Charge fees for use of memo #3007
Conversation
|
Thank you for your submission. It will be reviewed soon and submitted for processing in CI. |
|
👍 Alternative (credits to @codetsunami for the idea) is a simple PoW like solution (find a hash, amount of prefix zeroes based on the memo size. Some free bytes and after that: find the zeroes) |
|
I like the XRP fee rather than a proof-of-work solution. It's more effective (and more in-keeping with existing XRPL features) to charge real value in the form of XRP than pseudo-value in the form of "work" (whose actual value depends on your electricity costs and computing power). I also like how this implementation keeps memos ≤ 32 bytes free—equivalent to adding an InvoiceID or similar Hash256-type field.. |
| memos.add (s); | ||
|
|
||
| if (s.size() > 32) | ||
| memoCount = 2 * static_cast<std::uint32_t>(s.size()); |
There was a problem hiding this comment.
Seems reasonable. I'd probably consider making the multiplier a function of length too. For example:
memoCount = std::max(1, (s.size() / 128)) * static_cast<std::uint32_t>(s.size());
This gives it a nice stepped "curve" of increasing slope, as you can see on this WolframAlpha graph
There was a problem hiding this comment.
Maybe just s.size() * s.size() / 128 for simplicity. With a minimum s.size() of 32, this expression starts at 8 and scales to 8192.
There was a problem hiding this comment.
@miguelportilla makes a good point that super-linear fee scaling will just encourage splitting into multiple transactions at the point where the marginal cost of a memo byte exceeds the cost of a new transaction. That means we should just use s.size() for memoCount.
| @@ -118,6 +118,7 @@ detail::supportedAmendments () | |||
| "MultiSignReserve", | |||
| "fixTakerDryOfferRemoval", | |||
| "fixMasterKeyAsRegularKey", | |||
| "MemoFee" | |||
There was a problem hiding this comment.
Need to also add "MemoFee" to featureNames in Feature.h.
There was a problem hiding this comment.
Please add a trailing comma to this line as well.
Jenkins Build SummaryBuilt from this commit Built at 20190723 - 23:11:47 Test Results
|
|
The more I think about this, the more I think it’s the wrong approach. There’s nothing inherently wrong with memos, and charging more for them less sense the more I think about it. |
|
Wietse - Charging for this won't stop the child porn concern you expressed. I believe it already happened on BTC years ago. I tend to agree with you on people attempting to use XRPL for file storage. An alternative approach might be to write code fingerprinting these apps pulling the txn's from your servers. Then you could block/slow/timeout the results - rendering them useless. Nik - I'm not entirely opposed to a fee, but the idea of starting it at 32 bytes? That's a 1/4 tweet! I think it's killing innovation before we even know the possibilities of what could be developed. I also think the scaled approach is going to be a nightmare down the road. If anything I would suggest 4 tiers 128, 256, 512, and 768. Apps developed using the memo field would at least have a framework and cost structure that's a bit more stable. |
|
@OTNSam I agree, however: allowing to store a relatively large chunk of data, almost for free, makes it pretty easy to abuse the XRPL for something it's not designed for. Interesting you mention the fingerprinting and slowing/blocking certain responses. I started working on a rippled webservice proxy just now, allowing me to do just that. |
|
And that's the thing Wietse - Nobody is required to keep full history, so it's not technically a free lunch. The bigger question:
I can see the case for discouraging, but not hamstringing. Perhaps Free,1x,4x,8x fees? (Sorry Nik, just noticed yours has tiers - long time since I wrote any C++) |
|
How you can block a valid tx? Make no sense. |
|
@yxxyun I think you are replying at me? I mean blocking out the response message when one of those transactions is requested (fetching account transactions or individual transactions). As in: they won't be retrieving their files from my full history node. |
|
Why do we need images in memos at all? I just can't think of a single automated use case which requires passing image data. It's a silly niche thing for human eyes and only helps bloat the size of XRPL Still a little fuzzy on the approach for slowing down/blocking requests. Doesn't seem like this prevents the biggest issue which is inappropriate images stored on the chain for eternity? |
|
Is there a way to track down if a memo points to another one (e.g. if a memo contains another tx id) and then increase the fee exponentially with every chained transaction? |
|
@JamesGDiaz That's easy to bypass by encoding TX ID's some other way, and that wouldn't prevent the "Just dump lots of random data in it" (cheap) attack. |
|
@WietseWind Yes, I saw that discord. I'm just brainstorming here :) |
|
Taking some other approach and considering privacy and e.g. GDPR an issue, wouldn't it be an idea to enforce by the rippled software a hashed sha256 storage of the memo in question ? In that case an exchange of the content of the memo would always have to be off-chain, but size is guaranteed small and current fee schedule would suffice (also just brainstorming) |
|
My idea would also have been along the lines of increasing fees according to the total size of transactions in the last x units of time. People manage to spam the ledger with other things than memos too (high frequency OrderCreate/OrderCancel comes to mind). Looking not only at the current transaction but also the recent history might make sense (and would be more costly, resource-wise). This PR however seems to hit the wrong spots, the more I think about it. Memos really hurt servers with full history, validators shouldn't even store ANY history imho and bootstrap from a verified ledger state instead, so they are completely unaffected by excessive memo spam. It is not really in their interest to do anything against memos, as these only hurt the ecosystem as a whole, not their operations. Unfortunately there's only mostly fee and reserve settings as a knob to turn. There used to be a PoW implementation by the way on the PeerProtocol side of things, but it got removed after a while, as far as I understood it was mostly used for allowing peers to connect to you while making sure you're not being overloaded. In general the base fees on XRPL are too low, validators should just increase them from 10 drops to 1000 or 10000 drops and this whole attack is a non-starter while still costing fractions of an US-cent at current XRP prices per transaction. I personally switched mine off for now, I can't compile Generally,I tend to agree more with Wietse: Having MemoType, MemoData, MemoFormat and then MemoPoW (or MemoPoWNonce) in the spec would make memos a bit larger in general, but could keep them smaller in total by requiring a larger PoW for each byte added. This would be a similar approach to BitMessage, who run a "sliding window" blockchain of ~2 weeks and require a relatively hefty PoW to be attached to each of their (encrypted) message transactions. Still an incomplete solution though (can still be spammed by someone with a botnet and doesn't help anyone with a full history server or the network in general to keep history/shard size down). Another quick-fix non-solution would be a config switch to NOT return memos from transactions earlier than a certain amount of ledgers (similar to The fastest solution would be to limit memos to a rather small size instead of 1 kB and allow larger memos only after implementing a strict(er) verifier (e.g. you can add IPFS hashes as MemoType/MemoFormat, but stuff in MemoData has to be at least syntactically valid, not just random bytes or base64 encoded). 64 bytes of Memo should be enough for everyone after all! ;-) |
|
Stellar‘s implement:
|
|
Ripple have 9Tb+ and requires 32Gb RAM while exists since 2012 regarding wiki.
|
|
ETH with full state has ~300 GiB? Keep in mind that these ~9 TiB contain both transactions and state, the transactions themselves are a bit less than a TiB last time I checked. BTC for example only calculates, but doesn't store state (if you want to know the UTXO set at block 1000000, you need to calculate it by replaying transactions since genesis). Anyways, the "memo" feature in Bitcoin is |
|
ETH full node is over 2TB |
@MarkusTeufelberger yes, as @yxxyun mentioned it's not the 300Gb (i use Same time capacity-planning and configure-history-sharding tells us what a 2 weeks (300k ledgers regarding this article) will take upto 76Gb of disk space as is (upto 256b per ledger if i calc well). I personally have no negative to this pull request and every dev team must improve the codebase, but it looks very late, just when someoone wanted to inject 1Tb of trash into a blockchain. So i want to ask: what you did before? Why only now? P.S. personally i did not build anything yet on XRP, but i have a nice roadmap to do it. |
|
|


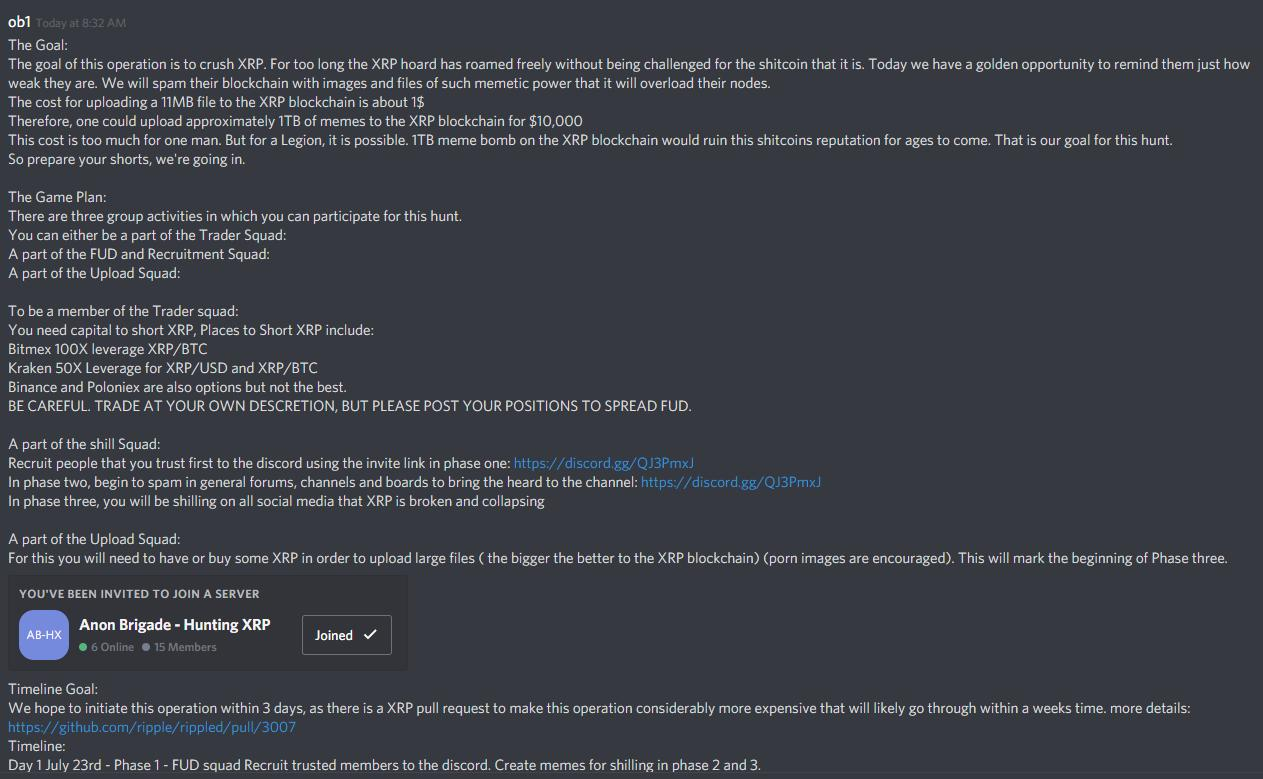{kind=link}
|
As some people have already discussed above instead of directly including the memo fields in the transaction, just leave a memo_hash = hash(accountID + seq_no + memo) in the transaction and then supply the memo as a separate entity after the transaction. Memos would not be inherently required for "full" history then, and some servers can collect and store memos if they wish to. I think this is the most flexible solution. It also allows memos containing illegal content to be removed from servers. |
@codetsunami you mean blockchain under moderation/cenzorship enabled? Lol, thats better than just to store 1Tb 😏 |
|
@nikitasius it wouldn’t be censorship. You’d still be able to submit whatever memo you want, and it’d still be relayed and processed by the network, it just makes it easier for history nodes to omit non essential blockchain data if they choose to |
|
@codetsunami we put to retieve it back. When we move the information out of the blockchain it's not a part of blockchain anymore. In such case if everyone (all full nodes) forget something, it will be lost forever. This is a moderation. Idk who need to use a blockchain with a moderation. |
|
@codetsunami - should these memos then also end up in the nodestore and/or shards or should they be discarded before storing them to disk? |
@MarkusTeufelberger I'd say by default they should be sharded and all data kept. Later if it is posing a problem an amendment to prune can be put through. Doesn't hurt anyone and gives full history node runners an easy way to remove any illegal content if they get a takedown notice. |
|
Then there could be lots of different versions of a shard (every transaction with and without memo). |
|
@MarkusTeufelberger agree shards would also need a revision to place any segwit content in a secondary shard (a segwit for shards if you will) which may or may not be available from a given history node. Does seem reasonably complicated, however network spam might force hands here |
|
seelabs@5b34dd0 |
|
@yxxyun it’s just an experimental branch... a “how would this look?” kind of thing. Ripple hasn’t decided whether to submit any proposed changes in response to this, and even if we do, it’s up to the network to decide whether to adopt those changes. |
|
Well,it's more fair but a bit complicated, for each type tx especially (muiti)path payment or future muiti-operation tx need determine the base fee before sign it. |
|
I will always strongly oppose the use of PoW as any part of a transaction fee. It is heavily biased in favor of the attacker and against the legitimate user. The attacker can seek out the most cost-effective hardware and the cheapest power. Legitimate users have whatever they have. It's a terrible solution, forcing value that the ledger creates to go to equipment manufacturers and electric companies rather than staying in the ecosystem. I would strongly prefer proposals that are the least likely to break existing code. There is a lot of software, much of it unfortunately unmaintained, that interacts with the XRP Ledger and any changes that make anything that's widely used that currently works break strikes me as undesirable unless there's really no better choice. For example, I'd prefer approaches that de-prioritize transactions based on size when recent ledger space consumption is especially elevated over approaches that raise the required minimum fees. Another possible option is to track recent ledger space consumption by account and require higher fees from accounts that have sent a lot of transactions, or a lot of large transactions, recently. Though this might just encourage determined attackers to use large numbers of accounts, I guess. Perhaps agree by consensus on a target maximum ledger growth rate and monitor recent ledger sizes. If the size exceeds the target, first start de-prioritizing large transactions or transactions from accounts that have sent lots of transaction recently. Always permit a reasonable fee to bypass any such limitations so nothing is prevented, just forced to bear costs commensurate with those it imposes on others. If all else fails to keep the growth in the target, escalate the fee structure completely. This would cause such an attack to just result in other people having to pay higher fees for larger transactions while the attack was going on. The attacker would push up the fees they themselves would have to pay and attacks would wind up being brief and self-limiting. |
|
Something of concern is that if the first N transaction of an account in short local (or global) size bursts are cheaper than the next ones, this incentivizes using up actual state (by funding new accounts) instead of just spamming transaction history. Yes, this has a certain cost (currently only 20 XRP!) in the form of reserves, but is hurting the system a lot more than just using up disk space of full history nodes or badly configured partial history ones. |
|
I guess it comes down to exactly what sort of problem we think we have. If we think that average-sized transactions are sufficiently handled with the existing fee escalation and the only real issue is that large and small transactions cost the same, then we never have to burden the most common transactions that people make today such as transfers of XRP with no (or minimal) memo. I suppose the cleanest change would be to start by taking size into account when computing the base transaction fee with things adjusted so that the vast majority of transactions made today still have a 10 drop base fee. For example (and I'm totally making numbers up here, I haven't measured) if 95% of transactions are less than 1KB, we can make transactions under 1KB pay the base fee and transactions over 1KB pay one base fee per kilobyte. If we think the problem is that a bad actor can just spam the ledger with 10 drop transactions and not deny any service (except to people who submit 10 drop transactions) but cause an unacceptable ledger growth rate, then I think we need to raise the base fee from 10 drops to a higher amount or, alternatively, trigger fee escalation whenever the transaction rate is higher than some amount. One the bright side, I don't believe there's any serious short-term attack. I believe the threat is that an attacker can maliciously gradually increase the cost of running a server and keeping history over a long period of time. |
|
https://bithomp.com/explorer/r3WRgUARJi8G6SDDjE8w3s6u17d7SrpbWZ What is the problem that currently needs to be solved? Find a way to disincentivize actors from spamming with long useless memos by making it financially expensive to do so? or Prevent the upload of illegal data via memos that both contain a chunk and reference the previous one needed to rebuild a file? |
|
I'd place the issues into two categories:
Proposed solutions seem to fit into these boxes: TL;DR - I don't consider B/C to be viable. I think a combination of A (fee changes) and D (memo hashing) are required to really resolve both resource burdens and censorship of illicit/spammy content. D is the only one of these that attempts to attack issue 2. Costs are easier to resolve than legal issues. As such, I find some form of D to be imperative if there are parties engaging in illicit-content attacks. So long as any form of arbitrary data exists with a transaction, this is a possibility. Limiting the memo to a single, arbitrary byte would still allow storage of an obnoxiously chunked 1kb file, just at a significantly higher cost. Allowing the memo type "YourFavoriteHash" still leaves the possibility of repeating the string "XRPScam" (or other arbitrary data) up to the byte-length expected of the hash, unless the hash is verified by validators. As much as I'd hate to see another processing burden on validators, the only extremely (I think?) solid solution I see is:
Drawbacks:
Note: I see that while I was busy with this novel, @socratesfin had the same question about which problem(s) were being addressed here. |
|
Most chunks are submitted to the same ledger, and have the same sender and recipient. Maybe it’s time to consider an anti-spam measure to prevent accounts from submitting too many transactions too fast? It could be limited to check for e.g. transactions of same type or same sender and recipient. And enforced by having a max number of transactions per ledger or using a velocity algorithm to calculate velocity over multiple ledgers and simply fail transactions when the limit is hit. It would prevent this kind of spam, but also mixer services sending many minor payments to obfuscate size and recipients. A backtest could be done to check who would’ve been caught in the past to ensure the right balance is found. |
|
@Silkjaer - Regarding a velocity limit:
Edit: I think my primary message here is that trying to prevent bad actors from doing bad things is a futile effort. This principle is already illustrated in the XRPL since, In short, you can broadcast anything you want, but no one has to listen. In this case, only forcing the storage of a memo hash means "bad actors can broadcast as much of any type of data as they want without forcing validators to choose between storing history and refusing to store the bad actors' content." |
|
As a general principle, my philosophy is that the cost to perform a transaction on a public ledger should never be significantly less than the actual cost the transaction imposes on the other users of the network. There can be a certain base level of subsidized service when demand is low (as 10 drop transactions currently are) so long as that can't be abused to discourage people from operating full nodes. I don't like heuristics that try to tell "bad" users from "good" users because the criteria are always going to be problematic. I prefer adjusting transaction costs based on objective criteria related to the actual costs imposed. These are much harder to game and, I think, much more fair. |
|
The cost to store a chunk of data “forever” actually depends on the contents of the data, because the primary business model for paying for data storage is to charge people who want to access it. The greater the number of people who want to access the data the more viable it is to store. That’s why splitting the data into “core” and “auxiliary” with a segwit style division makes sense. Relatively speaking a lot of people want access to all the core blockchain data but some guys 1Gib podcast encoded into 1,000,000 memos, not so much. In a sense the current system forces people who want access to historical core data to subsidise storage for non core data. If abuse continues indefinitely I foresee the historical core data becoming simply unavailable as a result. |
|
from discord https://ndm-inf.github.io/ndm/fileIndex |
|
lol, I actually embedded some images using memos back in the day ...
lost the code for piecing them back together though ...
can't recall what ledger/txn etc
… |
|
@TexasHodlem It could also use payment amount as a factor and all in an effort to limit DDOS-type attacks. As long as history is public, fees are low and speed is fast, it will be an open invitation to use the system unintentionally. Like banks are also targets for graffiti artists because it has walls. If a velocity factor is used, transparency of when limit is hit is opaque, and any high-frequency service would have to implement error handling. It would complicate misuse, not avoid it, hence not targeting any illicit/unintentional use directly. The tricky part would be to find the right factors to use and avoid trapping real use. I suppose high-frequency, low amount payments would be better served using payment channels anyway :) |
|
Loosing access to full history (or long term history) would/could complicate AML measures such as checks to see if a VASP is receiving “dirty” XRP. If history is paywalled every VASP would have to rely on established parties to buy access, host a full history node themselves or use AML service providers who does. It would give established parties in the space an added benefit – as it is now everyone is equal only limited by own technical competences, allowing small players to participate in or even accelerate innovation. |
|
Is this 32 bytes per memo or 32 bytes of memo(s) per tx? A tx can have multiple memo's. I tend to use two memo's per tx. The first memo is the wallet version used to sign the tx. The second memo I use to mark my orders with an identifying word. |
|
@jargoman 32 bytes across all Memos, MemoTypes, and MemoFormats together. |
|
|
Regarding the "illicit data" problem, I'd like to reiterate (as several others have mentioned) that the "memo hash" proposition does not ultimately fix the problem. The hash field itself doesn't have to be a hash; it could just be used as an arbitrary data field of whatever size hash it is, and servers themselves probably couldn't tell the difference. There are other fields that can be used to store arbitrary data, like destination tags, which have important and legitimate use cases. At best, memo hashing makes it more effort to encode illicit data into the indispensable fields of a transaction and might reduce how many bytes any single transaction could store. This is an intrinsic problem of all blockchains. As long as the idea that "having" a specific string of bytes is illegal, operators are forced to choose between storing illegal data or not being able to reconstruct all history. The XRP Ledger has it less bad than Bitcoin, because on the XRP Ledger you don't need to replay all history to know the latest state. Memo hashing also impacts legitimate uses of memos today so we should only take action if there's a reasonable belief that the pros and cons of memo hashing are weighted appropriately.
The other problem is "spammy data". This problem can be summed up as:
As some commenters above have pointed out, it's already pretty expensive to serve full history, even without that many large-size transactions. It would improve the overall utility and accessibility of the network if we could do things to make it easier to store history in general. History sharding is a good step in that regard. Charging a size fee for transactions might help, but my intuition is that it wouldn't have a big impact on the current ledger. Another idea (credit @ximinez for the idea) would be to make an effort to reduce the number of failed transactions that get stored in the ledger. If you submit a cross-currency Payment that can't succeed because it requires paths that don't exist, for example, you'll probably get a |
|
@TrashAccount3424
I don't necessarily disagree with you that all combinations of bits should be legally equal as far as the machinery of the Internet is concerned however this is effectively activism and not really appropriate for this discussion. The reality is full history nodes need to comply with the laws in the jurisdictions where they are hosted. If this becomes impossible for most jurisdictions there simply won't be any FH nodes. |
We are certainly moving in the "build deterministic shards and store history on HDD" direction and moving rapidly: the idea is that each server will maintain a minimum of two shards: the "current" (open) shard, and the the "previous" shard. Beyond that, a server can opt to keep as many shards as it wants, with each shard being fully self-contained. |
|
I have mostly read this thread but might have missed something. To me a solution where the cost of the transaction is increased with 1 (or a multiplier of it) drop for every byte of a memo (or other free-form data fields) looks best:
I don't think I've read such a proposal in this PR. Perhaps I missed something that makes this proposal nonviable. There's no way to prevent illicit content from being uploaded. Nor is there certainty that you would be able to trace it back to the person who did it (e.g. hacked account). |
|
Thanks for contributing code, but the consensus seems to be that this is premature and that we shoulnd't rush to get this adopted, so I am going to be closing this PR. If you would like to continue discussing the topic of fees and ensuring that fees charged remain effective at preventing ledger and tx spam, please feel free to open a separate issue and reference this PR for context. |
No description provided.