This project is a part of the CS5228 Machine Learning course at the National University of Singapore. For more details, please visit the Kaggle competition page. The objective of this project is to build a model that accurately predicts the resale prices of HDB (Housing & Development Board) flats in Singapore.
The project is organized into the following directories and files:
.
├── data
│ ├── auxiliary-data
│ ├── auxiliary-data-preprocessed
│ ├── test_cleaned.csv
│ ├── test.csv
│ ├── train_cleaned.csv
│ └── train.csv
├── data_preprocess.ipynb
├── EDA.ipynb
├── main.py
├── README.md
└── result
└── submission.csvdata: Contains the raw and preprocessed data files.auxiliary-data: Contains additional data files.auxiliary-data-preprocessed: Contains preprocessed auxiliary data files.test_cleaned.csv: Cleaned test data file.test.csv: Raw test data file.train_cleaned.csv: Cleaned train data file.train.csv: Raw train data file.
data_preprocess.ipynb: Jupyter notebook for data preprocessing.EDA.ipynb: Jupyter notebook for Exploratory Data Analysis (EDA).main.py: Main Python script containing the implementation of machine learning models.README.md: This file, providing an overview of the project.result: Contains the output results of the predictions.submission.csv: Sample prediction output file.
- Clone the repository to your local machine. And download the data files from the Kaggle competition page.
- Install the required Python packages by running
pip install -r requirements.txt(if provided) or install the necessary packages individually (e.g., pandas, scikit-learn, xgboost, lightgbm, optuna, etc.). - Open the
data_preprocess.ipynbandEDA.ipynbnotebooks in Jupyter to view the data preprocessing and exploratory data analysis steps, respectively. - Run the
main.pyscript to execute the machine learning models and generate predictions. - Visualize the results using optuna-dashboard. Details are shown in the Visualization subsection.
The project explores various machine learning models, including:
- Linear Regression
- LightGBM
- Gradient Boosting Tree
- Random Forest (with GPU support)
- XGBRegressor (with GPU support)
Models are evaluated using cross-validation, and hyperparameter tuning is performed using GPU-supported frameworks like Optuna. The performance of each model is compared to identify the best performing model for predicting HDB resale prices.
$ pip install optuna-dashboard
$ optuna-dashboard sqlite:///example-study.dbPlease check out the GitHub repository for more details.
| Manage Studies | Visualize with Interactive Graphs |
|---|---|
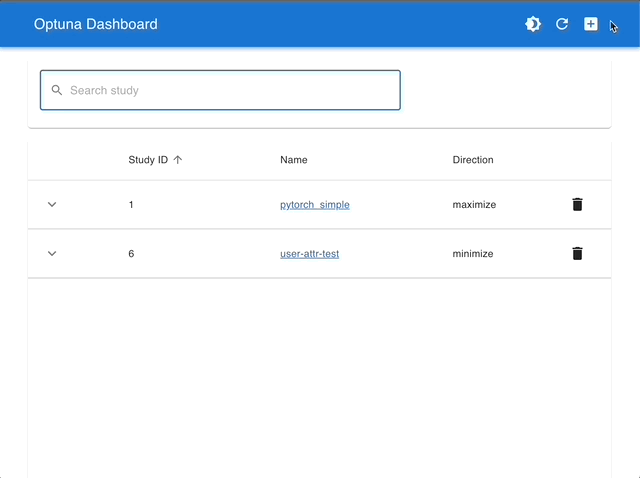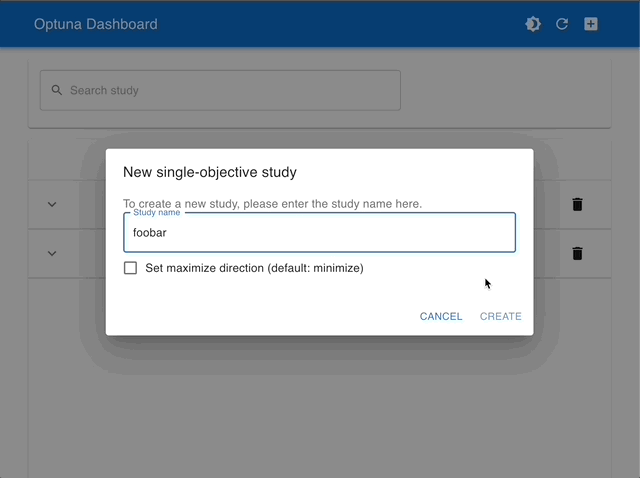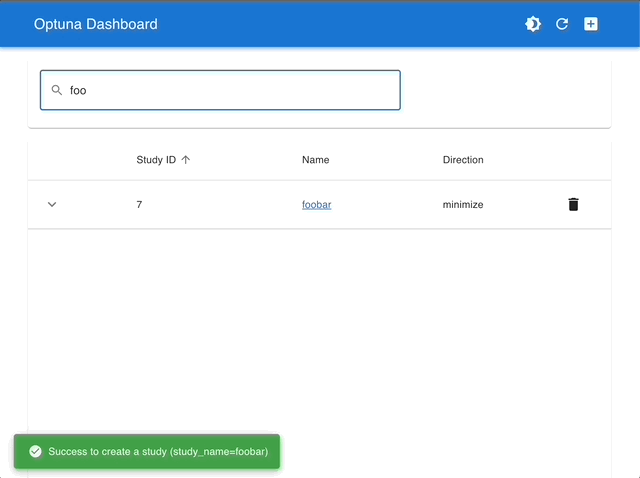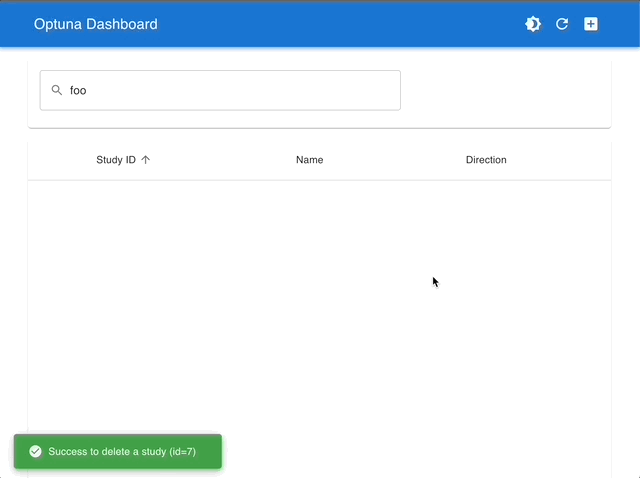 |
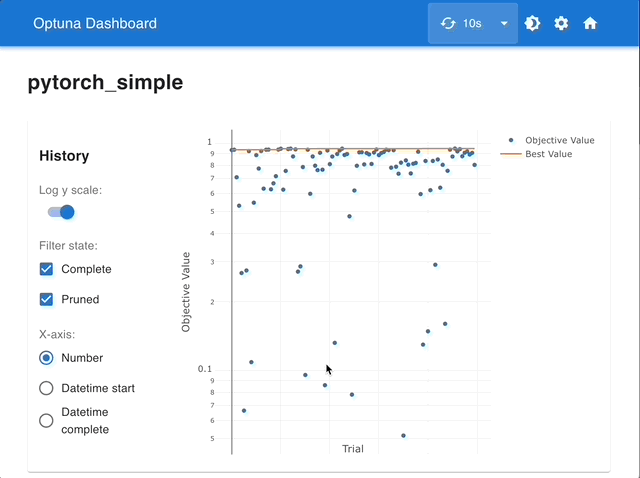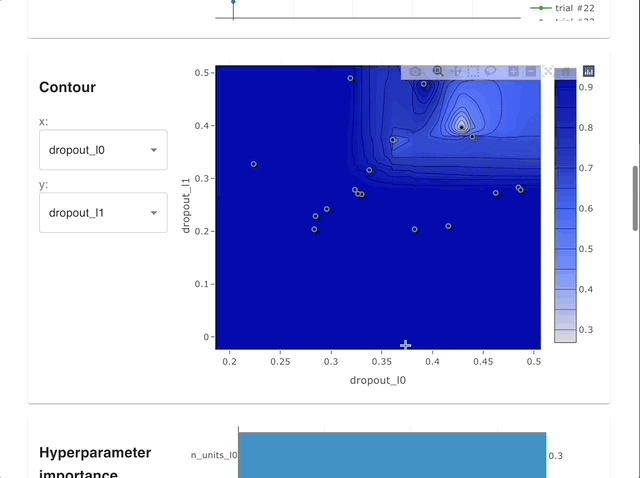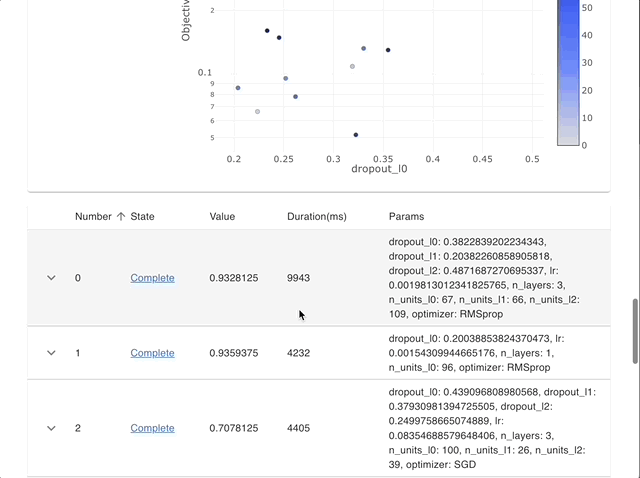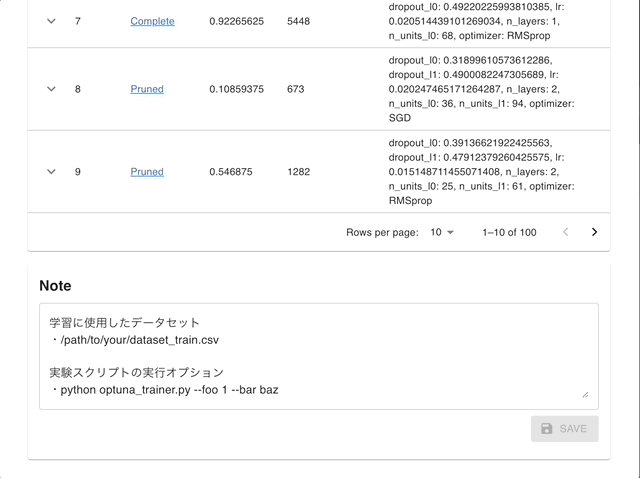 |
Visualize the optimization history.

Visualize high-dimensional parameter relationships.

Visualize individual hyperparameters as slice plot.

Visualize parameter importances.

Visualize empirical distribution function.
