(/Multimodal-sentiment-analysis/image-speech-audio)
本项目代码是课题:基于多模态情感分析的健康导航研究 的本地运行代码项目工程的一部分
该代码仅供学术使用,相关软件已申请著作权,涉及到敏感信息完整版本将在后续时间节点(22年底)进行发布(缺失main.py与专家系统的核心代码文件)。
(情感计算部分涉及:Official Code of "AMSA: Adaptive Multimodal Learning for Sentiment Analysis")
机器学习领域日益多元化,涵盖心理健康等新领域。 最近变得相关的话题,特别是在抑郁、焦虑或心理和精神科帮助的问题上。 该项目旨在达到两个项目相遇的地步,拥有一个可以接收视频作为输入并可以对其中表示的情绪进行分类的智能模型,其想法是在未来它可能被用作一种工具可以根据更多信息做出诊断的心理健康专家。 这个模型也在寻找的是考虑到视频中出现的病人或人的所有方面,分析他们的声音、他们的演讲内容和他们的面部表情; 这与推理在执行时具有最多可用属性的想法有关。
==整个代码工程包括三部分代码:自适应多模态情感计算框架,用于健康导航的专家系统以及人机交互界面GUI==
AMSA_main.ipynb是**==colab==**的文件
该项目的当前状态包括分析视频并在考虑到上述特征的情况下做出三种不同的推断:音频、文本和图像。 推断可以独立进行,但在存储库中更容易在同一介质上进行推断。
对视频的推断结果总结如下:
- ASR - 视频中音频的转录。
- 文本 - 分析成绩单,然后分类。
- 音频 - 分析音频特征,然后分类。
- 图像 - 分析视频的每一帧,生成带有面部点的输出视频。
如果要对用户音频或视频进行推断:
- 运行直到 ASR 部分的所有单元以下载要使用的依赖项和权重。
- 根据具体情况,使用
import_audio、import_video函数,以及 notebook 指示的transcribe函数。 - 在 M11 部分更改行内:
path_to_video = Path('../', asr_demo_result[0]['audio_path'])asr_demo_result 带有接收到 transcribe 函数结果的变量的名称
- 继续执行单元格,直到 Text Inferences 部分中的倒数第二个必须进行与上一个类似的更改:
x = predictions(asr_demo_result[0]['transcription'], glove, fasttext)asr_demo_result 带有接收 transcribe 函数结果的变量的名称
- 最后,在 DETR 部分中将
INPUT_PATH变量的值更改为:<接收转录函数的变量名>[0]['video_path']
- 用于此联合实施的不同模型位于单独的文件夹中, 每个文件夹内的自述文件中都有更详细的解释。
本地界面:创建一个空列表来存储规则
rules = []云部署平台:采用MySQL编写,利用API接口上云
采用阿里云:https://www.aliyun.com/sswd/396339-1.html
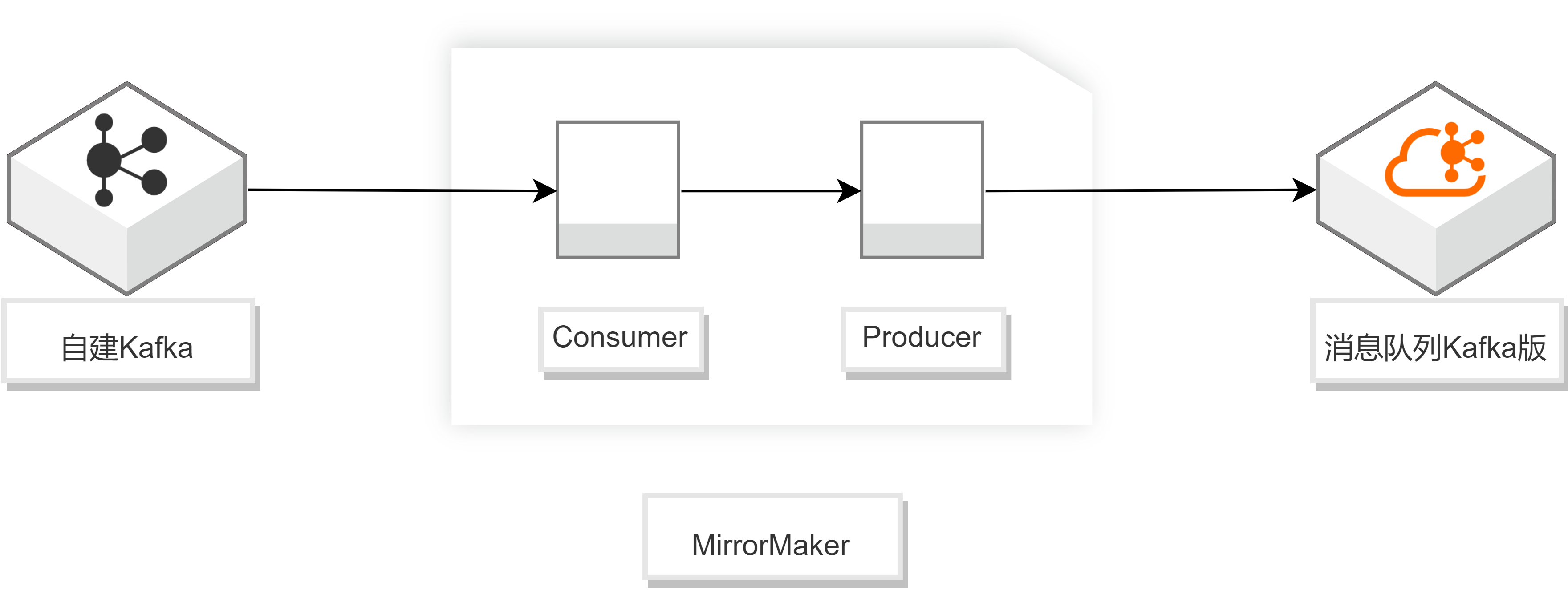
-
配置consumer.properties。
## 自建Kafka集群的接入点 bootstrap.servers=XXX.XXX.XXX.XXX:9092 ## 消费者分区分配策略 partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor ## Group的名称 group.id=test-consumer-group
-
配置producer.properties。
## 消息队列Kafka版集群的默认接入点(可在消息队列Kafka版控制台获取) bootstrap.servers=XXX.XXX.XXX.XXX:9092 ## 数据压缩方式 compression.type=none
-
执行以下命令开启迁移进程。
sh bin/kafka-mirror-maker.sh --consumer.config config/consumer.properties --producer.config config/producer.proper
该方法用来读取规则库,读取规则库文件中规则,并存放在rules字典中:
- 字典的键:前提
- 字典的值:结论
def readRules(filePath):
global rules
for line in opoen(filePath, mode = 'r',encoding = 'utf-8'):修改readRules(filePath)文件的global rules
这一步是专家系统的核心,主要是利用综合数据库与规则库进行匹配,包括如下步骤:
- 推理机用这些事实(即:facts变量),依次与知识库中的规则的前提匹配
- 若某规则的前提全被事实满足,则规则可以得到运用
- 规则的结论部分作为新的事实存储
- 用更新过的事实再与其他规则的前提匹配,直到不再有可匹配的规则为止
def matchRules(facts):
print()
# 循环匹配
isEnd = False
def loop():
...
# 是否推导出最终结论
while(not isEnd):
loop()对于RIMER函数采用 def loop()的循环匹配进行更新
主要是用户输入规则
def ui():
# 到时候绑定控件,或者和GUI联调的时候再处理GUI时间绑定后加载规则库
调用定义的函数加载规则库txt数据
filePath = r'#规则库的txt链接'
readRules(filePath)参考规则库,分别输入情感特征(以 and 连接),按 回车键 输入系统检索:
ui() # 人机交互函数本项目一共包含三种平台:
本地界面,云部署平台以及机器人
采用pyqt进行编写,pyinstaller封装成软件:
中文版本——

英文版本——

包括多种功能:
- 系统算法实现:情感监测,心理调查,情感分析,健康反馈,调节指南,生成报告
- 数据库检索实现:“提供服务”,“健康问答自测”,“常见健康问题”
主要功能包括基于本课题算法实现的,以及在数据库中添加的条目通过控件查看的,可以运行封装好的软件,或者运行:
GUI.py,GUI_connect_cn.py,GUI_connect_en.py以及GUI_connect_button.py进行查看。