Apache of Kafka Architecture (As per Apache Kafka 0.8.0 Dcoumentation)
Architecture of Apache Kafka I will first introduce the basic concepts in Kafka.
- A stream of messages of a particular type is defined as a topic.
- A producer can publish messages to a topic.
- The published messages are then stored at a set of servers called brokers.
- A consumer can subscribe to one or more topics and consume the published messages by pulling data from the brokers.
Messaging is conceptually simple. A message is defined to contain just a payload of bytes. A user can choose their favorite serialization method to encode a message. For efficiency, the producer can send a set of messages in a single publish request.
Sample producer code:
producer = new Producer(…);
message = new Message("test message str".getBytes());
set = new MessageSet(message);
producer.send("topic1", set);
For subscribing topic, a consumer first create one or more message streams for the topic. The messages published to that topic will be evenly distributed into these streams. Each message stream provides an iterator interface over the continual stream of messages being produced. The consumer then iterates over every message in the stream and processes the payload of the message. Unlike traditional iterators, the message stream iterator never terminates. If currently no message is there to consume, the iterator blocks until new messages are published to the topic. Kafka support both the point-to-point delivery model in which multiple consumers jointly consume a single copy of messages in a topic, as well as the publish-subscribe model in which multiple consumers retrieve its own copy of a topic.
Sample consumer code:
streams[] = Consumer.createMessageStreams(“topic1”, 1)
for (message : streams[0]) {
bytes = message.payload();
// do something with the bytes
}
The overall architecture of Kafka is shown in Figure 1. Since Kafka is distributed in nature, a Kafka cluster typically consists of multiple brokers. To balance load, a topic is divided into multiple partitions and each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.

Figure 1- Kafka Architecture
Kafka Storage - Kafka has a very simple storage layout. Each partition of a topic corresponds to a logical log. Physically, a log is implemented as a set of segment files of equal sizes. Every time a producer publishes a message to a partition, the broker simply appends the message to the last segment file. Segment file is flushed to disk after configurable number of messages has been published or after certain amount of time. Messages are exposed to consumer after it gets flushed.
Unlike traditional message system, a message stored in Kafka system doesn’t have explicit message ids. Messages are exposed by the logical offset in the log. This avoids the overhead of maintaining auxiliary, seek-intensive random-access index structures that map the message ids to the actual message locations. Messages ids are increasing but not consecutive. To compute the id of next message adds a length of the current message to its logical offset.
Consumer always consumes messages from a particular partition sequentially and if the consumer acknowledge particular message offset, it implies that the consumer has consumed all prior messages. Consumer issues asynchronous pull request to the broker to have a buffer of bytes ready to consume. Each asynchronous pull request contains the offset of the message to consume. Kafka exploits the sendfile API to efficiently deliver bytes in a log segment file from a broker to a consumer.
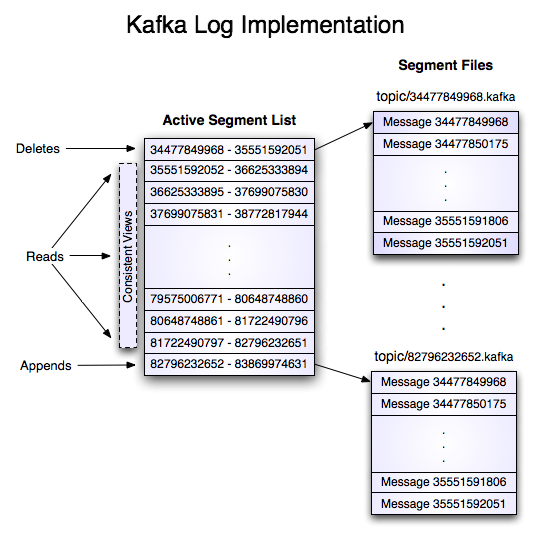
Figure 2- Kafka Storage Architecture
Kafka Broker: Unlike other message system, Kafka broker are stateless. By stateless, means consumer has to maintain how much he has consumed. Consumer maintains it by itself and broker would not do anything. Such design is very tricky and innovative in itself –
-
It is very tricky to delete message from the broker as broker doesn't whether consumer consumed the message or not. Kafka solves this problem by using a simple time-based SLA for the retention policy. A message is automatically deleted if it has been retained in the broker longer than a certain period.
-
This design has a benefit too, as consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but proves to be an essential feature for many consumers