kv: bound the size of in-flight write tracking in txnPipeliner #32522
Comments
|
Thanks @manigandham. As the node crashes, does it leave anything in |
|
Are you talking about the folder on the node? I already deleted the cluster but can run the process again... |
|
It looks like the debug output contains that? Can you check the attached zip file and see if it's valid? |
|
Oh, I had missed that attached file. Apologies! Taking a look. |
|
@nvanbenschoten this looks like your wheelhouse. We don't unconditionally support large transactions, but the profile indicates something we need to fix regarding the txn pipeliner.
|

|
@tbg, @nvanbenschoten, back in v1.0, we had a known limitation about truncating a large table. But that was resolved, and we no longer have a stated limitation about large transactions. At the very end of a current limitation about Write and update limits for a single statement, we say:
Given that large transactions can go beyond just impacting performance (and crash nodes, as in this case), should we create a separate known limitation about this? This might also be another sign that we need to revive the docs project to identify and publish "production limits" (nodes, dbs, tables, rows, transactions, etc.), even if they are just recommendations based on our current understanding. |
|
Large transactions are still a bad idea, though we weren't aware of them causing an outright memory blowup as seen here. My assumption right now is that this is a regression. |
|
Another update: reading the table with a Our expectation is that updates and queries will always complete, even if slow. Is this inaccurate? Will there be hard limits to data updates? And if so, how would we approach such large transactions? |
Informs cockroachdb#32522. There is a tradeoff here between the overhead of waiting for consensus for a batch if we don't pipeline and proving that all of the writes in the batch succeed if we do pipeline. We set this default to a value which experimentally strikes a balance between the two costs. To determine the best value for this setting, I ran a three-node single-AZ AWS cluster with 4 vCPU nodes (`m5d.xlarge`). I modified KV to perform writes in an explicit txn and to run multiple statements. I then ran `kv0` with 8 DML statements per txn (a reasonable estimate for the average number of statements that an **explicit** txn runs) and adjusted the batch size of these statements from 1 to 256. This resulted in the following graph: <see graph in PR> We can see that the cross-over point where txn pipelining stops being beneficial is with batch sizes somewhere between 128 and 256 rows. Given this information, I set the default for `kv.transaction.write_pipelining_max_batch_size` to 128. Of course, there are a lot of variables at play here: storage throughput, replication latency, node size, etc. I think the setup I used hits a reasonable middle ground with these. Release note: None
|
The memory blowup in the txn pipeliner is due to two issues. The first is that the The other issue is more general - we need to address this TODO: cockroach/pkg/kv/txn_interceptor_pipeliner.go Lines 185 to 187 in a7e13e8 I suspect that the first issue is the cause of almost all cases where this memory blows up, but we should have a hard memory bound here regardless.
This sounds like a different issue. Is it reproducible for you? |
Informs cockroachdb#32522. There is a tradeoff here between the overhead of waiting for consensus for a batch if we don't pipeline and proving that all of the writes in the batch succeed if we do pipeline. We set this default to a value which experimentally strikes a balance between the two costs. To determine the best value for this setting, I ran a three-node single-AZ AWS cluster with 4 vCPU nodes (`m5d.xlarge`). I modified KV to perform writes in an explicit txn and to run multiple statements. I then ran `kv0` with 8 DML statements per txn (a reasonable estimate for the average number of statements that an **explicit** txn runs) and adjusted the batch size of these statements from 1 to 256. This resulted in the following graph: <see graph in PR> We can see that the cross-over point where txn pipelining stops being beneficial is with batch sizes somewhere between 128 and 256 rows. Given this information, I set the default for `kv.transaction.write_pipelining_max_batch_size` to 128. Of course, there are a lot of variables at play here: storage throughput, replication latency, node size, etc. I think the setup I used hits a reasonable middle ground with these. Release note: None
32606: kv: set sane default for kv.transaction.write_pipelining_max_batch_size r=nvanbenschoten a=nvanbenschoten Informs #32522. There is a tradeoff here between the overhead of waiting for consensus for a batch if we don't pipeline and proving that all of the writes in the batch succeed if we do pipeline. We set this default to a value which experimentally strikes a balance between the two costs. To determine the best value for this setting, I ran a three-node single-AZ AWS cluster with 4 vCPU nodes (`m5d.xlarge`). I modified KV to perform writes in an explicit txn and to run multiple statements. I then ran `kv0` with 8 DML statements per txn (a reasonable estimate for the average number of statements that an **explicit** txn runs) and adjusted the batch size of these statements from 1 to 256. This resulted in the following graph: 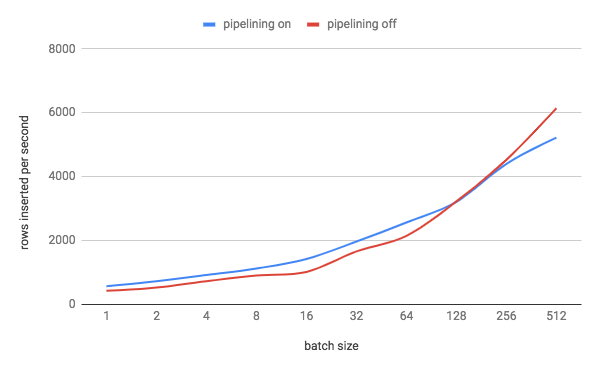 We can see that the cross-over point where txn pipelining stops being beneficial is with batch sizes somewhere between 128 and 256 rows. Given this information, I set the default for kv.transaction.write_pipelining_max_batch_size` to 128. Of course, there are a lot of variables at play here: storage throughput, replication latency, node size, etc. I think the setup I used hits a reasonable middle ground with these. Release note: None Co-authored-by: Nathan VanBenschoten <[email protected]>
|
Somewhat reproducible. After crashing from the delete query, I restart the node, then run the Here's a screenshot of a 17 minute query time. Running the same exact query again takes 44 seconds.
|

{kind=link}
Informs cockroachdb#32522. There is a tradeoff here between the overhead of waiting for consensus for a batch if we don't pipeline and proving that all of the writes in the batch succeed if we do pipeline. We set this default to a value which experimentally strikes a balance between the two costs. To determine the best value for this setting, I ran a three-node single-AZ AWS cluster with 4 vCPU nodes (`m5d.xlarge`). I modified KV to perform writes in an explicit txn and to run multiple statements. I then ran `kv0` with 8 DML statements per txn (a reasonable estimate for the average number of statements that an **explicit** txn runs) and adjusted the batch size of these statements from 1 to 256. This resulted in the following graph: <see graph in PR> We can see that the cross-over point where txn pipelining stops being beneficial is with batch sizes somewhere between 128 and 256 rows. Given this information, I set the default for `kv.transaction.write_pipelining_max_batch_size` to 128. Of course, there are a lot of variables at play here: storage throughput, replication latency, node size, etc. I think the setup I used hits a reasonable middle ground with these. Release note (performance improvement): Change the default value for the cluster setting kv.transaction.write_pipelining_max_batch_size to 128. This speeds up bulk write operations.
Fixes cockroachdb#32522. This change creates a new cluster setting called: ``` kv.transaction.write_pipelining_max_outstanding_size ``` It limits the size in bytes that can be dedicated to tracking in-flight writes that have been pipelined. Once this limit is hit, not more writes will be pipelined by a transaction until some of the writes are proven and removed from the outstanding write set. This change once again illustrates the need for periodic proving of outstanding writes. We touch upon that in the type definition's comment and in cockroachdb#35009. Release note: None
Fixes cockroachdb#32522. This change creates a new cluster setting called: ``` kv.transaction.write_pipelining_max_outstanding_size ``` It limits the size in bytes that can be dedicated to tracking in-flight writes that have been pipelined. Once this limit is hit, not more writes will be pipelined by a transaction until some of the writes are proven and removed from the outstanding write set. This change once again illustrates the need for periodic proving of outstanding writes. We touch upon that in the type definition's comment and in cockroachdb#35009. Release note: None
35014: kv: introduce new "max outstanding size" setting to txnPipeliner r=nvanbenschoten a=nvanbenschoten Fixes #32522. This change creates a new cluster setting called: ``` kv.transaction.write_pipelining_max_outstanding_size ``` It limits the size in bytes that can be dedicated to tracking in-flight writes that have been pipelined. Once this limit is hit, not more writes will be pipelined by a transaction until some of the writes are proven and removed from the outstanding write set. This change once again illustrates the need for periodic proving of outstanding writes. We touch upon that in the type definition's comment and in #35009. Release note: None 35199: log: fix remaining misuse of runtime.Callers/runtime.FuncForPC r=nvanbenschoten a=nvanbenschoten Fixes #17770. This commit fixes the last user of `runtime.Callers` that misused the stdlib function by translating the PC values it returned directly into symbolic information (see https://golang.org/pkg/runtime/#Callers) [1]. Go's documentation warns that this is a recipe for disaster when mixed with mid-stack inlining. The other concern in #17770 was this comment: #17770 (comment). This was discussed in golang/go#29582 and addressed in golang/go@956879d. An alternative would be to use `runtime.Caller` here, but that would force an allocation that was hard-earned in #29017. Instead, this commit avoids any performance hit. ``` name old time/op new time/op delta Header-4 267ns ± 1% 268ns ± 0% ~ (p=0.584 n=10+10) VDepthWithVModule-4 260ns ± 3% 255ns ± 1% -1.87% (p=0.018 n=10+9) name old alloc/op new alloc/op delta Header-4 0.00B 0.00B ~ (all equal) VDepthWithVModule-4 0.00B 0.00B ~ (all equal) name old allocs/op new allocs/op delta Header-4 0.00 0.00 ~ (all equal) VDepthWithVModule-4 0.00 0.00 ~ (all equal) ``` [1] I went through and verified that this was still correct. Release note: None 35203: closedts: react faster to config changes r=danhhz a=tbg This approximately halves the duration of `make test PKG=./pkg/ccl/changefeedccl TESTS=/sinkless`, from ~60s to ~30s. Touches #34455. Release note: None Co-authored-by: Nathan VanBenschoten <[email protected]> Co-authored-by: Tobias Schottdorf <[email protected]>
We have a table with a 26M rows and 20 columns. Issuing a delete, for roughly half the rows in the table, crashes the node:
DELETE FROM accounts WHERE datasetversion = 4;Limiting the deletes works, I tried up to 500k without issue.
DELETE FROM accounts WHERE datasetversion = 4 LIMIT 500000;3 nodes x n1-standard-2 (2 cpu / 7.5gb) with local nvme SSD on GCE with 25% cache/mem settings, 3x RF, this is the only table in the database.
Tried it again with a single node with 4 cpu / 15gb, same result
To Reproduce
Start single or multi-node cluster. Run
importof 6gb CSV file containing 26M rows. Run 'DELETE' command filtering on a single column with 2 possible values, which should remove about half of the data. The node connected to the client will slowly run up memory usage until it crashes.Expected behavior
Delete around 12M out of 26M rows in table without crashing.
Environment:
Debug output from 3 node cluster:
debug.zip
The text was updated successfully, but these errors were encountered: