GanLM is a sequence-to-sequence pre-training model for both language generation and understanding tasks.
- Paper:
- Abstract:
Pre-trained models have achieved remarkable success in natural language processing (NLP).
However, existing pre-training methods underutilize the benefits of language understanding
for generation. Inspired by the idea of Generative Adversarial Networks (GANs), we propose
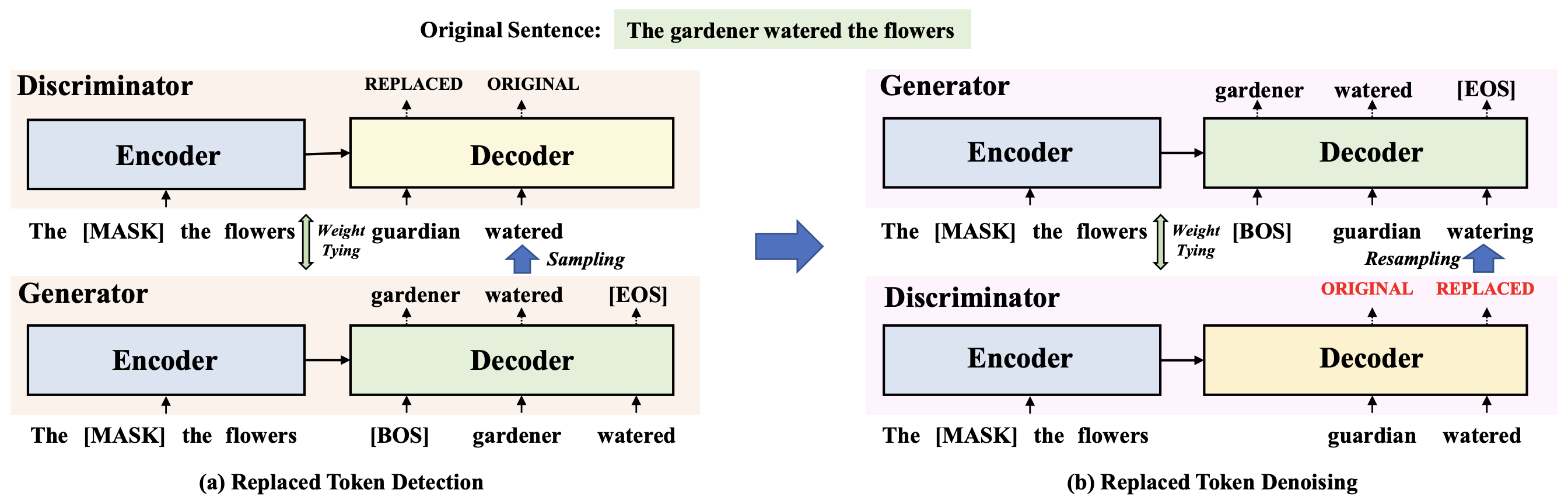
a GAN-style model for encoder-decoder pre-training by introducing an auxiliary discriminator,
unifying the ability of language understanding and generation in a single model. Our model,
named as GanLM, is trained with two pre-training objectives: replaced token detection and
replaced token denoising. Specifically, given masked source sentences, the generator outputs
the target distribution and the discriminator predicts whether the target sampled tokens from
distribution are incorrect. The target sentence is replaced with misclassified tokens to
construct noisy previous context, which is used to generate the gold sentence. In general,
both tasks improve the ability of language understanding and generation by selectively using
the denoising data. Extensive experiments in language generation benchmarks show that GanLM
with the powerful language understanding capability outperforms various strong pre-trained
language models (PLMs) and achieves state-of-the-art performance.
Following the previous work RoBERTa, Our English pre-trained model GanLM is trained on 160GB English monolingual data from BookCorpus, CC-News, OpenWebText, and CCStories.
In addition, we pre-train GanLM-m with 6TB multilingual data as the pioneering work DeltaLM, which is a combination of CC100, CCNet, and Wikipedia, covering 100 languages.
All texts are tokenized by SentencePiece (SentencePiece GitHub Repo) and encoded by the dictionary from XLM-R.
Download the SentencePiece model and tokenization dictionary from Google Drive
sentence_piece/spm_en.model: SentencePiece-model-Englishsentence_piece/spm_multilingual.model: SentencePiece-model-Multilingualdictionary/dict_en.txt: Tokenization-Dictionary-Englishdictionary/dict_multilingual.txt: Tokenization-Dictionary-Multilingual
Download the trained checkpoints from Google Drive
model_checkpoint/model_base_en.pt: GanLM-base-Englishmodel_checkpoint/model_base_multilingual.pt: GanLM-base-Multilingualmodel_checkpoint/model_base_multilingual_ft100lang.pt: GanLM-base-Multilingual + Finetune on 100 languagesmodel_checkpoint/model_large_en.pt: GanLM-large-Englishmodel_checkpoint/model_large_multilingual.pt: GanLM-large-Multilingual
DATA_DIR="/path/to/data_dir/" # Required: the directory of the tokenized data file (spm: sentence piece)
PRETRAINED_MODEL_PATH="/path/to/model_file" # Required: the filepath of the pretrained model checkpoint
bash finetune_generartion.sh "${DATA_DIR}" "${PRETRAINED_MODEL_PATH}"DATA_DIR="/path/to/data_dir/" # Required: the directory of the tokenized data file (spm: sentence piece)
PRETRAINED_MODEL_PATH="/path/to/model_file" # Required: the filepath of the pretrained model checkpoint
bash finetune_understanding.sh "${DATA_DIR}" "${PRETRAINED_MODEL_PATH}"GanLM is MIT-licensed.
Please cite as:
@inproceedings{GanLM,
title = "{G}an{LM}: Encoder-Decoder Pre-training with an Auxiliary Discriminator",
author = "Yang, Jian and
Ma, Shuming and
Dong, Li and
Huang, Shaohan and
Huang, Haoyang and
Yin, Yuwei and
Zhang, Dongdong and
Yang, Liqun and
Wei, Furu and
Li, Zhoujun",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.522",
pages = "9394--9412",
}