Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
32606: kv: set sane default for kv.transaction.write_pipelining_max_batch_size r=nvanbenschoten a=nvanbenschoten Informs #32522. There is a tradeoff here between the overhead of waiting for consensus for a batch if we don't pipeline and proving that all of the writes in the batch succeed if we do pipeline. We set this default to a value which experimentally strikes a balance between the two costs. To determine the best value for this setting, I ran a three-node single-AZ AWS cluster with 4 vCPU nodes (`m5d.xlarge`). I modified KV to perform writes in an explicit txn and to run multiple statements. I then ran `kv0` with 8 DML statements per txn (a reasonable estimate for the average number of statements that an **explicit** txn runs) and adjusted the batch size of these statements from 1 to 256. This resulted in the following graph: 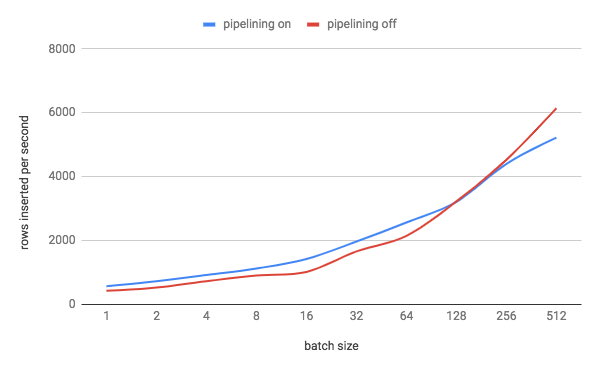 We can see that the cross-over point where txn pipelining stops being beneficial is with batch sizes somewhere between 128 and 256 rows. Given this information, I set the default for kv.transaction.write_pipelining_max_batch_size` to 128. Of course, there are a lot of variables at play here: storage throughput, replication latency, node size, etc. I think the setup I used hits a reasonable middle ground with these. Release note: None Co-authored-by: Nathan VanBenschoten <[email protected]>
{kind=link}
- Loading branch information