pFlogger_UserGuide
In High Performance Computing (HPC) applications, the use of text-base
messages (for instance using print statements) can be cumbersome.
The messages may not be organized enough to contain critical information
developers and users need to understand the behavior of their applications.
The typical problems we may encounter are:
- Clarity
- Important messages are lost in the noise of numerous routine messages.
- Performance
- Print statements in an inner loop or across all processes can be expensive, unless control logic is added to limit their execution.
- Anonymity
- Important messages of unknown origin
- Which process (MPI)
- Which software layer
- Which line in a file
- Important messages of unknown origin
- Loss of productivity
- Recompile to activate/deactivate low-level debug diagnostics.
- Complexity
- Ad hoc control logic and/or preprocessing macros used to control execution of optional print statements.
In HPC software running on multi-core platforms, we need to have a framework that facilitates the creation of text-based messages providing useful information on the behavior of the software so as to help code developers and users debug and track down errors systematically. The framework needs to be able to:
- Route warnings and errors to prominent location (file)
- More generally group related messages (e.g., profiling data)
- Have the ability to suppress low severity (”debugging”) messages at runtime.
- Manage duplicate messages on sibling processes. E.g., only produce on root process.
- Support serial and parallel applications. I.e., not force MPI onto serial apps.
- Annotate messages with:
- Time stamp
- Process rank
- Software component
- Other application-specific metadata
All these features need to be controllable at runtime (i.e., without recompilation).
pFLogger (parallel Fortran logger)
is largely a reimplementation of the Python logging module
in standard conforming Fortran, but with additional extensions to support use with MPI. Some logging features that are less relevant to HPC computing are absent.
As with Python logging, pFLogger enables Fortran code developers and users
to better control where, how, and what they log, with much more granularity.
They can then reduce debugging time, improve code quality,
and increase the visibility of their applications.
In this document, we provide an overview of the Python logging module from a Fortran/HPC perspective.
In particular, we present its main classes and how they are used to log messages
in Python applications.
We then describe how pFLogger follows the logging module to implement similar
classes to record messages in Fortran HPC software.
We give details on how pFLogger uses MPI for it to properly work on
both single and multi-core applications.
We provide a description of the pFLogger API.
Finally, we present examples on how pFLogger is used
(statements in the code and settings in the configuration file)
and the variety of messages pFLogger can produce (based on the configuration file settings).
The Python logging module
provides a flexible framework for producing log messages from Python codes.
It allows applications to configure different log handlers and
a way of routing log messages to these handlers.
It is used to monitor applications by tracking and recording events that occur,
such as errors, warnings, or other important information.
The produced log messages can be formatted to meet different requirements,
customized with timestamps, sent to different destinations (terminal, files),
and filtered based on their severity.
This monitoring helps diagnose issues, understand runtime behavior,
and analyze user interactions, offering insights into design decisions.
It can help developers easily identify areas where their code needs
to be improved or better optimised.
This leads to faster development cycles, fewer bugs and higher-quality code.
For more information on the Python logging module, please check the summary page:
As mentioned in the introduction, pFlogger attempts to implement the
features of the Python logging module in the context of Fortran HPC applications.
An important extension in pFlogger is to manage log messages across multiple processes when running under MPI. pFlogger includes direct analogs of logging:
- Logging levels with log severities.
- Log Formatter to enrich a log message by adding context information to it.
- Log Handler to write a log in the console or in a file.
- Logger to log messages or display information we want to see.
pFlogger implements those features in Fortran to enrich the development and maintainance of Fortran applications on high performance platforms.
As in Python, we want pFlogger log messages to be
descriptive (provide a useful piece of information),
contextual (give an overview of the state of the application at a given moment), and
reactive (allow users to take action if something happened).
As mentioned earlier, pFlogger imitates the implementation principles
of the Python logging module.
As such, all the main classes of logging also appear in pFlogger.
The main challenge was to add the MPI extensions and make sure
the messages from MPI processes could be streamlined and properly logged.
Because pFlogger is written purely in Fortran, a huge effort was made
to take advantage of the modern object-oriented features of the language
(Fortran 2003 or above).
The following classes were implemented in pFlogger:
Associated with a logger instance is a set of handlers which dispatch logging events to specific destinations, e.g. STDOUT or a file. A logger can record messages with various levels of severity. A logger looks at a message and ignores it if the message level is less severe than its own level (default is INFO).
Loggers in pFlogger maintain the hierachical rule and all of them inherit from the root logger.
Inheritance is defined by "." (dots), like: mymodule.this.that
is child of mymodule.this.
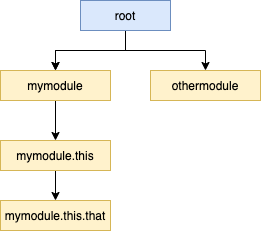
Image Source: https://guicommits.com/how-to-log-in-python-like-a-pro/
To accommodate MPI, the LoggerManager is configured with global communicator (defaults to MPI_COMM_WORLD).
In addition, the Logger can be associated with a communicator (defaults to global)
with the root_level being the root process of a given communicator.
Handler instances are responsible for writing log messages.
They send logs to the appropriate destination (file, STDOUT).
The pFlogger tool exposes four predefined handlers:
-
StreamHandlerwrites logging events to a stream. E.g.,OUTPUT_UNIT(stdout default),ERROR_UNIT, or a unit opened by the user (but hard to use that way). -
FileHandlerwrites logging events to an arbitrary file (usually named in the config file). -
MpiFileHandleris similar to theFileHandlersubclass but each process writes to a separate file. These per-process files can be named using the process rank e.g.,debug_%(rank)i3.3~.logwould write todebug_000.logon root process and so on. -
RotatingFileHandleris used when log messages are too frequent and only the most recent messages are important. This is more common in system logs. This handler switches to a new file when the current file reaches a specified size (max_bytes). At mostbackup_count(default 0) backup files are kept - older files are deleted.
In the context of MPI, pFlogger provides a lock subclass,MpiLock a lock for files which guarantees only one MPI process at a time can write to the file. MpiLock is is implemented with one-sided MPI communication. pFlogger also provides a special filter class for MPI, MpiFilter, which can be used to control which processes actually write to the file. This can be useful at scale to write from say just every 10th process rather than all process. It can work together with other filter subclasses.
LogRecord instances are created every time something is logged, and contains all the information pertinent to the event being logged. This class is generally only used internally within pFlogger and users should generally not concern themselves with this level of detail.
It specifies the layout of log messages in the final destination.
It is up to users to decide what they want the output of the log messages to look like.
The minimum recommendation for this is to include the logging level in your output format.
By default if you do not specify a custom Formatter class,
your log records will contain only the text you provided to the corresponding log methods.
Formatters use the attributes of a LogRecord object to construct the string that will actually be sent to its ultimate destination (typically a file.) It can annotate the original string provided by the user with various bits of information like logger name, severity level, and time stamp. The Formatter class is responsible for "filling in" some of the elements of the original message string passed by the user. Some special cases listed below are derived internally by pFlogger, but log requests also pass down a container of any optional arguments specified by the user for further customization by the Formatter.
E.g., in the following bit of user code:
call warn(".....%a~,... %g25.10", name, x)The Formatter will expand the contents of name at %a~ and the value of the real variable x as a string at the edit descriptor %g25.10. These edit-descriptors are based upon Fortran edit-descriptors, but see the section on edit-descriptors the Appendix below for more details.
The following is a list of reserved expressions that Formatters automatically fill-in from values obtained at runtime. This list can be expanded by the user with an optional "extra" dictionary passed down as an optional argument, but this an advanced use case.
%(name)a Name of the logger
%(short_name)a Short name of the logger
%(level_number)i Integer severity level of the message. (DEBUG, INFO, ...)
%(level_name)a Text logging level for the message
("DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL")
%(asctime)a Textual time when the LogRecord was created
%(message)a The result of record%get_message(), computed just as
the record is emitted
%(line)i Integer line number of recorded in the record.
%(file)a Text file recorded in the record.
%(basename)a Text basename of file recorded in the record.
The MpiFormatter subclass was added to be able to identity the the number of
available processes and a process rank for annotations.
The following diagram illustrates the flow of a Fortran program that writes a message into a log output stream.

Ideally, we also want to implement advanced capabilities such as:
Subcommunicators: How to specify in run-time configuration file?
- Construct communicators prior to initializing framework
- Build dictionary of named communicators
- Pass as optional argument to framework configuration step
Simulation time: Enable annotation of messages with model’s internal representation of time/phase information
- Create a custom procedure that accesses model internal state and returns a dictionary of time related fields. E.g. {‘year’: 2000, ’month’: ’May’, ‘phase’: ‘quality control’}
- Set logger global procedure pointer
get_sim_time()to custom procedure.
In this section, we describe how to include pFlogger calls to record log messages
in Fortran applications.
Before the declaration section of your application (or the component of interest), users first need to import the pFlogger module:
use pFlogger, only : init_pflogger => initialize
use pFlogger, only : logging
use pFlogger, only : LoggerIn addition to that, users need to include the declaration:
class (Logger), pointer :: lgrpFlogger needs to be initialized using the statement:
call init_pflogger()Users may also want to provide the name of the YAML configuration file that has the
settings pFlogger will use to the log records to be written to the desired destination(s).
call logging%load_file('all_in_one.cfg')The previous calls are executed at the beginning of the application. Here, we focus on the calls in any module, subroutine or function. We first need to create a logger (required to produce messages) using a name:
lgr => logging%get_logger('my_section_name')We can create multiple loggers to separate logs for different parts of the application. Loggers are organized hierarchically and identified by name, a string identified by the dots. When a logger is created, it is given a name that identifies its location in the logger hierarchy.
Then, we can now introduce the calls for recording messages:
call lgr%info('Entering the file: %a', trim(FILENAME))
call lgr%info('Begin info at line: %i3.3 in file: %a', __LINE__,__FILE__)
call lgr%debug('myId= %i %a', mype, trim(Iam))
call lgr%debug('Begin debug at line: %i3.3 in file: %a', __LINE__,__FILE__)
call lgr%warning('Warning: ref_date/time %i %i',ref_date, ref_time)
call lgr%warning('Begin warning at line: %i3.3 in file: %a', __LINE__,__FILE__)
call lgr%error('Begin error at line: %i3.3 in file: %a', __LINE__,__FILE__)To record arrays, a special treatment is needed to avoid any compilation issue.
pFlogger has a utility function to wrap arrays:
use pFlogger, only: WrapArray
...
call lgr%debug("grid global max= [%3(i0,:,',')~]", WrapArray(counts))
call lgr%debug("ims= [%1000(i0,:,',')~]", WrapArray(ims))Here, count is an array with 3 entries and ims is array with an 'unknown' number of entries (it is why we use the number 1000 in the formatting).
Before exiting the application, users need to include the call:
call finalize()Users can create a YAML-like configuration file that will be used by their applications to determine the message formats and the types of messages to record. The file has the following main sections:
This is meant to provide the version of pFlogger that users want to use.
It serves for backward compatibility.
Currently, there is only one version and the setting should be:
schema_version: 1
It exercises the MPI lock mechanism which permits access to a target by only one process at a time,
so that other processes cannot interfere while communication is in progress.
In the current version of pFlogger, only the MPI_COMM_WORLD communicator can be employed.
In the future, any user's created communicator can be used here.
locks:
mpi:
class: MpiLock
comm: MPI_COMM_WORLD
The section allow users to define the layout
(what each logger needs to follow when generating a log)
of the logs that will appear in the various output streams.
It represents a list of formatters that will be used by different handlers to format messages.
Here are three formatters options (basic, mpi, column):
formatters:
basic:
class: Formatter
format: '%(name)a~: %(level_name)a~: %(message)a'
mpi:
class: MpiFormatter
format: '%(mpi_rank)i4.4~: %(name)~: %(level_name)a~: %(message)a'
comm: MPI_COMM_WORLD
column:
class: Formatter
format: '(%(i)i3.3,%(j)i3.3): %(level_name)'
Note here that we need to specify the pFlogger formatter class that will be used to implement the desired output format.
It is important to understand the style in the format variable of the different formatters.
We basically have a combination of key names and associated data types.
More details are provided in the Formatter Class section above.
This section defines the various output streams (standard output, specific files, unique file per process) the log records will be sent to. It provides the settings specifying where the log messages will be saved. We need to provide the name of the output stream (as a subsection) and include the settings:
-
class: for thepFloggerclass to be considered for the stream. -
formatter: any of the appropriate formatter denied in the sectionformatters. -
unit: can be the Fortran OUTPUT_UNIT or ERROR_UNIT -
level: the (lowest) logger level to apply to the stream -
filename: name of the file the log records will be written into. We can have a setting where each MPI process has its own log file. -
comm: the MPI communicator to use -
lock: In the context where all the MPI processes write to the same file, it is important to make sure that there is no conflict.
handlers:
console:
class: streamhandler
formatter: basic
unit: OUTPUT_UNIT
level: DEBUG
warnings:
class: FileHandler
filename: warnings.log
lock: mpi
level: WARNING
formatter: basic
infos:
class: FileHandler
filename: infos.log
lock: mpi
level: INFO
formatter: mpi
debugs:
class: FileHandler
filename: debugs.log
lock: mpi
level: DEBUG
formatter: mpi
errors:
class: StreamHandler
formatter: basic
unit: ERROR_UNIT
level: ERROR
mpi_shared:
class: FileHandler
filename: allPEs.log
formatter: mpi
comm: MPI_COMM_WORLD
lock: mpi
rank_keyword: rank
level: INFO
mpi_debug:
class: MpiFileHandler
formatter: basic
filename: debug_%(rank)i3.3~.log
comm: MPI_COMM_WORLD
rank_prefix: rank
level: INFO
Note that in the mpi_debug sub-section, each process records the log
messages in its own file.
The logger level applies to all the processes.
If instead rootlevel is instead used, it will be for the root process
of the communicator.
It is meant to represent the root logger of the application.
Here, we select the logger output streams that will be used
based on the settings in the handlers section.
It has the members variables:
parallel-
handlers: the list selected handler names defined in thehandlerssection of the configuration file. -
level: name of the lowest level that will be considered for all the selected streams inhandlers
root:
parallel: true
handlers: [console,warnings,debugs,infos]
level: DEBUG
It is recommended that users only attach each handler to one logger and rely on propagation to apply handlers to the appropriate child loggers. This means that if users have a default logging configuration that they want all of loggers to pick up, they need add it to a parent logger (such as the root logger), rather than applying it to each lower-level logger.
Here we list all the loggers that are instantiated in the code through the call:
call logging%get_logger(logger_name)In this section, we provide the names of the loggers associated with the code sections we want to monitor. Each logger is defined with its own configuration.
loggers:
MAPL.GENERIC:
parallel: false
comm: MPI_COMM_WORLD
level: INFO
parallel:
parallel: true
handlers: [mpi_debug,mpi_shared]
lock: mpi
propagate: true
level: INFO
By default, all created loggers will pass the log events to the handlers of
the parent logger, in addition to any handlers attached to the created logger.
You can deactivate this by setting propagate: false.
Sometimes when you wonder why you don't see log messages from another module, then this property may be the reason.
For pFlogger to be effective, we should only attach each handler to one logger and
rely on propagation to apply handlers to the appropriate child loggers.
This means that if we have a default logging configuration that we want all of your loggers to pick up,
we should add it to a parent logger (such as the root logger), rather than applying it to each lower-level logger.
Consider the following Fortran code (contained in a file name complexMpi.F90).
It shows how to include pFlogger statements to record log messages.
There are a main program, and two supporting subroutines (sub_A and sub_B),
all of them having different types of annotations.
- Main program
- Is expected to read the configuration file all_in_one.cfg
- Has one logger,
mainwith message of level INFO.
- Subroutine sub_A
- Has two loggers
-
main.Awith messages of levels INFO, DEBUG and WARNING. - 'parallel.A` with messages of levels INFO and DEBUG.
-
- Has two loggers
- Subroutine sub_B
- Has two loggers
-
main.Bwith messages of levels INFO, DEBUG and ERROR. -
parallel.Bwith a message of level INFO.
-
- Has two loggers
subroutine sub_A()
use pflogger
integer :: i
class (Logger), pointer :: log
class (Logger), pointer :: plog
integer, allocatable :: counts(:)
allocate(counts(2))
counts = [7, 19]
log => logging%get_logger('main.A')
plog => logging%get_logger('parallel.A')
call log%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
call log%debug('inside sub_A')
call plog%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
call plog%debug('inside sub_A')
call log%warning('empty procedure')
call log%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
call log%debug("counts= [%1000(i0,:,',')~]", WrapArray(counts))
deallocate(counts)
end subroutine sub_A
subroutine sub_B()
use pflogger
integer :: i
class (Logger), pointer :: log
class (Logger), pointer :: plog
real, dimension(3) :: var = [2.133, 4.7962, -3.7845]
log => logging%get_logger('main.B')
plog => logging%get_logger('parallel.B')
call log%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
call log%debug('inside sub_B')
call plog%debug('inside sub_B')
call log%error('this procedure is empty as well')
call log%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
call log%debug("Values of var= [%3(f8.5,:,',')~]", WrapArray(var))
end subroutine sub_B
program main
use pflogger
use mpi
implicit none
integer :: ier
class (Logger), pointer :: log
integer :: rc
integer :: rank
call mpi_init(ier)
call mpi_comm_rank(MPI_COMM_WORLD, rank, rc)
! Initialize pFlogger
call initialize()
call logging%load_file('all_in_one.cfg')
log => logging%get_logger('main')
call log%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
call sub_A()
call log%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
call sub_B()
call log%info('at line: %i3.3 in file: %a', __LINE__,__FILE__)
! Finalize pFlogger
call finalize()
call mpi_finalize(ier)
end program mainThe configuration below is meant to be used by the executable (of the above code) to determine which messages will be logged and to which destination(s).
schema_version: 1
locks:
mpi:
class: MpiLock
comm: MPI_COMM_WORLD
formatters:
basic:
class: Formatter
format: '%(name)a~: %(level_name)a~: %(message)a'
mpi:
class: MpiFormatter
format: 'Rank %(mpi_rank)i4.4~: %(name)~: %(level_name)a~: %(message)a'
comm: MPI_COMM_WORLD
column:
class: Formatter
format: '(%(i)i3.3,%(j)i3.3): %(level_name)'
handlers:
console:
class: streamhandler
formatter: basic
unit: OUTPUT_UNIT
level: WARNING
debugs:
class: FileHandler
filename: debug_msgs.log
level: DEBUG
formatter: basic
infos:
class: FileHandler
filename: info_msgs.log
level: INFO
formatter: basic
warnings:
class: FileHandler
filename: warnings.log
lock: mpi
level: WARNING
formatter: basic
errors:
class: StreamHandler
formatter: basic
unit: ERROR_UNIT
level: ERROR
mpi_shared:
class: FileHandler
filename: allPEs.log
formatter: mpi
comm: MPI_COMM_WORLD
lock: mpi
rank_keyword: rank
level: DEBUG
mpi_debug:
class: MpiFileHandler
formatter: basic
filename: debug_%(rank)i3.3~.log
comm: MPI_COMM_WORLD
rank_prefix: rank
level: DEBUG
root:
parallel: true
handlers: [warnings,errors]
level: WARNING
loggers:
main:
parallel: false
comm: MPI_COMM_WORLD
level: INFO
parallel:
parallel: true
handlers: [mpi_debug,mpi_shared]
lock: mpi
propagate: false
level: DEBUG
main.A:
level: WARNING
main.B:
level: INFO
parallel.A:
level: WARNING
parallel.B:
level: DEBUG
In the above configuration file, we define six (6) loggers: main (producing no parallel messages: parallel: false), parallel (can produce parallel messages: parallel: true), main.A, main.B, parallel.A and parallel.B.
Each logger has its own logging level. main relies on the handlers set in root while main.A and main.B inherit main handlers.
parallel has two handlers (mpi_debug and mpi_shared) that are shared with parallel.A and parallel.B.
If we run the application with the above configuration settings, we expect the following:
- The
main,main.A, andmain.Bcan only create messages of severity WARNING and above or ERROR and above because they rely onrootthat only supports thewarningsanderrorshandlers. The log messages will be recorded in the output streams:- warnings.log: for reporting the WARNING logs (or above).
- STDOUT: for reporting the ERROR logs (or above).
-
parallel.Aandparallel.Bcan create messages for thempi_shared(severity DEBUG and above) andmpi_debug(severity DEBUG and above) handlers. The log messages will be recorded in the output streams:- allPEs.log: for recording all the DEBUG logs (or above) from all the MPI processes.
- debug_XXX.log: (where XXX is the process id) for DEBUG logs (or above) for processor XXX.
A simple test on 4 processors generated the outputs:
STDOUT
main.B: ERROR: this procedure is empty as well
main.B: ERROR: this procedure is empty as well
main.B: ERROR: this procedure is empty as well
main.B: ERROR: this procedure is empty as well
warnings.log
main.A: WARNING: empty procedure
main.A: WARNING: empty procedure
main.A: WARNING: empty procedure
main.A: WARNING: empty procedure
main.B: ERROR: this procedure is empty as well
main.B: ERROR: this procedure is empty as well
main.B: ERROR: this procedure is empty as well
main.B: ERROR: this procedure is empty as well
allPEs.log
Rank 0003: parallel.B: DEBUG: inside sub_B
Rank 0000: parallel.B: DEBUG: inside sub_B
Rank 0001: parallel.B: DEBUG: inside sub_B
Rank 0002: parallel.B: DEBUG: inside sub_B
debug_000.log
parallel.B: DEBUG: inside sub_B
debug_001.log
parallel.B: DEBUG: inside sub_B
debug_002.log
parallel.B: DEBUG: inside sub_B
debug_003.log
parallel.B: DEBUG: inside sub_B
Note that in the configuration file, the severity level INFO is set for logger main.B
in the loggers: section.
However, the logs related to main.B only contain (in STDOUT) ERROR messages.
We do not see anywhere any main.B INFO logs though the code has calls to produce INFO logs.
The reason is that the configuration file does not have any setting (in the handlers: section)
specifying how to treat (format, destination, etc.) INFO messages.
That is the advantage of pFlogger that allows users to select at run time which log messages
to write out.
If we add infos in the list of handlers in the root: section:
root:
parallel: true
handlers: [warnings,errors,infos]
level: WARNING
Running the application again (without recompiling) creates a new log file:
info_msgs.log
main: INFO: at line: 065 in file: complexMpi.F90
main.A: WARNING: empty procedure
main: INFO: at line: 068 in file: complexMpi.F90
main.B: INFO: at line: 033 in file: complexMpi.F90
main.B: ERROR: this procedure is empty as well
main.B: INFO: at line: 038 in file: complexMpi.F90
main: INFO: at line: 071 in file: complexMpi.F90
The new file has log messages (for the loggers main, main.A and main.B) of severity at least equal to INFO for various loggers.
Now assume that we only want the logger main.B to produce messages at the level INFO or above. Then root will have its original setting:
root:
parallel: true
handlers: [warnings,errors]
level: WARNING
and the handlers will be set for the main.B logger in the loggers section:
main.B:
handlers: [infos]
level: INFO
The new info_msgs.log will then be:
info_msgs.log
main.B: INFO: at line: 033 in file: complexMpi.F90
main.B: ERROR: this procedure is empty as well
main.B: INFO: at line: 038 in file: complexMpi.F90
The loggers main.A and main.B have log calls for severity level DEBUG,
some of which are expected to record arrays.
In the subroutine sub_A, the size of the array counts is known at run time.
For this reason, we assume that the size is at most 1000 and the log call is:
call log%debug("counts= [%1000(i0,:,',')~]", WrapArray(counts))
Similarly, in sub_B, the size of var is known to be equal to 3 and the call is:
call log%debug("Values of var= [%3(f8.5,:,',')~]", WrapArray(var))
to record an array of floating point numbers (each one with 8 digits and 5 of them after the decimal).
Now we want the loggers main.A and main.B to record messages of severity level DEBUG or above.
We include the following settings in the configuration file:
main.A:
handlers: [debugs]
level: DEBUG
main.B:
handlers: [debugs]
level: DEBUG
After running the executable, ww will create the file debug_msgs.log that contains:
main.A: INFO: at line: 015 in file: complexMpi.F90
main.A: DEBUG: inside sub_A
main.A: WARNING: empty procedure
main.A: INFO: at line: 021 in file: complexMpi.F90
main.A: DEBUG: counts= [7,19]
main.B: INFO: at line: 042 in file: complexMpi.F90
main.B: DEBUG: inside sub_B
main.B: ERROR: this procedure is empty as well
main.B: INFO: at line: 047 in file: complexMpi.F90
main.B: DEBUG: Values of var= [ 2.13300, 4.79620,-3.78450]
In the previous example, the file debug_msgs.log had log messages of severity level of DEBUG and above.
However, we want the file to only have DEBUG messages.
pFlogger has utility functions that allow users to filter messages.
To exercise them, users need to add a filters section in the configuration file:
filters:
fdebug:
class: levelfilter
min_level: DEBUG
max_level: DEBUG
In the above, we want to have a fdebug filter that only allows debug messages.
We can filter messages within a range of severity levels by modifying the values of min_level and max_level.
The next step is to specify the filter for the handler we are interested in. In our case, it is the debugs handler:
debugs:
class: FileHandler
filename: debug_msgs.log
level: DEBUG
filters: [fdebug]
formatter: basic
Note that the filters needs to be set as a list of filters.
If we keeo the same settings for the loggers:
main.A:
handlers: [debugs]
level: DEBUG
main.B:
handlers: [debugs]
then, after running the code, the file debug_msgs.log will then be:
main.A: DEBUG: inside sub_A
main.A: DEBUG: counts= [7,19]
main.B: DEBUG: inside sub_B
main.B: DEBUG: Values of var= [ 2.13300, 4.79620,-3.78450]
- Python Logging HOWTO
- Python Logging Cookbook
- Arfan Sharif, Python Logging Guide: The Basics, February 3, 2023.
- Son Nguyen Kim, Python Logging: An In-Depth Tutorial
- Thomas Clune and Carlos Cruz,
pFlogger: The Parallel Fortran LOgging UTility, CodeSE17, Denver, CO. - Thomas L. Clune and Carlos A. Cruz,
pFLogger: The parallel Fortran logging framework for HPC applications, Proceedings of the 1st International Workshop on Software Engineering for High Performance Computing in Computational and Data-enabled Science & Engineering, November 2017, Pages 18-21, https://doi.org/10.1145/3144763.3144764
Formatted data transferred to a destination, require the exact formatting of the data to be specified. The format specification contains edit descriptors which describe exactly how values should be converted into a character string on a destination. They can be of data edit descriptors, control edit descriptors, or string edit descriptors. Here, we focus on the data edit descriptor that takes one of the following forms:
[r]c [r]cw [r]cw.m [r]cw.d [r]cw.d[Ee]
-
r: An optional repeat count. (If you omit "r", the repeat count is assumed to be 1.)
-
c: A format code (I, B, O, Z, F, E, EN, ES, D, G, L, or A).
-
w: The total number of digits in the field (the field width).
-
m: The minimum number of digits that must appear in the field (including leading zeros).
-
d: The number of digits to the right of the decimal point.
-
E: Identifies an exponent field.
-
e: The number of digits in the exponent.
The specific forms for data edit descriptors follow:
| Function | Format |
|---|---|
| Integer | Iw[.m] |
| Binary | Bw[.m] |
| Octal | Ow[.m] |
| Hexadecimal | Zw[.m] |
| Real number | Fw.d |
| Exponential form | Ew.d[Ee] |
| D exponential form | Dw.d |
| G exponential form | Gw.d[Ee] |
| Scientific form | ESw.d[Ee] |
| Engineering form | ENw.d[Ee] |
| Logical | Lw |
| Character | A[w] |
- The
Adescriptor is used for strings.- The number of characters in the output (the field width) is equal to the length of the string.
- The field width
wcan be prescribed by using the formAw. - If the string has more than w characters it is truncated. If it has fewer that w characters, it is padded out with leading spaces.
- For example
A20is used for a string in a field width of 20 characters.
When pFlogger parse formats (controlling the appearance of the output streams), it needs to know when a format is completed.
pFlogger relies on a blank space or the symbol ~ (tilde) to indicate the end of a format descriptor.
For instance in:
'Rank %(mpi_rank)i4.4~: %(name)~: %(level_name)a~: %(message)a'
there are two format descriptors in i4.4~: which endings are identified with ~ (for i4.4) and (black for:`).