git clone https://github.com/arun2728/Abstractive-Text-Summarization.git
cd Abstractive-Text-Summarization
pip install -r requirements.txt
from preprocessing import Preprocessing
from model import T5Summarizer
# Perform data preprocessing
preprocessing = Preprocessing()
# Train T5 Summarizer
summarizer = T5Summarizer()
t5_model = summarizer.train(preprocessing)Note: The trained model will be saved automatically in the checkpoints folder.
-
Download the model checkpoint from here. Move the file to model_checkpoint folder. Skip this if you trained the model
-
Add the text which is to be summarized into test_article.txt file.
-
Then run the following commands:
from config import config
from model import NewsSummaryModel
tester = Tester()
text = tester.read_input(file_path = "./test_article.txt")
summary = tester.summarize(text, tester.model)
print(summary)In the modern Internet age, textual data is ever increasing. We need some way to condense this data while preserving the information and its meaning. We need to summarise textual data for that. Text summarisation is the process of automatically generating natural language summaries from an input document while retaining the important points. It helps in the easy and fast retrieval of information.
There are two prominent types of summarisation algorithms:
- Extractive Text Summarization: In this summarization technique we form summaries by copying parts of the source text through some measure of importance and then combining those parts/sentences together to render a summary. The importance of the sentence is based on its linguistic and statistical features.

- Abstractive Text Summarization: Abstractive summarisation includes generating new phrases, possibly rephrasing or using words that were not in the original text.

Naturally abstractive approaches are harder. For a perfect abstractive summary, the model has to first truly understand the document and then try to express that understanding in shortform, possibly using new words and phrases. This is much harder than an extractive summary, requiring complex capabilities like generalisation, paraphrasing and incorporating real-world knowledge.
The primary objective of this project is to deploy advanced NLP techniques to generate grammatically correct and insightful summaries for a given article. To accomplish this, we will test various publicly available transformer models for seq-to-seq modeling and retrain them on the wikiHow dataset.
Dataset Repo - News Summary
The dataset consists of 4515 examples and contains Author_name, Headlines, Url of Article, Short text, Complete Article. I gathered the summarized news from Inshorts and only scraped the news articles from Hindu, Indian times and Guardian. Time period ranges from febrauary to august 2017.
| Number of sentences | Independent Feature | Target Data Column |
|---|---|---|
4515 |
ctext |
text |
To achieve best in class outcomes for the above mentioned experiment, we are using Transformers. Transformer is an architecture for transforming one sequence into another one with the help of two parts (Encoder and Decoder), but it differs from the traditional sequence-to-sequence models because it does not imply any Recurrent Networks (GRU, LSTM, etc.).
So, what exactly is a Transformer? An image is worth a thousand words, so we will start with that!

On a high level, the encoder maps an input sequence into an abstract continuous representation that holds all the learned information of that input. The decoder then takes that continuous representation and step by step generates a single output while also being fed the previous output.
Let’s see how this setup of the encoder and the decoder stack works:
The word embeddings of the input sequence are passed to the first encoder. These are then transformed and propagated to the next encoder. The output from the last encoder in the encoder-stack is passed to all the decoders in the decoder-stack as shown in the figure below:

An important thing to note here – in addition to the self-attention and feed-forward layers, the decoders also have one more layer of Encoder-Decoder Attention layer. This helps the decoder focus on the appropriate parts of the input sequence.
What is Self-Attention?
Self-attention, sometimes called intra-attention, is an attention mechanism relating to different positions of a single sequence in order to compute a representation of the sequence.
Self-attention allows the model to look at the other words in the input sequence to get a better understanding of a certain word in the sequence.
More details can be found here.
Google’s T5(Text-To-Text Transfer Transformer): T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a different prefix to the input corresponding to each task, e.g.: For translation: Translate English to German

Facebook’s Bart: BART is a denoising autoencoder that maps a corrupted document to the original document it was derived from. It is implemented as a sequence-to-sequence model with a bidirectional encoder over corrupted text and a left-to-right autoregressive decoder.
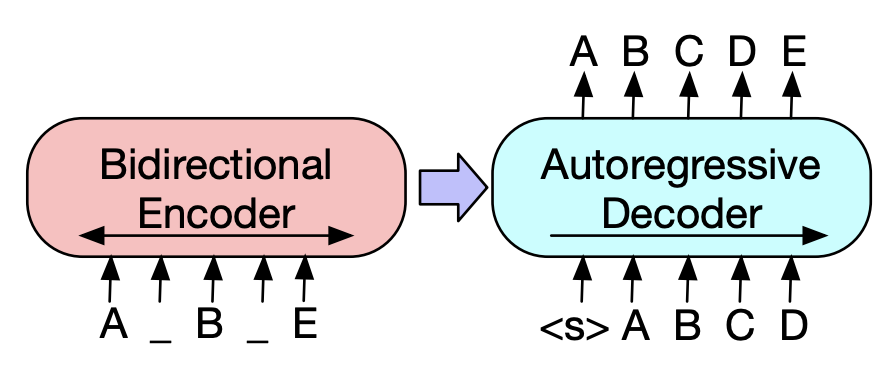


In the scope of this experiment, we have adopted only content-based methods to measure the performance. Method used is:
Rouge Score: ROUGE stands for Recall-Oriented Understudy for Gisting Evaluation. It is essentially a set of metrics for evaluating automatic summarisation of texts as well as machine translation. It works by comparing an automatically produced summary or translation against a set of reference summaries (typically human-produced).
It is further divided into different measures depending upon the granularity. More details can be found here
- ROUGE-1 refers to overlap of unigrams between the system summary and reference summary
- ROUGE-2 refers to the overlap of bigrams between the system and reference summaries
- ROUGE-L – measures longest matching sequence of words using LCS
- T5 Transformer: We have retrained the T5 model on the pubmed dataset and then found the summary for 9 different combinations of hyperparameters. Some of the hyperparameters are listed below:
- Beam Search: Beam search reduces the risk of missing hidden high probability word sequences by keeping the most likely num_beams of hypotheses at each time step and eventually choosing the hypothesis that has the overall highest probability.
- Sampling: Sampling means randomly picking the next word according to its conditional probability distribution.
- Top k-sampling: In Top-K sampling, the K most likely next words are filtered and the probability mass is redistributed among only those K next words.
- Top-p (nucleus) sampling: Instead of sampling only from the most likely K words, Top-p sampling chooses from the smallest possible set of words whose cumulative probability exceeds the probability p.
- Temperature: Temperature is a trick is to make the distribution P(w|w1:t−1) sharper (increasing the likelihood of high probability words and decreasing the likelihood of low probability words) by lowering the so-called temperature of the softmax.
- Bart Transformer: Similar to T5, Bart is also retrained on Pubmed dataset using FastAi with the help of a wrapper called Blurr which acts as an interface between two state-of-the-art models.
We were able to summarise articles within our dataset with a Rouge-1 score above 0.35 and Rouge-L score above 0.3 which are inline with the publicly accepted benchmarks.
| Model | Rouge-1 | Rouge-2 | Rouge-l |
|---|---|---|---|
| T5 | 0.453173 |
0.232103 |
0.418052 |
| Bart | 0.431542 |
0.208504 |
0.398183 |
We were able to identify the best combination of various parameters to extract the most human-like summary. The best combination is as follows:
num_beams = 4
no_repeat_ngram_size = 3
min_length = 100
max_length = 300
early_stopping = True
There are a few possible direct extensions of this work -
-
More Accurate Summaries: We can further increase the accuracy of the model by training it on an even larger dataset and datasets from various other domains.
-
Extend Evaluation Measurement Parameters: We can extend the summary evaluation pipeline by including text quality measurement and other extrinsic measures that evaluates the performance of models in terms of generated text i.e. if the grammar of the generated sentence is acceptable with the correct structure and referential clarity.
-
Extension to additional NLP tasks: Since this experiment is an application of the wider Natural Language Generation problem, the algorithms trialled here can be tweaked and applied for Machine Reading Comprehension and Question Answering systems.