Training‐Lora
我们提供了一个可供EasyAnimate进行Lora训练的图文数据集。
这是一个人像的Minimalism极简风数据集,共包含约20张图片,其中demo如下所示:

数据集中已经提供了标注信息。我们可以将其放置在datasets目录下,如下图所示。
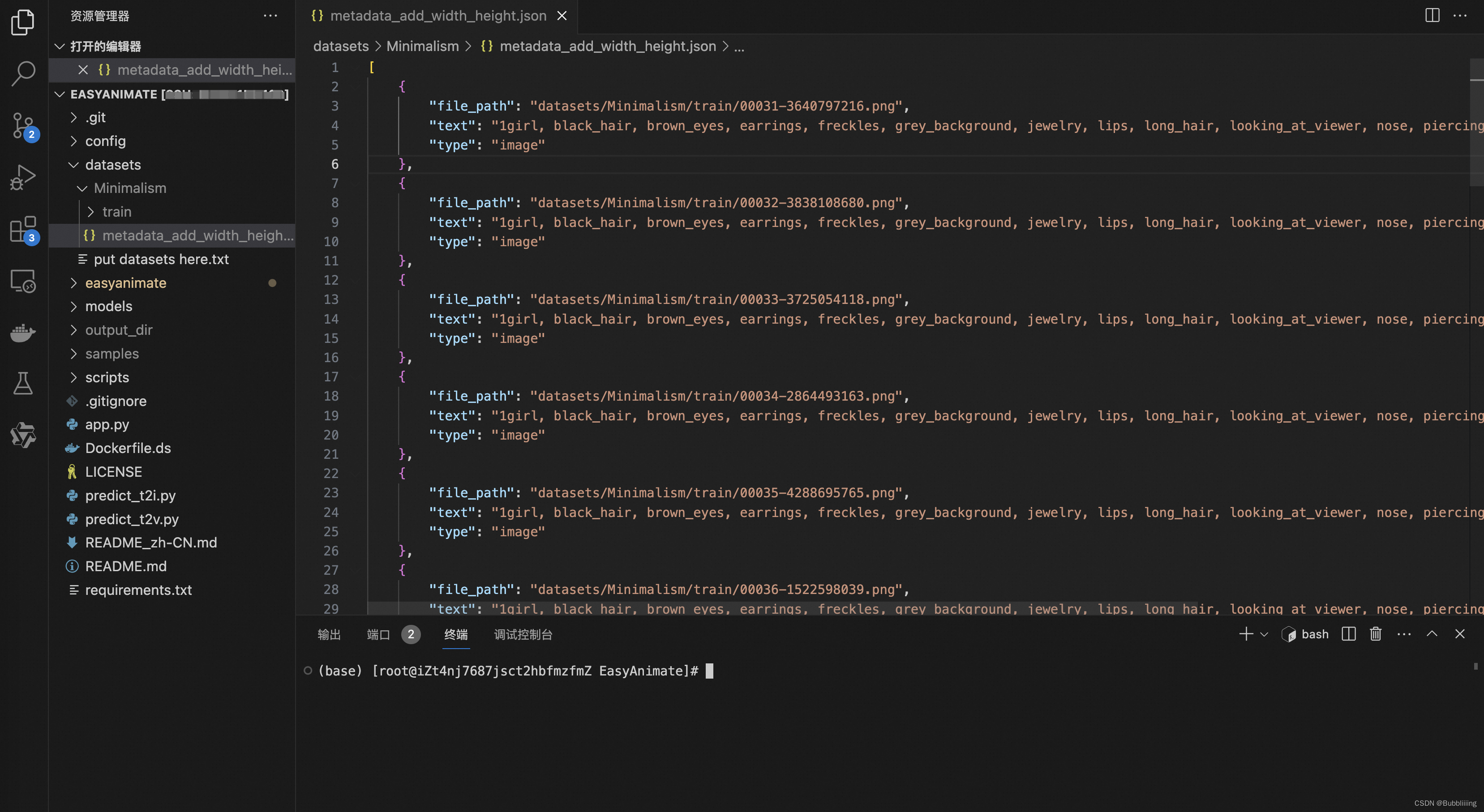
在这里我们即可使用相对路径也可以使用绝对路径,为了不同机器的使用方便,这里我使用了相对路径。
如果同学们期待使用自己的数据集进行训练,训练准备数据集json文件,数据集json文件的格式如下:
[
{
"file_path": "videos/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "train/00000001.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]其中,file_path指的是文件的路径,type指的是文件的种类,有video和image两种,text指的是视频对应的描述。
训练Lora权重需要使用到scripts/train_lora.sh文件,我们首先更新其中的MODEL_NAME、DATASET_NAME和DATASET_META_NAME。
- MODEL_NAME指向了模型的权重文件,这里我们以EasyAnimateV5-7b为例进行演示。
- DATASET_NAME指向了数据集相对路径的根目录,以本文的摆放路径为例,直接指定EasyAnimate的根目录即可,即"./"
- DATASET_META_NAME指向了数据集对应的json文件,指向Minimalism下的json文件,即"datasets/Minimalism/metadata_add_width_height.json"即可。

不同的显卡有可以有不同设置方案,本文以24G显卡(对应A10、3090、4090、4090D显卡)为例,讲述EasyAnimate最低的Lora训练需求,当使用A100、A800和H800时,可以根据自身需要调整参数。
- EasyAnimateV5在扩大模型参数量后,原始low rank dim为128的Lora已经无法在24G显卡上进行训练,因此需要适当减少rank和network_alpha,在这里我们减少rank为16,network_alpha为8;
- 进一步减少显存需求,在这里我们开启low_vram减少显存需求,在无用text encoder和vae时,将其offload到cpu上。
- 进一步减少显存需求,在这里我们开启deepspeed zero2进行训练,在参数中加入deepspeed。
- 由于训练的是图片,将对应video_sample_n_frames设置为1。

训练sh具体为:
export MODEL_NAME="models/Diffusion_Transformer/EasyAnimateV5-7b-zh-InP"
export DATASET_NAME=""
export DATASET_META_NAME="datasets/Minimalism/metadata_add_width_height.json"
export NCCL_IB_DISABLE=1
export NCCL_P2P_DISABLE=1
NCCL_DEBUG=INFO
# When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
accelerate launch --use_deepspeed --deepspeed_config_file config/zero_stage2_config.json --deepspeed_multinode_launcher standard scripts/train_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATASET_NAME \
--train_data_meta=$DATASET_META_NAME \
--config_path "config/easyanimate_video_v5_magvit_multi_text_encoder.yaml" \
--image_sample_size=1024 \
--video_sample_size=256 \
--token_sample_size=512 \
--video_sample_stride=3 \
--video_sample_n_frames=1 \
--train_batch_size=1 \
--video_repeat=1 \
--gradient_accumulation_steps=1 \
--dataloader_num_workers=8 \
--num_train_epochs=100 \
--checkpointing_steps=100 \
--learning_rate=1e-04 \
--seed=42 \
--low_vram \
--output_dir="output_dir" \
--gradient_checkpointing \
--mixed_precision="bf16" \
--adam_weight_decay=5e-3 \
--adam_epsilon=1e-10 \
--vae_mini_batch=1 \
--max_grad_norm=0.05 \
--random_hw_adapt \
--rank=16 \
--network_alpha=8 \
--training_with_video_token_length \
--not_sigma_loss \
--enable_bucket \
--use_deepspeed \
--uniform_sampling \
--train_mode="inpaint"开始训练的流程较为简单,在配置好的环境下直接sh scripts/train_lora.sh即可。

开始训练后如下所示:
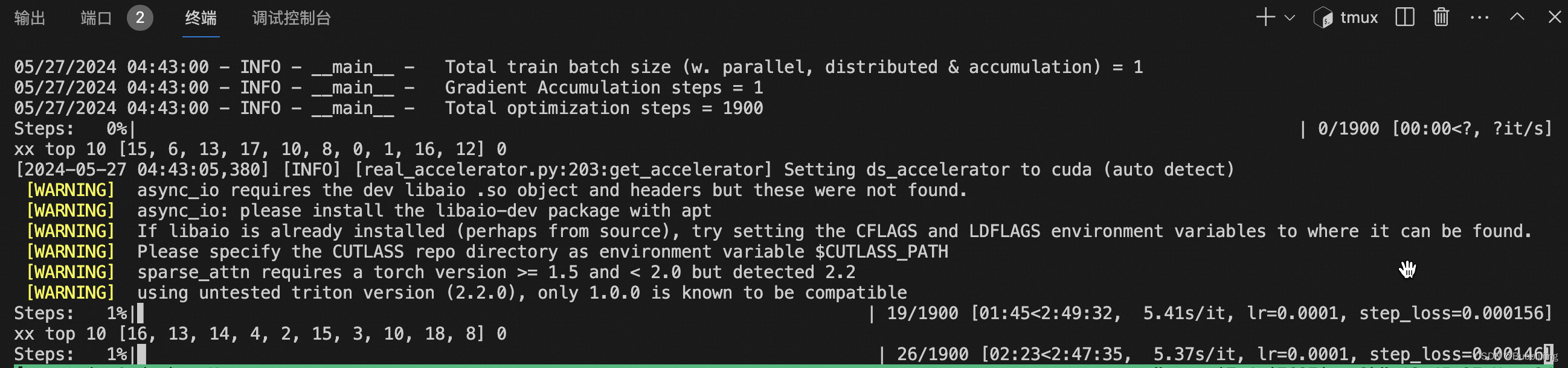
我们首先将训练好的Lora移动到指定的文件夹。

然后python app.py启动webui,在页面上进行选择。

点击下方的生成即可获得结果。