| nearest neighbors of frog |
Litoria | Leptodactylidae | Rana | Eleutherodactylus |
|---|---|---|---|---|
| Pictures |  |
 |
 |
 |
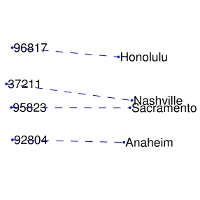
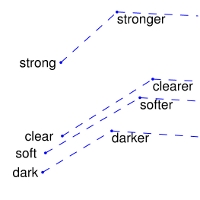
| Comparisons | man -> woman | city -> zip | comparative -> superlative |
|---|---|---|---|
| GloVe Geometry | 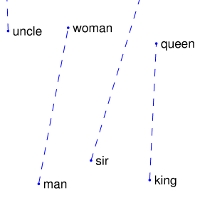 |
 |
 |
We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the project page or the paper for more information on glove vectors.
The links below contain word vectors obtained from the respective corpora. If you want word vectors trained on massive web datasets, you need only download one of these text files! Pre-trained word vectors are made available under the Public Domain Dedication and License.
- Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download): glove.42B.300d.zip
- Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download): glove.840B.300d.zip
- Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 300d vectors, 822 MB download): glove.6B.zip
- Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 200d vectors, 1.42 GB download): glove.twitter.27B.zip

If the web datasets above don't match the semantics of your end use case, you can train word vectors on your own corpus.
$ git clone http://github.com/stanfordnlp/glove
$ cd glove && make
$ ./demo.sh
The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading demo.sh or the src/README.md
All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.