>Delaunay triangulations</li>
+ <li>Travelling Salesman Problem (TSP)</li>
+ </ul>
+ </li>
+ <li>
+ <p>Since some of the problems are NP hard, the paper considers approximate solutions whereever the exact solutions are not feasible to compute.</p>
+ </li>
+ <li>
+ <p>The authors used the exact same architecture and model parameters of all the instances of the 3 problems to show the generality of the model.</p>
+ </li>
+ <li>
+ <p>The proosed Pointer Nets outperforms LSTMs and LSTMs with attention and can generalise quite well for much larger sequences.</p>
+ </li>
+ <li>
+ <p>Interestingly, the order in which the inputs are fed to the system affects its performance. The authors discussed this apsect in their subsequent paper titled <a href="https://arxiv.org/pdf/1511.06391v4.pdf">Order Matters: Sequence To Sequence for Sets</a></p>
+ </li>
+</ul>
+
+
+
+
+ Learning to Compute Word Embeddings On the Fly
+
+ 2017-08-21T00:00:00-04:00
+ /site/2017/08/21/Learning to Compute Word Embeddings On the Fly
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Word based language models suffer from the problem of rare or Out of Vocabulary (OOV) words.</p>
+ </li>
+ <li>
+ <p>Learning representations for OOV words directly on the end task often results in poor representation.</p>
+ </li>
+ <li>
+ <p>The alternative is to replace all the rare words with a single, unique representation (loss of information) or use character level models to obtain word representations (they tend to miss on the semantic relationship).</p>
+ </li>
+ <li>
+ <p>The paper proposes to learn a network that can predict the representations of words using auxiliary data (referred to as definitions) such as dictionary definitions, Wikipedia infoboxes, the spelling of the word etc.</p>
+ </li>
+ <li>
+ <p>The auxiliary data encoders are trained jointly with the end task to ensure that word representations align with the requirements of the end task.</p>
+ </li>
+</ul>
+
+<h2 id="approach">Approach</h2>
+
+<ul>
+ <li>
+ <p>Given a rare word <em>w</em>, let <em>d(w) = <x<sub>1</sub>, x<sub>2</sub>…></em> denote its defination where <em>x<sub>i</sub></em> are words.</p>
+ </li>
+ <li>
+ <p><em>d(w)</em> is fed to a <em>defination reader</em> network <em>f</em> (LSTM) and its last state is used as the <em>defination embedding e<sub>d</sub>(w)</em></p>
+ </li>
+ <li>
+ <p>In case <em>w</em> has multiple definitions, the embeddings are combined using mean pooling.</p>
+ </li>
+ <li>
+ <p>The approach can be extended to in-vocabulary words as well by using the <em>definition embedding</em> of such words to update their original embeddings.</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>Auxiliary data sources
+ <ul>
+ <li>Word definitions from WordNet</li>
+ <li>Spelling of words</li>
+ </ul>
+ </li>
+ <li>
+ <p>The proposed approach was tested on following tasks:</p>
+
+ <ul>
+ <li>Extractive Question Answering over SQuAD
+ <ul>
+ <li>Base model from <a href="https://arxiv.org/abs/1611.01604">Xiong et al. 2016</a></li>
+ </ul>
+ </li>
+ <li>Entailment Prediction over SNLI corpus
+ <ul>
+ <li>Base models from <a href="https://nlp.stanford.edu/pubs/snli_paper.pdf">Bowman et al. 2015</a> and <a href="https://arxiv.org/abs/1609.06038">Chen et al. 2016</a></li>
+ </ul>
+ </li>
+ <li>One Billion Words Language Modelling</li>
+ </ul>
+ </li>
+ <li>
+ <p>For all the tasks, models using both spelling and dictionary (SD) outperformed the model using just one.</p>
+ </li>
+ <li>While SD does not outperform the Glove model (with full vocabulary), it does bridge the performance gap significantly.</li>
+</ul>
+
+<h2 id="future-work">Future Work</h2>
+
+<ul>
+ <li>
+ <p>Multi-token words like “San Francisco” are not accounted for now.</p>
+ </li>
+ <li>
+ <p>The model does not handle the rare words which appear in the definition and just replaces them by the <UNK> token. Making the model recursive would be a useful addition.</UNK></p>
+ </li>
+</ul>
+
+
+
+
+ R-NET - Machine Reading Comprehension with Self-matching Networks
+
+ 2017-08-07T00:00:00-04:00
+ /site/2017/08/07/R-NET - Machine Reading Comprehension with Self-matching Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>R-NET is an end-to-end trained neural network model for machine comprehension.</p>
+ </li>
+ <li>
+ <p>It starts by matching the question and the given passage (using gated attention based RNN) to obtain question-aware passage representation.</p>
+ </li>
+ <li>
+ <p>Next, it uses a self-matching attention mechanism to refine the passage representation by matching the passage against itself.</p>
+ </li>
+ <li>
+ <p>Lastly, it uses pointer networks to determine the position of the answer in the passage.</p>
+ </li>
+ <li>
+ <p><a href="https://www.microsoft.com/en-us/research/publication/mrc/">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="datasets">Datasets</h2>
+
+<ul>
+ <li>
+ <p>SQuAD</p>
+ </li>
+ <li>
+ <p>MS-MARCO</p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>Question / Passage Encoder</p>
+
+ <ul>
+ <li>Concatenate the word level and character level embeddings for each word and feed into a bidirectional GRU to obtain question and passage representation.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Gated Attention based RNN</p>
+
+ <ul>
+ <li>
+ <p>Given question and passage representation, sentence pair representation is generated via soft-alignment of the words in the question and in the passage.</p>
+ </li>
+ <li>
+ <p>The newly added gate captures the relation between the question and the current passage word as only some parts of the passage are relevant for answering the given question.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Self Matching Attention</p>
+
+ <ul>
+ <li>
+ <p>The passage representation obtained so far would not capture most of the context.</p>
+ </li>
+ <li>
+ <p>So the current representation is matched against itself so as to collect evidence from the entire passage and encode the evidence relevant to the current passage word and question.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Output Layer</p>
+
+ <ul>
+ <li>
+ <p>Use pointer network (initialized using attention pooling over answer representation) to predict the position of the answer.</p>
+ </li>
+ <li>
+ <p>Loss function is the sum of negative log probabilities of start and end positions.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>Results</p>
+
+ <ul>
+ <li>
+ <p>R-NET is ranked second on <a href="https://rajpurkar.github.io/SQuAD-explorer/">SQuAD Leaderboard</a> as of 7th August, 2017 and achieves best-published results on MS-MARCO dataset.</p>
+ </li>
+ <li>
+ <p>Using ideas like sentence ranking, using syntax information performing multihop inference and augmenting question dataset (using seqToseq network) do not help in improving the performance.</p>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ ReasoNet - Learning to Stop Reading in Machine Comprehension
+
+ 2017-07-24T00:00:00-04:00
+ /site/2017/07/24/ReasoNet - Learning to Stop Reading in Machine Comprehension
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>In the domain of machine comprehension, making multiple passes over the given document is an effective technique to extract the relation between the given passage, question and answer.</p>
+ </li>
+ <li>
+ <p>Unlike previous approaches, which perform a fixed number of passes over the passage, Reasoning Network (ReasoNet) uses reinforcement learning (RL) to decide how many times a document should be read.</p>
+ </li>
+ <li>
+ <p>Every time the document is read, ReasoNet determines whether the document should be read again or has the termination state been reached. If termination state is reached, the answer module is triggered to generate the answer.</p>
+ </li>
+ <li>
+ <p>Since the termination state is discrete and not connected to the final output, RL approach is used.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1609.05284">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="datasets">Datasets</h2>
+
+<ul>
+ <li>
+ <p>CNN, DailyMail Dataset</p>
+ </li>
+ <li>
+ <p>SQuAD</p>
+ </li>
+ <li>
+ <p>Graph Reachability Dataset</p>
+ <ul>
+ <li>2 synthetic datasets to test if the network can answer questions like “Is node_1 connected to node_12”?</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p><strong>Memory (M)</strong> - Comprises of the vector representation of the document and the question (encoded using GRU or other RNNs).</p>
+ </li>
+ <li>
+ <p><strong>Attention</strong> - Attention vector (<strong>x<sub>t</sub></strong>) is a function of current internal state <strong>s<sub>t</sub></strong> and external memory <strong>M</strong>. The state and memory are passed through FCs and fed to a similarity function.</p>
+ </li>
+ <li>
+ <p><strong>Internal State (s<sub>t</sub>)</strong> - Vector representation of the question state computed by a RNN using the previous internal state and the attention vector <strong>x<sub>t</sub></strong></p>
+ </li>
+ <li>
+ <p><strong>Termination Gate (T<sub>t</sub>)</strong> - Uses a logistic regression model to generate a random binary variable using the current internal state <strong>s<sub>t</sub></strong>.</p>
+ </li>
+ <li><strong>Answer</strong> - Answer module is triggered when <strong>T<sub>t</sub> = 1</strong>.
+ <ul>
+ <li>For CNN and DailyMail, a linear projection of GRU outputs is used to predict the answer from candidate entities.</li>
+ <li>For SQuAD, the position of the first and the last word from the answer span are predicted.</li>
+ <li>For Graph Reachability, a logistic regression module is used to predict yes/no as the answer.</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Reinforcement Learning</strong> - For the RL setting, reward at time <strong>t</strong>, <strong>r<sub>t</sub></strong> = 1 if <strong>T<sub>t</sub></strong> = 1 and answer is correct. Otherwise <strong>r<sub>t</sub> = 0</strong></p>
+ </li>
+ <li>
+ <p><strong>Workflow</strong> - Given a passage p, query q and answer a:</p>
+
+ <ul>
+ <li>
+ <p>Extract memory using p</p>
+ </li>
+ <li>
+ <p>Extract initial hidden state using q</p>
+ </li>
+ <li>
+ <p>ReasoNet executes all possible episodes that can be enumerated by setting an upper limit on the number of passes.</p>
+ </li>
+ <li>
+ <p>These episodes generate actions and answers that are used to train the ReasoNet.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Result</strong></p>
+
+ <ul>
+ <li>
+ <p>CNN, DailyMail Corpus</p>
+
+ <ul>
+ <li>ReasoNet outperforms all the baselines which use fixed number of reasoning steps and could benefit by capturing the word alignment signals between query and passage.</li>
+ </ul>
+ </li>
+ <li>
+ <p>SQuAD</p>
+
+ <ul>
+ <li>At the time of submission, ReasoNet was ranked 2nd on the <a href="https://rajpurkar.github.io/SQuAD-explorer/">SQuAD leaderboard</a> and as of 9th July 2017, it is ranked 4th.</li>
+ </ul>
+ </li>
+ <li>
+ <p>Graph Reachability Dataset</p>
+
+ <ul>
+ <li>
+ <p>ReasoNet - Standard ReasoNet as described above.</p>
+ </li>
+ <li>
+ <p>ReasoNet-Last - Use the prediction from the <strong>T<sub>max</sub></strong></p>
+ </li>
+ <li>
+ <p>ReasoNet > ReasoNet-Last > Deep LSTM Reader</p>
+ </li>
+ <li>
+ <p>ReasoNet converges faster than ReasoNet-Last indicating that the terminate gate is useful.</p>
+ </li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Notes</strong></p>
+
+ <ul>
+ <li>As such there is nothing discouraging the ReasoNet to make unnecessary passes over the passage.</li>
+ <li>In fact, the modal value of the number of passes = upper bound on the number of passes.</li>
+ <li>This effect is more prominent for large graph indicating that the ReasoNet may try to play safe by performing extra passes.</li>
+ <li>It would be interesting to see if the network can be discouraged from making unnecessary passed by awarding a small negative reward for each pass.</li>
+ </ul>
+ </li>
+</ul>
+
+
+
+
+ Principled Detection of Out-of-Distribution Examples in Neural Networks
+
+ 2017-07-17T00:00:00-04:00
+ /site/2017/07/17/Principled Detection of Out of Distribution Examples in Neural Networks
+ <h2 id="problem-statement">Problem Statement</h2>
+
+<ul>
+ <li>
+ <p>Given a pre-trained neural network, which is trained using data from some distribution P (referred to as in-distribution data), the task is to detect the examples coming from a distribution Q which is different from P (referred to as out-of-distribution data).</p>
+ </li>
+ <li>
+ <p>For example, if a digit recognizer neural network is trained using MNIST images, an out-of-distribution example would be images of animals.</p>
+ </li>
+ <li>
+ <p>Neural Networks can make high confidence predictions even in such cases where the input is unrecognisable or irrelevant.</p>
+ </li>
+ <li>
+ <p>The paper proposes <em>ODIN</em> which can detect such out-of-distribution examples without changing the pre-trained model itself.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1706.02690">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="odin">ODIN</h2>
+
+<ul>
+ <li>
+ <p>Uses 2 major techniques</p>
+
+ <ul>
+ <li><strong>Temperature Scaling</strong>
+ <ul>
+ <li>
+ <p>Softmax classifier for the classification network can be written as:</p>
+
+ <p><em>p<sub>i</sub>(x, T) = exp(f<sub>i</sub>(x)/T) / sum(exp(f<sub>j</sub>(x)/T))</em></p>
+ </li>
+ </ul>
+
+ <p>where <em>x</em> is the input, <em>p</em> is the softmax probability and <em>T</em> is the temperature scaling parameter.</p>
+
+ <ul>
+ <li>Increasing <em>T</em> (up to some extent) boosts the performance in distinguishing in-distribution and out-of-distribution examples.</li>
+ </ul>
+ </li>
+ <li><strong>Input Preprocessing</strong>
+ <ul>
+ <li>
+ <p>Add small perturbations to the input (image) before feeding it into the network.</p>
+ </li>
+ <li>
+ <p><em>x_perturbed = x - ε * sign(-δ<sub>x</sub>log(p<sub>y</sub>(x, T)))</em></p>
+ </li>
+ </ul>
+
+ <p>where ε is the perturbation magnitude</p>
+
+ <ul>
+ <li>The perturbations are such that softmax scores between in-distribution and out-of-distribution samples become separable.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+ <li>Given an input (image), first perturb the input.</li>
+ <li>Feed the perturbed input to the network to get its softmax score.</li>
+ <li>If the softmax score is greater than some threshold, mark the input as in-distribution and feed in the unperturbed version of the input to the network for classification.</li>
+ <li>Otherwise, mark the input as out-of-distribution.</li>
+ <li>For detailed mathematical treatment, refer section 6 and appendix in the <a href="https://arxiv.org/abs/1706.02690">paper</a></li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>Code available on <a href="https://github.com/ShiyuLiang/odin-pytorch">github</a></p>
+ </li>
+ <li>
+ <p>Models</p>
+
+ <ul>
+ <li>DenseNet with depth L = 100 and growth rate k = 12</li>
+ <li>Wide ResNet with depth = 28 and widen factor = 10</li>
+ </ul>
+ </li>
+ <li>
+ <p>In-Distribution Datasets</p>
+
+ <ul>
+ <li>CIFAR-10</li>
+ <li>CIFAR-100</li>
+ </ul>
+ </li>
+ <li>
+ <p>Out-of-Distribution Datasets</p>
+
+ <ul>
+ <li>TinyImageNet</li>
+ <li>LSUN</li>
+ <li>iSUN</li>
+ <li>Gaussian Noise</li>
+ </ul>
+ </li>
+ <li>
+ <p>Metrics</p>
+
+ <ul>
+ <li>False Positive Rate at 95% True Positive Rate</li>
+ <li>Detection Error - minimum misclassification probability over all thresholds</li>
+ <li>Area Under the Receiver Operating Characteristic Curve</li>
+ <li>Area Under the Precision-Recall Curve</li>
+ </ul>
+ </li>
+ <li>
+ <p>ODIN outperforms the baseline across all datasets and all models by a good margin.</p>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<ul>
+ <li>Very simple and straightforward approach with theoretical justification under some conditions.</li>
+ <li>Limited to examples from Vision so can not judge its applicability for NLP tasks.</li>
+</ul>
+
+
+
+
+ Ask Me Anything - Dynamic Memory Networks for Natural Language Processing
+
+ 2017-07-09T00:00:00-04:00
+ /site/2017/07/09/Ask Me Anything- Dynamic Memory Networks for Natural Language Processing
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>
+ <p>Dynamic Memory Networks (DMN) is a neural network based general framework that can be used for tasks like sequence tagging, classification, sequence to sequence and question answering requiring transitive reasoning.</p>
+ </li>
+ <li>
+ <p>The basic idea is that all these tasks can be modelled as question answering task in general and a common architecture could be used for solving them.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1506.07285">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>DMN takes as input a document(sentence, story, article etc) and a question which is to be answered given the document.</li>
+</ul>
+
+<h3 id="input-module">Input Module</h3>
+
+<ul>
+ <li>
+ <p>Concatenate all the sentences (or facts) in the document and encode them by feeding the word embeddings of the text to a GRU.</p>
+ </li>
+ <li>
+ <p>Each time a sentence ends, extract the hidden representation of the GRU till that point and use as the encoded representation of the sentence.</p>
+ </li>
+</ul>
+
+<h3 id="question-module">Question Module</h3>
+
+<ul>
+ <li>Similarly, feed the question to a GRU to obtain its representation.</li>
+</ul>
+
+<h3 id="episodic-memory-module">Episodic Memory Module</h3>
+
+<ul>
+ <li>
+ <p>Episodic memory consists of an attention mechanism and a recurrent network with which it updates its memory.</p>
+ </li>
+ <li>
+ <p>During each iteration, the network generates an episode <em>e</em> by attending over the representation of the sentences, question and the previous memory.</p>
+ </li>
+ <li>
+ <p>The episodic memory is updated using the current episode and the previous memory.</p>
+ </li>
+ <li>
+ <p>Depending on the amount of supervision available, the network may perform multiple passes. eg, in the bAbI dataset, some tasks specify how many passes would be needed and which sentence should be attended to in each pass. For others, a fixed number of passes are made.</p>
+ </li>
+ <li>
+ <p>Multiple passes allow the network to perform transitive inference.</p>
+ </li>
+</ul>
+
+<h3 id="attention-mechanism">Attention Mechanism</h3>
+
+<ul>
+ <li>
+ <p>Given the input representation <em>c</em>, memory <em>m</em> and question <em>q</em>, produce a scalar score using a 2-layer feedforward network, to use as attention mechanism.</p>
+ </li>
+ <li>
+ <p>A separate GRU encodes the input representation and weights it by the attention.</p>
+ </li>
+ <li>
+ <p>Final state of the GRU is fed to the answer module.</p>
+ </li>
+</ul>
+
+<h3 id="answer-module">Answer Module</h3>
+
+<ul>
+ <li>Use a GRU (initialized with the final state of the episodic module) and at each timestep, feed it the question vector, last hidden state of the same GRU and the previously predicted output.</li>
+</ul>
+
+<h3 id="training">Training</h3>
+
+<ul>
+ <li>There are two possible losses:
+ <ul>
+ <li>Cross-entropy loss of the predicted answer (all datasets)</li>
+ <li>Cross-entropy loss of the attention supervision (for datasets like bAbI)</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="question-answering">Question Answering</h3>
+
+<ul>
+ <li>
+ <p>bAbI Dataset</p>
+ </li>
+ <li>
+ <p>For most tasks, DMN either outperforms or performs as good as Memory Networks.</p>
+ </li>
+ <li>
+ <p>For tasks like answering with 2 or 3 supporting facts, DMN lags because of limitation of RNN in modelling long sentences.</p>
+ </li>
+</ul>
+
+<h3 id="text-classification">Text Classification</h3>
+
+<ul>
+ <li>
+ <p>Stanford Sentiment Treebank Dataset</p>
+ </li>
+ <li>
+ <p>DMN outperforms all the baselines for both binary and fine-grained sentiment analysis.</p>
+ </li>
+</ul>
+
+<h3 id="sequence-tagging">Sequence Tagging</h3>
+
+<ul>
+ <li>
+ <p>Wall Street Journal Dataset</p>
+ </li>
+ <li>
+ <p>DMN archives state of the art accuracy of 97.56%</p>
+ </li>
+</ul>
+
+<h2 id="observations">Observations</h2>
+
+<ul>
+ <li>
+ <p>Multiple passes help in reasoning tasks but not so much for sentiment/POS tags.</p>
+ </li>
+ <li>
+ <p>Attention in the case of 2-iteration DMN is more focused than attention in 1-iteration DMN.</p>
+ </li>
+ <li>
+ <p>For 2-iteration DMN, attention in the second iteration focuses only on relevant words and less attention is paid to words that lose their relevance in the context of the entire document.</p>
+ </li>
+</ul>
+
+<h2 id="notes">Notes</h2>
+
+<ul>
+ <li>
+ <p>It would be interesting to put some mechanism in place to determine the number of episodes that should be generated before an answer is predicted. A naive way would be to predict the answer after each episode and check if the softmax score of the predicted answer is more than a threshold.</p>
+ </li>
+ <li>
+ <p>Alternatively, the softmax score and other information could be fed to a Reinforcement Learning (RL) agent which decided if the document should be read again. So every time an episode is generated, the state is passed to the RL agent which decides if another iteration should be performed. If it decides to predict the answer and correct answer is generated, the agent gets a large +ve reward else a large -ve reward.</p>
+ </li>
+ <li>
+ <p>To discourage unnecessary iterations, a small -ve reward could be given everytime the agent decides to perform another iteration.</p>
+ </li>
+</ul>
+
+
+
+
+ One Model To Learn Them All
+
+ 2017-07-01T00:00:00-04:00
+ /site/2017/07/01/One Model To Learn Them All
+ <ul>
+ <li>
+ <p>The current trend in deep learning is to design, train and fine tune a separate model for each problem.</p>
+ </li>
+ <li>
+ <p>Though multi-task models have been explored, they have been trained for problems from the same domain only and no competitive multi-task, multi-modal models have been proposed.</p>
+ </li>
+ <li>
+ <p>The paper explores the possibility of such a unified deep learning model that can solve different tasks across multiple domains by training concurrently on them.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1706.05137">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h2 id="design-philosophy">Design Philosophy</h2>
+
+<ul>
+ <li>
+ <p>Small, modality-specific subnetworks (called modality nets) should be used to map input data to a joint representation space and back.</p>
+
+ <ul>
+ <li>
+ <p>The joint representation is to be of variable size.</p>
+ </li>
+ <li>
+ <p>Different tasks from the same domain share the modality net.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p>MultiModel networks should use computational blocks from different domains even if they are not specifically designed for the task at hand.</p>
+
+ <ul>
+ <li>Eg the paper reports that attention and mixture-of-experts (MOE) layers slightly improve the performance on ImageNet even though they are not explicitly needed.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="architecture">Architecture</h2>
+
+<ul>
+ <li>
+ <p>MulitModel Network consists of few, small modality nets, an encoder, I/O mixer and an autoregressive decoder.</p>
+ </li>
+ <li>
+ <p>Encoder and decoder use the following computational blocks:</p>
+
+ <ul>
+ <li>
+ <p><strong>Convolutional Block</strong></p>
+
+ <ul>
+ <li>ReLU activations on inputs followed by depthwise separable convolutions and layer normalization.</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Attention Block</strong></p>
+
+ <ul>
+ <li>Multihead, dot product based attention mechanism.</li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Mixture-of-Experts (MoE) Block</strong></p>
+
+ <ul>
+ <li>Consists of simple feed-forward networks (called experts) and a trainable gating network which selects a sparse combination of experts to process the inputs.</li>
+ </ul>
+ </li>
+ <li>
+ <p>For further details, refer the <a href="https://arxiv.org/abs/1706.05137">original paper</a>.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Encoder</strong> consists of 6 conv blocks with a MoE block in the middle.</p>
+ </li>
+ <li>
+ <p><strong>I/O mixer</strong> consists of an attention block and 2 conv blocks.</p>
+ </li>
+ <li>
+ <p><strong>Decoder</strong> consists of 4 blocks of convolution and attention with a MoE block in the middle.</p>
+ </li>
+ <li>
+ <p><strong>Modality Nets</strong></p>
+
+ <ul>
+ <li>
+ <p><strong>Language Data</strong></p>
+
+ <ul>
+ <li>
+ <p>Input is the sequence of tokens ending in a termination token.</p>
+ </li>
+ <li>
+ <p>This sequence is mapped to correct dimensionality using a learned embedding.</p>
+ </li>
+ <li>
+ <p>For output, the network takes the decoded output and performs a learned linear mapping followed by Softmax.</p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Image</strong> and <strong>Categorical Data</strong></p>
+
+ <ul>
+ <li>
+ <p>Uses residual convolution blocks.</p>
+ </li>
+ <li>
+ <p>Similar to the exit flow for <a href="https://arxiv.org/abs/1610.02357">Xception Network</a></p>
+ </li>
+ </ul>
+ </li>
+ <li>
+ <p><strong>Audio Data</strong></p>
+
+ <ul>
+ <li>1-d waveform over time or 2-d spectrogram operated upon by stack of 8 residual convolution blocks.</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="tasks">Tasks</h2>
+
+<ul>
+ <li>
+ <p>WSJ speech corpus</p>
+ </li>
+ <li>
+ <p>ImageNet dataset</p>
+ </li>
+ <li>
+ <p>COCO image captioning dataset</p>
+ </li>
+ <li>
+ <p>WSJ parsing dataset</p>
+ </li>
+ <li>
+ <p>WMT English-German translation corpus</p>
+ </li>
+ <li>
+ <p>German-English translation</p>
+ </li>
+ <li>
+ <p>WMT English-French translation corpus</p>
+ </li>
+ <li>
+ <p>German-French translation</p>
+ </li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>
+ <p>The experimental section is not very rigorous with many details skipped (would probably be added later).</p>
+ </li>
+ <li>
+ <p>While MultiModel does not beat the state of the art models, it does outperform some recent models.</p>
+ </li>
+ <li>
+ <p>Jointly trained model performs similar to single trained models on tasks with a lot of data and sometimes outperformed single trained models on tasks with less data (like parsing).</p>
+ </li>
+ <li>
+ <p>Interestingly, jointly training the model for parsing task and Imagenet tasks improves the performance of parsing task even though the two tasks are seemingly unrelated.</p>
+ </li>
+ <li>
+ <p>Another experiment was done to evaluate the effect of components (like MoE) on tasks (like Imagenet) which do not explicitly need them. It was observed that either the performance either went down or remained the same when MoE component was removed. This indicates that mixing different components does help to improve performance over multiple tasks.</p>
+ </li>
+ <li>
+ <p>But this observation is not conclusive as a different combination of say the encoder (that does not use MoE) could achieve better performance than one that does. The paper does not explore possibilities like these.</p>
+ </li>
+</ul>
+
+
+
+
+ Two/Too Simple Adaptations of Word2Vec for Syntax Problems
+
+ 2017-06-26T00:00:00-04:00
+ /site/2017/06/26/Two-Too Simple Adaptations of Word2Vec for Syntax Problems
+ <ul>
+ <li>The paper proposes two variants of Word2Vec model so that it may account for syntactic properties of words and perform better on syntactic tasks like POS tagging and dependency parsing.</li>
+ <li><a href="http://www.cs.cmu.edu/~lingwang/papers/naacl2015.pdf">Link to the paper</a></li>
+ <li>In the original Skip-Gram setting, the model predicts the <em>2c</em> words in the context window (<em>c</em> is the size of the context window). But it uses the same set of parameters whether predicting the word next to the centre word or the word farthest away, thus losing all information about the word order.</li>
+ <li>Similarly, the CBOW (Continuous Bas Of Words) model just adds the embedding of all the surrounding words thereby losing the word order information.</li>
+ <li>The paper proposes to use a set of <em>2c</em> matrices each for a different word in the context window for both Skip-Gram and CBOW models.</li>
+ <li>This simple trick allows for accounting of syntactic properties in the word vectors and improves the performance of dependency parsing task and POS tagging.</li>
+ <li>The downside of using this is that now the model has far more parameters than before which increases the training time and needs a large enough corpus to avoid sparse representation.</li>
+</ul>
+
+
+
+
+ A Decomposable Attention Model for Natural Language Inference
+
+ 2017-06-17T00:00:00-04:00
+ /site/2017/06/17/A Decomposable Attention Model for Natural Language Inference
+ <h3 id="introduction">Introduction</h3>
+
+<ul>
+ <li>The paper proposes an attention based mechanism to decompose the problem of Natural Language Inference (NLI) into parallelizable subproblems.</li>
+ <li>Further, it uses much fewer parameters as compared to any other model while obtaining state of the art results.</li>
+ <li><a href="https://arxiv.org/abs/1606.01933">Link to the paper</a></li>
+ <li>The motivation behind the paper is that the tasks like NLI do not require deep modelling of the sentence structure and comparison of local text substructures followed by aggregation can also work very well</li>
+</ul>
+
+<h3 id="approach">Approach</h3>
+
+<ul>
+ <li>
+ <p>Given two sentences <strong>a</strong> and <strong>b</strong>, the model has to predict whether they have an “entailment” relationship, “neutral” relationship or “contradiction” relationship.</p>
+ </li>
+ <li><strong>Embed</strong>
+ <ul>
+ <li>All the words are mapped to their corresponding word vector representation. In subsequent steps, “word” refers to the word vector representation of the actual word.</li>
+ </ul>
+ </li>
+ <li><strong>Attend</strong>
+ <ul>
+ <li>For each word <em>i</em> in <strong>a</strong> and <em>j</em> in <strong>b</strong>, obtain unnormalized attention weights *e(i, j)=F(i)<sup>T</sup>F(j) where F is a feed-forward neural network.</li>
+ <li>For <em>i</em>, compute a β<sub>i</sub> by performing softmax-like normalization of <em>j</em> using <em>e(i, j)</em> as the weight and normalizing for all words <em>j</em> in <strong>b</strong>.</li>
+ <li>β<sub>i</sub> captures the subphrase in <strong>b</strong> that is softly aligned to <em>a</em>.</li>
+ <li>Similarly compute α<sub>j</sub> for <em>j</em>.</li>
+ </ul>
+ </li>
+ <li><strong>Compare</strong>
+ <ul>
+ <li>Create two set of comparison vectors, one for <strong>a</strong> and another for <strong>b</strong></li>
+ <li>For <strong>a</strong>, <strong>v<sub>1, i</sub></strong> = G(concatenate(i, β<sub>i</sub>)).</li>
+ <li>Similarly for <strong>b</strong>, <strong>v<sub>2, j</sub></strong> = G(concatenate(j, α<sub>j</sub>))</li>
+ <li>G is another feed-forward neural network.</li>
+ </ul>
+ </li>
+ <li><strong>Aggregate</strong>
+ <ul>
+ <li>Aggregate over the two set of comparison vectors to obtain <strong>v<sub>1</sub></strong> and <strong>v<sub>2</sub></strong>.</li>
+ <li>Feed the aggregated results through the final classifier layer.</li>
+ <li>Multi-class cross-entropy loss function.</li>
+ </ul>
+ </li>
+ <li>The paper also explains how this representation can be augmented using intra-sentence attention to the model compositional relationship between words.</li>
+</ul>
+
+<h3 id="computational-complexity">Computational Complexity</h3>
+
+<ul>
+ <li>Computationally, the proposed model is asymptotically as good as LSTM with attention.</li>
+ <li>Assuming that dimensionality of word vectors > length of the sentence (reasonable for the given SNLI dataset), the model is asymptotically as good as regular LSTM.</li>
+ <li>Further, the model has the advantage of being parallelizable.</li>
+</ul>
+
+<h3 id="experiment">Experiment</h3>
+
+<ul>
+ <li>On Stanford Natural Language Inference (SNLI) dataset, the proposed model achieves the state of the art results even when it uses an order of magnitude lesser parameters than the next best model.</li>
+ <li>Adding intra-sentence attention further improve the test accuracy by 0.5 percent.</li>
+</ul>
+
+<h3 id="notes">Notes</h3>
+
+<ul>
+ <li>A similar approach could be tried on paraphrase detection problem as even that problem should not require very deep sentence representation. <a href="https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs">Quora Duplicate Question Detection Challenege</a> would have been an ideal dataset but it has a lot of out-of-vocabulary information related to named entities which need to be accounted for.</li>
+</ul>
+
+
+
+
+ A Fast and Accurate Dependency Parser using Neural Networks
+
+ 2017-06-03T00:00:00-04:00
+ /site/2017/06/03/A Fast and Accurate Dependency Parser using Neural Networks
+ <h2 id="introduction">Introduction</h2>
+<ul>
+ <li>The paper proposes a neural network classifier to perform transition-based dependency parsing using dense vector representation for the features.</li>
+ <li>Earlier approaches used a large, manually designed sparse feature vector which took a lot of time and effort to compute and was often incomplete.</li>
+ <li><a href="http://cs.stanford.edu/people/danqi/papers/emnlp2014.pdf">Link to the paper</a></li>
+</ul>
+
+<h2 id="description-of-the-system">Description of the system</h2>
+
+<ul>
+ <li>The system described in the paper uses <a href="http://www.mitpressjournals.org/doi/pdf/10.1162/coli.07-056-R1-07-027"><strong>arc-standard</strong> system</a> (a greedy, transition-based dependency parsing system).</li>
+ <li>Words, POS tags and arc labels are represented as d dimensional vectors.</li>
+ <li>S<sup>w</sup>, S<sup>t</sup>, S<sup>l</sup> denote the set of words, POS and labels respectively.</li>
+ <li>Neural network takes as input selected words from the 3 sets and uses a single hidden layer followed by Softmax which models the different actions that can be chosen by the arc-standard system.</li>
+ <li>Uses a cube activation function to allow interaction between features coming from the set of words, POS and labels in the first layer itself. These features come from different embeddings and are not related as such.</li>
+ <li>Using separate embedding for POS tags and labels allow for capturing aspects like NN (singular noun) should be closer to NNS (plural noun) than DT (determiner).</li>
+ <li>Input to the network contains words on the stack and buffer and their left and right children (read upon transition-based parsing), their labels and corresponding arc labels.</li>
+ <li>Output generated by the system is the action to be taken (transition to be performed) when reading each word in the input.</li>
+ <li>This sequential and deterministic nature of the input-output mapping allows the problem to be modelled as a supervised learning problem and a cross entropy loss can be used.</li>
+ <li>L2-regularization term is also added to the loss.</li>
+ <li>During inference, a greedy decoding strategy is used and transition with the highest score is chosen.</li>
+ <li>The paper mentions a pre-computation trick where matrix computation of most frequent top 10000 words is performed beforehand and cached.</li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>Dataset
+ <ul>
+ <li>English Penn Treebank (PTB)</li>
+ <li>Chinese Penn Treebank (CTB)</li>
+ </ul>
+ </li>
+ <li>Two dependency representations used:
+ <ul>
+ <li>CoNLL Syntactic Dependencies (CD)</li>
+ <li>Stanford Basic Dependencies (SD)</li>
+ </ul>
+ </li>
+ <li>Metrics:
+ <ul>
+ <li>Unlabeled Attached Scores (UAS)</li>
+ <li>Labeled Attached Scores (LAS)</li>
+ </ul>
+ </li>
+ <li>Benchmarked against:
+ <ul>
+ <li>Greedy arc-eager parser</li>
+ <li>Greedy arc-standard parser</li>
+ <li>Malt-Parser</li>
+ <li>MSTParser</li>
+ </ul>
+ </li>
+ <li>Results
+ <ul>
+ <li>The system proposed in the paper outperforms all other parsers in both speed and accuracy.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="analysis">Analysis</h2>
+
+<ul>
+ <li>Cube function gives a 0.8-1.2% improvement over tanh.</li>
+ <li>Pretained embeddings give 0.7-1.7% improvement over training embeddings from scratch.</li>
+ <li>Using POS and labels gives an improvement of 1.7% and 0.4% respectively.</li>
+</ul>
+
+
+
+
+ Neural Module Networks
+
+ 2017-05-23T00:00:00-04:00
+ /site/2017/05/23/Neural Module Networks
+ <h2 id="introduction">Introduction</h2>
+
+<ul>
+ <li>For the task of <a href="https://shagunsodhani.in/papers-I-read/VQA-Visual-Question-Answering">Visual Question Answering</a>, decompose a question into its linguistic substructures and train a neural network module for each substructure.</li>
+ <li>Jointly train the modules and dynamically compose them into deep networks which can learn to answer the question.</li>
+ <li>Start by analyzing the question and decide what logical units are needed to answer the question and what should be the relationship between them.</li>
+ <li>The paper also introduces a new dataset for Visual Question Answering which has challenging, highly compositional questions about abstract shapes.</li>
+ <li><a href="https://arxiv.org/abs/1511.02799">Link to the paper</a></li>
+</ul>
+
+<h2 id="inspiration">Inspiration</h2>
+
+<ul>
+ <li>Questions tend to be compositional.</li>
+ <li>Different architectures are needed for different tasks - CNNs for object detection, RNNs for counting.</li>
+ <li>Recurrent and Recursive Neural Networks also use the idea of a different network graph for each input.</li>
+</ul>
+
+<h2 id="neural-module-network-for-vqa">Neural Module Network for VQA</h2>
+
+<ul>
+ <li>Training samples of form <em>(w, x, y)</em>
+ <ul>
+ <li><em>w</em> - Natural Language Question</li>
+ <li><em>x</em> - Images</li>
+ <li><em>y</em> - Answer</li>
+ </ul>
+ </li>
+ <li>Model specified by collection of modules <em>{m}</em> and a network layout predictor <em>P</em>.</li>
+ <li>Model instantiates a network based on <em>P(w)</em> and uses that to encode a distribution <em>P(y|w, x, model_params)</em></li>
+</ul>
+
+<h2 id="modules">Modules</h2>
+
+<ul>
+ <li>Find: Finds objects of interest.</li>
+ <li>Transform: Shift regions of attention.</li>
+ <li>Combine: Merge two attention maps into a single one.</li>
+ <li>Describe: Map a pair of attention and input image to a distribution over the labels.</li>
+ <li>Measure: Map attention to a distribution over the labels.</li>
+</ul>
+
+<h2 id="natural-language-question-to-networks">Natural Language Question to Networks</h2>
+
+<ul>
+ <li>Map question to the layout which specifies the set of modules and connections between them.</li>
+ <li>Assemble the final network using the layout.</li>
+ <li>Parse the input question to obtain set of dependencies and obtain a representation similar to combinatory logic.</li>
+ <li>eg “what is the colour of the truck?” becomes “colour(truck)”</li>
+ <li>The symbolic representation is mapped to a layout:
+ <ul>
+ <li>All leaves become <em>find</em> module.</li>
+ <li>All internal nodes become <em>transform/combine</em> module.</li>
+ <li>All root nodes become <em>describe/measure</em> module.</li>
+ </ul>
+ </li>
+</ul>
+
+<h2 id="answering-natural-language-question">Answering Natural Language Question</h2>
+
+<ul>
+ <li>Final model combines output from a simple LSTM question encoder with the output of the neural module network.</li>
+ <li>This helps in modelling the syntactic and semantic regularities of the question.</li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<ul>
+ <li>Since some modules are updated more frequently than others, adaptive per weight learning rates are better.</li>
+ <li>The paper introduces a small SHAPES datasets (64 images and 244 unique questions per image).</li>
+ <li>Neural Module Network achieves a score of 90% on SHAPES dataset while VIS + LSTM baseline achieves an accuracy of 65.3%.</li>
+ <li>Even on natural images (VQA dataset), the neural module network outperforms the VIS + LSTM baseline.</li>
+</ul>
+
+
+
+
+
+ Making the V in VQA Matter - Elevating the Role of Image Understanding in Visual Question Answering
+
+ 2017-05-14T00:00:00-04:00
+ /site/2017/05/14/Making the V in VQA Matter - Elevating the Role of Image Understanding in Visual Question Answering
+ <h3 id="problem-statement">Problem Statement</h3>
+
+<ul>
+ <li>Standard VQA models benefit from the inherent bias in the structure of the world and the language of the question.</li>
+ <li>For example, if the question starts with “Do you see a …”, it is more likely to be “yes” than “no”.</li>
+ <li>To truly assess the capability of any VQA system, we need to have evaluation tasks that require the use of both the visual and the language modality.</li>
+ <li>The authors present a balanced version of <a href="https://shagunsodhani.in/papers-I-read/VQA-Visual-Question-Answering">VQA dataset</a> where each question in the dataset is associated with a pair of similar images such that the same question would give different answers on the two images.</li>
+ <li>The proposed data collection procedure enables the authors to develop a novel interpretable model which, given an image and a question, identifies an image that is similar to the original image but has a different answer to the same question thereby building trust for the system.</li>
+ <li><a href="https://arxiv.org/abs/1612.00837">Link to the paper</a></li>
+</ul>
+
+<h3 id="dataset-collection">Dataset Collection</h3>
+
+<ul>
+ <li>Given an (image, question, answer) triplet (I, Q, A) from the VQA dataset, a human worker (on AMT) is asked to identify an image I’ which is similar to I but for which the answer to question Q is A’ (different from A).</li>
+ <li>To facilitate the search for I’, the worker is shown 24 nearest-neighbor images of I (based on VGGNet features) and is asked to choose the most similar image to I, for which Q makes sense and answer for Q is different than A. In case none of the 24 images qualifies, the worker may select “not possible”.</li>
+ <li>In the second round, the workers were asked to answer Q for I’.</li>
+ <li>This 2-stage protocol results in a significantly more balanced dataset than the previous dataset.</li>
+</ul>
+
+<h3 id="observation">Observation</h3>
+
+<ul>
+ <li>State-of-the-art models trained on unbalanced VQA dataset perform significantly worse on the new, balanced dataset indicating that those models benefitted from the language bias in the older dataset.</li>
+ <li>Training on balanced dataset improves performance on the unbalanced dataset.</li>
+ <li>Further, the VQA model, trained on the balanced dataset, learns to differentiate between otherwise similar images.</li>
+</ul>
+
+<h3 id="counter-example-explanations">Counter-example Explanations</h3>
+
+<ul>
+ <li>Given an image and a question, the model not only answers the question, it also provides an image (from the k nearest neighbours of I, based on VGGNet features) which is similar to the input image but for which the model would have given different answer for the same image.</li>
+ <li>Supervising signal is provided by the data collection procedure where humans pick the image I’ from the same set of candidate images.</li>
+ <li>For each image in the candidate set, compute the inner product of question-image embedding and answer embedding.</li>
+ <li>The K inner product values are passed through a fully connected layer to generate K scores.</li>
+ <li>Trained with pairwise hinge ranking loss so that the score of the human picked image is higher than the score of all other images by a margin of M (hyperparameter).</li>
+ <li>The proposed explanation model achieves a recall@5 of 43.49%</li>
+</ul>
+
+
+
+
+ Conditional Similarity Networks
+
+ 2017-05-07T00:00:00-04:00
+ /site/2017/05/07/Conditional Similarity Networks
+ <h2 id="problem-statement">Problem Statement</h2>
+
+<ul>
+ <li>A common way of measuring image similarity is to embed them into feature spaces where distance acts as a proxy for similarity.</li>
+ <li>But this feature space can capture one (or a weighted combination) of the many possible notions of similarity.</li>
+ <li>What if contracting notions of similarity could be captured at the same time - in terms of semantically distinct subspaces.</li>
+ <li>The paper proposes a new architecture called as Conditional Similarity Networks (CSNs) which learns a disentangled embedding such that the features, for different notions of similarity, are encoded into separate dimensions.</li>
+ <li>It jointly learns masks (or feature extractors) that select and reweights relevant dimensions to induce a subspace that encodes a specific notion of similarity.</li>
+ <li><a href="https://vision.cornell.edu/se3/conditional-similarity-networks/">Link to the paper</a></li>
+</ul>
+
+<h2 id="conditional-similarity-networks">Conditional Similarity Networks</h2>
+
+<ul>
+ <li>Given an image, <em>x</em>, learn a non-linear feature embedding <em>f(x)</em> such that for any 2 images <em>x<sub>1</sub></em> and <em>x<sub>2</sub></em>, the euclidean distance between <em>f(x<sub>1</sub>)</em> and <em>f(x<sub>2</sub>)</em> reflects their similarity.</li>
+</ul>
+
+<h3 id="conditional-similarity-triplets">Conditional Similarity Triplets</h3>
+
+<ul>
+ <li>Given a triplet of images <em>(x<sub>1</sub>, x<sub>2</sub>, x<sub>3</sub>)</em> and a condition <em>c</em> (the notion of similarity), an oracle (say crowd) is used to determmine if <em>x<sub>1</sub></em> is more similar to <em>x<sub>2</sub></em> or <em>x<sub>3</sub></em> as per the given criteria <em>c</em>.</li>
+ <li>In general, for images <em>i, j, l</em>, the triplet <em>t</em> is ordered {i, j, l | c} if <em>i</em> is more similar to <em>j</em> than <em>l</em>.</li>
+</ul>
+
+<h3 id="learning-from-triplets">Learning From Triplets</h3>
+
+<ul>
+ <li>Define a loss function <em>L<sub>T</sub>()</em> to model the similarity structure over the triplets.</li>
+ <li><em>L<sub>T</sub>(i, j, l) = max{0, D(i, j) - D(i, l) + h}</em> where <em>D</em> is the euclidean distance function and <em>h</em> is the similarity scalar margin to prevent trivial solutions.</li>
+ <li>To model conditional similarities, masks <em>m</em> are defined as <em>m = σ(β)</em> where σ is the RELU unit and β is a set of parameters to be learnt.</li>
+ <li><em>m<sub>c</sub></em> denotes the selection of the c-th mask column from feature vector. It thus acts as an element-wise gating function which selects the relevant dimensions of the embedding to attend to a particular similarity concept.</li>
+ <li>The euclidean function <em>D</em> now computes the masked distance (<em>f(i, c)m<sub>c</sub></em>) between the two given images.</li>
+ <li>Two regularising terms are also added - L2 norm for <em>D</em> and L1 norm for <em>m</em>.</li>
+</ul>
+
+<h2 id="experiments">Experiments</h2>
+
+<h3 id="datasets">Datasets</h3>
+
+<ul>
+ <li>Fonts dataset by Bernhardsson
+ <ul>
+ <li>3.1 million 64 by 64-pixel grey scale images.</li>
+ </ul>
+ </li>
+ <li>Zappos50k shoe dataset
+ <ul>
+ <li>Contains 50,000 images of individual richly annotated shoes.</li>
+ <li>Characteristics of interest:
+ <ul>
+ <li>Type of the shoes (i.e., shoes, boots, sandals or slippers)</li>
+ <li>Suggested gender of the shoes (i.e., for women, men, girls or boys)</li>
+ <li>Height of the shoes’ heels (0 to 5 inches)</li>
+ <li>Closing mechanism of the shoes (buckle, pull on, slip on, hook and loop or laced up)</li>
+ </ul>
+ </li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="models">Models</h3>
+
+<ul>
+ <li>Initial model for the experiments is a ConvNet pre-trained on ImageNet</li>
+ <li><strong>Standard Triplet Network</strong>
+ <ul>
+ <li>Learn from all available triplets jointly as if they have the same notion of similarity.</li>
+ </ul>
+ </li>
+ <li><strong>Set of Task Specific Triplet Networks</strong>
+ <ul>
+ <li>Train n separate triplet networks such that each is trained on a single notion of similarity.</li>
+ <li>Needs far more parameters and compute.</li>
+ </ul>
+ </li>
+ <li><strong>Conditional Similarity Networks - fixed disjoint masks</strong>
+ <ul>
+ <li>In this version, only the convolutional filters and the embedding is learnt and masks are predefined to be disjoint.</li>
+ <li>Aims to learn a fully disjoint embedding.</li>
+ </ul>
+ </li>
+ <li><strong>Conditional Similarity Networks - learned masks</strong>
+ <ul>
+ <li>Learns all the components - conv filters, embedding and the masks.</li>
+ </ul>
+ </li>
+ <li>Refer paper for details on hyperparameters.</li>
+</ul>
+
+<h2 id="results">Results</h2>
+
+<ul>
+ <li>Visual exploration of the learned subspaces (t-sne visualisation) show that network successfully disentangles different features in the embedded vector space.</li>
+ <li>The learned masks are very sparse and share dimensions. This shows that CSNs may learn to only use the required number of dimensions thereby doing away with the need of picking the right size of embedding.</li>
+ <li>Order of performance:
+ <ul>
+ <li>CSNs with learned masks > CSNs with fixed masks > Task-specific networks > standard triplet network.</li>
+ <li>Though CSNs with learned masks require more training data.</li>
+ </ul>
+ </li>
+ <li>CSNs also outperform Standard Triplet Network when used as off the shelf features for (brand) classification task and is very close to the performance of ResNet trained on ImageNet.</li>
+ <li>This shows that while CSN retained most of the information in the original network, the training mechanism of Standard Triplet Network hurts the underlying conv features and their generalising capability</li>
+</ul>
+
+
+
+
+ Simple Baseline for Visual Question Answering
+
+ 2017-04-28T00:00:00-04:00
+ /site/2017/04/28/Simple Baseline for Visual Question Answering
+ <h3 id="problem-statement">Problem Statement</h3>
+
+<ul>
+ <li>VQA Task: Given an image and a free-form, open-ended, natural language question (about the image), produce the answer for the image.</li>
+ <li>The paper attempts to fine tune the simple baseline method of Bag-of-Words + Image features (iBOWIMG) to make it competitive against more sophisticated LSTM models.</li>
+ <li><a href="http://arxiv.org/pdf/1512.02167.pdf">Link to the paper</a></li>
+</ul>
+
+<h3 id="model">Model</h3>
+
+<ul>
+ <li>VQA modelled as a classification task where the system learns to choose among one of the top k most prominent answers.</li>
+ <li><strong>Text Features</strong> - Convert input question to a one-hot vector and then transform to word vectors using a word embedding.</li>
+ <li><strong>Image Features</strong> - Last layer activations from GoogLeNet.</li>
+ <li>Text features are concatenated with image features and fed into a softmax.</li>
+ <li>Different learning rates and weight clipping for word embedding layer and softmax layer with the learning rate for embedding layer much higher than that of softmax layer.</li>
+</ul>
+
+<h3 id="results">Results</h3>
+
+<ul>
+ <li>iBOWIMG model reports an accuracy of 55.89% for Open-ended questions and 61.97% for Multiple-Choice questions which is comparable to the performance of other, more sophisticated models.</li>
+</ul>
+
+<h3 id="interpretation-of-the-model">Interpretation of the model</h3>
+
+<ul>
+ <li>Since the model is very simple, it is possible to interpret the model to know what exactly is the model learning. This is the greatest strength of the paper even though the model is very simple and naive.</li>
+ <li>The model attempts to memorise the correlation between the answer class and the informative words (in the question) and image features.</li>
+ <li>Question words generally can influence the answer given the bias in images occurring in COCO dataset.</li>
+ <li>Given the simple linear transformation being used, it is possible to quantify the importance of each single words (in the question) to the answer.</li>
+ <li>The paper uses the Class Activation Mapping (CAM) approach (which uses the linear relation between softmax and final image feature map) to highlight the informative image regions relevant to the predicted answer.</li>
+ <li>While the results reported by the paper are not themselves so significant, the described approach provides a way to interpret the strengths and weakness of different VQA datasets.</li>
+</ul>
+
+
+
+
+ VQA-Visual Question Answering
+
+ 2017-04-27T00:00:00-04:00
+ /site/2017/04/27/VQA Visual Question Answering
+ <h3 id="problem-statement">Problem Statement</h3>
+
+<ul>
+ <li>
+ <p>Given an image and a free-form, open-ended, natural language question (about the image), produce the answer for the image.</p>
+ </li>
+ <li>
+ <p><a href="https://arxiv.org/abs/1505.00468v6">Link to the paper</a></p>
+ </li>
+</ul>
+
+<h3 id="vqa-challenge-and-workshop"><a href="http://www.visualqa.org/">VQA Challenge and Workshop</a></h3>
+
+<ul>
+ <li>The authors organise an annual challenge and workshop to discuss the state-of-the-art methods and best practices in this domain.</li>
+ <li>Interestingly, the second version is starting on 27th April 2017 (today).</li>
+</ul>
+
+<h3 id="benefits-over-tasks-like-image-captioning">Benefits over tasks like image captioning:</h3>
+
+<ul>
+ <li>Simple, <em>n-gram</em> statistics based methods are not sufficient.</li>
+ <li>Requires the system to blend in different aspects of knowledge - object detection, activity recognition, commonsense reasoning etc.</li>
+ <li>Since only short answers are expected, evaluation is easier.</li>
+</ul>
+
+<h3 id="dataset">Dataset</h3>
+
+<ul>
+ <li>Created a new dataset of 50000 realistic, abstract images.</li>
+ <li>Used AMT to crowdsource the task of collecting questions and answers for MS COCO dataset (>200K images) and abstract images.</li>
+ <li>Three questions per image and ten answers per question (along with their confidence) were collected.</li>
+ <li>The entire dataset contains over 760K questions and 10M answers.</li>
+ <li>The authors also performed an exhaustive analysis of the dataset to establish its diversity and to explore how the content of these question-answers differ from that of standard image captioning datasets.</li>
+</ul>
+
+<h3 id="highlights-of-data-collection-methodology">Highlights of data collection methodology</h3>
+
+<ul>
+ <li>Emphasis on questions that require an image, and not just common sense, to be answered correctly.</li>
+ <li>Workers were shown previous questions when writing new questions to increase diversity.</li>
+ <li>Answers collected from multiple users to account for discrepancies in answers by humans.</li>
+ <li>Two modalities supported:
+ <ul>
+ <li><strong>Open-ended</strong> - produce the answer</li>
+ <li><strong>multiple-choice</strong> - select from a set of options provided (18 options comprising of popular, plausible, random and ofc correct answer)</li>
+ </ul>
+ </li>
+</ul>
+
+<h3 id="highlights-from-data-analysis">Highlights from data analysis</h3>
+
+<ul>
+ <li>Most questions range from four to ten words while answers range from one to three words.</li>
+ <li>Around 40% questions are “yes/no” questions.</li>
+ <li>Significant (>80%) inter-human agreement for answers.</li>
+ <li>The authors performed a study where human evaluators were asked to answer the questions without looking at the images.</li>
+ <li>Further, they performed a study where evaluators were asked to label if a question could be answered using common sense and what was the youngest age group, they felt, could answer the question.</li>
+ <li>The idea was to establish that a sufficient number of questions in the dataset required more than just common sense to answer.</li>
+</ul>
+
+<h3 id="baseline-models">Baseline Models</h3>
+
+<ul>
+ <li><strong>random</strong> selection</li>
+ <li><strong>prior (“yes”)</strong> - always answer as yes.</li>
+ <li><strong>per Q-type prior</strong> - pick the most popular answer per question type.</li>
+ <li><strong>nearest neighbor</strong> - find the k nearest neighbors for the given (image, question) pair.</li>
+</ul>
+
+<h3 id="methods">Methods</h3>
+
+<ul>
+ <li>
+ <p>2-channel model (using vision and language models) followed by softmax over (K = 1000) most frequent answers.</p>
+ </li>
+ <li><strong>Image Channel</strong>
+ <ul>
+ <li><strong>I</strong> - Used last hidden layer of VGGNet to obtain 4096-dim image embedding.</li>
+ <li><strong>norm I</strong> - : l2 normalized version of <strong>I</strong>.</li>
+ </ul>
+ </li>
+ <li><strong>Question Channel</strong>
+ <ul>
+ <li><strong>BoW Q</strong> - Bag-of-Words representation for the questions using the top 1000 words plus the top 1- first, second and third words of the questions.</li>
+ <li><strong>LSTM Q</strong> - Each word is encoded into 300-dim vectors using fully connected + tanh non-linearity. These embeddings are fed to an LSTM to obtain 1024d-dim embedding.</li>
+ <li><strong>Deeper LSTM Q</strong> - Same as LSTM Q but uses two hidden layers to obtain 2048-dim embedding.</li>
+ </ul>
+ </li>
+ <li><strong>Multi-Layer Perceptron (MLP)</strong> - Combine image and question embeddings to obtain a single embedding.
+ <ul>
+ <li><strong>BoW Q + I</strong> method - concatenate BoW Q and I embeddings.</li>
+ <li><strong>LSTM Q + I, deeper LSTM Q + norm I</strong> methods - image embedding transformed to 1024-dim using a FC layer and tanh non-linearity followed by element-wise multiplication of image and question vectors.</li>
+ </ul>
+ </li>
+ <li>Pass combined embedding to an MLP - FC neural network with 2 hidden layers (1000 neurons and 0.5 dropout) with tanh, followed by softmax.</li>
+ <li>Cross-entropy loss with VGGNet parameters frozen.</li>
+</ul>
+
+<h3 id="results">Results</h3>
+
+<ul>
+ <li>Deeper LSTM Q + norm I is the best model with 58.16% accuracy on open-ended dataset and 63.09% on multiple-choice but far behind the human evaluators (>80% and >90% respectively).</li>
+ <li>The best model performs well for answers involving common visual objects but performs poorly for answers involving counts.</li>
+ <li>Vision only model performs even worse than the model which always produces “yes” as the answer.</li>
+</ul>
+
+
+
+
+
diff --git a/_site/site/index.html b/_site/site/index.html
new file mode 100644
index 00000000..c842c537
--- /dev/null
+++ b/_site/site/index.html
@@ -0,0 +1,13 @@
+
+
+
+
+
+
+ Older
+
+
+ Newer
+
+
+
diff --git a/_site/site/index.html.1 b/_site/site/index.html.1
new file mode 100755
index 00000000..cac41710
--- /dev/null
+++ b/_site/site/index.html.1
@@ -0,0 +1,924 @@
+#!/usr/bin/env bash
+
+shopt -s extglob
+set -o errtrace
+set -o errexit
+
+rvm_install_initialize()
+{
+ DEFAULT_SOURCES=(github.com/rvm/rvm bitbucket.org/mpapis/rvm)
+
+ BASH_MIN_VERSION="3.2.25"
+ if
+ [[ -n "${BASH_VERSION:-}" &&
+ "$(\printf "%b" "${BASH_VERSION:-}\n${BASH_MIN_VERSION}\n" | LC_ALL=C \sort -t"." -k1,1n -k2,2n -k3,3n | \head -n1)" != "${BASH_MIN_VERSION}"
+ ]]
+ then
+ echo "BASH ${BASH_MIN_VERSION} required (you have $BASH_VERSION)"
+ exit 1
+ fi
+
+ export HOME PS4
+ export rvm_trace_flag rvm_debug_flag rvm_user_install_flag rvm_ignore_rvmrc rvm_prefix rvm_path
+
+ PS4="+ \${BASH_SOURCE##\${rvm_path:-}} : \${FUNCNAME[0]:+\${FUNCNAME[0]}()} \${LINENO} > "
+}
+
+log() { printf "%b\n" "$*"; }
+debug(){ [[ ${rvm_debug_flag:-0} -eq 0 ]] || printf "%b\n" "Running($#): $*"; }
+fail() { log "\nERROR: $*\n" ; exit 1 ; }
+
+rvm_install_commands_setup()
+{
+ \which which >/dev/null 2>&1 || fail "Could not find 'which' command, make sure it's available first before continuing installation."
+ \which grep >/dev/null 2>&1 || fail "Could not find 'grep' command, make sure it's available first before continuing installation."
+ if
+ [[ -z "${rvm_tar_command:-}" ]] && builtin command -v gtar >/dev/null
+ then
+ rvm_tar_command=gtar
+ elif
+ ${rvm_tar_command:-tar} --help 2>&1 | GREP_OPTIONS="" \grep -- --strip-components >/dev/null
+ then
+ rvm_tar_command="${rvm_tar_command:-tar}"
+ else
+ case "$(uname)" in
+ (OpenBSD)
+ log "Trying to install GNU version of tar, might require sudo password"
+ if (( UID ))
+ then sudo pkg_add -z gtar-1
+ else pkg_add -z gtar-1
+ fi
+ rvm_tar_command=gtar
+ ;;
+ (Darwin|FreeBSD|DragonFly) # it's not possible to autodetect on OSX, the help/man does not mention all flags
+ rvm_tar_command=tar
+ ;;
+ (SunOS)
+ case "$(uname -r)" in
+ (5.10)
+ log "Trying to install GNU version of tar, might require sudo password"
+ if (( UID ))
+ then
+ if \which sudo >/dev/null 2>&1
+ then sudo_10=sudo
+ elif \which /opt/csw/bin/sudo >/dev/null 2>&1
+ then sudo_10=/opt/csw/bin/sudo
+ else fail "sudo is required but not found. You may install sudo from OpenCSW repository (https://www.opencsw.org/about)"
+ fi
+ pkginfo -q CSWpkgutil || $sudo_10 pkgadd -a $rvm_path/config/solaris/noask -d https://get.opencsw.org/now CSWpkgutil
+ sudo /opt/csw/bin/pkgutil -iy CSWgtar -t https://mirror.opencsw.org/opencsw/unstable
+ else
+ pkginfo -q CSWpkgutil || pkgadd -a $rvm_path/config/solaris/noask -d https://get.opencsw.org/now CSWpkgutil
+ /opt/csw/bin/pkgutil -iy CSWgtar -t https://mirror.opencsw.org/opencsw/unstable
+ fi
+ rvm_tar_command=/opt/csw/bin/gtar
+ ;;
+ (*)
+ rvm_tar_command=tar
+ ;;
+ esac
+ esac
+ builtin command -v ${rvm_tar_command:-gtar} >/dev/null ||
+ fail "Could not find GNU compatible version of 'tar' command, make sure it's available first before continuing installation."
+ fi
+ if
+ [[ " ${rvm_tar_options:-} " != *" --no-same-owner "* ]] &&
+ $rvm_tar_command --help 2>&1 | GREP_OPTIONS="" \grep -- --no-same-owner >/dev/null
+ then
+ rvm_tar_options="${rvm_tar_options:-}${rvm_tar_options:+ }--no-same-owner"
+ fi
+}
+
+usage()
+{
+ printf "%b" "
+
+Usage
+
+ rvm-installer [options] [action]
+
+Options
+
+ [[--]version]
+
+ The version or tag to install. Valid values are:
+
+ latest - The latest tagged version.
+ latest-minor - The latest minor version of the current major version.
+ latest- - The latest minor version of version x.
+ latest-. - The latest patch version of version x.y.
+ .. - Major version x, minor version y and patch z.
+
+ [--]branch
+
+ The name of the branch from which RVM is installed. This option can be used
+ with the following formats for :
+
+ /
+
+ If account is wayneeseguin or mpapis, installs from one of the following:
+
+ https://github.com/rvm/rvm/archive/master.tar.gz
+ https://bitbucket.org/mpapis/rvm/get/master.tar.gz
+
+ Otherwise, installs from:
+
+ https://github.com//rvm/archive/master.tar.gz
+
+ /
+
+ If account is wayneeseguin or mpapis, installs from one of the following:
+
+ https://github.com/rvm/rvm/archive/.tar.gz
+ https://bitbucket.org/mpapis/rvm/get/.tar.gz
+
+ Otherwise, installs from:
+
+ https://github.com//rvm/archive/.tar.gz
+
+ [/]
+
+ Installs the branch from one of the following:
+
+ https://github.com/rvm/rvm/archive/.tar.gz
+ https://bitbucket.org/mpapis/rvm/get/.tar.gz
+
+ [--]source
+
+ Defines the repository from which RVM is retrieved and installed in the format:
+
+ //
+
+ Where:
+
+ - Is bitbucket.org, github.com or a github enterprise site serving
+ an RVM repository.
+ - Is the user account in which the RVM repository resides.
+ - Is the name of the RVM repository.
+
+ Note that when using the [--]source option, one should only use the [/]branch format
+ with the [--]branch option. Failure to do so will result in undefined behavior.
+
+ --trace
+
+ Provides debug logging for the installation script.
+Actions
+
+ master - Installs RVM from the master branch at rvm/rvm on github or mpapis/rvm
+ on bitbucket.org.
+ stable - Installs RVM from the stable branch a rvm/rvm on github or mpapis/rvm
+ on bitbucket.org.
+ help - Displays this output.
+
+"
+}
+
+## duplication marker 32fosjfjsznkjneuera48jae
+__rvm_curl_output_control()
+{
+ if
+ (( ${rvm_quiet_curl_flag:-0} == 1 ))
+ then
+ __flags+=( "--silent" "--show-error" )
+ elif
+ [[ " $*" == *" -s"* || " $*" == *" --silent"* ]]
+ then
+ # make sure --show-error is used with --silent
+ [[ " $*" == *" -S"* || " $*" == *" -sS"* || " $*" == *" --show-error"* ]] ||
+ {
+ __flags+=( "--show-error" )
+ }
+ fi
+}
+
+## duplication marker 32fosjfjsznkjneuera48jae
+# -S is automatically added to -s
+__rvm_curl()
+(
+ __rvm_which curl >/dev/null ||
+ {
+ rvm_error "RVM requires 'curl'. Install 'curl' first and try again."
+ return 200
+ }
+
+ typeset -a __flags
+ __flags=( --fail --location --max-redirs 10 )
+
+ [[ "$*" == *"--max-time"* ]] ||
+ [[ "$*" == *"--connect-timeout"* ]] ||
+ __flags+=( --connect-timeout 30 --retry-delay 2 --retry 3 )
+
+ if [[ -n "${rvm_proxy:-}" ]]
+ then __flags+=( --proxy "${rvm_proxy:-}" )
+ fi
+
+ __rvm_curl_output_control
+
+ unset curl
+ __rvm_debug_command \curl "${__flags[@]}" "$@" || return $?
+)
+
+rvm_error() { printf "ERROR: %b\n" "$*"; }
+__rvm_which(){ which "$@" || return $?; true; }
+__rvm_debug_command()
+{
+ debug "Running($#): $*"
+ "$@" || return $?
+ true
+}
+rvm_is_a_shell_function()
+{
+ [[ -t 0 && -t 1 ]] || return $?
+ return ${rvm_is_not_a_shell_function:-0}
+}
+
+# Searches the tags for the highest available version matching a given pattern.
+# fetch_version (github.com/rvm/rvm bitbucket.org/mpapis/rvm) 1.10. -> 1.10.3
+# fetch_version (github.com/rvm/rvm bitbucket.org/mpapis/rvm) 1.10. -> 1.10.3
+# fetch_version (github.com/rvm/rvm bitbucket.org/mpapis/rvm) 1. -> 1.11.0
+# fetch_version (github.com/rvm/rvm bitbucket.org/mpapis/rvm) "" -> 2.0.1
+fetch_version()
+{
+ typeset _account _domain _pattern _repo _sources _values _version
+ _sources=(${!1})
+ _pattern=$2
+ for _source in "${_sources[@]}"
+ do
+ IFS='/' read -r _domain _account _repo <<< "${_source}"
+ _version="$(
+ fetch_versions ${_domain} ${_account} ${_repo} |
+ GREP_OPTIONS="" \grep "^${_pattern:-}" | tail -n 1
+ )"
+ if
+ [[ -n ${_version} ]]
+ then
+ echo "${_version}"
+ return 0
+ fi
+ done
+}
+
+# Returns a sorted list of all version tags from a repository
+fetch_versions()
+{
+ typeset _account _domain _repo _url
+ _domain=$1
+ _account=$2
+ _repo=$3
+ case ${_domain} in
+ (bitbucket.org)
+ _url=https://${_domain}/api/1.0/repositories/${_account}/${_repo}/branches-tags
+ ;;
+ (github.com)
+ _url=https://api.${_domain}/repos/${_account}/${_repo}/tags
+ ;;
+
+ (*)
+ _url=https://${_domain}/api/v3/repos/${_account}/${_repo}/tags
+ ;;
+ esac
+ __rvm_curl -s ${_url} |
+ \awk -v RS=',' -v FS='"' '$2=="name"{print $4}' |
+ sort -t. -k 1,1n -k 2,2n -k 3,3n -k 4,4n -k 5,5n
+}
+
+install_release()
+{
+ typeset _source _sources _url _version _verify_pgp
+ _sources=(${!1})
+ _version=$2
+ debug "Downloading RVM version ${_version}"
+ for _source in "${_sources[@]}"
+ do
+ case ${_source} in
+ (bitbucket.org*)
+ _url="https://${_source}/get/${_version}.tar.gz"
+ _verify_pgp="https://${_source}/downloads/${_version}.tar.gz.asc"
+ ;;
+ (*)
+ _url="https://${_source}/archive/${_version}.tar.gz"
+ _verify_pgp="https://${_source}/releases/download/${_version}/${_version}.tar.gz.asc"
+ ;;
+ esac
+ get_and_unpack "${_url}" "rvm-${_version}.tgz" "$_verify_pgp" && return
+ done
+ return $?
+}
+
+install_head()
+{
+ typeset _branch _source _sources _url
+ _sources=(${!1})
+ _branch=$2
+ debug "Selected RVM branch ${_branch}"
+ for _source in "${_sources[@]}"
+ do
+ case ${_source} in
+ (bitbucket.org*)
+ _url=https://${_source}/get/${_branch}.tar.gz
+ ;;
+ (*)
+ _url=https://${_source}/archive/${_branch}.tar.gz
+ ;;
+ esac
+ get_and_unpack "${_url}" "rvm-${_branch//\//_}.tgz" && return
+ done
+ return $?
+}
+
+# duplication marker dfkjdjngdfjngjcszncv
+# Drop in cd which _doesn't_ respect cdpath
+__rvm_cd()
+{
+ typeset old_cdpath ret
+ ret=0
+ old_cdpath="${CDPATH}"
+ CDPATH="."
+ chpwd_functions="" builtin cd "$@" || ret=$?
+ CDPATH="${old_cdpath}"
+ return $ret
+}
+
+get_package()
+{
+ typeset _url _file
+ _url="$1"
+ _file="$2"
+ log "Downloading ${_url}"
+ __rvm_curl -sS ${_url} > ${rvm_archives_path}/${_file} ||
+ {
+ _return=$?
+ case $_return in
+ # duplication marker lfdgzkngdkjvnfjknkjvcnbjkncvjxbn
+ (60)
+ log "
+Could not download '${_url}', you can read more about it here:
+https://rvm.io/support/fixing-broken-ssl-certificates/
+To continue in insecure mode run 'echo insecure >> ~/.curlrc'.
+"
+ ;;
+ # duplication marker lfdgzkngdkjvnfjknkjvcnbjkncvjxbn
+ (77)
+ log "
+It looks like you have old certificates, you can read more about it here:
+https://rvm.io/support/fixing-broken-ssl-certificates/
+"
+ ;;
+ # duplication marker lfdgzkngdkjvnfjknkjvcnbjkncvjxbn
+ (141)
+ log "
+Curl returned 141 - it is result of a segfault which means it's Curls fault.
+Try again and if it crashes more than a couple of times you either need to
+reinstall Curl or consult with your distribution manual and contact support.
+"
+ ;;
+ (*)
+ log "
+Could not download '${_url}'.
+ curl returned status '$_return'.
+"
+ ;;
+ esac
+ return $_return
+ }
+}
+
+# duplication marker flnglfdjkngjndkfjhsbdjgfghdsgfklgg
+rvm_install_gpg_setup()
+{
+ export rvm_gpg_command
+ {
+ rvm_gpg_command="$( \which gpg2 2>/dev/null )" &&
+ [[ ${rvm_gpg_command} != "/cygdrive/"* ]]
+ } || rvm_gpg_command=""
+
+ debug "Detected GPG program: '$rvm_gpg_command'"
+
+ [[ -n "$rvm_gpg_command" ]] || return $?
+}
+
+# duplication marker rdjgndfnghdfnhgfdhbghdbfhgbfdhbn
+verify_package_pgp()
+{
+ if
+ "${rvm_gpg_command}" --verify "$2" "$1"
+ then
+ log "GPG verified '$1'"
+ else
+ typeset _ret=$?
+ log "\
+Warning, RVM 1.26.0 introduces signed releases and automated check of signatures when GPG software found. \
+Assuming you trust Michal Papis import the mpapis public key (downloading the signatures).
+
+GPG signature verification failed for '$1' - '$3'! Try to install GPG v2 and then fetch the public key:
+
+ ${SUDO_USER:+sudo }${rvm_gpg_command##*/} --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
+
+or if it fails:
+
+ command curl -sSL https://rvm.io/mpapis.asc | ${SUDO_USER:+sudo }${rvm_gpg_command##*/} --import -
+
+the key can be compared with:
+
+ https://rvm.io/mpapis.asc
+ https://keybase.io/mpapis
+
+NOTE: GPG version 2.1.17 have a bug which cause failures during fetching keys from remote server. Please downgrade \
+or upgrade to newer version (if available) or use the second method described above.
+"
+ exit $_ret
+ fi
+}
+
+verify_pgp()
+{
+ [[ -n "${1:-}" ]] ||
+ {
+ debug "No PGP url given, skipping."
+ return 0
+ }
+
+ get_package "$1" "$2.asc" ||
+ {
+ debug "PGP url given but does not exist: '$1'"
+ return 0
+ }
+
+ rvm_install_gpg_setup ||
+ {
+ log "Found PGP signature at: '$1',
+but no GPG software exists to validate it, skipping."
+ return 0
+ }
+
+ verify_package_pgp "${rvm_archives_path}/$2" "${rvm_archives_path}/$2.asc" "$1"
+}
+
+get_and_unpack()
+{
+ typeset _url _file _patern _return _verify_pgp
+ _url="$1"
+ _file="$2"
+ _verify_pgp="$3"
+
+ get_package "$_url" "$_file" || return $?
+ verify_pgp "$_verify_pgp" "$_file" || return $?
+
+ [[ -d "${rvm_src_path}/rvm" ]] || \mkdir -p "${rvm_src_path}/rvm"
+ __rvm_cd "${rvm_src_path}/rvm" ||
+ {
+ _return=$?
+ log "Could not change directory '${rvm_src_path}/rvm'."
+ return $_return
+ }
+
+ rm -rf ${rvm_src_path}/rvm/*
+ __rvm_debug_command $rvm_tar_command xzf ${rvm_archives_path}/${_file} ${rvm_tar_options:-} --strip-components 1 ||
+ {
+ _return=$?
+ log "Could not extract RVM sources."
+ return $_return
+ }
+}
+
+rvm_install_default_settings()
+{
+ # Tracing, if asked for.
+ if
+ [[ "$*" == *--trace* ]] || (( ${rvm_trace_flag:-0} > 0 ))
+ then
+ set -o xtrace
+ rvm_trace_flag=1
+ fi
+
+ # Variable initialization, remove trailing slashes if they exist on HOME
+ true \
+ ${rvm_trace_flag:=0} ${rvm_debug_flag:=0}\
+ ${rvm_ignore_rvmrc:=0} HOME="${HOME%%+(\/)}"
+
+ if
+ (( rvm_ignore_rvmrc == 0 ))
+ then
+ for rvmrc in /etc/rvmrc "$HOME/.rvmrc"
+ do
+ if
+ [[ -s "$rvmrc" ]]
+ then
+ if
+ GREP_OPTIONS="" \grep '^\s*rvm .*$' "$rvmrc" >/dev/null 2>&1
+ then
+ printf "%b" "
+ Error: $rvmrc is for rvm settings only.
+ rvm CLI may NOT be called from within $rvmrc.
+ Skipping the loading of $rvmrc
+ "
+ exit 1
+ else
+ source "$rvmrc"
+ fi
+ fi
+ done
+ fi
+
+ if
+ [[ -z "${rvm_path:-}" ]]
+ then
+ if
+ (( UID == 0 ))
+ then
+ rvm_user_install_flag=0
+ rvm_prefix="/usr/local"
+ rvm_path="${rvm_prefix}/rvm"
+ else
+ rvm_user_install_flag=1
+ rvm_prefix="$HOME"
+ rvm_path="${rvm_prefix}/.rvm"
+ fi
+ fi
+ if [[ -z "${rvm_prefix}" ]]
+ then rvm_prefix=$( dirname $rvm_path )
+ fi
+
+ # duplication marker kkdfkgnjfndgjkndfjkgnkfjdgn
+ [[ -n "${rvm_user_install_flag:-}" ]] ||
+ case "$rvm_path" in
+ (/usr/local/rvm) rvm_user_install_flag=0 ;;
+ ($HOME/*|/${USER// /_}*) rvm_user_install_flag=1 ;;
+ (*) rvm_user_install_flag=0 ;;
+ esac
+}
+
+rvm_install_parse_params()
+{
+ install_rubies=()
+ install_gems=()
+ flags=( ./scripts/install )
+ forwarded_flags=()
+ while
+ (( $# > 0 ))
+ do
+ token="$1"
+ shift
+ case "$token" in
+
+ (--trace)
+ set -o xtrace
+ rvm_trace_flag=1
+ flags=( -x "${flags[@]}" "$token" )
+ forwarded_flags+=( "$token" )
+ ;;
+
+ (--debug|--quiet-curl)
+ flags+=( "$token" )
+ forwarded_flags+=( "$token" )
+ token=${token#--}
+ token=${token//-/_}
+ export "rvm_${token}_flag"=1
+ printf "%b" "Turning on ${token/_/ } mode.\n"
+ ;;
+
+ (--path)
+ if [[ -n "${1:-}" ]]
+ then
+ rvm_path="$1"
+ shift
+ else
+ fail "--path must be followed by a path."
+ fi
+ ;;
+
+ (--branch|branch) # Install RVM from a given branch
+ if [[ -n "${1:-}" ]]
+ then
+ case "$1" in
+ (/*)
+ branch=${1#/}
+ ;;
+ (*/)
+ branch=master
+ if [[ "${1%/}" -ne wayneeseguin ]] && [[ "${1%/}" -ne mpapis ]]
+ then sources=(github.com/${1%/}/rvm)
+ fi
+ ;;
+ (*/*)
+ branch=${1#*/}
+ if [[ "${1%%/*}" -ne wayneeseguin ]] && [[ "${1%%/*}" -ne mpapis ]]
+ then sources=(github.com/${1%%/*}/rvm)
+ fi
+ ;;
+ (*)
+ branch="$1"
+ ;;
+ esac
+ shift
+ else
+ fail "--branch must be followed by a branchname."
+ fi
+ ;;
+
+ (--source|source)
+ if [[ -n "${1:-}" ]]
+ then
+ if [[ "$1" = */*/* ]]
+ then
+ sources=($1)
+ shift
+ else
+ fail "--source must be in the format //."
+ fi
+ else
+ fail "--source must be followed by a source."
+ fi
+ ;;
+
+ (--user-install|--ignore-dotfiles)
+ token=${token#--}
+ token=${token//-/_}
+ export "rvm_${token}_flag"=1
+ printf "%b" "Turning on ${token/_/ } mode.\n"
+ ;;
+
+ (--auto-dotfiles)
+ flags+=( "$token" )
+ export "rvm_auto_dotfiles_flag"=1
+ printf "%b" "Turning on auto dotfiles mode.\n"
+ ;;
+
+ (--auto)
+ export "rvm_auto_dotfiles_flag"=1
+ printf "%b" "Warning, --auto is deprecated in favor of --auto-dotfiles.\n"
+ ;;
+
+ (--verify-downloads)
+ if [[ -n "${1:-}" ]]
+ then
+ export rvm_verify_downloads_flag="$1"
+ forwarded_flags+=( "$token" "$1" )
+ shift
+ else
+ fail "--verify-downloads must be followed by level(0|1|2)."
+ fi
+ ;;
+
+ (--autolibs=*)
+ flags+=( "$token" )
+ export rvm_autolibs_flag="${token#--autolibs=}"
+ forwarded_flags+=( "$token" )
+ ;;
+
+ (--without-gems=*|--with-gems=*|--with-default-gems=*)
+ flags+=( "$token" )
+ value="${token#*=}"
+ token="${token%%=*}"
+ token="${token#--}"
+ token="${token//-/_}"
+ export "rvm_${token}"="${value}"
+ printf "%b" "Installing RVM ${token/_/ }: ${value}.\n"
+ ;;
+
+ (--version|version)
+ version="$1"
+ shift
+ ;;
+
+ (head|master)
+ version="head"
+ branch="master"
+ ;;
+
+ (stable)
+ version="latest"
+ ;;
+
+ (latest|latest-*|+([[:digit:]]).+([[:digit:]]).+([[:digit:]]))
+ version="$token"
+ ;;
+
+ (--ruby)
+ install_rubies+=( ruby )
+ ;;
+
+ (--ruby=*)
+ token=${token#--ruby=}
+ install_rubies+=( ${token//,/ } )
+ ;;
+
+ (--rails)
+ install_gems+=( rails )
+ ;;
+
+ (--gems=*)
+ token=${token#--gems=}
+ install_gems+=( ${token//,/ } )
+ ;;
+
+ (--add-to-rvm-group)
+ export rvm_add_users_to_rvm_group="$1"
+ shift
+ ;;
+
+ (help|usage)
+ usage
+ exit 0
+ ;;
+
+ (*)
+ usage
+ exit 1
+ ;;
+
+ esac
+ done
+
+ if (( ${#install_gems[@]} > 0 && ${#install_rubies[@]} == 0 ))
+ then install_rubies=( ruby )
+ fi
+
+ true "${version:=head}"
+ true "${branch:=master}"
+
+ if [[ -z "${sources[@]}" ]]
+ then sources=("${DEFAULT_SOURCES[@]}")
+ fi
+
+ rvm_src_path="$rvm_path/src"
+ rvm_archives_path="$rvm_path/archives"
+ rvm_releases_url="https://rvm.io/releases"
+}
+
+rvm_install_validate_rvm_path()
+{
+ case "$rvm_path" in
+ (*[[:space:]]*)
+ printf "%b" "
+It looks you are one of the happy *space* users (in home dir name),
+RVM is not yet fully ready for it, use this trick to fix it:
+
+ sudo mkdir -p /${USER// /_}.rvm
+ sudo chown -R \"$USER:\" /${USER// /_}.rvm
+ echo \"export rvm_path=/${USER// /_}.rvm\" >> \"$HOME/.rvmrc\"
+
+and start installing again.
+
+"
+ exit 2
+ ;;
+ (/usr/share/ruby-rvm)
+ printf "%b" "
+It looks you are one of the happy Ubuntu users,
+RVM packaged by Ubuntu is old and broken,
+follow this link for details how to fix:
+
+ https://stackoverflow.com/a/9056395/497756
+
+"
+ [[ "${rvm_uses_broken_ubuntu_path:-no}" == "yes" ]] || exit 3
+ ;;
+ esac
+
+ if [[ "$rvm_path" != "/"* ]]
+ then fail "The rvm install path must be fully qualified. Tried $rvm_path"
+ fi
+}
+
+rvm_install_validate_volume_mount_mode()
+{
+ \typeset path partition test_exec
+
+ path=$rvm_path
+
+ # Directory $rvm_path might not exists at this point so we need to traverse the tree upwards
+ while [[ -n "$path" ]]
+ do
+ if [[ -d $path ]]
+ then
+ partition=`df -P $path | awk 'END{print $1}'`
+
+ test_exec=$(mktemp $path/rvm-exec-test.XXXXXX)
+ echo '#!/bin/sh' > "$test_exec"
+ chmod +x "$test_exec"
+
+ if ! "$test_exec"
+ then
+ rm -f "$test_exec"
+ printf "%b" "
+It looks that scripts located in ${path}, which would be RVM destination ${rvm_path},
+are not executable. One of the reasons might be that partition ${partition} holding this location
+is mounted in *noexec* mode, which prevents RVM from working correctly. Please verify your setup
+and re-mount partition ${partition} without the noexec option."
+ exit 2
+ fi
+
+ rm -f "$test_exec"
+ break
+ fi
+
+ path=${path%/*}
+ done
+}
+
+rvm_install_select_and_get_version()
+{
+ typeset _version_release
+
+ for dir in "$rvm_src_path" "$rvm_archives_path"
+ do
+ [[ -d "$dir" ]] || mkdir -p "$dir"
+ done
+
+ _version_release="${version}"
+ case "${version}" in
+ (head)
+ _version_release="${branch}"
+ install_head sources[@] ${branch:-master} || exit $?
+ ;;
+
+ (latest)
+ install_release sources[@] $(fetch_version sources[@]) || exit $?
+ ;;
+
+ (latest-minor)
+ version="$(\cat "$rvm_path/VERSION")"
+ install_release sources[@] $(fetch_version sources[@] ${version%.*}) || exit $?
+ ;;
+
+ (latest-*)
+ install_release sources[@] $(fetch_version sources[@] ${version#latest-}) || exit $?
+ ;;
+
+ (+([[:digit:]]).+([[:digit:]]).+([[:digit:]])) # x.y.z
+ install_release sources[@] ${version} || exit $?
+ ;;
+
+ (*)
+ fail "Something went wrong, unrecognized version '$version'"
+ ;;
+ esac
+ echo "${_version_release}" > "$rvm_path/RELEASE"
+}
+
+rvm_install_main()
+{
+ [[ -f ./scripts/install ]] ||
+ {
+ log "'./scripts/install' can not be found for installation, something went wrong, it usally means your 'tar' is broken, please report it here: https://github.com/rvm/rvm/issues"
+ return 127
+ }
+
+ # required flag - path to install
+ flags+=( --path "$rvm_path" )
+ \command bash "${flags[@]}"
+}
+
+rvm_install_ruby_and_gems()
+(
+ if
+ (( ${#install_rubies[@]} > 0 ))
+ then
+ source ${rvm_scripts_path:-${rvm_path}/scripts}/rvm
+ source ${rvm_scripts_path:-${rvm_path}/scripts}/version
+ __rvm_version
+
+ for _ruby in ${install_rubies[@]}
+ do command rvm "${forwarded_flags[@]}" install ${_ruby} -j 2
+ done
+ # set the first one as default, skip rest
+ for _ruby in ${install_rubies[@]}
+ do
+ rvm "${forwarded_flags[@]}" alias create default ${_ruby}
+ break
+ done
+
+ for _gem in ${install_gems[@]}
+ do rvm "${forwarded_flags[@]}" all do gem install ${_gem}
+ done
+
+ printf "%b" "
+ * To start using RVM you need to run \`source $rvm_path/scripts/rvm\`
+ in all your open shell windows, in rare cases you need to reopen all shell windows.
+"
+
+ if
+ [[ "${install_gems[*]}" == *"rails"* ]]
+ then
+ printf "%b" "
+ * To start using rails you need to run \`rails new \`.
+"
+ fi
+ fi
+)
+
+rvm_install()
+{
+ rvm_install_initialize
+ rvm_install_commands_setup
+ rvm_install_default_settings
+ rvm_install_parse_params "$@"
+ rvm_install_validate_rvm_path
+ rvm_install_validate_volume_mount_mode
+ rvm_install_select_and_get_version
+ rvm_install_main
+ rvm_install_ruby_and_gems
+}
+
+rvm_install "$@"
diff --git a/_site/site/public/apple-touch-icon-precomposed.png b/_site/site/public/apple-touch-icon-precomposed.png
new file mode 100755
index 00000000..6cb41a8e
Binary files /dev/null and b/_site/site/public/apple-touch-icon-precomposed.png differ
diff --git a/_site/site/public/css/lanyon.css b/_site/site/public/css/lanyon.css
new file mode 100755
index 00000000..1d57108e
--- /dev/null
+++ b/_site/site/public/css/lanyon.css
@@ -0,0 +1,563 @@
+/*
+ * ___
+ * /\_ \
+ * \//\ \ __ ___ __ __ ___ ___
+ * \ \ \ /'__`\ /' _ `\/\ \/\ \ / __`\ /' _ `\
+ * \_\ \_/\ \_\.\_/\ \/\ \ \ \_\ \/\ \_\ \/\ \/\ \
+ * /\____\ \__/.\_\ \_\ \_\/`____ \ \____/\ \_\ \_\
+ * \/____/\/__/\/_/\/_/\/_/`/___/> \/___/ \/_/\/_/
+ * /\___/
+ * \/__/
+ *
+ * Designed, built, and released under MIT license by @mdo. Learn more at
+ * https://github.com/poole/lanyon.
+ */
+
+
+/*
+ * Contents
+ *
+ * Global resets
+ * Masthead
+ * Sidebar
+ * Slide effect
+ * Posts and pages
+ * Pagination
+ * Reverse layout
+ * Themes
+ */
+
+
+/*
+ * Global resets
+ *
+ * Update the foundational and global aspects of the page.
+ */
+
+/* Prevent scroll on narrow devices */
+html,
+body {
+ overflow-x: hidden;
+}
+
+html {
+ font-family: "PT Serif", Georgia, "Times New Roman", serif;
+}
+
+h1, h2, h3, h4, h5, h6 {
+ font-family: "PT Sans", Helvetica, Arial, sans-serif;
+ font-weight: 400;
+ color: #313131;
+ letter-spacing: -.025rem;
+}
+
+
+/*
+ * Wrapper
+ *
+ * The wrapper is used to position site content when the sidebar is toggled. We
+ * use an outter wrap to position the sidebar without interferring with the
+ * regular page content.
+ */
+
+.wrap {
+ position: relative;
+ width: 100%;
+}
+
+
+/*
+ * Container
+ *
+ * Center the page content.
+ */
+
+.container {
+ max-width: 28rem;
+}
+@media (min-width: 38em) {
+ .container {
+ max-width: 32rem;
+ }
+}
+@media (min-width: 56em) {
+ .container {
+ max-width: 38rem;
+ }
+}
+
+
+/*
+ * Masthead
+ *
+ * Super small header above the content for site name and short description.
+ */
+
+.masthead {
+ padding-top: 1rem;
+ padding-bottom: 1rem;
+ margin-bottom: 3rem;
+ border-bottom: 1px solid #eee;
+}
+.masthead-title {
+ margin-top: 0;
+ margin-bottom: 0;
+ color: #505050;
+}
+.masthead-title a {
+ color: #505050;
+}
+.masthead-title small {
+ font-size: 75%;
+ font-weight: 400;
+ color: #c0c0c0;
+ letter-spacing: 0;
+}
+
+@media (max-width: 48em) {
+ .masthead-title {
+ text-align: center;
+ }
+ .masthead-title small {
+ display: none;
+ }
+}
+
+
+/*
+ * Sidebar
+ *
+ * The sidebar is the drawer, the item we are toggling with our handy hamburger
+ * button in the corner of the page.
+ *
+ * This particular sidebar implementation was inspired by Chris Coyier's
+ * "Offcanvas Menu with CSS Target" article, and the checkbox variation from the
+ * comments by a reader. It modifies both implementations to continue using the
+ * checkbox (no change in URL means no polluted browser history), but this uses
+ * `position` for the menu to avoid some potential content reflow issues.
+ *
+ * Source: http://css-tricks.com/off-canvas-menu-with-css-target/#comment-207504
+ */
+
+/* Style and "hide" the sidebar */
+.sidebar {
+ position: fixed;
+ top: 0;
+ bottom: 0;
+ left: -14rem;
+ width: 14rem;
+ visibility: hidden;
+ overflow-y: auto;
+ font-family: "PT Sans", Helvetica, Arial, sans-serif;
+ font-size: .875rem; /* 15px */
+ color: rgba(255,255,255,.6);
+ background-color: #202020;
+ -webkit-transition: all .3s ease-in-out;
+ transition: all .3s ease-in-out;
+}
+@media (min-width: 30em) {
+ .sidebar {
+ font-size: .75rem; /* 14px */
+ }
+}
+
+/* Sidebar content */
+.sidebar a {
+ font-weight: normal;
+ color: #fff;
+}
+.sidebar-item {
+ padding: 1rem;
+}
+.sidebar-item p:last-child {
+ margin-bottom: 0;
+}
+
+/* Sidebar nav */
+.sidebar-nav {
+ border-bottom: 1px solid rgba(255,255,255,.1);
+}
+.sidebar-nav-item {
+ display: block;
+ padding: .5rem 1rem;
+ border-top: 1px solid rgba(255,255,255,.1);
+}
+.sidebar-nav-item.active,
+a.sidebar-nav-item:hover,
+a.sidebar-nav-item:focus {
+ text-decoration: none;
+ background-color: rgba(255,255,255,.1);
+ border-color: transparent;
+}
+
+@media (min-width: 48em) {
+ .sidebar-item {
+ padding: 1.5rem;
+ }
+ .sidebar-nav-item {
+ padding-left: 1.5rem;
+ padding-right: 1.5rem;
+ }
+}
+
+/* Hide the sidebar checkbox that we toggle with `.sidebar-toggle` */
+.sidebar-checkbox {
+ position: absolute;
+ opacity: 0;
+ -webkit-user-select: none;
+ -moz-user-select: none;
+ user-select: none;
+}
+
+/* Style the `label` that we use to target the `.sidebar-checkbox` */
+.sidebar-toggle {
+ position: absolute;
+ top: .8rem;
+ left: 1rem;
+ display: block;
+ padding: .25rem .75rem;
+ color: #505050;
+ background-color: #fff;
+ border-radius: .25rem;
+ cursor: pointer;
+}
+
+.sidebar-toggle:before {
+ display: inline-block;
+ width: 1rem;
+ height: .75rem;
+ content: "";
+ background-image: -webkit-linear-gradient(to bottom, #555, #555 20%, #fff 20%, #fff 40%, #555 40%, #555 60%, #fff 60%, #fff 80%, #555 80%, #555 100%);
+ background-image: -moz-linear-gradient(to bottom, #555, #555 20%, #fff 20%, #fff 40%, #555 40%, #555 60%, #fff 60%, #fff 80%, #555 80%, #555 100%);
+ background-image: -ms-linear-gradient(to bottom, #555, #555 20%, #fff 20%, #fff 40%, #555 40%, #555 60%, #fff 60%, #fff 80%, #555 80%, #555 100%);
+ background-image: linear-gradient(to bottom, #555, #555 20%, #fff 20%, #fff 40%, #555 40%, #555 60%, #fff 60%, #fff 80%, #555 80%, #555 100%);
+}
+
+.sidebar-toggle:active,
+#sidebar-checkbox:focus ~ .sidebar-toggle,
+#sidebar-checkbox:checked ~ .sidebar-toggle {
+ color: #fff;
+ background-color: #555;
+}
+
+.sidebar-toggle:active:before,
+#sidebar-checkbox:focus ~ .sidebar-toggle:before,
+#sidebar-checkbox:checked ~ .sidebar-toggle:before {
+ background-image: -webkit-linear-gradient(to bottom, #fff, #fff 20%, #555 20%, #555 40%, #fff 40%, #fff 60%, #555 60%, #555 80%, #fff 80%, #fff 100%);
+ background-image: -moz-linear-gradient(to bottom, #fff, #fff 20%, #555 20%, #555 40%, #fff 40%, #fff 60%, #555 60%, #555 80%, #fff 80%, #fff 100%);
+ background-image: -ms-linear-gradient(to bottom, #fff, #fff 20%, #555 20%, #555 40%, #fff 40%, #fff 60%, #555 60%, #555 80%, #fff 80%, #fff 100%);
+ background-image: linear-gradient(to bottom, #fff, #fff 20%, #555 20%, #555 40%, #fff 40%, #fff 60%, #555 60%, #555 80%, #fff 80%, #fff 100%);
+}
+
+@media (min-width: 30.1em) {
+ .sidebar-toggle {
+ position: fixed;
+ }
+}
+
+@media print {
+ .sidebar-toggle {
+ display: none;
+ }
+}
+
+/* Slide effect
+ *
+ * Handle the sliding effects of the sidebar and content in one spot, seperate
+ * from the default styles.
+ *
+ * As an a heads up, we don't use `transform: translate3d()` here because when
+ * mixed with `position: fixed;` for the sidebar toggle, it creates a new
+ * containing block. Put simply, the fixed sidebar toggle behaves like
+ * `position: absolute;` when transformed.
+ *
+ * Read more about it at http://meyerweb.com/eric/thoughts/2011/09/12/.
+ */
+
+.wrap,
+.sidebar,
+.sidebar-toggle {
+ -webkit-backface-visibility: hidden;
+ -ms-backface-visibility: hidden;
+ backface-visibility: hidden;
+}
+.wrap,
+.sidebar-toggle {
+ -webkit-transition: -webkit-transform .3s ease-in-out;
+ transition: transform .3s ease-in-out;
+}
+
+#sidebar-checkbox:checked + .sidebar {
+ z-index: 10;
+ visibility: visible;
+}
+#sidebar-checkbox:checked ~ .sidebar,
+#sidebar-checkbox:checked ~ .wrap,
+#sidebar-checkbox:checked ~ .sidebar-toggle {
+ -webkit-transform: translateX(14rem);
+ -ms-transform: translateX(14rem);
+ transform: translateX(14rem);
+}
+
+
+/*
+ * Posts and pages
+ *
+ * Each post is wrapped in `.post` and is used on default and post layouts. Each
+ * page is wrapped in `.page` and is only used on the page layout.
+ */
+
+.page,
+.post {
+ margin-bottom: 4em;
+}
+
+/* Blog post or page title */
+.page-title,
+.post-title,
+.post-title a {
+ color: #303030;
+}
+.page-title,
+.post-title {
+ margin-top: 0;
+}
+
+/* Meta data line below post title */
+.post-date {
+ display: block;
+ margin-top: -.5rem;
+ margin-bottom: 1rem;
+ color: #9a9a9a;
+}
+
+/* Related posts */
+.related {
+ padding-top: 2rem;
+ padding-bottom: 2rem;
+ border-top: 1px solid #eee;
+}
+.related-posts {
+ padding-left: 0;
+ list-style: none;
+}
+.related-posts h3 {
+ margin-top: 0;
+}
+.related-posts li small {
+ font-size: 75%;
+ color: #999;
+}
+.related-posts li a:hover {
+ color: #268bd2;
+ text-decoration: none;
+}
+.related-posts li a:hover small {
+ color: inherit;
+}
+
+
+/*
+ * Pagination
+ *
+ * Super lightweight (HTML-wise) blog pagination. `span`s are provide for when
+ * there are no more previous or next posts to show.
+ */
+
+.pagination {
+ overflow: hidden; /* clearfix */
+ margin-left: -1rem;
+ margin-right: -1rem;
+ font-family: "PT Sans", Helvetica, Arial, sans-serif;
+ color: #ccc;
+ text-align: center;
+}
+
+/* Pagination items can be `span`s or `a`s */
+.pagination-item {
+ display: block;
+ padding: 1rem;
+ border: 1px solid #eee;
+}
+.pagination-item:first-child {
+ margin-bottom: -1px;
+}
+
+/* Only provide a hover state for linked pagination items */
+a.pagination-item:hover {
+ background-color: #f5f5f5;
+}
+
+@media (min-width: 30em) {
+ .pagination {
+ margin: 3rem 0;
+ }
+ .pagination-item {
+ float: left;
+ width: 50%;
+ }
+ .pagination-item:first-child {
+ margin-bottom: 0;
+ border-top-left-radius: 4px;
+ border-bottom-left-radius: 4px;
+ }
+ .pagination-item:last-child {
+ margin-left: -1px;
+ border-top-right-radius: 4px;
+ border-bottom-right-radius: 4px;
+ }
+}
+
+
+/*
+ * Reverse layout
+ *
+ * Flip the orientation of the page by placing the `.sidebar` and sidebar toggle
+ * on the right side.
+ */
+
+.layout-reverse .sidebar {
+ left: auto;
+ right: -14rem;
+}
+.layout-reverse .sidebar-toggle {
+ left: auto;
+ right: 1rem;
+}
+
+.layout-reverse #sidebar-checkbox:checked ~ .sidebar,
+.layout-reverse #sidebar-checkbox:checked ~ .wrap,
+.layout-reverse #sidebar-checkbox:checked ~ .sidebar-toggle {
+ -webkit-transform: translateX(-14rem);
+ -ms-transform: translateX(-14rem);
+ transform: translateX(-14rem);
+}
+
+
+/*
+ * Themes
+ *
+ * Apply custom color schemes by adding the appropriate class to the `body`.
+ * Based on colors from Base16: http://chriskempson.github.io/base16/#default.
+ */
+
+/* Red */
+.theme-base-08 .sidebar,
+.theme-base-08 .sidebar-toggle:active,
+.theme-base-08 #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #ac4142;
+}
+.theme-base-08 .container a,
+.theme-base-08 .sidebar-toggle,
+.theme-base-08 .related-posts li a:hover {
+ color: #ac4142;
+}
+
+/* Orange */
+.theme-base-09 .sidebar,
+.theme-base-09 .sidebar-toggle:active,
+.theme-base-09 #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #d28445;
+}
+.theme-base-09 .container a,
+.theme-base-09 .sidebar-toggle,
+.theme-base-09 .related-posts li a:hover {
+ color: #d28445;
+}
+
+/* Yellow */
+.theme-base-0a .sidebar,
+.theme-base-0a .sidebar-toggle:active,
+.theme-base-0a #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #f4bf75;
+}
+.theme-base-0a .container a,
+.theme-base-0a .sidebar-toggle,
+.theme-base-0a .related-posts li a:hover {
+ color: #f4bf75;
+}
+
+/* Green */
+.theme-base-0b .sidebar,
+.theme-base-0b .sidebar-toggle:active,
+.theme-base-0b #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #90a959;
+}
+.theme-base-0b .container a,
+.theme-base-0b .sidebar-toggle,
+.theme-base-0b .related-posts li a:hover {
+ color: #90a959;
+}
+
+/* Cyan */
+.theme-base-0c .sidebar,
+.theme-base-0c .sidebar-toggle:active,
+.theme-base-0c #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #75b5aa;
+}
+.theme-base-0c .container a,
+.theme-base-0c .sidebar-toggle,
+.theme-base-0c .related-posts li a:hover {
+ color: #75b5aa;
+}
+
+/* Blue */
+.theme-base-0d .sidebar,
+.theme-base-0d .sidebar-toggle:active,
+.theme-base-0d #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #6a9fb5;
+}
+.theme-base-0d .container a,
+.theme-base-0d .sidebar-toggle,
+.theme-base-0d .related-posts li a:hover {
+ color: #6a9fb5;
+}
+
+/* Magenta */
+.theme-base-0e .sidebar,
+.theme-base-0e .sidebar-toggle:active,
+.theme-base-0e #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #aa759f;
+}
+.theme-base-0e .container a,
+.theme-base-0e .sidebar-toggle,
+.theme-base-0e .related-posts li a:hover {
+ color: #aa759f;
+}
+
+/* Brown */
+.theme-base-0f .sidebar,
+.theme-base-0f .sidebar-toggle:active,
+.theme-base-0f #sidebar-checkbox:checked ~ .sidebar-toggle {
+ background-color: #8f5536;
+}
+.theme-base-0f .container a,
+.theme-base-0f .sidebar-toggle,
+.theme-base-0f .related-posts li a:hover {
+ color: #8f5536;
+}
+
+
+/*
+ * Overlay sidebar
+ *
+ * Make the sidebar content overlay the viewport content instead of pushing it
+ * aside when toggled.
+ */
+
+.sidebar-overlay #sidebar-checkbox:checked ~ .wrap {
+ -webkit-transform: translateX(0);
+ -ms-transform: translateX(0);
+ transform: translateX(0);
+}
+.sidebar-overlay #sidebar-checkbox:checked ~ .sidebar-toggle {
+ box-shadow: 0 0 0 .25rem #fff;
+}
+.sidebar-overlay #sidebar-checkbox:checked ~ .sidebar {
+ box-shadow: .25rem 0 .5rem rgba(0,0,0,.1);
+}
+
+/* Only one tweak for a reverse layout */
+.layout-reverse.sidebar-overlay #sidebar-checkbox:checked ~ .sidebar {
+ box-shadow: -.25rem 0 .5rem rgba(0,0,0,.1);
+}
diff --git a/_site/site/public/css/poole.css b/_site/site/public/css/poole.css
new file mode 100755
index 00000000..8ec27e7a
--- /dev/null
+++ b/_site/site/public/css/poole.css
@@ -0,0 +1,430 @@
+/*
+ * ___
+ * /\_ \
+ * _____ ___ ___\//\ \ __
+ * /\ '__`\ / __`\ / __`\\ \ \ /'__`\
+ * \ \ \_\ \/\ \_\ \/\ \_\ \\_\ \_/\ __/
+ * \ \ ,__/\ \____/\ \____//\____\ \____\
+ * \ \ \/ \/___/ \/___/ \/____/\/____/
+ * \ \_\
+ * \/_/
+ *
+ * Designed, built, and released under MIT license by @mdo. Learn more at
+ * https://github.com/poole/poole.
+ */
+
+
+/*
+ * Contents
+ *
+ * Body resets
+ * Custom type
+ * Messages
+ * Container
+ * Masthead
+ * Posts and pages
+ * Pagination
+ * Reverse layout
+ * Themes
+ */
+
+
+/*
+ * Body resets
+ *
+ * Update the foundational and global aspects of the page.
+ */
+
+* {
+ -webkit-box-sizing: border-box;
+ -moz-box-sizing: border-box;
+ box-sizing: border-box;
+}
+
+html,
+body {
+ margin: 0;
+ padding: 0;
+}
+
+html {
+ font-family: "Helvetica Neue", Helvetica, Arial, sans-serif;
+ font-size: 16px;
+ line-height: 1.5;
+}
+@media (min-width: 38em) {
+ html {
+ font-size: 20px;
+ }
+}
+
+body {
+ color: #515151;
+ background-color: #fff;
+ -webkit-text-size-adjust: 100%;
+ -ms-text-size-adjust: 100%;
+}
+
+/* No `:visited` state is required by default (browsers will use `a`) */
+a {
+ color: #268bd2;
+ text-decoration: none;
+}
+a strong {
+ color: inherit;
+}
+/* `:focus` is linked to `:hover` for basic accessibility */
+a:hover,
+a:focus {
+ text-decoration: underline;
+}
+
+/* Headings */
+h1, h2, h3, h4, h5, h6 {
+ margin-bottom: .5rem;
+ font-weight: bold;
+ line-height: 1.25;
+ color: #313131;
+ text-rendering: optimizeLegibility;
+}
+h1 {
+ font-size: 2rem;
+}
+h2 {
+ margin-top: 1rem;
+ font-size: 1.5rem;
+}
+h3 {
+ margin-top: 1.5rem;
+ font-size: 1.25rem;
+}
+h4, h5, h6 {
+ margin-top: 1rem;
+ font-size: 1rem;
+}
+
+/* Body text */
+p {
+ margin-top: 0;
+ margin-bottom: 1rem;
+}
+
+strong {
+ color: #303030;
+}
+
+
+/* Lists */
+ul, ol, dl {
+ margin-top: 0;
+ margin-bottom: 1rem;
+}
+
+dt {
+ font-weight: bold;
+}
+dd {
+ margin-bottom: .5rem;
+}
+
+/* Misc */
+hr {
+ position: relative;
+ margin: 1.5rem 0;
+ border: 0;
+ border-top: 1px solid #eee;
+ border-bottom: 1px solid #fff;
+}
+
+abbr {
+ font-size: 85%;
+ font-weight: bold;
+ color: #555;
+ text-transform: uppercase;
+}
+abbr[title] {
+ cursor: help;
+ border-bottom: 1px dotted #e5e5e5;
+}
+
+/* Code */
+code,
+pre {
+ font-family: Menlo, Monaco, "Courier New", monospace;
+}
+code {
+ padding: .25em .5em;
+ font-size: 85%;
+ color: #bf616a;
+ background-color: #f9f9f9;
+ border-radius: 3px;
+}
+pre {
+ display: block;
+ margin-top: 0;
+ margin-bottom: 1rem;
+ padding: 1rem;
+ font-size: .8rem;
+ line-height: 1.4;
+ white-space: pre;
+ white-space: pre-wrap;
+ word-break: break-all;
+ word-wrap: break-word;
+ background-color: #f9f9f9;
+}
+pre code {
+ padding: 0;
+ font-size: 100%;
+ color: inherit;
+ background-color: transparent;
+}
+
+/* Pygments via Jekyll */
+.highlight {
+ margin-bottom: 1rem;
+ border-radius: 4px;
+}
+.highlight pre {
+ margin-bottom: 0;
+}
+
+/* Gist via GitHub Pages */
+.gist .gist-file {
+ font-family: Menlo, Monaco, "Courier New", monospace !important;
+}
+.gist .markdown-body {
+ padding: 15px;
+}
+.gist pre {
+ padding: 0;
+ background-color: transparent;
+}
+.gist .gist-file .gist-data {
+ font-size: .8rem !important;
+ line-height: 1.4;
+}
+.gist code {
+ padding: 0;
+ color: inherit;
+ background-color: transparent;
+ border-radius: 0;
+}
+
+/* Quotes */
+blockquote {
+ padding: .5rem 1rem;
+ margin: .8rem 0;
+ color: #7a7a7a;
+ border-left: .25rem solid #e5e5e5;
+}
+blockquote p:last-child {
+ margin-bottom: 0;
+}
+@media (min-width: 30em) {
+ blockquote {
+ padding-right: 5rem;
+ padding-left: 1.25rem;
+ }
+}
+
+img {
+ display: block;
+ max-width: 100%;
+ margin: 0 0 1rem;
+ border-radius: 5px;
+}
+
+/* Tables */
+table {
+ margin-bottom: 1rem;
+ width: 100%;
+ border: 1px solid #e5e5e5;
+ border-collapse: collapse;
+}
+td,
+th {
+ padding: .25rem .5rem;
+ border: 1px solid #e5e5e5;
+}
+tbody tr:nth-child(odd) td,
+tbody tr:nth-child(odd) th {
+ background-color: #f9f9f9;
+}
+
+
+/*
+ * Custom type
+ *
+ * Extend paragraphs with `.lead` for larger introductory text.
+ */
+
+.lead {
+ font-size: 1.25rem;
+ font-weight: 300;
+}
+
+
+/*
+ * Messages
+ *
+ * Show alert messages to users. You may add it to single elements like a `
diff --git a/site/_posts/2023-02-10-Toolformer - Language Models Can Teach Themselves to Use Tools.md b/site/_posts/2023-02-10-Toolformer - Language Models Can Teach Themselves to Use Tools.md
index bcd511dd..570a84e9 100755
--- a/site/_posts/2023-02-10-Toolformer - Language Models Can Teach Themselves to Use Tools.md
+++ b/site/_posts/2023-02-10-Toolformer - Language Models Can Teach Themselves to Use Tools.md
@@ -25,7 +25,7 @@ tags:
- Starting with a language model, M, the goal is to enable the language model to use tools by invoking API calls.
-- An API call is denoted by the tuple $c = (api-name, api-input)$. It can be linearized as $e(c) = [api-name(api-input)]$ or as $e(c, r) = [api-name(api-input) -> r]$ where $r$ denotes the result of the API.
+- An API call is denoted by the tuple $c =$ (api_name, api_input). It can be linearized as $e(c) =$ [api_name(api_input)$]$ or as $e(c, r) = [$api_name(api_input) $ -> r]$ where $r$ denotes the result of the API.
- The given dataset of plain text, $C$, is converted into a dataset $C*$ augmented with the API calls using a three-step process.
diff --git a/site/_site b/site/_site
index 595a66b8..f852505c 160000
--- a/site/_site
+++ b/site/_site
@@ -1 +1 @@
-Subproject commit 595a66b8361d6a240aafa6bb4450f0133b6a7a96
+Subproject commit f852505cc19589ddf6596d882825bea7293282e9